ملاحظة من المؤلف: شرح تفصيلي لبنية Thinker-Talker MoE في نموذج اللغة الكبير متعدد الوسائط الأصلي Qwen3.5-Omni، مع استعراض قدرات نافذة السياق 256K، وإمكانات ترميز الصوت والفيديو، وقدرة "Audio-Visual Vibe Coding" الناشئة.
أطلق فريق "通义千问" (Qwen) في شركة علي بابا رسمياً نموذج Qwen3.5-Omni في 30 مارس 2026، وهو نموذج متعدد الوسائط أصلي وموحد يعالج النصوص والصور والصوت والفيديو في مسار حسابي واحد. كجزء من سلسلة الإصدارات المكثفة لشركة علي بابا خلال شهري مارس وأبريل، حقق Qwen3.5-Omni نتائج SOTA في 215 اختباراً معيارياً، مما يمثل اختراقاً مهماً لشركات الذكاء الاصطناعي الصينية في مجال نماذج اللغة الكبيرة متعددة الوسائط بالكامل.
القيمة الجوهرية: تعرف في 3 دقائق على تصميم بنية Thinker-Talker في Qwen3.5-Omni، واستراتيجيات اختيار متغيرات النموذج الثلاثة، وقدرة "Audio-Visual Vibe Coding" الناشئة.
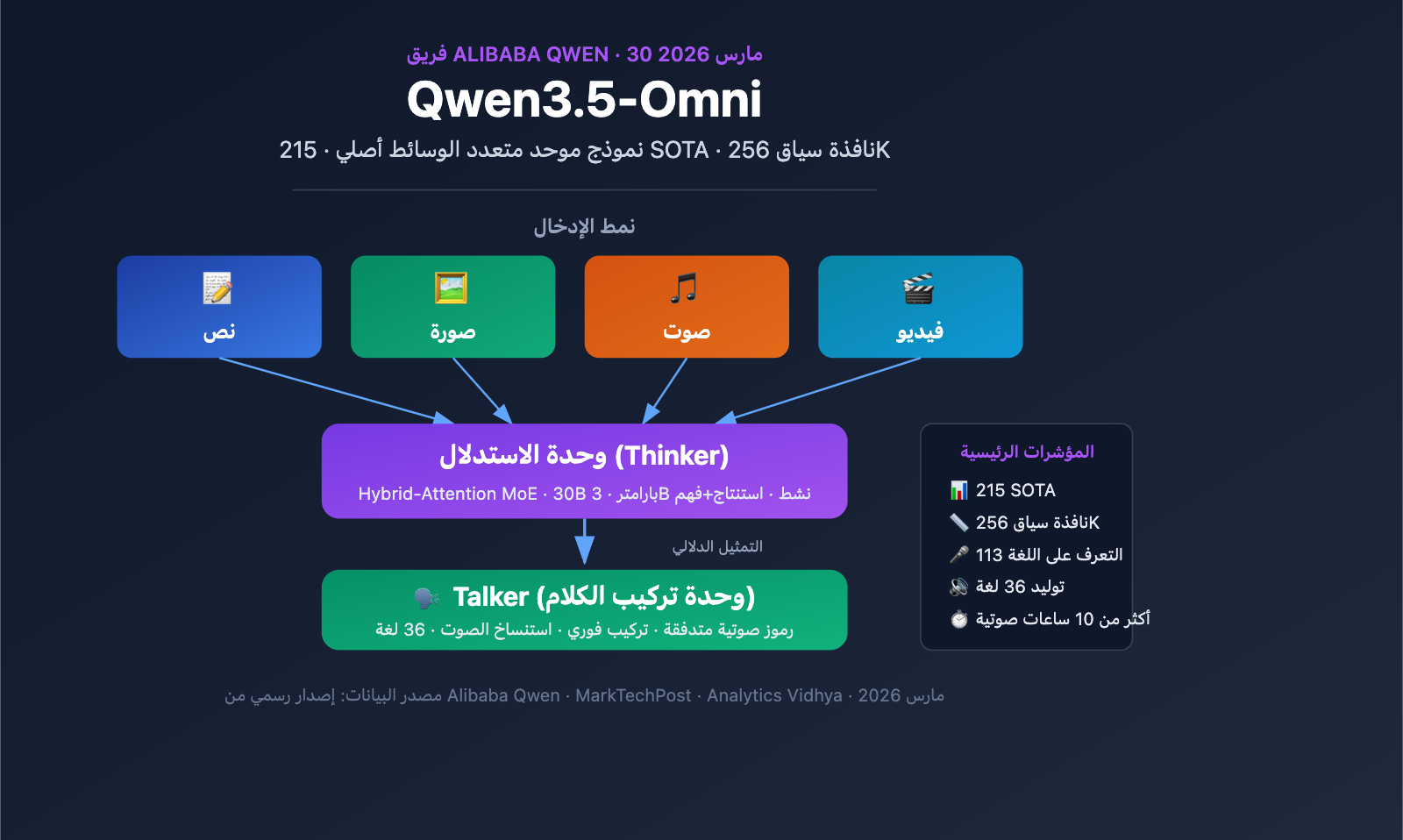
معلومات جوهرية حول نموذج Qwen3.5-Omni متعدد الوسائط
نظرة سريعة على المعلمات الرئيسية لنموذج Qwen3.5-Omni
| المعلمة | التفاصيل |
|---|---|
| تاريخ الإصدار | 30 مارس 2026 |
| الجهة المطورة | فريق "通义千问" (Qwen) التابع لشركة علي بابا |
| البنية | Thinker-Talker + Hybrid-Attention MoE |
| إصدارات النموذج | Plus (30B-A3B MoE)، Flash (MoE خفيف)، Light (نموذج كثيف/مفتوح الأوزان) |
| نافذة السياق | 256 ألف رمز (Token) |
| سعة الصوت | أكثر من 10 ساعات من الصوت المتواصل |
| سعة الفيديو | أكثر من 400 ثانية من فيديو بدقة 720p (بمعدل 1 إطار في الثانية) |
| التعرف على الكلام | 113 لغة ولهجة (مقارنة بـ 19 لغة في الجيل السابق) |
| توليد الكلام | 36 لغة (مقارنة بـ 10 لغات في الجيل السابق) |
| بيانات التدريب | أكثر من 100 مليون ساعة من البيانات الصوتية والمرئية |
| نتائج الاختبارات | تحقيق مستوى SOTA في 215 معياراً لفهم الصوت/الفيديو |
تموضع نموذج Qwen3.5-Omni
تكمن الأهمية الجوهرية لنموذج Qwen3.5-Omni في كونه متعدد الوسائط أصلياً (Native Multimodal)؛ فهو ليس مجرد نموذج نصي تم ربطه بوحدات صوتية ومرئية، بل هو نموذج موحد تم تدريبه مسبقاً من الصفر على أكثر من 100 مليون ساعة من البيانات الصوتية والمرئية. تتم معالجة جميع الوسائط في مسار حسابي واحد، مما يعني أن النموذج يمكنه فهم المعلومات الدلالية في الصوت والفيديو بشكل حقيقي، بدلاً من مجرد تحويل الصوت والفيديو إلى نصوص ثم معالجتها.
في الوقت نفسه، يُعد Qwen3.5-Omni واحداً من سلسلة النماذج التي أطلقتها علي بابا بكثافة في الفترة ما بين مارس وأبريل 2026. فبعد أيام قليلة فقط، وتحديداً في 2 أبريل، أطلقت علي بابا نموذج Qwen3.6-Plus الموجه للتطبيقات المؤسسية (والذي يدعم نافذة سياق تصل إلى مليون رمز، ويركز على البرمجة الوكيلة)، مما يعكس الاستثمار القوي لشركة علي بابا في مجال نماذج اللغة الكبيرة.
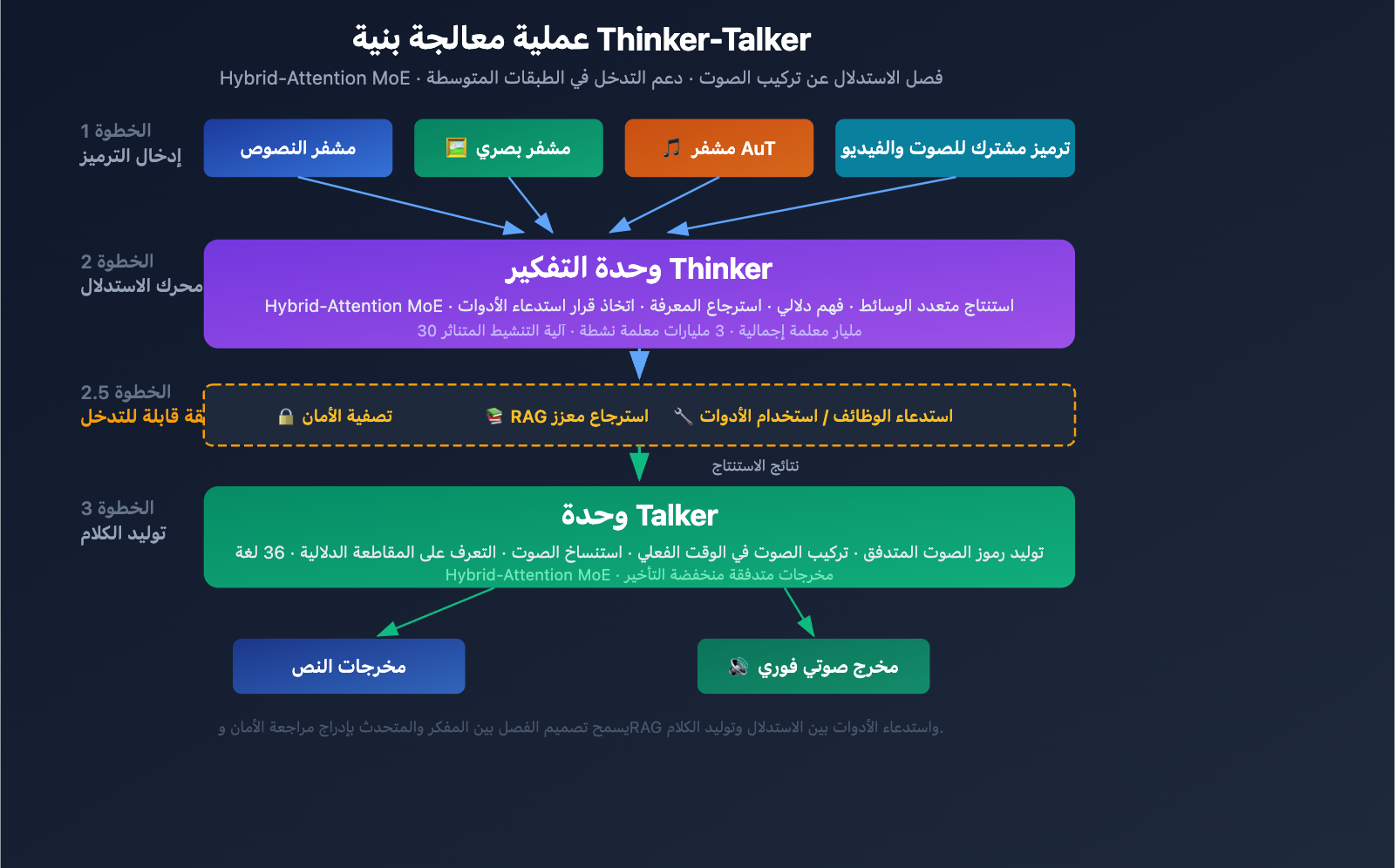
شرح مفصل لبنية Qwen3.5-Omni Thinker-Talker
تصميم الوحدتين Thinker-Talker
يعتمد نموذج Qwen3.5-Omni على بنية فريدة مكونة من وحدتين (Thinker-Talker)، وهو تصميم تم تقديمه لأول مرة في Qwen2.5-Omni، وشهد ترقية كبيرة في إصدار 3.5، حيث تستخدم كلتا الوحدتين بنية Hybrid-Attention MoE (خليط الخبراء مع الانتباه الهجين).
وحدة Thinker (المُفكر):
- تعالج جميع أنماط المدخلات: النص، الصور، الصوت، والفيديو.
- تنفذ مهام الاستنتاج والفهم.
- تولد تمثيلات استنتاجية داخلية.
- تستخدم مشفر Audio Transformer (AuT) الأصلي لمعالجة الصوت.
- تخرج تمثيلات دلالية مهيكلة.
وحدة Talker (المُعبّر):
- تستقبل التمثيلات الاستنتاجية من وحدة Thinker.
- تحول التمثيلات الدلالية إلى رموز (Tokens) صوتية متدفقة.
- تدعم تركيب الصوت في الوقت الفعلي.
- تحقق تعبيرًا صوتيًا طبيعيًا (بما في ذلك نبرة الصوت، العاطفة، والتوقفات).
القيمة الهندسية لبنية Thinker-Talker
الميزة الأساسية لهذا التصميم المنفصل هي قابلية التدخل في المنتصف، حيث يمكن للأنظمة الخارجية (خطوط أنابيب استرجاع RAG، مرشحات الأمان، استدعاء الوظائف) التدخل بين مخرجات Thinker وعملية التركيب في Talker. وهذا يعني:
- يمكن للشركات إضافة فحص أمني قبل إخراج الصوت.
- يمكن للمطورين تشغيل استدعاءات الأدوات بناءً على نتائج الاستنتاج.
- يمكن لأنظمة RAG إضافة نتائج استرجاع المعرفة قبل الإجابة.
آلية التنشيط المتناثر MoE
جوهر تصميم Hybrid-Attention MoE هو التنشيط المتناثر، حيث يقوم النموذج بتنشيط جزء فقط من المعلمات عند معالجة كل رمز (3 مليارات معلمة نشطة فقط من إجمالي 30 مليار). تتيح هذه الآلية للنموذج الحفاظ على سعة عالية مع إبقاء تكلفة حساب الاستنتاج الفردي ضمن نطاق مقبول، وهو أمر بالغ الأهمية للتطبيقات في الوقت الفعلي (مثل المحادثات الصوتية).
🎯 نصيحة للمطورين: بنية Thinker-Talker المنفصلة في Qwen3.5-Omni مثالية لبناء سير عمل AI متعدد الخطوات. إذا كنت بحاجة إلى دمج قدرات متعددة الوسائط في تطبيقك، يمكنك اختبار فروق الأداء بين Qwen3.5-Omni والنماذج الرائدة الأخرى بسرعة عبر منصة APIYI apiyi.com.
مقارنة بين متغيرات نموذج Qwen3.5-Omni
دليل اختيار الإصدارات (Plus / Flash / Light)
يوفر Qwen3.5-Omni ثلاثة متغيرات للنموذج تناسب سيناريوهات مختلفة:
| المتغير | نوع البنية | حجم المعلمات | طريقة الاستخدام | سيناريوهات الاستخدام |
|---|---|---|---|---|
| Plus | MoE (30B-A3B) | 30 مليار إجمالي/3 نشطة | API (DashScope) | استنتاج بأعلى جودة، مهام متعددة الوسائط معقدة |
| Flash | MoE خفيف | معلمات أقل | API (DashScope) | سيناريوهات زمن الانتقال المنخفض، المحادثات الفورية |
| Light | نموذج كثيف | حجم أصغر | أوزان مفتوحة (HuggingFace) | النشر المحلي، أجهزة الحافة |
نصيحة الاختيار:
- للحصول على أفضل النتائج → اختر متغير Plus، فهو يحقق أعلى الدرجات في 215 اختبارًا قياسيًا.
- لتقليل زمن الانتقال → اختر متغير Flash، فهو مناسب للمحادثات الصوتية الفورية والتفاعل المتدفق.
- للنشر المحلي → اختر متغير Light، حيث تتوفر الأوزان المفتوحة للتشغيل على وحدات معالجة الرسومات (GPU) المحلية.
طريقة ربط API لنموذج Qwen3.5-Omni
تتبع API الخاصة بـ Qwen3.5-Omni تنسيق /v1/chat/completions القياسي، ويتم تحديد نوع المخرجات عبر معامل modalities:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # الربط الموحد عبر APIYI
)
response = client.chat.completions.create(
model="qwen3.5-omni-plus",
modalities=["text", "audio"],
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "يرجى تحليل محتوى هذا الفيديو"},
{"type": "video_url", "video_url": {"url": "https://example.com/video.mp4"}}
]
}
]
)
عرض مثال كامل للمدخلات متعددة الوسائط
import openai
import base64
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
# مدخلات متعددة الوسائط: صورة + صوت + نص
response = client.chat.completions.create(
model="qwen3.5-omni-plus",
modalities=["text", "audio"],
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "يرجى إنشاء تقرير تحليل بناءً على الصورة والوصف الصوتي"},
{
"type": "image_url",
"image_url": {"url": "data:image/png;base64,..."}
},
{
"type": "input_audio",
"input_audio": {
"data": base64.b64encode(audio_bytes).decode(),
"format": "wav"
}
}
]
}
],
max_tokens=2000
)
# الحصول على الرد النصي
print(response.choices[0].message.content)
# إذا تم طلب مخرجات صوتية، احصل على البيانات الصوتية
if hasattr(response.choices[0].message, 'audio'):
audio_data = response.choices[0].message.audio
print(f"تنسيق الصوت: {audio_data.format}")
💡 نصيحة الربط: تتوافق API الخاصة بـ Qwen3.5-Omni مع تنسيق OpenAI SDK. إذا كان لديك كود يعتمد على OpenAI SDK، فما عليك سوى تعديل
base_urlومعاملmodelللتبديل بسرعة. يمكنك اختبار القدرات متعددة الوسائط لـ Qwen3.5-Omni ونماذج مثل GPT-4o في وقت واحد عبر منصة APIYI apiyi.com.
تحليل أداء Qwen3.5-Omni في الاختبارات المعيارية
قدرات فهم الصوت
يتفوق نموذج Qwen3.5-Omni-Plus بشكل شامل على نموذج Google Gemini 3.1 Pro في الاختبارات المعيارية المتعلقة بالصوت:
| الاختبار المعياري | Qwen3.5-Omni-Plus | Gemini 3.1 Pro | الفائز |
|---|---|---|---|
| MMAU فهم الصوت | 82.2 | 81.1 | Qwen |
| MuchoMusic فهم الموسيقى | 72.4 | 59.6 | Qwen (+21%) |
| VoiceBench المحادثة | 93.1 | 88.9 | Qwen |
تظهر ميزة Qwen3.5-Omni بشكل واضح في فهم الموسيقى (MuchoMusic)، حيث يتفوق بنسبة تصل إلى 21%.
القدرات البصرية والمرئية
| الاختبار المعياري | Qwen3.5-Omni-Plus | ملاحظات |
|---|---|---|
| MMMU-Pro | 73.9 | أعلى درجة في الفهم متعدد الوسائط |
| RealWorldQA | 84.1 | الأسئلة والأجوبة البصرية في العالم الحقيقي |
| VideoMME (بدون ترجمة) | 81.9 | الفهم متعدد الوسائط للفيديو |
| MLVU | 86.8 | فهم الفيديوهات الطويلة |
| MVBench | 79.0 | اختبار معياري للفيديو متعدد الأبعاد |
| LVBench | 71.2 | اختبار معياري للفيديو الطويل |
الحفاظ على قدرات الاستدلال النصي
بينما اكتسب Qwen3.5-Omni قدرات شاملة في جميع الوسائط، إلا أن أداء الاستدلال النصي لم يتأثر تقريباً:
| الاختبار المعياري | Qwen3.5-Omni-Plus | Qwen3.5-Plus (نص فقط) | الفارق |
|---|---|---|---|
| MMLU-Redux | 94.2 | 94.3 | -0.1 |
| C-Eval | 92.0 | 92.3 | -0.3 |
| IFEval | 89.7 | 89.7 | 0 |
هذا يعني أن اختيار Qwen3.5-Omni لا يأتي على حساب جودة الاستدلال النصي، حيث يمكنك الاعتماد على نموذج واحد لتغطية سيناريوهات النصوص والوسائط المتعددة معاً.
🎯 نصيحة للاختيار: يتمتع Qwen3.5-Omni بميزة واضحة في فهم الصوت والموسيقى. إذا كان تطبيقك يتضمن تفاعلاً صوتياً أو تحليلاً صوتياً، فنحن نوصي بإعطاء الأولوية لهذا النموذج. يمكنك استخدام خدمة وكيل API عبر APIYI (apiyi.com) للمقارنة السريعة بين أداء Qwen3.5-Omni و GPT-4o في سيناريوهاتك الخاصة.

القدرات الثلاث المميزة لنموذج Qwen3.5-Omni
القدرة 1: البرمجة المرئية والصوتية (Audio-Visual Vibe Coding)
يُظهر نموذج Qwen3.5-Omni ما يسميه فريق "تونغ يي تشيان ون" (Tongyi Qianwen) بـ "القدرة الناشئة للبرمجة المرئية والصوتية" (Audio-Visual Vibe Coding)؛ حيث يمكن للنموذج كتابة كود برمجي قابل للتشغيل من خلال مشاهدة مقاطع الفيديو والاستماع إلى الأوامر الصوتية، دون الحاجة إلى تدريب مخصص لهذه القدرة.
في الاختبارات العملية، أثبت النموذج قدرته على:
- تحويل الرسومات اليدوية (التي يتم تصويرها عبر الكاميرا) إلى صفحات ويب React قابلة للتشغيل.
- كتابة كود وظيفي بناءً على عرض توضيحي بالفيديو ووصف شفهي.
- فهم نوايا التصميم المرئي وإنشاء واجهة أمامية مطابقة لها.
تكتسب هذه القدرة قيمة كبيرة في تطوير النماذج الأولية السريعة وسيناريوهات البرمجة منخفضة الأكواد (Low-code).
القدرة 2: التعرف على المقاطعة الدلالية
تعجز أنظمة التفاعل الصوتي التقليدية عن التمييز بين ردود الفعل التفاعلية للمستخدم مثل "همم" أو "آه" وبين نية المقاطعة الحقيقية. يقدم Qwen3.5-Omni ميزة التعرف على نية تبادل الأدوار (Turn-Taking Intent Recognition) الأصلية، والتي يمكنها التمييز بين:
- ردود الفعل التفاعلية (Backchanneling): مثل "همم" أو "نعم"، وهي ردود لا تحمل نية مقاطعة دلالية.
- المقاطعة الدلالية (Semantic Interruption): الحالات التي يكون لدى المستخدم فيها نية واضحة لتولي زمام الحوار.
هذا يجعل تجربة الحوار الصوتي مع Qwen3.5-Omni أقرب إلى التواصل البشري الطبيعي.
القدرة 3: استنساخ الصوت
يمكن للمستخدمين تحميل تسجيل صوتي، وسيقوم Qwen3.5-Omni بتعلم ونسخ خصائص ذلك الصوت، واستخدامه في جميع المخرجات الصوتية اللاحقة. يحافظ الصوت المستنسخ على طبيعته واستقراره حتى في سيناريوهات تعدد اللغات.
موقع Qwen3.5-Omni في استراتيجية إطلاق نماذج الذكاء الاصطناعي من علي بابا
جدول إطلاق نماذج الذكاء الاصطناعي من علي بابا (مارس – أبريل 2026)
| تاريخ الإطلاق | النموذج | التموضع | الميزات الرئيسية |
|---|---|---|---|
| 30 مارس | Qwen3.5-Omni | نموذج متعدد الوسائط أصلي | معالجة موحدة للنصوص/الصور/الصوت/الفيديو |
| 2 أبريل | Qwen3.6-Plus | نموذج وكيل للمؤسسات | نافذة سياق بمليون Token، برمجة وكيلية |
| تحديث مستمر | Qwen3-TTS | توليد الكلام | سلسلة TTS مفتوحة المصدر، تدعم استنساخ الصوت |
تشير وتيرة الإطلاق المكثفة هذه إلى أن علي بابا تدفع بقوة نحو بناء قدرات نموذج لغة كبير شاملة. يغطي Qwen3.5-Omni الإدراك والفهم متعدد الوسائط، بينما يغطي Qwen3.6-Plus قدرات توليد الكود والوكلاء على مستوى المؤسسات، مما يجعلهما متكاملين.
ومن الجدير بالذكر أن نسختي Plus وFlash من Qwen3.5-Omni تم إطلاقهما عبر API مغلق المصدر، مما يكسر استراتيجية علي بابا السابقة التي كانت تركز بشكل أساسي على المصادر المفتوحة. وترى وسائل إعلام مثل WinBuzzer أن هذا يعكس تركيز علي بابا على الأرباح في ظل ضغوط تجارية؛ حيث جاء عنوان تقرير بلومبرج صريحاً: "علي بابا تطلق ثالث نموذج ذكاء اصطناعي مغلق المصدر، مع التركيز على الأرباح".
💰 نصيحة حول التكلفة: إذا كنت تفكر في دمج Qwen3.5-Omni في منتجك، يُنصح بإجراء إثبات للمفهوم (PoC) باستخدام الرصيد المجاني المتاح على منصة APIYI (apiyi.com)، والتأكد من أداء النموذج قبل الانتقال إلى مرحلة النشر الإنتاجي. تدعم المنصة مجموعة كاملة من النماذج مثل Qwen وGPT وClaude وGemini، مما يسهل الاختيار المرن حسب السيناريوهات المختلفة.
الأسئلة الشائعة
س1: هل نموذج Qwen3.5-Omni مفتوح المصدر أم مغلق المصدر؟
يتوفر Qwen3.5-Omni في ثلاثة إصدارات: Plus و Flash متاحان حالياً فقط عبر واجهة برمجة تطبيقات (API) DashScope من علي بابا (مغلق المصدر)، بينما إصدار Light متاح للأوزان على HuggingFace ويمكن تحميله (مفتوح المصدر). الجيل السابق Qwen3-Omni كان مفتوح المصدر بالكامل بموجب ترخيص Apache 2.0، لكن إصدارات 3.5 من نوع Plus/Flash تحولت إلى نموذج يعتمد على API فقط. إذا كنت بحاجة إلى النشر المحلي، يمكنك اختيار إصدار Light.
س2: كيف يقارن Qwen3.5-Omni مع GPT-4o؟
في مجالات فهم الصوت والموسيقى، يتفوق Qwen3.5-Omni-Plus بشكل ملحوظ على GPT-4o. أما في فهم الفيديو، فلكل منهما نقاط قوة مختلفة. وفيما يخص الاستدلال النصي، فإن أداء Qwen3.5-Omni يكاد يطابق نموذج Qwen3.5-Plus النصي البحت. نوصي بإجراء اختبارات مقارنة في سيناريوهات تطبيقك الخاصة عبر منصة APIYI apiyi.com، حيث قد تختلف النتائج بشكل كبير بناءً على حالة الاستخدام.
س3: كيف أبدأ باستخدام Qwen3.5-Omni API بسرعة؟
تتوافق واجهة برمجة تطبيقات Qwen3.5-Omni مع تنسيق OpenAI SDK القياسي، مما يجعل عملية الربط سهلة للغاية. ما عليك سوى تثبيت openai SDK، وتعيين مفتاح API و base_url المناسبين، ثم البدء في الاستدعاء. يمكنك الحصول على رصيد تجريبي مجاني عبر APIYI apiyi.com، واستخدام أمثلة الكود في هذا المقال للتحقق بسرعة من نتائج استدعاء الوسائط المتعددة.
الخلاصة
النقاط الجوهرية لنموذج الوسائط المتعددة Qwen3.5-Omni:
- وسائط متعددة أصلية: يعالج النص، الصور، الصوت، والفيديو في مسار واحد موحد، وليس عبر حلول تجميعية.
- بنية Thinker-Talker: فصل الاستدلال عن توليد الصوت، مع دعم التدخل في الطبقات المتوسطة واستدعاء الأدوات.
- ثلاثة إصدارات: Plus (الأقوى)، Flash (زمن استجابة منخفض)، Light (أوزان مفتوحة للنشر المحلي).
- 215 معيار SOTA: تفوق ملحوظ على Gemini 3.1 Pro في فهم الصوت والموسيقى.
- قدرات ناشئة: ميزة Audio-Visual Vibe Coding التي تتيح للنموذج كتابة الكود عبر الفيديو والصوت.
يمثل Qwen3.5-Omni تقدماً مهماً في مجال الذكاء الاصطناعي متعدد الوسائط؛ حيث يغطي نموذج واحد النص والرؤية والصوت والفيديو في آن واحد، مع الحفاظ على قدرات استدلال نصي قوية. بالنسبة للمطورين الذين يحتاجون إلى قدرات الوسائط المتعددة، يعد هذا خياراً يستحق التقييم الجاد.
نوصي باستخدام منصة APIYI apiyi.com لاختبار Qwen3.5-Omni ونماذج الوسائط المتعددة الرائدة الأخرى بسرعة، حيث توفر المنصة رصيداً مجانياً وواجهة API موحدة لتسهيل المقارنة والاختيار.
📚 المراجع
-
تقرير MarkTechPost: تفاصيل إطلاق Qwen3.5-Omni
- الرابط:
marktechpost.com/2026/03/30/alibaba-qwen-team-releases-qwen3-5-omni-a-native-multimodal-model-for-text-audio-video-and-realtime-interaction - الوصف: تحليل تقني مفصل وشرح للبنية الهندسية للنموذج.
- الرابط:
-
مستودع Qwen3-Omni على GitHub: الكود المصدري وأوزان النموذج
- الرابط:
github.com/QwenLM/Qwen3-Omni - الوصف: الكود الكامل والوثائق الخاصة بالجيل السابق Qwen3-Omni.
- الرابط:
-
تحليل معمق من Analytics Vidhya: تحليل التقرير التقني لـ Qwen3.5-Omni
- الرابط:
analyticsvidhya.com/blog/2026/03/qwen3-5-omni-ai-model - الوصف: تغطية شاملة لقدرات استنساخ الصوت، و"Vibe Coding"، وغيرها من الميزات.
- الرابط:
-
تقرير eWeek: نموذج Qwen3.5-Omni كأحدث نماذج الذكاء الاصطناعي متعدد الوسائط من علي بابا
- الرابط:
eweek.com/news/qwen3-5-omni-alibaba-multimodal-ai-launch - الوصف: تحليل من منظور صناعي ومقارنة مع المنافسين.
- الرابط:
-
صفحة النموذج على HuggingFace: Qwen3-Omni-30B-A3B-Instruct
- الرابط:
huggingface.co/Qwen/Qwen3-Omni-30B-A3B-Instruct - الوصف: تنزيل أوزان النموذج والمواصفات التقنية.
- الرابط:
المؤلف: الفريق التقني لـ APIYI
تبادل الخبرات: نرحب بمناقشاتكم في قسم التعليقات حول تطبيقات الذكاء الاصطناعي متعدد الوسائط، وللمزيد من مواد تطوير الذكاء الاصطناعي يمكنكم زيارة مركز توثيق APIYI عبر الرابط: docs.apiyi.com