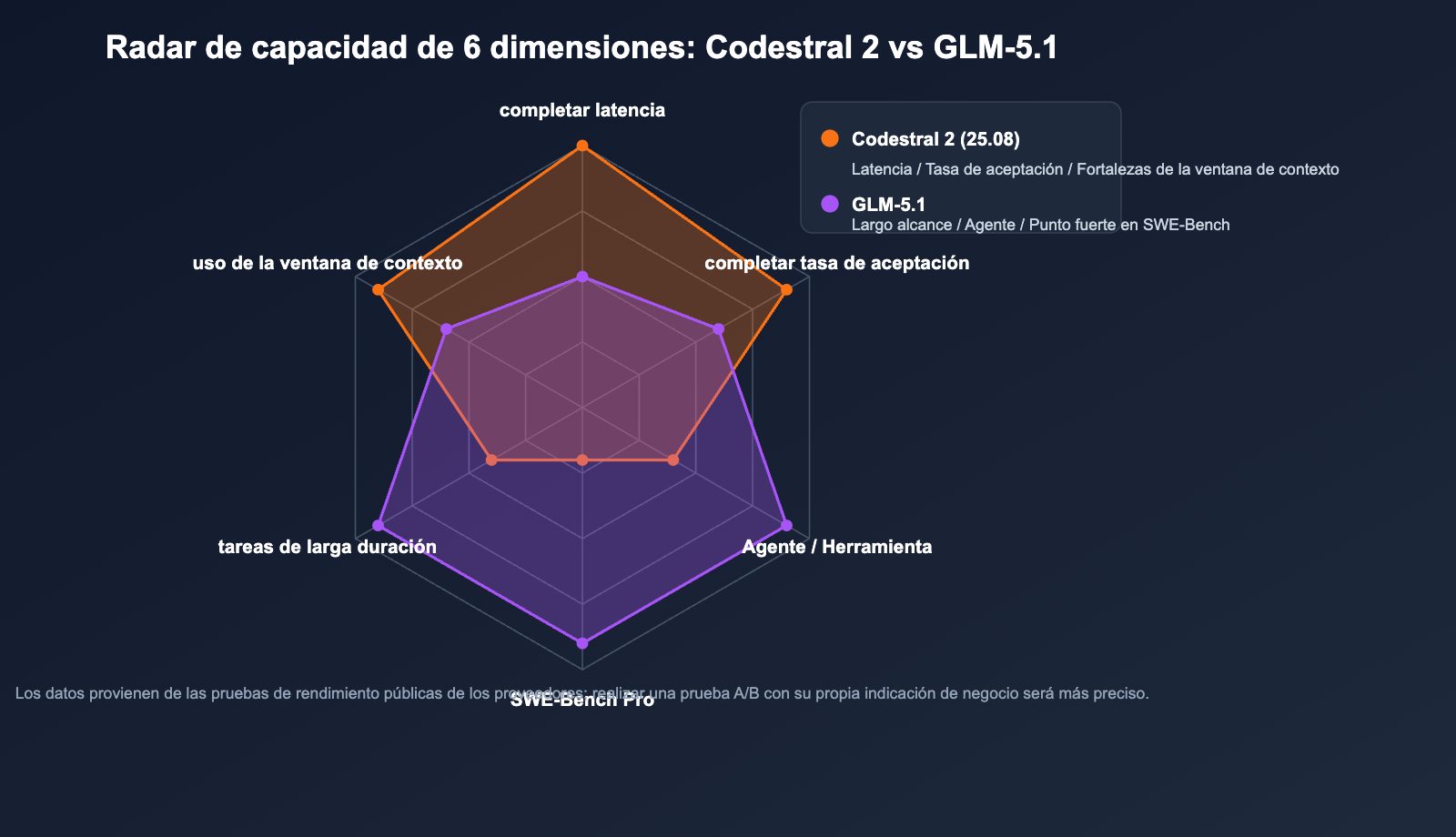
En 2026, el panorama de los Modelos de Lenguaje Grande dedicados a la programación está dividido por dos tipos de productos radicalmente distintos: por un lado, los especialistas en "IDE y autocompletado de alta frecuencia", representados por Mistral Codestral 2 (la versión más reciente, Codestral 25.08), enfocados en el Fill-in-the-Middle (FIM), una alta tasa de aceptación en el autocompletado y una respuesta instantánea en más de 80 lenguajes; por otro lado, los "agentes de largo alcance", como Zhipu GLM-5.1, que utilizan una arquitectura MoE de 744B de parámetros y una ventana de contexto de 200K, diseñados para tareas de ingeniería autónomas de 8 horas, con capacidades de nivel SWE-Bench Pro.
Aunque estas dos rutas tienen públicos y estrategias de facturación que apenas se solapan, a menudo se comparan bajo la pregunta de "¿cuál es mejor para programar?". Este artículo, basado en los anuncios oficiales de Mistral AI (Codestral 25.08 del 30/07/2025) y la documentación para desarrolladores de Z.ai (GLM-5.1, lanzado el 27/03/2026), ofrece una tabla de decisiones de selección replicable basada en 6 dimensiones: arquitectura, benchmarks, contexto, tareas de largo alcance, despliegue y precios, además de incluir código de comparación para la invocación del modelo vía API, ayudándote a decidir en menos de 10 minutos.

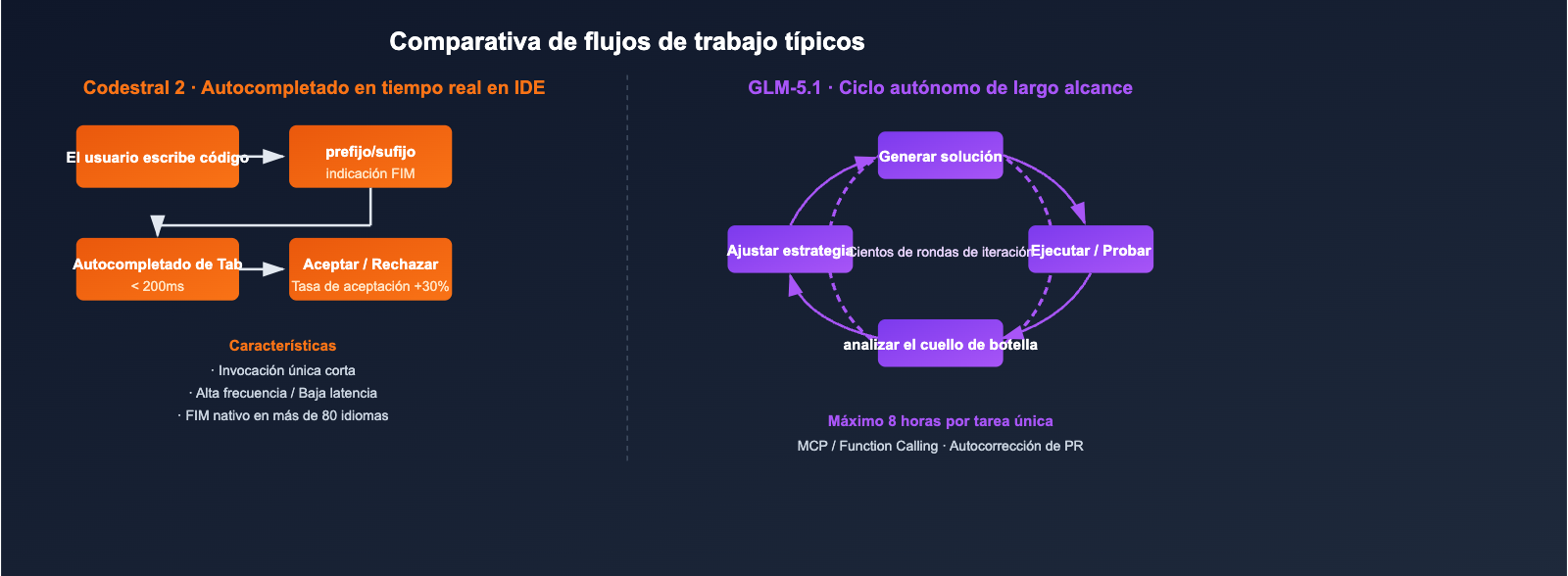
Diferencias de posicionamiento central entre Codestral 2 y GLM-5.1
Antes de profundizar en las pruebas de rendimiento, debemos aclarar algo: estos dos modelos no pertenecen a la misma categoría de producto. Compararlos directamente en el mismo plano puede llevar a conclusiones muy engañosas.
Posicionamiento en una frase
- Codestral 2 (25.08): Un Modelo de Lenguaje Grande especializado en código, orientado a tareas de autocompletado y edición. Con una arquitectura densa de 22B, objetivo de entrenamiento FIM nativo y énfasis en "respuesta en milisegundos + alta tasa de aceptación", es un estándar de facto para productos tipo IDE Copilot.
- GLM-5.1: Un Modelo de Lenguaje Grande insignia de propósito general, orientado a agentes y tareas de programación de largo alcance. Con 744B MoE (activación de ~40B por token) y una ventana de contexto de 200K, alcanzó 58.4 puntos en SWE-Bench Pro, superando a GPT-5.4, Claude Opus 4.6 y Gemini 3.1 Pro.
Tres preguntas que debes responder antes de elegir
| Pregunta | Se inclina por Codestral 2 | Se inclina por GLM-5.1 |
|---|---|---|
| ¿Tu caso de uso principal es el autocompletado en el IDE o la creación autónoma de PRs? | Autocompletado en IDE | Tareas autónomas de varios pasos |
| ¿El volumen de tokens por solicitud es de decenas o de decenas de miles? | Decenas a miles | Miles a decenas de miles |
| ¿Puede el usuario tolerar tiempos de espera de decenas de segundos? | No | Sí |
🎯 Recomendación de selección: Si el 80% de tus invocaciones provienen del "autocompletado tras escribir una línea de código", elige Codestral 2; si el 80% proviene de "ayúdame a corregir este error en el repositorio", elige GLM-5.1. Ambos pueden probarse en paralelo mediante la interfaz unificada de APIYI (apiyi.com), sin necesidad de integrar Mistral y Z.ai por separado.
title: "Comparativa de arquitectura y parámetros: Codestral 2 vs GLM-5.1"
description: "Análisis técnico detallado entre Codestral 2 y GLM-5.1: arquitectura, rendimiento en tareas de código y recomendaciones de despliegue."
Comparativa de arquitectura y parámetros: Codestral 2 vs GLM-5.1
Las diferencias arquitectónicas son la raíz de todo el rendimiento posterior.
Resumen de especificaciones clave
| Proyecto | Codestral 2 (25.08) | GLM-5.1 |
|---|---|---|
| Fabricante | Mistral AI | Zhipu AI (Z.ai) |
| Arquitectura | Dense Transformer | Mixture-of-Experts |
| Parámetros totales | 22B | 744B |
| Parámetros activos | 22B | Aprox. 40B (256 expertos, 8 activos por token) |
| Ventana de contexto | 256K | 200K |
| Salida máxima | Estándar | 128K tokens |
| Mecanismo de atención | Estándar + optimización FIM | DeepSeek Sparse Attention |
| Licencia | Licencia comercial Mistral / MNPL | MIT (pesos de código abierto) |
| Fecha de lanzamiento | 30-07-2025 (última iteración) | 27-03-2026 |
| Cobertura de lenguajes | 80+ lenguajes principales | Multilingüe general |
Impacto directo de las diferencias arquitectónicas
- Memoria de video y costes de despliegue: Codestral 2 (22B) puede realizar inferencia en una sola máquina (A100 80G); GLM-5.1 requiere paralelismo multitarjeta o un servicio de inferencia gestionado.
- Latencia por token: La arquitectura densa de Codestral 2 ofrece una latencia más estable en entradas cortas; GLM-5.1, debido a la selección del enrutador y la atención dispersa, tiene un primer token ligeramente más lento, pero destaca en secuencias largas.
- Estrategia de código abierto: GLM-5.1 libera sus pesos bajo licencia MIT, lo que facilita el despliegue privado y el reentrenamiento; Codestral 2 puede ejecutarse localmente, pero requiere licencia para uso comercial.
🎯 Sugerencia de despliegue: Los equipos que necesiten un despliegue totalmente privado deben priorizar los pesos MIT de GLM-5.1. Aquellos que solo busquen una integración rápida sin preocuparse por la autogestión pueden utilizar el servicio proxy de API de APIYI (apiyi.com) para invocar ambos modelos, ahorrándose los trámites de adquisición y autorización.
Comparativa de benchmarks de código: Codestral 2 vs GLM-5.1
Los resultados de ambos modelos provienen de pruebas internas de los fabricantes, y los conjuntos de evaluación no coinciden totalmente. A continuación, solo se enumeran las métricas con significado comparativo directo.
Puntos fuertes de Codestral 2: Calidad de autocompletado e indicadores de IDE
| Métrica | Valor | Explicación |
|---|---|---|
| Accepted Completions (Tasa de aceptación) | +30% (vs 25.01) | Tasa de adopción en IDE de producción |
| Retained Code (Tasa de retención) | +10% | Proporción de código sugerido que no se elimina al enviar |
| Runaway Generations (Generaciones fuera de control) | -50% | Reducción de continuaciones largas e inútiles |
| IFEval v8 (Seguimiento de instrucciones) | +5% | Precisión en las instrucciones |
| Puntuación media MultiPL-E | +5% | Capacidad de código multilingüe |
| HumanEval (Datos gen. anterior 25.01) | 86.6% | Datos de referencia |
| MBPP (Datos gen. anterior 25.01) | 91.2% | Datos de referencia |
Puntos fuertes de GLM-5.1: Tareas de ingeniería complejas
| Métrica | Valor | Explicación |
|---|---|---|
| SWE-Bench Pro | 58.4 | Supera a GPT-5.4 / Claude Opus 4.6 / Gemini 3.1 Pro |
| Comparativa Claude Code | 45.3 (Opus 4.6 es 47.9) | Alcanza el 94.6% de Opus 4.6 |
| vs Línea base GLM-5 | +28% | Optimización post-entrenamiento |
| KernelBench Nivel 3 | 3.6x aceleración | Escenarios de optimización de kernel ML |
| Duración continua por tarea | Máximo 8 horas | Ciclo autónomo de "experimento-análisis-optimización" |
Evaluación de solapamiento de capacidades
| Capacidad | Codestral 2 | GLM-5.1 |
|---|---|---|
| Autocompletado de archivo único | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ |
| Refactorización multiactivo | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
| Localización de errores + PR de reparación | ⭐⭐ | ⭐⭐⭐⭐⭐ |
| Traducción entre lenguajes | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| Agente / Uso de herramientas | ⭐⭐ | ⭐⭐⭐⭐⭐ |
| Latencia del primer token | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ |
🎯 Nota sobre los resultados: Los datos oficiales suelen provenir de configuraciones de evaluación relativamente óptimas, por lo que el rendimiento real en el negocio puede variar entre un 10% y un 20%. Se recomienda realizar una prueba A/B con su propia base de código en APIYI (apiyi.com) antes de tomar una decisión final.
title: "Capacidades de contexto y tareas de largo alcance: Codestral 2 vs. GLM-5.1"
description: "Analizamos las diferencias clave entre Codestral 2 y GLM-5.1 en cuanto a gestión de contexto y ejecución de tareas complejas."
Capacidades de contexto y tareas de largo alcance: Codestral 2 vs. GLM-5.1
Aunque una ventana de contexto de 256K frente a una de 200K parece similar en números, el tipo de tareas que soportan es completamente distinto.
Contexto de 256K en Codestral 2: Autocompletado de repositorio completo
Codestral 2 utiliza sus 256K de contexto principalmente para "introducir todo el repositorio en la indicación", permitiendo que el modelo comprenda las dependencias entre archivos durante el autocompletado:
- Ideal para: Autocompletado de funciones grandes dentro de un monorepo, correcciones de Lint en todo el proyecto y renombrado entre módulos.
- No es ideal para: Flujos de trabajo de agentes que requieran razonamiento en múltiples pasos, llamadas a herramientas y escritura de resultados.
Contexto de 200K + ciclo autónomo de 8 horas en GLM-5.1
El avance de GLM-5.1 no radica en "cuánto contexto puede almacenar", sino en "cuánto tiempo puede trabajar de forma continua":
- En las demostraciones oficiales, el modelo puede iterar cientos de veces en una sola tarea: ejecutar benchmark → identificar cuellos de botella → ajustar estrategia → volver a ejecutar el benchmark.
- La atención dispersa (Sparse Attention) de DeepSeek mantiene el costo de inferencia de secuencias largas de 200K en un rango manejable.
- Al combinarse con Function Calling / MCP, puede conectarse directamente a cadenas de herramientas externas.
Comparativa de tareas de largo alcance
| Tarea | Codestral 2 | GLM-5.1 |
|---|---|---|
| Completar una función de 200 líneas | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| Generar un PR desde un Issue de GitHub | ⭐⭐ | ⭐⭐⭐⭐⭐ |
| Buscar y corregir errores en todo el repo | ⭐⭐ | ⭐⭐⭐⭐⭐ |
| Optimización automática multironda de kernels ML | ⭐ | ⭐⭐⭐⭐⭐ |
| Autocompletado con Tab en el IDE | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ |
🎯 Sugerencia de migración: Si tu equipo utilizaba Codestral para autocompletado de repositorios completos pero se encuentra con escenarios donde "el código se completa pero no pasa las pruebas", intenta que GLM-5.1 tome el control del ciclo "generar-ejecutar-corregir". Puedes reutilizar el mismo código compatible con OpenAI simplemente cambiando la
base_urla través de APIYI apiyi.com.
Inicio rápido: Comparativa de acceso a API para Codestral 2 y GLM-5.1
Ambos modelos ofrecen interfaces compatibles con OpenAI; las diferencias reales residen principalmente en el nombre del modelo y los parámetros. El siguiente ejemplo muestra el código mínimo necesario utilizando la base_url unificada de APIYI apiyi.com.
Invocación de Codestral 2 (autocompletado de código)
from openai import OpenAI
client = OpenAI(
base_url="https://api.apiyi.com/v1",
api_key="YOUR_API_KEY",
)
resp = client.chat.completions.create(
model="codestral-latest", # Apunta a Codestral 25.08
messages=[
{"role": "system", "content": "Eres un ingeniero senior de Python."},
{"role": "user", "content": "Completa una implementación de caché LRU de alto rendimiento."},
],
temperature=0.2,
max_tokens=512,
)
print(resp.choices[0].message.content)
Invocación de GLM-5.1 (tareas de largo alcance)
from openai import OpenAI
client = OpenAI(
base_url="https://api.apiyi.com/v1",
api_key="YOUR_API_KEY",
)
resp = client.chat.completions.create(
model="glm-5.1",
messages=[
{"role": "system", "content": "Eres un agente ingeniero de software. Analiza el repo, ejecuta pruebas e itera."},
{"role": "user", "content": "Corrige todos los casos de prueba fallidos en tests/test_api.py del repositorio."},
],
temperature=0.3,
max_tokens=8192,
# GLM-5.1 soporta Function Calling + salida estructurada
)
print(resp.choices[0].message.content)
📎 Desplegar para ver la invocación específica de FIM (exclusiva de Codestral 2)
# El FIM nativo de Codestral ensambla la indicación mediante prefijo / sufijo
prefix = "def binary_search(arr, target):\n "
suffix = "\n return -1"
prompt = f"[PREFIX]{prefix}[SUFFIX]{suffix}[MIDDLE]"
# Envía el prompt como contenido de usuario a codestral-latest para obtener un autocompletado de alta precisión
🎯 Sugerencia de integración: Ambos modelos siguen el esquema de OpenAI, por lo que solo necesitas cambiar el nombre del modelo para reutilizar el mismo código de negocio. Centralizar las llamadas a través de APIYI apiyi.com te ahorra los costos operativos de mantener cuentas, saldos y estrategias de limitación de tasa por separado en Mistral Console y Z.ai.
Estrategias de precios y despliegue para Codestral 2 y GLM-5.1
El precio y la flexibilidad de despliegue suelen ser el último kilómetro en la toma de decisiones.
Referencia de precios públicos
| Modelo | Precio de entrada | Precio de salida | Notas |
|---|---|---|---|
| Codestral 2 (25.08) | $0.20 / 1M | $0.60 / 1M | Mantiene los precios de la serie Codestral |
| GLM-5.1 | Desde aprox. $3 (Plan Coding) | Basado en plan | Opción de pago por token disponible |
Nota: Los precios anteriores se basan en información pública de los sitios web oficiales y canales de los proveedores; el tipo de cambio real y las promociones están sujetos a cambios diarios.
Comparativa de opciones de despliegue
| Método de despliegue | Codestral 2 | GLM-5.1 |
|---|---|---|
| API oficial en la nube | ✅ Mistral Console | ✅ Plataforma Z.ai |
| Pasarela compatible de terceros | ✅ (APIYI, apiyi.com, etc.) | ✅ (APIYI, apiyi.com, etc.) |
| VPC / Nube privada | ✅ Requiere licencia | ✅ Despliegue libre MIT |
| Inferencia local en máquina única | ✅ A100 única / GPU de consumo limitada | ❌ Requiere múltiples tarjetas |
| Function Calling | Compatible (vía chat completions) | ✅ Soporte nativo + MCP |
🎯 Sugerencia de optimización de costes: Para escenarios de IDE con alta frecuencia de autocompletado y pocos tokens por solicitud, prioriza Codestral 2 con caché. Para escenarios de agentes de baja frecuencia pero con un gran volumen de tokens por solicitud, el plan de suscripción de GLM-5.1 resultará más rentable. Puedes configurar ambas estrategias por grupos de modelos en APIYI (apiyi.com) para evitar que tu cuenta principal se agote por el consumo de un solo modelo.
Guía de recomendaciones y errores comunes para Codestral 2 y GLM-5.1
Decisión en cuatro escenarios típicos
| Escenario | Modelo recomendado | Motivo clave |
|---|---|---|
| Plugins de autocompletado (VSCode / JetBrains) | Codestral 2 | FIM nativo + baja latencia |
| Robots para corrección automática de bugs / PR | GLM-5.1 | Ciclo autónomo de largo alcance |
| Asistente de revisión de código (comentarios por archivo) | Codestral 2 | Respuesta rápida, bajo coste |
| Agente de extremo a extremo (pruebas/despliegue) | GLM-5.1 | MCP + Function Calling |
| Generación de estructuras de proyectos (boilerplate) | Indistinto | Cualquiera de los dos |
| Optimización de rendimiento de kernels ML | GLM-5.1 | Aceleración 3.6x en KernelBench |
Lista de errores comunes a evitar
- ❌ No utilices Codestral 2 para agentes: Aunque su tasa de generación descontrolada se ha reducido en un 50%, no está optimizado para la toma de decisiones en múltiples pasos.
- ❌ No utilices GLM-5.1 para autocompletado de milisegundos: La latencia del primer token no es ideal para la experiencia de respuesta al presionar la tecla Tab en el IDE.
- ❌ No te bases en una sola clasificación: GLM-5.1 gana en SWE-Bench Pro, pero la serie Codestral no se queda atrás en HumanEval.
- ✅ Realiza una pequeña prueba A/B: Toma las 100 indicaciones (prompts) más típicas de tu negocio y ejecútalas comparándolas en APIYI (apiyi.com) cambiando los parámetros del modelo.
Preguntas frecuentes (FAQ)
P1: ¿Por qué la página oficial lo llama Codestral 25.08 y no Codestral 2?
La convención de nombres de Mistral sigue el formato <serie>-<año>.<mes>. Codestral 25.08 pertenece a la segunda generación de iteraciones de Codestral (la primera generación, 24.05, fue lanzada anteriormente, y la segunda generación evolucionó desde 25.01 hasta 25.08). En la industria y la comunidad, es común referirse a las versiones 25.01+ como "Codestral 2". Al realizar la invocación del modelo, basta con especificar codestral-latest para acceder a la versión más reciente de esta segunda generación.
P2: ¿Será muy lenta la inferencia del GLM-5.1 con sus 744B de parámetros?
Gracias a la arquitectura MoE (Mixture of Experts), solo se activan 40B de parámetros por token. Sumado a la atención dispersa (Sparse Attention) de DeepSeek, la velocidad de inferencia real es cercana a la de un modelo denso de 40B. Al combinarlo con las conexiones persistentes y las estrategias de caché de APIYI (apiyi.com), la latencia percibida en escenarios de ventana de contexto larga es bastante aceptable.
P3: ¿Cuál de los dos modelos aprovecha mejor la ventana de contexto?
Los 256K de Codestral 2 son más una cuestión de "capacidad", mientras que los 200K de GLM-5.1, junto con su atención dispersa, resultan más amigables para una "tasa de utilización real". Antes de realizar tareas que involucren repositorios completos, se recomienda usar tiktoken o el tokenizador oficial para estimar el número real de tokens y evitar truncamientos innecesarios.
P4: ¿Qué importancia real tienen los pesos de código abierto para las empresas?
GLM-5.1 libera sus pesos bajo licencia MIT, lo que permite su despliegue en redes internas y reentrenamiento; por otro lado, el uso comercial de Codestral 2 requiere un acuerdo de licencia. Para clientes del sector financiero, gubernamental o empresarial con requisitos de cumplimiento estrictos, esta diferencia es enorme. Si el objetivo es simplemente evitar restricciones de acceso regional, APIYI (apiyi.com) también ofrece un punto de entrada estable y disponible a nivel nacional.
P5: ¿Se pueden usar ambos modelos simultáneamente?
Sí, y de hecho es recomendable. Un enfoque típico es usar Codestral 2 para el autocompletado en el IDE y GLM-5.1 para el agente en segundo plano. Ambos utilizan diferentes claves de modelo (model keys) y se centraliza la facturación a través de APIYI (apiyi.com).
P6: Las puntuaciones son pruebas internas de los fabricantes, ¿qué tan fiables son?
Las puntuaciones de Codestral y GLM son autoinformadas; la puntuación de 58.4 en SWE-Bench Pro de Z.ai aún no cuenta con una replicación independiente. Se recomienda tomar las puntuaciones públicas como una "referencia del límite de capacidad" y realizar pruebas de regresión en sus escenarios de negocio antes de implementarlos.
Conclusión: Recomendaciones finales para elegir entre Codestral 2 y GLM-5.1
Volviendo a las tres preguntas iniciales:
- Si tu producto es un Copilot, autocompletado de pestañas o generación de fragmentos de código, elige Codestral 2. Su FIM (Fill-In-the-Middle), latencia, precio y cobertura de más de 80 lenguajes son el mejor equilibrio para este tipo de escenarios.
- Si tu producto es un robot de PR (Pull Request), agente de corrección de errores o un agente en segundo plano que ejecuta tareas durante 8 horas, elige GLM-5.1. Sus 744B MoE + 58.4 en SWE-Bench Pro + ciclo autónomo de largo alcance, lo convierten en la opción más cercana a Claude Opus 4.6 dentro del ecosistema de código abierto.
- Si tu producto incluye ambos escenarios, usar ambos modelos es la estrategia más económica para 2026.
🎯 Consejo de implementación: Evoluciona tu selección de "elegir uno" a "orquestación de modelos duales". A través de la interfaz compatible con OpenAI de APIYI (apiyi.com), solo necesitas usar un campo en tu código de negocio para distinguir entre "autocompletado corto / tarea larga", lo que te permitirá enrutar automáticamente entre Codestral 2 y GLM-5.1, enviando cada solicitud al modelo más adecuado.
— Equipo de APIYI (Equipo técnico de apiyi.com)