最近收到一個很典型的諮詢:用戶想把一位寫作高手的幾十萬字文章「蒸餾」給大模型當風格底子,但不知道該把 Markdown 語料怎麼塞進去最划算。常見的三種思路是:把文件一個個傳進 Cherry Studio 這類對話工具、用 MCP 讓模型直接調用硬盤上的文件、或者全部塞進知識庫做 RAG。乍一看每種都能跑通,但當語料體量超過 30 萬字時,Token 賬單和延遲會迅速分化,選錯方案動輒多花十倍預算。
這篇文章會把圍繞大模型 Markdown 語料 省 Token的四種主流方案掰開揉碎對比:Token 實際消耗、單次任務成本、首 Token 延遲、可控性、以及不同語料規模下的最佳選擇。最後給出一條分階段的決策路徑——前期探索用什麼、規模化以後又該換成什麼。如果你正在做風格蒸餾、知識庫問答或語料微調前的清洗工作,讀完應該能直接落地選型。
一、大模型 Markdown 語料 省 Token 的核心問題
在拆解方案之前,先把這個問題真正貴在哪裏講清楚。把幾十萬字 Markdown 餵給大模型,本質上是在四類成本之間做權衡:輸入 Token、輸出 Token、檢索/索引成本、以及人力調試成本。
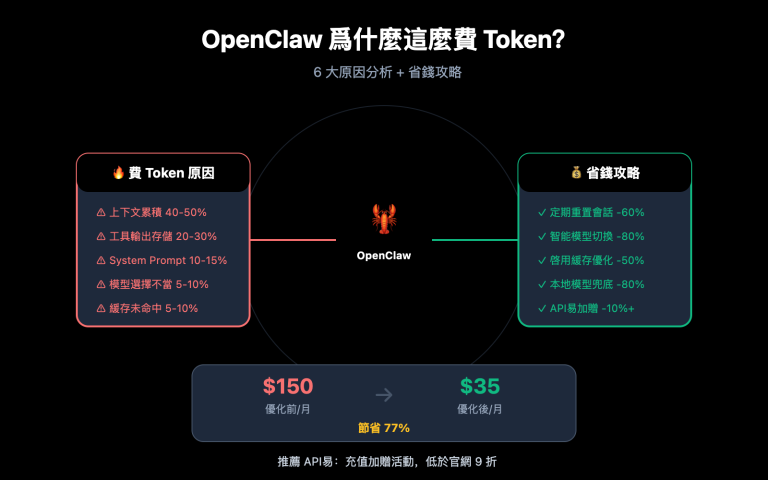
輸入 Token 是最容易被低估的一項。一篇技術博客如果是 HTML 原始格式,轉成 Markdown 之後通常能省下 70%~80% 的 Token,因爲標籤、樣式、嵌入腳本都被剝離。這也是爲什麼所有處理大語料的流水線第一步都要先把內容統一成 Markdown 或 txt。把這件事做好,後續選哪種喂入方式的成本基線都會降一個臺階。
輸出 Token 看似無關,但在「蒸餾」類任務裏其實是隱性瓶頸。Claude Sonnet 和 Opus 都已經把 100 萬 Token 上下文做成標準定價(Sonnet 輸入 $3/M、Opus 輸入 $5/M),理論上你可以一次性把幾十萬字塞進去,但單次響應的最大輸出依然只有幾萬 Token,這意味着你沒法用一次調用就完成全量改寫。任務必須切片,這也直接決定了批處理腳本通常比交互式對話更適合規模化場景。
🎯 選型前的準備建議: 在挑方案之前,先把所有 Markdown 文件做一次脫敏和格式歸一化處理。我們建議通過 API易 apiyi.com 平臺先跑通小批量樣本,確認每千字的實際 Token 消耗後,再決定走對話工具還是批處理腳本,避免後期成本失控。
二、4 種方案的核心差異與適用邊界
四種方案各自有清晰的能力邊界,理解差異比死記參數更重要。
2.1 方案 A:Cherry Studio 等對話工具直接上傳
這是門檻最低的方式。Cherry Studio、Claude Desktop、ChatGPT 這類工具允許你把多個 Markdown 文件直接拖進對話框,模型把全部文件內容拼成一個長提示詞處理。優點是零工程量、所見即所得;缺點是每開一個新會話都要重新喂一遍,Token 重複消耗嚴重,而且單次能塞下的文件量被上下文窗口卡死。
對於 5 萬字以內的小樣本任務,這種方式效率反而最高,因爲你能用自然語言一邊調一邊看效果。但語料一旦超過 20 萬字,就會頻繁遇到上下文截斷、長上下文延遲(首 Token 可能拖到 20-30 秒)和重複扣費問題。
2.2 方案 B:MCP 直連本地文件
MCP(Model Context Protocol)讓模型像調用工具一樣去讀你硬盤上的文件。聽起來很優雅:模型按需調用,不需要全量加載。但實測下來 MCP 的 Token 消耗經常被低估——一次工具調用返回的 JSON 哪怕只用得到 3 個字段,完整結構都會進入上下文,關鍵詞匹配模式比向量檢索多消耗約 3 倍 Token。
MCP 的真正強項是動態變化的數據源,比如實時日誌、用戶私有數據、或必須保持本地不出域的財務數據。對於「幾十萬字靜態 Markdown」這種典型場景,MCP 是殺雞用牛刀,而且容易在多輪調用中把上下文窗口提前耗光。
2.3 方案 C:向量化知識庫 / NotebookLM
把所有文件切片、嵌入、入庫,通過語義檢索按需調用相關片段,這就是 RAG 路線。一個良好設計的 RAG 流水線每次查詢只檢索 5-20 個 chunk,通常合計 2000-10000 Token,相比全量加載能省 50-200 倍輸入 Token。
NotebookLM 是 Google 提供的開箱即用 RAG 產品,自動處理嵌入、檢索和引用,適合寫作風格分析、文獻綜述、筆記問答這種偏讀取的任務。它的侷限是回答只基於源文件,不會主動聯想訓練數據,而且自定義程度有限。如果你需要複雜的檢索策略或多步推理,自己搭一套向量知識庫會更靈活。
🎯 方案 C 落地提醒: 向量知識庫的檢索質量直接決定輸出質量,chunk 切分、embedding 模型、檢索 top-k 都要根據語料調優。我們建議在 API易 apiyi.com 平臺先用 Claude 或 GPT 跑一次小規模評測,對比不同檢索參數下的回答準確率,再決定是否上 NotebookLM 還是自建。
2.4 方案 D:AI 寫批處理腳本(規模化最優解)
這是問題原始答覆裏最被強調的方案:讓 AI 幫你寫一段批處理腳本,先用大模型處理 5-10 篇樣本數據,人工或自動識別出可複用的規律(比如句式模板、段落結構、關鍵詞分佈),然後把規律固化進代碼,讓代碼處理剩餘的幾十萬字,大模型只在關鍵節點介入。
這本質上是「規則下沉」:大模型用來發現模式,代碼負責批量執行。配合 Claude/GPT 的 Batch API(50% 折扣),整體成本通常只有方案 A 的 5%-15%。劣勢是前期需要 1-2 天工程投入,不適合一次性任務。
三、4 種方案的 Token 消耗與成本對比
把抽象差異落到數字上,才能真正算出賬。下面這張表基於一個具體場景做對比:用戶要蒸餾 30 萬字 Markdown 語料(約 60 萬 Token),最終輸出 100 篇風格仿寫文章(每篇約 2000 字)。
| 方案 | 單次輸入 Token | 總輸入 Token | 總輸出 Token | 估算成本(Sonnet) | 首 Token 延遲 |
|---|---|---|---|---|---|
| A. 對話工具直傳 | 60 萬 | 6000 萬(100 次) | 600 萬 | ≈ $270 | 20-30 秒 |
| B. MCP 文件訪問 | 5-15 萬(分次) | 1500 萬 | 600 萬 | ≈ $135 | 8-15 秒 |
| C. 向量知識庫 | 5000-1 萬 | 100 萬 | 600 萬 | ≈ $93 | 1-2 秒 |
| D. 批處理腳本 + Batch API | 5000(樣本期)+ 代碼處理 | 100 萬 | 600 萬 | ≈ $46 | 異步 |
可以看到方案 D 的成本只有方案 A 的約 17%,而且延遲最穩定。如果再疊加 Batch API 的 50% 折扣,D 方案實際花費還能再降一半。Claude 1M context 把超長上下文做成標準定價之後,方案 A 不再被加價 2 倍,但重複輸入相同語料的浪費依然存在——這是對話式工作流繞不開的硬傷。
🎯 成本驗證建議: 上面的成本是基於公開報價估算,實際數字會因 prompt 設計、緩存命中率、是否啓用 prompt caching 有 30%-50% 浮動。我們建議在 API易 apiyi.com 控制檯開啓用量監控,前 3 天每天對賬,把抽象的預算變成可視化的曲線,再決定要不要把更多任務遷到 Batch API。
下面這張表把四種方案的工程複雜度也拉進來,方便橫向看:
| 維度 | 方案 A 對話直傳 | 方案 B MCP | 方案 C 向量知識庫 | 方案 D 批處理腳本 |
|---|---|---|---|---|
| 工程投入 | 幾乎爲零 | 中等 | 中等偏高 | 高(前期) |
| 上手時間 | 5 分鐘 | 1-2 小時 | 半天到 1 天 | 1-2 天 |
| 可復現性 | 弱(對話歷史易丟) | 中 | 強 | 極強 |
| 適合語料規模 | < 5 萬字 | 5-30 萬字動態數據 | 10 萬字 – 1000 萬字靜態 | 30 萬字以上 |
| 輸出可控性 | 受上下文長度限制 | 受工具調用次數限制 | 受檢索質量限制 | 完全可控 |
四、不同語料規模下的場景推薦
把方案套到具體場景裏更直觀。下面分三種規模給出推薦路徑。
4.1 小語料(< 5 萬字)學習探索期
此時核心目標是快速驗證想法,而不是追求成本最優。方案 A 對話直傳是最合理的選擇,把所有文件拖進 Cherry Studio 或 Claude Desktop,直接和模型對話調試 prompt。這一階段你應該重點關注:模型是不是真的能抓住目標作者的風格特徵?哪些維度是可量化的(句長、用詞、句式)?哪些是模糊的(語氣、節奏)?這些問題在小樣本下成本極低,幾美元就能跑完。
4.2 中等語料(5-30 萬字)研究分析期
進入這個區間,方案 A 的重複輸入開銷會快速膨脹。此時最佳實踐是切到方案 C 向量知識庫或 NotebookLM,把樣本寫入向量庫後用語義檢索按需調用。如果你只是做內容分析、風格歸納、問答式探索,NotebookLM 幾乎零工程量就能跑;如果需要更復雜的多步推理,自己搭一套基於 Claude 或 GPT 的 RAG 系統。
🎯 中等規模選型提示: NotebookLM 適合純讀取分析,但不支持自定義檢索策略和複雜工作流。我們建議在 API易 apiyi.com 平臺上對接 Claude Sonnet 或 Opus 1M context 來跑 RAG,既享受標準定價又能靈活控制 chunk 數和檢索權重,適合需要長期運營的語料庫。
4.3 大規模語料(30 萬字以上)生產期
到了幾十萬字甚至上百萬字的量級,方案 D 批處理腳本幾乎是唯一可持續的選擇。把任務拆成「樣本發現規律 → 代碼批量處理 → 大模型只做關鍵節點」三段式工作流,配合 Batch API 異步執行,可以把單字成本壓到原來的 5%-15%。這個階段你需要的不是更聰明的 prompt,而是更工程化的流水線。

五、分階段省 Token 決策建議
把上面的分析濃縮成一張實操路徑表,可以直接照着選:
| 觸發條件 | 推薦方案 | 關鍵動作 |
|---|---|---|
| 語料 < 5 萬字 / 一次性探索 | 方案 A 對話直傳 | 直接拖文件、調 prompt、記錄有效提示詞 |
| 5-30 萬字 / 靜態語料 / 偏讀取分析 | 方案 C 向量知識庫 | 選 NotebookLM 或自建 RAG,優先調 chunk 和 top-k |
| 30 萬字以上 / 重複任務 / 需要量產 | 方案 D 批處理腳本 + Batch API | 讓 AI 幫你寫腳本,樣本期人工驗證規律 |
| 動態變化數據 / 必須本地不出域 | 方案 B MCP | 限定工具調用次數,慎用關鍵詞檢索 |
實際項目中常見的組合是「方案 A 起步,方案 C 中段,方案 D 收尾」。這是因爲任務理解本身就是漸進的:小樣本對話幫你弄清楚要做什麼、衡量標準是什麼;中等樣本幫你驗證檢索質量和泛化能力;大規模階段則是把已經成熟的流程固化進代碼。
跳過中間階段直接上批處理腳本是常見誤區——你會發現腳本寫得很完美,但跑出來的結果不達預期,因爲最初的 prompt 還沒有充分調優。反過來,長期停留在對話階段也會浪費 Token,幾百美元的賬單可能只買到幾十個有效樣本。
🎯 階段切換的判斷信號: 當你發現連續 5 次以上對話都在用相似的 prompt 處理類似文件,就說明該切到向量知識庫了;當你每次任務都要重複輸入相同的檢索邏輯,就說明該寫腳本了。我們建議在 API易 apiyi.com 平臺開啓 prompt 緩存和用量統計,讓切換時機有數據支撐而不是憑感覺。
六、批處理腳本方案的最小可運行例子
爲了讓方案 D 更具體,這裏給一段極簡版的批處理腳本骨架,演示「樣本發現 → 規則固化 → 批量執行」的核心流程:
import os, json
from anthropic import Anthropic
client = Anthropic(base_url="https://vip.apiyi.com")
def extract_style_features(markdown_text: str) -> dict:
"""用大模型從單篇文章提取可量化的風格特徵。"""
resp = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=1500,
messages=[{"role": "user", "content": f"""
請從下面這篇 Markdown 文章中提取寫作風格特徵,輸出 JSON,包含:
- avg_sentence_length: 平均句長
- paragraph_structure: 段落結構模式
- key_phrases: 高頻短語前 10 個
- tone: 語氣標籤(如嚴謹/通俗/犀利)
文章內容:
{markdown_text}
"""}],
)
return json.loads(resp.content[0].text)
# 樣本期: 用 10 篇文章發現規律
samples = [open(f, encoding="utf-8").read() for f in os.listdir("samples")[:10]]
features = [extract_style_features(s) for s in samples]
# 規律固化: 把高頻特徵寫進配置文件,後續由代碼直接套用
with open("style_profile.json", "w", encoding="utf-8") as f:
json.dump(features, f, ensure_ascii=False, indent=2)
樣本期跑完之後,真正的批量改寫階段可以完全用代碼套用 style_profile.json 裏的規則,大模型只在「最終潤色」這一步介入,Token 消耗可以從十萬級壓到幾千。
🎯 批處理腳本的 API 接入建議: 上面的
base_url指向 API易 apiyi.com 的中轉端點,可以直接複用 Anthropic 官方 SDK,無需改代碼。我們建議在腳本里加上 retry 和 cost tracking 邏輯,跑長任務時一旦超預算就自動停,這是大規模批處理最容易踩坑的地方。
七、常見問題 FAQ
Q1:Claude Sonnet 和 Opus 都已經有 100 萬 Token 上下文,直接全量塞進去不行嗎?
技術上可行,但有兩個隱性成本。一是首 Token 延遲會拖到 20-30 秒,交互體驗差;二是同一段語料每次會話都要重新輸入,幾次下來比 RAG 貴 50-200 倍。1M context 適合做一次性的全局推理(比如「跨文檔找矛盾」),不適合反覆訪問同一份語料。我們建議在 API易 apiyi.com 上用 Sonnet 1M 跑全局推理任務、用 Haiku 跑批處理細分任務,組合起來性價比最高。
Q2:NotebookLM 和自己搭向量庫怎麼選?
如果只是個人或小團隊做靜態語料分析、風格研究、問答查詢,NotebookLM 上手最快,直接拖文件就能用。如果需要定製 chunk 策略、控制檢索權重、對接業務系統、或者用別家的模型做生成,自建向量庫更靈活。
Q3:MCP 真的沒用嗎?
完全不是。MCP 的強項在於「數據頻繁變動」或「不能離開本地」的場景,比如讀取實時日誌、查詢私有數據庫、調用內部 API。對於靜態 Markdown 語料,RAG 幾乎在所有維度都更優,這纔是結論。
Q4:Batch API 真的能省 50% 嗎?響應慢不慢?
Batch API 是異步的,通常 24 小時內返回結果,價格是標準 API 的 50%。對於「蒸餾寫作風格生成 100 篇仿寫文章」這種不要求實時的任務非常合適。疊加 1M context 標準定價後,綜合成本可以壓到原來的 30%-40%。我們建議在 API易 apiyi.com 平臺先用同步 API 跑通流程,再切到 Batch 模式批量產出。
Q5:語料裏有圖片、表格、代碼塊怎麼辦?
Markdown 本身已經把這些結構保留得很好,但要注意:大段代碼塊會佔用大量 Token,如果只是分析文字風格,可以先用腳本剝離代碼;表格如果太複雜建議轉成 CSV 單獨存儲,只把摘要塞給大模型,這能進一步節省 30% 以上的 Token。
八、總結
回到最初那個問題:幾十萬字 Markdown 該用哪種方式喂大模型?答案不是單選,而是分階段組合。小樣本探索期用對話直傳最快,中等規模研究期用向量知識庫或 NotebookLM 最穩,規模化生產期一定要切到批處理腳本配合 Batch API,把大模型的角色從「執行者」收斂到「規律發現者」,代碼纔是真正負責跑量的那一環。
理解這條路徑之後,大模型 Markdown 語料 省 Token這件事就從「選哪個工具」變成了「選哪個階段用哪個組合」。如果你現在正卡在某個階段不確定要不要切換,可以先用 API易 apiyi.com 平臺跑一次小規模評測,把每千字成本、檢索準確率、首 Token 延遲三組數據拉出來比對,決策會清晰很多。希望這篇對比能幫你少走幾條彎路,把預算花在真正產出價值的環節上。
—— APIYI Team(api.apiyi.com)