The slow API response times for Alibaba Cloud's Qwen3.5 are a hot topic in the developer community lately. As a model developed in-house by Alibaba, Qwen3.5-Plus and Qwen3.5-Flash should theoretically perform exceptionally well on their own compute resources. However, the actual user experience has left many developers puzzled – it's not just that their own models run slowly on their own platform, but calling third-party models like GLM-5, Kimi-K2.5, and MiniMax-M2.5 through Alibaba Cloud is noticeably sluggish.
Core Value: This article will delve into the root causes of slow API responses on Alibaba Cloud from three perspectives: compute resource supply, architecture design, and scheduling strategies. It will also provide three proven alternative solutions to help you achieve faster inference experiences in your actual projects.

5 Major Reasons for Slow Alibaba Cloud Qwen3.5 API Performance
Reason 1: Severe Shortage of Global GPU Compute Power
This isn't just an Alibaba Cloud issue; it's a systemic problem across the entire industry. The delivery lead time for datacenter-grade GPUs has stretched to 36-52 weeks by 2026. Alibaba Cloud executives have publicly acknowledged a comprehensive shortage of semiconductor manufacturers, storage chips, and memory components, stating that the supply side will be a "major bottleneck" for the next 2-3 years.
| Compute Supply Metric | 2025 | 2026 | Trend |
|---|---|---|---|
| GPU Delivery Lead Time | 12-24 weeks | 36-52 weeks | ↑ Significantly Extended |
| Alibaba Cloud AI Revenue Growth | — | 34% | Demand Explosion |
| Alibaba Cloud Compute Price Adjustment | Benchmark Price | Up to 34% Increase | ↑ Starting April 18, 2026 |
| Global AI Inference Spending Share | 42% | 55% | Exceeds Training for the First Time |
Alibaba Cloud has officially announced a price hike for AI compute power starting April 18, 2026, with increases up to 34%. The direct cause cited is the "global AI demand explosion and rising supply chain costs." Despite a 34% revenue increase, Alibaba Cloud states they still can't meet demand – this is the macro backdrop for the slow Qwen3.5 API performance.
Reason 2: Compute Consumption of the Qwen3.5 Model Architecture
The Qwen3.5 family uses a MoE (Mixture of Experts) architecture. The flagship Qwen3.5-397B-A17B boasts a total of 397 billion parameters, activating 17 billion parameters for each inference. Even the lighter Qwen3.5-Flash (based on 35B-A3B) natively supports a 1 million token context window and multimodal input (text + image + video).
| Model Version | Total Parameters | Activated Parameters | Default Context | Multimodal Support |
|---|---|---|---|---|
| Qwen3.5-397B-A17B (Flagship) | 397 Billion | 17 Billion | 262K→1M | Text+Image+Video |
| Qwen3.5-Plus (API Version) | Not Disclosed | Not Disclosed | 1M | Text+Image+Video |
| Qwen3.5-Flash (API Version) | 35 Billion | 3 Billion | 1M | Text+Image+Video |
| Qwen3.5-122B-A10B | 122 Billion | 10 Billion | 262K | Text+Image+Video |
These models adopt an early-fusion multimodal architecture from the training stage, natively supporting unified processing of text, images, and video. The trade-off for this powerful functionality is a significantly higher computational overhead per request compared to pure text models. Combined with the million-token context window, the VRAM and compute utilization per inference increase substantially.
Reason 3: Additional Latency from Alibaba Cloud Reselling Third-Party Models
When calling third-party models like GLM-5 (Zhipu AI), Kimi-K2.5 (Moonshot AI), or MiniMax-M2.5 through Alibaba Cloud's DashScope platform, the request path actually looks like this:
Your Application → Alibaba Cloud API Gateway → DashScope Orchestration Layer → Third-Party Model Service
Each additional hop introduces more latency. More critically, when Alibaba Cloud resells these models, the GPU resource allocation priority might be lower than for their proprietary models, especially given the overall compute shortage. Developers in the community commonly report that calling GLM-5, Kimi-K2.5, and MiniMax-M2.5 via Alibaba Cloud is noticeably slower than using their official APIs.
Reason 4: Insufficient Optimization in Inference Scheduling Strategies
Specialized third-party inference platforms (like SiliconFlow, Fireworks AI, Together AI) offer significant advantages in inference efficiency through custom CUDA kernels, fused attention mechanisms, and fine-grained scheduling. Real-world benchmarks show:
- SiliconFlow: Up to 2.3x faster inference than general cloud platforms, with a 32% reduction in latency.
- Fireworks AI: Their FireAttention v2 technology claims up to 8x speedup, with practical tests showing around 747 TPS.
- Together AI: Achieves up to 2x speedup for open-source models through speculative decoding and FP4 quantization.
As a general-purpose cloud platform, Alibaba Cloud's inference scheduling prioritizes universality and stability over extreme optimization for inference speed. While this might not be noticeable when compute is abundant, the difference becomes amplified during periods of GPU scarcity.
Reason 5: Multi-Tenant Resource Contention
As China's largest cloud service provider, Alibaba Cloud's AI inference clusters serve a massive number of users simultaneously. During peak hours, contention for GPU resources directly leads to increased queuing times. While Alibaba Cloud's Aegaeon resource pooling system claims to improve GPU utilization by 82%, this fundamentally "cuts the limited pie into smaller slices" and doesn't address the core issue of insufficient total compute capacity.
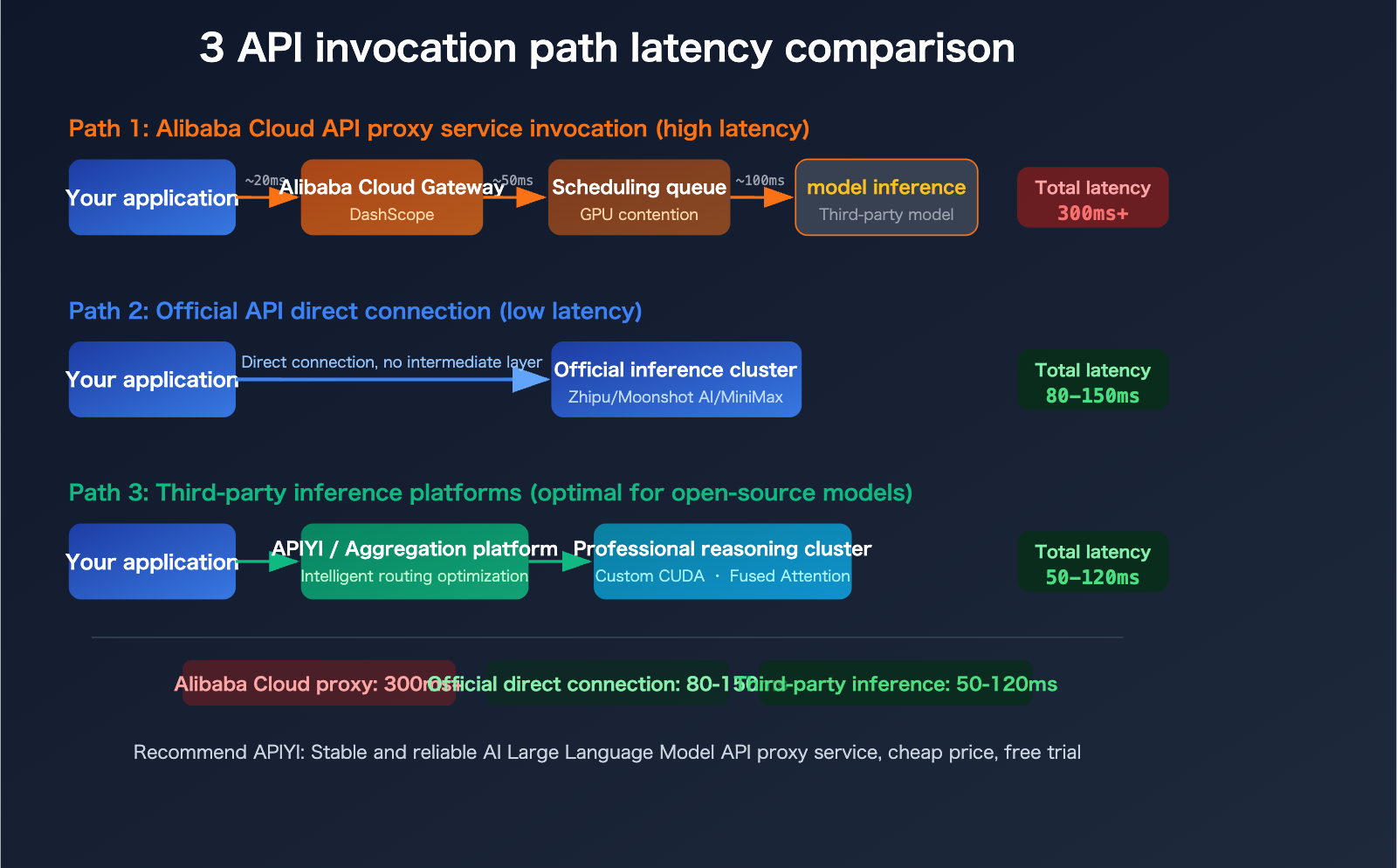
GLM-5, Kimi-K2.5, MiniMax-M2.5: Alibaba Cloud vs. Official API Latency Comparison
Now that we've covered the "why," let's dive into specific model invocation scenarios. Here's an analysis of the experience differences across various platforms for three popular models.
GLM-5 (Zhipu AI) API Invocation Latency Analysis
GLM-5 is Zhipu AI's flagship model, released in February 2026. It boasts 744 billion total parameters and 40 billion active parameters, utilizing an MoE architecture. Trained on Huawei Ascend chips, it supports a 200,000 token context window and is open-sourced under the MIT license.
Key Facts: GLM-5 natively supports Agent mode, allowing it to autonomously break down tasks into sub-tasks for execution. It can also directly generate professional office documents (.docx, .pdf, .xlsx). Its pricing is $1.00/M tokens for input and $3.20/M tokens for output.
When invoking GLM-5 through Alibaba Cloud, requests pass through additional gateway and scheduling layers, significantly increasing latency. In contrast, directly connecting to Zhipu AI's official API (bigmodel.cn) sends requests straight to Zhipu's proprietary inference cluster, resulting in faster responses.
Kimi-K2.5 (Moonshot AI) API Invocation Latency Analysis
Released in January 2026, Kimi-K2.5 is a 1 trillion parameter MoE model, activating only 32 billion parameters per request. It was pre-trained on 15 trillion mixed visual and text tokens and is natively multimodal.
Biggest Highlight: Agent Swarm functionality – it can coordinate up to 100 specialized AI Agents to work collaboratively, reducing execution time by 4.5x. It surpasses Gemini 3 Pro on SWE-Bench Verified, and Cursor AI has confirmed its Composer 2 feature is built upon Kimi technology.
Using Alibaba Cloud's proxy service to invoke Kimi-K2.5 adds extra forwarding hops, making the experience even worse for this trillion-parameter model that already requires substantial computing power. It's recommended to use Moonshot AI's official API directly (platform.moonshot.ai).
MiniMax-M2.5 API Invocation Latency Analysis
MiniMax-M2.5, released in February 2026, has 230 billion total parameters and 10 billion active parameters. It scores 80.2% on SWE-Bench Verified, completing tasks 37% faster than M2.1, on par with Claude Opus 4.6.
Outstanding Cost Advantage: It's claimed to be the first cutting-edge model where "users don't need to worry about costs" – running continuously for 1 hour at 100 tokens/second costs only about $1. It's open-sourced on Hugging Face, and deployment with vLLM or SGLang is recommended.
| Model | Release Date | Total Parameters | Active Parameters | Recommended Invocation | Open Source Status |
|---|---|---|---|---|---|
| GLM-5 | 2026.02.11 | 744 Billion | 40 Billion | Zhipu Official API | MIT Open Source |
| Kimi-K2.5 | 2026.01.27 | 1 Trillion | 32 Billion | Moonshot Official API | Open Source |
| MiniMax-M2.5 | 2026.02.12 | 230 Billion | 10 Billion | MiniMax Official / 3rd Party | MIT Modified |
🎯 Practical Recommendation: For closed-source or semi-open-source third-party models like GLM-5, Kimi-K2.5, and MiniMax-M2.5, we recommend direct connection to their official APIs for the best experience. If you need to manage API interfaces for multiple models uniformly, you can use the APIYI apiyi.com platform to call various models with a single API key, while also enjoying better pricing.
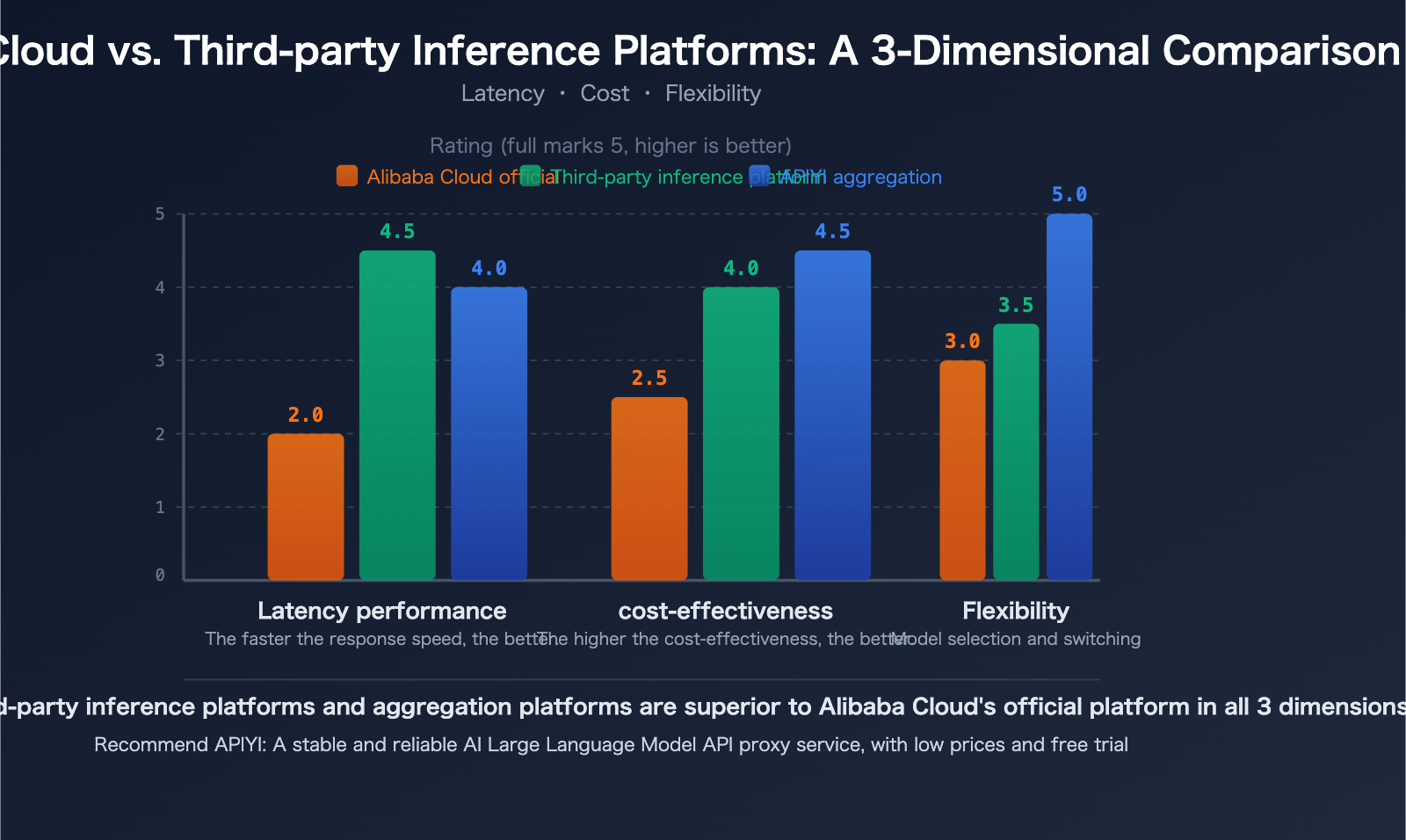
Third-Party Inference Platforms vs. Alibaba Cloud: 3 Key Advantages for Deploying Open-Source Models
For open-source models like Qwen3.5, developers have more options beyond Alibaba Cloud's official API. Professional third-party inference platforms often match or even surpass the performance of native cloud providers when deploying open-source models.
Advantage 1: Faster Inference Speed
The core competitive advantage of specialized inference platforms is speed. Through customized inference engine optimizations, they achieve lower latency on the same models:
| Platform Type | Typical Latency | Throughput | Speed Advantage |
|---|---|---|---|
| General Cloud Platforms (Alibaba Cloud, etc.) | 100-300ms | Baseline | — |
| SiliconFlow | 32% Reduction | 2.3x Increase | Custom CUDA Kernels |
| Fireworks AI | ~0.17s | ~747 TPS | FireAttention v2 |
| Together AI | — | 2x Increase | Speculative Decoding + FP4 Quantization |
| APIYI apiyi.com | Multi-channel Optimization | Intelligent Routing | Auto-selects fastest channel |
Advantage 2: Lower Costs
In 2026, AI inference expenditure surpassed training costs for the first time, accounting for 55% of total AI cloud infrastructure spending. In this context, optimizing inference costs becomes crucial:
- Invoking open-source models via third-party APIs typically costs less than $1/M tokens, saving 70-90% compared to closed-source models.
- Specialized inference platforms leverage next-generation hardware like NVIDIA Blackwell to reduce AI inference costs by up to 10x.
- No need to build your own GPU clusters; pay-as-you-go pricing is suitable for small to medium teams and individual developers.
Advantage 3: More Flexible Model Selection
Third-party platforms usually support both open-source and closed-source models, offering unified API interfaces and transparent pricing. This means:
- No Vendor Lock-in: Not tied to any single cloud service provider.
- Quick Switching: Call multiple models through one interface, compare results, and choose the best.
- Custom Optimization: Open-source models support quantization, fine-tuning, merging, and other custom operations.
💡 Selection Advice: For open-source models like Qwen3.5, third-party inference platforms might offer better deployment performance than Alibaba Cloud's official API. We recommend using the APIYI apiyi.com platform for actual testing and comparison. This platform aggregates multiple inference channels, automatically selecting the lowest latency path for you.
Quick Start Guide to Calling Open-Source Model APIs: 5-Minute Integration
This guide demonstrates how to quickly call open-source model APIs using a third-party platform, with Qwen3.5-Flash as an example.
Minimal Code Example
import openai
client = openai.OpenAI(
api_key="your-api-key",
base_url="https://api.apiyi.com/v1" # APIYI unified interface
)
response = client.chat.completions.create(
model="qwen3.5-flash",
messages=[
{"role": "user", "content": "Analyze the advantages of Qwen3.5's MoE architecture"}
]
)
print(response.choices[0].message.content)
View Full Code (with multi-model switching and error handling)
import openai
import time
# Initialize client - unified model calls via APIYI
client = openai.OpenAI(
api_key="your-api-key",
base_url="https://api.apiyi.com/v1"
)
# Supported model list
models = [
"qwen3.5-flash", # Alibaba Qwen3.5-Flash
"qwen3.5-plus", # Alibaba Qwen3.5-Plus
"glm-5", # Zhipu GLM-5
"kimi-k2.5", # Moonshot Kimi-K2.5
"minimax-m2.5", # MiniMax-M2.5
]
prompt = "Explain the advantages of MoE architecture in Large Language Model inference in 3 sentences"
for model_name in models:
try:
start = time.time()
response = client.chat.completions.create(
model=model_name,
messages=[{"role": "user", "content": prompt}],
max_tokens=500,
temperature=0.7
)
elapsed = time.time() - start
content = response.choices[0].message.content
print(f"\n[{model_name}] Time taken: {elapsed:.2f}s")
print(f"Response: {content[:200]}...")
except Exception as e:
print(f"\n[{model_name}] Call failed: {e}")
🚀 Get Started Quickly: We recommend using the APIYI apiyi.com platform to quickly test the models above. Register to receive free credits. A single API key allows you to call mainstream models like Qwen3.5, GLM-5, Kimi-K2.5, and MiniMax-M2.5 without registering on multiple platforms separately.
Recommended Model Calling Solutions for Different Scenarios
Choose the most suitable calling method based on your actual needs:
Scenario 1: Calling Closed-Source/Semi-Closed-Source Models
If you primarily use the closed-source versions of models like GLM-5, Kimi-K2.5 (not self-deployed), we recommend:
- First Choice: Direct connection to each official API for the lowest latency.
- Second Choice: Unified calling through aggregation platforms like APIYI apiyi.com, trading a small amount of latency for management convenience.
Scenario 2: Deploying Open-Source Models
If you are using open-source models like Qwen3.5, GLM-5 open-source version, MiniMax-M2.5 open-source version, etc.:
- Sufficient Budget: Opt for professional inference platforms like SiliconFlow or Together AI for optimal latency.
- Cost-Performance Priority: Use APIYI apiyi.com for aggregated calls, which automatically routes to the best channel.
- Full Control: Build your own inference service using vLLM or SGLang, which requires your own GPU resources.
Scenario 3: Multi-Model Comparison Testing
When you need to quickly compare the performance of multiple models during the early stages of development:
- Recommended: Use a unified API interface (like APIYI apiyi.com). Register once to switch and test multiple models.
- Avoid registering separate accounts and managing multiple API keys for each model.
💰 Cost Optimization Tip: For budget-sensitive projects, calling open-source model APIs through the APIYI apiyi.com platform is the most cost-effective solution. The platform offers flexible billing, and the cost of calling open-source models is significantly lower than the official pricing for closed-source models.
Frequently Asked Questions
Q1: Qwen3.5-Flash is advertised as a lightweight model, why is the API still slow?
Although Qwen3.5-Flash only activates 3 billion parameters per inference, it supports a 1 million token context window by default and natively integrates multimodal processing capabilities (text + image + video) and built-in tool calling. These "hidden costs" make its actual computing power consumption far higher than pure text models of the same parameter count. Coupled with the tight GPU resource situation on Alibaba Cloud, waiting times further increase perceived latency.
Q2: Will the performance of open-source models be compromised when deployed on third-party platforms?
No. Professional third-party inference platforms (like SiliconFlow, Together AI) use original open-source weights and optimized inference engines, resulting in performance consistent with the original developers, and often faster inference speeds. Through the APIYI apiyi.com platform, you can quickly compare the inference quality and speed of different channels to choose the optimal solution.
Q3: When will Alibaba Cloud’s computing power issues be alleviated?
According to public statements from Alibaba Cloud executives, the GPU supply shortage is expected to last for 2-3 years. In the short term, Alibaba Cloud is more inclined to improve the utilization of existing GPUs through resource pooling technologies like Aegaeon, rather than significant expansion. It's recommended that developers don't wait for platform optimizations but proactively choose more suitable invocation solutions – direct official API connections or third-party inference platforms are both viable alternatives. You can test the invocation speed of different models for free via APIYI apiyi.com.
Summary: Strategies to Address Slow Alibaba Cloud Qwen3.5 API Responses
The fundamental reason for the slow response of Alibaba Cloud's Qwen3.5 API is the global shortage of GPU computing power, compounded by factors such as the model architecture's high computational demand and contention for resources among multiple tenants. For stuttering issues when calling third-party models like GLM-5, Kimi-K2.5, and MiniMax-M2.5 through Alibaba Cloud, the underlying cause is the same – Alibaba Cloud prioritizes its own models for computing power, with third-party models receiving secondary resource allocation.
3 Core Recommendations:
- Direct Connection for Closed-Source Models: Use Zhipu AI's API for GLM-5, Moonshot AI's API for Kimi-K2.5, and MiniMax's API for MiniMax-M2.5 to avoid latency from intermediate forwarding layers.
- Third-Party Platforms for Open-Source Models: Open-source models like Qwen3.5 may perform better on professional inference platforms than on Alibaba Cloud's official API.
- Unified Management with Aggregation Platforms: If you need to use multiple models simultaneously, we recommend using APIYI apiyi.com to call all models through a single interface, balancing efficiency and management convenience.
The computing power shortage is expected to be the norm for the entire industry over the next 2-3 years. Instead of passively waiting for cloud platforms to expand capacity, it's better to proactively optimize your invocation strategy – choosing the most suitable combination of platforms and models is the best path to improving the AI application experience.
Author: APIYI Team | For more AI model API invocation tips, welcome to visit APIYI apiyi.com for the latest tutorials and free testing credits.
📚 References
-
Qwen3.5 Model Series Official Documentation: Alibaba Cloud Tongyi Qianwen Model Technical Specifications
- Link:
github.com/QwenLM/Qwen3.5 - Description: Contains complete model parameters, benchmarks, and usage guidelines.
- Link:
-
Alibaba Cloud Computing Power Price Adjustment Announcement: AI Computing Power Prices to Increase Starting April 2026
- Link:
www.alibabacloud.com - Description: Official explanation regarding the supply-demand imbalance for computing power.
- Link:
-
GLM-5 Technical Report: Technical Details of Zhipu AI's Flagship Model
- Link:
github.com/THUDM/GLM-5 - Description: Explanation of the 744 billion parameter MoE architecture and Agent mode.
- Link:
-
Kimi-K2.5 Official Documentation: Moonshot AI's Trillion-Parameter Model
- Link:
platform.moonshot.ai/docs/guide/kimi-k2-5-quickstart - Description: Guide to Agent Swarm functionality and API integration.
- Link:
-
MiniMax-M2.5 Technical Blog: In-depth Explanation of the Cutting-Edge Open-Source Model
- Link:
www.minimax.io/news/minimax-m25 - Description: Performance benchmarks, deployment recommendations, and cost analysis.
- Link: