6 мая 2026 года компания xAI разослала всем пользователям API официальное письмо с темой «Grok 4.3 release and xAI API model retirement». В нем содержались две критически важные новости: Grok 4.3 стал доступен в API в полном объеме, а восемь устаревших моделей (включая grok-4-fast, grok-4-0709, grok-3, grok-code-fast-1, grok-imagine-image-pro и другие) будут отключены 15 мая 2026 года в 12:00 по тихоокеанскому времени. Это обновление знаменует собой не только важный релиз, но и начало девятидневного обратного отсчета для миграции.
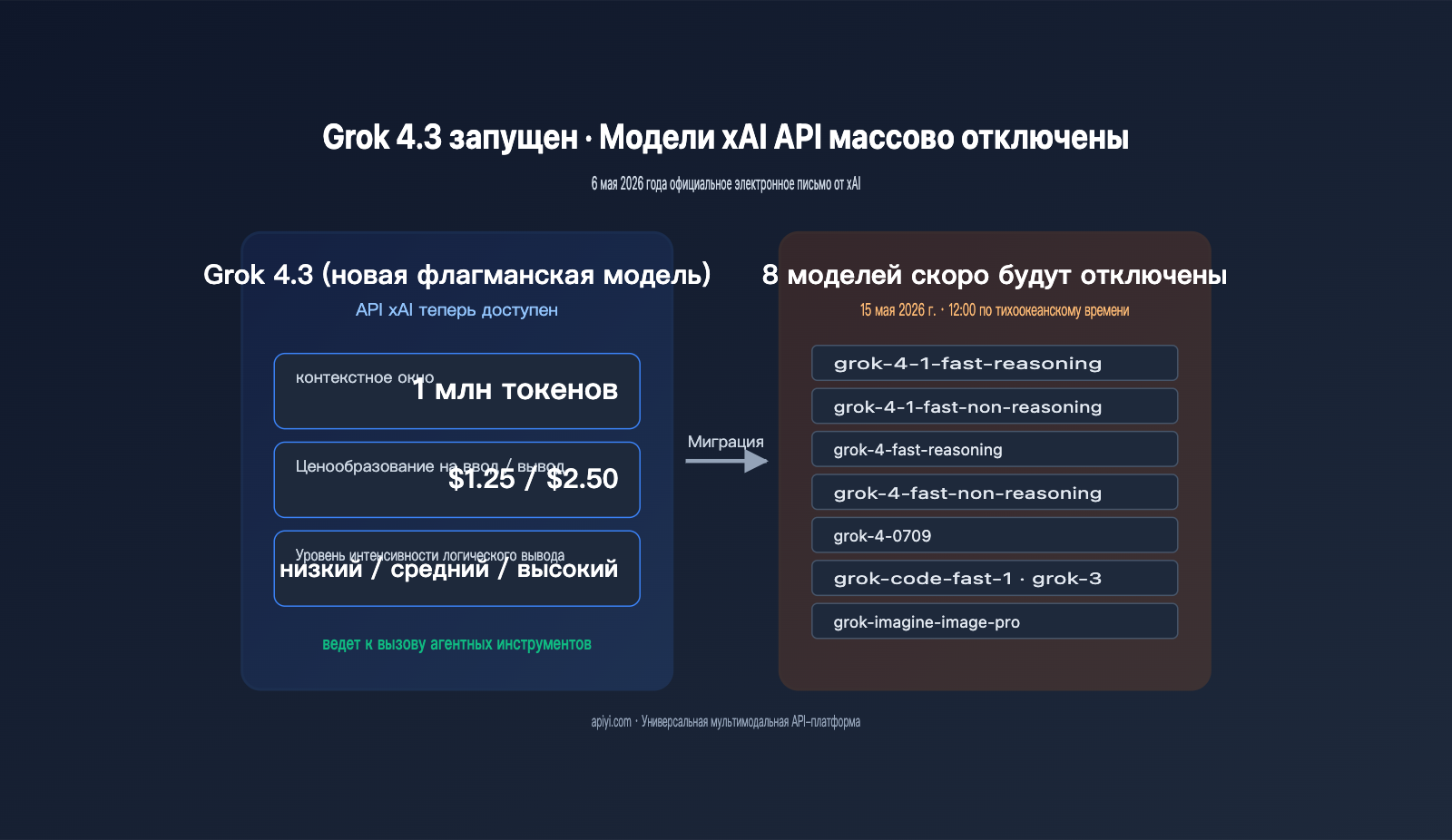
Самое примечательное в релизе Grok 4.3 — это не просто смена версии, а сочетание контекстного окна в 1 млн токенов, ценообразования $1.25/$2.50 за входные/выходные данные и трех уровней интенсивности рассуждений. Такая ценовая категория ставит Grok 4.3 в один ряд с Gemini 3.1 Pro и GPT-5.4, при этом модель сохраняет высокую скорость обработки токенов, характерную для xAI. Мы рекомендуем командам, использующим семейство моделей Grok, как можно скорее провести тестирование через платформу APIYI (apiyi.com). Универсальный интерфейс, совместимый с OpenAI, позволит свести к минимуму затраты на миграцию при переключении между моделями.
Полный обзор характеристик и цен Grok 4.3
Grok 4.3 — это флагманская модель последнего поколения, которую xAI в своем письме назвала «самой быстрой и интеллектуальной моделью, которую мы когда-либо создавали». Она занимает лидирующие позиции в рейтингах по вызову инструментов (agentic tool calling) и следованию инструкциям (instruction following), позиционируясь как универсальное решение для написания кода, работы агентов и сложных логических задач. Контекстное окно было расширено с 256 тыс. токенов в эпоху Grok 4 до 1 млн, что позволяет загружать в модель целые кодовые базы или объемные технические документы.
В таблице ниже собраны ключевые параметры Grok 4.3 в xAI API, основанные на официальных данных xAI и независимых тестах Artificial Analysis.
| Параметр | Значение Grok 4.3 | Примечание |
|---|---|---|
| Контекстное окно | 1 000 000 токенов | Вход + выход |
| Цена за вход | $1.25 / 1 млн токенов | На 50% дешевле GPT-5.4, на уровне Gemini 3.1 Pro |
| Цена за выход | $2.50 / 1 млн токенов | Снижение на ~83% по сравнению с $15 у Grok 4 |
| Интенсивность рассуждений | 3 уровня: low / medium / high | Управление глубиной логического вывода |
| Входные модальности | Текст + изображения | Поддержка визуального понимания |
| Выходные модальности | Текст | Генерация изображений не поддерживается |
| Вызов инструментов | Нативный function calling | Поддержка структурированного вывода и параллельных вызовов |
| Скорость вывода | ~207 токенов/с | По данным Artificial Analysis |
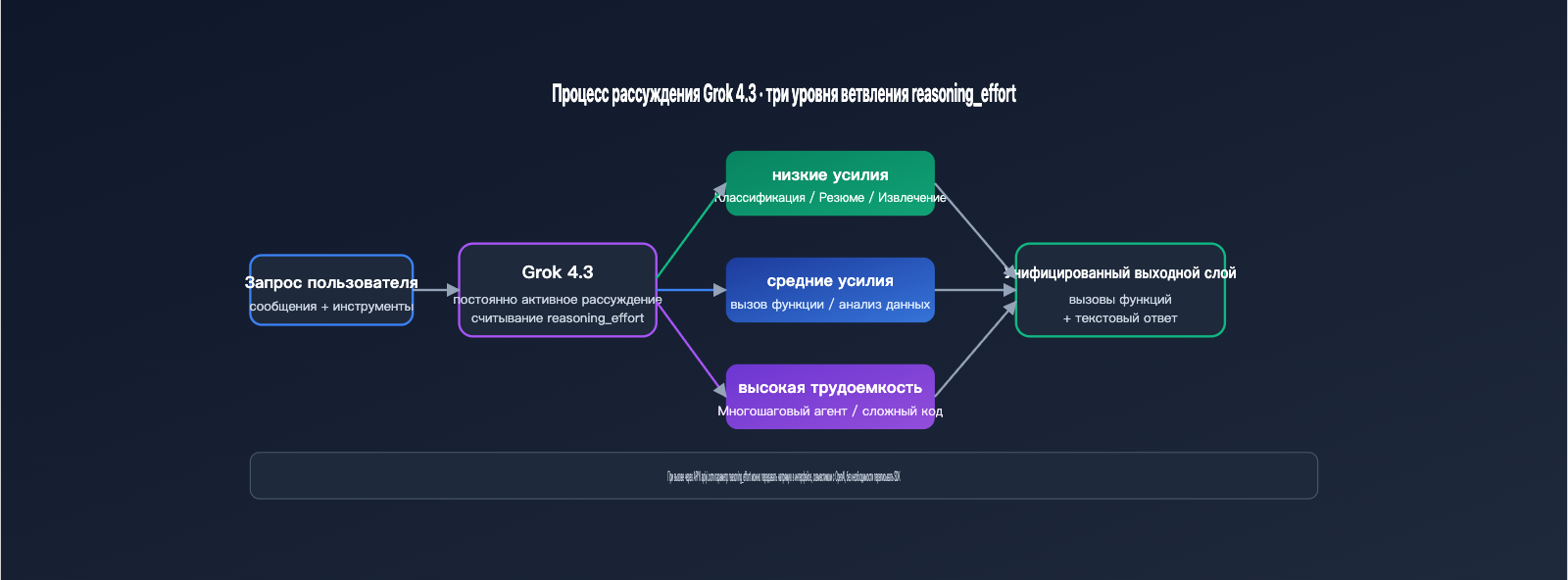
Три уровня интенсивности рассуждений (reasoning effort) — ключевая особенность Grok 4.3, позволяющая разработчикам регулировать глубину «мышления» модели в зависимости от сложности задачи, что напрямую влияет на задержку и стоимость. Этот механизм заимствован из концепции reasoning_effort в OpenAI, однако xAI сделала рассуждения «всегда включенными», предоставив возможность лишь настраивать их глубину. В таблице ниже приведены типичные сценарии использования для каждого уровня.
| Интенсивность | Типичные сценарии | Задержка | Влияние на стоимость |
|---|---|---|---|
| low | Простая классификация, суммаризация, извлечение данных | Минимальная | Минимальный расход токенов |
| medium | Вызов функций, анализ данных, автодополнение кода | Сбалансированная | Рекомендуемый уровень по умолчанию |
| high | Многошаговые агенты, сложная математика, длинный код | Высокая (из-за этапа мышления) | Значительное увеличение токенов |
🎯 Совет по интеграции: Если вы не уверены, какой уровень выбрать, рекомендуем сначала протестировать реальные бизнес-задачи на платформе APIYI (apiyi.com) с уровнем
medium, а затем решить, стоит ли переходить наhighисходя из точности и затрат. Единый интерфейс позволяет менять параметрreasoning_effortмежду моделями без переписывания SDK.
Результаты тестирования Grok 4.3 в рейтингах агентных возможностей и следования инструкциям
Причина, по которой xAI в своей рассылке сделала акцент на том, что Grok 4.3 «возглавляет рейтинги по агентному вызову инструментов и следованию инструкциям», кроется в данных от независимых площадок: Artificial Analysis, τ²-Bench, IFBench, GDPval-AA и других. Согласно индексу Artificial Analysis Intelligence Index, модель получила общую оценку 53,2, а стоимость прохождения полного цикла тестирования составила около $395, что примерно на 20% дешевле, чем у Grok 4.20. В бенчмарке τ²-Bench Telecom (симуляция двустороннего вызова инструментов в техподдержке), который максимально приближен к реальным сценариям работы агентов, Grok 4.3 набрал 98%, улучшив результат Grok 4.20 на 5 процентных пунктов и сравнявшись с GLM-5.1.
Для разработчиков куда важнее бенчмарк GDPval-AA, оценивающий реальную экономическую ценность рабочих процессов. В нем Grok 4.3 набрал 1500 ELO, что на 321 балл выше результата предыдущей версии Grok 4.20 0309 v2 (1179 ELO). Это позволило модели обойти Gemini 3.1 Pro Preview, Muse Spark, GPT-5.4 mini (xhigh), Kimi K2.5 и другие. Что касается следования инструкциям, Grok 4.3 удерживает планку в 81% в IFBench, что соответствует показателям Grok 4.20 0309 v2.
| Бенчмарк | Результат Grok 4.3 | Сравнение | Основной навык |
|---|---|---|---|
| AA Intelligence Index | 53.2 | Лучше 98% моделей | Общий интеллект |
| AA Coding Index | 41.0 | Лучше 89% моделей | Код и рефакторинг |
| τ²-Bench Telecom | 98% | На уровне GLM-5.1 | Вызов инструментов + взаимодействие |
| IFBench | 81% | На уровне Grok 4.20 | Сложное следование инструкциям |
| GDPval-AA | ELO 1500 | Выше Gemini 3.1 Pro Preview | Реальная ценность рабочих процессов |
Важно понимать: сильная сторона Grok 4.3 — это агентные рабочие процессы и вызов инструментов, а не чисто алгоритмические соревнования. Для таких приложений, как кодинг-агенты, браузерные агенты или боты техподдержки, где критически важен стабильный вывод JSON и многошаговые вызовы инструментов, надежность Grok 4.3 будет заметно выше, чем у предшественника. Однако, если ваш основной сценарий — это синтез кода в стиле SWE-bench, мы рекомендуем протестировать Grok 4.3, Claude 4.7 Opus и GPT-5.4 на одном и том же наборе данных через платформу APIYI (apiyi.com), чтобы принять решение о выборе основной модели на основе процента успешных выполнений.
Список моделей xAI, уходящих в архив, и рекомендации по миграции
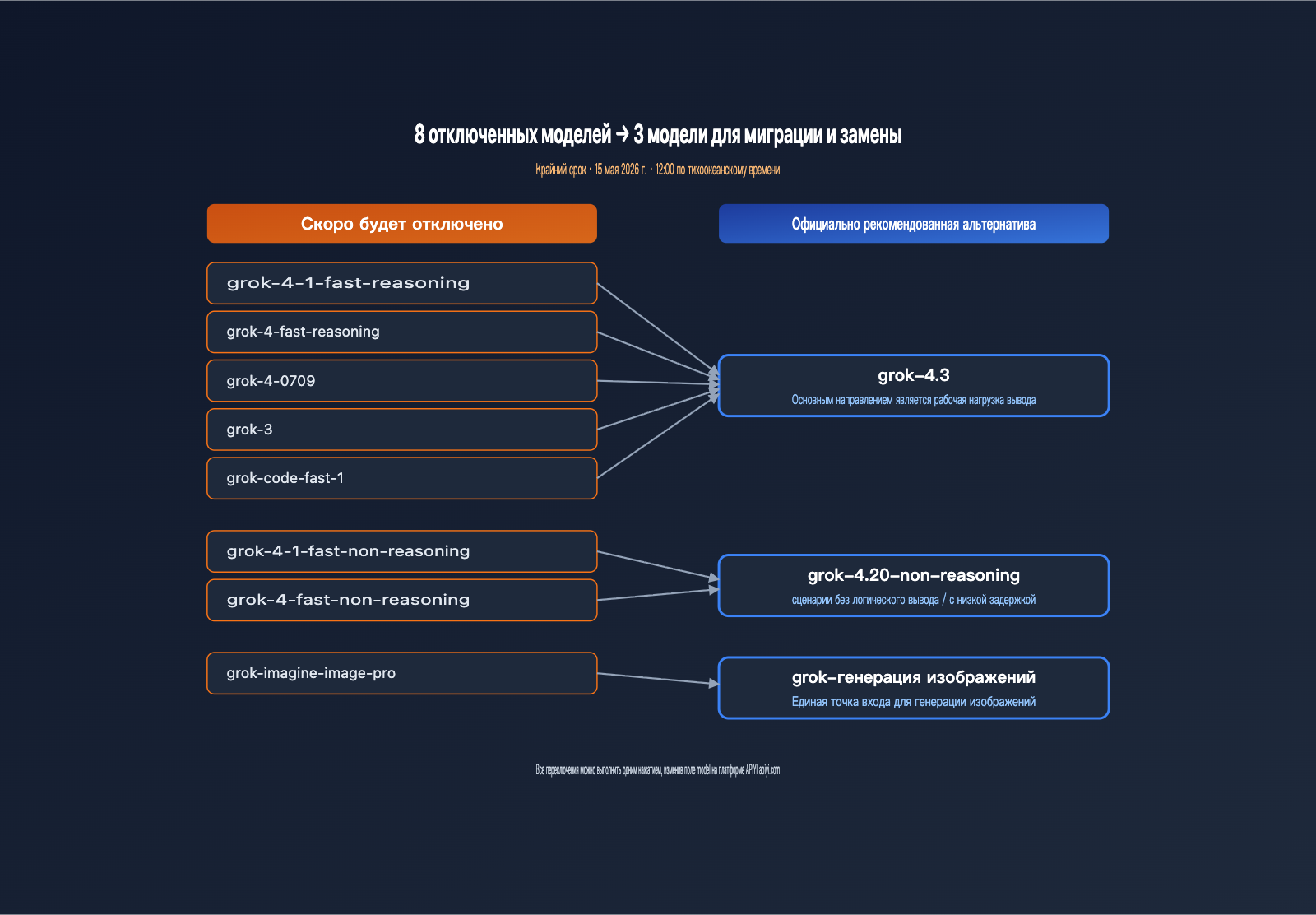
xAI одновременно выводит из эксплуатации 8 моделей, включая решения для текстовых рассуждений, генерации кода и изображений — по сути, компания разом «зачищает» весь стек эпохи Grok 4. Если в вашем проекте названия моделей прописаны жестко (hard-code), вам необходимо обновить код в течение 9 дней. В таблице ниже собраны все затронутые модели и официальные пути миграции.
| Модель под списание | Тип | Рекомендуемая замена | Примечание по миграции |
|---|---|---|---|
| grok-4-1-fast-reasoning | Рассуждение | grok-4.3 | Выше качество, ниже цена |
| grok-4-1-fast-non-reasoning | Без рассуждений | grok-4.20-non-reasoning | Сохранение низкой задержки |
| grok-4-fast-reasoning | Рассуждение | grok-4.3 | Доступ к контекстному окну 1M |
| grok-4-fast-non-reasoning | Без рассуждений | grok-4.20-non-reasoning | Полная совместимость API |
| grok-4-0709 | Рассуждение | grok-4.3 | Устаревший снапшот Grok 4 |
| grok-code-fast-1 | Код | grok-4.3 | Унификация кодинг-сценариев |
| grok-3 | Общая | grok-4.3 | Официальный конец эпохи Grok 3 |
| grok-imagine-image-pro | Генерация изображений | grok-imagine-image | Упрощение SKU генерации |
Дата отключения — 15 мая 2026 года, 12:00 по тихоокеанскому времени (16 мая, 03:00 по МСК). После этого все запросы к этим 8 ID будут возвращать ошибку. С момента рассылки уведомления (6 мая) у разработчиков есть всего 9 дней — для крупных проектов это крайне сжатые сроки. Мы советуем разбить миграцию на 3 этапа: сначала найти все жестко прописанные ID моделей в коде, затем провести нагрузочное тестирование на платформе APIYI (apiyi.com), и, наконец, переключать поле model через переменные окружения, не затрагивая основную логику приложения.
Отдельно отметим, что grok-code-fast-1 был моделью по умолчанию для многих проектов с кодинг-агентами в последние полгода. Его отключение означает, что все инструменты типа Cursor, IDE-плагины и CLI-агенты, зависящие от этого ID, должны быть переведены на grok-4.3. В задачах программирования стабильность вызова инструментов у Grok 4.3 выше, чем у grok-code-fast-1, но стоимость за токен немного выше, поэтому стоит пересчитать бюджет на вызовы.
Сравнительный анализ Grok 4.3, GPT-5.4, Claude 4.7 и Gemini 3.1 Pro
К моменту выхода Grok 4.3 во втором квартале 2026 года рынок передовых моделей переживает период самой жесткой конкуренции в истории. Claude Opus 4.7 удерживает лидерство с показателем 87,6% в SWE-bench Verified, Gemini 3.1 Pro достигает 94,3% в GPQA Diamond, а GPT-5.4 остается эталоном стабильности при рассуждениях на длинных текстах. Позиционирование Grok 4.3 — это «средний интеллект + крайне низкая цена + мощная цепочка инструментов для агентов», что делает её идеальной для высокочастотных сценариев, чувствительных к затратам.
В таблице ниже собраны ключевые показатели четырех флагманских моделей. Цены указаны в долларах за миллион токенов.
| Модель | Цена на вход | Цена на выход | Контекстное окно | Основные сценарии |
|---|---|---|---|---|
| Grok 4.3 | $1.25 | $2.50 | 1M | Агентные цепочки, частые вызовы, средние задачи |
| GPT-5.4 | $2.50 | $15.00 | 400K | Длинные тексты, сложное планирование |
| Claude 4.7 Opus | $15.00 | $75.00 | 1M | Топ-кодинг, написание документации, глубокий анализ |
| Gemini 3.1 Pro | $2.00 | $12.00 | 2M | Мультимодальность, видео, сверхдлинные документы |
Из таблицы видно главное: стоимость выходных токенов у Grok 4.3 в 30 раз ниже, чем у Claude 4.7 Opus, и примерно в 4,8 раза ниже, чем у Gemini 3.1 Pro. Для таких задач, как агентская поддержка клиентов, линтинг кода или пакетная очистка данных, преимущество Grok 4.3 в стоимости будет колоссальным. Однако в задачах, требующих высочайшего качества кода или глубокого мультимодального понимания, Claude 4.7 Opus и Gemini 3.1 Pro остаются незаменимыми.
🎯 Рекомендация по мультимодельной стратегии: Мы советуем использовать Grok 4.3 для высокочастотных общих задач, Claude 4.7 Opus — для сложного кода и подготовки документации, а Gemini 3.1 Pro — для мультимодальных задач. Используя единый интерфейс APIYI (apiyi.com) для маршрутизации, вы сможете не только экономить на Grok 4.3, но и подключать более мощные модели в критических узлах.
Руководство по миграции на API Grok 4.3 и примеры кода
Переход на Grok 4.3 с инженерной точки зрения максимально прост: xAI предоставляет интерфейс chat completions, совместимый с OpenAI. Большая часть работы сводится к изменению base_url и поля model. Для проектов, уже использующих SDK OpenAI, ниже приведен минималистичный пример кода на Python.
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1",
)
resp = client.chat.completions.create(
model="grok-4.3",
messages=[
{"role": "user", "content": "Объясни в одном предложении, что такое reasoning effort"},
],
extra_body={"reasoning_effort": "medium"},
)
print(resp.choices[0].message.content)
Направив base_url на платформу APIYI (apiyi.com), вы получаете единую точку входа для вызова Grok 4.3, Claude 4.7, GPT-5.4 и Gemini 3.1 Pro. В дальнейшем для переключения между моделями достаточно изменить параметр model, не переписывая логику аутентификации и маршрутизации. Такая унификация значительно снижает риски при миграции до крайнего срока (15 мая).
Для перехода со старых моделей мы подготовили таблицу соответствия идентификаторов, которую можно сразу использовать в коде.
| Старый ID модели | Новый ID модели | Нужны ли другие параметры? |
|---|---|---|
| grok-3 | grok-4.3 | Опционально: reasoning_effort |
| grok-4-0709 | grok-4.3 | Опционально: reasoning_effort |
| grok-4-fast-reasoning | grok-4.3 | Опционально: reasoning_effort |
| grok-4-fast-non-reasoning | grok-4.20-non-reasoning | Не требуется |
| grok-code-fast-1 | grok-4.3 | Рекомендуется reasoning_effort=high |
| grok-imagine-image-pro | grok-imagine-image | Эндпоинт API для изображений остается прежним |
Часто задаваемые вопросы (FAQ) по Grok 4.3
В1: Действительно ли Grok 4.3 поддерживает контекстное окно 1M? Снижается ли производительность при работе с длинными текстами?
Да, Grok 4.3 официально предоставляет контекстное окно 1M токенов через API xAI, что соответствует уровню Claude 4.7 Opus. Однако, как и у любой модели с большим контекстом, после 600K токенов понимание запроса может немного снижаться. Мы рекомендуем размещать ключевую информацию в первой половине документа. Вы можете использовать платформу APIYI (apiyi.com), чтобы провести тест на полноту поиска (recall) с реальными длинными документами, прежде чем переводить Grok 4.3 в статус основной модели для работы с длинными текстами.
В2: Как выбрать интенсивность рассуждений (low / medium / high)?
Используйте low для задач с низким риском (классификация, суммаризация, извлечение правил), medium — для стандартных бизнес-задач (поддержка клиентов, вызов функций, анализ данных), и high — для сложного логического вывода (многошаговые агенты, длинные цепочки кода, сложная математика). Режим high значительно увеличивает количество выходных токенов и задержку (latency), поэтому рекомендуем оценивать выбор с учетом бюджета и SLA по времени отклика.
В3: Можно ли будет использовать старые модели после 12:00 PT 15 мая?
Нет. В письме от xAI четко указано: «After May 15, 2026, requests to these models will no longer work» (После 15 мая 2026 года запросы к этим моделям больше не будут работать). Просроченные запросы будут возвращать ошибку. Весь код, где ID старых моделей прописаны жестко (hard-code), должен быть обновлен до указанного срока.
В4: Как минимизировать затраты на миграцию?
Самый надежный способ — вынести поле model в переменные окружения или конфигурационные файлы, вместо того чтобы прописывать его напрямую в коде. В сочетании с совместимым с OpenAI интерфейсом от APIYI (apiyi.com) миграция сведется к изменению одной строки в конфигурации и проведению регрессионного тестирования.
В5: Подходит ли Grok 4.3 для создания Coding Agent?
Да. Grok 4.3 набрал 98% в тесте τ²-Bench Telecom. Стабильность вызова инструментов и многоходовых диалогов у него выше, чем у grok-code-fast-1, а стоимость за единицу вызова крайне низка. Это делает его отличным выбором для часто используемых IDE-плагинов, CLI-агентов и скриптов автоматизации обслуживания.
Итоги: основные моменты запуска Grok 4.3 и миграции на API xAI
Главная особенность релиза Grok 4.3 заключается не просто в том, что модель стала «сильнее», а в том, что она стала «сильнее при меньшей стоимости». Цена $1.25/$2.50 выводит xAI с контекстным окном 1M и качественными инструментами для агентов в тот же ценовой сегмент, что и Gemini 3.1 Pro, фактически переопределяя стандарты соотношения цены и качества для высокочастотных задач. В то же время массовое отключение 8 старых моделей 15 мая — это напоминание всем командам: ID моделей не должны быть жестко «зашиты» в бизнес-логику, их следует абстрагировать за настраиваемым уровнем маршрутизации.
Мы рекомендуем сделать Grok 4.3 основной моделью для высокочастотных вызовов и агентских цепочек инструментов. Используйте унифицированный интерфейс APIYI (apiyi.com), чтобы минимизировать затраты на переключение, сохраняя при этом возможность комбинировать разные модели (Claude 4.7 Opus, GPT-5.4, Gemini 3.1 Pro) и динамически распределять задачи для достижения оптимального баланса между стоимостью и качеством.
Техническая команда APIYI · Мы следим за практическими аспектами работы с API моделей ИИ и инструментами для разработчиков. Больше технических статей на сайте apiyi.com