يُعد بطء استدعاء واجهة برمجة تطبيقات (API) لنموذج Qwen3.5 من Alibaba Cloud أحد أكثر المواضيع التي يناقشها مجتمع المطورين حاليًا. نظريًا، يجب أن يقدم نموذجا Qwen3.5-Plus و Qwen3.5-Flash، وهما من تطوير Alibaba الذاتي، أداءً ممتازًا على البنية التحتية الخاصة بالشركة. ومع ذلك، فإن التجربة الفعلية أربكت العديد من المطورين – فنماذج الشركة نفسها تعمل ببطء على منصتها الخاصة، كما أن استدعاء نماذج طرف ثالث مثل GLM-5 و Kimi-K2.5 و MiniMax-M2.5 عبر Alibaba Cloud يعاني من تباطؤ ملحوظ.
القيمة الأساسية: ستحلل هذه المقالة بعمق الأسباب الجذرية لبطء استجابة واجهات برمجة تطبيقات Alibaba Cloud من ثلاثة أبعاد: توفير موارد الحوسبة، وتصميم البنية، واستراتيجيات الجدولة. كما ستقدم ثلاث طرق بديلة مجربة لمساعدتك في الحصول على تجربة استدلال أسرع في مشاريعك الفعلية.
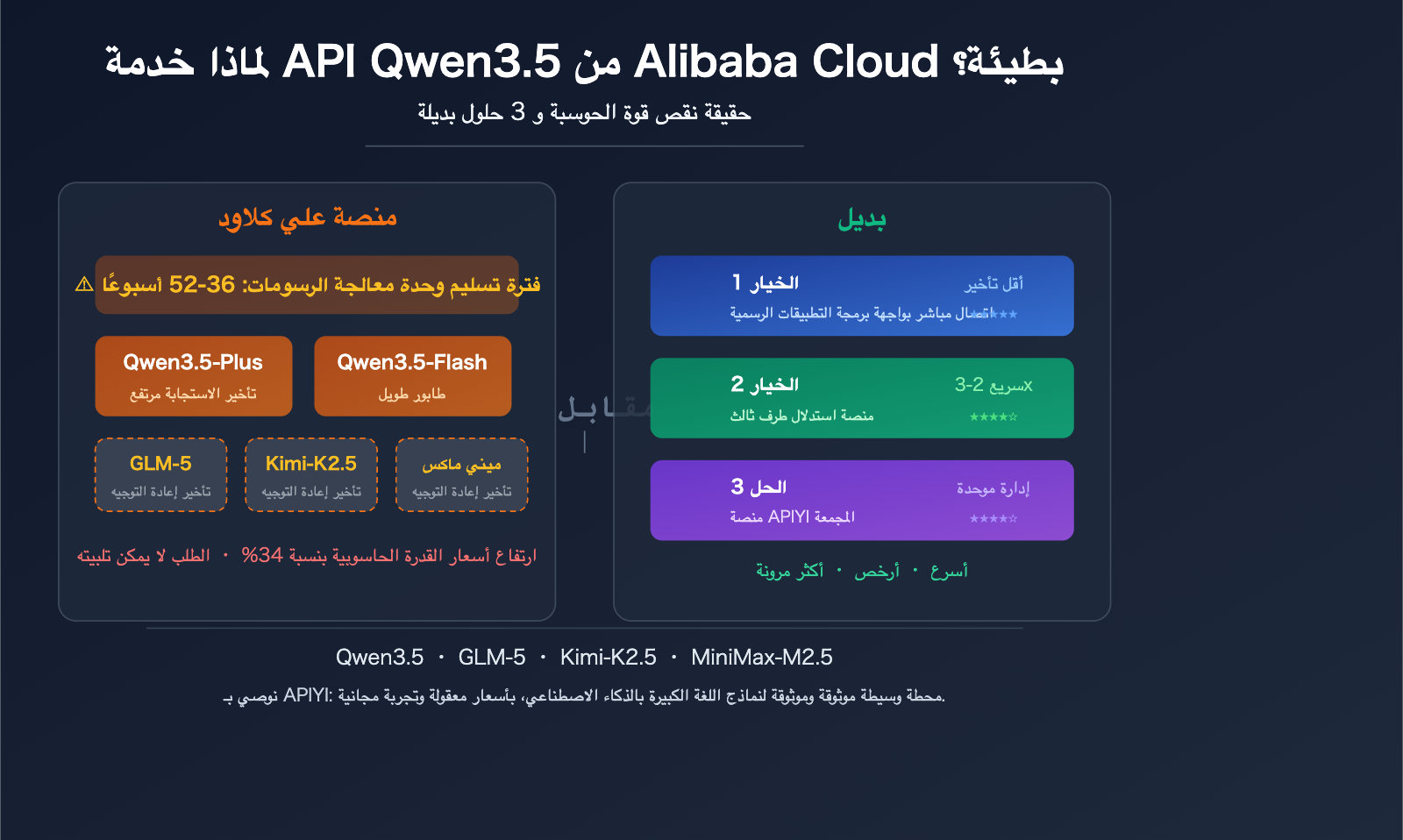
تحليل لأكبر 5 أسباب لبطء واجهة برمجة تطبيقات Qwen3.5 من Alibaba Cloud
السبب الأول: نقص حاد في إمدادات قدرات معالجة الرسوميات (GPU) عالميًا
هذه ليست مشكلة خاصة بـ Alibaba Cloud فحسب، بل هي تناقض هيكلي في الصناعة بأكملها. امتدت دورة تسليم وحدات معالجة الرسوميات (GPU) على مستوى مراكز البيانات إلى 36-52 أسبوعًا بحلول عام 2026. وقد اعترف مسؤولون تنفيذيون في Alibaba Cloud علنًا بأن هناك نقصًا شاملاً في الشركات المصنعة لأشباه الموصلات، ورقائق التخزين، وأجهزة الذاكرة، وأن جانب العرض سيصبح "عنق زجاجة كبيرًا" خلال العامين إلى الثلاثة أعوام القادمة.
| مؤشر إمداد القدرات الحاسوبية | عام 2025 | عام 2026 | اتجاه التغيير |
|---|---|---|---|
| دورة تسليم وحدات معالجة الرسوميات (GPU) | 12-24 أسبوعًا | 36-52 أسبوعًا | ↑ زيادة كبيرة |
| نمو إيرادات الذكاء الاصطناعي لـ Alibaba Cloud | — | 34% | انفجار الطلب |
| تعديل أسعار القدرات الحاسوبية لـ Alibaba Cloud | السعر الأساسي | زيادة تصل إلى 34% | ↑ اعتبارًا من 18 أبريل 2026 |
| نسبة الإنفاق العالمي على استدلال الذكاء الاصطناعي | 42% | 55% | تتجاوز التدريب لأول مرة |
أعلنت Alibaba Cloud رسميًا عن رفع أسعار قدرات الذكاء الاصطناعي الحاسوبية اعتبارًا من 18 أبريل 2026، بزيادة تصل إلى 34%، والسبب المباشر هو "انفجار الطلب العالمي على الذكاء الاصطناعي وارتفاع أسعار سلاسل التوريد". على الرغم من أن إيرادات Alibaba Cloud زادت بنسبة 34%، إلا أنها صرحت علنًا بأنها لا تزال غير قادرة على تلبية الطلب – وهذا هو السياق الكلي لبطء واجهة برمجة تطبيقات Qwen3.5.
تحليل لأسباب بطء واجهة برمجة تطبيقات Qwen3.5 من Alibaba Cloud (5 أسباب رئيسية)
السبب الثاني: استهلاك موارد الحوسبة لبنية نموذج Qwen3.5
تعتمد عائلة Qwen3.5 على بنية MoE (مزيج الخبراء)، حيث يصل إجمالي عدد البارامترات في الإصدار الرائد Qwen3.5-397B-A17B إلى 397 مليار، مع تفعيل 17 مليار بارامتر لكل استدلال. حتى Qwen3.5-Flash، المصمم ليكون خفيفًا (يعتمد على 35B-A3B)، يدعم أصلاً مليون توكن في نافذة السياق ومدخلات متعددة الوسائط (نص + صور + فيديو).
| إصدار النموذج | إجمالي البارامترات | البارامترات النشطة | سياق افتراضي | دعم الوسائط المتعددة |
|---|---|---|---|---|
| Qwen3.5-397B-A17B (رائد) | 397 مليار | 17 مليار | 262 ألف → 1 مليون | نص + صور + فيديو |
| Qwen3.5-Plus (إصدار API) | غير معلن | غير معلن | 1 مليون | نص + صور + فيديو |
| Qwen3.5-Flash (إصدار API) | 35 مليار | 3 مليار | 1 مليون | نص + صور + فيديو |
| Qwen3.5-122B-A10B | 122 مليار | 10 مليار | 262 ألف | نص + صور + فيديو |
تستخدم هذه النماذج بنية الوسائط المتعددة المدمجة مبكرًا (early-fusion) منذ مرحلة التدريب، مما يدعم المعالجة الموحدة للنص والصور والفيديو أصلاً. ثمن هذه الإمكانيات القوية هو: أن عبء الحوسبة لكل طلب أعلى بكثير من النماذج النصية البحتة. بالإضافة إلى ذلك، مع نافذة سياق تصل إلى مليون توكن، يزداد استهلاك الذاكرة العشوائية (RAM) وموارد الحوسبة بشكل كبير في كل عملية استدلال.
تحليل لأسباب بطء واجهة برمجة تطبيقات Qwen3.5 من Alibaba Cloud (5 أسباب رئيسية)
السبب الثالث: التأخير الإضافي الناتج عن إعادة بيع Alibaba Cloud لنماذج الجهات الخارجية
عند استدعاء نماذج جهات خارجية مثل GLM-5 (من Zhipu AI) و Kimi-K2.5 (من Moonshot AI) و MiniMax-M2.5 عبر منصة DashScope من Alibaba Cloud، يصبح مسار الطلب فعليًا:
تطبيقك → بوابة واجهة برمجة تطبيقات Alibaba Cloud → طبقة جدولة DashScope → خدمة النموذج الخارجية
كل طبقة إعادة توجيه إضافية تزيد من التأخير. والأهم من ذلك، عند إعادة بيع هذه النماذج، قد تكون أولوية تخصيص موارد وحدات معالجة الرسومات (GPU) أقل من النماذج الخاصة بـ Alibaba Cloud – فالموارد الحاسوبية نفسها غير كافية. تشير التعليقات الشائعة من المطورين في هذا المجال إلى أن: استدعاء GLM-5 و Kimi-K2.5 و MiniMax-M2.5 عبر Alibaba Cloud أبطأ بشكل ملحوظ مقارنة بواجهات برمجة التطبيقات الرسمية.
تحليل أسباب بطء واجهة برمجة تطبيقات Qwen3.5 من Alibaba Cloud: 5 أسباب رئيسية
السبب الرابع: ضعف تحسين استراتيجية جدولة الاستدلال
تتمتع منصات الاستدلال المتخصصة التابعة لجهات خارجية (مثل SiliconFlow، وFireworks AI، و Together AI) بمزايا كبيرة في كفاءة الاستدلال من خلال تقنيات مخصصة مثل وحدات CUDA المخصصة، ودمج آليات الانتباه، والجدولة الدقيقة. تُظهر بيانات الاختبار الفعلية:
- SiliconFlow: أسرع بـ 2.3 مرة من منصات السحابة العامة في سرعة الاستدلال، مع انخفاض في زمن الاستجابة بنسبة 32%.
- Fireworks AI: تدعي تقنية FireAttention v2 زيادة تصل إلى 8 أضعاف في السرعة، مع سرعة اختبار فعلية تبلغ حوالي 747 طلبًا في الثانية (TPS).
- Together AI: زيادة تصل إلى ضعفين في سرعة استدلال النماذج مفتوحة المصدر من خلال فك التشفير التكهني وتكميم FP4.
تُركز Alibaba Cloud، كمنصة سحابية عامة، بشكل أكبر على العمومية والاستقرار في جدولة الاستدلال، بدلاً من التحسين الأقصى لسرعة الاستدلال. هذا لا يؤثر كثيرًا عندما تكون موارد الحوسبة وفيرة، ولكن الفجوة تتسع عندما تكون وحدات معالجة الرسومات (GPU) شحيحة.
تحليل أسباب بطء واجهة برمجة تطبيقات Qwen3.5 من Alibaba Cloud: 5 أسباب رئيسية
السبب الخامس: التنافس على الموارد في بيئة متعددة المستأجرين
تخدم Alibaba Cloud، بصفتها أكبر مزود للخدمات السحابية في الصين، مجموعات استدلال الذكاء الاصطناعي الخاصة بها لعدد هائل من المستخدمين في وقت واحد. خلال فترات الذروة، يؤدي التنافس على موارد وحدات معالجة الرسومات (GPU) مباشرةً إلى زيادة أوقات الانتظار. على الرغم من أن نظام تجميع الموارد Aegaeon الذي طورته Alibaba Cloud يدعي زيادة استخدام وحدات معالجة الرسومات بنسبة 82%، إلا أن هذا في جوهره "تقطيع الكعكة المحدودة إلى شرائح أدق"، ولا يحل مشكلة نقص إجمالي قدرة الحوسبة من جذورها.
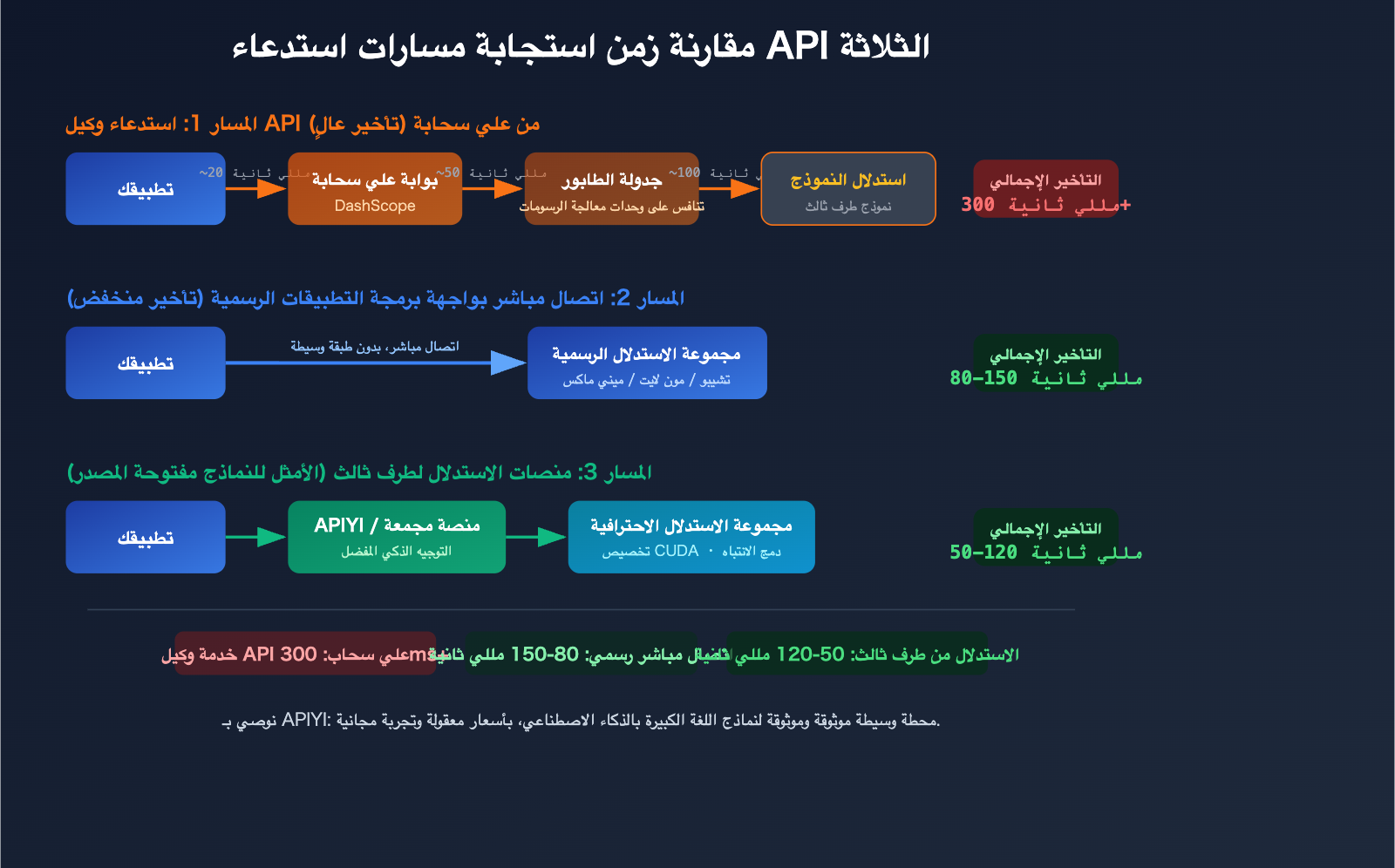
مقارنة زمن الاستجابة لاستدعاء GLM-5 و Kimi-K2.5 و MiniMax-M2.5 عبر Alibaba Cloud مقابل واجهة برمجة التطبيقات الرسمية
بعد فهم الأسباب، دعنا ننتقل إلى سيناريوهات استدعاء النماذج المحددة. فيما يلي تحليل للاختلافات في التجربة بين 3 نماذج شائعة على منصات مختلفة.
تحليل زمن استجابة استدعاء واجهة برمجة التطبيقات لـ GLM-5 (Zhipu AI)
GLM-5 هو النموذج الرئيسي الذي أصدرته Zhipu AI في فبراير 2026، بإجمالي 744 مليار معامل، و 40 مليار معامل نشط، ويعتمد على بنية MoE. تم تدريبه على شرائح Huawei Ascend، ويدعم سياق 200 ألف توكن، وهو مفتوح المصدر بالفعل (بترخيص MIT).
حقائق رئيسية: يدعم GLM-5 أصلاً وضع الوكيل (Agent Mode)، حيث يمكنه تقسيم المهام تلقائيًا إلى مهام فرعية لتنفيذها، ويمكنه إنشاء مستندات مكتبية احترافية مباشرة (.docx، .pdf، .xlsx). يبلغ سعره 1.00 دولار لكل مليون توكن للإدخال، و 3.20 دولار لكل مليون توكن للإخراج.
عند استدعاء GLM-5 عبر Alibaba Cloud، تحتاج الطلبات إلى المرور عبر طبقات بوابات وجدولة إضافية لإعادة التوجيه، مما يزيد زمن الاستجابة بشكل كبير. في المقابل، عند الاتصال المباشر بواجهة برمجة التطبيقات الرسمية لـ Zhipu AI (bigmodel.cn)، تصل الطلبات مباشرة إلى مجموعات الاستدلال الخاصة بـ Zhipu، مما يوفر استجابة أسرع.
تحليل زمن استجابة استدعاء واجهة برمجة التطبيقات لـ Kimi-K2.5 (Moonshot AI)
تم إصدار Kimi-K2.5 في يناير 2026، وهو نموذج MoE بـ 1 تريليون معامل، وينشط 32 مليار معامل فقط لكل طلب. تم تدريبه مسبقًا على 15 تريليون توكن نصي ومرئي مختلط، وهو متعدد الوسائط أصلاً.
أبرز ميزة: وظيفة Agent Swarm – يمكنها تنسيق ما يصل إلى 100 وكيل ذكاء اصطناعي متخصص للعمل معًا في وقت واحد، مما يقلل وقت التنفيذ بمقدار 4.5 مرة. تفوق على Gemini 3 Pro في SWE-Bench Verified، وقد أكدت Cursor AI أن وظيفة Composer 2 الخاصة بها مبنية على تقنية Kimi.
عند استدعاء Kimi-K2.5 عبر خدمة وكيل API الخاصة بـ Alibaba Cloud، فإن مسار إعادة التوجيه الإضافي يجعل تجربة هذا النموذج الذي يتطلب بالفعل قدرًا كبيرًا من قوة الحوسبة (تريليون معامل) أسوأ. يُنصح باستخدام واجهة برمجة التطبيقات الرسمية لـ Moonshot AI مباشرة (platform.moonshot.ai).
تحليل زمن استجابة استدعاء واجهة برمجة التطبيقات لـ MiniMax-M2.5
تم إصدار MiniMax-M2.5 في فبراير 2026، بإجمالي 230 مليار معامل، و 10 مليارات معامل نشط. سجل 80.2% في SWE-Bench Verified، وأسرع بنسبة 37% من M2.1، ويتساوى مع Claude Opus 4.6.
ميزة التكلفة البارزة: يُزعم أنه أول نموذج متطور "لا يحتاج المستخدمون للقلق بشأن تكلفته" – حيث يكلف تشغيله المستمر لمدة ساعة واحدة بسرعة 100 توكن/ثانية حوالي دولار واحد فقط. تم إصداره مفتوح المصدر على Hugging Face، ويُنصح بنشره باستخدام vLLM أو SGLang.
| النموذج | تاريخ الإصدار | إجمالي المعاملات | المعاملات النشطة | طريقة الاستدعاء الموصى بها | حالة المصدر المفتوح |
|---|---|---|---|---|---|
| GLM-5 | 2026.02.11 | 7440 مليار | 400 مليار | واجهة برمجة التطبيقات الرسمية لـ Zhipu | مفتوح المصدر (MIT) |
| Kimi-K2.5 | 2026.01.27 | 1 تريليون | 320 مليار | واجهة برمجة التطبيقات الرسمية لـ Moonshot AI | مفتوح المصدر |
| MiniMax-M2.5 | 2026.02.12 | 2300 مليار | 100 مليار | MiniMax الرسمي / طرف ثالث | MIT (تعديل) |
🎯 توصية عملية: بالنسبة للنماذج الخارجية المغلقة أو شبه مفتوحة المصدر مثل GLM-5 و Kimi-K2.5 و MiniMax-M2.5، يُوصى بالاتصال المباشر بواجهات برمجة التطبيقات الرسمية لكل منها للحصول على أفضل تجربة. إذا كنت بحاجة إلى إدارة واجهات برمجة التطبيقات لنماذج متعددة بشكل موحد، يمكنك استخدام منصة APIYI apiyi.com لاستدعاء نماذج متعددة باستخدام مفتاح API واحد، مع الاستمتاع بأسعار أفضل.
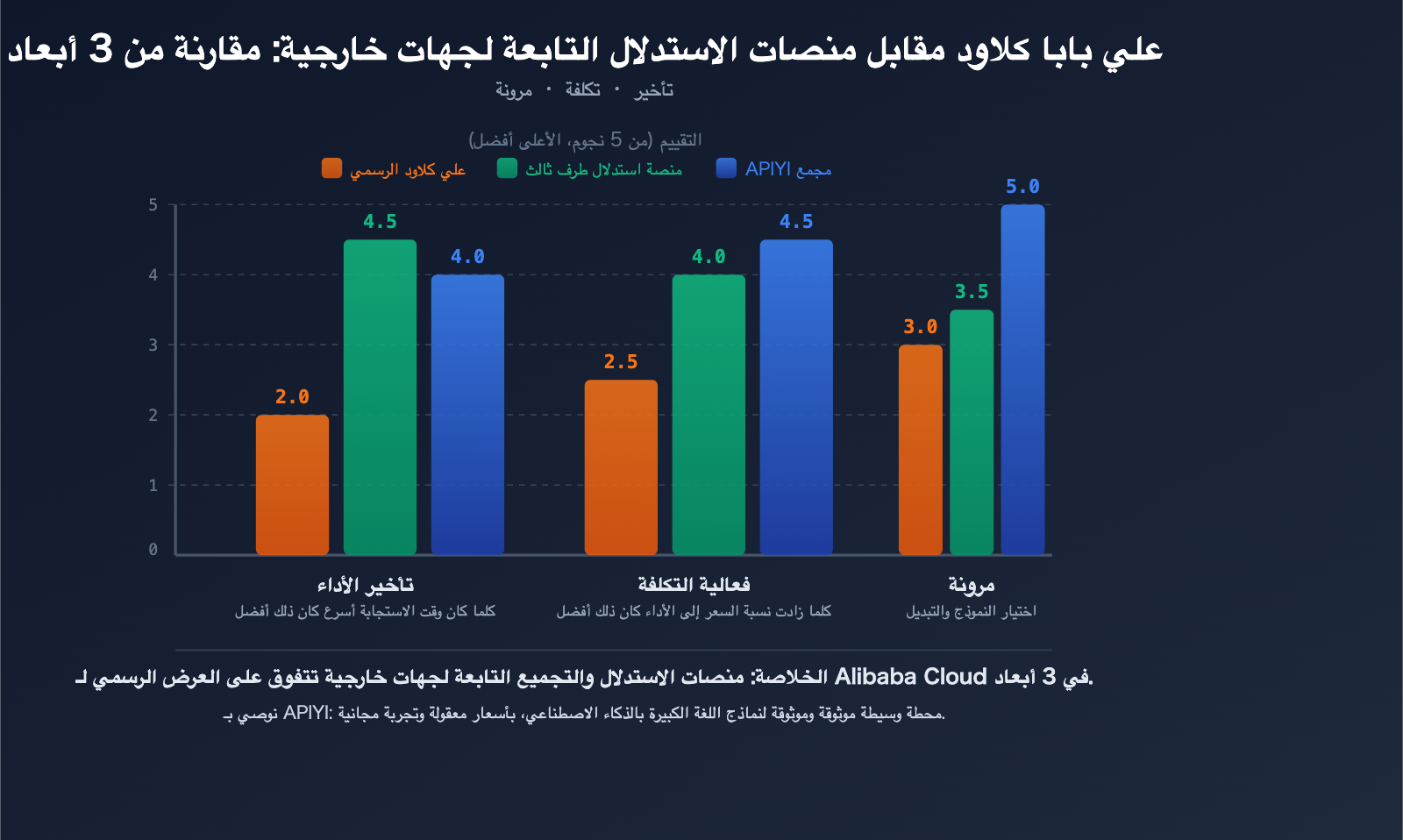
منصات الاستدلال الخارجية مقابل Alibaba Cloud: 3 مزايا رئيسية لنشر النماذج مفتوحة المصدر
بالنسبة للنماذج مفتوحة المصدر مثل Qwen3.5، لدى المطورين خيارات أكثر من مجرد واجهة برمجة تطبيقات Alibaba Cloud الرسمية. غالبًا ما تتمتع منصات الاستدلال الخارجية المتخصصة بأداء لا يقل عن أداء المصنع الأصلي، بل ويتفوق عليه في نشر النماذج مفتوحة المصدر.
الميزة الأولى: سرعة استدلال أسرع
تكمن القدرة التنافسية الأساسية للمنصات المتخصصة في الاستدلال في السرعة. من خلال محركات استدلال محسّنة ومخصصة، تحقق زمن استجابة أقل لنفس النموذج:
| نوع المنصة | زمن الاستجابة النموذجي | الإنتاجية | ميزة السرعة |
|---|---|---|---|
| منصات السحابة العامة (مثل Alibaba Cloud) | 100-300 مللي ثانية | أساسي | — |
| SiliconFlow | انخفاض بنسبة 32% | زيادة 2.3x | نوى CUDA مخصصة |
| Fireworks AI | ~0.17 ثانية | ~747 طلبًا في الثانية | FireAttention v2 |
| Together AI | — | زيادة 2x | فك تشفير تخميني + كمية FP4 |
| APIYI apiyi.com | اختيار متعدد القنوات | توجيه ذكي | اختيار تلقائي لأسرع قناة |
الميزة الثانية: تكلفة أقل
في عام 2026، ستتجاوز نفقات الاستدلال للذكاء الاصطناعي نفقات التدريب لأول مرة، لتشكل 55% من إجمالي نفقات البنية التحتية السحابية للذكاء الاصطناعي. في هذا السياق، يصبح تحسين تكلفة الاستدلال أمرًا بالغ الأهمية:
- نماذج مفتوحة المصدر عبر استدعاءات واجهة برمجة التطبيقات الخارجية، عادةً ما تكون أقل من 1 دولار لكل مليون رمز (tokens)، مما يوفر 70-90% مقارنة بالنماذج مغلقة المصدر.
- تستفيد المنصات المتخصصة في الاستدلال من أجهزة الجيل الجديد مثل NVIDIA Blackwell، مما يقلل تكلفة استدلال الذكاء الاصطناعي بما يصل إلى 10 أضعاف.
- لا حاجة لبناء مجموعات GPU خاصة بك، الدفع حسب الاستخدام، مناسب للفرق الصغيرة والمتوسطة والمطورين الأفراد.
الميزة الثالثة: خيارات نماذج أكثر مرونة
تدعم المنصات الخارجية عادةً النماذج مفتوحة المصدر والمغلقة المصدر، وتوفر واجهات برمجة تطبيقات موحدة وأسعار شفافة. هذا يعني:
- لا يوجد تقييد بمزود واحد: لا ترتبط بأي مزود خدمة سحابية.
- تبديل سريع: استدعاء نماذج متعددة بواجهة واحدة، والمقارنة للحصول على أفضل النتائج.
- تحسين مخصص: تدعم النماذج مفتوحة المصدر عمليات مثل الكمية (quantization)، والضبط الدقيق (fine-tuning)، والدمج (merging).
💡 اقتراح الاختيار: بالنسبة للنماذج مفتوحة المصدر مثل Qwen3.5، قد يكون أداء نشر النماذج مفتوحة المصدر على المنصات الخارجية أفضل من واجهة برمجة تطبيقات Alibaba Cloud الرسمية. نوصي بالاختبار الفعلي والمقارنة عبر منصة APIYI apiyi.com، التي تجمع بين قنوات استدلال متعددة وتختار لك تلقائيًا المسار الأقل زمن استجابة.
دليل سريع للبدء في استدعاء واجهات برمجة التطبيقات للنماذج مفتوحة المصدر: دليل دمج في 5 دقائق
سنستخدم Qwen3.5-Flash كمثال لعرض كيفية استدعاء واجهات برمجة التطبيقات للنماذج مفتوحة المصدر بسرعة عبر منصة طرف ثالث.
مثال كود بسيط للغاية
import openai
client = openai.OpenAI(
api_key="your-api-key",
base_url="https://api.apiyi.com/v1" # واجهة APIYI الموحدة
)
response = client.chat.completions.create(
model="qwen3.5-flash",
messages=[
{"role": "user", "content": "تحليل مزايا بنية MoE في Qwen3.5"}
]
)
print(response.choices[0].message.content)
عرض الكود الكامل (مع تبديل نماذج متعددة ومعالجة الأخطاء)
import openai
import time
# تهيئة العميل - استدعاء نماذج متعددة بشكل موحد عبر APIYI
client = openai.OpenAI(
api_key="your-api-key",
base_url="https://api.apiyi.com/v1"
)
# قائمة النماذج المدعومة
models = [
"qwen3.5-flash", #阿里 Qwen3.5-Flash
"qwen3.5-plus", #阿里 Qwen3.5-Plus
"glm-5", # 智谱 GLM-5
"kimi-k2.5", # 月之暗面 Kimi-K2.5
"minimax-m2.5", # MiniMax-M2.5
]
prompt = "اشرح مزايا بنية MoE في استدلال النماذج اللغوية الكبيرة في 3 جمل"
for model_name in models:
try:
start = time.time()
response = client.chat.completions.create(
model=model_name,
messages=[{"role": "user", "content": prompt}],
max_tokens=500,
temperature=0.7
)
elapsed = time.time() - start
content = response.choices[0].message.content
print(f"\n[{model_name}] الوقت المستغرق: {elapsed:.2f}s")
print(f"الرد: {content[:200]}...")
except Exception as e:
print(f"\n[{model_name}] فشل الاستدعاء: {e}")
🚀 البدء السريع: نوصي باستخدام منصة APIYI apiyi.com لاختبار النماذج المذكورة أعلاه بسرعة. عند التسجيل، ستحصل على رصيد مجاني، ويمكنك استدعاء نماذج رئيسية مثل Qwen3.5 و GLM-5 و Kimi-K2.5 و MiniMax-M2.5 باستخدام مفتاح API واحد، دون الحاجة للتسجيل في منصات متعددة بشكل منفصل.
توصيات حلول استدعاء النماذج لمختلف السيناريوهات
اختر الطريقة الأنسب لاحتياجاتك الفعلية:
السيناريو الأول: الحاجة إلى استدعاء نماذج مغلقة المصدر / شبه مغلقة المصدر
إذا كنت تستخدم بشكل أساسي الإصدارات المغلقة المصدر من نماذج مثل GLM-5 و Kimi-K2.5 (وليس النماذج المنشورة ذاتيًا)، فننصح بما يلي:
- الخيار الأول: الاتصال المباشر بواجهات برمجة التطبيقات الرسمية لكل جهة، للحصول على أقل زمن استجابة.
- الخيار الثاني: استخدام منصات التجميع مثل APIYI apiyi.com لاستدعاء موحد، مقابل تضحية بسيطة في زمن الاستجابة مقابل راحة الإدارة.
السيناريو الثاني: الحاجة إلى نشر نماذج مفتوحة المصدر
إذا كنت تستخدم نماذج مثل Qwen3.5، والإصدار مفتوح المصدر من GLM-5، والإصدار مفتوح المصدر من MiniMax-M2.5، فننصح بما يلي:
- ميزانية وفيرة: اختر منصات الاستدلال المتخصصة مثل SiliconFlow أو Together AI، للحصول على أفضل زمن استجابة.
- الأولوية للتكلفة مقابل الأداء: استدعاء موحد عبر منصة APIYI apiyi.com، مع توجيه تلقائي إلى أفضل قناة.
- تحكم كامل: استخدم vLLM أو SGLang لبناء خدمة استدلال خاصة بك، وهذا يتطلب موارد GPU خاصة بك.
السيناريو الثالث: الحاجة إلى اختبار مقارن لنماذج متعددة
عندما تحتاج إلى مقارنة تأثيرات نماذج متعددة بسرعة في المراحل المبكرة من التطوير:
- موصى به: استخدام واجهة API موحدة (مثل APIYI apiyi.com)، حيث يمكنك التبديل والاختبار بين نماذج متعددة بتسجيل واحد.
- تجنب التسجيل في حسابات منفصلة وإدارة مفاتيح API متعددة لكل نموذج.
💰 اقتراحات لتحسين التكلفة: بالنسبة للمشاريع الحساسة للميزانية، فإن استدعاء واجهات برمجة التطبيقات للنماذج مفتوحة المصدر عبر منصة APIYI apiyi.com هو الحل الأكثر فعالية من حيث التكلفة. توفر المنصة خيارات فوترة مرنة، وتكلفة استدعاء النماذج مفتوحة المصدر أقل بكثير من التسعير الرسمي للنماذج مغلقة المصدر.
أسئلة شائعة
س1: يُقال إن Qwen3.5-Flash نموذج خفيف الوزن، فلماذا لا يزال استدعاء API بطيئًا؟
على الرغم من أن Qwen3.5-Flash ينشط 3 مليارات معامل فقط في كل استدلال، إلا أنه يدعم افتراضيًا نافذة سياق تصل إلى مليون رمز (token)، ويتكامل أصلاً مع قدرات معالجة الوسائط المتعددة (نص + صور + فيديو) واستدعاء الأدوات المدمج. هذه "التكاليف المخفية" تجعل استهلاكه الفعلي للطاقة الحسابية أعلى بكثير من النماذج النصية البحتة ذات العدد المماثل من المعاملات. بالإضافة إلى ذلك، فإن الضغط على موارد وحدة معالجة الرسومات (GPU) في Alibaba Cloud يزيد من وقت الانتظار، مما يرفع زمن الاستجابة المتصور.
س2: هل يؤثر نشر النماذج مفتوحة المصدر على منصات طرف ثالث على الأداء؟
لا. تستخدم منصات الاستدلال المتخصصة من طرف ثالث (مثل SiliconFlow و Together AI) الأوزان الأصلية للنماذج مفتوحة المصدر، جنبًا إلى جنب مع محركات استدلال محسّنة، مما يوفر أداءً متسقًا مع المصدر الأصلي، بل وأسرع في الاستدلال. من خلال منصة APIYI apiyi.com، يمكنك مقارنة جودة وسرعة الاستدلال من قنوات مختلفة بسرعة واختيار الحل الأمثل.
س3: متى سيتم تخفيف مشكلة موارد الحوسبة في Alibaba Cloud؟
وفقًا للتصريحات العلنية لكبار المسؤولين في Alibaba Cloud، من المتوقع أن يستمر نقص إمدادات وحدات معالجة الرسومات (GPU) لمدة 2-3 سنوات. على المدى القصير، تفضل Alibaba Cloud زيادة استخدام وحدات معالجة الرسومات الحالية من خلال تقنيات تجميع الموارد مثل Aegaeon، بدلاً من التوسع الكبير في السعة. يُنصح المطورون بعدم انتظار تحسينات المنصة، بل اختيار حلول استدعاء أكثر ملاءمة بنشاط – سواء كان ذلك الاتصال المباشر بواجهات برمجة التطبيقات الرسمية (API) أو منصات الاستدلال من طرف ثالث، وكلاهما بدائل قابلة للتطبيق حاليًا. يمكنك اختبار سرعة استدعاء النماذج المختلفة مجانًا عبر APIYI apiyi.com.
الخلاصة: استراتيجيات التعامل مع بطء استدعاء API الخاص بـ Qwen3.5 على Alibaba Cloud
السبب الجذري لبطء استجابة API الخاص بـ Qwen3.5 على Alibaba Cloud هو نقص العرض العالمي لقوة الحوسبة لوحدات معالجة الرسومات (GPU)، بالإضافة إلى عوامل مثل الاستهلاك العالي للطاقة الحسابية لهيكلية النموذج والمنافسة على الموارد بين المستأجرين المتعددين. بالنسبة لمشاكل التباطؤ التي تحدث عند استدعاء نماذج طرف ثالث مثل GLM-5 و Kimi-K2.5 و MiniMax-M2.5 عبر Alibaba Cloud، فإن السبب الأساسي هو نفسه – تمنح Alibaba Cloud الأولوية لمواردها لنماذجها الخاصة، بينما يتم تخصيص موارد نماذج الطرف الثالث في مرتبة ثانوية.
3 توصيات أساسية:
- الاتصال المباشر بالنماذج المغلقة المصدر عبر واجهات برمجة التطبيقات الرسمية: استخدم واجهة برمجة التطبيقات Zhipu لـ GLM-5، وواجهة برمجة التطبيقات Moonshot لـ Kimi-K2.5، وواجهة برمجة التطبيقات MiniMax لـ MiniMax-M2.5، لتجنب زمن التأخير الناتج عن إعادة التوجيه عبر طبقات وسيطة.
- اختيار منصات طرف ثالث للنماذج مفتوحة المصدر: قد يكون أداء النماذج مفتوحة المصدر مثل Qwen3.5 على منصات الاستدلال المتخصصة أفضل من واجهة برمجة التطبيقات الرسمية لـ Alibaba Cloud.
- استخدام منصات التجميع للإدارة الموحدة: إذا كنت بحاجة إلى استخدام نماذج متعددة في وقت واحد، فمن المستحسن استخدام APIYI apiyi.com لاستدعاء جميع النماذج عبر واجهة برمجة تطبيقات واحدة، مما يجمع بين الكفاءة وسهولة الإدارة.
يُعد نقص قوة الحوسبة أمرًا طبيعيًا في الصناعة بأكملها خلال العامين إلى الثلاثة أعوام القادمة. بدلاً من انتظار توسيع سعة المنصات السحابية بشكل سلبي، من الأفضل تحسين استراتيجيات الاستدعاء بشكل استباقي – يعد اختيار المجموعة الأنسب من المنصات والنماذج هو المسار الأمثل لتحسين تجربة تطبيقات الذكاء الاصطناعي.
المؤلف: فريق APIYI | لمزيد من تقنيات استدعاء واجهات برمجة تطبيقات نماذج الذكاء الاصطناعي، نرحب بزيارة APIYI apiyi.com للحصول على أحدث الدروس وحدود الاختبار المجانية
📚 مصادر
-
الوثائق الرسمية لسلسلة نماذج Qwen3.5: المواصفات التقنية لنماذج Qwen من Alibaba Cloud.
- الرابط:
github.com/QwenLM/Qwen3.5 - الوصف: تتضمن معلمات النموذج الكاملة، والاختبارات المعيارية، وأدلة الاستخدام.
- الرابط:
-
إعلان تعديل أسعار الحوسبة من Alibaba Cloud: زيادة أسعار الحوسبة بالذكاء الاصطناعي اعتبارًا من أبريل 2026.
- الرابط:
www.alibabacloud.com - الوصف: توضيح رسمي من Alibaba Cloud حول تضارب العرض والطلب على الحوسبة.
- الرابط:
-
التقرير الفني لـ GLM-5: تفاصيل تقنية عن نموذج Zhipu AI الرائد.
- الرابط:
github.com/THUDM/GLM-5 - الوصف: شرح لبنية MoE ذات 744 مليار معامل ووضع الوكيل (Agent).
- الرابط:
-
الوثائق الرسمية لـ Kimi-K2.5: نموذج Moonshot AI ذي التريليون معامل.
- الرابط:
platform.moonshot.ai/docs/guide/kimi-k2-5-quickstart - الوصف: دليل لوظيفة Agent Swarm وواجهة برمجة التطبيقات (API).
- الرابط:
-
المدونة التقنية لـ MiniMax-M2.5: شرح تفصيلي لنماذج المصدر المفتوح المتطورة.
- الرابط:
www.minimax.io/news/minimax-m25 - الوصف: معايير الأداء، واقتراحات النشر، وتحليل التكاليف.
- الرابط: