Ada pembaruan menarik yang patut disimak oleh para pengembang! Pada 28 April 2026, keluarga model dasar Dola dari ByteDance meluncurkan model pemahaman omnimodal (seluruh modalitas) pertama mereka, yaitu Seed-2.0-lite-260428. Model ini secara native mendukung input video, gambar, audio, dan teks. Ini adalah model pertama dalam keluarga Dola Seed yang "bisa melihat sekaligus mendengar", serta telah ditingkatkan kemampuannya dalam tugas-tugas seperti Agent, Coding, dan GUI. Artikel ini akan membahas kemampuan model, detail pemahaman audio, dan skenario aplikasi tipikal, berdasarkan spesifikasi resmi BytePlus ModelArk, tolok ukur publik ByteDance Seed, dan pengujian akses melalui APIYI (apiyi.com).
I. Apa itu Seed-2.0-lite-260428: Posisi Inti dan Poin Pembaruan
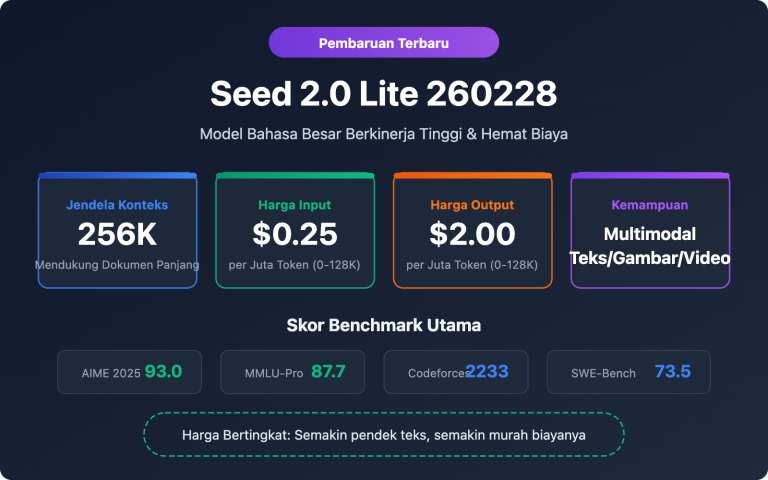
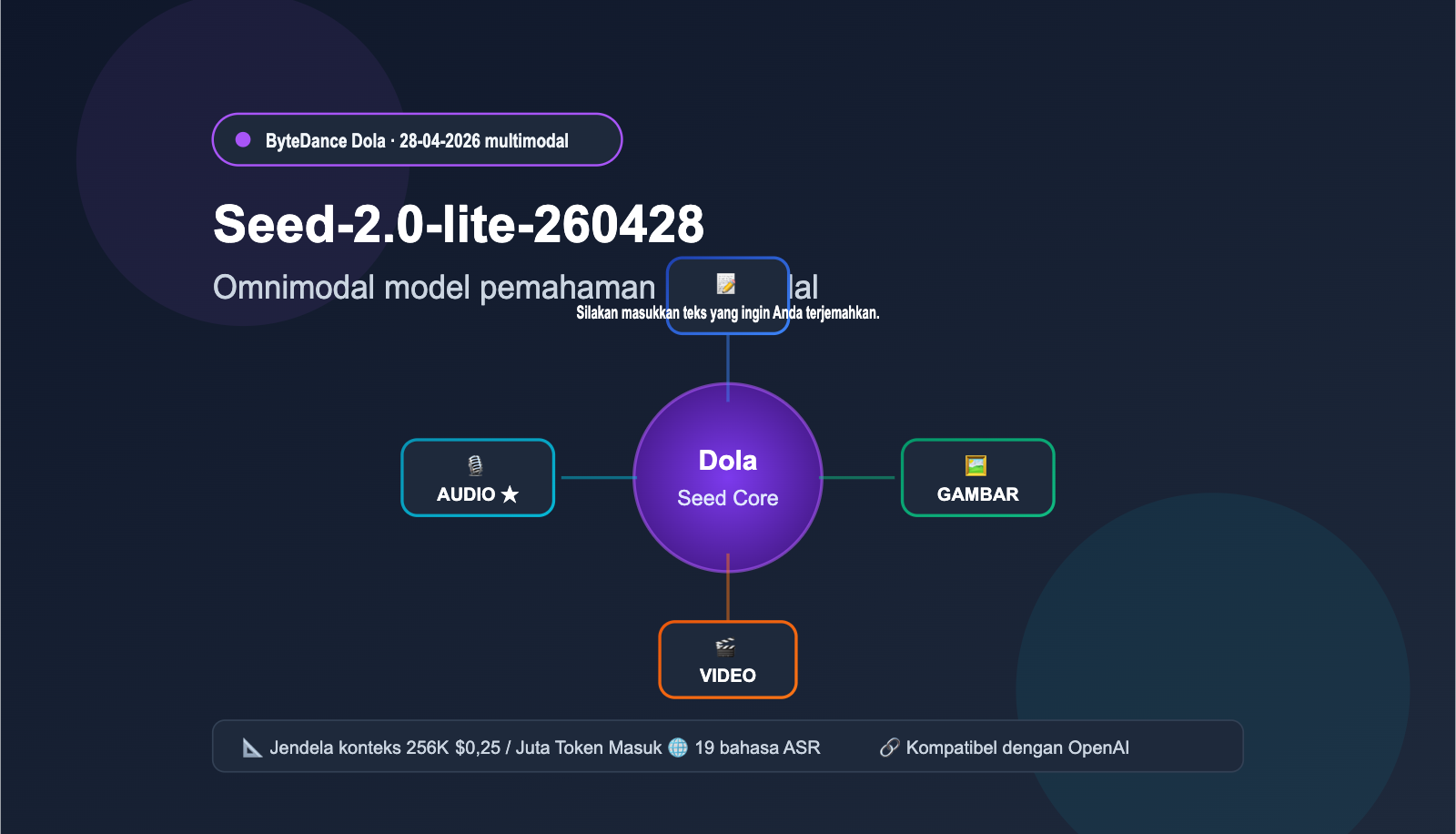
Seed-2.0-lite-260428 adalah iterasi penting dari ByteDance Seed yang dirilis pada 28 April 2026. Model dasarnya masih menggunakan Seed-2.0-Lite yang dirilis awal Maret, namun untuk pertama kalinya menambahkan "input audio" sebagai kemampuan native, sehingga membawa lini produk ini ke tahap "omnimodal" yang sesungguhnya. Angka 260428 pada nama model merujuk pada versi tanggal 28 April 2026.
1.1 Model Omnimodal Pertama dari Keluarga Dola ByteDance
Dalam keluarga Dola Seed sebelumnya, kemampuan teks dan multimodal ditempatkan di cabang yang berbeda. Seed-2.0-lite-260428 menyatukan video, gambar, audio, dan teks dalam satu model inferensi yang sama. Artinya, model ini dapat "melihat layar video" dan "mendengar konten audio" secara bersamaan, lalu melakukan penilaian gabungan serta pencarian sekuensial berdasarkan data tersebut. Arsitektur terpadu ini sangat krusial untuk aplikasi berbasis Agent, karena banyak tugas nyata (seperti moderasi video, ringkasan rapat, dan kontrol kualitas layanan pelanggan) secara alami memerlukan penalaran lintas modal.
1.2 Ringkasan Spesifikasi Utama Model
Tabel di bawah ini merangkum parameter utama Seed-2.0-lite-260428 yang tersedia di BytePlus ModelArk saat ini, agar pembaca dapat dengan cepat menentukan apakah model ini sesuai dengan kebutuhan bisnis mereka.
| Item Spesifikasi | Parameter Detail |
|---|---|
| ID Model API | seed-2-0-lite-260428 |
| Keluarga Model | ByteDance Seed / Dola |
| Tanggal Rilis | 28-04-2026 |
| Jendela Konteks | 262.144 token (sekitar 256K) |
| Output Maksimum | 131.072 token (sekitar 128K) |
| Modalitas Input | Teks + Gambar + Video + Audio |
| Harga Input | $0,25 / Juta token |
| Harga Output | $2,00 / Juta token |
| Kompatibilitas Antarmuka | API Kompatibel OpenAI |
二、4 Kemampuan Utama Pemahaman Multimodal Seed-2.0-lite-260428
Kemampuan multimodal model ini bukan sekadar "menghubungkan" berbagai input, melainkan melakukan penalaran gabungan melalui representasi terpadu. Dokumentasi resmi merangkum kemampuan intinya ke dalam empat arah.
2.1 Penalaran Gabungan Audio-Video dan Pencarian Berbasis Waktu
Model ini dapat menganalisis informasi visual dan audio dalam video secara bersamaan, serta menilai secara akurat apakah "gambar yang dilihat" konsisten dengan "suara yang didengar". Misalnya, model dapat menentukan apakah ekspresi karakter dalam video sesuai dengan emosi saat berbicara, atau apakah gerakan objek dalam layar sesuai dengan efek suara yang tepat. Kemampuan penyelarasan audio-video ini sangat praktis untuk skenario seperti moderasi video dan deteksi deepfake.
2.2 Dekomposisi Video Mendalam dan Pelacakan Jangka Panjang
Untuk video berdurasi panjang, Seed-2.0-lite-260428 mendukung ekstraksi petunjuk kunci di berbagai segmen waktu, melacak perkembangan karakter dan peristiwa secara berkelanjutan, serta melakukan penalaran multi-langkah antar bingkai untuk merekonstruksi hubungan peristiwa dan konteks perilaku. Dibandingkan dengan pendekatan tradisional yang mendeskripsikan per bingkai, kemampuan "pemahaman urutan panjang" ini lebih cocok untuk tugas seperti peninjauan video pengawasan dan asisten penyuntingan film dokumenter.
2.3 Peningkatan Kemampuan Agen dan Pengodean
Model ini memiliki kemampuan eksekusi yang stabil dan andal dalam tugas-tugas urutan panjang yang kompleks, serta memiliki kemampuan pengembangan full-stack yang mendalam. Artinya, pengembang dapat menghubungkannya ke kerangka kerja Agen untuk menjalankan siklus tertutup yang mencakup perencanaan, pemanggilan alat, peninjauan langkah historis, dan pembuatan kode, tanpa perlu memecah tugas ke beberapa model yang berbeda.
2.4 Antarmuka Terpadu untuk Pemahaman GUI dan Eksekusi Operasi
Kemampuan GUI diintegrasikan ke dalam antarmuka yang sama, di mana model dapat memahami tangkapan layar (tombol, formulir, menu) sekaligus mengeluarkan instruksi operasi (koordinat klik, pengetikan teks). Ini merupakan peningkatan kemampuan langsung untuk pengujian otomatis, Agen desktop, dan aplikasi jenis RPA.
III、Analisis Mendalam Kemampuan Pemahaman Audio Seed-2.0-lite-260428
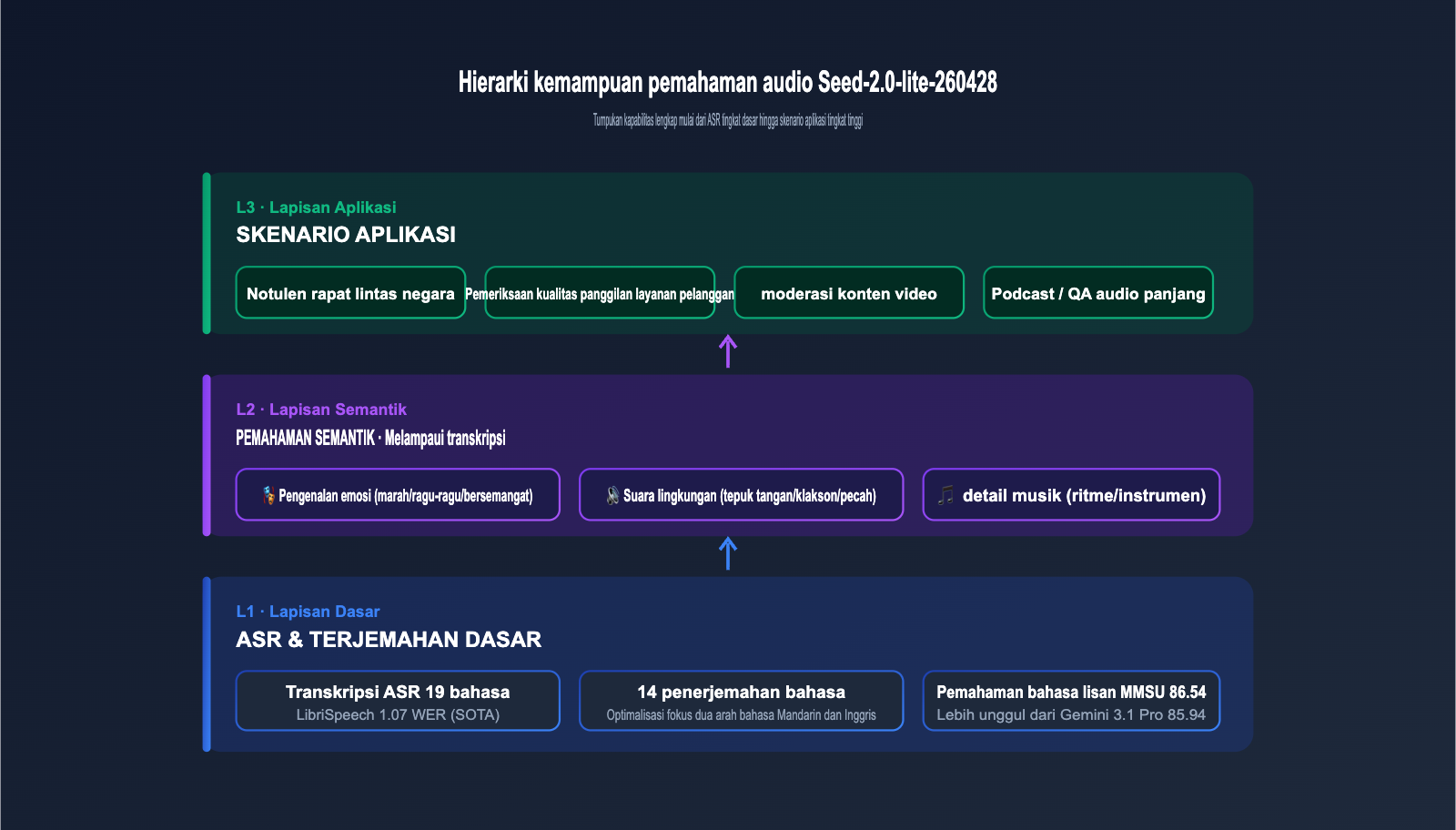
Audio adalah kemampuan pembeda terbesar dalam pembaruan kali ini, jadi kami akan membahasnya secara terpisah. Model ini memberikan hasil yang sangat mengesankan pada berbagai tolok ukur audio arus utama.
3.1 Skor Pengujian Tolok Ukur Audio Arus Utama
Tabel di bawah merangkum hasil tolok ukur yang dipublikasikan secara resmi oleh ByteDance Seed, mencakup tiga dimensi: pengenalan ucapan (ASR), pemahaman bahasa lisan, dan skenario ucapan di lapangan.
| Tolok Ukur | Jenis Tugas | Seed-2.0-lite-260428 |
|---|---|---|
| LibriSpeech test-clean | ASR Bahasa Inggris (Bersih) | 1.07 WER |
| LibriSpeech test-other | ASR Bahasa Inggris (Bising) | 2.17 WER |
| WenetSpeech test-net | ASR Bahasa Mandarin (Jaringan) | 4.47 WER |
| WenetSpeech test-meeting | ASR Rapat Bahasa Mandarin | 5.31 WER |
| Fleurs (15 Bahasa) | ASR Multibahasa | 74.70 |
| MMSU | Pemahaman Bahasa Lisan | 86.54 |
| WildSpeech | Ucapan di Lapangan | 75.81 |
WER sebesar 1.07 pada LibriSpeech test-clean sudah berada di level teratas industri, mengungguli hasil serupa dari Whisper large-v3 yang tersedia untuk publik; skor MMSU dan WildSpeech juga sedikit lebih tinggi daripada data publik Gemini 3.1 Pro, yang menunjukkan bahwa model ini juga mencapai level unggulan arus utama dalam hal "pemahaman", bukan sekadar "transkripsi".
3.2 Transkripsi 19 Bahasa dan Terjemahan Antar 14 Bahasa
Dokumentasi resmi menyatakan bahwa model ini mendukung transkripsi ucapan dalam 19 bahasa dan terjemahan antar 14 bahasa, dengan terjemahan dua arah Mandarin-Inggris sebagai fokus optimasi utama. Artinya, untuk rekaman rapat multibahasa yang sama, model dapat menghasilkan subtitle dan terjemahan dalam bahasa yang seragam, cocok untuk tim lintas negara, layanan pelanggan e-commerce lintas batas, dan skenario lainnya.
3.3 Melampaui "Transkripsi": Emosi, Suara Latar, dan Detail Musik
Perbedaan terbesar dari model ASR tradisional adalah Seed-2.0-lite-260428 juga dapat menangkap informasi tingkat semantik di luar "konten teks": fluktuasi emosi pembicara (marah, ragu-ragu, bersemangat), suara latar belakang (kaca pecah, tepuk tangan, klakson mobil), dan detail musik (ritme, instrumen, gaya). Dimensi-dimensi ini memiliki nilai langsung untuk bisnis seperti pemeriksaan kualitas layanan pelanggan, moderasi konten, dan rekomendasi musik.
🎯 Saran Akses: Dalam skenario yang membutuhkan sinergi "audio + teks" seperti notulensi rapat lintas batas, pemeriksaan kualitas layanan pelanggan, dan moderasi konten video, kami menyarankan untuk mengakses Seed-2.0-lite-260428 secara langsung melalui APIYI apiyi.com. Satu
base_urlsudah cukup untuk mendapatkan manfaat ganda dari penalaran multimodal dan jendela konteks 256K, tanpa perlu membangun jalur pipa suara sendiri.
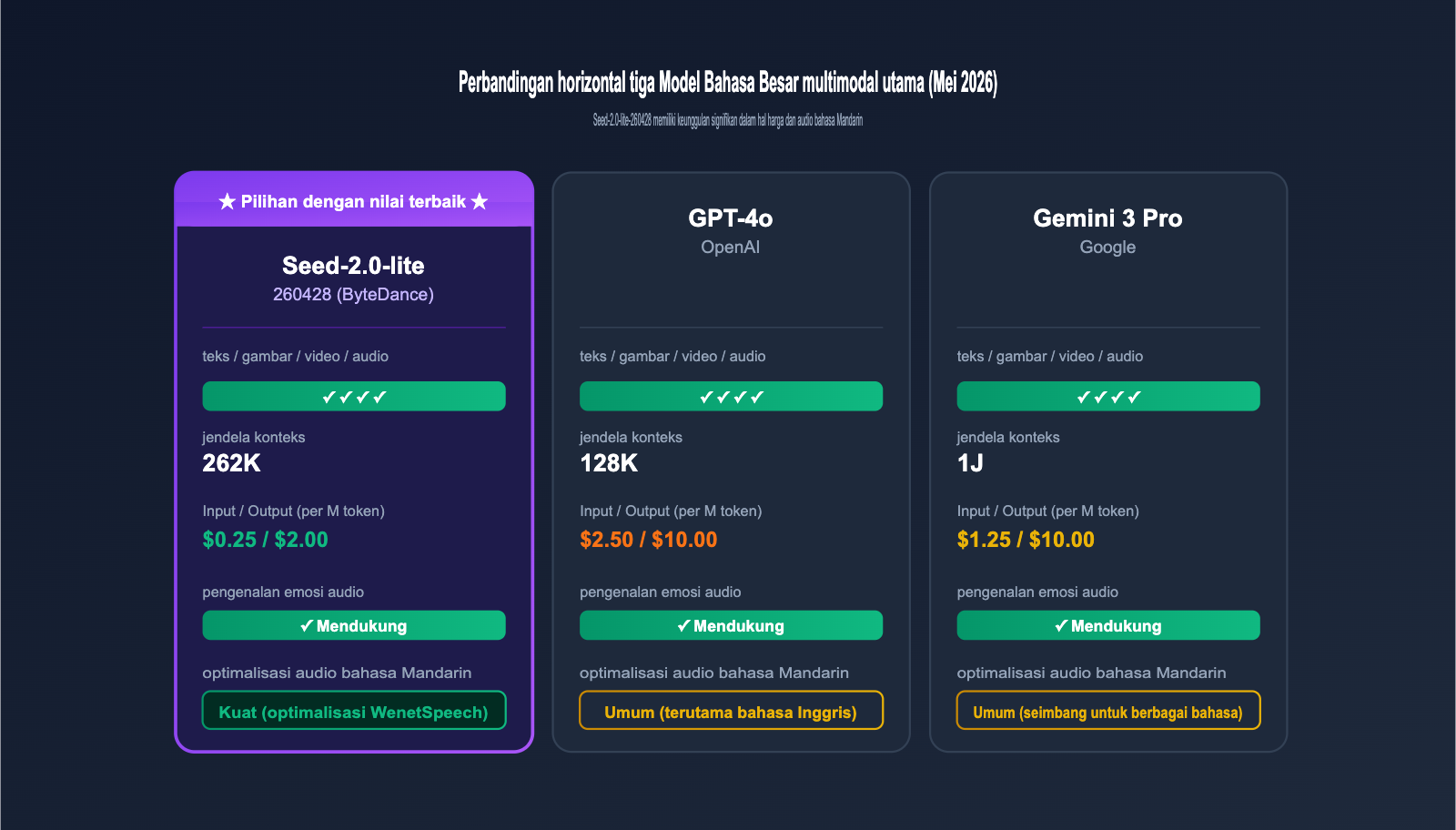
IV. Perbandingan Horizontal Seed-2.0-lite-260428 dengan Model Multimodal Utama
Cara terbaik untuk menilai posisi model ini di tahun 2026 adalah dengan membandingkannya langsung dengan model multimodal unggulan di periode yang sama, seperti GPT-4o dan Gemini 3 Pro.
4.1 Perbandingan Kemampuan Model Multimodal Utama
| Dimensi | Seed-2.0-lite-260428 | GPT-4o | Gemini 3 Pro |
|---|---|---|---|
| Input Teks | ✓ | ✓ | ✓ |
| Input Gambar | ✓ | ✓ | ✓ |
| Input Video | ✓ | ✓ | ✓ |
| Input Audio | ✓ | ✓ | ✓ |
| Jendela Konteks | 262K | 128K | 1M |
| Harga Input / M | $0,25 | $2,50 | $1,25 |
| Harga Output / M | $2,00 | $10,00 | $10,00 |
| Pengenalan Emosi Audio | ✓ | ✓ | ✓ |
| Optimasi Audio Mandarin | Kuat (Optimasi WenetSpeech) | Standar | Standar |
Seperti yang terlihat, keunggulan utama Seed-2.0-lite-260428 terletak pada kombinasi "harga + audio Mandarin + jendela konteks panjang 256K". Hal ini membuatnya sangat hemat biaya untuk tugas-tugas seperti pemrosesan audio-video multibahasa dan rekapitulasi rapat panjang. Sementara itu, GPT-4o dan Gemini 3 Pro tetap unggul dalam kemampuan komprehensif bahasa Inggris dan luasnya ekosistem, sehingga lebih cocok untuk skenario penggunaan umum.
🎯 Saran Pemilihan: Jika bisnis Anda berfokus pada pemrosesan audio-video Mandarin dan sensitif terhadap biaya, Seed-2.0-lite-260428 adalah pilihan dengan nilai terbaik saat ini. Jika Anda lebih banyak menggunakan bahasa Inggris atau membutuhkan pembuatan konten kreatif multibahasa yang intensif, Anda dapat menggunakan gerbang terpadu APIYI (apiyi.com) untuk mengakses ketiga model unggulan ini sekaligus dan melakukan perutean berdasarkan skenario.
V. Memulai Cepat Pemanggilan Seed-2.0-lite-260428 melalui APIYI
Model ini sepenuhnya kompatibel dengan antarmuka gaya OpenAI, sehingga biaya migrasi sangat rendah. Berikut adalah contoh pemanggilan minimalis untuk mengubah potongan gambar atau audio menjadi deskripsi terstruktur.
5.1 Contoh Minimalis Antarmuka yang Kompatibel dengan OpenAI
from openai import OpenAI
client = OpenAI(
api_key="<APIYI_API_KEY>",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="seed-2-0-lite-260428",
messages=[
{"role": "user", "content": [
{"type": "text", "text": "Tolong deskripsikan konten, emosi, dan suara latar dari audio ini."},
{"type": "input_audio", "audio": {"data": "<base64-or-url>", "format": "mp3"}}
]}
]
)
print(response.choices[0].message.content)
Arahkan base_url ke titik akses terpadu APIYI apiyi.com, lalu cukup ganti model untuk memanggil Seed-2.0-lite-260428 dan model multimodal lainnya dalam SDK yang sama, tanpa perlu menulis ulang kode di sisi bisnis Anda.
5.2 Skenario Aplikasi Khas untuk Seed-2.0-lite-260428
Tabel di bawah ini merangkum beberapa skenario khas dan manfaat yang bisa didapatkan dari fitur "inferensi terpadu audio + video + teks" pada model ini.
| Skenario Aplikasi | Kemampuan Utama | Nilai Bisnis |
|---|---|---|
| Notulensi Rapat Lintas Negara | ASR 19 bahasa + Terjemahan 14 bahasa + Jendela konteks 256K | Notulensi dwibahasa sekali klik untuk rapat multibahasa |
| Kendali Mutu Panggilan CS | Pengenalan emosi + Deteksi suara latar + Analisis audio panjang | Penandaan otomatis untuk kemarahan/interupsi/durasi berlebih |
| Moderasi Konten Video | Inferensi gabungan audio-video + Pelacakan sekuensial panjang | Identifikasi simultan gambar berbahaya dan suara mencurigakan |
| QA Podcast / Video Panjang | Jendela konteks 256K + Transkripsi audio | Tanya jawab langsung pada konten audio berdurasi berjam-jam |
| Otomatisasi Agen Desktop | Pemahaman GUI + Pemanggilan alat | Menyelesaikan alur kerja kompleks lintas aplikasi |
VI. Tanya Jawab Umum Seed-2.0-lite-260428
6.1 Bagaimana cara mengisi kolom model saat pemanggilan API?
Cukup isi dengan seed-2-0-lite-260428. Perhatikan bahwa di tengahnya adalah tanda hubung, bukan garis bawah; akhiran 260428 adalah nomor versi (28-04-2026), jangan dihilangkan agar tidak diarahkan ke versi lama. Daftar model dapat diperiksa di konsol APIYI apiyi.com untuk memastikan kesesuaian dengan rilis terbaru.
6.2 Format dan durasi audio apa saja yang didukung?
Model mengikuti konvensi kolom input_audio gaya OpenAI, mendukung format umum seperti MP3, WAV, M4A, dan FLAC. Durasi maksimum dan laju sampel spesifik mengacu pada dokumentasi resmi ModelArk. Kami menyarankan input tunggal tidak melebihi 30 menit untuk memastikan stabilitas inferensi. Audio yang sangat panjang dapat dipotong per segmen lalu digabungkan hasilnya.
6.3 Apa perbedaan dengan Seed-2.0-Lite tanpa akhiran 260428?
Versi tanpa akhiran adalah Seed-2.0-Lite generasi pertama yang dirilis pada 10 Maret, hanya mendukung teks, gambar, dan video. Versi 260428 adalah versi peningkatan multimodal penuh yang dirilis pada 28 April, dengan penambahan input audio dan kemampuan inferensi gabungan audio-video. Jika bisnis Anda menggunakan audio, Anda wajib menggunakan versi dengan akhiran tersebut.
6.4 Apakah penagihan didasarkan pada token atau durasi audio?
Model ditagih secara terpadu berdasarkan token, di mana audio akan dikodekan secara internal menjadi token sebelum dihitung. Harga saat ini adalah $0,25 / M input dan $2,00 / M output. Jumlah token yang sesuai untuk potongan audio tertentu dapat dilihat di "Riwayat Tagihan" pada konsol APIYI apiyi.com untuk memudahkan estimasi dan optimasi biaya.
6.5 Apakah mendukung output streaming dan Function Call?
Sepenuhnya mendukung. Seed-2.0-lite-260428 kompatibel dengan protokol standar OpenAI Chat Completions untuk bidang stream=true dan tools, sehingga dapat langsung diintegrasikan ke kerangka kerja utama seperti LangChain, LangGraph, OpenAI Agents SDK, dan lainnya tanpa modifikasi khusus.
VII. Kesimpulan: Model Full-Modal Membawa Aplikasi Multimodal ke Era "Inferensi Terpadu"
Nilai dari Seed-2.0-lite-260428 bukan sekadar "menambah kemampuan audio", melainkan menyatukan video, gambar, audio, dan teks dalam satu model yang sama untuk melakukan inferensi. Bagi bisnis yang secara alami bersifat lintas modal (seperti rapat, layanan pelanggan, moderasi konten, analisis video, dan otomatisasi Agen), "inferensi terpadu" ini merupakan penyederhanaan arsitektur yang sesungguhnya: Anda tidak perlu lagi menggabungkan tiga model terpisah untuk ASR, visual, dan teks, serta tidak perlu khawatir akan hilangnya konteks antar-model.
Dilihat dari sisi biaya dan skenario penggunaan bahasa Mandarin, model ini memiliki keunggulan rasio harga-performa yang sangat signifikan di antara model unggulan lainnya. Harga $0,25 / M input membuat pemrosesan audio dan video skala besar menjadi layak secara teknis, dan jendela konteks 256K sudah cukup untuk mencakup skenario audio dan video berdurasi panjang selama berjam-jam.
Jika Anda perlu memanggil Seed-2.0-lite-260428 dan berbagai model multimodal unggulan lainnya di bawah base_url yang sama, silakan kunjungi dokumentasi resmi APIYI di apiyi.com untuk melihat contoh integrasi lengkap dan daftar model yang tersedia.
Penulis: Tim APIYI — Terus menyediakan layanan proksi API dan perutean multi-model yang stabil dan efisien bagi pengembang AI global. Kunjungi apiyi.com untuk detail lebih lanjut.