Die langsame API-Antwortzeit von Alibaba Cloud Qwen3.5 ist eines der am häufigsten diskutierten Themen in der Entwickler-Community. Qwen3.5-Plus und Qwen3.5-Flash, als von Alibaba selbst entwickelte Modelle, sollten theoretisch auf eigener Rechenleistung hervorragend abschneiden. Die tatsächliche Erfahrung hat jedoch viele Entwickler verwirrt: Eigene Modelle laufen auf der eigenen Plattform langsam, und der Aufruf von Drittanbietermodellen wie GLM-5, Kimi-K2.5 und MiniMax-M2.5 über Alibaba Cloud ist spürbar träge.
Kernnutzen: Dieser Artikel analysiert die grundlegenden Ursachen für die langsame API-Antwortzeit von Alibaba Cloud aus den drei Perspektiven Rechenleistungsangebot, Architekturentwurf und Scheduling-Strategie. Außerdem werden drei bewährte alternative Lösungen vorgestellt, die Ihnen helfen, eine schnellere Inferenzleistung in Ihren Projekten zu erzielen.
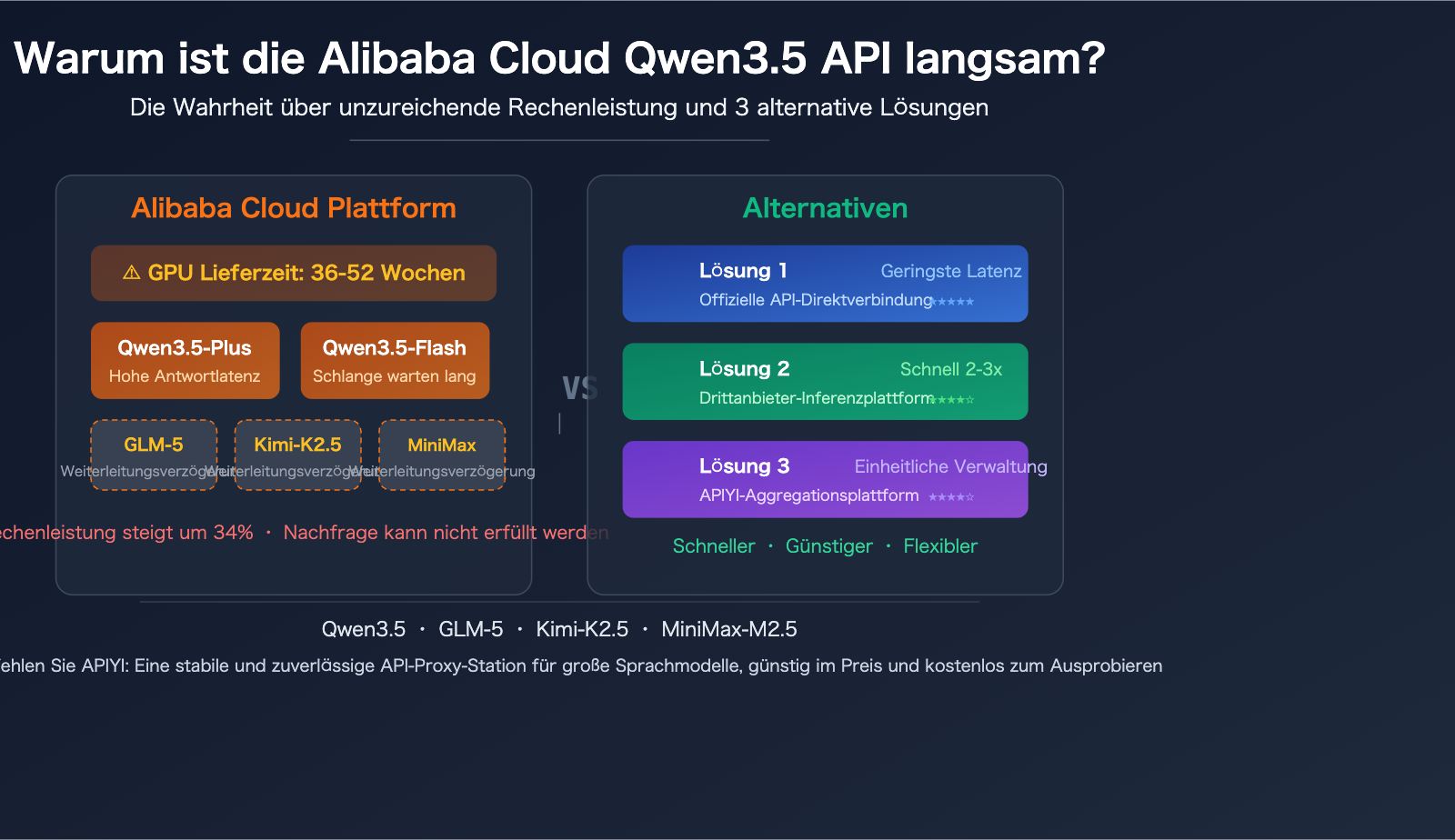
Ursache 1: Ernsthafter Mangel an globalen GPU-Rechenkapazitäten
Dies ist kein Problem, das nur Alibaba Cloud betrifft, sondern ein struktureller Konflikt in der gesamten Branche. Die Lieferzeiten für Rechenzentrums-GPUs im Jahr 2026 haben sich auf 36-52 Wochen verlängert. Führungskräfte von Alibaba Cloud gaben offen zu, dass es einen umfassenden Mangel an Halbleiterherstellern, Speicherchips und Speicherkomponenten gibt, und dass die Angebotsseite in den nächsten 2-3 Jahren zu einem "größeren Engpass" werden wird.
| Kennzahl zur Rechenkapazitätsversorgung | 2025 | 2026 | Trend |
|---|---|---|---|
| GPU-Lieferzeit | 12-24 Wochen | 36-52 Wochen | ↑ Deutlich verlängert |
| Umsatzwachstum von Alibaba Cloud AI | — | 34 % | Nachfrage-Explosion |
| Preisanpassung der Rechenkapazität von Alibaba Cloud | Basispreis | Bis zu 34 % Erhöhung | ↑ Ab 18. April 2026 |
| Anteil der globalen KI-Inferenz-Ausgaben | 42 % | 55 % | Übertrifft erstmals das Training |
Alibaba Cloud hat bereits angekündigt, die Preise für KI-Rechenkapazitäten ab dem 18. April 2026 um bis zu 34 % zu erhöhen. Der direkte Grund dafür ist die "Explosion der globalen KI-Nachfrage und steigende Lieferkettenpreise". Obwohl der Umsatz von Alibaba Cloud um 34 % gestiegen ist, gaben sie öffentlich an, die Nachfrage immer noch nicht befriedigen zu können – dies ist der makroökonomische Hintergrund für die langsame Qwen3.5 API.
Ursache 2: Rechenkapazitätsverbrauch der Qwen3.5-Modellarchitektur
Die Qwen3.5-Familie verwendet eine MoE (Mixture of Experts)-Architektur. Die Flaggschiff-Version Qwen3.5-397B-A17B hat insgesamt 397 Milliarden Parameter, wobei bei jeder Inferenz 17 Milliarden Parameter aktiviert werden. Selbst das leichtgewichtige Qwen3.5-Flash (basierend auf 35B-A3B) unterstützt nativ ein 1 Million Token Kontextfenster und multimodale Eingaben (Text + Bild + Video).
| Modellversion | Gesamtparameter | Aktivierte Parameter | Standardkontext | Multimodale Unterstützung |
|---|---|---|---|---|
| Qwen3.5-397B-A17B (Flaggschiff) | 397 Milliarden | 17 Milliarden | 262K → 1M | Text + Bild + Video |
| Qwen3.5-Plus (API-Version) | Nicht veröffentlicht | Nicht veröffentlicht | 1M | Text + Bild + Video |
| Qwen3.5-Flash (API-Version) | 35 Milliarden | 3 Milliarden | 1M | Text + Bild + Video |
| Qwen3.5-122B-A10B | 122 Milliarden | 10 Milliarden | 262K | Text + Bild + Video |
Diese Modelle verwenden bereits in der Trainingsphase eine Early-Fusion-Multimodale Architektur, die die einheitliche Verarbeitung von Text, Bildern und Videos nativ unterstützt. Der Preis für diese leistungsstarke Funktionalität ist: Der Rechenaufwand für jede Anfrage ist weitaus höher als bei reinen Textmodellen. In Kombination mit einem Kontextfenster von bis zu einer Million Tokens erhöhen sich der Speicher- und Rechenkapazitätsbedarf für eine einzelne Inferenz erheblich.
Ursache 3: Zusätzliche Latenz durch Alibaba Clouds Weiterverkauf von Drittanbieter-Modellen
Beim Aufruf von Drittanbieter-Modellen wie GLM-5 (Zhipu AI), Kimi-K2.5 (Moonshot AI) und MiniMax-M2.5 über die Alibaba Cloud DashScope-Plattform wird die Anfrage-Kette tatsächlich zu:
Ihre Anwendung → Alibaba Cloud API Gateway → DashScope-Steuerungsebene → Drittanbieter-Modellservice
Jede zusätzliche Weiterleitungsebene bedeutet zusätzliche Latenz. Noch wichtiger ist, dass bei der Weiterveräußerung dieser Modelle durch Alibaba Cloud die Priorität der GPU-Ressourcenzuweisung möglicherweise niedriger ist als bei eigenen Modellen – schließlich reicht die Rechenkapazität ohnehin nicht aus. Weit verbreitetes Feedback von Entwicklern in der Branche ist: Der Aufruf von GLM-5, Kimi-K2.5 und MiniMax-M2.5 über Alibaba Cloud ist deutlich langsamer als über die offiziellen APIs.
Ursache 4: Unzureichende Optimierung der Inferenz-Scheduling-Strategie
Professionelle Drittanbieter-Inferenzplattformen (wie SiliconFlow, Fireworks AI, Together AI) haben signifikante Vorteile bei der Inferenzgeschwindigkeit durch maßgeschneiderte CUDA-Kerne, Fusions-Aufmerksamkeitsmechanismen, feingranulares Scheduling und andere technische Mittel. Testergebnisse zeigen:
- SiliconFlow: Inferenzgeschwindigkeit bis zu 2,3x schneller als bei allgemeinen Cloud-Plattformen, Latenz um 32 % reduziert
- Fireworks AI: FireAttention v2-Technologie verspricht eine Geschwindigkeitssteigerung von bis zu 8x, gemessene Leistung ca. 747 TPS
- Together AI: Durch spekulatives Dekodieren und FP4-Quantisierung wird die Inferenzgeschwindigkeit von Open-Source-Modellen um bis zu das 2-fache erhöht.
Alibaba Cloud ist eine allgemeine Cloud-Plattform, deren Inferenz-Scheduling stärker auf Universalität und Stabilität ausgerichtet ist als auf die Optimierung der extremen Inferenzgeschwindigkeit. Dies hat bei ausreichender Rechenkapazität keine großen Auswirkungen, aber in Zeiten knapper GPU-Ressourcen wird die Lücke vergrößert.
Ursache 5: Ressourcenkonflikte durch Mandantenfähigkeit
Als größter Cloud-Dienstleister Chinas bedient Alibaba Cloud seine KI-Inferenzcluster für eine riesige Anzahl von Benutzern gleichzeitig. Während Spitzenzeiten führt der Kampf um GPU-Ressourcen direkt zu erhöhten Wartezeiten. Obwohl das von Alibaba Cloud entwickelte Aegaeon-System zur Poolbildung von Ressourcen angeblich die GPU-Auslastung um 82 % erhöht hat, ist dies im Wesentlichen "ein feineres Schneiden des begrenzten Kuchens" und löst das Problem der unzureichenden Gesamtmenge an Rechenkapazität nicht grundlegend.
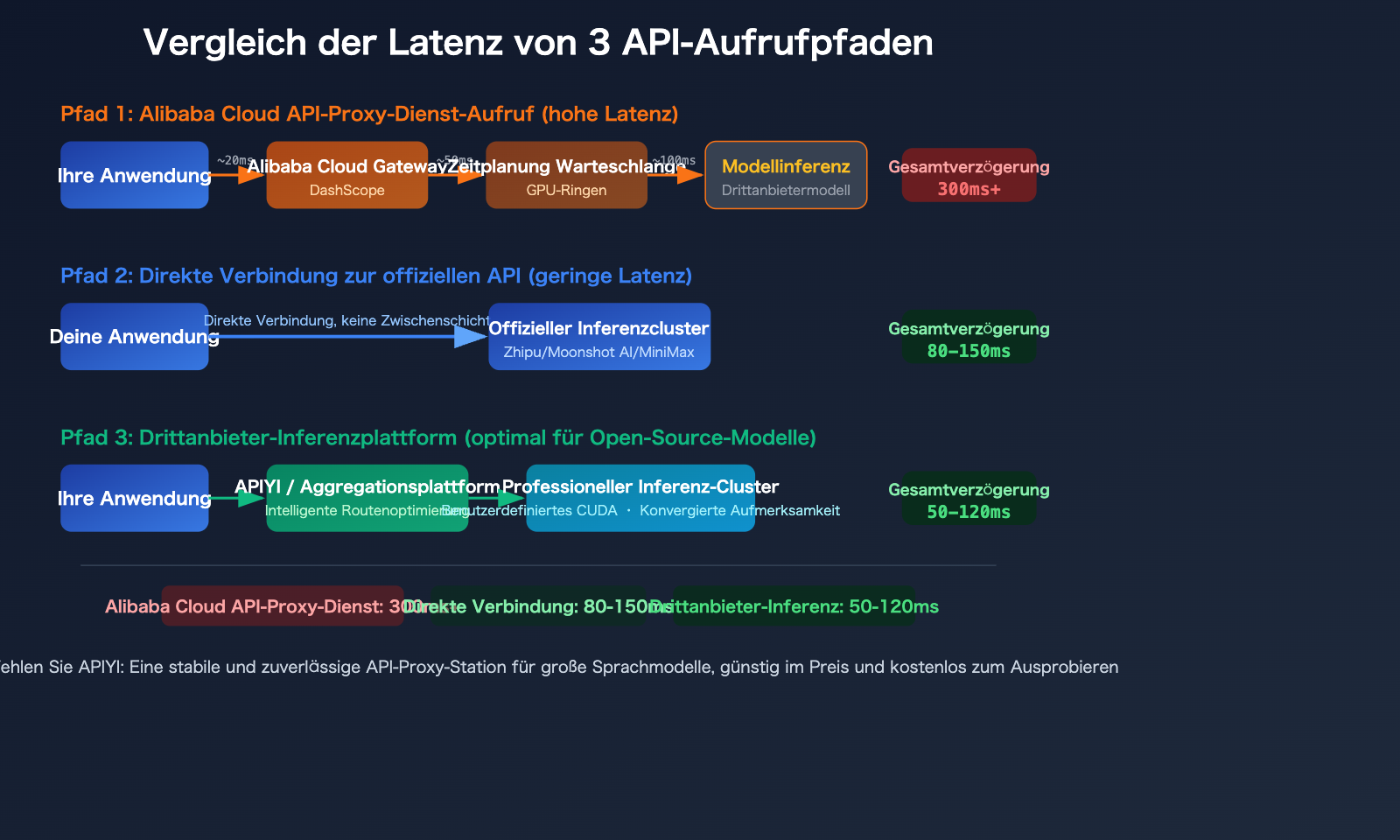
GLM-5, Kimi-K2.5, MiniMax-M2.5: Vergleich der Latenz bei Aufrufen über Alibaba Cloud vs. offizielle APIs
Nachdem wir die Gründe verstanden haben, schauen wir uns konkrete Szenarien für Modellaufrufe an. Hier ist eine Analyse der Erfahrungsunterschiede zwischen 3 beliebten Modellen auf verschiedenen Plattformen.
Analyse der API-Aufruflatenz für GLM-5 (Zhipu AI)
GLM-5 ist das Flaggschiffmodell von Zhipu AI, das im Februar 2026 veröffentlicht wurde. Es verfügt über insgesamt 744 Milliarden Parameter, davon 40 Milliarden aktivierte Parameter, und verwendet eine MoE-Architektur. Es wurde auf Huawei Ascend-Chips trainiert, unterstützt ein Kontextfenster von 200.000 Tokens und ist Open Source (MIT-Lizenz).
Wichtige Fakten: GLM-5 unterstützt nativ den Agentenmodus, kann Aufgaben autonom in Unteraufgaben zerlegen und direkt professionelle Office-Dokumente (.docx, .pdf, .xlsx) generieren. Die Preisgestaltung beträgt 1,00 $/M Tokens für Eingaben und 3,20 $/M Tokens für Ausgaben.
Beim Aufruf von GLM-5 über Alibaba Cloud müssen Anfragen zusätzliche Gateway- und Dispatching-Schichten durchlaufen, was die Latenz erheblich erhöht. Ein direkter Aufruf der offiziellen Zhipu AI API (bigmodel.cn) leitet Anfragen direkt an die eigenen Inferenzcluster von Zhipu weiter, was zu schnelleren Antworten führt.
Analyse der API-Aufruflatenz für Kimi-K2.5 (Moonshot AI)
Kimi-K2.5 wurde im Januar 2026 veröffentlicht und ist ein 1 Billion Parameter MoE-Modell, das pro Anfrage nur 32 Milliarden Parameter aktiviert. Es wurde auf 15 Billionen gemischten visuellen und Text-Tokens vortrainiert und ist nativ multimodal.
Größtes Highlight: Die Agent Swarm-Funktion – sie kann bis zu 100 spezialisierte KI-Agenten gleichzeitig koordinieren, um zusammenzuarbeiten und die Ausführungszeit um das 4,5-fache zu verkürzen. Es übertrifft Gemini 3 Pro auf SWE-Bench Verified, und Cursor AI hat bestätigt, dass seine Composer 2-Funktion auf Kimi-Technologie basiert.
Der Aufruf von Kimi-K2.5 über den Alibaba Cloud-Proxy führt zu einer zusätzlichen Weiterleitungskette, die die Erfahrung mit diesem Billionen-Parameter-Modell, das ohnehin viel Rechenleistung benötigt, noch verschlechtert. Es wird empfohlen, direkt die offizielle Moonshot AI API (platform.moonshot.ai) zu verwenden.
Analyse der API-Aufruflatenz für MiniMax-M2.5
MiniMax-M2.5 wurde im Februar 2026 veröffentlicht, hat insgesamt 230 Milliarden Parameter und aktiviert 10 Milliarden Parameter. Es erzielte 80,2 % auf SWE-Bench Verified, ist 37 % schneller als M2.1 und liegt gleichauf mit Claude Opus 4.6.
Hervorragender Kostenvorteil: Es wird als das erste zukunftsweisende Modell bezeichnet, bei dem "Benutzer sich keine Sorgen um die Kosten machen müssen" – eine Stunde kontinuierlicher Betrieb mit 100 Tokens/Sekunde kostet nur etwa 1 US-Dollar. Es ist Open Source auf Hugging Face und die Verwendung von vLLM oder SGLang zur Bereitstellung wird empfohlen.
| Modell | Veröffentlichungsdatum | Gesamtparameter | Aktivierte Parameter | Empfohlene Aufrufmethode | Open Source Status |
|---|---|---|---|---|---|
| GLM-5 | 2026.02.11 | 744 Milliarden | 40 Milliarden | Offizielle Zhipu AI API | MIT Open Source |
| Kimi-K2.5 | 2026.01.27 | 1 Billion | 32 Milliarden | Offizielle Moonshot AI API | Open Source |
| MiniMax-M2.5 | 2026.02.12 | 230 Milliarden | 10 Milliarden | Offizielle MiniMax / Dritthersteller | MIT Modifizierte Version |
🎯 Praktische Empfehlung: Für proprietäre oder semi-Open-Source-Drittanbietermodelle wie GLM-5, Kimi-K2.5 und MiniMax-M2.5 wird die direkte Verbindung zu den offiziellen APIs der jeweiligen Anbieter für die beste Erfahrung empfohlen. Wenn Sie die API-Schnittstellen mehrerer Modelle zentral verwalten müssen, können Sie die Plattform APIYI apiyi.com nutzen, um mit einem API-Schlüssel auf mehrere Modelle zuzugreifen und gleichzeitig von besseren Preisen zu profitieren.
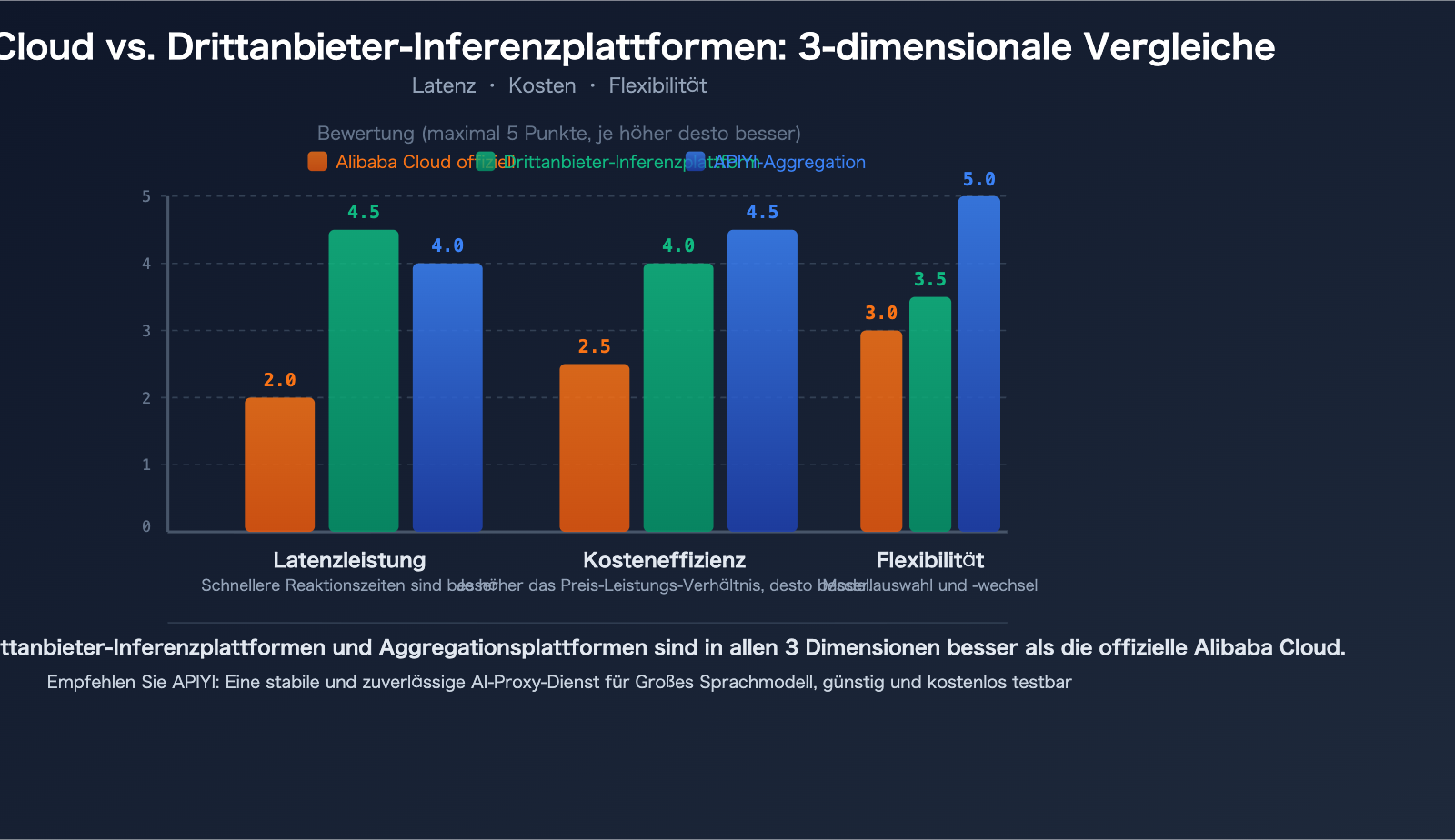
Drittanbieter-Inferenzplattformen vs. Alibaba Cloud: 3 Hauptvorteile der Bereitstellung von Open-Source-Modellen
Für Open-Source-Modelle wie Qwen3.5 gibt es neben der offiziellen Alibaba Cloud API weitere Optionen für Entwickler. Professionelle Drittanbieter-Inferenzplattformen bieten bei der Bereitstellung von Open-Source-Modellen oft eine Leistung, die der von Originalanbietern entspricht oder diese übertrifft.
Vorteil 1: Schnellere Inferenzgeschwindigkeit
Die Kernkompetenz professioneller Inferenzplattformen ist Geschwindigkeit. Durch maßgeschneiderte Inferenz-Engine-Optimierungen erreichen sie bei denselben Modellen eine geringere Latenz:
| Plattformtyp | Typische Latenz | Durchsatz | Geschwindigkeitsvorteil |
|---|---|---|---|
| Allgemeine Cloud-Plattformen (Alibaba Cloud etc.) | 100-300ms | Basis | — |
| SiliconFlow | Reduziert um 32% | Erhöht um 2,3x | Angepasste CUDA-Kerne |
| Fireworks AI | ~0,17s | ~747 TPS | FireAttention v2 |
| Together AI | — | Erhöht um 2x | Spekulative Dekodierung + FP4-Quantisierung |
| APIYI apiyi.com | Mehrkanal-Optimierung | Intelligentes Routing | Automatische Auswahl des schnellsten Kanals |
Vorteil 2: Geringere Kosten
Im Jahr 2026 übersteigen die Kosten für KI-Inferenz erstmals die Kosten für das Training und machen 55 % der gesamten KI-Cloud-Infrastrukturkosten aus. In diesem Zusammenhang ist die Optimierung der Inferenzkosten von entscheidender Bedeutung:
- Open-Source-Modelle, die über Drittanbieter-APIs aufgerufen werden, kosten in der Regel weniger als 1 $/M Tokens, was 70-90 % im Vergleich zu proprietären Modellen spart.
- Professionelle Inferenzplattformen nutzen neue Hardware wie NVIDIA Blackwell, um die Kosten für KI-Inferenz um bis zu 10x zu senken.
- Keine Notwendigkeit, eigene GPU-Cluster zu bauen, Pay-as-you-go, geeignet für kleine Teams und einzelne Entwickler.
Vorteil 3: Flexiblere Modellauswahl
Drittanbieterplattformen unterstützen in der Regel sowohl Open-Source- als auch proprietäre Modelle und bieten einheitliche API-Schnittstellen und transparente Preisgestaltung. Das bedeutet:
- Keine Anbieterbindung: Keine Abhängigkeit von einem einzelnen Cloud-Anbieter.
- Schneller Wechsel: Ein Interface zur Ansteuerung mehrerer Modelle, um nach dem Vergleich der Ergebnisse das beste auszuwählen.
- Benutzerdefinierte Optimierung: Open-Source-Modelle unterstützen benutzerdefinierte Operationen wie Quantisierung, Fine-Tuning und Merging.
💡 Auswahl-Empfehlung: Für Open-Source-Modelle wie Qwen3.5 kann die Bereitstellung über Drittanbieter-Inferenzplattformen besser sein als über die offizielle Alibaba Cloud API. Wir empfehlen, die Plattform APIYI apiyi.com für praktische Testvergleiche zu nutzen. Diese Plattform aggregiert mehrere Inferenzkanäle und wählt automatisch den Pfad mit der geringsten Latenz für Sie aus.
Schneller Einstieg in den API-Aufruf von Open-Source-Modellen: Eine 5-Minuten-Anleitung
Am Beispiel von Qwen3.5-Flash wird gezeigt, wie Sie schnell über eine Drittplattform auf die API von Open-Source-Modellen zugreifen können.
Minimalistisches Codebeispiel
import openai
client = openai.OpenAI(
api_key="your-api-key",
base_url="https://api.apiyi.com/v1" # Einheitliche Schnittstelle von APIYI
)
response = client.chat.completions.create(
model="qwen3.5-flash",
messages=[
{"role": "user", "content": "Analysiere die Vorteile der MoE-Architektur von Qwen3.5"}
]
)
print(response.choices[0].message.content)
Vollständigen Code anzeigen (mit Modellwechsel und Fehlerbehandlung)
import openai
import time
# Client initialisieren - Einheitlicher Aufruf mehrerer Modelle über APIYI
client = openai.OpenAI(
api_key="your-api-key",
base_url="https://api.apiyi.com/v1"
)
# Liste der unterstützten Modelle
models = [
"qwen3.5-flash", # Alibaba Qwen3.5-Flash
"qwen3.5-plus", # Alibaba Qwen3.5-Plus
"glm-5", # Zhipu GLM-5
"kimi-k2.5", # Moonshot Kimi-K2.5
"minimax-m2.5", # MiniMax-M2.5
]
prompt = "Erkläre in 3 Sätzen die Vorteile der MoE-Architektur bei der Inferenz großer Sprachmodelle"
for model_name in models:
try:
start = time.time()
response = client.chat.completions.create(
model=model_name,
messages=[{"role": "user", "content": prompt}],
max_tokens=500,
temperature=0.7
)
elapsed = time.time() - start
content = response.choices[0].message.content
print(f"\n[{model_name}] Dauer: {elapsed:.2f}s")
print(f"Antwort: {content[:200]}...")
except Exception as e:
print(f"\n[{model_name}] Aufruf fehlgeschlagen: {e}")
🚀 Schnellstart: Empfohlen wird die Nutzung der APIYI apiyi.com Plattform, um die obigen Modelle schnell zu testen. Bei der Registrierung erhalten Sie kostenlose Credits. Ein API-Schlüssel ermöglicht den Aufruf gängiger Modelle wie Qwen3.5, GLM-5, Kimi-K2.5, MiniMax-M2.5 usw., ohne sich bei mehreren Plattformen separat registrieren zu müssen.
Empfehlungen für Modellaufrufe in verschiedenen Szenarien
Wählen Sie die am besten geeignete Aufrufmethode basierend auf Ihren spezifischen Anforderungen:
Szenario 1: Aufruf von Closed-Source/Semi-Closed-Source-Modellen erforderlich
Wenn Sie hauptsächlich die Closed-Source-Versionen von Modellen wie GLM-5, Kimi-K2.5 usw. verwenden (nicht selbst gehostet), wird empfohlen:
- Erste Wahl: Direkte Verbindung zu den offiziellen APIs der Anbieter für die geringste Latenz.
- Zweite Wahl: Einheitlicher Aufruf über aggregierte Plattformen wie APIYI apiyi.com, um geringfügig höhere Latenz gegen mehr Verwaltungsfreundlichkeit einzutauschen.
Szenario 2: Bereitstellung von Open-Source-Modellen erforderlich
Wenn Sie Open-Source-Modelle wie Qwen3.5, GLM-5 Open-Source-Version, MiniMax-M2.5 Open-Source-Version usw. verwenden:
- Ausreichendes Budget: Wählen Sie spezialisierte Inferenzplattformen wie SiliconFlow, Together AI usw. für die beste Latenz.
- Preis-Leistungs-Priorität: Nutzen Sie die aggregierten Aufrufe über APIYI apiyi.com, die automatisch zum besten Kanal weiterleiten.
- Vollständige Kontrolle: Verwenden Sie vLLM oder SGLang, um eigene Inferenzdienste zu erstellen. Dies erfordert eigene GPU-Ressourcen.
Szenario 3: Vergleichstests mehrerer Modelle erforderlich
Wenn Sie in der frühen Entwicklungsphase die Leistung mehrerer Modelle schnell vergleichen müssen:
- Empfohlen: Verwenden Sie eine einheitliche API-Schnittstelle (z. B. APIYI apiyi.com), um nach einmaliger Registrierung mehrere Modelle zu testen.
- Vermeiden Sie die separate Registrierung von Konten und die Verwaltung mehrerer API-Schlüssel für jedes Modell.
💰 Kostenoptimierungsempfehlung: Für budgetbewusste Projekte ist der Aufruf von Open-Source-Modell-APIs über die APIYI apiyi.com Plattform die kostengünstigste Lösung. Die Plattform bietet flexible Abrechnungsmodelle, und die Kosten für den Aufruf von Open-Source-Modellen sind deutlich niedriger als die offiziellen Preise für Closed-Source-Modelle.
Häufig gestellte Fragen
F1: Qwen3.5-Flash wird als leichtgewichtiges Modell beworben, warum ist die API trotzdem langsam?
Obwohl Qwen3.5-Flash bei jeder Inferenz nur 3 Milliarden Parameter aktiviert, unterstützt es standardmäßig ein Kontextfenster von 1 Million Tokens und integriert nativ multimodale Verarbeitungsfähigkeiten (Text + Bild + Video) sowie integrierte Tool-Aufrufe. Diese "versteckten Kosten" führen dazu, dass sein tatsächlicher Rechenleistungsverbrauch weit über dem von reinen Textmodellen mit vergleichbarer Parameteranzahl liegt. Hinzu kommt der allgemeine Mangel an GPU-Ressourcen bei Alibaba Cloud, was die Wartezeiten weiter erhöht und die wahrgenommene Latenz steigert.
F2: Werden Open-Source-Modelle, die auf Plattformen von Drittanbietern bereitgestellt werden, schlechter funktionieren?
Nein. Professionelle Drittanbieter-Inferenzplattformen (wie SiliconFlow, Together AI) verwenden die originalen Open-Source-Gewichte und optimierte Inferenz-Engines, was zu einer vergleichbaren Leistung wie bei den Originalanbietern führt und die Inferenzgeschwindigkeit sogar erhöht. Über die APIYI apiyi.com Plattform können Sie die Inferenzqualität und -geschwindigkeit verschiedener Kanäle schnell vergleichen und die beste Lösung auswählen.
F3: Wann wird sich die Situation mit der Rechenleistung bei Alibaba Cloud verbessern?
Laut öffentlichen Äußerungen von Führungskräften von Alibaba Cloud wird die Knappheit an GPU-Angeboten voraussichtlich noch 2-3 Jahre andauern. Kurzfristig wird Alibaba Cloud eher auf Technologien wie Aegaeon zur Poolbildung von Ressourcen setzen, um die Auslastung bestehender GPUs zu erhöhen, anstatt die Kapazitäten stark zu erweitern. Es wird Entwicklern empfohlen, nicht auf Plattformoptimierungen zu warten, sondern proaktiv geeignetere Aufrufstrategien zu wählen – direkte Verbindungen zu offiziellen APIs oder Drittanbieter-Inferenzplattformen sind derzeit praktikable Alternativen. Sie können die Aufrufsgeschwindigkeit verschiedener Modelle kostenlos über APIYI apiyi.com testen.
Zusammenfassung: Strategien zur Bewältigung der langsamen Alibaba Cloud Qwen3.5 API
Der Hauptgrund für die langsame Antwortzeit der Alibaba Cloud Qwen3.5 API ist der globale Mangel an GPU-Rechenleistung, ergänzt durch den hohen Rechenleistungsverbrauch der Modellarchitektur und die Ressourcenkonkurrenz zwischen mehreren Mandanten. Bei Rucklern, die beim Aufruf von Drittanbietermodellen wie GLM-5, Kimi-K2.5, MiniMax-M2.5 über Alibaba Cloud auftreten, liegt im Wesentlichen derselbe Grund vor – Alibaba Cloud priorisiert die Rechenleistung für eigene Modelle, während die Ressourcenverteilung für Modelle von Drittanbietern eine untergeordnete Rolle spielt.
3 Kernempfehlungen:
- Direkte Verbindung zu offiziellen geschlossenen Modellen: Nutzen Sie die Zhipu API für GLM-5, die Moonshot AI API für Kimi-K2.5 und die MiniMax API für MiniMax-M2.5, um Verzögerungen durch Weiterleitungsschichten zu vermeiden.
- Auswahl von Drittanbietern für Open-Source-Modelle: Open-Source-Modelle wie Qwen3.5 können auf professionellen Inferenzplattformen besser abschneiden als die offizielle API von Alibaba Cloud.
- Einheitliche Verwaltung über Aggregationsplattformen: Wenn Sie mehrere Modelle gleichzeitig nutzen müssen, empfiehlt sich die Nutzung von APIYI apiyi.com, um über eine einzige Schnittstelle auf alle Modelle zuzugreifen, was Effizienz und Verwaltungsfreundlichkeit vereint.
Die Knappheit an Rechenleistung wird in den nächsten 2-3 Jahren ein Branchenstandard sein. Anstatt passiv auf die Kapazitätserweiterung der Cloud-Plattformen zu warten, ist es besser, proaktiv Aufrufstrategien zu optimieren – die Auswahl der am besten geeigneten Plattform- und Modellkombination ist der beste Weg, um die Erfahrung mit KI-Anwendungen zu verbessern.
Autor: APIYI Team | Weitere Tipps zum Aufrufen von KI-Modell-APIs finden Sie auf APIYI apiyi.com für die neuesten Tutorials und kostenlose Testkontingente.
📚 Referenzmaterialien
-
Offizielle Dokumentation der Qwen3.5-Modellreihe: Technische Spezifikationen der Tongyi Qianwen-Modelle von Alibaba Cloud
- Link:
github.com/QwenLM/Qwen3.5 - Beschreibung: Enthält vollständige Modellparameter, Benchmarks und Nutzungshinweise
- Link:
-
Ankündigung zur Anpassung der Rechenleistungspreise von Alibaba Cloud: Anstieg der Preise für KI-Rechenleistung ab April 2026
- Link:
www.alibabacloud.com - Beschreibung: Offizielle Erklärung zu Angebots- und Nachfrageschwierigkeiten bei Rechenleistung
- Link:
-
GLM-5 Technischer Bericht: Technische Details des Flaggschiffmodells von Zhipu AI
- Link:
github.com/THUDM/GLM-5 - Beschreibung: Erläuterung der 744-Milliarden-Parameter-MoE-Architektur und des Agentenmodus
- Link:
-
Kimi-K2.5 Offizielle Dokumentation: Moonshot AI's Billionen-Parameter-Modell
- Link:
platform.moonshot.ai/docs/guide/kimi-k2-5-quickstart - Beschreibung: Anleitung zur Agent Swarm-Funktion und API-Integration
- Link:
-
MiniMax-M2.5 Technischer Blog: Detaillierte Erklärung des fortschrittlichen Open-Source-Modells
- Link:
www.minimax.io/news/minimax-m25 - Beschreibung: Leistungs-Benchmarks, Bereitstellungsempfehlungen und Kostenanalyse
- Link: