L'appel aux API Qwen3.5 d'Alibaba Cloud est lent, c'est l'un des sujets les plus discutés dans la communauté des développeurs ces derniers temps. En tant que modèle développé en interne par Alibaba, Qwen3.5-Plus et Qwen3.5-Flash devraient théoriquement offrir d'excellentes performances sur leur propre infrastructure de calcul. Cependant, l'expérience réelle a laissé de nombreux développeurs perplexes : les modèles maison sont lents sur leur propre plateforme, et l'appel à des modèles tiers comme GLM-5, Kimi-K2.5, MiniMax-M2.5 via Alibaba Cloud est encore plus lent.
Valeur principale : Cet article analyse en profondeur les causes fondamentales de la lenteur des réponses des API Alibaba Cloud sous 3 angles : l'offre de calcul, la conception de l'architecture et la stratégie de planification. Il propose également 3 solutions alternatives éprouvées pour vous aider à obtenir une expérience d'inférence plus rapide dans vos projets réels.
Analyse des 5 principales raisons de la lenteur de l'API Qwen3.5 d'Alibaba Cloud
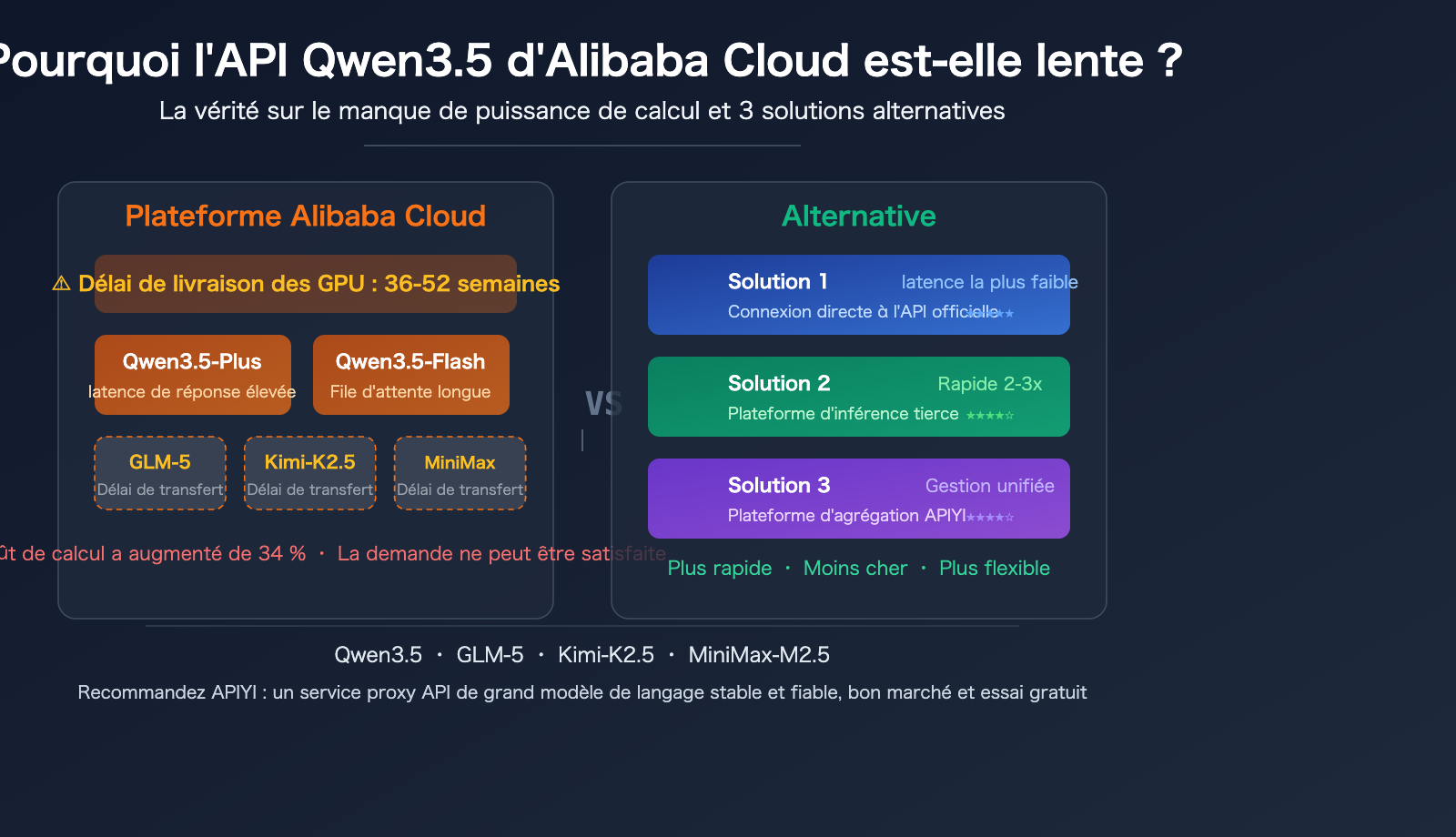
Raison 1 : Pénurie mondiale sévère de l'offre de puissance de calcul GPU
Il ne s'agit pas seulement d'un problème pour Alibaba Cloud, mais d'une contradiction structurelle dans l'ensemble de l'industrie. Les délais de livraison des GPU de niveau centre de données en 2026 ont été prolongés à 36-52 semaines. Les dirigeants d'Alibaba Cloud l'ont publiquement reconnu : les fabricants de semi-conducteurs, les puces de stockage et les composants de mémoire sont en pénurie généralisée, et l'offre deviendra un "goulot d'étranglement majeur" au cours des 2 à 3 prochaines années.
| Indicateur d'approvisionnement en puissance de calcul | 2025 | 2026 | Tendance d'évolution |
|---|---|---|---|
| Délai de livraison des GPU | 12-24 semaines | 36-52 semaines | ↑ Prolongation significative |
| Croissance des revenus IA d'Alibaba Cloud | — | 34 % | Explosion de la demande |
| Ajustement des prix de la puissance de calcul d'Alibaba Cloud | Prix de référence | Augmentation jusqu'à 34 % | ↑ À partir du 18 avril 2026 |
| Part des dépenses mondiales d'inférence IA | 42 % | 55 % | Dépasse pour la première fois l'entraînement |
Alibaba Cloud a officiellement annoncé qu'elle augmenterait les prix de sa puissance de calcul IA à partir du 18 avril 2026, avec une augmentation pouvant aller jusqu'à 34 %. La raison directe est "l'explosion de la demande mondiale d'IA et la hausse des prix de la chaîne d'approvisionnement". Bien que les revenus d'Alibaba Cloud aient augmenté de 34 %, elle a déclaré publiquement qu'elle ne pouvait toujours pas répondre à la demande, ce qui constitue le contexte macroéconomique de la lenteur de l'API Qwen3.5.
Raison 2 : Consommation de puissance de calcul de l'architecture du modèle Qwen3.5
La famille Qwen3.5 adopte une architecture MoE (Mixture of Experts). La version phare Qwen3.5-397B-A17B compte un total de 397 milliards de paramètres, activant 17 milliards de paramètres à chaque inférence. Même le Qwen3.5-Flash, positionné comme léger (basé sur 35B-A3B), prend en charge nativement une fenêtre de contexte de 1 million de tokens et des entrées multimodales (texte + image + vidéo).
| Version du modèle | Nombre total de paramètres | Nombre de paramètres activés | Contexte par défaut | Support multimodal |
|---|---|---|---|---|
| Qwen3.5-397B-A17B (Phare) | 397 milliards | 17 milliards | 262K → 1M | Texte + Image + Vidéo |
| Qwen3.5-Plus (Version API) | Non divulgué | Non divulgué | 1M | Texte + Image + Vidéo |
| Qwen3.5-Flash (Version API) | 35 milliards | 3 milliards | 1M | Texte + Image + Vidéo |
| Qwen3.5-122B-A10B | 122 milliards | 10 milliards | 262K | Texte + Image + Vidéo |
Ces modèles utilisent une architecture multimodale à fusion précoce (early-fusion) dès la phase d'entraînement, prenant en charge nativement le traitement unifié du texte, de l'image et de la vidéo. Le prix de cette fonctionnalité puissante est que la charge de calcul de chaque requête est beaucoup plus élevée que celle des modèles purement textuels. En ajoutant une fenêtre de contexte de plusieurs millions de tokens, l'utilisation de la mémoire et de la puissance de calcul lors d'une seule inférence augmente considérablement.
Raison 3 : Latence supplémentaire due à la revente de modèles tiers par Alibaba Cloud
Lors de l'appel de modèles tiers tels que GLM-5 (Zhipu AI), Kimi-K2.5 (Moonshot AI), MiniMax-M2.5 via la plateforme DashScope d'Alibaba Cloud, la chaîne de requête devient en fait :
Votre application → Passerelle API Alibaba Cloud → Couche de planification DashScope → Service de modèle tiers
Chaque couche de transfert supplémentaire ajoute de la latence. Plus important encore, lors de la revente de ces modèles, la priorité d'allocation des ressources GPU par Alibaba Cloud peut être inférieure à celle de ses propres modèles, car la puissance de calcul est déjà insuffisante. Les retours généraux des développeurs du secteur indiquent que : l'appel de GLM-5, Kimi-K2.5, MiniMax-M2.5 via Alibaba Cloud est nettement plus lent que via l'API officielle.
Raison 4 : Optimisation insuffisante de la stratégie de planification de l'inférence
Les plateformes d'inférence tierces spécialisées (telles que SiliconFlow, Fireworks AI, Together AI) ont des avantages significatifs en termes d'efficacité d'inférence grâce à des techniques telles que les noyaux CUDA personnalisés, la fusion des mécanismes d'attention et la planification à grain fin. Les données de test montrent que :
- SiliconFlow : La vitesse d'inférence est jusqu'à 2,3 fois plus rapide que celle des plateformes cloud générales, avec une latence réduite de 32 %.
- Fireworks AI : La technologie FireAttention v2 promet une augmentation de vitesse jusqu'à 8 fois, avec des tests montrant environ 747 TPS.
- Together AI : Grâce au décodage spéculatif et à la quantification FP4, la vitesse d'inférence des modèles open source est augmentée jusqu'à 2 fois.
En tant que plateforme cloud générale, Alibaba Cloud privilégie la généralité et la stabilité dans sa planification d'inférence, plutôt que l'optimisation extrême de la vitesse d'inférence. Cela a peu d'impact lorsque la puissance de calcul est abondante, mais l'écart s'amplifie lorsque les GPU sont rares.
Raison 5 : Concurrence pour les ressources multi-locataires
En tant que plus grand fournisseur de services cloud en Chine, Alibaba Cloud dessert des millions d'utilisateurs simultanément avec ses clusters d'inférence IA. Pendant les périodes de pointe, la concurrence pour les ressources GPU entraîne directement une augmentation du temps d'attente. Bien que le système de mise en pool de ressources Aegaeon développé par Alibaba Cloud affirme avoir augmenté l'utilisation des GPU de 82 %, il s'agit essentiellement de "couper un gâteau limité en plus petits morceaux" et ne résout pas fondamentalement le problème de la quantité totale insuffisante de puissance de calcul.

GLM-5、Kimi-K2.5、MiniMax-M2.5 : Comparaison de latence entre l'appel via Alibaba Cloud et l'API officielle
Une fois les raisons comprises, examinons les scénarios d'invocation de modèles spécifiques. Voici une analyse des différences d'expérience entre 3 modèles populaires sur différentes plateformes.
Analyse de la latence d'invocation de l'API GLM-5 (Zhipu AI)
GLM-5 est le modèle phare lancé par Zhipu AI en février 2026. Il compte 744 milliards de paramètres au total, avec 40 milliards de paramètres activés, et utilise une architecture MoE. Il a été entraîné sur des puces Ascend de Huawei, prend en charge une fenêtre de contexte de 200 000 tokens et est déjà open source (licence MIT).
Faits clés : GLM-5 prend en charge nativement le mode Agent, capable de décomposer automatiquement les tâches en sous-tâches pour exécution, et peut générer directement des documents professionnels (.docx, .pdf, .xlsx). Son prix est de 1,00 $/M tokens en entrée et de 3,20 $/M tokens en sortie.
Lors de l'invocation de GLM-5 via Alibaba Cloud, la requête doit transiter par des couches de passerelle et de planification supplémentaires, ce qui augmente considérablement la latence. En revanche, une connexion directe à l'API officielle de Zhipu AI (bigmodel.cn) permet aux requêtes d'atteindre directement les clusters d'inférence de Zhipu, offrant une réponse plus rapide.
Analyse de la latence d'invocation de l'API Kimi-K2.5 (Moonshot AI)
Kimi-K2.5, lancé en janvier 2026, est un modèle MoE de 1 trillion de paramètres, n'activant que 32 milliards de paramètres par requête. Il a été pré-entraîné sur 15 billions de tokens mixtes visuels et textuels et est nativement multimodal.
Point fort majeur : La fonction Agent Swarm – capable de coordonner simultanément jusqu'à 100 agents IA spécialisés pour travailler ensemble, réduisant le temps d'exécution de 4,5 fois. Il surpasse Gemini 3 Pro sur SWE-Bench Verified, et Cursor AI a confirmé que sa fonction Composer 2 est basée sur la technologie Kimi.
L'invocation de Kimi-K2.5 via le service proxy API de Alibaba Cloud, avec sa chaîne de transfert supplémentaire, dégrade l'expérience de ce modèle d'un trillion de paramètres qui nécessite déjà beaucoup de puissance de calcul. Il est recommandé d'utiliser directement l'API officielle de Moonshot AI (platform.moonshot.ai).
Analyse de la latence d'invocation de l'API MiniMax-M2.5
MiniMax-M2.5, lancé en février 2026, compte 230 milliards de paramètres au total, avec 10 milliards de paramètres activés. Il a obtenu un score de 80,2 % sur SWE-Bench Verified, avec une vitesse d'exécution 37 % plus rapide que M2.1, à égalité avec Claude Opus 4.6.
Avantage de coût exceptionnel : Il se présente comme le premier modèle de pointe "où les utilisateurs n'ont pas à se soucier du coût" – fonctionner en continu à 100 tokens/seconde pendant 1 heure ne coûte qu'environ 1 dollar. Il est open source sur Hugging Face, et son déploiement est recommandé avec vLLM ou SGLang.
| Modèle | Date de sortie | Paramètres totaux | Paramètres activés | Méthode d'invocation recommandée | Statut open source |
|---|---|---|---|---|---|
| GLM-5 | 2026.02.11 | 744 milliards | 40 milliards | API officielle Zhipu | Open source MIT |
| Kimi-K2.5 | 2026.01.27 | 1 trillion | 32 milliards | API officielle Moonshot | Open source |
| MiniMax-M2.5 | 2026.02.12 | 230 milliards | 10 milliards | Officiel MiniMax / Tiers | MIT modifié |
🎯 Recommandation pratique : Pour les modèles tiers fermés ou semi-ouverts comme GLM-5, Kimi-K2.5, MiniMax-M2.5, il est recommandé de se connecter directement aux API officielles de chaque fournisseur pour une expérience optimale. Si vous avez besoin de gérer de manière centralisée les interfaces API de plusieurs modèles, vous pouvez utiliser la plateforme APIYI apiyi.com pour appeler plusieurs modèles avec une seule clé API, tout en bénéficiant de meilleurs prix.
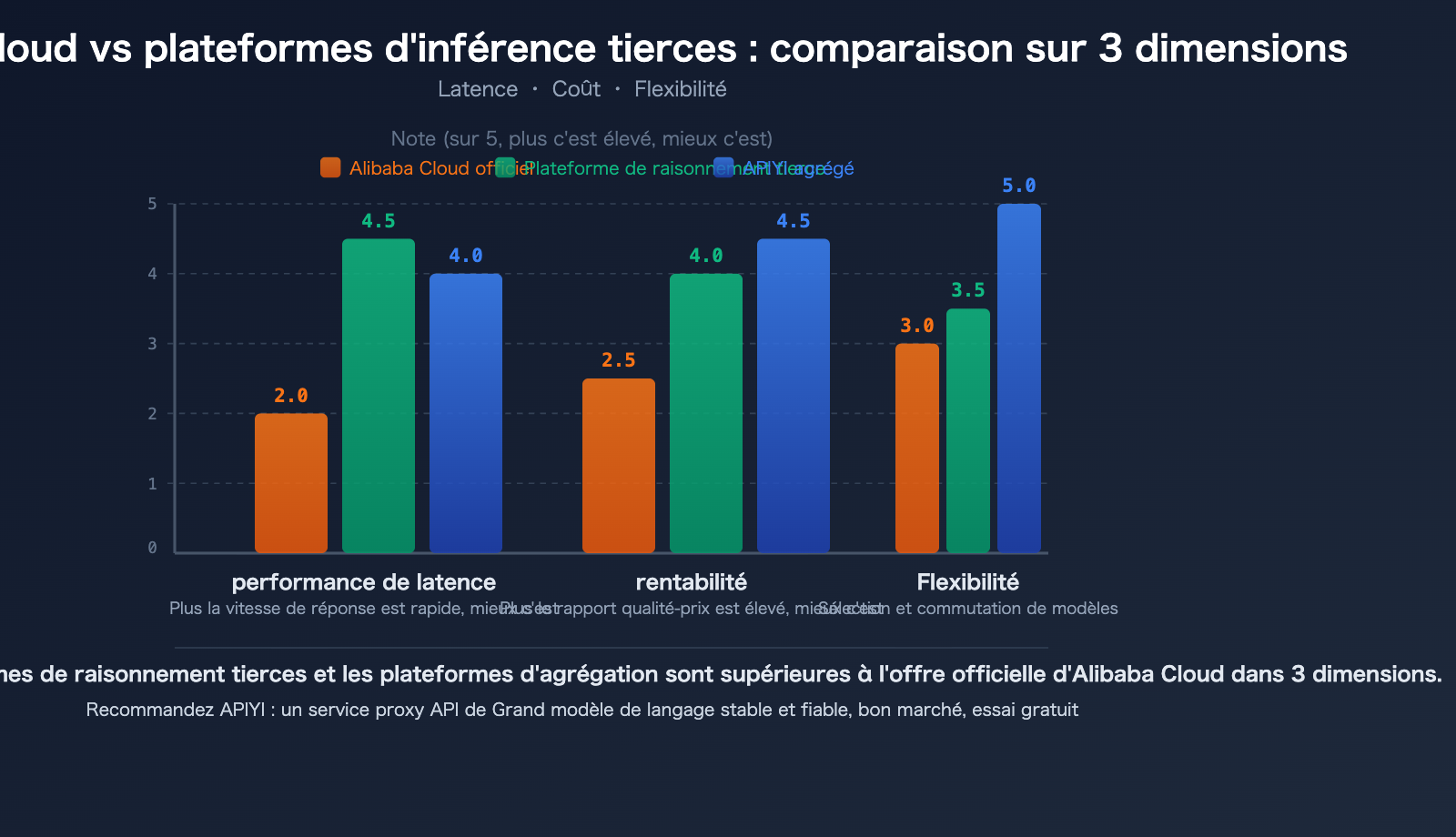
Plateformes d'inférence tierces vs Alibaba Cloud : 3 avantages majeurs pour le déploiement de modèles open source
Pour les modèles open source comme Qwen3.5, les développeurs disposent de plus d'options que l'API officielle d'Alibaba Cloud. Les plateformes d'inférence tierces spécialisées offrent souvent des performances égales, voire supérieures, à celles du fournisseur d'origine pour le déploiement de modèles open source.
Avantage 1 : Vitesse d'inférence plus rapide
La vitesse est la principale force concurrentielle des plateformes d'inférence spécialisées. Grâce à l'optimisation de moteurs d'inférence personnalisés, elles atteignent une latence plus faible sur les mêmes modèles :
| Type de plateforme | Latence typique | Débit | Avantage de vitesse |
|---|---|---|---|
| Plateforme cloud générique (Alibaba Cloud, etc.) | 100-300 ms | Référence | — |
| SiliconFlow | Réduction de 32 % | Augmentation de 2,3x | Noyaux CUDA personnalisés |
| Fireworks AI | ~0,17 s | ~747 TPS | FireAttention v2 |
| Together AI | — | Augmentation de 2x | Décodage spéculatif + quantification FP4 |
| APIYI apiyi.com | Optimisation multi-canaux | Routage intelligent | Sélection automatique du canal le plus rapide |
Avantage 2 : Coût inférieur
En 2026, les dépenses d'inférence IA dépasseront pour la première fois les dépenses d'entraînement, représentant 55 % des dépenses totales d'infrastructure cloud pour l'IA. Dans ce contexte, l'optimisation des coûts d'inférence devient cruciale :
- L'appel de modèles open source via des API tierces coûte généralement moins de 1 $/M tokens, permettant d'économiser 70-90 % par rapport aux modèles fermés.
- Les plateformes d'inférence spécialisées utilisent du matériel de nouvelle génération comme NVIDIA Blackwell pour réduire les coûts d'inférence IA jusqu'à 10 fois.
- Pas besoin de construire son propre cluster GPU, paiement à l'usage, adapté aux petites et moyennes équipes ainsi qu'aux développeurs individuels.
Avantage 3 : Choix de modèles plus flexible
Les plateformes tierces prennent généralement en charge à la fois les modèles open source et fermés, offrant une interface API unifiée et une tarification transparente. Cela signifie :
- Pas de verrouillage fournisseur : Pas de dépendance à l'égard d'un fournisseur de services cloud spécifique.
- Changement rapide : Appel de plusieurs modèles via une seule interface, comparaison des performances pour choisir le meilleur.
- Optimisation personnalisée : Les modèles open source prennent en charge des opérations personnalisées telles que la quantification, le réglage fin et la fusion.
💡 Conseil de choix : Pour les modèles open source comme Qwen3.5, les performances de déploiement des plateformes d'inférence tierces peuvent être meilleures que celles de l'API officielle d'Alibaba Cloud. Nous vous recommandons de tester et de comparer via la plateforme APIYI apiyi.com, qui agrège plusieurs canaux d'inférence et sélectionne automatiquement le chemin le plus rapide pour vous.
Appel rapide aux API de modèles open source : Guide de démarrage en 5 minutes
Prenons Qwen3.5-Flash comme exemple pour montrer comment appeler rapidement les API de modèles open source via une plateforme tierce.
Exemple de code ultra-simple
import openai
client = openai.OpenAI(
api_key="your-api-key",
base_url="https://api.apiyi.com/v1" # Interface unifiée APIYI
)
response = client.chat.completions.create(
model="qwen3.5-flash",
messages=[
{"role": "user", "content": "Analyser les avantages de l'architecture MoE de Qwen3.5"}
]
)
print(response.choices[0].message.content)
Voir le code complet (avec commutation multi-modèles et gestion des erreurs)
import openai
import time
# Initialiser le client - Appel unifié de plusieurs modèles via APIYI
client = openai.OpenAI(
api_key="your-api-key",
base_url="https://api.apiyi.com/v1"
)
# Liste des modèles pris en charge
models = [
"qwen3.5-flash", # Alibaba Qwen3.5-Flash
"qwen3.5-plus", # Alibaba Qwen3.5-Plus
"glm-5", # Zhipu GLM-5
"kimi-k2.5", # Moonshot Kimi-K2.5
"minimax-m2.5", # MiniMax-M2.5
]
prompt = "Expliquez en 3 phrases les avantages de l'architecture MoE dans l'inférence des grands modèles de langage"
for model_name in models:
try:
start = time.time()
response = client.chat.completions.create(
model=model_name,
messages=[{"role": "user", "content": prompt}],
max_tokens=500,
temperature=0.7
)
elapsed = time.time() - start
content = response.choices[0].message.content
print(f"\n[{model_name}] Temps écoulé : {elapsed:.2f}s")
print(f"Réponse : {content[:200]}...")
except Exception as e:
print(f"\n[{model_name}] Appel échoué : {e}")
🚀 Démarrage rapide : Il est recommandé d'utiliser la plateforme APIYI apiyi.com pour tester rapidement les modèles ci-dessus. Des crédits gratuits sont offerts à l'inscription, et une seule clé API permet d'appeler des modèles majeurs tels que Qwen3.5, GLM-5, Kimi-K2.5, MiniMax-M2.5, sans avoir à s'inscrire séparément auprès de plusieurs plateformes.
Recommandations de solutions d'appel de modèles pour différents scénarios
Choisissez la méthode d'appel la plus adaptée à vos besoins réels :
Scénario 1 : Nécessité d'appeler des modèles fermés/semi-fermés
Si vous utilisez principalement les versions fermées (non auto-déployées) de modèles comme GLM-5, Kimi-K2.5, etc., il est recommandé de :
- Option préférée : Connexion directe aux API officielles de chaque fournisseur pour une latence minimale.
- Option secondaire : Utilisation de plateformes agrégées comme APIYI apiyi.com pour un appel unifié, en échange d'une légère augmentation de latence pour plus de commodité de gestion.
Scénario 2 : Nécessité de déployer des modèles open source
Si vous utilisez des modèles open source tels que Qwen3.5, GLM-5 version open source, MiniMax-M2.5 version open source, etc. :
- Budget suffisant : Choisissez des plateformes d'inférence spécialisées comme SiliconFlow, Together AI pour une latence optimale.
- Priorité au rapport qualité-prix : Utilisez l'agrégation d'APIYI apiyi.com pour un appel unifié, avec routage automatique vers le meilleur canal.
- Contrôle total : Utilisez vLLM ou SGLang pour construire votre propre service d'inférence, nécessitant vos propres ressources GPU.
Scénario 3 : Nécessité de tester et comparer plusieurs modèles
Lorsque vous avez besoin de comparer rapidement les performances de plusieurs modèles au début du développement :
- Recommandé : Utilisez une interface API unifiée (comme APIYI apiyi.com) pour vous inscrire une seule fois et basculer entre les tests de plusieurs modèles.
- Évitez de vous inscrire séparément pour chaque modèle et de gérer plusieurs clés API.
💰 Conseils d'optimisation des coûts : Pour les projets sensibles au budget, l'appel aux API de modèles open source via la plateforme APIYI apiyi.com est la solution la plus rentable. La plateforme offre des modes de facturation flexibles, et le coût d'appel des modèles open source est bien inférieur aux prix officiels des modèles fermés.
Foire aux questions
Q1 : Le modèle Qwen3.5-Flash est annoncé comme un modèle léger, pourquoi l’API est-elle quand même lente ?
Bien que Qwen3.5-Flash n'active que 3 milliards de paramètres par inférence, il prend en charge par défaut une fenêtre de contexte de 1 million de tokens et intègre nativement des capacités de traitement multimodal (texte + image + vidéo) ainsi que des appels d'outils intégrés. Ces "coûts cachés" font que sa consommation de puissance de calcul réelle est bien supérieure à celle des modèles purement textuels de taille de paramètres équivalente. De plus, dans le contexte général de la tension sur les ressources GPU d'Alibaba Cloud, le temps d'attente en file d'attente augmente encore la latence perçue.
Q2 : L’utilisation de modèles open source déployés sur des plateformes tierces réduit-elle les performances ?
Non. Les plateformes d'inférence tierces professionnelles (comme SiliconFlow, Together AI) utilisent les poids open source originaux, associés à des moteurs d'inférence optimisés. Les performances sont donc identiques à celles du constructeur, et la vitesse d'inférence est même plus rapide. La plateforme APIYI apiyi.com permet de comparer rapidement la qualité et la vitesse d'inférence de différents canaux pour choisir la solution optimale.
Q3 : Quand la pénurie de puissance de calcul d’Alibaba Cloud sera-t-elle résolue ?
Selon les déclarations publiques des dirigeants d'Alibaba Cloud, la pénurie d'approvisionnement en GPU devrait se poursuivre pendant 2 à 3 ans. À court terme, Alibaba Cloud privilégie l'amélioration de l'utilisation des GPU existants grâce à des technologies de mise en pool de ressources comme Aegaeon, plutôt qu'une expansion majeure. Il est conseillé aux développeurs de ne pas attendre l'optimisation de la plateforme, mais de choisir activement une solution d'appel plus adaptée : les API officielles directes ou les plateformes d'inférence tierces sont des alternatives viables à l'heure actuelle. Vous pouvez tester gratuitement la vitesse d'appel de différents modèles via APIYI apiyi.com.
Conclusion : Stratégies pour pallier la lenteur de l'API Qwen3.5 d'Alibaba Cloud
La raison fondamentale de la lenteur de réponse de l'API Qwen3.5 d'Alibaba Cloud est la pénurie mondiale de puissance de calcul GPU, combinée à la consommation élevée de puissance de calcul de l'architecture du modèle et à la concurrence pour les ressources entre plusieurs locataires. Pour les problèmes de ralentissement rencontrés lors de l'appel de modèles tiers tels que GLM-5, Kimi-K2.5, MiniMax-M2.5 via Alibaba Cloud, la cause est fondamentalement la même : Alibaba Cloud priorise ses propres modèles pour l'allocation de puissance de calcul, tandis que les modèles tiers sont relégués à une position secondaire.
3 recommandations clés :
- Connexion directe aux officiels pour les modèles propriétaires : Utilisez l'API Zhipu pour GLM-5, l'API Moonshot pour Kimi-K2.5, et l'API MiniMax pour MiniMax-M2.5, afin d'éviter la latence due aux intermédiaires.
- Choisir des tiers pour les modèles open source : Les modèles open source comme Qwen3.5 peuvent offrir de meilleures performances sur les plateformes d'inférence professionnelles que l'API officielle d'Alibaba Cloud.
- Utiliser une plateforme d'agrégation pour une gestion unifiée : Si vous devez utiliser plusieurs modèles simultanément, nous recommandons APIYI apiyi.com pour appeler tous les modèles via une seule interface, alliant efficacité et facilité de gestion.
La pénurie de puissance de calcul sera la norme pour l'ensemble de l'industrie au cours des 2 à 3 prochaines années. Plutôt que d'attendre passivement l'expansion des plateformes cloud, il est préférable d'optimiser activement votre stratégie d'appel : choisir la combinaison de plateformes et de modèles la plus adaptée est le meilleur moyen d'améliorer l'expérience de vos applications IA.
Auteur : Équipe APIYI | Pour plus d'astuces sur l'appel d'API de modèles IA, n'hésitez pas à visiter APIYI apiyi.com pour obtenir les derniers tutoriels et des crédits de test gratuits.
📚 Références
-
Documentation officielle de la série de modèles Qwen3.5 : Spécifications techniques des modèles Tongyi Qianwen d'Alibaba Cloud
- Lien :
github.com/QwenLM/Qwen3.5 - Description : Contient les paramètres complets du modèle, les benchmarks et les guides d'utilisation.
- Lien :
-
Annonce d'ajustement des prix de la puissance de calcul d'Alibaba Cloud : Augmentation des prix de la puissance de calcul IA à partir d'avril 2026.
- Lien :
www.alibabacloud.com - Description : Explication officielle du déséquilibre entre l'offre et la demande de puissance de calcul.
- Lien :
-
Rapport technique GLM-5 : Détails techniques du modèle phare de Zhipu AI.
- Lien :
github.com/THUDM/GLM-5 - Description : Explication de l'architecture MoE (Mixture of Experts) de 744 milliards de paramètres et du mode Agent.
- Lien :
-
Documentation officielle Kimi-K2.5 : Modèle à mille milliards de paramètres de Moonshot AI.
- Lien :
platform.moonshot.ai/docs/guide/kimi-k2-5-quickstart - Description : Guide sur la fonctionnalité Agent Swarm et l'intégration API.
- Lien :
-
Blog technique MiniMax-M2.5 : Analyse détaillée des modèles open source de pointe.
- Lien :
www.minimax.io/news/minimax-m25 - Description : Benchmarks de performance, conseils de déploiement et analyse des coûts.
- Lien :