A lentidão na invocação da API do Qwen3.5 da Alibaba Cloud (阿里云) é um dos tópicos mais discutidos na comunidade de desenvolvedores ultimamente. Como um modelo desenvolvido internamente pela Alibaba, o Qwen3.5-Plus e o Qwen3.5-Flash deveriam, teoricamente, ter um desempenho excelente em sua própria infraestrutura de computação. No entanto, a experiência real tem deixado muitos desenvolvedores confusos: o modelo da própria empresa roda devagar em sua própria plataforma, e chamar modelos de terceiros como GLM-5, Kimi-K2.5, MiniMax-M2.5 através da Alibaba Cloud resulta em lentidão ainda mais acentuada.
Valor Central: Este artigo analisará em profundidade as causas fundamentais da lentidão na resposta da API da Alibaba Cloud a partir de três perspectivas: fornecimento de capacidade computacional, design de arquitetura e estratégia de agendamento. Além disso, apresentaremos três soluções alternativas comprovadas para ajudá-lo a obter uma experiência de inferência mais rápida em seus projetos práticos.

Análise das 5 Principais Razões para a Lentidão da API Qwen3.5 da Alibaba Cloud
Razão 1: Grave Insuficiência no Fornecimento Global de Capacidade de GPU
Este não é um problema exclusivo da Alibaba Cloud, mas sim um conflito estrutural em toda a indústria. O ciclo de entrega de GPUs de nível de data center em 2026 já se estendeu para 36-52 semanas. Executivos da Alibaba Cloud admitiram publicamente que a escassez generalizada de fabricantes de semicondutores, chips de memória e dispositivos de memória tornará a cadeia de suprimentos um "grande gargalo" nos próximos 2-3 anos.
| Indicador de Fornecimento de Capacidade | 2025 | 2026 | Tendência de Mudança |
|---|---|---|---|
| Ciclo de Entrega de GPU | 12-24 semanas | 36-52 semanas | ↑ Prolongamento significativo |
| Crescimento da Receita de IA da Alibaba Cloud | — | 34% | Explosão da demanda |
| Ajuste de Preço da Capacidade da Alibaba Cloud | Preço base | Aumento de até 34% | ↑ A partir de 18 de abril de 2026 |
| Participação nos Gastos Globais de Inferência de IA | 42% | 55% | Ultrapassa o treinamento pela primeira vez |
A Alibaba Cloud já anunciou oficialmente que aumentará os preços da capacidade de IA a partir de 18 de abril de 2026, com um aumento de até 34%. A razão direta é a "explosão da demanda global de IA e o aumento dos preços da cadeia de suprimentos". Embora a receita da Alibaba Cloud tenha crescido 34%, eles declararam publicamente que ainda não conseguem atender à demanda – este é o pano de fundo macro para a lentidão da API Qwen3.5.
Razão 2: Consumo de Capacidade de Computação da Arquitetura do Modelo Qwen3.5
A família Qwen3.5 adota a arquitetura MoE (Mixture of Experts). A versão principal, Qwen3.5-397B-A17B, tem um total de 397 bilhões de parâmetros, ativando 17 bilhões de parâmetros a cada inferência. Mesmo o Qwen3.5-Flash, posicionado como leve (baseado em 35B-A3B), suporta nativamente uma janela de contexto de 1 milhão de tokens e entrada multimodal (texto + imagem + vídeo).
| Versão do Modelo | Parâmetros Totais | Parâmetros Ativados | Contexto Padrão | Suporte Multimodal |
|---|---|---|---|---|
| Qwen3.5-397B-A17B (Principal) | 397 bilhões | 17 bilhões | 262K→1M | Texto + Imagem + Vídeo |
| Qwen3.5-Plus (Versão API) | Não divulgado | Não divulgado | 1M | Texto + Imagem + Vídeo |
| Qwen3.5-Flash (Versão API) | 35 bilhões | 3 bilhões | 1M | Texto + Imagem + Vídeo |
| Qwen3.5-122B-A10B | 122 bilhões | 10 bilhões | 262K | Texto + Imagem + Vídeo |
Esses modelos utilizam uma arquitetura multimodal de fusão antecipada (early-fusion) desde a fase de treinamento, suportando nativamente o processamento unificado de texto, imagem e vídeo. O preço da funcionalidade poderosa é que o custo computacional de cada solicitação é muito maior do que o de modelos puramente textuais. Adicionando a isso a janela de contexto de nível de milhão de tokens, o uso de memória e capacidade de computação para inferência única aumenta significativamente.
Razão 3: Latência Adicional da Alibaba Cloud na Revenda de Modelos de Terceiros
Ao chamar modelos de terceiros como GLM-5 (Zhipu AI), Kimi-K2.5 (Moonshot AI) e MiniMax-M2.5 através da plataforma DashScope da Alibaba Cloud, o caminho da solicitação se torna:
Sua Aplicação → Gateway de API da Alibaba Cloud → Camada de Agendamento DashScope → Serviço de Modelo de Terceiros
Cada camada de retransmissão adiciona latência. Mais importante ainda, ao revender esses modelos, a prioridade de alocação de recursos de GPU da Alibaba Cloud pode ser menor do que para seus próprios modelos – afinal, a capacidade de computação em si é insuficiente. O feedback comum dos desenvolvedores do setor é que chamar GLM-5, Kimi-K2.5 e MiniMax-M2.5 através da Alibaba Cloud é visivelmente mais lento do que usar as APIs oficiais.
Razão 4: Otimização Insuficiente da Estratégia de Agendamento de Inferência
Plataformas de inferência de terceiros especializadas (como SiliconFlow, Fireworks AI, Together AI) possuem vantagens significativas em eficiência de inferência através de técnicas como núcleos CUDA personalizados, mecanismos de atenção fundidos e agendamento de granularidade fina. Dados de testes práticos mostram:
- SiliconFlow: Velocidade de inferência até 2,3 vezes mais rápida que plataformas de nuvem genéricas, com latência reduzida em 32%.
- Fireworks AI: A tecnologia FireAttention v2 afirma um aumento de velocidade de até 8 vezes, com testes práticos mostrando cerca de 747 TPS.
- Together AI: Aceleração de inferência de modelos de código aberto de até 2 vezes através de decodificação especulativa e quantização FP4.
A Alibaba Cloud, como uma plataforma de nuvem genérica, foca mais em universalidade e estabilidade em seu agendamento de inferência, em vez de otimização extrema de velocidade de inferência. Isso tem pouco impacto quando a capacidade de computação é abundante, mas a diferença é amplificada em tempos de escassez de GPU.
Razão 5: Disputa por Recursos em Ambientes Multi-Tenant
Como a maior provedora de serviços de nuvem na China, a Alibaba Cloud atende a um grande número de usuários simultaneamente em seus clusters de inferência de IA. Durante os horários de pico, a disputa por recursos de GPU leva diretamente a um aumento no tempo de espera. Embora o sistema de pooling de recursos Aegaeon desenvolvido pela Alibaba Cloud afirme ter aumentado a utilização de GPU em 82%, isso é essencialmente "cortar um bolo limitado em fatias mais finas" e não resolve fundamentalmente o problema da quantidade total insuficiente de capacidade de computação.
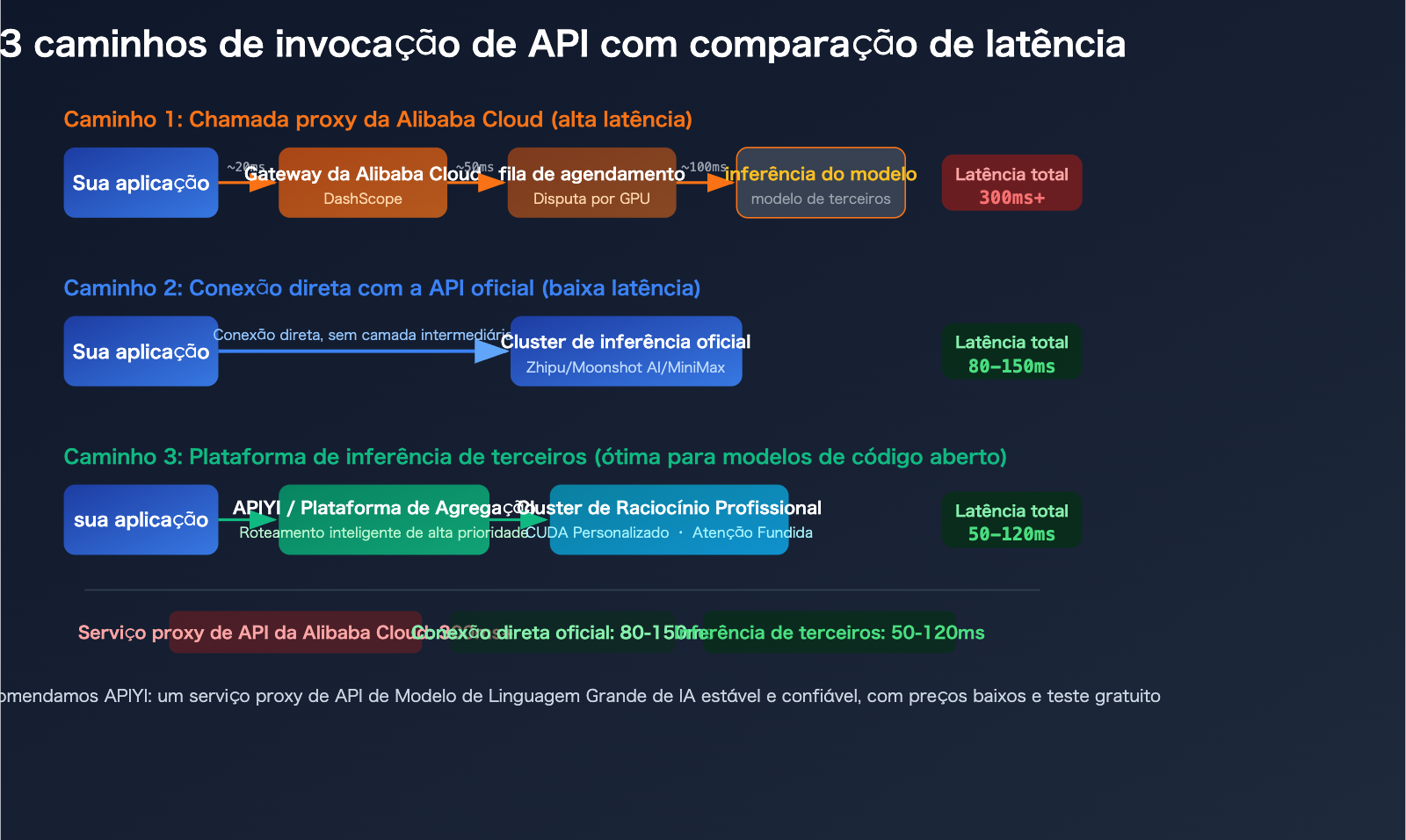
GLM-5、Kimi-K2.5、MiniMax-M2.5: Comparativo de Latência entre Chamada via Alibaba Cloud e API Oficial
Após entendermos os motivos, vamos analisar cenários específicos de invocação de modelos. Abaixo está uma análise das diferenças de experiência entre 3 modelos populares em diferentes plataformas.
Análise de Latência de Chamada da API GLM-5 (Zhipu AI)
GLM-5 é o modelo carro-chefe lançado pela Zhipu AI em fevereiro de 2026, com 744 bilhões de parâmetros totais e 40 bilhões de parâmetros ativados, utilizando uma arquitetura MoE. Ele foi treinado em chips Ascend da Huawei, suporta uma janela de contexto de 200.000 tokens e já é de código aberto (licença MIT).
Fatos Chave: GLM-5 suporta nativamente o modo Agente, podendo decompor tarefas em subtarefas para execução autônoma e gerar diretamente documentos de escritório profissionais (.docx, .pdf, .xlsx). Seu preço é de $1.00/M tokens para entrada e $3.20/M tokens para saída.
Ao chamar GLM-5 via Alibaba Cloud, a requisição precisa passar por camadas adicionais de gateway e agendamento, aumentando significativamente a latência. Por outro lado, ao conectar diretamente à API oficial da Zhipu AI (bigmodel.cn), a requisição chega diretamente ao cluster de inferência da Zhipu, resultando em uma resposta mais rápida.
Análise de Latência de Chamada da API Kimi-K2.5 (Moonshot AI)
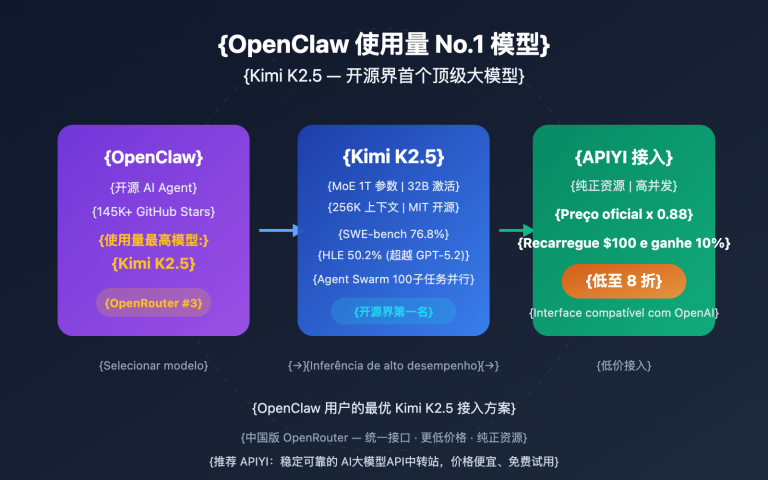
Kimi-K2.5 foi lançado em janeiro de 2026 e é um modelo MoE de 1 trilhão de parâmetros, ativando apenas 32 bilhões de parâmetros por requisição. Ele foi pré-treinado em 15 trilhões de tokens mistos de texto e visão e é nativamente multimodal.
Destaque Principal: Funcionalidade Agent Swarm – pode coordenar até 100 Agentes de IA especializados para trabalhar em conjunto simultaneamente, reduzindo o tempo de execução em 4,5 vezes. Superou o Gemini 3 Pro no SWE-Bench Verified, e o Cursor AI confirmou que sua funcionalidade Composer 2 é construída com base na tecnologia Kimi.
Ao chamar Kimi-K2.5 através do serviço proxy de API da Alibaba Cloud, o link de retransmissão adicional piora a experiência deste modelo de trilhões de parâmetros, que já exige muitos recursos computacionais. Recomenda-se o uso direto da API oficial da Moonshot AI (platform.moonshot.ai).
Análise de Latência de Chamada da API MiniMax-M2.5
MiniMax-M2.5 foi lançado em fevereiro de 2026, com 230 bilhões de parâmetros totais e 10 bilhões de parâmetros ativados. Ele obteve uma pontuação de 80,2% no SWE-Bench Verified, com velocidade de conclusão 37% mais rápida que o M2.1, igualando o Claude Opus 4.6.
Vantagem de Custo Notável: Alega ser o primeiro modelo de ponta "onde os usuários não precisam se preocupar com custos" – rodar continuamente por 1 hora a 100 tokens/segundo custa apenas cerca de 1 dólar. Já é de código aberto no Hugging Face, e recomenda-se o uso de vLLM ou SGLang para implantação.
| Modelo | Data de Lançamento | Parâmetros Totais | Parâmetros Ativados | Forma de Chamada Recomendada | Status de Código Aberto |
|---|---|---|---|---|---|
| GLM-5 | 11/02/2026 | 744 Bilhões | 40 Bilhões | API Oficial Zhipu | Código Aberto MIT |
| Kimi-K2.5 | 27/01/2026 | 1 Trilhão | 32 Bilhões | API Oficial Moonshot | Código Aberto |
| MiniMax-M2.5 | 12/02/2026 | 230 Bilhões | 10 Bilhões | Oficial MiniMax / Terceiros | MIT Modificado |
🎯 Recomendação Prática: Para modelos de terceiros de código fechado ou semiabertos como GLM-5, Kimi-K2.5 e MiniMax-M2.5, recomenda-se conectar diretamente às APIs oficiais de cada um para obter a melhor experiência. Se você precisar gerenciar interfaces de API de vários modelos de forma unificada, pode usar a plataforma APIYI apiyi.com para chamar vários modelos com uma única chave API, aproveitando também preços mais vantajosos.
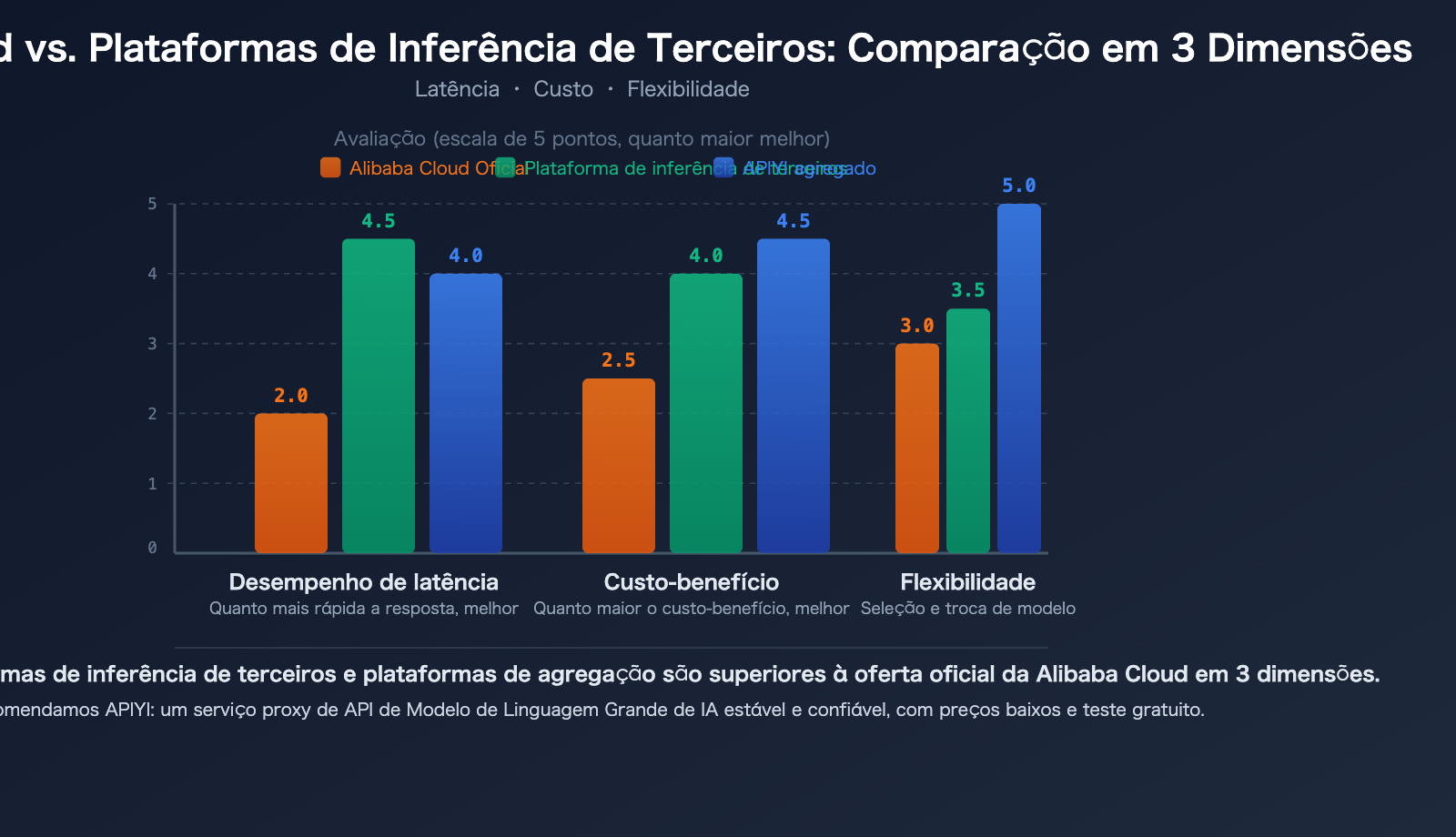
Plataformas de Inferência de Terceiros vs. Alibaba Cloud: 3 Vantagens Principais na Implantação de Modelos de Código Aberto
Para modelos de código aberto como Qwen3.5, além da API oficial da Alibaba Cloud, os desenvolvedores têm mais opções. Plataformas de inferência de terceiros especializadas geralmente oferecem desempenho igual ou até superior ao do fabricante original na implantação de modelos de código aberto.
Vantagem 1: Velocidade de Inferência Mais Rápida
A principal vantagem competitiva das plataformas de inferência especializadas é a velocidade. Através de otimizações personalizadas do motor de inferência, elas alcançam menor latência no mesmo modelo:
| Tipo de Plataforma | Latência Típica | Throughput | Vantagem de Velocidade |
|---|---|---|---|
| Plataforma de Nuvem Genérica (Alibaba Cloud, etc.) | 100-300ms | Base | — |
| SiliconFlow | Redução de 32% | Aumento de 2,3x | Núcleos CUDA Personalizados |
| Fireworks AI | ~0.17s | ~747 TPS | FireAttention v2 |
| Together AI | — | Aumento de 2x | Decodificação Especulativa + Quantização FP4 |
| APIYI apiyi.com | Otimização Multicanal | Roteamento Inteligente | Seleção Automática do Canal Mais Rápido |
Vantagem 2: Custo Mais Baixo
Em 2026, os gastos com inferência de IA ultrapassaram os gastos com treinamento pela primeira vez, respondendo por 55% dos gastos totais com infraestrutura de nuvem de IA. Nesse contexto, a otimização de custos de inferência torna-se crucial:
- A chamada de modelos de código aberto via APIs de terceiros geralmente custa menos de $1/M tokens, economizando 70-90% em comparação com modelos de código fechado.
- Plataformas de inferência especializadas utilizam hardware de nova geração como NVIDIA Blackwell para reduzir os custos de inferência de IA em até 10 vezes.
- Não há necessidade de construir clusters de GPU próprios; o pagamento é por demanda, adequado para equipes pequenas e médias e desenvolvedores individuais.
Vantagem 3: Seleção de Modelos Mais Flexível
Plataformas de terceiros geralmente suportam modelos de código aberto e fechado simultaneamente, oferecendo interfaces de API unificadas e preços transparentes. Isso significa:
- Sem bloqueio de fornecedor: Não vinculado a nenhum provedor de serviços em nuvem.
- Troca rápida: Chame vários modelos com uma única interface, compare os resultados e escolha o melhor.
- Otimização personalizada: Modelos de código aberto suportam quantização, ajuste fino, fusão e outras operações personalizadas.
💡 Sugestão de Escolha: Para modelos de código aberto como Qwen3.5, o desempenho de implantação em plataformas de inferência de terceiros pode ser melhor do que a API oficial da Alibaba Cloud. Recomendamos usar a plataforma APIYI apiyi.com para testes e comparações práticas. Esta plataforma agrega múltiplos canais de inferência e seleciona automaticamente o caminho de menor latência para você.
Chamada Rápida de API para Modelos de Código Aberto: Guia de Integração em 5 Minutos
Usando Qwen3.5-Flash como exemplo, demonstramos como chamar rapidamente APIs de modelos de código aberto através de plataformas de terceiros.
Exemplo de Código Minimalista
import openai
client = openai.OpenAI(
api_key="sua-chave-api",
base_url="https://api.apiyi.com/v1" # Interface unificada APIYI
)
response = client.chat.completions.create(
model="qwen3.5-flash",
messages=[
{"role": "user", "content": "Analise as vantagens da arquitetura MoE do Qwen3.5"}
]
)
print(response.choices[0].message.content)
Ver código completo (inclui troca de múltiplos modelos e tratamento de erros)
import openai
import time
# Inicializa o cliente - chama múltiplos modelos através da interface unificada APIYI
client = openai.OpenAI(
api_key="sua-chave-api",
base_url="https://api.apiyi.com/v1"
)
# Lista de modelos suportados
models = [
"qwen3.5-flash", # Alibaba Qwen3.5-Flash
"qwen3.5-plus", # Alibaba Qwen3.5-Plus
"glm-5", # Zhipu GLM-5
"kimi-k2.5", # Moonshot Kimi-K2.5
"minimax-m2.5", # MiniMax-M2.5
]
prompt = "Explique em 3 frases as vantagens da arquitetura MoE na inferência de Modelos de Linguagem Grandes"
for model_name in models:
try:
start = time.time()
response = client.chat.completions.create(
model=model_name,
messages=[{"role": "user", "content": prompt}],
max_tokens=500,
temperature=0.7
)
elapsed = time.time() - start
content = response.choices[0].message.content
print(f"\n[{model_name}] Tempo decorrido: {elapsed:.2f}s")
print(f"Resposta: {content[:200]}...")
except Exception as e:
print(f"\n[{model_name}] Falha ao chamar: {e}")
🚀 Comece Rápido: Recomendamos a plataforma APIYI apiyi.com para testar rapidamente os modelos acima. Registre-se e receba créditos gratuitos. Uma chave API permite chamar modelos populares como Qwen3.5, GLM-5, Kimi-K2.5, MiniMax-M2.5, etc., sem precisar se registrar em várias plataformas separadamente.
Recomendações de Soluções de Chamada de Modelo para Diferentes Cenários
Escolha a forma de chamada mais adequada com base nas suas necessidades reais:
Cenário 1: Necessidade de Chamar Modelos Fechados/Semi-fechados
Se você usa principalmente versões fechadas (não auto-hospedadas) de modelos como GLM-5, Kimi-K2.5, recomendamos:
- Primeira Escolha: Conexão direta com as APIs oficiais de cada provedor para menor latência.
- Segunda Escolha: Chamar unificadamente através de plataformas agregadoras como APIYI apiyi.com, trocando um pouco de latência por conveniência de gerenciamento.
Cenário 2: Necessidade de Implantar Modelos de Código Aberto
Se você usa modelos de código aberto como Qwen3.5, GLM-5 (versão de código aberto), MiniMax-M2.5 (versão de código aberto), etc.:
- Orçamento Suficiente: Escolha plataformas de inferência profissionais como SiliconFlow, Together AI para a melhor latência.
- Prioridade de Custo-Benefício: Chame unificadamente através do agregador APIYI apiyi.com, que roteia automaticamente para o canal mais otimizado.
- Controle Total: Use vLLM ou SGLang para construir seu próprio serviço de inferência, o que requer recursos próprios de GPU.
Cenário 3: Necessidade de Teste Comparativo de Múltiplos Modelos
Ao comparar rapidamente o desempenho de vários modelos no início do desenvolvimento:
- Recomendado: Use uma interface de API unificada (como APIYI apiyi.com) para registrar uma vez e alternar entre testes de múltiplos modelos.
- Evite registrar contas separadas e gerenciar múltiplos conjuntos de chaves API para cada modelo.
💰 Sugestão de Otimização de Custo: Para projetos sensíveis ao orçamento, chamar APIs de modelos de código aberto através da plataforma APIYI apiyi.com é a solução mais econômica. A plataforma oferece modelos de preços flexíveis, e o custo de chamada de modelos de código aberto é muito menor do que o preço oficial de modelos fechados.
Perguntas Frequentes
Q1: O Qwen3.5-Flash é anunciado como um modelo leve, por que a API ainda é lenta?
Embora o Qwen3.5-Flash ative apenas 3 bilhões de parâmetros por inferência, ele suporta nativamente uma janela de contexto de 1 milhão de tokens, integra capacidades de processamento multimodal (texto + imagem + vídeo) e chamadas de ferramentas internas. Esses "custos ocultos" fazem com que seu consumo real de poder computacional seja muito maior do que modelos puramente textuais com parâmetros equivalentes. Além disso, o cenário de escassez de recursos de GPU na Alibaba Cloud aumenta ainda mais a latência percebida devido ao tempo de espera.
Q2: A implantação de modelos de código aberto em plataformas de terceiros pode comprometer o desempenho?
Não. Plataformas de inferência profissionais de terceiros (como SiliconFlow, Together AI) usam pesos de código aberto originais e motores de inferência otimizados, resultando em desempenho consistente com os originais e, na verdade, velocidades de inferência mais rápidas. Através da plataforma APIYI apiyi.com, você pode comparar rapidamente a qualidade e a velocidade de inferência de diferentes canais para escolher a melhor solução.
Q3: Quando a escassez de poder computacional da Alibaba Cloud será aliviada?
De acordo com declarações públicas de executivos da Alibaba Cloud, a escassez de fornecimento de GPU deve persistir por 2 a 3 anos. No curto prazo, a Alibaba Cloud tende a aumentar a utilização das GPUs existentes por meio de tecnologias de pooling de recursos como Aegaeon, em vez de expandir significativamente a capacidade. Recomenda-se que os desenvolvedores não esperem pela otimização da plataforma, mas sim escolham proativamente soluções de chamada mais adequadas – a conexão direta com a API oficial ou plataformas de inferência de terceiros são alternativas viáveis no momento. Você pode testar gratuitamente a velocidade de chamada de diferentes modelos através da APIYI apiyi.com.
Resumo: Estratégias para Lidar com a Lentidão da API Qwen3.5 da Alibaba Cloud
A causa raiz da lentidão na resposta da API Qwen3.5 da Alibaba Cloud é a insuficiência global no fornecimento de poder computacional de GPU, agravada pelo alto consumo de poder computacional da arquitetura do modelo e pela disputa por recursos em ambientes multilocatários. Para problemas de lentidão ao chamar modelos de terceiros como GLM-5, Kimi-K2.5, MiniMax-M2.5 através da Alibaba Cloud, a essência é a mesma razão – a Alibaba Cloud prioriza seus próprios modelos, e a alocação de recursos para modelos de terceiros é secundária.
3 Recomendações Principais:
- Conexão Direta com APIs Oficiais para Modelos Fechados: Use a API Zhipu para GLM-5, a API Moonshot para Kimi-K2.5 e a API MiniMax para MiniMax-M2.5, evitando a latência de retransmissão em camadas intermediárias.
- Escolha Plataformas de Terceiros para Modelos de Código Aberto: Modelos de código aberto como Qwen3.5 podem ter um desempenho melhor em plataformas de inferência profissionais do que na API oficial da Alibaba Cloud.
- Use Plataformas de Agregação para Gerenciamento Unificado: Se você precisar usar vários modelos simultaneamente, recomendamos o uso da APIYI apiyi.com para chamar todos os modelos com uma única interface, garantindo eficiência e facilidade de gerenciamento.
A escassez de poder computacional será a norma para toda a indústria nos próximos 2 a 3 anos. Em vez de esperar passivamente pela expansão da capacidade da plataforma de nuvem, é melhor otimizar proativamente as estratégias de chamada – escolher a combinação mais adequada de plataforma e modelo é o melhor caminho para melhorar a experiência da aplicação de IA.
Autor: Equipe APIYI | Para mais dicas sobre chamadas de API de modelos de IA, visite APIYI apiyi.com para obter os tutoriais mais recentes e créditos de teste gratuitos.
📚 Referências
-
Documentação Oficial da Série de Modelos Qwen3.5: Especificações técnicas dos modelos Tongyi Qianwen da Alibaba Cloud.
- Link:
github.com/QwenLM/Qwen3.5 - Descrição: Inclui parâmetros completos do modelo, benchmarks e guias de uso.
- Link:
-
Anúncio de Ajuste de Preços de Computação da Alibaba Cloud: Aumento dos preços de computação de IA a partir de abril de 2026.
- Link:
www.alibabacloud.com - Descrição: Explicação oficial sobre o conflito entre oferta e demanda de computação.
- Link:
-
Relatório Técnico GLM-5: Detalhes técnicos do modelo carro-chefe da Zhipu AI.
- Link:
github.com/THUDM/GLM-5 - Descrição: Explicação da arquitetura MoE de 744 bilhões de parâmetros e do modo Agente.
- Link:
-
Documentação Oficial Kimi-K2.5: Modelo de trilhões de parâmetros da Moonshot AI.
- Link:
platform.moonshot.ai/docs/guide/kimi-k2-5-quickstart - Descrição: Guia sobre a funcionalidade Agent Swarm e acesso via API.
- Link:
-
Blog Técnico MiniMax-M2.5: Análise detalhada de modelos de ponta de código aberto.
- Link:
www.minimax.io/news/minimax-m25 - Descrição: Benchmarks de desempenho, sugestões de implantação e análise de custos.
- Link: