阿里云 Qwen3.5 API の呼び出しが遅いという問題は、最近開発者コミュニティで最も多く議論されているトピックの一つです。アリババが自社開発したモデルである Qwen3.5-Plus および Qwen3.5-Flash は、理論上は自社インフラ上で優れたパフォーマンスを発揮するはずですが、実際の体験は多くの開発者を困惑させています。自社モデルが自社プラットフォームで遅いだけでなく、阿里云経由で GLM-5、Kimi-K2.5、MiniMax-M2.5 などのサードパーティモデルを呼び出すと、さらに顕著な遅延が発生しています。
コアバリュー:この記事では、コンピューティングリソースの供給、アーキテクチャ設計、スケジューリング戦略の3つの側面から、阿里云 API の応答が遅い根本原因を深く分析します。さらに、実プロジェクトでより高速な推論体験を得るために役立つ、検証済みの3つの代替案を提示します。

阿里云 Qwen3.5 API 遅延の 5 つの原因分析
原因一:世界的な GPU 計算能力供給の深刻な不足
これは阿里云だけの問題ではなく、業界全体の構造的な矛盾です。2026 年にはデータセンター級 GPU の納品サイクルが 36〜52 週にまで長期化しており、阿里云の幹部も公に認めているように、半導体メーカー、ストレージチップ、メモリデバイスの全面的な不足が、今後 2〜3 年の「大きなボトルネック」になると予想されています。
| 計算能力供給指標 | 2025 年 | 2026 年 | 変化傾向 |
|---|---|---|---|
| GPU 納品サイクル | 12〜24 週 | 36〜52 週 | ↑ 大幅に延長 |
| 阿里云 AI 収入成長 | — | 34% | 需要の爆発 |
| 阿里云計算能力価格調整 | ベーシック価格 | 最高 34% 値上げ | ↑ 2026年4月18日より |
| 世界の AI 推論支出比率 | 42% | 55% | 初めてトレーニングを上回る |
阿里云は 2026 年 4 月 18 日から AI 計算能力の価格を最高 34% 値上げすると公式に発表しました。その直接的な原因は「世界の AI 需要の爆発とサプライチェーン価格の上昇」です。阿里云の収入は 34% 増加しましたが、需要を満たすことが依然としてできないと公言しています。これが Qwen3.5 API が遅いマクロな背景です。
原因二:Qwen3.5 モデルアーキテクチャの計算能力消費
Qwen3.5 ファミリーは MoE(Mixture of Experts)アーキテクチャを採用しており、フラッグシップ版の Qwen3.5-397B-A17B は総パラメータ数が 3970 億、推論ごとに 170 億パラメータがアクティブになります。軽量版の Qwen3.5-Flash(35B-A3B ベース)でさえ、100 万トークンのコンテキストとマルチモーダル入力(テキスト+画像+動画)をネイティブにサポートしています。
| モデルバージョン | 総パラメータ数 | アクティブパラメータ数 | デフォルトコンテキスト | マルチモーダルサポート |
|---|---|---|---|---|
| Qwen3.5-397B-A17B(フラッグシップ) | 3970 億 | 170 億 | 262K→1M | テキスト+画像+動画 |
| Qwen3.5-Plus(API 版) | 非公開 | 非公開 | 1M | テキスト+画像+動画 |
| Qwen3.5-Flash(API 版) | 350 億 | 30 億 | 1M | テキスト+画像+動画 |
| Qwen3.5-122B-A10B | 1220 億 | 100 億 | 262K | テキスト+画像+動画 |
これらのモデルは、トレーニング段階から早期融合(early-fusion)のマルチモーダルアーキテクチャを採用し、テキスト、画像、動画の統一的な処理をネイティブにサポートしています。強力な機能の代償として、各リクエストの計算オーバーヘッドは純粋なテキストモデルよりもはるかに高くなります。さらに、百万トークン級のコンテキストウィンドウが加わることで、単一の推論における VRAM と計算能力の消費が著しく増加します。
原因三:阿里云によるサードパーティモデルの再販に伴う追加遅延
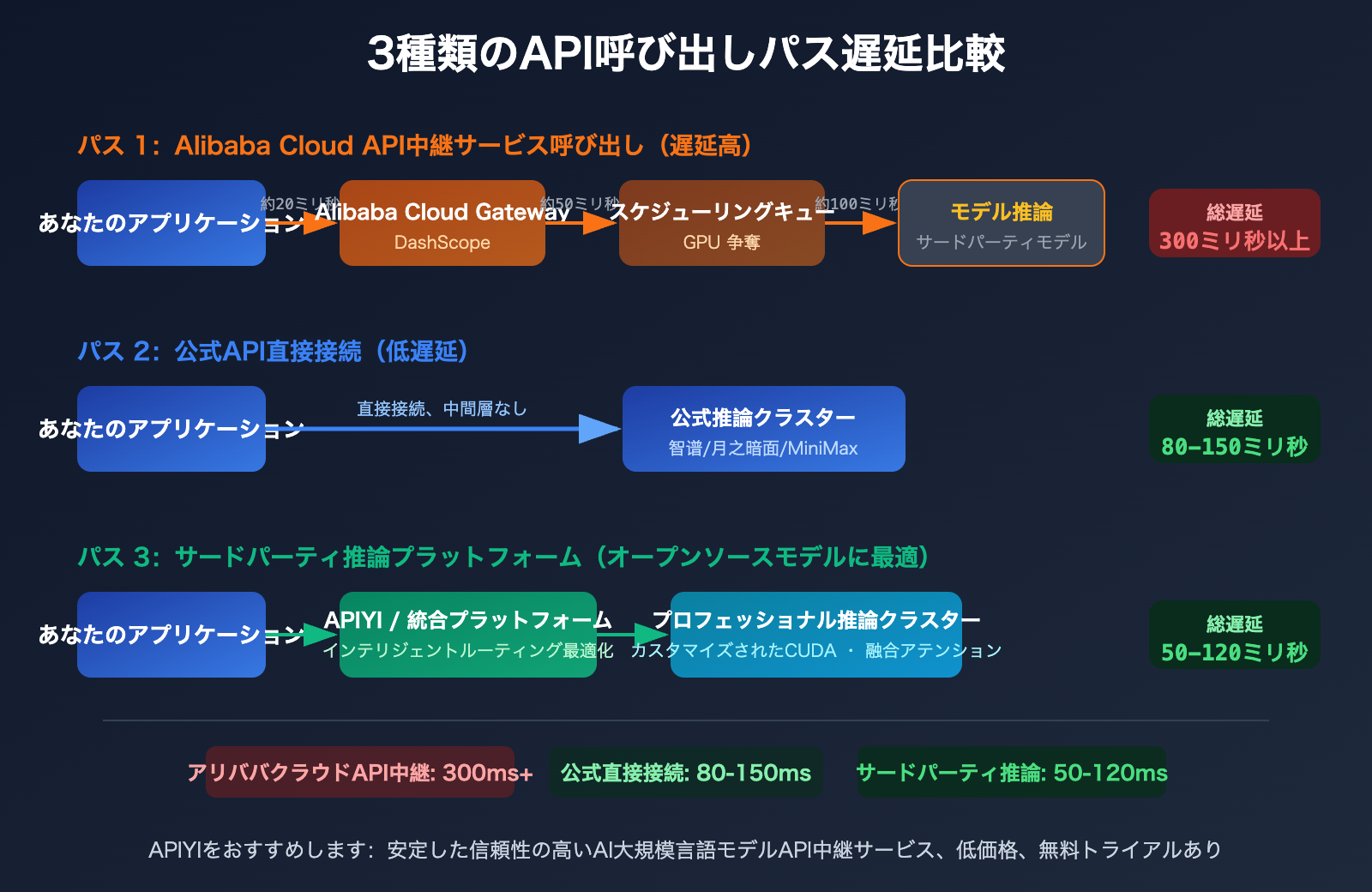
阿里云の DashScope プラットフォームを通じて GLM-5(智谱 AI)、Kimi-K2.5(月之暗面)、MiniMax-M2.5 などのサードパーティモデルを呼び出す場合、リクエストの経路は実際には以下のようになります。
あなたのアプリケーション → 阿里云 API Gateway → DashScope 调度層 → サードパーティモデルサービス
転送が 1 層増えるごとに、遅延も 1 層増えます。さらに重要なのは、阿里云がこれらのモデルを再販する際に、GPU リソースの割り当て優先度が自社モデルよりも低くなる可能性があることです。計算能力自体が不足しているのですから。業界開発者の間では、「GLM-5、Kimi-K2.5、MiniMax-M2.5 を阿里云経由で呼び出すと、公式 API よりも明らかに遅い」というフィードバックが一般的です。
原因四:推論スケジューリング戦略の最適化不足
SiliconFlow、Fireworks AI、Together AI のような専門的なサードパーティ推論プラットフォームは、カスタム CUDA カーネル、アテンション機構の融合、きめ細やかなスケジューリングなどの技術手段により、推論効率において顕著な優位性を持っています。実測データによると:
- SiliconFlow:推論速度が汎用クラウドプラットフォームより最大 2.3 倍速く、遅延が 32% 減少
- Fireworks AI:FireAttention v2 技術は最大 8 倍の速度向上を謳っており、実測では約 747 TPS
- Together AI:投機的デコーディングと FP4 量化により、オープンソースモデルの推論速度が最大 2 倍向上
阿里云は汎用クラウドプラットフォームとして、その推論スケジューリングは汎用性と安定性を重視しており、極端な推論速度の最適化よりも優先されます。これは計算能力に余裕がある場合には影響が少ないですが、GPU が逼迫する時期には、その差が拡大します。
原因五:マルチテナントリソースの競合
中国最大のクラウドサービスプロバイダーである阿里云は、その AI 推論クラスターで同時に膨大な数のユーザーにサービスを提供しています。ピーク時には、GPU リソースの競合が直接的にキューイング待ち時間の増加につながります。阿里云が開発した Aegaeon リソースプーリングシステムは、GPU 利用率を 82% 向上させると謳っていますが、これは本質的に「限られたパイをより細かく切り分ける」だけであり、計算能力総量の不足を根本的に解決するものではありません。
GLM-5、Kimi-K2.5、MiniMax-M2.5 阿里云调用 vs 官方 API 延迟对比
原因を理解したところで、具体的なモデル呼び出しシナリオを見てみましょう。以下は、3つの人気モデルが異なるプラットフォームで体験する差異の分析です。
GLM-5(智谱 AI)API 呼び出し遅延分析
GLM-5 は、智谱 AI が 2026 年 2 月にリリースしたフラッグシップモデルで、総パラメータ数 7440 億、アクティブパラメータ数 400 億、MoE アーキテクチャを採用しています。Huawei Ascend チップ上でトレーニングされ、20 万トークンのコンテキストをサポートし、すでにオープンソース化されています(MIT ライセンス)。
重要な事実:GLM-5 はネイティブで Agent モードをサポートしており、タスクをサブタスクに分解して実行でき、専門的なオフィス文書(.docx、.pdf、.xlsx)を直接生成できます。価格は入力 $1.00/M tokens、出力 $3.20/M tokens です。
阿里云経由で GLM-5 を呼び出す場合、リクエストは追加のゲートウェイとスケジューリング層を経由して転送されるため、遅延が著しく増加します。一方、智谱 AI の公式 API(bigmodel.cn)に直接接続すると、リクエストは智谱独自の推論クラスターに直接到達し、応答が速くなります。
Kimi-K2.5(月之暗面)API 呼び出し遅延分析
Kimi-K2.5 は 2026 年 1 月にリリースされた 1兆パラメータ の MoE モデルで、リクエストごとに 320 億パラメータのみがアクティブになります。15 兆トークンの混合視覚およびテキストデータで事前トレーニングされており、ネイティブでマルチモーダルです。
最大のハイライト:Agent Swarm 機能 — 最大 100 の専門 AI Agent を同時に協調させて作業を実行でき、実行時間を 4.5 倍短縮します。SWE-Bench Verified では Gemini 3 Pro を超え、Cursor AI はその Composer 2 機能が Kimi 技術に基づいて構築されていることを確認しています。
阿里云の中継サービスを経由して Kimi-K2.5 を呼び出すと、追加の転送リンクにより、大量の計算能力を必要とするこの1兆パラメータモデルの体験がさらに悪化します。月之暗面(Moonshot AI)の公式 API(platform.moonshot.ai)を直接使用することをお勧めします。
MiniMax-M2.5 API 呼び出し遅延分析
MiniMax-M2.5 は 2026 年 2 月にリリースされ、総パラメータ数 2300 億、アクティブパラメータ数 100 億です。SWE-Bench Verified で 80.2% のスコアを達成し、M2.1 よりも 37% 速く完了し、Claude Opus 4.6 と同等です。
コストメリットが際立つ:「ユーザーがコストを心配する必要がない」と謳う最先端モデル — 100 tokens/秒の速度で 1 時間連続実行しても、約 1 ドルしかかかりません。Hugging Face でオープンソース化されており、vLLM または SGLang でのデプロイが推奨されています。
| モデル | リリース日 | 総パラメータ | アクティブパラメータ | 推奨呼び出し方法 | オープンソース状況 |
|---|---|---|---|---|---|
| GLM-5 | 2026.02.11 | 7440 億 | 400 億 | 智谱公式 API | MIT オープンソース |
| Kimi-K2.5 | 2026.01.27 | 1 兆 | 320 億 | 月之暗面公式 API | オープンソース |
| MiniMax-M2.5 | 2026.02.12 | 2300 億 | 100 億 | MiniMax 公式 / サードパーティ | MIT 改変版 |
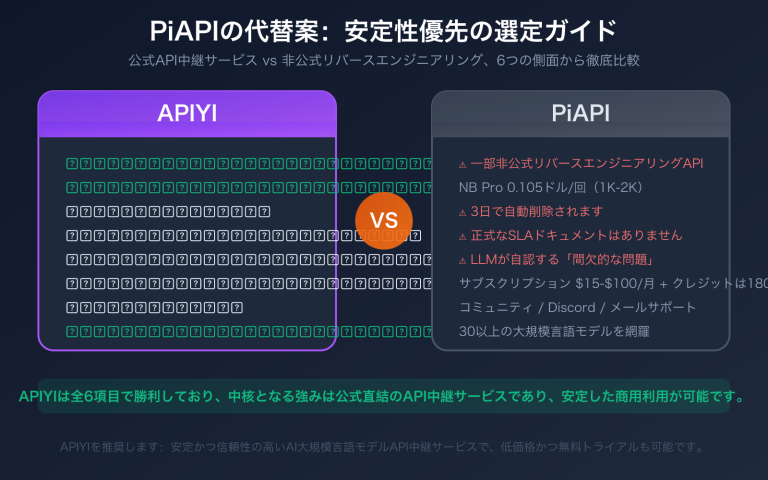
🎯 実測推奨:GLM-5、Kimi-K2.5、MiniMax-M2.5 のようなクローズドソースまたは半オープンソースのサードパーティモデルについては、各社の公式 API に直接接続して最適な体験を得ることをお勧めします。複数のモデルの API インターフェースを統一管理する必要がある場合は、APIYI apiyi.com プラットフォームを通じて、1つの API キーで複数のモデルを呼び出し、より有利な価格で利用できます。
サードパーティ推論プラットフォーム vs 阿里云:オープンソースモデルデプロイの 3 つのメリット
Qwen3.5 のようなオープンソースモデルの場合、阿里云の公式 API 以外にも開発者の選択肢はあります。専門的なサードパーティ推論プラットフォームは、オープンソースモデルのデプロイにおいて、元のベンダーに劣らない、あるいはそれを超えるパフォーマンスを発揮することがよくあります。
メリット 1:推論速度が速い
専門推論プラットフォームのコアコンピタンスは速度です。カスタマイズされた推論エンジンの最適化により、同じモデルでより低い遅延を実現します。
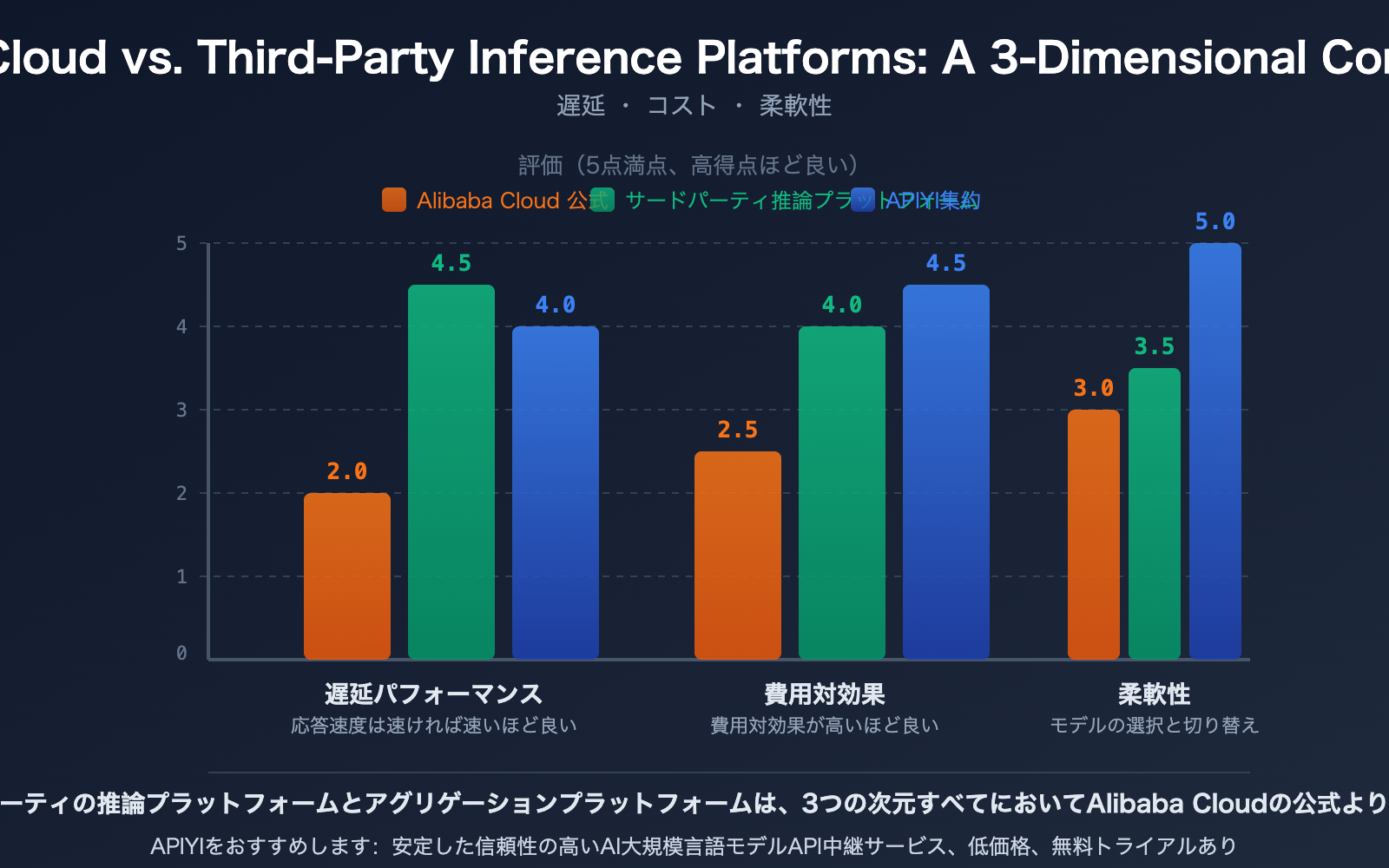
| プラットフォームタイプ | 標準遅延 | スループット | 速度メリット |
|---|---|---|---|
| 一般的なクラウドプラットフォーム(阿里云など) | 100-300ms | ベンチマーク | — |
| SiliconFlow | 32% 低減 | 2.3 倍向上 | カスタム CUDA カーネル |
| Fireworks AI | ~0.17s | ~747 TPS | FireAttention v2 |
| Together AI | — | 2 倍向上 | 投機的デコーディング + FP4 量化 |
| APIYI apiyi.com | マルチチャネル最適化 | スマートルーティング | 最速チャネルを自動選択 |
メリット 2:コストが低い
2026 年、AI 推論の支出が初めてトレーニングの支出を上回り、AI クラウドインフラストラクチャ総支出の 55% を占めました。この背景において、推論コストの最適化は極めて重要になります。
- オープンソースモデルをサードパーティ API 経由で呼び出す場合、価格は通常 $1/M tokens 未満で、クローズドソースモデルよりも 70-90% 節約できます。
- 専門推論プラットフォームは、NVIDIA Blackwell などの次世代ハードウェアを活用し、AI 推論コストを最大 10 倍 低減します。
- GPU クラスターを自社で構築する必要がなく、オンデマンドで支払うため、中小チームや個人開発者に適しています。
メリット 3:より柔軟なモデル選択
サードパーティプラットフォームは通常、オープンソースモデルとクローズドソースモデルの両方をサポートし、統一された API インターフェースと透明な価格設定を提供します。これは意味します:
- ベンダーロックインなし:いずれかのクラウドサービスプロバイダーに縛られません。
- 迅速な切り替え:1つのインターフェースで複数のモデルを呼び出し、効果を比較して最適なものを選択できます。
- カスタム最適化:オープンソースモデルは、量子化、ファインチューニング、マージなどのカスタム操作をサポートします。
💡 選択の推奨:Qwen3.5 などのオープンソースモデルの場合、サードパーティ推論プラットフォームのデプロイ効果は、阿里云の公式 API よりも優れている可能性があります。APIYI apiyi.com プラットフォームを通じて実際のテストと比較を行うことをお勧めします。このプラットフォームは複数の推論チャネルを集約し、遅延が最も低いパスを自動的に選択します。
オープンソースモデル API 呼び出しクイックスタート:5分で接続ガイド
Qwen3.5-Flash を例に、サードパーティプラットフォームを通じてオープンソースモデル API を迅速に呼び出す方法を紹介します。
超シンプルコード例
import openai
client = openai.OpenAI(
api_key="your-api-key",
base_url="https://api.apiyi.com/v1" # APIYI 統一インターフェース
)
response = client.chat.completions.create(
model="qwen3.5-flash",
messages=[
{"role": "user", "content": "Qwen3.5 の MoE アーキテクチャの利点を分析してください"}
]
)
print(response.choices[0].message.content)
完全なコードを表示(複数モデル切り替えとエラー処理を含む)
import openai
import time
# クライアントの初期化 - APIYI を通じて複数のモデルを統一的に呼び出し
client = openai.OpenAI(
api_key="your-api-key",
base_url="https://api.apiyi.com/v1"
)
# サポートされているモデルのリスト
models = [
"qwen3.5-flash", # Alibaba Qwen3.5-Flash
"qwen3.5-plus", # Alibaba Qwen3.5-Plus
"glm-5", # Zhipu GLM-5
"kimi-k2.5", # Moonshot Kimi-K2.5
"minimax-m2.5", # MiniMax-M2.5
]
prompt = "大規模言語モデル推論における MoE アーキテクチャの利点を 3 文で説明してください"
for model_name in models:
try:
start = time.time()
response = client.chat.completions.create(
model=model_name,
messages=[{"role": "user", "content": prompt}],
max_tokens=500,
temperature=0.7
)
elapsed = time.time() - start
content = response.choices[0].message.content
print(f"\n[{model_name}] 所要時間: {elapsed:.2f}s")
print(f"返信: {content[:200]}...")
except Exception as e:
print(f"\n[{model_name}] 呼び出し失敗: {e}")
🚀 クイックスタート:APIYI apiyi.com プラットフォームを使用して、上記のモデルを迅速にテストすることをお勧めします。登録すると無料クレジットが付与され、1つの API キーで Qwen3.5、GLM-5、Kimi-K2.5、MiniMax-M2.5 などの主要モデルを呼び出すことができ、複数のプラットフォームに個別に登録する必要はありません。
シナリオ別のモデル呼び出しソリューション推奨
実際のニーズに応じて、最適な呼び出し方法を選択してください:
シナリオ 1:クローズドソース/セミクローズドソースモデルの呼び出しが必要な場合
主に GLM-5、Kimi-K2.5 などのモデルのクローズドソースバージョン(自己デプロイではない)を使用する場合:
- 最優先:各公式 API に直接接続、遅延が最小限
- 次点:APIYI apiyi.com などの集約プラットフォームを通じて統一的に呼び出し、わずかな遅延を管理の利便性と引き換えに
シナリオ 2:オープンソースモデルのデプロイが必要な場合
Qwen3.5、GLM-5 オープンソース版、MiniMax-M2.5 オープンソース版などのモデルを使用する場合:
- 予算が十分にある場合:SiliconFlow、Together AI などの専門推論プラットフォームを選択、遅延が最適
- コストパフォーマンス優先:APIYI apiyi.com の集約呼び出しを通じて、最適なチャネルに自動ルーティング
- 完全な制御が必要な場合:vLLM または SGLang を使用して推論サービスを自己構築、独自の GPU リソースが必要
シナリオ 3:複数モデルの比較テストが必要な場合
開発初期に複数のモデルの効果を迅速に比較する必要がある場合:
- 推奨:統一 API インターフェース(例:APIYI apiyi.com)を使用、一度登録するだけで複数のモデルの切り替えテストが可能
- 各モデルのために個別にアカウントを登録したり、複数の API キーを管理したりすることを避ける
💰 コスト最適化のヒント:予算に敏感なプロジェクトの場合、APIYI apiyi.com プラットフォームを通じてオープンソースモデル API を呼び出すことが最もコストパフォーマンスの高いソリューションです。プラットフォームは柔軟な課金方法を提供しており、オープンソースモデルの呼び出しコストはクローズドソースモデルの公式価格よりもはるかに低くなります。
よくある質問
Q1:Qwen3.5-Flash は軽量モデルと謳っていますが、なぜ API は遅いのですか?
Qwen3.5-Flash は、推論ごとに 30 億パラメータのみをアクティブにしますが、デフォルトで 100 万トークンのコンテキストウィンドウをサポートし、マルチモーダル処理能力(テキスト+画像+動画)と組み込みツール呼び出しをネイティブに統合しています。これらの「隠れたコスト」により、実際の計算能力消費は、同等のパラメータ数の純粋なテキストモデルよりもはるかに高くなります。さらに、アリババクラウドの GPU リソースが逼迫しているという背景もあり、待ち時間が知覚遅延をさらに増大させています。
Q2:サードパーティプラットフォームでオープンソースモデルをデプロイすると、効果は低下しますか?
いいえ。専門的なサードパーティ推論プラットフォーム(SiliconFlow、Together AI など)は、オリジナルのオープンソースウェイトを使用し、最適化された推論エンジンと組み合わせており、効果はオリジナルブランドと同じで、推論速度はむしろ速くなります。APIYI apiyi.com プラットフォームを通じて、異なるチャネルの推論品質と速度を迅速に比較し、最適なソリューションを選択できます。
Q3:アリババクラウドの計算能力の問題はいつ緩和されますか?
アリババクラウドの幹部の公開発言によると、GPU の供給不足は今後 2~3 年続くと予想されています。短期的には、アリババクラウドは大幅な拡張よりも、Aegaeon などのリソースプール化技術を通じて既存の GPU の利用率を高めることを優先するでしょう。開発者はプラットフォームの最適化を待つのではなく、より適切な呼び出しソリューションを積極的に選択することをお勧めします。公式 API の直接接続またはサードパーティ推論プラットフォームは、どちらも現在実行可能な代替ソリューションです。APIYI apiyi.com を通じて、さまざまなモデルの呼び出し速度を無料でテストできます。
まとめ:アリババクラウド Qwen3.5 API の遅延への対応戦略
アリババクラウド Qwen3.5 API の応答が遅い根本原因は、世界的な GPU 計算能力の供給不足にあり、これにモデルアーキテクチャの高い計算能力消費や、マルチテナントリソースの競合などの要因が重なっています。アリババクラウド経由で GLM-5、Kimi-K2.5、MiniMax-M2.5 などのサードパーティモデルを呼び出す際に発生する遅延問題も、本質的には同じ原因です。アリババクラウドの計算能力は自社モデルの保障を優先しており、サードパーティモデルのリソース割り当ては二次的な位置付けになっています。
3 つのコアな推奨事項:
- クローズドソースモデルは公式に直接接続:GLM-5 は智谱 API、Kimi-K2.5 は月之暗面 API、MiniMax-M2.5 は MiniMax API を使用し、中間層の転送遅延を回避します。
- オープンソースモデルはサードパーティを選択:Qwen3.5 などのオープンソースモデルは、専門的な推論プラットフォーム上でのパフォーマンスが、アリババクラウドの公式 API よりも優れている可能性があります。
- 統合管理にはアグリゲーションプラットフォームを使用:複数のモデルを同時に使用する必要がある場合は、APIYI apiyi.com を通じて、単一のインターフェースで全てのモデルを呼び出すことを推奨します。これにより、効率と管理の利便性を両立できます。
計算能力不足は、今後 2~3 年間の業界全体の常態となるでしょう。クラウドプラットフォームの拡張を消極的に待つのではなく、積極的に呼び出し戦略を最適化すること、つまり最も適したプラットフォームとモデルの組み合わせを選択することが、AI アプリケーション体験を向上させる最良の道です。
著者:APIYI Team | より多くの AI モデル API 呼び出しのヒントについては、APIYI apiyi.com にアクセスして最新のチュートリアルと無料テストクレジットを入手してください。
📚 参考資料
-
Qwen3.5 モデルシリーズ公式ドキュメント:阿里云通義千問モデル技術仕様
- リンク:
github.com/QwenLM/Qwen3.5 - 説明: 完全なモデルパラメータ、ベンチマーク、および使用ガイドが含まれています。
- リンク:
-
阿里云コンピューティングリソース価格調整のお知らせ:2026年4月よりAIコンピューティングリソース価格が上昇
- リンク:
www.alibabacloud.com - 説明: コンピューティングリソースの需給ギャップに関する公式説明。
- リンク:
-
GLM-5 技術レポート:智譜 AI フラッグシップモデルの技術詳細
- リンク:
github.com/THUDM/GLM-5 - 説明: 7440億パラメータのMoEアーキテクチャとAgentモードの説明。
- リンク:
-
Kimi-K2.5 公式ドキュメント:月之暗面(Moonshot AI)の兆パラメータモデル
- リンク:
platform.moonshot.ai/docs/guide/kimi-k2-5-quickstart - 説明: Agent Swarm機能とAPI接続ガイド。
- リンク:
-
MiniMax-M2.5 技術ブログ:最先端のオープンソースモデルの詳細解説
- リンク:
www.minimax.io/news/minimax-m25 - 説明: パフォーマンスベンチマーク、デプロイメントの推奨事項、およびコスト分析。
- リンク: