في 6 مايو 2026، أرسلت xAI بريداً إلكترونياً رسمياً لجميع مستخدمي API بعنوان "إصدار Grok 4.3 وإيقاف نماذج xAI API القديمة"، حاملاً معه خبرين جوهريين للمطورين: الإطلاق الكامل لنموذج Grok 4.3 عبر API، بالتزامن مع إيقاف 8 نماذج قديمة (بما في ذلك grok-4-fast، وgrok-4-0709، وgrok-3، وgrok-code-fast-1، وgrok-imagine-image-pro) في 15 مايو 2026 الساعة 12:00 بتوقيت المحيط الهادئ. يمثل هذا البريد ليس فقط تحديثاً رئيسياً للإصدار، بل عدداً تنازلياً للترحيل يجب إتمامه في غضون 9 أيام فقط.
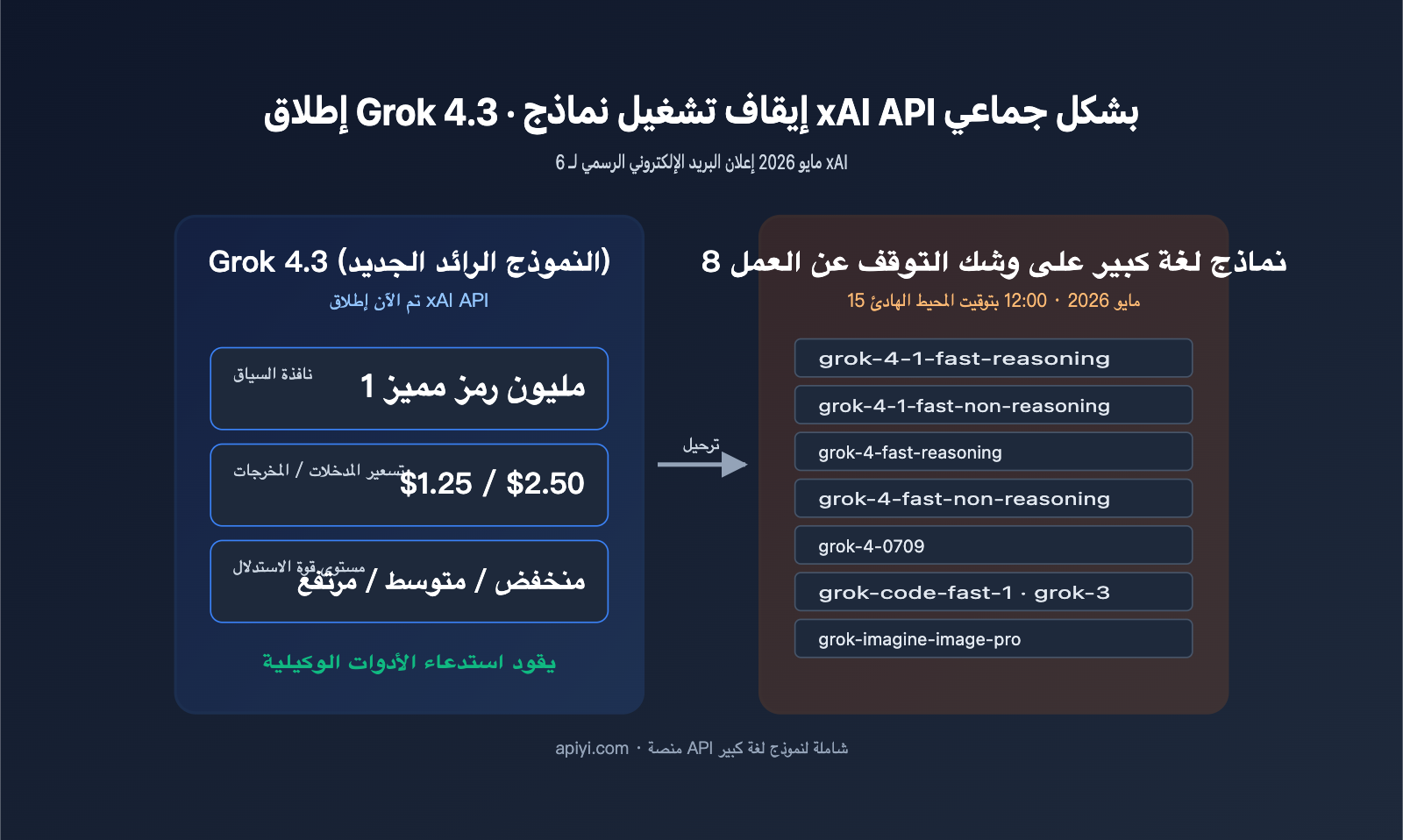
إن أهم ما يميز إصدار Grok 4.3 ليس مجرد تغيير الاسم، بل نافذة السياق التي تصل إلى 1 مليون token، وتسعير المدخلات والمخرجات بـ 1.25 دولار / 2.50 دولار، بالإضافة إلى 3 مستويات قابلة للتعديل من قوة الاستنتاج. تضع هذه الأسعار نموذج Grok 4.3 في منافسة مباشرة مع نماذج الاستنتاج السائدة مثل Gemini 3.1 Pro وGPT-5.4، مع الحفاظ على ميزة xAI المعهودة في سرعة معالجة الـ token. ننصح الفرق التي تعتمد على سلسلة Grok بالبدء في اختبارات الربط عبر منصة APIYI (apiyi.com) في أقرب وقت ممكن، حيث تتيح الواجهة المتوافقة مع OpenAI تقليل تكاليف الترحيل عند التبديل بين النماذج المختلفة.
تحليل شامل لمواصفات وتسعير Grok 4.3
يُعد Grok 4.3 أحدث جيل من النماذج الرائدة التي وصفتها xAI في بريدها الإلكتروني بأنها "أسرع وأذكى نموذج قمنا ببنائه على الإطلاق". يحتل النموذج مراكز متقدمة في قوائم تصنيف استدعاء الأدوات (agentic tool calling) واتباع التعليمات (instruction following)، وهو مصمم ليكون نموذجاً رائداً للأغراض العامة يغطي البرمجة، والوكلاء (Agents)، والاستنتاج المعقد. ومن حيث المواصفات، وسعت xAI نافذة السياق في Grok 4.3 من 256 ألف token في عصر Grok 4 إلى 1 مليون token مباشرة، وهو ما يضاهي Gemini 3 Pro وClaude 4.7، مما يعني إمكانية إدخال مستودع برمجيات كامل أو وثائق تقنية طويلة في طلب واحد.
يلخص الجدول التالي المعايير الأساسية لنموذج Grok 4.3 عبر xAI API، وجميع البيانات مستمدة من البريد الإلكتروني الرسمي لـ xAI وصفحة الاختبارات المستقلة من Artificial Analysis.
| المعيار | قيمة Grok 4.3 | ملاحظات |
|---|---|---|
| نافذة السياق | 1,000,000 token | المدخلات + المخرجات مشتركة |
| تسعير المدخلات | 1.25 دولار / 1 مليون token | أقل بنسبة 50% من GPT-5.4، ومساوٍ لـ Gemini 3.1 Pro |
| تسعير المخرجات | 2.50 دولار / 1 مليون token | انخفاض بنسبة 83% تقريباً عن سعر عصر Grok 4 البالغ 15 دولاراً |
| قوة الاستنتاج | 3 مستويات (منخفض / متوسط / مرتفع) | التحكم في ميزانية الاستنتاج العميق عبر المعاملات |
| نمط المدخلات | نص + صور | يدعم الفهم البصري |
| نمط المخرجات | نص | لا يدعم توليد الصور مباشرة |
| استدعاء الأدوات | استدعاء الوظائف الأصلي (function calling) | يدعم المخرجات المهيكلة والاستدعاء المتوازي |
| سرعة المخرجات | حوالي 207 tokens/s | وفقاً لاختبارات Artificial Analysis |
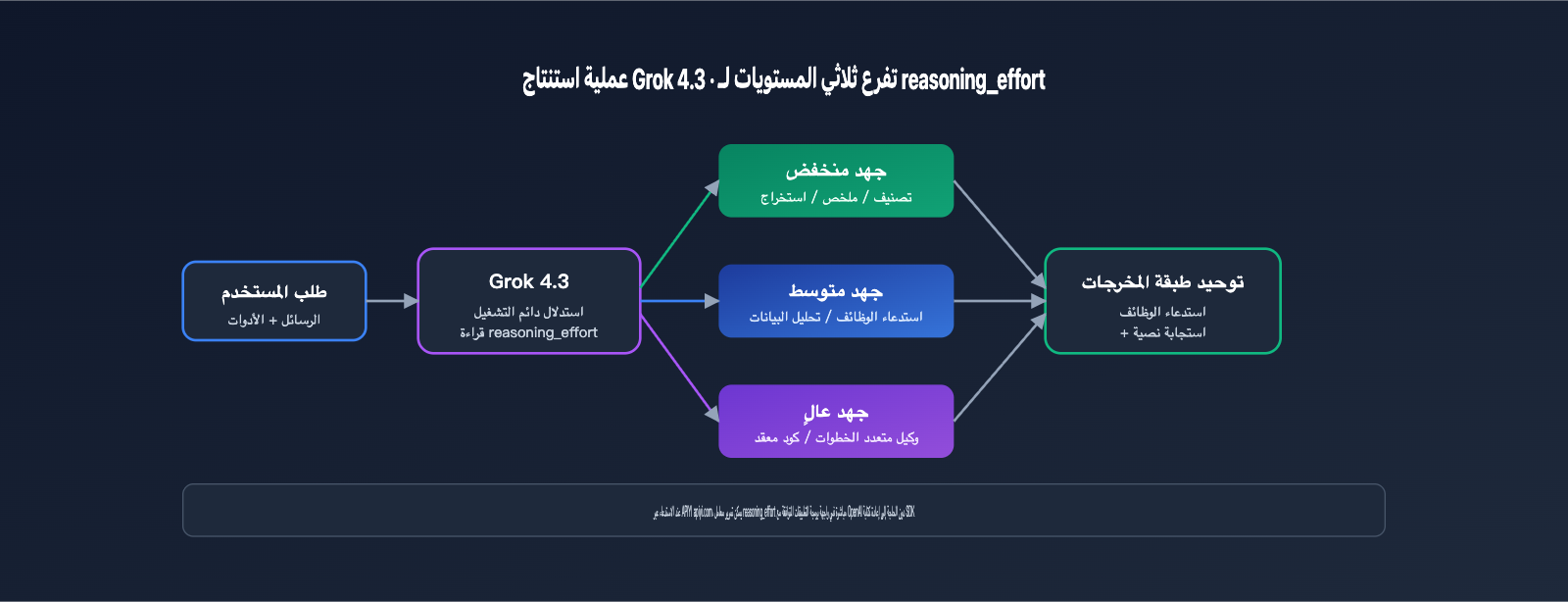
تعد مستويات قوة الاستنتاج الثلاثة (reasoning effort) ميزة جديدة رئيسية تميز Grok 4.3 عن الجيل السابق، حيث تسمح للمطورين بضبط عمق "تفكير" النموذج بناءً على تعقيد المهمة، مما يؤثر بشكل مباشر على زمن الاستجابة والتكلفة. تستلهم هذه الآلية تصميم reasoning_effort في OpenAI، لكن xAI جعلت الاستنتاج نفسه في حالة "تشغيل دائم" (always-on)، مع السماح فقط بضبط العمق. يوضح الجدول التالي سيناريوهات الاستخدام النموذجية وتأثير كل مستوى.
| قوة الاستنتاج | سيناريو الاستخدام | خصائص زمن الاستجابة | تأثير التكلفة |
|---|---|---|---|
| منخفض (low) | التصنيف البسيط، التلخيص، الاستخراج المنظم | قريب من النماذج غير الاستنتاجية | أقل كمية من الـ token للمخرجات |
| متوسط (medium) | استدعاء الوظائف، تحليل البيانات، إكمال الكود | موازنة بين زمن الاستجابة والجودة | المستوى الموصى به افتراضياً |
| مرتفع (high) | الوكلاء متعددو الخطوات، الرياضيات المعقدة، الكود الطويل | مرحلة "تفكير" أطول | زيادة ملحوظة في الـ token للمخرجات |
🎯 نصيحة للربط: بالنسبة للفرق التي لم تقرر بعد المستوى المناسب، ننصح بتشغيل مجموعة من عينات الأعمال الحقيقية على مستوى "متوسط" (medium) عبر منصة APIYI (apiyi.com)، ثم اتخاذ قرار الترقية إلى مستوى "مرتفع" (high) بناءً على الدقة وعائد التكلفة. تتيح الواجهة الموحدة تبديل معامل
reasoning_effortبين النماذج المختلفة بضغطة زر دون الحاجة لإعادة كتابة حزمة تطوير البرمجيات (SDK).
أداء Grok 4.3 في اختبارات الأداء للوكلاء (Agentic) واتباع التعليمات
يعود السبب في تركيز xAI على Grok 4.3 في رسائلها البريدية وتأكيدها أنه "يتصدر لوحات الصدارة في استدعاء الأدوات للوكلاء واتباع التعليمات" إلى البيانات الجوهرية المستمدة من منصات تقييم خارجية مثل Artificial Analysis، وτ²-Bench، وIFBench، وGDPval-AA. فقد منح مؤشر Artificial Analysis Intelligence Index النموذج درجة إجمالية قدرها 53.2، بتكلفة إجمالية للتقييم تبلغ حوالي 395 دولاراً، وهو ما يمثل توفيراً بنسبة 20% مقارنة بـ Grok 4.20. وفي اختبار τ²-Bench Telecom (الذي يحاكي استدعاء الأدوات ثنائي الاتجاه لخدمة عملاء الاتصالات)، وهو الاختبار الأقرب لسيناريوهات الوكلاء الحقيقية، حقق Grok 4.3 نسبة 98%، محققاً تحسناً بنسبة 5 نقاط مئوية عن Grok 4.20، ومتساوياً مع GLM-5.1.
بالنسبة للمطورين، الأمر الأكثر أهمية هو اختبار GDPval-AA، الذي يقيس القيمة الاقتصادية الحقيقية لسير العمل. فقد حصل Grok 4.3 على 1500 نقطة ELO، متفوقاً بفارق 321 نقطة عن الجيل السابق Grok 4.20 0309 v2 الذي سجل 1179 نقطة، ليتجاوز بذلك نماذج مثل Gemini 3.1 Pro Preview، وMuse Spark، وGPT-5.4 mini (xhigh)، وKimi K2.5. أما في جانب اتباع التعليمات (Instruction Following)، فقد حافظ Grok 4.3 على نسبة 81% في اختبار IFBench، وهي نفس نتيجة Grok 4.20 0309 v2.
| اختبار الأداء | نتيجة Grok 4.3 | مقارنة بالفئة | القدرة الأساسية |
|---|---|---|---|
| AA Intelligence Index | 53.2 | أفضل من 98% من النماذج | الذكاء العام |
| AA Coding Index | 41.0 | أفضل من 89% من النماذج | البرمجة وإعادة الهيكلة |
| τ²-Bench Telecom | 98% | متساوٍ مع GLM-5.1 | استدعاء الأدوات + تعاون المستخدم |
| IFBench | 81% | متساوٍ مع Grok 4.20 | اتباع التعليمات المعقدة |
| GDPval-AA | ELO 1500 | يتفوق على Gemini 3.1 Pro Preview | قيمة سير العمل الحقيقية |
تجدر الإشارة إلى أن نقاط قوة Grok 4.3 تكمن في سير عمل الوكلاء واستدعاء الأدوات، وليس في مسابقات الخوارزميات البحتة. بالنسبة للتطبيقات التي تتطلب مخرجات JSON مستقرة واستدعاء أدوات متعدد الجولات مثل وكلاء البرمجة (Code Agents)، ووكلاء المتصفح (Browser Agents)، وروبوتات خدمة العملاء، فإن موثوقية Grok 4.3 ستكون أفضل بشكل ملحوظ من الجيل السابق. أما إذا كان سيناريو فريقكم الأساسي يعتمد على تركيب الأكواد البرمجية البحتة مثل SWE-bench، فننصحكم باختبار Grok 4.3 وClaude 4.7 Opus وGPT-5.4 معاً على نفس مجموعة الاختبارات عبر منصة APIYI (apiyi.com)، ثم اتخاذ قرار بشأن النموذج الرئيسي بناءً على معدل النجاح.
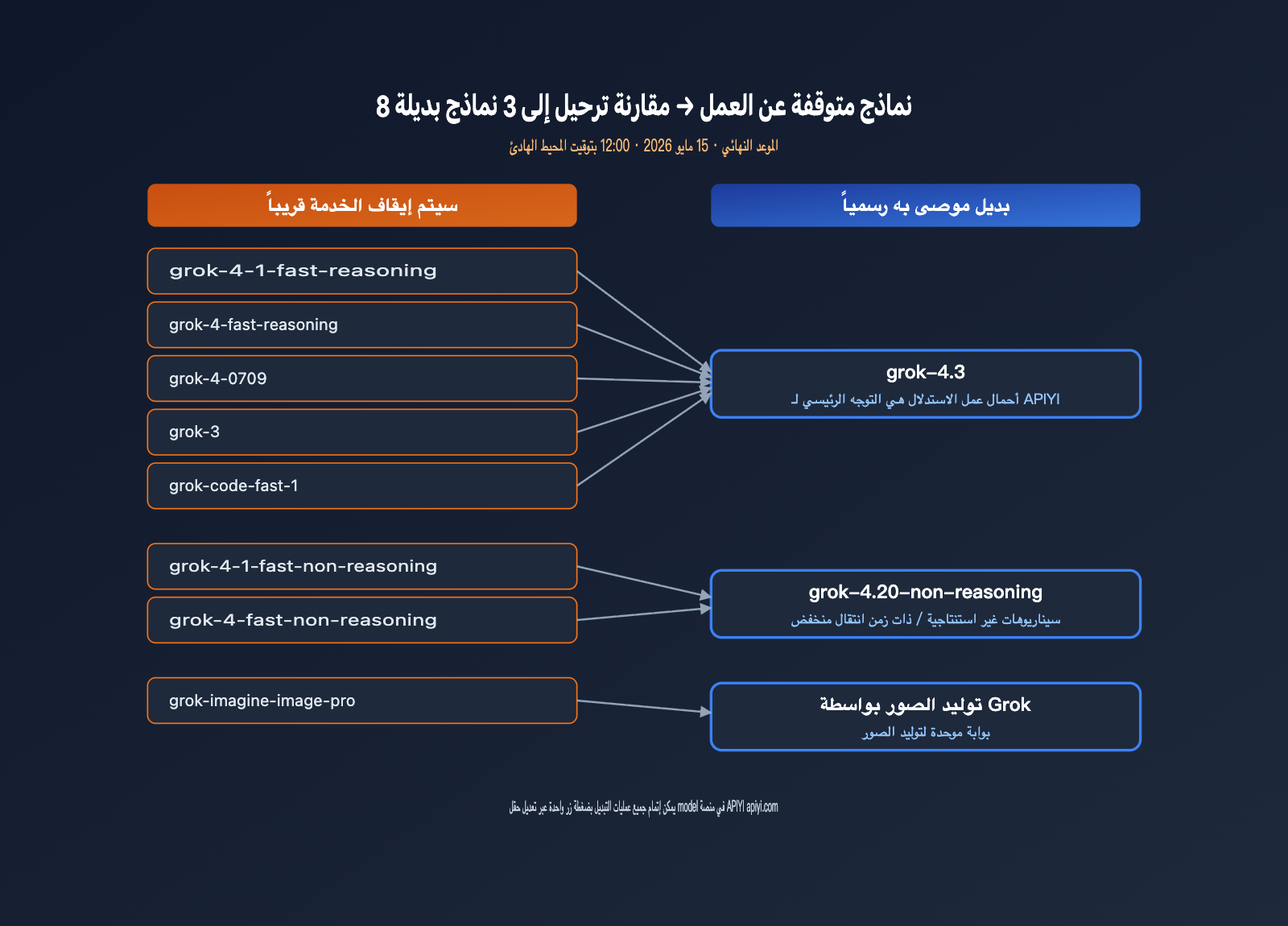
قائمة النماذج التي سيتم إيقافها من xAI وتوصيات الترحيل
تقوم xAI هذه المرة بإيقاف 8 نماذج دفعة واحدة، تغطي الاستنتاج النصي، ونماذج البرمجة، وتوليد الصور، مما يعني تنظيفاً شاملاً لمجموعة SKU الخاصة بعصر Grok 4. بالنسبة للفرق التي قامت ببرمجة أسماء النماذج بشكل ثابت (hard-code) في أنظمتها، فهذا موعد نهائي إلزامي يتطلب تعديل الكود خلال 9 أيام. يوضح الجدول أدناه جميع النماذج المتأثرة ومسارات البدائل الموصى بها رسمياً.
| النموذج الذي سيتم إيقافه | النوع | البديل الموصى به | ملاحظات الترحيل |
|---|---|---|---|
| grok-4-1-fast-reasoning | استنتاج | grok-4.3 | جودة استنتاج أعلى، سعر أقل |
| grok-4-1-fast-non-reasoning | غير استنتاجي | grok-4.20-non-reasoning | الحفاظ على ميزة التأخير المنخفض |
| grok-4-fast-reasoning | استنتاج | grok-4.3 | الحصول على نافذة سياق 1M |
| grok-4-fast-non-reasoning | غير استنتاجي | grok-4.20-non-reasoning | توافق مع شكل API |
| grok-4-0709 | استنتاج | grok-4.3 | إيقاف لقطة Grok 4 المبكرة |
| grok-code-fast-1 | برمجة | grok-4.3 | توحيد سيناريوهات البرمجة إلى 4.3 |
| grok-3 | عام | grok-4.3 | نهاية عصر Grok 3 رسمياً |
| grok-imagine-image-pro | توليد صور | grok-imagine-image | تبسيط SKU لتوليد الصور |
موعد الإيقاف هو 15 مايو 2026 الساعة 12:00 بتوقيت المحيط الهادئ (16 مايو الساعة 3 صباحاً بتوقيت بكين). بعد هذا الموعد، ستفشل جميع الطلبات الموجهة لهذه النماذج الثمانية. بدءاً من تاريخ إرسال البريد الإلكتروني في 6 مايو، أمام المطورين 9 أيام فقط، وهو جدول زمني ضيق جداً للمشاريع المتوسطة والكبيرة. ننصح بتقسيم عملية الترحيل إلى 3 خطوات: أولاً، تحديد جميع معرفات النماذج الثابتة في الكود، ثانياً، إجراء اختبار تجريبي على منصة APIYI (apiyi.com)، ثالثاً، التبديل بين النماذج عبر متغيرات البيئة بدلاً من تعديل منطق العمل.
نود التنويه بشكل خاص إلى أن grok-code-fast-1 كان النموذج الافتراضي للعديد من مشاريع وكلاء البرمجة خلال الأشهر الستة الماضية، وإيقافه يعني أن جميع أدوات Cursor، وإضافات IDE، وCLI Agents التي تعتمد على هذا المعرف ستحتاج إلى الانتقال إلى grok-4.3. في سيناريوهات البرمجة، تعتبر استقرارية استدعاء الأدوات في Grok 4.3 أفضل من grok-code-fast-1، لكن تكلفة الرمز الواحد (token) أعلى قليلاً، مما يتطلب إعادة تقييم ميزانية الاستدعاء.
مقارنة أفقية بين Grok 4.3 و GPT-5.4 و Claude 4.7 و Gemini 3.1 Pro
مع إطلاق Grok 4.3 في الربع الثاني من عام 2026، يشهد سوق نماذج اللغة الكبيرة منافسة هي الأكثر شراسة في التاريخ. حيث يحافظ Claude Opus 4.7 على الصدارة بنسبة 87.6% في اختبار SWE-bench Verified، ويحقق Gemini 3.1 Pro نسبة 94.3% في اختبار GPQA Diamond، بينما يظل GPT-5.4 المرجع الأساسي في استقرار الاستنتاج للنصوص الطويلة. أما Grok 4.3، فقد تموضع في فئة "ذكاء متوسط + سعر منخفض جداً + سلسلة أدوات وكيل (Agent) قوية"، مستهدفاً سيناريوهات الاستدعاء عالي التكرار الحساسة للتكلفة.
يوضح الجدول التالي مقارنة للبيانات الرئيسية للنماذج الأربعة الرائدة في أبعاد شائعة، علماً بأن وحدة السعر هي دولار لكل مليون رمز (token).
| النموذج | سعر الإدخال | سعر الإخراج | نافذة السياق | سيناريوهات الميزة الرئيسية |
|---|---|---|---|---|
| Grok 4.3 | $1.25 | $2.50 | 1M | سلسلة أدوات الوكيل، الاستدعاء عالي التكرار، الاستنتاج المتوسط |
| GPT-5.4 | $2.50 | $15.00 | 400K | اتساق النصوص الطويلة، التخطيط المعقد |
| Claude 4.7 Opus | $15.00 | $75.00 | 1M | البرمجة المتقدمة، كتابة المستندات، التحليل العميق |
| Gemini 3.1 Pro | $2.00 | $12.00 | 2M | متعدد الوسائط، فهم الفيديو، المستندات فائقة الطول |
من جدول المقارنة هذا، يمكن ملاحظة حقيقة مباشرة: سعر رمز الإخراج لنموذج Grok 4.3 أرخص بـ 30 مرة من Claude 4.7 Opus، وأرخص بنحو 4.8 مرة من Gemini 3.1 Pro. بالنسبة لأعمال مثل وكلاء خدمة العملاء عاليي التكرار، وأدوات فحص الكود (Linter)، وتنظيف البيانات الضخمة، ستتضاعف ميزة التكلفة لكل وحدة لنموذج Grok 4.3 بشكل كبير. ولكن في السيناريوهات التي تتطلب جودة برمجة فائقة أو فهماً متعدد الوسائط، يظل كل من Claude 4.7 Opus و Gemini 3.1 Pro لا غنى عنهما.
🎯 نصيحة استراتيجية النماذج المتعددة: ننصح باستخدام Grok 4.3 كطبقة عامة عالية التكرار، وClaude 4.7 Opus كطبقة لمخرجات الكود والمستندات المعقدة، وGemini 3.1 Pro كطبقة متعددة الوسائط. من خلال الواجهة الموحدة لـ APIYI (apiyi.com) في طبقة توجيه الأعمال، يمكنك الاستفادة من ميزة التكلفة المنخفضة لـ Grok 4.3، مع القدرة على استخدام نماذج أقوى في النقاط الحرجة.
دليل ترحيل API لنموذج Grok 4.3 وأمثلة برمجية
يعد الانتقال إلى Grok 4.3 أمراً مباشراً للغاية على المستوى الهندسي، حيث توفر xAI واجهة chat completions متوافقة مع OpenAI، ومعظم أعمال الترحيل تقتصر على تعديل base_url وحقل model. بالنسبة للمشاريع التي تستخدم بالفعل حزمة OpenAI SDK، فإن مثال Python البسيط التالي يمثل الكود الكامل للاتصال.
from openai import OpenAI
# إعداد العميل للاتصال بـ APIYI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1",
)
resp = client.chat.completions.create(
model="grok-4.3",
messages=[
{"role": "user", "content": "اشرح مفهوم جهد الاستنتاج (reasoning effort) في جملة واحدة"},
],
extra_body={"reasoning_effort": "medium"},
)
print(resp.choices[0].message.content)
بعد توجيه base_url إلى منصة APIYI (apiyi.com)، ستمتلك أعمالك مدخلاً موحداً لاستدعاء Grok 4.3 و Claude 4.7 و GPT-5.4 و Gemini 3.1 Pro. لاحقاً، يتطلب تبديل النماذج تغيير معامل model فقط، دون الحاجة لإعادة كتابة كود المصادقة والتوجيه. هذا التجريد الموحد يمكن أن يقلل بشكل كبير من مخاطر الترحيل قبل الموعد النهائي لإيقاف النماذج القديمة في 15 مايو.
بالنسبة لترحيل النماذج القديمة، قمنا بتنظيم جدول مقارنة للحد الأدنى من التغييرات للانتقال من معرف النموذج القديم إلى الجديد، ويمكن تطبيقه مباشرة في الكود الخاص بك.
| حقل النموذج القديم | حقل النموذج الجديد | هل يتطلب تغيير معاملات أخرى؟ |
|---|---|---|
| grok-3 | grok-4.3 | اختياري إضافة reasoning_effort |
| grok-4-0709 | grok-4.3 | اختياري إضافة reasoning_effort |
| grok-4-fast-reasoning | grok-4.3 | اختياري إضافة reasoning_effort |
| grok-4-fast-non-reasoning | grok-4.20-non-reasoning | لا حاجة لتعديل معاملات أخرى |
| grok-code-fast-1 | grok-4.3 | يوصى بـ reasoning_effort=high |
| grok-imagine-image-pro | grok-imagine-image | نقاط نهاية API للصور تظل ثابتة |
الأسئلة الشائعة حول Grok 4.3
س1: هل يدعم Grok 4.3 حقاً نافذة سياق بحجم 1 مليون رمز (token)؟ وهل ينخفض الأداء مع النصوص الطويلة؟
نعم، يوفر Grok 4.3 عبر xAI API نافذة سياق بحجم 1 مليون رمز بشكل رسمي، وهو ما يضاهي Claude 4.7 Opus. ولكن، كما هو الحال مع جميع نماذج السياق الطويل، قد يحدث تراجع طفيف في فهم المتطلبات بعد تجاوز 600 ألف رمز. لذا، ننصح بوضع المعلومات الأساسية في النصف الأول من المستند. يمكنك إجراء اختبار لاسترجاع المعلومات باستخدام مستندات عمل حقيقية عبر منصة APIYI (apiyi.com) قبل اتخاذ قرار باعتماد Grok 4.3 كخيارك الأساسي للنصوص الطويلة.
س2: كيف أختار بين مستويات قوة الاستدلال (low / medium / high)؟
استخدم المستوى المنخفض (low) للمهام منخفضة المخاطر (التصنيف، التلخيص، استخراج القواعد)، والمستوى المتوسط (medium) للأعمال الروتينية (خدمة العملاء، استدعاء الدوال، تحليل البيانات)، والمستوى العالي (high) للاستدلال المعقد (الوكلاء متعددو الخطوات، سلاسل الأكواد الطويلة، الرياضيات المعقدة). لاحظ أن المستوى العالي يزيد بشكل ملحوظ من عدد رموز المخرجات وزمن الاستجابة، لذا ننصح بتقييم ذلك بناءً على ميزانيتك واتفاقية مستوى الخدمة (SLA) الخاصة بزمن الاستجابة.
س3: هل يمكنني الاستمرار في استخدام النماذج القديمة بعد الساعة 12:00 بتوقيت المحيط الهادئ في 15 مايو؟
لا. فقد نصت رسالة xAI بوضوح على أنه "بعد 15 مايو 2026، لن تعمل الطلبات الموجهة لهذه النماذج"، وستعيد الطلبات المنتهية الصلاحية خطأً مباشراً. يجب الانتهاء من تحديث جميع الأكواد التي تحتوي على معرفات نماذج (Model ID) ثابتة قبل هذا الموعد.
س4: كيف يمكنني تقليل تكلفة الانتقال إلى أدنى حد؟
الطريقة الأكثر أماناً هي تجريد حقل النموذج (model field) في نظامك ليصبح متغيراً بيئياً أو إعداداً قابلاً للتغيير، بدلاً من كتابته بشكل ثابت (hard-code) داخل الكود. ومن خلال استخدام واجهة APIYI (apiyi.com) المتوافقة مع OpenAI، ستقتصر عملية الانتقال على تغيير سطر واحد في الإعدادات وإجراء اختبار تراجع (regression test) واحد.
س5: هل Grok 4.3 مناسب لبناء وكيل برمجي (Coding Agent)؟
نعم، إنه مناسب جداً. حقق Grok 4.3 نسبة 98% في اختبار τ²-Bench Telecom، كما يتميز باستقرار أفضل في استدعاء الأدوات والمحادثات متعددة الجولات مقارنة بـ grok-code-fast-1. بالإضافة إلى ذلك، فإن تكلفته منخفضة جداً، مما يجعله مثالياً لإضافات بيئة التطوير المتكاملة (IDE) التي تتطلب استدعاءات متكررة، ووكلاء سطر الأوامر (CLI Agent)، ونصوص الأتمتة التشغيلية.
الخلاصة: النقاط الجوهرية لإطلاق Grok 4.3 والانتقال إلى xAI API
أهم ما يميز إطلاق Grok 4.3 ليس كونه "أقوى" فحسب، بل كونه "أرخص وأقوى في آن واحد". فبسعر يتراوح بين 1.25 و2.50 دولار، جلبت xAI نافذة سياق بحجم 1 مليون رمز مع قدرات استدعاء أدوات عالية الجودة إلى نفس النطاق السعري لـ Gemini 3.1 Pro، مما يعيد تعريف معيار التكلفة مقابل الأداء للنماذج العامة عالية التردد. في الوقت نفسه، يذكرنا إيقاف 8 نماذج قديمة في 15 مايو جميع الفرق بأن معرفات النماذج لا ينبغي أن تكون ثابتة في الكود، بل يجب تجريدها خلف طبقة توجيه قابلة للتهيئة.
نوصي باعتماد Grok 4.3 كخيار أساسي للاستدعاءات المتكررة وسلاسل أدوات الوكلاء، وإتمام عملية الانتقال عبر الواجهة الموحدة لـ APIYI (apiyi.com) لتقليل تكاليف التبديل إلى أدنى حد، مع الاحتفاظ بالقدرة على الجمع بين نماذج متعددة مثل Claude 4.7 Opus وGPT-5.4 وGemini 3.1 Pro، والتبديل بينها ديناميكياً حسب المهام المختلفة لتحقيق التوازن الأمثل بين التكلفة والجودة.
فريق APIYI التقني · نهتم بتقديم محتوى عملي حول واجهات برمجة تطبيقات نماذج الذكاء الاصطناعي وأدوات المطورين. للمزيد من المقالات التقنية، تفضل بزيارة apiyi.com