Author's Note: The xAI flagship model, Grok 4.20 Beta, continues to iterate with an industry-leading 78% non-hallucination rate. It features native 4-Agent multi-agent collaboration, a 2 million token context window, and support for voice conversations and image/video generation. This article provides a deep dive into its core capabilities and practical value.
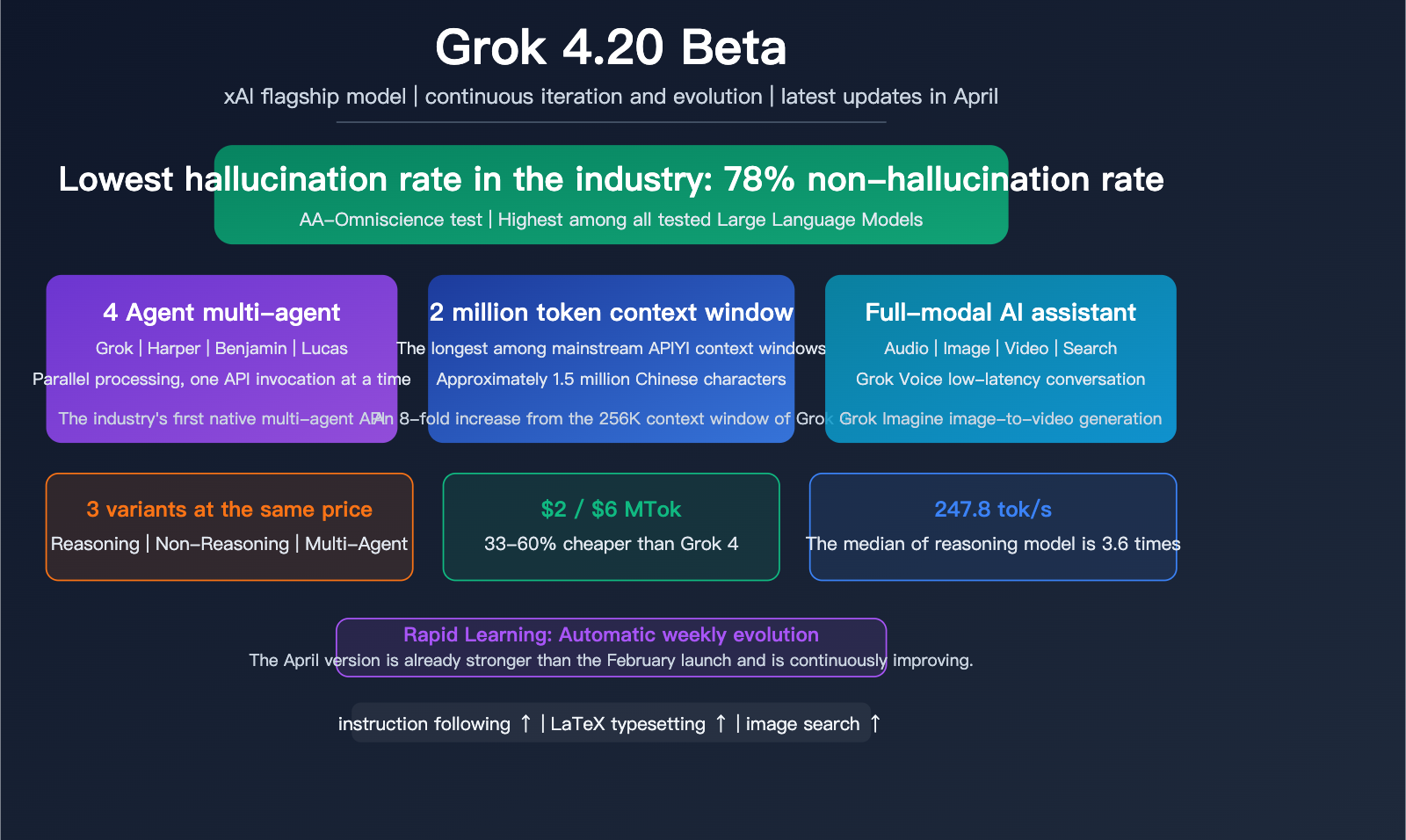
Elon Musk's xAI released the Grok 4.20 Beta in early 2026 and has been continuously iterating and optimizing it since. The most unique label for this model is its "industry-lowest hallucination rate"—achieving a 78% non-hallucination rate in Artificial Analysis Omniscience tests. It also introduces a native 4-Agent multi-agent architecture and a 2 million token context window. The latest April update further improves instruction following, LaTeX typesetting, and the accuracy of image search triggers.
Core Value: Spend 5 minutes to understand the core capabilities of Grok 4.20 Beta, the differences between its 3 model variants, its multimodal capabilities, and how it is positioned compared to Claude and GPT.
Grok 4.20 Beta Quick Overview
| Feature | Details |
|---|---|
| Release Date | Feb 17, 2026 (Beta) / Mar 10, 2026 (API) |
| Developer | xAI (Elon Musk) |
| Core Positioning | High-integrity + Multi-agent + Multimodal Flagship |
| Hallucination Rate | 78% non-hallucination rate (Industry best) |
| Context Window | 2 Million Tokens (Up from 256K in Grok 4) |
| Model Variants | Reasoning / Non-Reasoning / Multi-Agent |
| Output Speed | 247.8 tok/s (Median for reasoning models: 68.5) |
| Pricing | $2/MTok input, $6/MTok output |
| Multimodality | Text/Image/Video/Voice input and output |
Market Positioning of Grok 4.20 Beta
In the competitive landscape of Large Language Models, Grok 4.20 Beta has chosen a differentiated path: it doesn't aim for the highest score on every benchmark, but instead builds a unique advantage across three dimensions: integrity (low hallucination), speed, and multi-agent collaboration.
Its Artificial Analysis Intelligence Index score is 48, higher than the median of 31 for models in the same price range, though it still trails behind the top-tier scores of Claude Opus 4.5 and GPT-5.4. xAI's strategy is simple—rather than giving you a model that is occasionally stunning but frequently wrong, they'd rather give you a model that is consistently reliable.
Grok 4.20 Beta Core Capabilities Explained
Capability 1: Industry-Leading Low Hallucination Rate
The most prominent feature of Grok 4.20 Beta is its hallucination control:
| Evaluation | Grok 4.20 | Industry Average | Note |
|---|---|---|---|
| AA-Omniscience Non-hallucination Rate | 78% | ~60-70% | Industry Best |
| Instruction Following | Top-tier | – | Strict prompt adherence |
| LaTeX Typesetting | Continuous Optimization | – | Improved in April update |
A 78% non-hallucination rate means that when answering factual questions, Grok 4.20 is accurate in about 4 out of 5 responses—the highest among all tested models. For scenarios requiring high reliability (such as medical consultations, legal analysis, or academic research), a low hallucination rate can be more practically valuable than a higher "intelligence quotient."
Continuous April Optimizations: The latest iteration further improves instruction following and LaTeX mathematical formula typesetting, along with better accuracy for image search triggers.
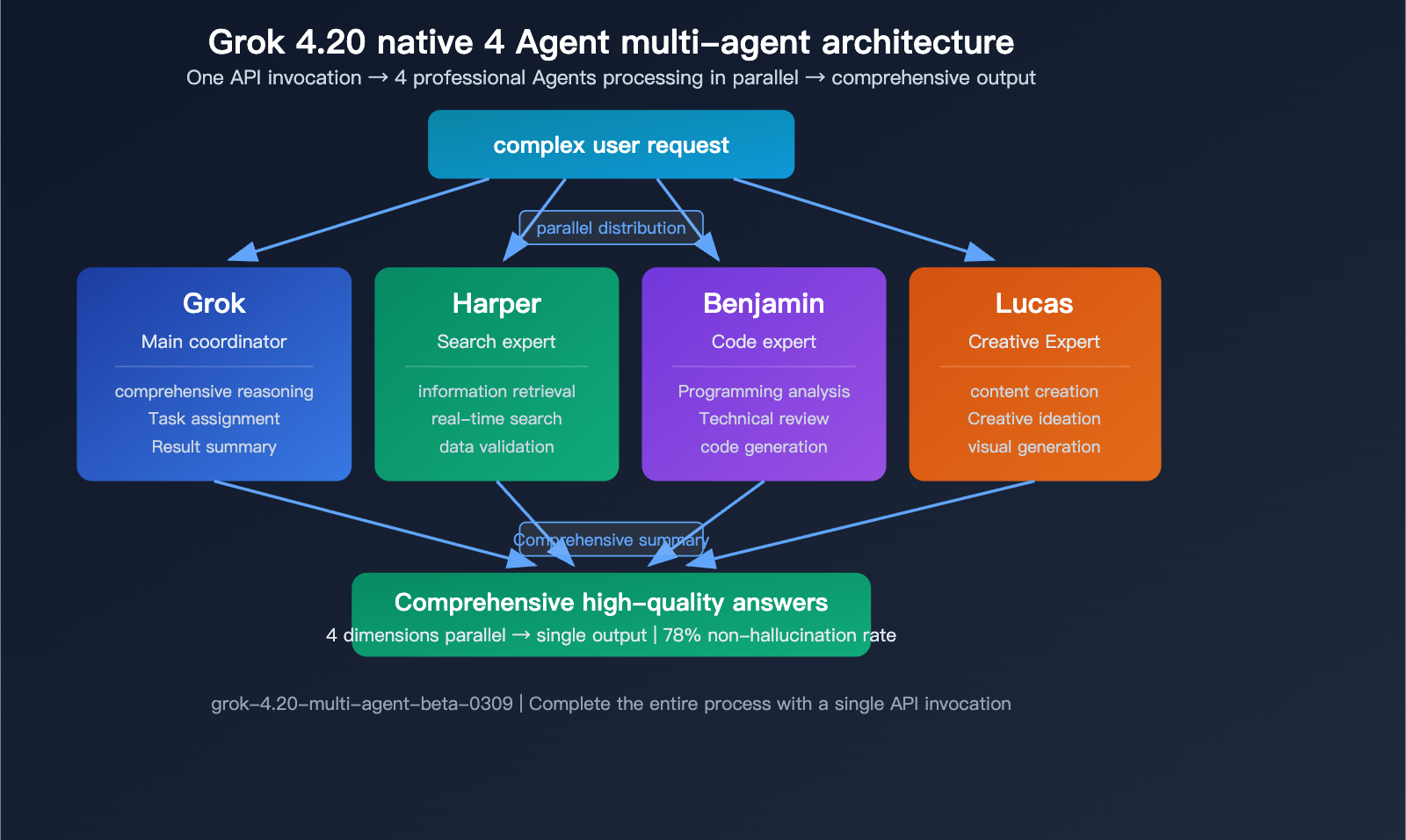
Capability 2: Native 4-Agent Multi-Agent Architecture
Grok 4.20 Beta introduces the industry's first native multi-agent API—a single API call triggers 4 specialized agents working in parallel in the background:
| Agent Name | Expertise | Role |
|---|---|---|
| Grok | Comprehensive reasoning and dialogue | Lead Coordinator |
| Harper | Research and information retrieval | Search Expert |
| Benjamin | Programming and technical analysis | Code Expert |
| Lucas | Creativity and content generation | Creative Expert |
When you send a complex query via the Multi-Agent API, the 4 agents work in parallel simultaneously, each leveraging their specific expertise, before Grok synthesizes the final output. This architecture is significantly more efficient when handling complex tasks that require multi-dimensional capabilities.
Capability 3: 2 Million Token Context Window
The context window for Grok 4.20 has jumped from the previous generation's 256K to 2 million tokens—currently the longest among all mainstream API models:
| Model | Context Window | Comparison |
|---|---|---|
| Grok 4.20 Beta | 2 Million Tokens | Industry Longest |
| GPT-5.4 (Extended) | 1 Million Tokens | 2x Grok |
| Claude Opus 4.5 | 200K Tokens | 10x Grok |
| Gemini 2.5 Pro | 1 Million Tokens | 2x Grok |
2 million tokens is roughly equivalent to 1.5 million Chinese characters or 3 million English words, enough to hold an entire long novel or a massive code repository.
🎯 Developer Tip: Grok 4.20 Beta offers unique advantages in hallucination control and context length. Through the APIYI (apiyi.com) API proxy service, you can access Grok 4.20 alongside Claude and GPT to compare the reliability and accuracy of different models for your specific tasks.
Grok 4.20 Beta: 3 Model Variants
The Grok 4.20 Model Family
xAI has released three distinct Grok 4.20 variants. They share the same pricing but offer different capabilities:
| Variant | Model ID | Core Capability | Best For |
|---|---|---|---|
| Non-Reasoning | grok-4.20-beta-0309-non-reasoning | Fast, direct answers | Daily chat, simple tasks |
| Reasoning | grok-4.20-beta-0309-reasoning | Deep chain-of-thought | Complex analysis, math |
| Multi-Agent | grok-4.20-multi-agent-beta-0309 | 4 Agents in parallel | Complex, multi-dimensional tasks |
Grok 4.20 Pricing Analysis
| Pricing Item | Grok 4.20 | Grok 4 (Previous Gen) | Change |
|---|---|---|---|
| Input | $2/MTok | $3/MTok | 33% lower |
| Output | $6/MTok | $15/MTok | 60% lower |
| Three Variants | Same price | – | Choose as needed |
Grok 4.20's pricing is highly competitive: at $2 for input and $6 for output, it's 33-60% cheaper than the previous Grok 4. Compared to competitors, the GPT-5.4 standard version is $2.5/$15, and Claude Opus 4.5 is even pricier. Among models in this price range, Grok 4.20 boasts the lowest hallucination rate and the fastest speed (247.8 tok/s).
Grok 4.20 Rapid Learning Architecture
A unique feature of Grok 4.20 is its Rapid Learning architecture: the model automatically updates its capabilities weekly based on real user data, without needing manual version releases. This means the Grok 4.20 you use keeps getting better over time—the April version of Grok 4.20 is already more powerful than the February version.
💡 Differentiated Advantage: Rapid Learning is exclusive to Grok—other models require a new version number for updates, whereas Grok 4.20 evolves continuously within the same version. This is why "continuous April iteration" is particularly important for Grok users.
Grok 4.20 Beta Multimodal Capabilities
The Complete Grok 4.20 Multimodal Matrix
| Modality | Input | Output | Notes |
|---|---|---|---|
| Text | ✓ | ✓ | Core capability |
| Image | ✓ | ✓ | Grok Imagine API |
| Video | ✓ | ✓ | End-to-end video generation |
| Voice | ✓ | ✓ | Grok Voice low latency |
| Code | ✓ | ✓ | Benjamin Agent specialty |
| Search | – | ✓ | Real-time web search |
Grok Voice Capabilities
Grok Voice is one of the most distinct multimodal features in Grok 4.20:
- Low-Latency Voice: Supports real-time voice conversations in dozens of languages.
- Tool Use: Triggers tool calls and searches directly from voice mode.
- Real-Time Data: Accesses live web data during voice conversations.
- Agent API: Integrates into third-party applications via API.
This makes Grok 4.20 more than just a text model; it's a full-modality AI assistant that can "hear, speak, see, and search."
Grok Imagine: Image and Video Generation
xAI has introduced the Grok Imagine API in Grok 4.20—a unified suite for end-to-end video and audio generation. It supports generating images and videos from text descriptions, and image search accuracy was further improved in the April update.

Grok 4.20 Beta vs. Competitors
Grok 4.20 vs. GPT-5.4 vs. Claude Opus 4.5
| Comparison Dimension | Grok 4.20 Beta | GPT-5.4 | Claude Opus 4.5 |
|---|---|---|---|
| Hallucination Rate | 78% (Lowest) | ~65% | ~70% |
| Intelligence Index | 48 | ~55+ | ~55+ |
| Context Window | 2 Million Tokens | 272K-1M | 200K |
| Output Speed | 247.8 tok/s | ~100 tok/s | ~80 tok/s |
| Input Price | $2/MTok | $2.5/MTok | Higher |
| Output Price | $6/MTok | $15/MTok | Higher |
| Multi-Agent | Native 4 Agents | None | None |
| Voice Chat | Native Support | Limited | None |
| Computer Control | None | Native Support | Limited |
| Coding Benchmarks | Above Average | Top-tier | Top-tier |
Grok 4.20 Strengths: Hallucination control, speed, pricing, context window length, multi-agent capabilities, and voice.
Grok 4.20 Weaknesses: Pure intelligence/reasoning benchmarks and specialized coding benchmarks.
Selection Advice: If you prioritize answer accuracy and reliability, Grok 4.20 is your top choice. If you prioritize coding prowess and complex reasoning, Claude or GPT are stronger contenders.
🚀 Comparison Tip: Through APIYI (apiyi.com), you can access Grok 4.20, GPT-5.4, and Claude simultaneously. Use a single API key to switch freely between these three models and quickly find the one that best fits your specific use case.
Grok 4.20 Beta API Integration
Quick Access via APIYI
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# Non-Reasoning mode (for fast responses)
response = client.chat.completions.create(
model="grok-4.20-beta-0309-non-reasoning",
messages=[{"role": "user", "content": "Explain the basic principles of quantum computing"}]
)
print(response.choices[0].message.content)
View Reasoning and Multi-Agent mode invocations
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# Reasoning mode (for deep analysis)
response = client.chat.completions.create(
model="grok-4.20-beta-0309-reasoning",
messages=[{"role": "user", "content": "Analyze the risk factors in the global AI chip supply chain"}]
)
# Multi-Agent mode (4 Agents working in parallel)
response = client.chat.completions.create(
model="grok-4.20-multi-agent-beta-0309",
messages=[{
"role": "user",
"content": "Write a research report on the commercial prospects of quantum computing"
}]
)
# 4 Agents (Grok/Harper/Benjamin/Lucas) processing in parallel
print(response.choices[0].message.content)
💰 Cost Advantage: Grok 4.20's $2/$6 pricing is among the lowest for current flagship models. Using APIYI (apiyi.com) for model invocation can further optimize your costs while allowing you to switch between Grok, Claude, GPT, and Gemini on demand.
FAQ
Q1: Which of the three Grok 4.20 variants should I choose?
For daily conversations, go with Non-Reasoning (it's the fastest). For complex analysis, choose Reasoning (it digs deeper). For multi-dimensional, complex tasks, opt for Multi-Agent (which runs 4 Agents in parallel). All three variants are priced the same ($2/$6 MTok), so you can switch between them freely based on your task. You can access all variants using a single API key from APIYI (apiyi.com).
Q2: What does it mean that Grok 4.20 has the lowest hallucination rate?
A 78% non-hallucination rate means that when it comes to factual answers, Grok is less likely to "make things up" compared to other models. For scenarios requiring high reliability—like medicine, law, academia, or corporate decision-making—this is more valuable than a higher "intelligence index." However, for creative writing and brainstorming, a moderate amount of "hallucination" can actually be an advantage.
Q3: Will Grok 4.20 continue to be updated?
Yes. Grok 4.20 uses a Rapid Learning architecture, which automatically optimizes based on user data every week. The April update has already improved instruction following, LaTeX formatting, and image search. The capabilities under the same model ID will continue to improve, so there's no need to wait for a new version number. When you use the APIYI (apiyi.com) API proxy service, you'll automatically benefit from the latest optimizations.
Summary
The core value proposition of Grok 4.20 Beta:
- Industry-lowest hallucination rate: A 78% non-hallucination rate provides a unique advantage in scenarios requiring high reliability.
- Native multi-agent system: 4 Agents (Grok/Harper/Benjamin/Lucas) collaborate in parallel, making it more efficient for complex tasks.
- 2 million token context window: The longest among mainstream API models, paired with a speed of 247.8 tok/s.
- Continuous evolution: Rapid Learning updates automatically every week; the April version is already stronger than the February launch.
Grok 4.20 Beta has taken a differentiated path—instead of trying to be the best at everything, it leads the industry in reliability, speed, and multi-agent capabilities. We recommend using APIYI (apiyi.com) to access Grok 4.20 alongside Claude and GPT. With one API key, you can compare models to find the best fit for your specific use case.
📚 References
-
xAI Official Grok 4.20 Updates: Latest news and feature announcements
- Link:
x.ai/news - Description: Includes the continuous iteration logs and feature updates for Grok 4.20
- Link:
-
Artificial Analysis – Grok 4.20 Evaluation: Independent third-party reviews and data
- Link:
artificialanalysis.ai/models/grok-4-20 - Description: Features detailed analysis of intelligence metrics, hallucination rates, speed, and pricing
- Link:
-
Grok 4.20 Multi-Agent Deep Dive: A complete comparison of the 4 model variants
- Link:
help.apiyi.com/en/grok-4-20-beta-4-models-multi-agent-reasoning-api-guide-en.html - Description: Covers detailed use cases for Reasoning, Non-Reasoning, and Multi-Agent models
- Link:
-
Grok 4.20 Beta Comprehensive Guide: In-depth analysis of architecture and features
- Link:
buildfastwithai.com/blogs/grok-4-20-beta-explained-2026 - Description: Includes a detailed breakdown of the Rapid Learning architecture and multimodal capabilities
- Link:
Author: APIYI Technical Team
Community: We'd love to hear about your experience with Grok 4.20 in the comments! For more resources on integrating AI models, visit the APIYI documentation center at docs.apiyi.com.