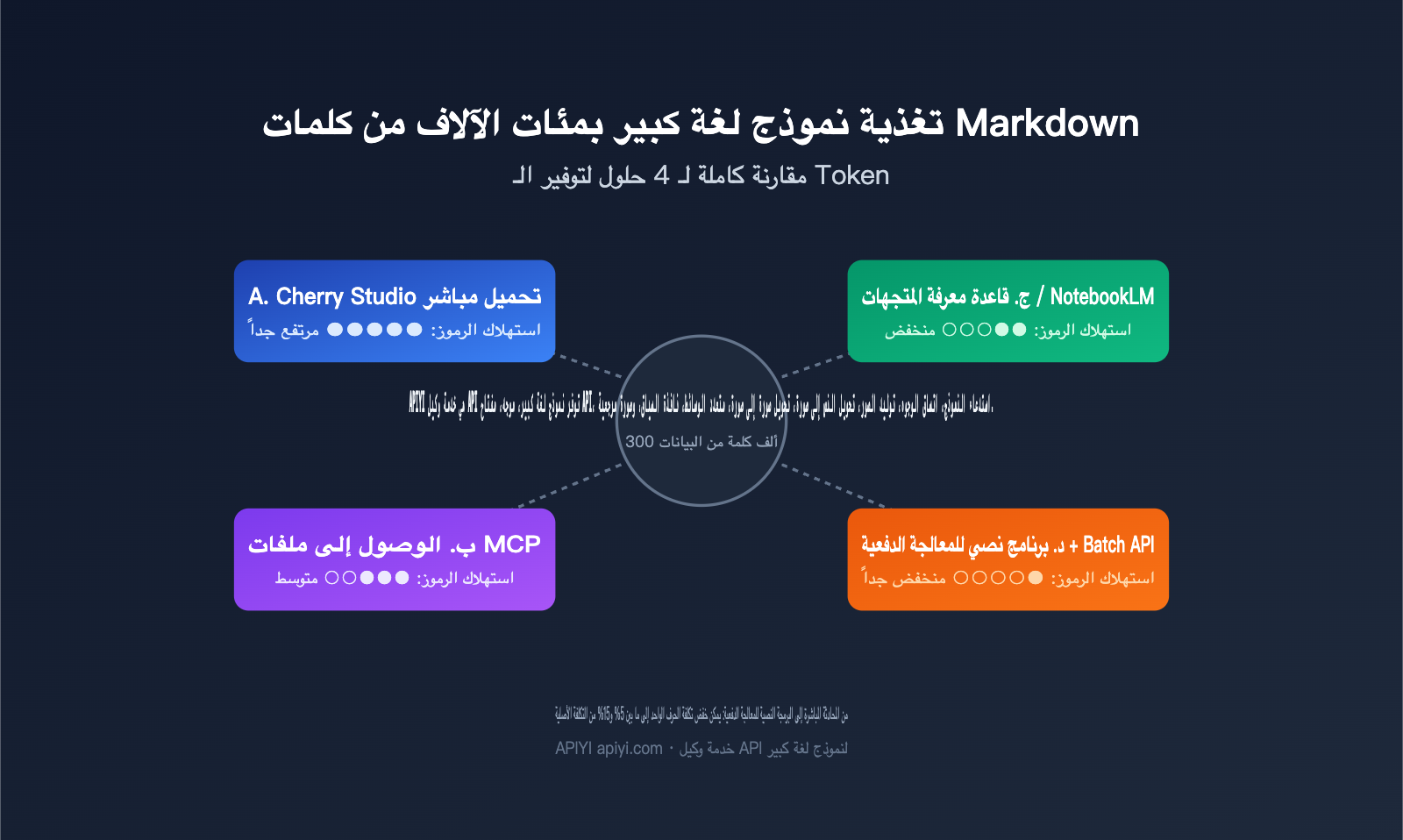
تلقيت مؤخرًا استشارة نموذجية: أراد مستخدم "تقطير" مئات الآلاف من الكلمات من مقالات كاتب خبير ليجعلها أساسًا لأسلوب نموذج لغة كبير، لكنه لم يكن يعرف كيف يدرج ملفات Markdown بأكثر الطرق فعالية من حيث التكلفة. هناك ثلاثة توجهات شائعة: رفع الملفات واحدًا تلو الآخر في أدوات المحادثة مثل Cherry Studio، أو استخدام MCP للسماح للنموذج باستدعاء الملفات مباشرة من القرص الصلب، أو وضع كل شيء في قاعدة معرفية لاستخدام تقنية RAG. للوهلة الأولى، تبدو جميع هذه الطرق قابلة للتنفيذ، ولكن عندما يتجاوز حجم البيانات 300 ألف كلمة، ستتفاوت فواتير الـ Token وزمن الاستجابة بسرعة، واختيار المسار الخاطئ قد يكلفك عشرة أضعاف الميزانية المطلوبة.
ستقوم هذه المقالة بتفكيك وتحليل أربعة توجهات رئيسية لتقليل استهلاك الـ Token عند التعامل مع بيانات Markdown الضخمة للنماذج: الاستهلاك الفعلي للـ Token، تكلفة المهمة الواحدة، زمن استجابة الـ Token الأول، قابلية التحكم، وأفضل خيار لكل حجم من البيانات. في النهاية، سأقدم مسار قرار مرحلي: ما الذي يجب استخدامه في مرحلة الاستكشاف، وما الذي يجب الانتقال إليه بعد التوسع. إذا كنت تعمل حاليًا على تقطير الأسلوب، أو الإجابة على الأسئلة من قاعدة معرفية، أو تنظيف البيانات قبل الضبط الدقيق (Fine-tuning)، فبعد قراءة هذا المقال ستكون قادرًا على اتخاذ قرارك التقني مباشرة.
أولاً: المشكلة الجوهرية لتوفير الـ Token في بيانات Markdown للنماذج الكبيرة
قبل تفكيك الحلول، دعونا نوضح أين تكمن التكلفة الحقيقية. إن تغذية نموذج لغة كبير بمئات الآلاف من كلمات Markdown هي في جوهرها موازنة بين أربع فئات من التكاليف: الـ Token المدخل، الـ Token المخرج، تكلفة الاسترجاع/الفهرسة، وتكلفة الجهد البشري في الضبط.
يُعد الـ Token المدخل العنصر الأكثر استخفافًا به. إذا كانت المدونة التقنية بتنسيق HTML الخام، فإن تحويلها إلى Markdown يوفر عادةً ما بين 70% إلى 80% من الـ Token، لأن الوسوم، والتنسيقات، والسكربتات المضمنة يتم إزالتها. ولهذا السبب، فإن الخطوة الأولى في أي خط أنابيب (Pipeline) لمعالجة البيانات الضخمة هي توحيد المحتوى في Markdown أو txt. إذا قمت بهذه الخطوة بشكل جيد، فإن أساس التكلفة لأي طريقة إدخال تختارها لاحقًا سينخفض درجة كاملة.
قد يبدو الـ Token المخرج غير ذي صلة، لكنه في مهام "التقطير" يمثل عنق زجاجة خفيًا. لقد جعلت نماذج Claude Sonnet وOpus نافذة سياق بمليون Token معيارًا للتسعير (3 دولارات لكل مليون Token مدخل لـ Sonnet، و5 دولارات لـ Opus)، نظريًا يمكنك إدخال مئات الآلاف من الكلمات دفعة واحدة، لكن الحد الأقصى للمخرجات في استجابة واحدة لا يزال بضعة آلاف من الـ Token، مما يعني أنه لا يمكنك إكمال إعادة الكتابة الكاملة في استدعاء واحد. يجب تقسيم المهمة، وهذا يحدد مباشرة أن سكربتات المعالجة الدفعية (Batch Processing) عادة ما تكون أكثر ملاءمة لسيناريوهات التوسع مقارنة بالمحادثات التفاعلية.
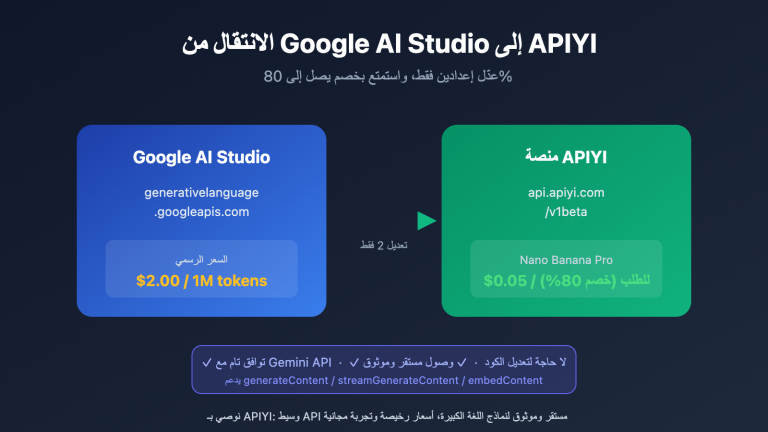
🎯 نصيحة قبل اختيار الحل: قبل اختيار الطريقة، قم بإجراء معالجة لإزالة البيانات الحساسة وتوحيد تنسيق جميع ملفات Markdown. نوصي باستخدام منصة APIYI (apiyi.com) لتجربة عينات صغيرة أولاً، والتأكد من استهلاك الـ Token الفعلي لكل ألف كلمة، ثم تقرر ما إذا كنت ستستخدم أدوات المحادثة أو سكربتات المعالجة الدفعية، لتجنب خروج التكاليف عن السيطرة لاحقًا.
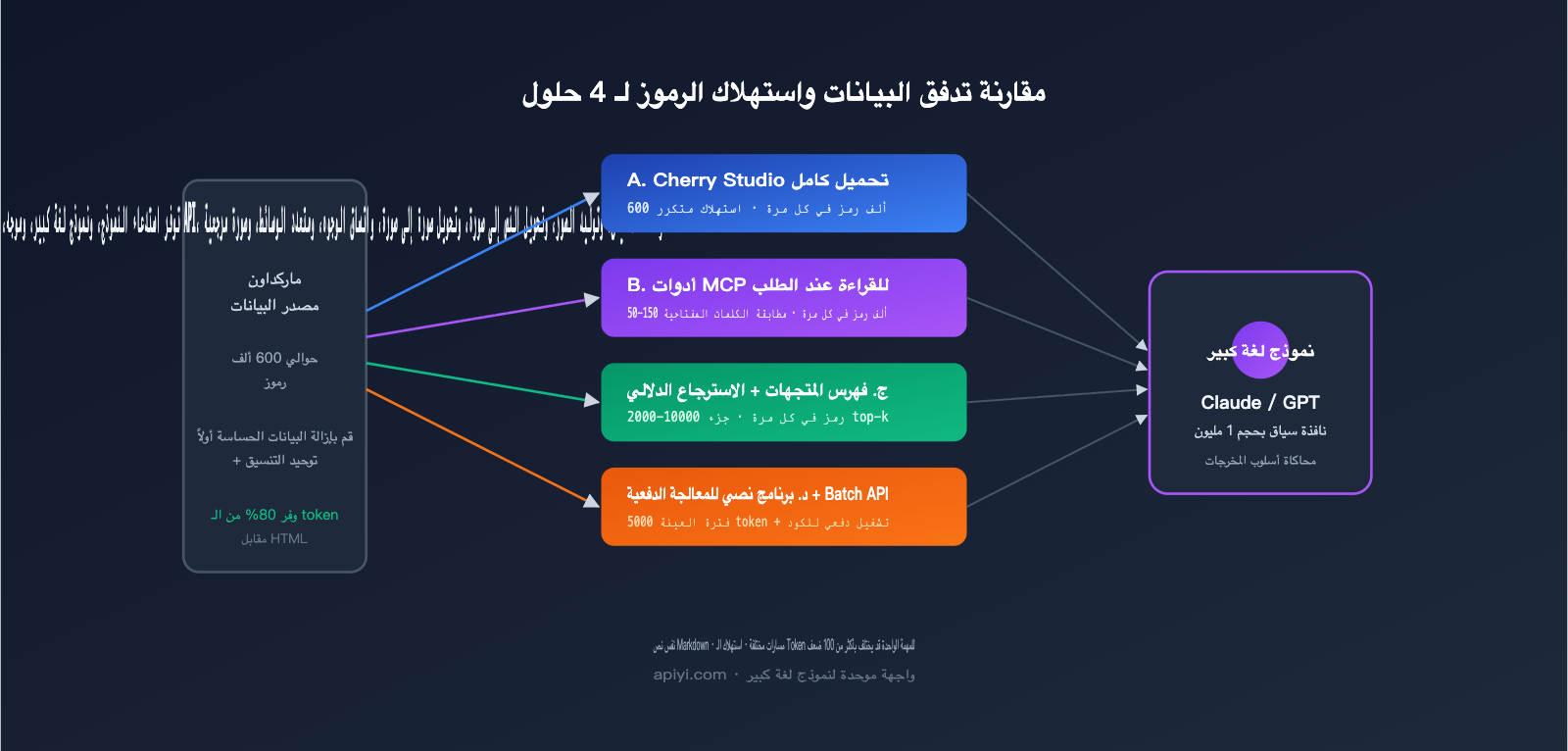
ثانياً: الفروقات الجوهرية وحدود الاستخدام للحلول الأربعة
تمتلك الحلول الأربعة حدوداً واضحة لقدراتها، وفهم هذه الفروقات أهم بكثير من حفظ المعايير التقنية.
2.1 الحل (أ): التحميل المباشر عبر أدوات المحادثة مثل Cherry Studio
هذا هو الخيار الأقل تعقيداً. تتيح لك أدوات مثل Cherry Studio أو Claude Desktop أو ChatGPT سحب وإفلات ملفات Markdown متعددة مباشرة في نافذة المحادثة، حيث يقوم النموذج بدمج محتوى الملفات بالكامل في "موجه" (Prompt) طويل. الميزة هنا هي غياب الجهد الهندسي والنتائج الفورية؛ أما العيب فهو الحاجة لإعادة تغذية الملفات في كل جلسة جديدة، مما يستهلك الكثير من الـ Token، كما أن حجم الملفات المسموح به مقيد بـ "نافذة السياق" (Context Window).
بالنسبة للمهام الصغيرة التي لا تتجاوز 50 ألف كلمة، يعتبر هذا الحل الأكثر كفاءة، حيث يمكنك التعديل والمتابعة بلغة طبيعية. ولكن بمجرد أن تتجاوز البيانات 200 ألف كلمة، ستواجه بشكل متكرر مشاكل انقطاع السياق، وتأخير في الاستجابة (قد يستغرق الـ Token الأول 20-30 ثانية)، وتكاليف إضافية بسبب التكرار.
2.2 الحل (ب): الربط المباشر للملفات المحلية عبر MCP
يتيح بروتوكول MCP (Model Context Protocol) للنموذج قراءة الملفات من قرصك الصلب كما لو كان يستدعي أداة. يبدو الأمر أنيقاً: يقوم النموذج بالاستدعاء عند الحاجة دون تحميل البيانات بالكامل. لكن في الاختبارات العملية، غالباً ما يتم التقليل من تقدير استهلاك الـ Token في MCP؛ فحتى لو احتاج النموذج إلى 3 حقول فقط من استجابة JSON، فإن الهيكل الكامل للملف يدخل في السياق، مما يجعل نمط مطابقة الكلمات المفتاحية يستهلك حوالي 3 أضعاف الـ Token مقارنة بالبحث المتجهي (Vector Search).
تكمن القوة الحقيقية لـ MCP في مصادر البيانات المتغيرة ديناميكياً، مثل سجلات الأحداث اللحظية، أو البيانات الخاصة للمستخدم، أو البيانات المالية التي يجب أن تظل محلية. بالنسبة لسيناريو "مئات الآلاف من كلمات Markdown الثابتة"، يعتبر MCP استخداماً مبالغاً فيه للموارد، وقد يؤدي إلى استنفاد نافذة السياق مبكراً في الاستدعاءات المتعددة.
2.3 الحل (ج): قاعدة المعرفة المتجهية / NotebookLM
تعتمد هذه الطريقة على تقطيع الملفات، وتحويلها إلى متجهات (Embedding)، وتخزينها، ثم استرجاع الأجزاء ذات الصلة عند الحاجة، وهو ما يعرف بمسار RAG. في خط أنابيب RAG المصمم جيداً، يتم استرجاع 5-20 قطعة فقط في كل استعلام، بإجمالي 2000-10000 Token، مما يوفر 50-200 ضعف من الـ Token المدخلة مقارنة بالتحميل الكامل.
يعد NotebookLM من Google منتج RAG جاهزاً للاستخدام، حيث يعالج التضمين والاسترجاع والمراجع تلقائياً، وهو مناسب للمهام التي تعتمد على القراءة مثل تحليل أسلوب الكتابة، مراجعة الأدبيات، والإجابة على الأسئلة من الملاحظات. حدوده تكمن في أن الإجابات تستند فقط إلى الملفات المصدرية ولا يقوم بربطها ببيانات التدريب، كما أن خيارات التخصيص محدودة. إذا كنت بحاجة إلى استراتيجيات استرجاع معقدة أو استنتاج متعدد الخطوات، فإن بناء قاعدة معرفة متجهية خاصة بك سيكون أكثر مرونة.
🎯 تنبيه عند تطبيق الحل (ج): جودة الاسترجاع في قاعدة المعرفة المتجهية تحدد مباشرة جودة المخرجات. يجب ضبط تقطيع البيانات (Chunking)، ونموذج التضمين (Embedding)، ومعاملات البحث (top-k) بناءً على طبيعة البيانات. ننصح بإجراء تقييم أولي على نطاق صغير باستخدام Claude أو GPT عبر منصة APIYI (apiyi.com)، ومقارنة دقة الإجابات تحت معاملات بحث مختلفة قبل اتخاذ قرار بشأن استخدام NotebookLM أو البناء الذاتي.
2.4 الحل (د): كتابة سكربتات معالجة الدفعات بواسطة الذكاء الاصطناعي (الحل الأمثل للتوسع)
هذا هو الحل الأكثر تأكيداً عليه في الإجابة الأصلية: اطلب من الذكاء الاصطناعي مساعدتك في كتابة سكربت لمعالجة الدفعات، ابدأ بمعالجة 5-10 عينات من البيانات، ثم حدد يدوياً أو تلقائياً الأنماط القابلة لإعادة الاستخدام (مثل قوالب الجمل، هيكل الفقرات، توزيع الكلمات المفتاحية)، ثم قم بتضمين هذه القواعد في الكود، واترك الكود يعالج مئات الآلاف من الكلمات المتبقية، بينما يتدخل نموذج اللغة الكبير فقط في النقاط الحرجة.
هذا في جوهره "تطبيق للقواعد": يستخدم نموذج اللغة الكبير لاكتشاف الأنماط، بينما يتولى الكود التنفيذ الجماعي. وبالتعاون مع Batch API لـ Claude/GPT (بخصم 50%)، تكون التكلفة الإجمالية عادةً 5%-15% فقط من تكلفة الحل (أ). العيب هو الحاجة إلى 1-2 يوم من العمل الهندسي في البداية، لذا فهو غير مناسب للمهام التي تُنفذ لمرة واحدة.
三、4 种方案的 Token 消耗与成本对比
只有将抽象的差异落实到数字上,才能真正算清账。下表基于一个具体场景进行了对比:用户需要处理 30 万字的 Markdown 语料(约 60 万 Token),并最终输出 100 篇风格仿写文章(每篇约 2000 字)。
| 方案 | 单次输入 Token | 总输入 Token | 总输出 Token | 估算成本(Sonnet) | 首 Token 延迟 |
|---|---|---|---|---|---|
| A. 对话工具直传 | 60 万 | 6000 万(100 次) | 600 万 | ≈ $270 | 20-30 秒 |
| B. MCP 文件访问 | 5-15 万(分次) | 1500 万 | 600 万 | ≈ $135 | 8-15 秒 |
| C. 向量知识库 | 5000-1 万 | 100 万 | 600 万 | ≈ $93 | 1-2 秒 |
| D. 批处理脚本 + Batch API | 5000(样本期)+ 代码处理 | 100 万 | 600 万 | ≈ $46 | 异步 |
可以看出,方案 D 的成本仅为方案 A 的 17% 左右,且延迟最为稳定。如果再叠加 Batch API 的 50% 折扣,方案 D 的实际花费还能再降一半。虽然 Claude 的 1M 上下文窗口已实现标准定价,不再有 2 倍加价,但重复输入相同语料造成的浪费依然存在——这是对话式工作流难以绕过的硬伤。
🎯 成本验证建议:上述成本基于公开报价估算,实际数字会因 Prompt 设计、缓存命中率以及是否启用 Prompt Caching 而有 30%-50% 的浮动。我们建议在 APIYI (apiyi.com) 控制台开启用量监控,前 3 天每天对账,将抽象的预算转化为可视化的曲线,再决定是否将更多任务迁移至 Batch API。
下表引入了四种方案的工程复杂度,方便进行横向对比:
| 维度 | 方案 A 对话直传 | 方案 B MCP | 方案 C 向量知识库 | 方案 D 批处理脚本 |
|---|---|---|---|---|
| 工程投入 | 几乎为零 | 中等 | 中等偏高 | 高(前期) |
| 上手时间 | 5 分钟 | 1-2 小时 | 半天到 1 天 | 1-2 天 |
| 可复现性 | 弱(对话历史易丢) | 中 | 强 | 极强 |
| 适合语料规模 | < 5 万字 | 5-30 万字动态数据 | 10 万字 – 1000 万字静态 | 30 万字以上 |
| 输出可控性 | 受上下文长度限制 | 受工具调用次数限制 | 受检索质量限制 | 完全可控 |
四、不同语料规模下的场景推荐
将方案套用到具体场景中会更直观。以下针对三种规模给出推荐路径。
4.1 小语料(< 5 万字)学习探索期
此阶段的核心目标是快速验证想法,而非追求成本最优。方案 A(对话直传)是最合理的选择,将所有文件拖入 Cherry Studio 或 Claude Desktop,直接与模型对话并调试 Prompt。这一阶段应重点关注:模型是否真正抓住了目标作者的风格特征?哪些维度是可量化的(句长、用词、句式)?哪些是模糊的(语气、节奏)?这些问题在小样本下成本极低,仅需几美元即可完成测试。
4.2 中等语料(5-30 万字)研究分析期
进入该区间,方案 A 的重复输入开销会迅速膨胀。此时的最佳实践是转向方案 C(向量知识库)或 NotebookLM,将样本写入向量库后,根据需求进行语义检索调用。如果仅进行内容分析、风格归纳或问答式探索,NotebookLM 几乎零工程量即可运行;若需要更复杂的多步推理,则建议搭建一套基于 Claude 或 GPT 的 RAG 系统。
🎯 中等规模选型提示:NotebookLM 适合纯读取分析,但不支持自定义检索策略和复杂工作流。我们建议在 APIYI (apiyi.com) 平台上对接 Claude Sonnet 或 Opus 1M 上下文窗口来运行 RAG,既能享受标准定价,又能灵活控制分块(Chunk)数量和检索权重,适合需要长期运营的语料库。
4.3 大规模语料(30 万字以上)生产期
当语料达到几十万甚至上百万字量级时,方案 D(批处理脚本)几乎是唯一可持续的选择。将任务拆解为「样本发现规律 → 代码批量处理 → 大模型只做关键节点」的三段式工作流,配合 Batch API 异步执行,可将单字成本压缩至原来的 5%-15%。这一阶段你需要的不再是更聪明的 Prompt,而是更工程化的流水线。

5. توصيات اتخاذ القرار لتوفير الـ Token على مراحل
لتبسيط التحليل السابق، إليك جدول مسار عملي يمكنك اتباعه مباشرة عند الاختيار:
| شرط التفعيل | الحل الموصى به | الإجراء الرئيسي |
|---|---|---|
| أقل من 50 ألف كلمة / استكشاف لمرة واحدة | الخيار أ: المحادثة المباشرة | سحب الملفات مباشرة، ضبط الموجه، تسجيل الموجهات الفعالة |
| 50 – 300 ألف كلمة / بيانات ثابتة / تحليل القراءة | الخيار ج: قاعدة معرفية متجهة (Vector RAG) | استخدام NotebookLM أو بناء RAG خاص، مع التركيز على ضبط chunk و top-k |
| أكثر من 300 ألف كلمة / مهام متكررة / إنتاج ضخم | الخيار د: نصوص برمجية للمعالجة + Batch API | دع الذكاء الاصطناعي يكتب لك النص البرمجي، وتحقق يدويًا من النتائج في مرحلة العينات |
| بيانات متغيرة / ضرورة البقاء محليًا | الخيار ب: MCP | تحديد عدد استدعاءات الأدوات، والحذر عند استخدام البحث بالكلمات المفتاحية |
التركيبة الشائعة في المشاريع الفعلية هي "البدء بالخيار أ، ثم الانتقال للخيار ج، والختام بالخيار د". يعود ذلك إلى أن فهم المهمة بحد ذاته عملية تدريجية: فالعينات الصغيرة تساعدك على معرفة ما يجب فعله ومعايير القياس، والبيانات المتوسطة تساعدك على التحقق من جودة الاسترجاع وقدرة التعميم، بينما مرحلة النطاق الواسع تهدف إلى تثبيت العمليات الناضجة داخل الكود.
تجاوز المراحل الوسطى والقفز مباشرة إلى نصوص المعالجة هو خطأ شائع؛ ستكتشف أن النص البرمجي مكتوب بشكل مثالي، لكن النتائج لا ترقى للتوقعات لأن الموجه (prompt) الأولي لم يتم ضبطه بدقة. وعلى العكس، البقاء لفترة طويلة في مرحلة المحادثة سيهدر الكثير من الـ Token، فقد تدفع مئات الدولارات مقابل الحصول على بضع عشرات من العينات الفعالة فقط.
🎯 إشارات الانتقال بين المراحل: عندما تلاحظ أنك تستخدم موجهات متشابهة لمعالجة ملفات مماثلة لأكثر من 5 مرات متتالية، فهذا يعني أن الوقت قد حان للانتقال إلى قاعدة معرفية متجهة؛ وعندما تضطر لتكرار نفس منطق الاسترجاع في كل مهمة، فهذا يعني أن الوقت قد حان لكتابة نص برمجي. ننصحك بتفعيل ميزة التخزين المؤقت للموجهات (prompt caching) وإحصائيات الاستخدام على منصة APIYI (apiyi.com)، ليكون قرار الانتقال مبنيًا على بيانات دقيقة وليس على التخمين.
6. مثال عملي مصغر لنص برمجي للمعالجة الدفعية
لجعل الخيار "د" أكثر وضوحًا، إليك هيكل نص برمجي مبسط يوضح العملية الجوهرية: "اكتشاف العينات ← تثبيت القواعد ← التنفيذ الجماعي":
import os, json
from anthropic import Anthropic
# استخدام خدمة وكيل API عبر APIYI
client = Anthropic(base_url="https://vip.apiyi.com")
def extract_style_features(markdown_text: str) -> dict:
"""استخدام نموذج لغة كبير لاستخراج خصائص الأسلوب القابلة للقياس من مقال واحد."""
resp = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=1500,
messages=[{"role": "user", "content": f"""
يرجى استخراج خصائص أسلوب الكتابة من مقال Markdown التالي، وإخراج النتيجة بصيغة JSON تتضمن:
- avg_sentence_length: متوسط طول الجملة
- paragraph_structure: نمط هيكل الفقرات
- key_phrases: أهم 10 عبارات متكررة
- tone: وسم النبرة (مثل: رصين/عامي/حاد)
محتوى المقال:
{markdown_text}
"""}],
)
return json.loads(resp.content[0].text)
# مرحلة العينات: استخدام 10 مقالات لاكتشاف الأنماط
samples = [open(f, encoding="utf-8").read() for f in os.listdir("samples")[:10]]
features = [extract_style_features(s) for s in samples]
# تثبيت القواعد: كتابة الخصائص عالية التكرار في ملف إعدادات لاستخدامها لاحقًا بواسطة الكود
with open("style_profile.json", "w", encoding="utf-8") as f:
json.dump(features, f, ensure_ascii=False, indent=2)
بعد الانتهاء من مرحلة العينات، يمكن لمرحلة إعادة الكتابة الجماعية الفعلية الاعتماد كليًا على القواعد الموجودة في style_profile.json عبر الكود، حيث يتدخل نموذج اللغة الكبير فقط في خطوة "اللمسات النهائية"، مما يقلل استهلاك الـ Token من مئات الآلاف إلى بضعة آلاف فقط.
🎯 نصيحة حول ربط API للمعالجة الدفعية: يشير
base_urlأعلاه إلى نقطة نهاية خدمة وكيل API في APIYI، ويمكنك إعادة استخدام SDK الرسمي لـ Anthropic مباشرة دون تعديل الكود. ننصحك بإضافة منطق لإعادة المحاولة (retry) وتتبع التكلفة (cost tracking) في النص البرمجي، بحيث يتوقف النظام تلقائيًا عند تجاوز الميزانية في المهام الطويلة؛ فهذا هو أكثر الجوانب التي قد تسبب مشاكل في المعالجة الدفعية واسعة النطاق.
سابعاً: الأسئلة الشائعة (FAQ)
س1: يمتلك كل من Claude Sonnet و Opus نافذة سياق تصل إلى مليون Token، ألا يمكننا حشو البيانات بالكامل مباشرة؟
من الناحية التقنية هذا ممكن، ولكن هناك تكلفتان خفيتان. الأولى هي أن تأخير الـ Token الأول قد يصل إلى 20-30 ثانية، مما يجعل تجربة التفاعل سيئة؛ والثانية هي أنك ستضطر لإعادة إدخال نفس البيانات في كل جلسة، مما يجعل التكلفة أغلى بـ 50-200 مرة مقارنة بـ RAG. نافذة السياق بحجم 1M مناسبة للاستدلال الشامل لمرة واحدة (مثل "البحث عن التناقضات عبر المستندات")، وليست مناسبة للوصول المتكرر إلى نفس البيانات. ننصح باستخدام Sonnet 1M على منصة APIYI (apiyi.com) لمهام الاستدلال الشامل، واستخدام Haiku لمهام المعالجة الدفعية التفصيلية، فهذا المزيج يوفر أفضل قيمة مقابل السعر.
س2: كيف أختار بين NotebookLM وبناء قاعدة بيانات متجهة (Vector Database) خاصة بي؟
إذا كنت فرداً أو ضمن فريق صغير وتعمل على تحليل بيانات ثابتة، أو دراسة الأسلوب، أو الاستعلام عن الأسئلة والأجوبة، فإن NotebookLM هو الأسرع في البدء، حيث يمكنك سحب الملفات واستخدامها مباشرة. أما إذا كنت بحاجة إلى تخصيص استراتيجية تقسيم النصوص (Chunking)، أو التحكم في أوزان الاسترجاع، أو الربط مع أنظمة أعمال، أو استخدام نماذج من شركات أخرى للتوليد، فإن بناء قاعدة بيانات متجهة خاصة بك سيكون أكثر مرونة.
س3: هل بروتوكول MCP عديم الفائدة حقاً؟
بالتأكيد لا. تكمن قوة MCP في سيناريوهات "تغير البيانات المتكرر" أو الحالات التي "لا يمكن فيها مغادرة البيانات المحلية"، مثل قراءة سجلات النظام (Logs) في الوقت الفعلي، أو الاستعلام عن قواعد بيانات خاصة، أو استدعاء واجهات برمجة تطبيقات داخلية. أما بالنسبة لبيانات Markdown الثابتة، فإن RAG يتفوق في جميع الجوانب تقريباً، وهذا هو الاستنتاج الصحيح.
س4: هل توفر Batch API فعلاً 50% من التكاليف؟ وهل الاستجابة بطيئة؟
واجهة Batch API تعمل بشكل غير متزامن، وعادة ما تعيد النتائج خلال 24 ساعة، وسعرها يعادل 50% من سعر الـ API القياسي. إنها مناسبة جداً للمهام التي لا تتطلب استجابة فورية، مثل "تقطير أسلوب الكتابة لتوليد 100 مقال محاكي". عند دمجها مع تسعير سياق 1M، يمكن خفض التكلفة الإجمالية إلى 30%-40% من التكلفة الأصلية. ننصحك بتجربة سير العمل باستخدام الـ API المتزامن على منصة APIYI (apiyi.com) أولاً، ثم الانتقال إلى وضع Batch للإنتاج الضخم.
س5: ماذا أفعل إذا كانت البيانات تحتوي على صور، جداول، أو كتل برمجية؟
تنسيق Markdown يحافظ على هذه الهياكل بشكل جيد، ولكن انتبه: كتل الأكواد البرمجية الكبيرة تستهلك الكثير من الـ Tokens. إذا كان هدفك هو تحليل أسلوب الكتابة فقط، يمكنك استخدام سكربت لإزالة الأكواد أولاً. أما إذا كانت الجداول معقدة جداً، فننصح بتحويلها إلى CSV وتخزينها بشكل منفصل، وتزويد نموذج اللغة الكبير بالملخص فقط، مما يوفر أكثر من 30% إضافية من الـ Tokens.
ثامناً: الخلاصة
بالعودة إلى السؤال الأصلي: ما هي الطريقة المثلى لتغذية نموذج لغة كبير بمئات الآلاف من كلمات Markdown؟ الإجابة ليست خياراً واحداً، بل مزيجاً مرحلياً. في مرحلة الاستكشاف للعينات الصغيرة، يكون الإرسال المباشر عبر المحادثة هو الأسرع. في مرحلة البحث متوسط النطاق، تكون قاعدة المعرفة المتجهة أو NotebookLM هي الأكثر استقراراً. أما في مرحلة الإنتاج واسع النطاق، فيجب الانتقال إلى سكربتات المعالجة الدفعية مع Batch API، وحصر دور نموذج اللغة الكبير في "اكتشاف الأنماط" بدلاً من "التنفيذ"، حيث يكون الكود هو المسؤول الفعلي عن معالجة الكميات الضخمة.
بعد فهم هذا المسار، يتحول موضوع "توفير الـ Tokens عند استخدام بيانات Markdown مع نماذج اللغة الكبيرة" من "أي أداة أختار؟" إلى "أي مزيج أستخدم في أي مرحلة؟". إذا كنت عالقاً في مرحلة ما وغير متأكد من الانتقال، يمكنك إجراء تقييم صغير على منصة APIYI (apiyi.com)، ومقارنة تكلفة كل ألف كلمة، ودقة الاسترجاع، وتأخير الـ Token الأول، وستصبح قراراتك أكثر وضوحاً. نأمل أن يساعدك هذا المقارنة في تجنب بعض العقبات وتوجيه ميزانيتك نحو الأجزاء التي تحقق قيمة حقيقية.
—— فريق APIYI (api.apiyi.com)