2026 年 5 月 6 日,xAI 向所有 API 用戶羣發了一封標題爲「Grok 4.3 release and xAI API model retirement」的官方郵件,一次性傳遞了兩條對開發者影響最大的消息:Grok 4.3 已經全量上線 API,同時 grok-4-fast、grok-4-0709、grok-3、grok-code-fast-1、grok-imagine-image-pro 等 8 款老模型將於 2026 年 5 月 15 日 12:00 PT 集中下線。這份郵件背後,既是一次重大版本迭代,也是一次需要在 9 天內完成的遷移倒計時。

Grok 4.3 這次發佈最值得關注的不是名字升級,而是 1M token 上下文窗口、$1.25/$2.50 的輸入輸出定價以及 3 檔可調推理強度的組合。這個價格檔位讓 Grok 4.3 直接進入了與 Gemini 3.1 Pro、GPT-5.4 同價位的主流推理模型競爭區間,但保留了 xAI 一貫的高 token 吞吐速度優勢。我們建議有 Grok 系列依賴的團隊儘早通過 API易 apiyi.com 平臺進行接入測試,統一的 OpenAI 兼容接口可以讓多模型切換的遷移成本降到最低。
Grok 4.3 核心規格與定價全面解讀
Grok 4.3 是 xAI 在郵件中明確稱爲「the fastest, most intelligent model we've ever built」的最新一代旗艦模型。它在 agentic tool calling 與 instruction following 兩條排行榜上都位列前排,定位是覆蓋代碼、Agent、複雜推理的通用型旗艦。從規格上看,Grok 4.3 把上下文窗口從 Grok 4 時代的 256K 直接擴展到 1M token,與 Gemini 3 Pro、Claude 4.7 同檔位,意味着可以單次塞入完整的代碼庫或長篇技術文檔。
下表彙總了 Grok 4.3 在 xAI API 上的核心參數,所有數據均來自 xAI 官方郵件與 Artificial Analysis 第三方實測頁面。
| 參數項 | Grok 4.3 取值 | 備註說明 |
|---|---|---|
| 上下文窗口 | 1,000,000 token | 輸入 + 輸出共享 |
| 輸入定價 | $1.25 / 1M token | 比 GPT-5.4 低 50%,與 Gemini 3.1 Pro 持平 |
| 輸出定價 | $2.50 / 1M token | 比 Grok 4 時代的 $15 下調約 83% |
| 推理強度 | low / medium / high 共 3 檔 | 通過參數控制深度推理預算 |
| 輸入模態 | 文本 + 圖像 | 支持視覺理解 |
| 輸出模態 | 文本 | 不直接生圖 |
| 工具調用 | 原生 function calling | 支持結構化輸出與並行調用 |
| 輸出速度 | 約 207 tokens/s | Artificial Analysis 實測 |
3 檔推理強度(reasoning effort)是 Grok 4.3 區別於上一代的關鍵新特性,它允許開發者根據任務複雜度調節模型「思考」深度,直接影響延遲與成本。這一機制借鑑自 OpenAI 的 reasoning_effort 設計,但 xAI 把推理本身設爲「always-on」常駐狀態,只是允許調節深度。下表整理了 3 檔強度的典型適用場景與影響。
| 推理強度 | 典型場景 | 延遲特徵 | 成本影響 |
|---|---|---|---|
| low | 簡單分類、摘要、規則化抽取 | 接近非推理模型 | 輸出 token 量最小 |
| medium | 函數調用、數據分析、代碼補全 | 平衡延遲與質量 | 默認推薦檔位 |
| high | 多步 Agent、複雜數學、長鏈路代碼 | 較長 thinking 階段 | 輸出 token 顯著增加 |
🎯 接入建議: 對於不確定該選哪一檔的團隊,我們建議先在 API易 apiyi.com 平臺上用 medium 檔跑一組真實業務樣本,再根據準確率與成本回報決定是否升級到 high 檔。統一接口可以讓 reasoning_effort 參數在不同模型間一鍵切換,無需重寫 SDK。

Grok 4.3 在 agentic 與 instruction following 排行榜的實測表現
Grok 4.3 之所以能在郵件裏被 xAI 重點強調「tops leaderboards in agentic tool calling and instruction following」,核心數據來自 Artificial Analysis、τ²-Bench、IFBench、GDPval-AA 等第三方榜單。Artificial Analysis Intelligence Index 給出的綜合得分是 53.2,跑完整套評測的總成本約 $395,比 Grok 4.20 節省約 20%。在 τ²-Bench Telecom(模擬電信客服雙向工具調用)這條最貼近真實 Agent 場景的榜單上,Grok 4.3 拿到了 98% 的成績,相比 Grok 4.20 提升了 5 個百分點,與 GLM-5.1 持平。
對開發者而言,更值得關注的是 GDPval-AA 這條衡量真實經濟價值的工作流榜單。Grok 4.3 在 GDPval-AA 上拿到 1500 ELO,比上一代 Grok 4.20 0309 v2 的 1179 ELO 直接提升 321 分,反超 Gemini 3.1 Pro Preview、Muse Spark、GPT-5.4 mini(xhigh)、Kimi K2.5 等模型。Instruction Following 方面,Grok 4.3 在 IFBench 上保持 81% 的成績,與 Grok 4.20 0309 v2 持平。
| 基準測試 | Grok 4.3 成績 | 同檔參考 | 主要考察能力 |
|---|---|---|---|
| AA Intelligence Index | 53.2 | 優於 98% 受測模型 | 綜合智能 |
| AA Coding Index | 41.0 | 優於 89% 受測模型 | 編碼與重構 |
| τ²-Bench Telecom | 98% | 與 GLM-5.1 持平 | 工具調用 + 用戶協同 |
| IFBench | 81% | 與 Grok 4.20 持平 | 複雜指令遵循 |
| GDPval-AA | ELO 1500 | 反超 Gemini 3.1 Pro Preview | 真實工作流價值 |
需要注意的是,Grok 4.3 的強項在 Agent 工作流與工具調用,而不是純算法競賽。對於代碼 Agent、Browser Agent、客服 Bot 這類需要穩定 JSON 輸出與多輪工具調用的應用,Grok 4.3 的可靠性會比上一代有明顯提升。但如果團隊的核心場景是 SWE-bench 類的純代碼合成,我們建議在 API易 apiyi.com 平臺上把 Grok 4.3、Claude 4.7 Opus、GPT-5.4 都拉到同一組測試集裏跑一遍,再根據通過率決定主力模型。
xAI API 模型下線清單與每款模型的遷移建議
xAI 這次同時下線 8 款模型,跨度覆蓋文本推理、代碼模型與圖像生成,基本上把 Grok 4 時代的整套 SKU 一次性清理。對於業務裏直接 hard-code 模型名的團隊,這是一次必須在 9 天內完成代碼改造的硬性截止。下表整理了所有受影響模型與官方推薦的替代路徑。
| 即將下線模型 | 類型 | 官方推薦替代 | 遷移備註 |
|---|---|---|---|
| grok-4-1-fast-reasoning | 推理 | grok-4.3 | 推理質量提升,價格下降 |
| grok-4-1-fast-non-reasoning | 非推理 | grok-4.20-non-reasoning | 保留低延遲特性 |
| grok-4-fast-reasoning | 推理 | grok-4.3 | 同時獲得 1M 上下文 |
| grok-4-fast-non-reasoning | 非推理 | grok-4.20-non-reasoning | API 形態保持兼容 |
| grok-4-0709 | 推理 | grok-4.3 | 早期 Grok 4 快照下線 |
| grok-code-fast-1 | 代碼 | grok-4.3 | 代碼場景統一到 4.3 |
| grok-3 | 通用 | grok-4.3 | Grok 3 時代正式終結 |
| grok-imagine-image-pro | 圖像生成 | grok-imagine-image | 圖像生成 SKU 簡化 |
下線時間是 2026 年 5 月 15 日 12:00 PT(北京時間 5 月 16 日凌晨 3 點),截止時間一過,所有發往這 8 個模型 ID 的請求都會直接報錯。從 5 月 6 日郵件發出算起,留給開發者的窗口是 9 天,對中大型業務來說是一個非常緊張的時間表。我們建議把遷移工作拆成 3 步:第一步定位代碼裏所有 hard-code 的模型 ID,第二步在 API易 apiyi.com 平臺上跑一套灰度測試,第三步通過環境變量切換實際 model 字段而不是修改業務邏輯。
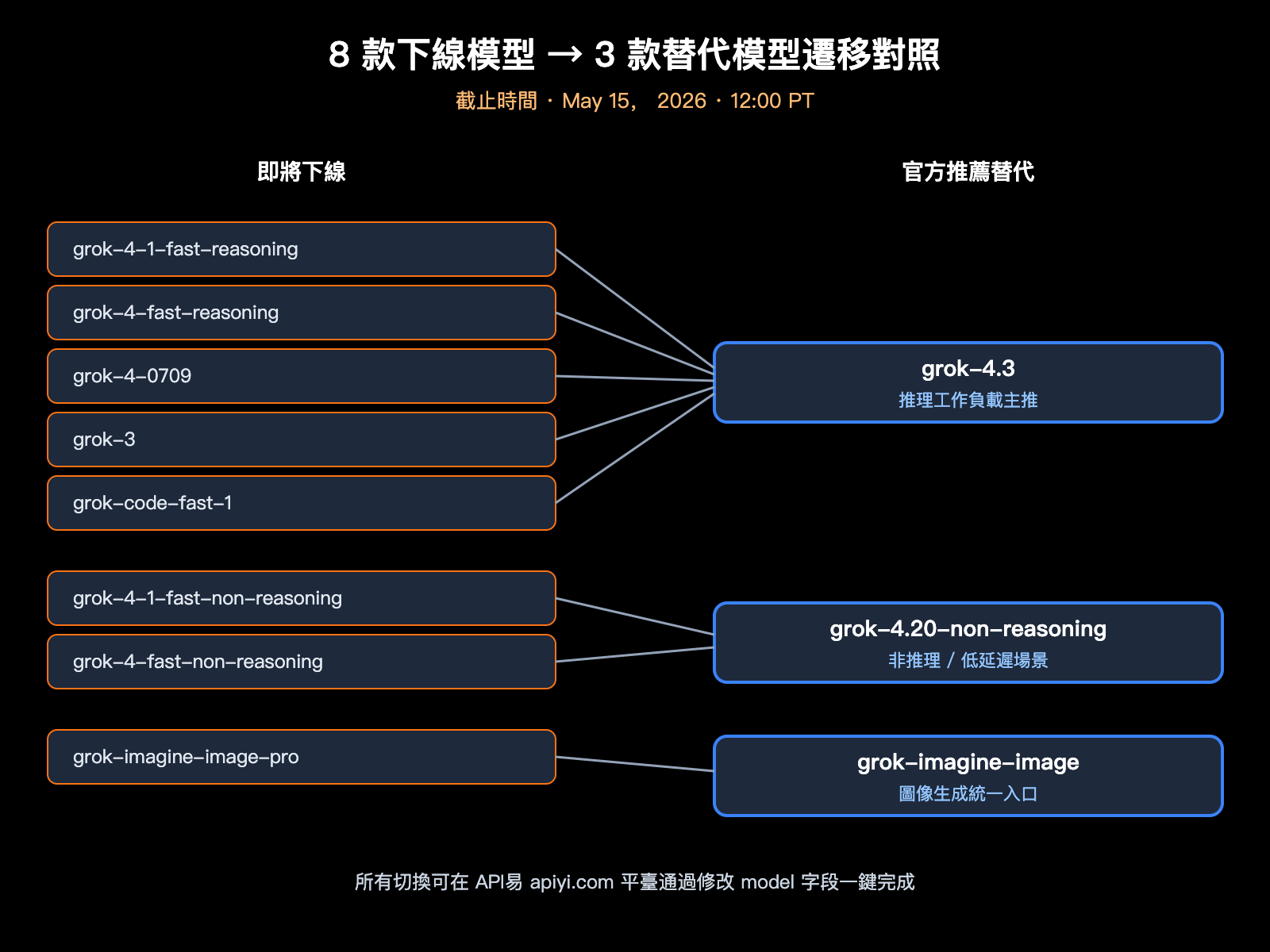
特別提醒一下,grok-code-fast-1 是過去半年裏很多代碼 Agent 項目的默認模型,它的下線意味着所有依賴這個 ID 的 Cursor 類工具、IDE 插件、CLI Agent 都需要切到 grok-4.3。代碼場景下,Grok 4.3 的工具調用穩定性比 grok-code-fast-1 更好,但單 token 成本略高,需要重新評估調用預算。
Grok 4.3 與 GPT-5.4、Claude 4.7、Gemini 3.1 Pro 橫向對比
Grok 4.3 落地的 2026 年第二季度,前沿模型市場正處於歷史上最激烈的競爭期。Claude Opus 4.7 在 SWE-bench Verified 上保持 87.6% 的領先,Gemini 3.1 Pro 在 GPQA Diamond 取得 94.3%,GPT-5.4 在長文本推理穩定性上仍是基線參考。Grok 4.3 的卡位則是「中等智商 + 極低價格 + 極強 Agent 工具鏈」,主打成本敏感的高頻調用場景。
下表把 4 個旗艦模型在常見維度上的關鍵數據放到一起對比,價格單位均爲美元每百萬 token。
| 模型 | 輸入價 | 輸出價 | 上下文 | 主要優勢場景 |
|---|---|---|---|---|
| Grok 4.3 | $1.25 | $2.50 | 1M | Agent 工具鏈、高頻調用、中等推理 |
| GPT-5.4 | $2.50 | $15.00 | 400K | 長文本一致性、複雜規劃 |
| Claude 4.7 Opus | $15.00 | $75.00 | 1M | 頂級編碼、文檔寫作、深度分析 |
| Gemini 3.1 Pro | $2.00 | $12.00 | 2M | 多模態、視頻理解、超長文檔 |
從這張對比表能直觀看到一個事實:Grok 4.3 的輸出 token 價格比 Claude 4.7 Opus 便宜 30 倍,比 Gemini 3.1 Pro 便宜約 4.8 倍。對於高頻調用的客服 Agent、代碼 Linter、批量數據清洗這類業務,Grok 4.3 的單位成本優勢會被無限放大。但在需要極致編碼質量或多模態理解的場景,Claude 4.7 Opus 與 Gemini 3.1 Pro 仍然是不可替代的。
🎯 多模型策略建議: 我們建議把 Grok 4.3 用作高頻通用層、Claude 4.7 Opus 用作複雜代碼與文檔輸出層、Gemini 3.1 Pro 用作多模態層,通過 API易 apiyi.com 的統一接口在業務路由層做模型分發,這樣既能享受 Grok 4.3 的低成本紅利,也能在關鍵節點用上更強的模型。
Grok 4.3 API 遷移指南與代碼示例
遷移到 Grok 4.3 在工程層面非常直接,xAI 提供 OpenAI 兼容的 chat completions 接口,大部分遷移工作就是修改 base_url 與 model 字段。對於已經使用 OpenAI SDK 的項目,下面這份極簡 Python 示例就是完整的接入代碼。
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1",
)
resp = client.chat.completions.create(
model="grok-4.3",
messages=[
{"role": "user", "content": "用一句話解釋 reasoning effort"},
],
extra_body={"reasoning_effort": "medium"},
)
print(resp.choices[0].message.content)
把 base_url 指向 API易 apiyi.com 平臺後,業務側就同時擁有了 Grok 4.3、Claude 4.7、GPT-5.4、Gemini 3.1 Pro 的統一調用入口,後續切換模型只需要改 model 參數,不需要重寫鑑權與路由代碼。這種統一抽象在 5 月 15 日下線截止前能顯著降低遷移風險。
針對老模型的遷移,我們整理了一份從老模型 ID 切到新模型 ID 的最小改動對照,可以直接套用到代碼裏。
| 舊 model 字段 | 新 model 字段 | 是否需要改其他參數 |
|---|---|---|
| grok-3 | grok-4.3 | 可選加 reasoning_effort |
| grok-4-0709 | grok-4.3 | 可選加 reasoning_effort |
| grok-4-fast-reasoning | grok-4.3 | 可選加 reasoning_effort |
| grok-4-fast-non-reasoning | grok-4.20-non-reasoning | 無需修改其他參數 |
| grok-code-fast-1 | grok-4.3 | 建議 reasoning_effort=high |
| grok-imagine-image-pro | grok-imagine-image | 圖像 API 端點保持一致 |
Grok 4.3 常見問題 FAQ
Q1: Grok 4.3 真的支持 1M 上下文嗎?長文本性能會衰減嗎?
是的,Grok 4.3 在 xAI API 上正式提供 1M token 上下文窗口,與 Claude 4.7 Opus 同檔。但和所有長上下文模型一樣,在 600K 之後的需求理解會出現一定衰減,我們建議關鍵信息放在文檔前半部分。可以通過 API易 apiyi.com 平臺先用真實業務長文檔跑一組檢索召回率測試,再決定是否把 Grok 4.3 作爲長文本主力。
Q2: 推理強度 low / medium / high 該怎麼選?
低風險任務(分類、摘要、規則抽取)用 low,常規業務(客服、函數調用、數據分析)用 medium,複雜推理(多步 Agent、長鏈路代碼、複雜數學)用 high。high 檔會顯著增加輸出 token 與延遲,建議結合預算與延遲 SLA 評估。
Q3: 5 月 15 日 12:00 PT 之後,老模型還能繼續用嗎?
不能。xAI 郵件明確寫到「After May 15, 2026, requests to these models will no longer work」,過期請求會直接返回錯誤。所有 hard-code 老 model ID 的代碼必須在截止前完成切換。
Q4: 怎樣讓遷移成本最低?
最穩妥的做法是在業務裏把 model 字段抽象成環境變量或配置項,而不是寫死在代碼裏。配合 API易 apiyi.com 的 OpenAI 兼容入口,遷移就只剩一行配置變更與一次迴歸測試。
Q5: Grok 4.3 適合做 Coding Agent 嗎?
適合。Grok 4.3 在 τ²-Bench Telecom 拿到 98%,工具調用與多輪對話穩定性比 grok-code-fast-1 更好,而且單位成本極低,非常適合高頻調用的 IDE 插件、CLI Agent 與自動化運維腳本。
總結:Grok 4.3 上線與 xAI API 遷移的核心要點
Grok 4.3 這次發佈最大的看點不在「更強」,而在「更便宜的同時也更強」。$1.25/$2.50 的定價讓 xAI 把 1M 上下文與高質量 Agent 工具調用一起帶到了和 Gemini 3.1 Pro 同檔的價格區間,直接重新定義了高頻通用層的性價比基線。同時 8 款老模型 5 月 15 日的集中下線也提醒所有團隊:模型 ID 不應該被 hard-code 到業務代碼裏,而是應該被抽象到一層可配置的路由層背後。
我們建議把 Grok 4.3 作爲高頻調用與 Agent 工具鏈的主力,通過 API易 apiyi.com 的統一接口完成遷移,把切換成本壓到最低,同時保留 Claude 4.7 Opus、GPT-5.4、Gemini 3.1 Pro 的多模型組合能力,在不同任務上動態調度,以拿到全局最優的成本與質量平衡。
APIYI 技術團隊 · 關注 AI 模型 API 與開發者工具的實戰內容,更多技術文章請訪問 apiyi.com