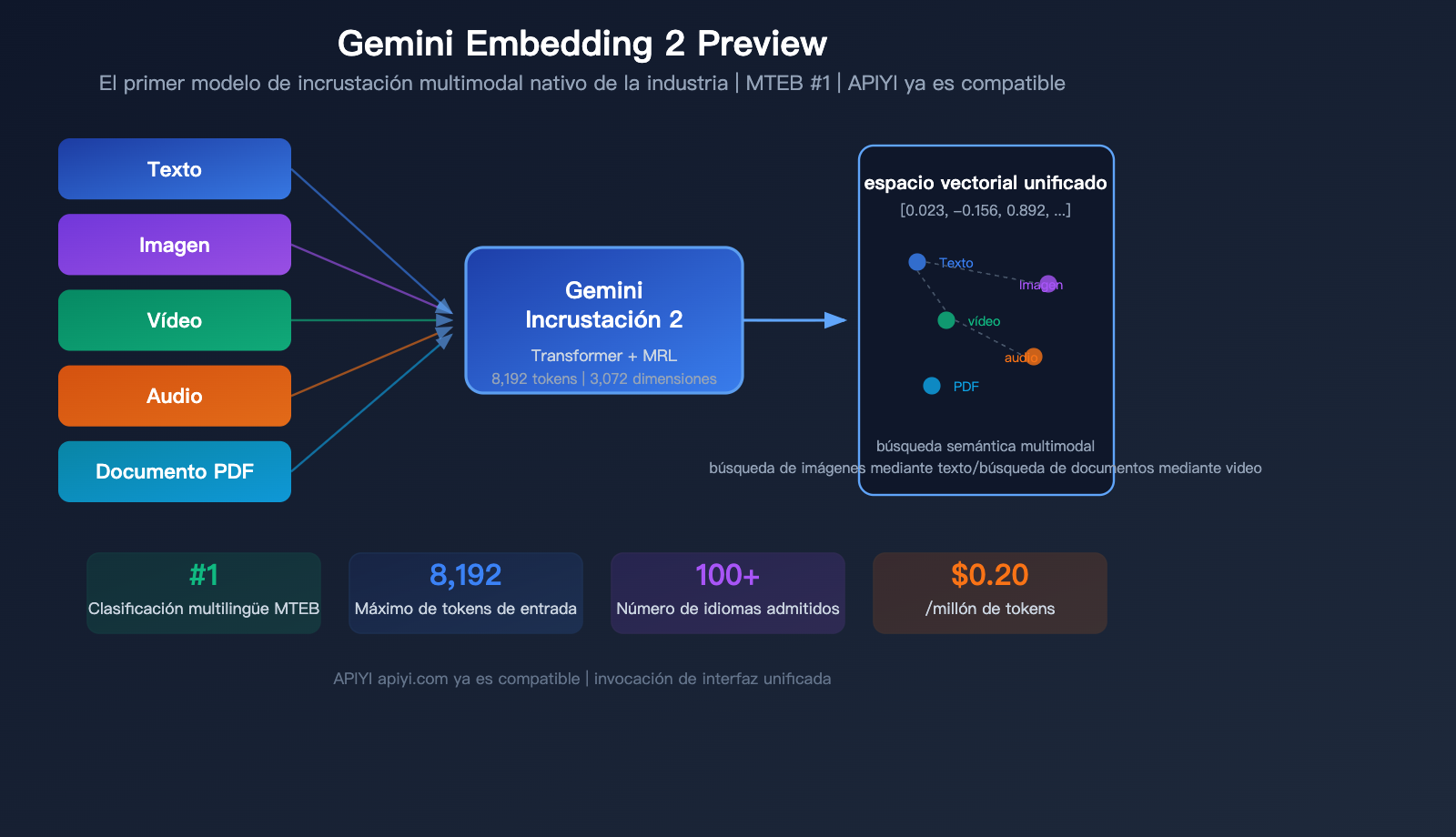
Google lanzó en marzo de 2026 un modelo fundamental: Gemini Embedding 2 Preview, el primer modelo de incrustación (embedding) multimodal nativo de la industria. Es capaz de mapear texto, imágenes, video, audio y documentos PDF en un mismo espacio vectorial, alcanzando el puesto número 1 en el benchmark multilingüe MTEB, superando al segundo lugar por más de 5 puntos porcentuales.
Valor principal: Al terminar de leer este artículo, conocerás los 5 avances técnicos de Gemini Embedding 2 Preview, una comparativa de rendimiento y precios frente a la competencia, y cómo integrarlo rápidamente mediante API.
¿Qué es Gemini Embedding 2 Preview?
Gemini Embedding 2 Preview es el modelo de incrustación (embedding) más reciente lanzado por Google el 10 de marzo de 2026. Está inicializado sobre la arquitectura Gemini, utiliza una estructura Transformer de atención bidireccional y es el primer modelo de incrustación de Google con soporte nativo para entradas multimodales.
| Especificación | Detalles |
|---|---|
| ID del modelo | gemini-embedding-2-preview |
| Fecha de lanzamiento | 10 de marzo de 2026 |
| Estado | Preview (versión preliminar, versión final pendiente) |
| Dimensión de salida predeterminada | 3,072 |
| Rango de dimensiones opcional | 128 — 3,072 |
| Máximo de tokens de entrada | 8,192 (4 veces más que la generación anterior) |
| Soporte multimodal | Texto, imágenes, video, audio, PDF |
| Soporte de idiomas | Más de 100 idiomas |
| Entrenamiento Matryoshka | Soportado (permite truncar dimensiones manteniendo la calidad semántica) |
| Plataformas disponibles | Gemini API, Vertex AI, APIYI apiyi.com |
Diferencias clave con los modelos anteriores
| Característica | text-embedding-004 | gemini-embedding-001 | gemini-embedding-2-preview |
|---|---|---|---|
| Máximo de tokens de entrada | 2,048 | 2,048 | 8,192 |
| Dimensión de salida | Hasta 768 | 128-3,072 | 128-3,072 |
| Multimodal | Solo texto | Solo texto | Texto+Imagen+Video+Audio+PDF |
| Especificación de tarea | Campo task_type |
Campo task_type |
Instrucciones integradas en el prompt |
| Soporte MRL | No soportado | Soportado | Soportado |
| Precio/millón de tokens | Servicio descontinuado | $0.15 | $0.20 |
🎯 Consejo de integración: APIYI apiyi.com ya admite la invocación del modelo gemini-embedding-2-preview.
Puedes integrarlo mediante la interfaz compatible con OpenAI, sin necesidad de configurar una clave API de Google por separado.
Análisis detallado de los 5 avances técnicos
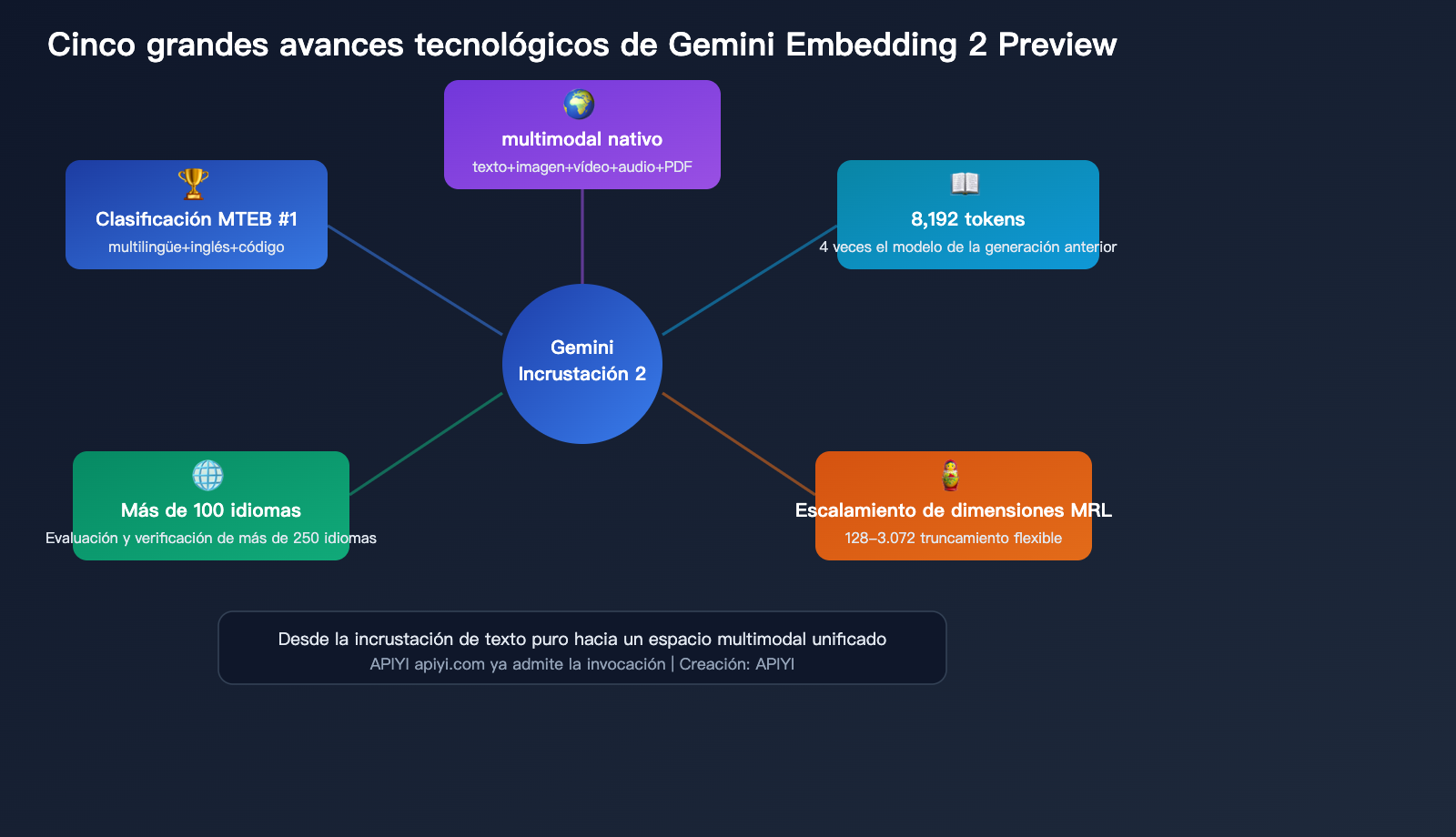
Avance 1: Espacio de incrustación unificado y nativamente multimodal
Esta es la mayor ventaja diferencial de Gemini Embedding 2: el contenido de 5 modalidades se mapea en el mismo espacio vectorial.
| Modalidad | Requisitos de formato | Límite por solicitud | Notas |
|---|---|---|---|
| Texto | Texto plano | 8,192 tokens | Soporta más de 100 idiomas |
| Imagen | PNG, JPEG | Hasta 6 por solicitud | Procesamiento directo de píxeles |
| Video | MP4, MOV | Máximo 120 segundos | Muestreo automático de hasta 32 fotogramas |
| Audio | MP3, WAV | Máximo 80 segundos | Procesamiento nativo, sin necesidad de transcripción |
| Documentos PDF | Hasta 6 páginas por solicitud | Incluye capacidad OCR |
Escenarios de aplicación reales:
- Búsqueda de imágenes mediante texto ("coche deportivo rojo en la pista" → devuelve imágenes coincidentes)
- Búsqueda de fragmentos de video similares mediante imágenes
- Búsqueda de documentos relacionados mediante descripciones de voz
- Construcción de bases de conocimiento unificadas y multimodales
Esto era imposible con modelos de incrustación anteriores; la serie text-embedding-3 de OpenAI solo admite texto. Si necesitabas buscar imágenes, debías usar primero un modelo visual para extraer una descripción y luego realizar la incrustación, lo que añadía un paso extra y provocaba pérdida de información.
Avance 2: Ventana de contexto de 8,192 tokens
La ventana de entrada ha pasado de 2,048 a 8,192 tokens, lo que significa que puedes incrustar fragmentos de documentos mucho más largos de una sola vez.
Para sistemas RAG (Generación Aumentada por Recuperación), esta mejora es muy práctica:
- Antes, era necesario dividir los documentos en fragmentos pequeños de 500-1000 tokens.
- Ahora, puedes usar fragmentos grandes de 2000-4000 tokens, conservando mucha más información contextual.
- Fragmentos de documento más grandes = menos divisiones = resultados de búsqueda más completos.
Avance 3: Escalabilidad de dimensiones Matryoshka
Gemini Embedding 2 utiliza el entrenamiento Matryoshka Representation Learning (MRL), donde el modelo concentra la información semántica más importante en las primeras dimensiones del vector.
Esto significa que puedes elegir las dimensiones de forma flexible según el escenario:
| Dimensión | Tamaño del vector | Escenario de aplicación | Pérdida de calidad |
|---|---|---|---|
| 3,072 (predeterminado) | 12.3 KB | Recuperación de máxima precisión | Ninguna |
| 1,536 | 6.1 KB | Equilibrio entre precisión y almacenamiento | Mínima |
| 768 | 3.1 KB | Preferido para despliegues a gran escala | Baja |
| 256 | 1.0 KB | Sistemas de recomendación en tiempo real | Media |
| 128 | 0.5 KB | Escenarios de compresión extrema | Alta |
Nota: Al usar dimensiones inferiores a 3,072, es necesario normalizar manualmente el vector antes de calcular la similitud.
Avance 4: Soporte para más de 100 idiomas
En las pruebas de referencia multilingües MTEB, Gemini Embedding 2 se evaluó en más de 250 idiomas, superando con creces la cobertura de la competencia.
Indicadores clave de rendimiento lingüístico:
- Minería de textos bilingües (Bitext Mining): 79.32 puntos
- Recuperación translingüe (XOR-Retrieve): Recall@5kt 90.42 puntos
- Comprensión multilingüe (XTREME-UP): MRR@10 64.33 puntos
Avance 5: Número 1 en múltiples rankings MTEB
| Prueba de referencia | Puntuación | Ranking | Margen de ventaja |
|---|---|---|---|
| MTEB Multilingüe (Mean Task) | 68.32 | N.º 1 | +5.09 |
| MTEB Multilingüe (Mean Type) | 59.64 | N.º 1 | — |
| MTEB Inglés v2 (Mean Task) | 73.30 | N.º 1 | — |
| MTEB Inglés v2 (Mean Type) | 67.67 | N.º 1 | — |
| MTEB Código (Mean All) | 74.66 | N.º 1 | — |
Como comparación, el segundo modelo, gte-Qwen2-7B-instruct, obtuvo 62.51 puntos en el MTEB multilingüe; Gemini Embedding 2 lidera por casi 6 puntos, lo cual es una brecha enorme en el campo de los modelos de incrustación.
💡 Consejo de desarrollo: Si estás construyendo un sistema RAG o una aplicación de búsqueda semántica,
Gemini Embedding 2 es actualmente la opción más potente en escenarios multilingües y de código.
A través de APIYI apiyi.com puedes integrar este modelo con un solo clic, además de soportar modelos de embedding de OpenAI,
lo que facilita comparar resultados rápidamente.
Comparativa de precios y rendimiento frente a la competencia
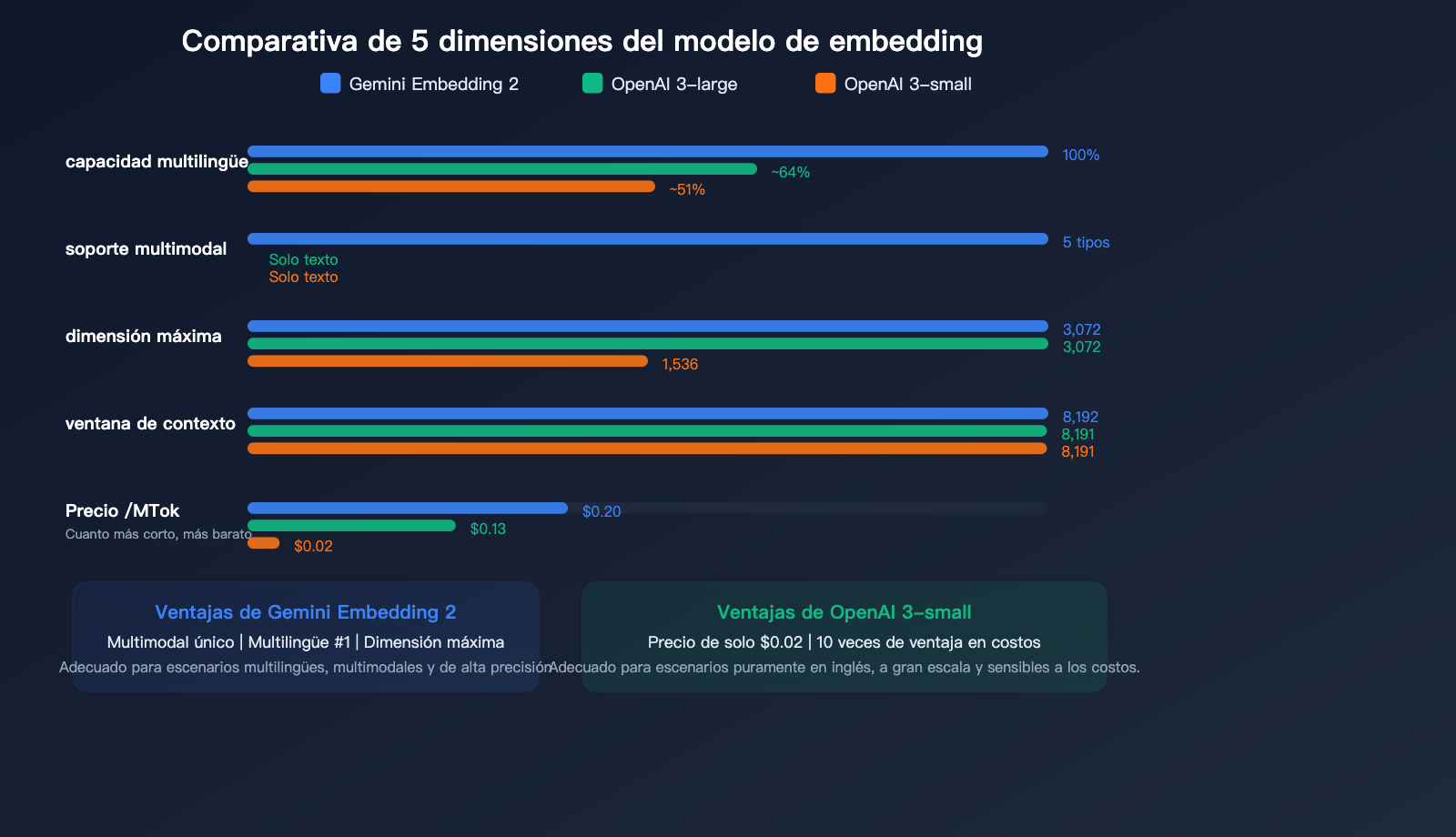
Comparativa de precios de incrustación de texto (embeddings)
| Modelo | Precio/Millón de Tokens | Dimensión máxima | Entrada máxima | Multimodal | Ranking multilingüe |
|---|---|---|---|---|---|
| Gemini Embedding 2 | $0.20 | 3,072 | 8,192 | ✅ Pentamodal | #1 |
| gemini-embedding-001 | $0.15 | 3,072 | 2,048 | ❌ | — |
| OpenAI text-embedding-3-large | $0.13 | 3,072 | 8,191 | ❌ | — |
| OpenAI text-embedding-3-small | $0.02 | 1,536 | 8,191 | ❌ | — |
Precios de contenido multimodal (Exclusivo de Gemini Embedding 2):
| Tipo de entrada | Precio estándar/Millón de Tokens | Precio por lotes/Millón de Tokens |
|---|---|---|
| Texto | $0.20 | $0.10 |
| Imagen | $0.45 (~$0.00012/ud) | $0.225 |
| Audio | $6.50 (~$0.00016/seg) | $3.25 |
| Video | $12.00 (~$0.00079/frame) | $6.00 |
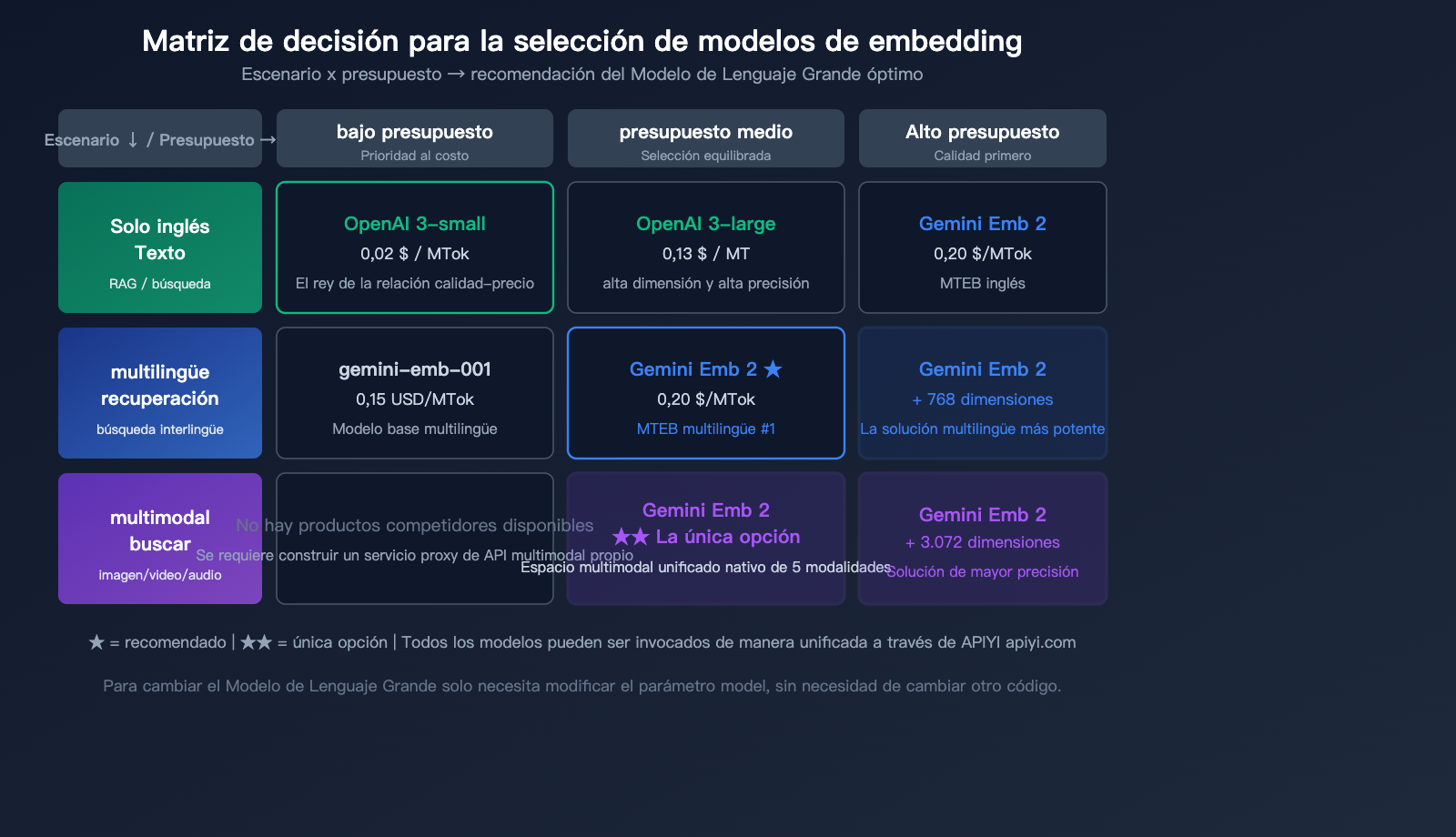
Recomendaciones de selección
| Escenario de uso | Modelo recomendado | Motivo |
|---|---|---|
| Solo texto, sensible al costo | OpenAI text-embedding-3-small | El más económico ($0.02) |
| Solo texto, alta precisión | Gemini Embedding 2 u OpenAI 3-large | Precisión similar, Gemini superior en multilingüe |
| Búsqueda multimodal | Gemini Embedding 2 | Única solución multimodal nativa |
| Recuperación multilingüe | Gemini Embedding 2 | #1 en multilingüe MTEB |
| Búsqueda de código | Gemini Embedding 2 | #1 en código MTEB |
| Gran escala, bajo costo | OpenAI 3-small + API por lotes | 10x ventaja en precio |
🎯 Consejo de selección: La elección del modelo de embedding depende de tu caso de uso específico.
Recomendamos integrar los modelos de embedding de Gemini y OpenAI a través de la plataforma APIYI (apiyi.com),
para comparar los resultados de recuperación con datos reales antes de decidir. La plataforma admite una interfaz unificada, por lo que puedes cambiar de modelo sin modificar tu código.
Detalles sobre la invocación de la API
Especificación del tipo de tarea (Cambio importante)
A diferencia de gemini-embedding-001, Gemini Embedding 2 ya no utiliza el parámetro task_type. En su lugar, el tipo de tarea se especifica incrustando instrucciones dentro del contenido de entrada.
8 tipos de tareas compatibles:
| Tipo de tarea | Formato de consulta | Formato de documento |
|---|---|---|
| Búsqueda/Recuperación | task: search result | query: {contenido} |
title: {título} | text: {contenido} |
| Preguntas y respuestas | task: question answering | query: {pregunta} |
title: {título} | text: {contenido} |
| Verificación de hechos | task: fact checking | query: {afirmación} |
title: {título} | text: {contenido} |
| Recuperación de código | task: code retrieval | query: {descripción} |
title: {título} | text: {código} |
| Clasificación | task: classification | query: {contenido} |
Mismo formato |
| Agrupamiento (Clustering) | task: clustering | query: {contenido} |
Mismo formato |
| Similitud de oraciones | task: sentence similarity | query: {oración} |
Mismo formato |
Para el lado del documento, si no hay título, utiliza title: none.
Ejemplo de invocación en Python
import openai
# Invocación a través de la interfaz unificada de APIYI
client = openai.OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
# Incrustación de texto - Escenario de búsqueda
response = client.embeddings.create(
model="gemini-embedding-2-preview",
input="task: search result | query: ¿Qué es una base de datos vectorial?",
dimensions=768 # Dimensiones opcionales: 128-3072
)
embedding = response.data[0].embedding
print(f"Dimensión del vector: {len(embedding)}")
print(f"Primeros 5 valores: {embedding[:5]}")
Ver el código completo del flujo de recuperación RAG
import openai
import numpy as np
from typing import List
client = openai.OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
def get_embedding(text: str, task: str = "search result", dim: int = 768) -> List[float]:
"""Obtener vector de incrustación de texto"""
formatted = f"task: {task} | query: {text}"
response = client.embeddings.create(
model="gemini-embedding-2-preview",
input=formatted,
dimensions=dim
)
vec = response.data[0].embedding
# La dimensión de truncamiento MRL requiere normalización manual
if dim < 3072:
norm = np.linalg.norm(vec)
vec = (np.array(vec) / norm).tolist()
return vec
def get_doc_embedding(title: str, text: str, dim: int = 768) -> List[float]:
"""Obtener vector de incrustación de documento"""
formatted = f"title: {title} | text: {text}"
response = client.embeddings.create(
model="gemini-embedding-2-preview",
input=formatted,
dimensions=dim
)
vec = response.data[0].embedding
if dim < 3072:
norm = np.linalg.norm(vec)
vec = (np.array(vec) / norm).tolist()
return vec
def cosine_similarity(a: List[float], b: List[float]) -> float:
"""Calcular similitud de coseno"""
a, b = np.array(a), np.array(b)
return np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b))
# Ejemplo de uso
query_vec = get_embedding("Cómo optimizar los resultados de recuperación RAG")
doc_vec = get_doc_embedding(
"Guía de optimización RAG",
"Este artículo presenta 5 métodos para optimizar la calidad de recuperación RAG..."
)
similarity = cosine_similarity(query_vec, doc_vec)
print(f"Similitud: {similarity:.4f}")
🚀 Inicio rápido: Recomendamos usar la plataforma APIYI apiyi.com para integrar Gemini Embedding 2 rápidamente.
Esta plataforma ofrece una interfaz de embedding compatible con OpenAI, permitiendo completar la integración en 5 minutos,
y admite la invocación unificada de modelos de embedding convencionales como OpenAI, Gemini y Cohere.
Notas de uso
Limitaciones del estado Preview
| Limitación | Descripción | Impacto |
|---|---|---|
| Posibles cambios de versión | Las especificaciones y precios pueden ajustarse en la fase Preview | Se recomienda preparar planes de respaldo para entornos de producción |
| Incompatibilidad de espacio vectorial | No se puede mezclar con vectores de modelos antiguos | La actualización requiere reindexación completa |
| Normalización para dimensiones bajas | Requiere normalización manual al usar dimensiones <3,072 | Es necesario añadir pasos de normalización en el código |
| Límites de tasa estrictos | La cuota de modelos Preview es menor que la de modelos GA | Se requiere solicitar un aumento de cuota para uso a gran escala |
| Uso de datos en capa gratuita | Los datos de la capa gratuita se utilizan para mejorar el producto | Se recomienda usar la capa de pago para datos sensibles |
Notas sobre la migración desde modelos antiguos
- Reindexación obligatoria: Los espacios vectoriales de diferentes modelos son incompatibles; no pueden mezclarse en la misma base de datos.
- Cambio de formato de tipo de tarea: Se cambió el parámetro
task_typepor instrucciones incrustadas en el prompt. - Procesamiento de normalización: Si utilizas dimensiones no predeterminadas, debes añadir lógica de normalización en tu código.
- Prueba de efectos antes de migrar: Se recomienda comparar los resultados de recuperación entre los modelos nuevos y antiguos en un entorno de prueba antes de decidir la migración.
Preguntas frecuentes
Q1: ¿Qué ventajas tiene Gemini Embedding 2 Preview frente a OpenAI text-embedding-3-large?
Sus ventajas principales se resumen en tres puntos: soporte multimodal nativo (OpenAI solo admite texto), el puesto número 1 en el ranking multilingüe MTEB (con una ventaja significativa) y una mayor calidad en la incrustación de código. Sin embargo, OpenAI text-embedding-3-large es más económico ($0.13 frente a $0.20) y, si solo necesitas incrustación de texto en inglés, la calidad de ambos es muy similar. A través de APIYI (apiyi.com) puedes invocar ambos modelos y compararlos con datos reales.
Q2: ¿Qué utilidad práctica tiene la incrustación multimodal?
Su aplicación más directa es la búsqueda transmodal: el usuario introduce texto y el sistema devuelve imágenes, vídeos o documentos relacionados. Por ejemplo, en un entorno de comercio electrónico, se puede buscar un producto con el término "vestido rojo", o en una base de conocimientos corporativa, buscar fragmentos relevantes en vídeos de formación mediante una descripción textual. El método tradicional requería usar primero un modelo visual para extraer una descripción y luego incrustar el texto; Gemini Embedding 2 procesa directamente la imagen o vídeo original, reduciendo la pérdida de información.
Q3: ¿Qué dimensiones son las más adecuadas? ¿Hay mucha diferencia entre 768 y 3072?
Para la mayoría de las aplicaciones, 768 dimensiones representan el equilibrio ideal: el coste de almacenamiento es solo una cuarta parte del de 3072, pero la pérdida en la calidad de recuperación es mínima (gracias al entrenamiento Matryoshka). Si tu conjunto de datos es pequeño (<1 millón de registros) y requieres una precisión extrema, utiliza 3072 dimensiones. Si manejas un gran volumen de datos o necesitas una recuperación en tiempo real, 768 o incluso 256 dimensiones son opciones perfectamente razonables.
Q4: ¿Cómo soporta APIYI a Gemini Embedding 2? ¿Se requiere configuración adicional?
APIYI (apiyi.com) ya es compatible con el modelo gemini-embedding-2-preview. Puedes invocarlo mediante la interfaz de incrustación estándar compatible con OpenAI, sin necesidad de configurar una clave API de Google adicional. Solo tienes que especificar gemini-embedding-2-preview en el parámetro model; el resto de los parámetros (como dimensions) son exactamente iguales a los de la interfaz de incrustación de OpenAI.
Resumen: El nuevo estándar en embeddings multimodales
Gemini Embedding 2 Preview marca un hito importante en los modelos de embedding: la transición del texto puro hacia un espacio unificado verdaderamente multimodal. Al alcanzar el primer puesto simultáneamente en las dimensiones multilingüe, inglés y código del MTEB, sumado a su ventana de contexto de 8K y la escalabilidad de dimensiones MRL, ofrece las capacidades fundamentales más potentes actualmente para sistemas RAG, búsqueda semántica y construcción de bases de conocimiento.
Resumen de puntos clave:
- El primer modelo de embedding nativo de cinco modalidades (texto + imagen + video + audio + PDF) de la industria.
- 1.er lugar en el benchmark multilingüe MTEB, superando al segundo por más de 5 puntos.
- Ventana de contexto de 8,192 tokens, 4 veces mayor que la generación anterior.
- Entrenamiento MRL que admite una escalabilidad flexible de 128 a 3,072 dimensiones.
- Precio de $0.20 por millón de tokens, ofreciendo una relación costo-beneficio extremadamente alta para escenarios multimodales.
Recomendamos acceder rápidamente a Gemini Embedding 2 Preview a través de APIYI apiyi.com; una sola clave API permite integrar modelos de embedding líderes como Gemini y OpenAI, facilitando la comparación y el cambio entre ellos.
📝 Autor de este artículo: Equipo técnico de APIYI | APIYI apiyi.com – Plataforma de acceso unificado a más de 300 APIs de Modelos de Lenguaje Grande.
Referencias
-
Blog oficial de Google: Anuncio del lanzamiento de Gemini Embedding 2
- Enlace:
blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-embedding-2/ - Descripción: Incluye la filosofía de diseño del modelo y una introducción a sus capacidades multimodales.
- Enlace:
-
Documentación de la API de Gemini: Guía oficial de uso de la API
- Enlace:
ai.google.dev/gemini-api/docs/embeddings - Descripción: Parámetros completos de la API y ejemplos de invocación del modelo.
- Enlace:
-
Documento de investigación de Gemini Embedding: Detalles técnicos y benchmarks
- Enlace:
arxiv.org/html/2503.07891v1 - Descripción: Datos detallados de las pruebas MTEB y análisis de la arquitectura del modelo.
- Enlace:
-
Precios de la API de Gemini: Información detallada de precios por modalidad
- Enlace:
ai.google.dev/gemini-api/docs/pricing - Descripción: Precios desglosados para texto, imágenes, audio y video.
- Enlace: