Pada 1 Juni 2026, MiniMax secara resmi merilis model unggulan sumber terbuka (open-weights) terbaru mereka, MiniMax-M3. Ini adalah model pertama di industri yang berhasil menggabungkan tiga kemampuan utama dalam satu model: kemampuan pemrograman tingkat lanjut, jendela konteks 1 juta token, dan input multimodal asli. Dalam pengujian SWE-Bench Pro, model ini mencatatkan skor 59,0, melampaui GPT-5.5 dan Gemini 3.1 Pro, serta mendekati performa Claude Opus 4.7.
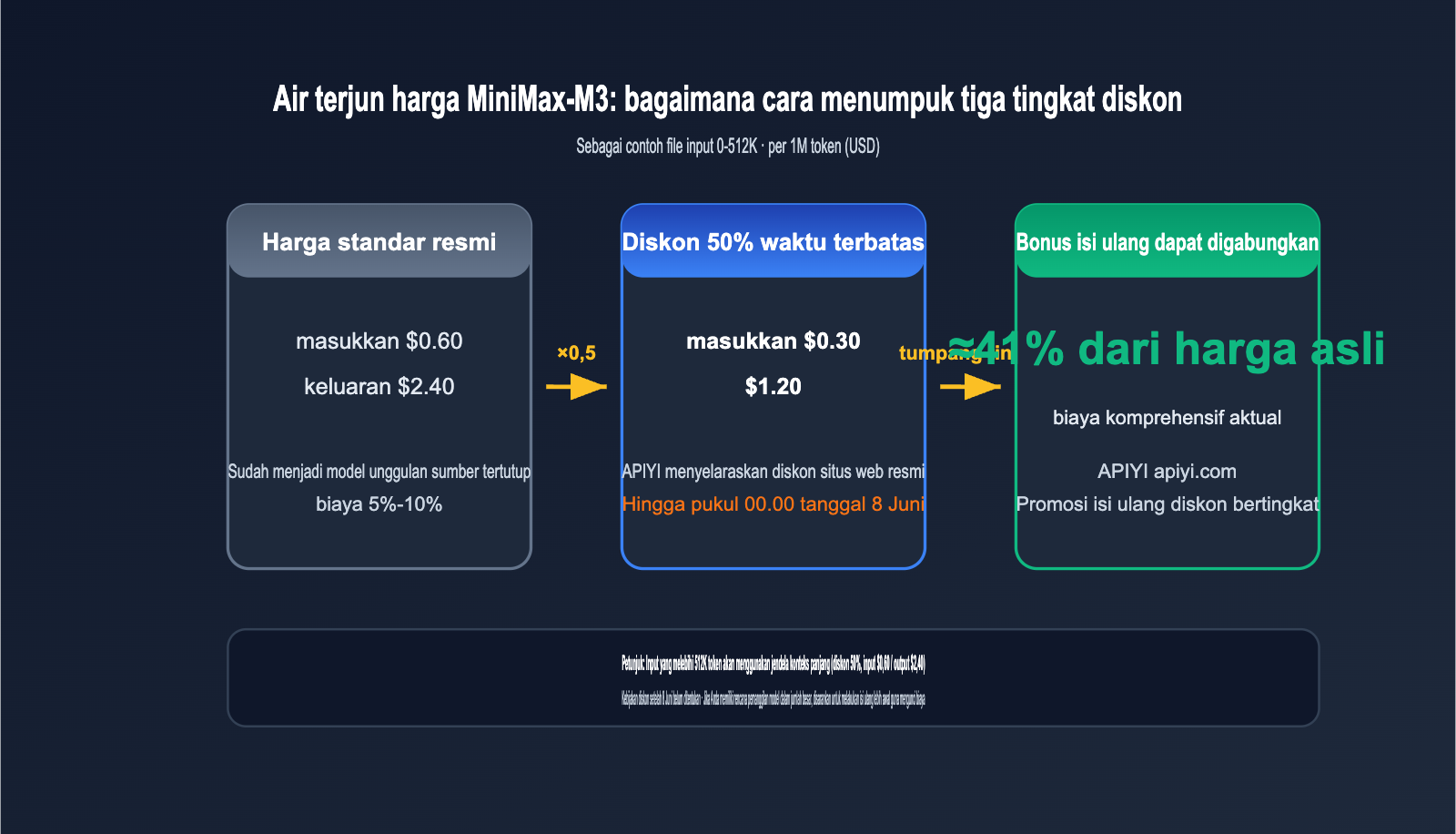
Yang lebih mengejutkan adalah harganya. Harga standar resmi sebesar $0,60 untuk input dan $2,40 untuk output per 1 juta token, yang sudah jauh lebih murah (hanya 5%-10%) dibandingkan model tertutup di kelas yang sama. Selama periode peluncuran, terdapat diskon 50%, sehingga harganya turun menjadi $0,30 untuk input dan $1,20 untuk output. Saat ini, MiniMax-M3 telah tersedia di platform APIYI (apiyi.com) dengan harga diskon 50% yang diselaraskan dengan situs resmi. Jika ditambah dengan bonus isi ulang, biaya efektifnya bisa mencapai sekitar 41% dari harga normal. Promo ini berlangsung hingga 8 Juni pukul 00.00 (UTC+8).
Artikel ini akan mengulas tuntas keunggulan arsitektur, hasil tolok ukur, skema harga, dan kode integrasi MiniMax-M3 untuk membantu Anda memutuskan apakah ini saat yang tepat untuk beralih.

Apa itu MiniMax-M3: Unggulan "Tiga-dalam-Satu" dari Kubu Sumber Terbuka
MiniMax-M3 adalah model unggulan generasi baru dari MiniMax setelah seri M2, yang diposisikan sebagai model serbaguna untuk skenario pemrograman dan agen AI. Model ini menggunakan arsitektur MoE (Mixture of Experts) berbutir halus, dengan total parameter sekitar 229,9B, di mana setiap token hanya mengaktifkan sekitar 9,8B parameter yang tersebar di 256 pakar. Artinya, biaya inferensinya mendekati model kecil berukuran 10B, namun kemampuannya menandingi model unggulan papan atas.
Skala data pelatihannya mencapai sekitar 100 triliun token, dan data teks-gambar yang saling terkait telah dimasukkan sejak tahap pra-pelatihan. Oleh karena itu, kemampuan multimodal MiniMax-M3 bersifat "asli"—kemampuan pemahaman gambar dan video tertanam langsung dalam ruang semantik, bukan hasil tempelan encoder visual eksternal. Selain input gambar dan video, model ini juga mendukung pengoperasian komputer desktop (Computer Use), menyediakan antarmuka yang cukup untuk skenario agen.
Pihak resmi menjanjikan bahwa bobot model dan laporan teknis akan dibuka sepenuhnya dalam waktu 10 hari setelah rilis. Anda bisa mendapatkannya di HuggingFace dan GitHub untuk kebutuhan penerapan mandiri (privat) dan fine-tuning. Merujuk pada lisensi MIT yang dimodifikasi pada seri M2 sebelumnya, hambatan untuk penggunaan komersial diperkirakan sangat rendah, namun detail pastinya akan mengikuti lisensi resmi saat dirilis.
Sekilas Spesifikasi Inti MiniMax-M3
| Dimensi | Spesifikasi MiniMax-M3 |
|---|---|
| Tanggal Rilis | 1 Juni 2026 |
| Arsitektur | MoE berbutir halus, total 229,9B / aktif 9,8B, 256 pakar |
| Mekanisme Atensi | MSA (MiniMax Sparse Attention) |
| Jendela Konteks | 1.000.000 token (sekitar 5x lipat seri M2) |
| Dukungan Modalitas | Input teks + gambar + video, output teks, mendukung operasi desktop |
| Data Pelatihan | Sekitar 100T token, korpus multimodal teks-gambar |
| Mode Berpikir | Mode Thinking yang bisa diaktifkan, harga tetap sama |
| Rencana Sumber Terbuka | Bobot dan laporan teknis dibuka dalam 10 hari setelah rilis |
🎯 Saran Uji Coba Cepat: Jika ingin segera memverifikasi kemampuan asli MiniMax-M3 tanpa menunggu bobot dirilis untuk membangun klaster sendiri, kami sarankan untuk langsung melakukan pemanggilan melalui antarmuka yang kompatibel dengan OpenAI di platform APIYI (apiyi.com). Cukup masukkan nama model
MiniMax-M3, dan Anda bisa menjalankan pengujian perbandingan dalam hitungan menit, dengan biaya yang jauh lebih hemat selama periode promosi.
Skor Benchmark MiniMax-M3: Apa Arti Angka 59,0 di SWE-Bench Pro
SWE-Bench Pro saat ini diakui sebagai salah satu benchmark rekayasa perangkat lunak dunia nyata yang paling menantang. Benchmark ini menguji kemampuan end-to-end model dalam memperbaiki bug dan menulis patch di repositori kode asli. MiniMax-M3 berhasil meraih skor 59,0. Data perbandingan resmi menunjukkan bahwa skor ini melampaui GPT-5.5 dan Gemini 3.1 Pro, serta hanya terpaut tipis dari Claude Opus 4.7. Bagi sebuah model yang akan segera dirilis secara open-source dengan parameter aktif kurang dari 10B, ini adalah pertama kalinya kubu open-source mengungguli model unggulan closed-source dalam benchmark ini.
Selain pemrograman, indikator terkait Agent juga sangat impresif. Skor Terminal-Bench 2.1 mencapai 66,0, MCP Atlas meraih 74,2, dan tugas penjelajahan mandiri BrowseComp mendapatkan 83,5—bahkan sedikit melampaui Claude Opus 4.7. Di sisi multimodal, SVG-Bench mengungguli Opus 4.7, dan benchmark pemahaman dokumen OmniDocBench lebih tinggi daripada Gemini 3.1 Pro.
Tentu saja, model ini tidak unggul di segala aspek. Pada PostTrainBench yang menguji kemampuan pasca-pelatihan ilmiah, MiniMax-M3 mencetak skor 0,37, lebih rendah dari Claude Opus 4.7 (0,42) dan setara dengan GPT-5.5 (0,39). Perlu diingat: angka-angka ini saat ini berasal dari blog teknis resmi, dan pengujian ulang independen oleh pihak ketiga masih berlangsung. Untuk kebutuhan bisnis yang krusial, disarankan untuk menjalankan evaluasi sendiri guna memastikannya.
Perbandingan MiniMax-M3 dengan Model Unggulan Utama
| Benchmark | MiniMax-M3 | Kesimpulan Perbandingan |
|---|---|---|
| SWE-Bench Pro | 59,0 | Melampaui GPT-5.5 & Gemini 3.1 Pro, mendekati Opus 4.7 |
| Terminal-Bench 2.1 | 66,0 | Jajaran teratas untuk tugas Agent terminal |
| BrowseComp | 83,5 | Sedikit melampaui Claude Opus 4.7 |
| MCP Atlas | 74,2 | Kemampuan pemanggilan alat & adaptasi ekosistem MCP yang kuat |
| SWE-fficiency | 34,8 | Menyeimbangkan kualitas patch dan efisiensi |
| PostTrainBench | 0,37 | Di bawah Opus 4.7 (0,42), setara dengan GPT-5.5 (0,39) |

Jika Anda ingin memverifikasi angka-angka ini secara horizontal, Anda dapat menggunakan platform APIYI untuk memanggil MiniMax-M3, GPT-5.5, dan Claude Opus 4.7 secara bersamaan dengan petunjuk yang sama—platform ini menyatukan format antarmuka, sehingga Anda hanya perlu mengubah parameter model untuk beralih, sangat cocok untuk pengujian A/B.
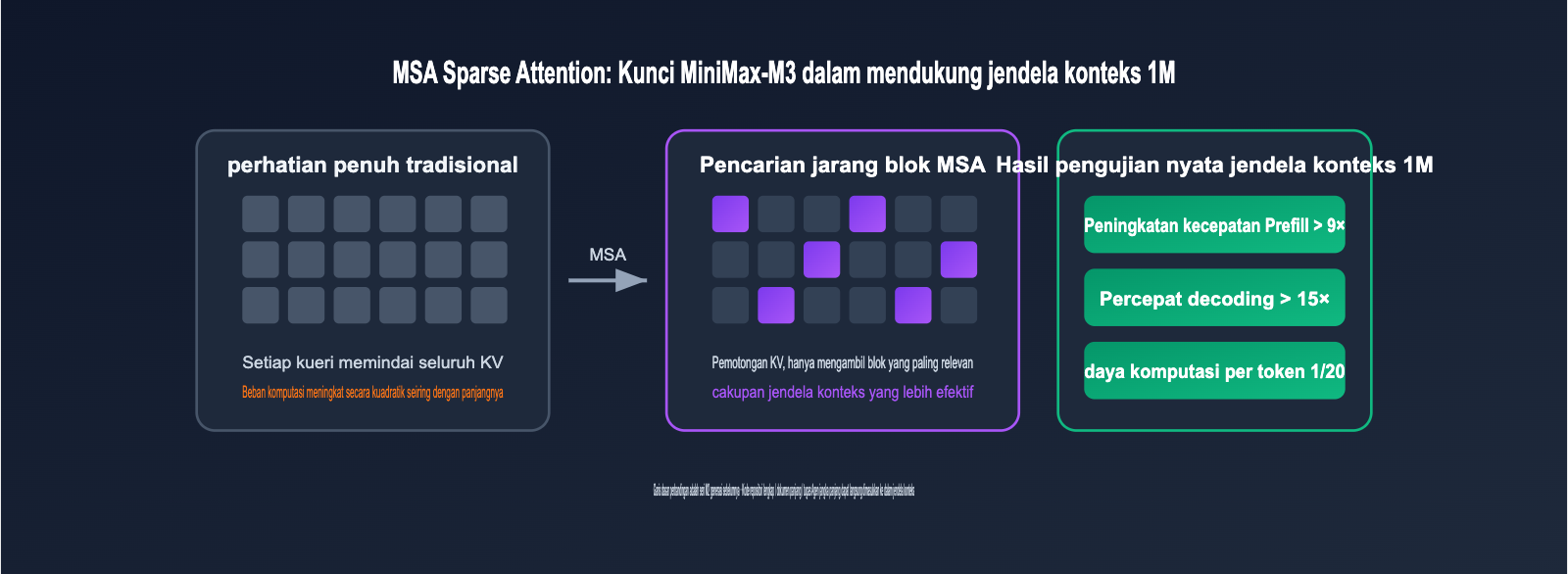
Analisis Arsitektur MiniMax-M3: Bagaimana MSA Sparse Attention Mendukung Jendela Konteks 1M
Jendela konteks 1 juta token bukanlah hal yang aneh, yang aneh adalah membuatnya layak secara ekonomi. Jawaban MiniMax-M3 adalah MSA (MiniMax Sparse Attention) yang dikembangkan sendiri. Komputasi perhatian penuh (full attention) tradisional tumbuh secara kuadrat seiring dengan panjang konteks, sementara MSA membagi cache KV menjadi blok-blok, dan setiap query hanya mengambil blok KV yang paling relevan secara presisi, sehingga mencapai cakupan jendela konteks efektif yang lebih tinggi.
Data teknis yang diberikan secara resmi cukup agresif: pada jendela konteks 1M token, jumlah komputasi per token MiniMax-M3 hanya 1/20 dari generasi sebelumnya, M2; kecepatan prefill meningkat lebih dari 9 kali lipat, dan kecepatan decode meningkat lebih dari 15 kali lipat; di tingkat operator, ia 4 kali lebih cepat daripada Flash-Sparse-Attention sumber terbuka. Dengan kata lain, memasukkan seluruh repositori kode, ratusan halaman PDF, atau video rapat berdurasi satu jam ke dalam jendela konteks tidak lagi menjadi penghalang karena masalah latensi dan biaya.
Bagi pengembang, ini berarti banyak tugas dokumen panjang yang sebelumnya memerlukan pemotongan RAG, pencarian vektor, dan ringkasan multi-putaran, sekarang dapat langsung dimasukkan ke dalam petunjuk. Tugas Agent jangka panjang juga tidak perlu lagi sering memadatkan riwayat, sehingga koherensi tugas meningkat secara signifikan.
💡 Tips Pengujian Konteks Panjang: Penagihan untuk konteks 1M dibagi menjadi dua tingkat, harga per unit berlipat ganda setelah input melebihi 512K. Kami menyarankan Anda untuk menguji efeknya di konsol APIYI apiyi.com dengan dokumen asli berukuran 200K-400K terlebih dahulu. Setelah memastikan kualitasnya memenuhi standar, barulah gunakan input yang lebih panjang. Statistik penggunaan platform akan membantu Anda menghitung biaya token untuk setiap pemanggilan secara akurat.
Harga API MiniMax-M3: Diskon 50% Terbatas + Tambahan Bonus Isi Ulang hingga ~41%
Penetapan harga MiniMax-M3 menggunakan model bertingkat berdasarkan panjang input. Input 0-512K token masuk dalam kategori standar, sementara di atas 512K masuk dalam kategori jendela konteks panjang. Selama periode peluncuran, tersedia diskon 50% untuk semua kategori. APIYI (apiyi.com) telah menyelaraskan harga dengan diskon resmi tersebut. Promo ini berlaku hingga 8 Juni 2026 pukul 00.00 (UTC+8), dan kebijakan harga setelah tanggal tersebut akan diumumkan kemudian.
Tabel Harga API MiniMax-M3 (per 1M token)
| Kategori Penagihan | Input (Harga Diskon 50%) | Output (Harga Diskon 50%) | Harga Standar (Input/Output) |
|---|---|---|---|
| Input 0-512K | $0,30 | $1,20 | $0,60 / $2,40 |
| Input di atas 512K | $0,60 | $2,40 | $1,20 / $4,80 |
Sebagai gambaran: untuk menjalankan tugas peninjauan kode berskala jutaan token, model unggulan closed-source mungkin memakan biaya belasan dolar, sementara dengan harga promo MiniMax-M3, Anda hanya perlu membayar beberapa sen dolar. Selisih biayanya mencapai 10-20 kali lipat. Untuk alur kerja Agent dengan panggilan frekuensi tinggi, migrasi kode massal, atau pemrosesan dokumen panjang, penghematan ini bisa membiayai satu mesin pengembangan dalam sebulan.
Di platform APIYI, Anda bahkan bisa mendapatkan harga yang lebih murah lagi. Promo bonus isi ulang platform dapat digabungkan dengan diskon model 50%, sehingga biaya efektifnya bisa mencapai sekitar 41% dari harga normal. Jika tim Anda memiliki volume pemanggilan model yang stabil, melakukan isi ulang sebelum 8 Juni adalah langkah yang paling menguntungkan.
Memulai Cepat API MiniMax-M3: Integrasi dalam 5 Menit
MiniMax-M3 di platform APIYI menggunakan protokol standar yang kompatibel dengan OpenAI, sehingga dapat diintegrasikan dengan mulus ke SDK, framework, atau klien apa pun yang mendukung base_url kustom. Satu hal yang perlu diperhatikan: nama model MiniMax-M3 bersifat case-sensitive (peka huruf besar-kecil). Huruf M harus kapital; jika ditulis minimax-m3, sistem akan melaporkan bahwa model tidak ditemukan.
Integrasi hanya butuh tiga langkah: daftar dan buat kunci API di APIYI (apiyi.com); arahkan base_url ke https://api.apiyi.com/v1; dan isi parameter model dengan MiniMax-M3. Berikut adalah contoh Python sederhana:
from openai import OpenAI
client = OpenAI(
api_key="sk-your-apiyi-key",
base_url="https://api.apiyi.com/v1" # Antarmuka terpadu APIYI
)
response = client.chat.completions.create(
model="MiniMax-M3", # Perhatikan huruf besar/kecil, M harus kapital
messages=[
{"role": "user", "content": "Implementasikan fungsi Fibonacci dengan cache LRU menggunakan Python"}
]
)
print(response.choices[0].message.content)
Jika Anda perlu mengirim gambar atau video, gunakan format pesan multimodal OpenAI seperti biasa, ubah content menjadi array yang berisi image_url. MiniMax-M3 akan menyelesaikan pemahaman visual dan pembuatan kode dalam satu sesi yang sama. Untuk alat Agent seperti Cline, Cursor, atau OpenClaw, Anda cukup mengubah base_url dan nama model di pengaturan untuk langsung menggunakan MiniMax-M3 sebagai basis asisten pemrograman Anda.
Panduan Cepat Skenario Penggunaan MiniMax-M3
| Skenario | Kecocokan | Penjelasan |
|---|---|---|
| Pemrograman Agent / Perbaikan Bug Otomatis | ⭐⭐⭐⭐⭐ | SWE-Bench Pro 59.0, tidak kehilangan konteks pada tugas panjang |
| Analisis & Migrasi Kode Repositori | ⭐⭐⭐⭐⭐ | Jendela konteks 1M dapat menampung repositori menengah secara utuh |
| Analisis Dokumen Panjang / Multimodal | ⭐⭐⭐⭐⭐ | OmniDocBench melampaui Gemini 3.1 Pro |
| Agent Penjelajahan Mandiri & Pemanggilan Alat | ⭐⭐⭐⭐ | BrowseComp 83.5, MCP Atlas 74.2 |
| Pelatihan Lanjutan / Penalaran Mutakhir | ⭐⭐⭐ | PostTrainBench lebih lemah dari Opus 4.7, bisa menggunakan penjadwalan campuran |
Penjadwalan campuran adalah pendekatan yang lebih realistis: gunakan MiniMax-M3 untuk menangani 80% beban panggilan tugas pengodean dan dokumen harian, sementara tugas penalaran tersulit diserahkan kepada Claude Opus 4.7 atau GPT-5.5. Melalui antarmuka terpadu APIYI untuk perutean model, satu set kode sudah cukup untuk mencapai strategi "efisiensi biaya bertingkat" ini tanpa perlu mengelola kunci API dan SDK dari berbagai penyedia.
FAQ MiniMax-M3
Q1:Kapan promo diskon 50% MiniMax-M3 berakhir?
Promo ini berakhir pada 8 Juni 2026 pukul 00.00 (UTC+8), sinkron dengan situs resmi MiniMax dan platform APIYI. Kebijakan harga setelah periode tersebut belum diumumkan secara resmi, namun biasanya akan kembali ke harga standar. Jika Anda memiliki rencana pemanggilan model dalam jumlah besar, disarankan untuk melakukan top-up sebelum batas waktu tersebut. Dengan menggabungkan bonus top-up, biaya efektif yang Anda dapatkan bisa mencapai sekitar 41% dari harga normal.
Q2:Apakah MiniMax-M3 benar-benar open source? Bisakah saya mengunduh bobotnya sekarang?
Pihak pengembang berkomitmen untuk merilis bobot model dan laporan teknis dalam waktu 10 hari setelah peluncuran, yang diperkirakan akan tersedia di halaman HuggingFace MiniMaxAI. Hingga artikel ini diterbitkan, bobot model belum selesai diunggah. Bagi tim yang tidak sabar untuk melakukan self-deployment, Anda bisa mencoba performanya melalui API terlebih dahulu, lalu mengevaluasi kebutuhan perangkat keras untuk penggunaan privat setelah bobotnya dirilis—sebagai model MoE dengan total 230B parameter, kebutuhan VRAM untuk deployment lokal cukup tinggi.
Q3:Apakah jendela konteks 1M hanya sekadar gimik atau benar-benar bisa digunakan?
Arsitektur MSA membuat jendela konteks 1M benar-benar dapat digunakan secara teknis: kecepatan prefill meningkat lebih dari 9 kali lipat, decode meningkat 15 kali lipat, dan beban komputasi per token turun menjadi 1/20 dari generasi sebelumnya. Namun, perhatikan skema penagihan; harga per unit akan berlipat ganda jika input melebihi 512K. Disarankan untuk menyesuaikan panjang konteks sesuai kebutuhan tugas, alih-alih mengisinya secara maksimal tanpa perhitungan.
Q4:Bagaimana cara memilih antara MiniMax-M3, GPT-5.5, dan Claude Opus 4.7?
Tergantung pada jenis tugas dan anggaran Anda. Untuk skenario coding agent, konteks panjang, dan dokumen multimodal, efisiensi biaya MiniMax-M3 saat ini tidak tertandingi. Untuk tugas penalaran kompleks tingkat tinggi dan penelitian ilmiah, Opus 4.7 masih memiliki keunggulan. Kami menyarankan Anda melakukan pengujian perbandingan skala kecil menggunakan petunjuk bisnis nyata di platform APIYI; data tersebut akan jauh lebih meyakinkan daripada papan peringkat (leaderboard) mana pun.
Kesimpulan: MiniMax-M3 Menghadirkan Kemampuan Flagship dengan Harga Terjangkau
Peluncuran MiniMax-M3 menjadi kejutan besar bagi pasar Model Bahasa Besar di tahun 2026: bobot open source + skor SWE-Bench Pro 59.0 yang melampaui GPT-5.5 + jendela konteks 1 juta + multimodal asli, ditambah dengan harga resmi yang hanya 5%-10% dari model flagship tertutup. Bahkan jika pengujian pihak ketiga nantinya membuat beberapa skor sedikit turun, dominasinya dalam aspek "efisiensi biaya" akan sulit digoyahkan.
Langkah jangka pendek yang paling layak diambil adalah memanfaatkan jendela harga: diskon terbatas 50% (Input $0,30 / Output $1,20 per 1M token) berakhir pada 8 Juni pukul 00.00. Di APIYI apiyi.com, Anda bisa menggabungkannya dengan promo top-up untuk mendapatkan harga efektif sekitar 41%. Jalankan evaluasi dengan biaya seminimal mungkin sebelum memutuskan untuk mengalihkan trafik produksi Anda; ini adalah strategi yang paling aman saat ini.
Untuk detail promo dan pembaruan model terbaru, silakan cek pengumuman resmi APIYI: docs.apiyi.com/news/minimax-m3-launch
Penulis: Tim APIYI
Berfokus pada agregasi API Model Bahasa Besar AI dan praktik terbaik. Untuk panduan evaluasi dan integrasi model lainnya, silakan kunjungi APIYI apiyi.com.