Обновление, которое точно стоит взять на заметку разработчикам: 28 апреля 2026 года семейство базовых моделей Dola от ByteDance пополнилось первой моделью с поддержкой понимания всех модальностей (Omnimodal) — Seed-2.0-lite-260428. Она нативно поддерживает ввод видео, изображений, аудио и текста. Это первая модель в семействе Dola Seed, которая «видит и слышит одновременно», а также получила значительные улучшения в задачах, связанных с агентами (Agent), написанием кода (Coding) и графическими интерфейсами (GUI). В этой статье мы разберем возможности модели, детали обработки аудио и типичные сценарии использования, опираясь на официальные спецификации BytePlus ModelArk, публичные бенчмарки ByteDance Seed и результаты тестирования через APIYI (apiyi.com).
I. Что такое Seed-2.0-lite-260428: позиционирование и ключевые обновления
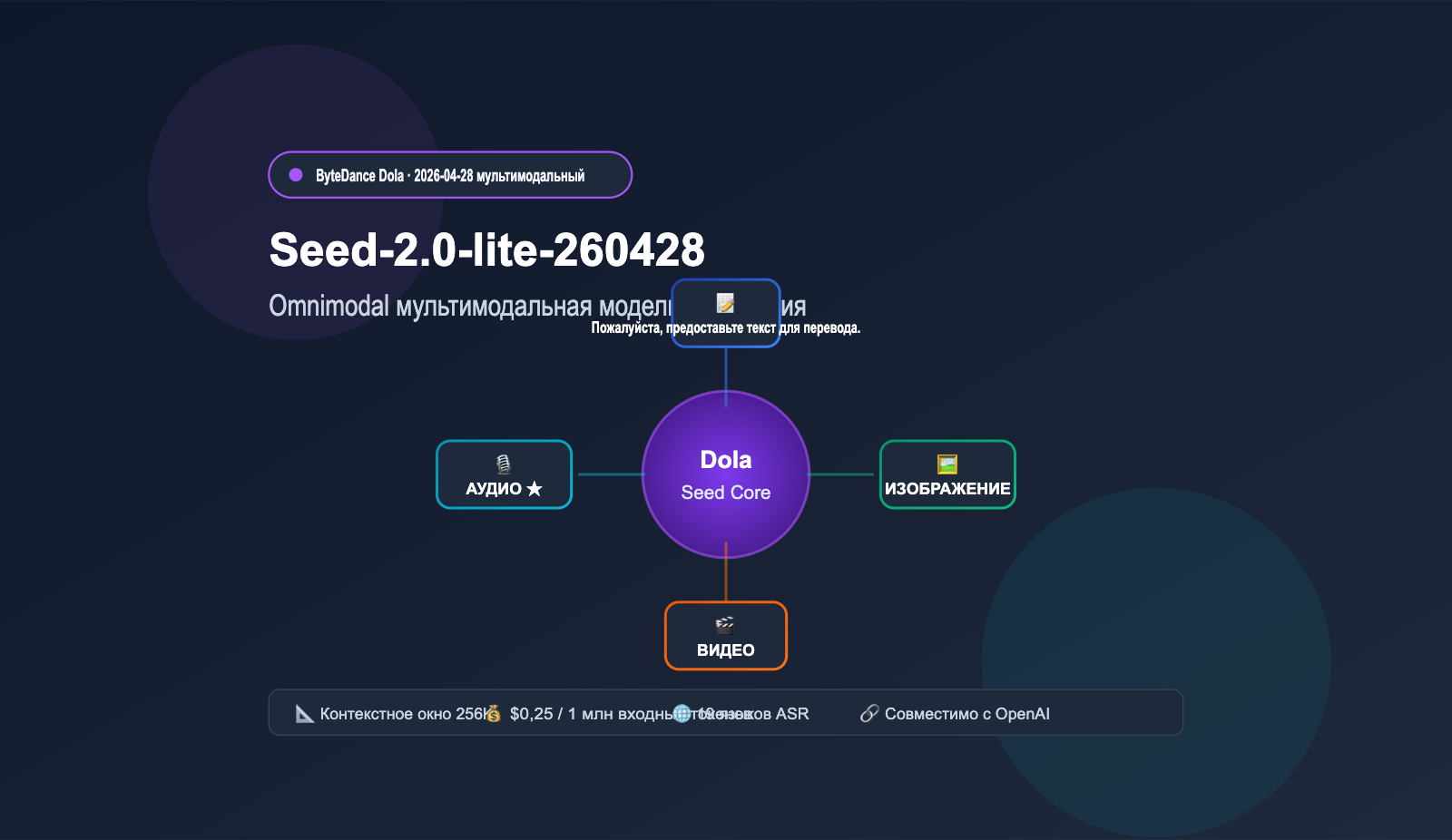
Seed-2.0-lite-260428 — это важный этап развития семейства ByteDance Seed, выпущенный 28 апреля 2026 года. В качестве основы используется модель Seed-2.0-Lite, представленная в начале марта, но теперь в нее впервые добавлена нативная поддержка аудиоввода, что переводит линейку в категорию полноценных «мультимодальных» (Omnimodal) решений. Индекс 260428 в названии указывает на дату релиза.
1.1 Первая мультимодальная модель в семействе Dola от ByteDance
Ранее в семействе Dola Seed текстовые и мультимодальные возможности были разделены по разным веткам. Seed-2.0-lite-260428 объединяет обработку видео, изображений, аудио и текста в рамках одного вызова модели. Это означает, что она может одновременно «видеть» видеоряд и «слышать» аудиодорожку, выполняя на их основе комплексный анализ и временной поиск. Такая унифицированная архитектура критически важна для агентских приложений, так как многие реальные задачи (например, модерация видео, создание протоколов совещаний или контроль качества в поддержке) требуют кросс-модального вывода.
1.2 Краткий обзор характеристик модели
В таблице ниже собраны основные параметры Seed-2.0-lite-260428, доступные через BytePlus ModelArk, чтобы вы могли быстро оценить, подходит ли модель для ваших задач.
| Параметр | Значение |
|---|---|
| ID модели API | seed-2-0-lite-260428 |
| Семейство моделей | ByteDance Seed / Dola |
| Дата релиза | 28.04.2026 |
| Контекстное окно | 262 144 токенов (ок. 256K) |
| Макс. выход | 131 072 токенов (ок. 128K) |
| Входные модальности | текст + изображение + видео + аудио |
| Цена на вход | $0.25 / 1 млн токенов |
| Цена на выход | $2.00 / 1 млн токенов |
| Совместимость | OpenAI Compatible API |
二、4 ключевые способности мультимодального понимания Seed-2.0-lite-260428
Мультимодальность модели — это не просто «подключение» различных типов входных данных, а полноценный совместный вывод на основе унифицированного представления. В официальной документации ключевые возможности модели разделены на четыре направления.
2.1 Совместный аудиовизуальный вывод и временной поиск
Модель способна одновременно анализировать визуальную и аудиоинформацию в видео, точно определяя, соответствуют ли «увиденное» и «услышанное» друг другу. Например, она может понять, совпадает ли выражение лица персонажа с эмоциональной окраской его речи или соответствуют ли действия объектов на экране звуковым эффектам. Такая способность к аудиовизуальному выравниванию крайне полезна для модерации видео, обнаружения дипфейков и других подобных задач.
2.2 Глубокий анализ видео и долгосрочное отслеживание
Для длинных видео Seed-2.0-lite-260428 поддерживает извлечение ключевых данных из нескольких временных отрезков. Модель непрерывно отслеживает развитие событий и персонажей, выполняя многошаговый вывод между кадрами для восстановления контекста поведения и взаимосвязей. В отличие от традиционного покадрового описания, такой «долгосрочный анализ» лучше подходит для разбора записей с камер наблюдения или помощи в монтаже документальных фильмов.
2.3 Улучшенные возможности агентов и кодинга
Модель демонстрирует стабильность и надежность при выполнении сложных задач с длинным временным рядом, а также обладает глубокими навыками полностековой разработки. Это означает, что разработчики могут интегрировать её в агентские фреймворки для реализации полного цикла: планирования, вызова инструментов, анализа истории действий и генерации кода — без необходимости разделять задачу между несколькими моделями.
2.4 Унифицированный интерфейс для понимания GUI и управления
Функции GUI интегрированы в единый интерфейс: модель не только понимает скриншоты (кнопки, формы, меню), но и выдает команды управления (координаты кликов, ввод текста). Это прямой апгрейд возможностей для автоматизированного тестирования, настольных агентов и RPA-решений.
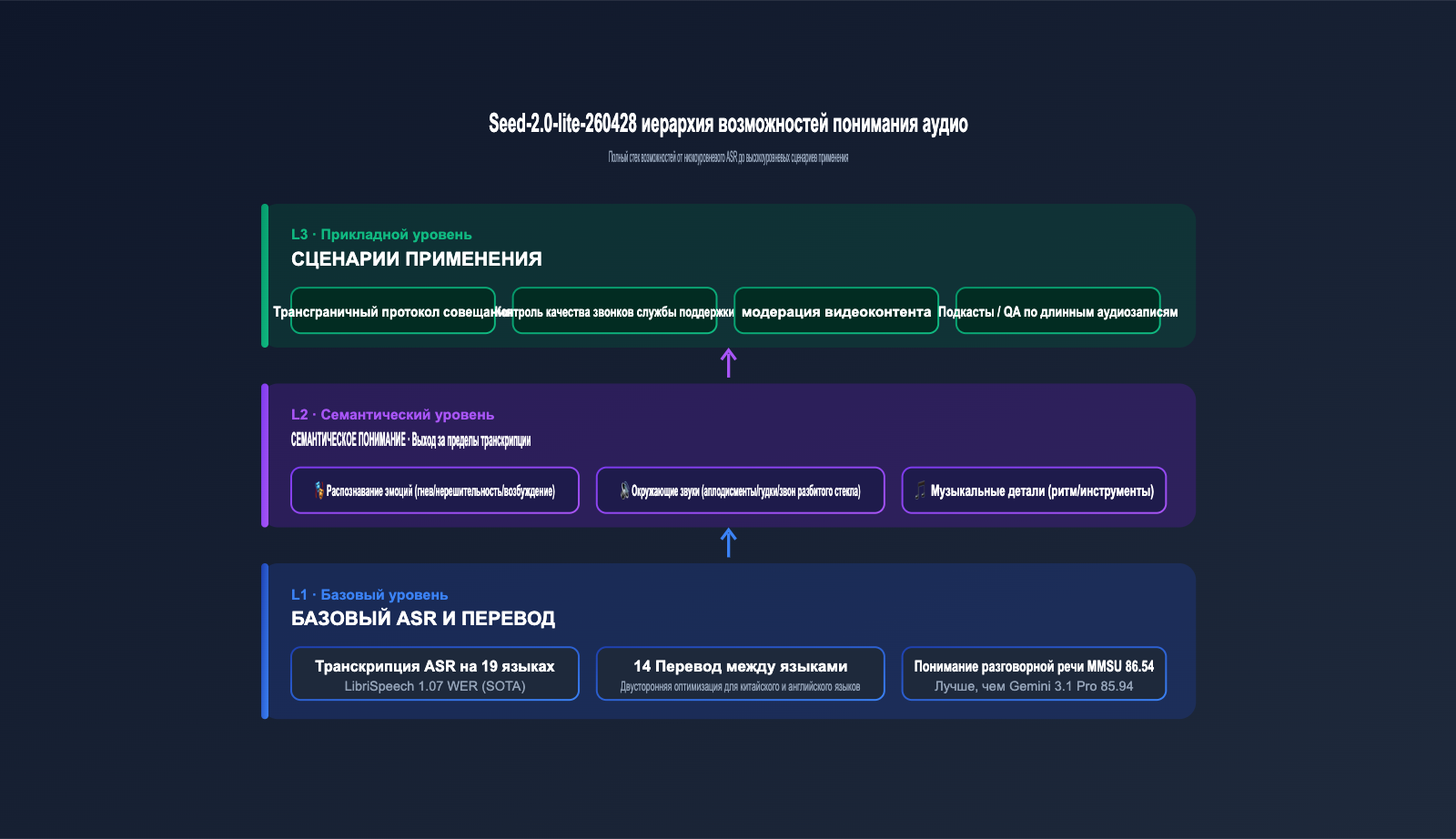
三、Глубокий анализ возможностей понимания аудио в Seed-2.0-lite-260428
Аудио — это главное отличие данного обновления, поэтому остановимся на нем подробнее. Модель показала впечатляющие результаты в ряде ведущих аудио-бенчмарков.
3.1 Результаты тестирования на основных аудио-бенчмарках
В таблице ниже собраны официальные результаты ByteDance Seed, охватывающие три измерения: распознавание речи (ASR), понимание разговорной речи и работу с аудио в «полевых» условиях.
| Бенчмарк | Тип задачи | Seed-2.0-lite-260428 |
|---|---|---|
| LibriSpeech test-clean | Английский ASR (чистый) | 1.07 WER |
| LibriSpeech test-other | Английский ASR (шум) | 2.17 WER |
| WenetSpeech test-net | Китайский ASR (сеть) | 4.47 WER |
| WenetSpeech test-meeting | Китайский ASR (конференция) | 5.31 WER |
| Fleurs (15 языков) | Мультиязычный ASR | 74.70 |
| MMSU | Понимание разговорной речи | 86.54 |
| WildSpeech | «Полевая» речь | 75.81 |
Показатель WER 1.07 на LibriSpeech test-clean уже находится на топовом уровне, превосходя аналогичные результаты Whisper large-v3. Оценки MMSU и WildSpeech также немного выше публичных данных Gemini 3.1 Pro, что доказывает: модель достигла уровня флагманов не только в «диктовке», но и в глубоком понимании.
3.2 Транскрипция на 19 языках и перевод между 14 языками
Согласно документации, модель поддерживает транскрипцию на 19 языках и взаимный перевод между 14 языками, при этом двусторонний китайско-английский перевод стал приоритетным направлением оптимизации. Это означает, что для одной многоязычной записи конференции модель может выдать субтитры и перевод на едином языке, что идеально подходит для международных команд или служб поддержки.
3.3 Больше, чем просто «транскрипция»: эмоции, фоновые звуки и музыкальные детали
Главное отличие от традиционных ASR-моделей заключается в том, что Seed-2.0-lite-260428 улавливает семантическую информацию за пределами текста: эмоциональные колебания говорящего (гнев, сомнение, возбуждение), фоновые шумы (звон разбитого стекла, аплодисменты, гудки автомобилей) и музыкальные нюансы (ритм, инструменты, стиль). Эти данные имеют прямую ценность для контроля качества в колл-центрах, модерации контента и рекомендательных систем.
🎯 Рекомендация по интеграции: Для сценариев, требующих синергии «аудио + текст» (создание протоколов совещаний, контроль качества в поддержке, модерация видео), мы рекомендуем использовать Seed-2.0-lite-260428 через сервис-прокси API APIYI (apiyi.com). Один
base_urlобеспечит вам преимущества мультимодального вывода и контекстного окна в 256K без необходимости самостоятельно строить конвейеры обработки аудио.
IV. Сравнительный анализ Seed-2.0-lite-260428 и ведущих мультимодальных моделей
Чтобы понять место этой модели в 2026 году, лучше всего сравнить её с флагманскими мультимодальными моделями того же периода, такими как GPT-4o и Gemini 3 Pro.
4.1 Сравнение возможностей популярных мультимодальных моделей
| Параметр | Seed-2.0-lite-260428 | GPT-4o | Gemini 3 Pro |
|---|---|---|---|
| Текстовый ввод | ✓ | ✓ | ✓ |
| Ввод изображений | ✓ | ✓ | ✓ |
| Ввод видео | ✓ | ✓ | ✓ |
| Ввод аудио | ✓ | ✓ | ✓ |
| Контекстное окно | 262K | 128K | 1M |
| Цена за вход / M | $0.25 | $2.50 | $1.25 |
| Цена за выход / M | $2.00 | $10.00 | $10.00 |
| Распознавание эмоций в аудио | ✓ | ✓ | ✓ |
| Оптимизация аудио (китайский) | Высокая (WenetSpeech) | Средняя | Средняя |
Как видите, ключевое преимущество Seed-2.0-lite-260428 заключается в сочетании «цена + работа с китайским аудио + контекстное окно 262K». Это делает модель особенно выгодной для задач обработки многоязычного аудио и видео, а также для анализа длинных записей совещаний. GPT-4o и Gemini 3 Pro по-прежнему лидируют в комплексных задачах на английском языке и обладают более широкой экосистемой, что делает их отличным выбором для универсальных сценариев.

🎯 Рекомендация по выбору: Если ваш бизнес в основном связан с обработкой аудио и видео на китайском языке и вы чувствительны к затратам, Seed-2.0-lite-260428 — это отличный выбор с высокой рентабельностью. Если же вы работаете преимущественно с английским языком или занимаетесь сложной многоязычной генерацией контента, вы можете использовать APIYI (apiyi.com) как единый шлюз для доступа ко всем трем флагманским моделям и переключаться между ними в зависимости от задачи.
5. Быстрый старт: вызов Seed-2.0-lite-260428 через APIYI
Модель полностью совместима с интерфейсом в стиле OpenAI, поэтому миграция пройдет максимально безболезненно. Ниже приведен минималистичный пример вызова для преобразования аудио или изображения в структурированное описание.
5.1 Минимальный пример использования совместимого API
from openai import OpenAI
client = OpenAI(
api_key="<APIYI_API_KEY>",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="seed-2-0-lite-260428",
messages=[
{"role": "user", "content": [
{"type": "text", "text": "Опиши содержание, эмоции и фоновые звуки в этой аудиозаписи."},
{"type": "input_audio", "audio": {"data": "<base64-or-url>", "format": "mp3"}}
]}
]
)
print(response.choices[0].message.content)
Просто укажите base_url на единую точку входа APIYI (apiyi.com) и переключите model — это позволит вызывать Seed-2.0-lite-260428 и другие мультимодальные модели в рамках одного SDK без необходимости переписывать код.
5.2 Типичные сценарии использования Seed-2.0-lite-260428
В таблице ниже собраны типичные сценарии и преимущества, которые дает функция «единого вывода аудио + видео + текста» этой модели.
| Сценарий | Ключевые возможности | Бизнес-ценность |
|---|---|---|
| Протоколы встреч | ASR на 19 языках + перевод на 14 языков + контекстное окно 256K | Автоматическое создание двуязычных протоколов |
| Контроль качества колл-центров | Распознавание эмоций + фоновых шумов + анализ длинных аудио | Автоматическая пометка гнева/перебиваний/превышения времени |
| Модерация видеоконтента | Совместный аудио-видео анализ + отслеживание во времени | Синхронное выявление опасных кадров и подозрительных звуков |
| QA для подкастов / видео | Контекстное окно 256K + транскрибация аудио | Ответы на вопросы по многочасовым записям |
| Автоматизация Desktop Agent | Понимание GUI + вызов инструментов | Выполнение сложных кросс-приложенческих рабочих процессов |
6. Часто задаваемые вопросы по Seed-2.0-lite-260428
6.1 Что указывать в поле model при вызове API?
Просто впишите seed-2-0-lite-260428. Обратите внимание: в названии используются дефисы, а не подчеркивания. Суффикс 260428 — это номер версии (от 28 апреля 2026 года), его нельзя опускать, иначе запрос может быть перенаправлен на старую версию. Актуальный список моделей всегда можно найти в консоли APIYI (apiyi.com).
6.2 Какие форматы и длительность аудио поддерживаются?
Модель следует соглашению OpenAI для поля input_audio, поддерживаются все популярные форматы: MP3, WAV, M4A, FLAC. Максимальная длительность и частота дискретизации соответствуют официальной документации ModelArk. Для стабильной работы рекомендуем ограничивать один запрос 30 минутами аудио. Сверхдлинные записи можно предварительно нарезать на сегменты.
6.3 В чем отличие от Seed-2.0-Lite без суффикса 260428?
Версия без суффикса — это оригинальный Seed-2.0-Lite, выпущенный 10 марта, он поддерживает только текст, изображения и видео. Версия 260428 — это обновленный мультимодальный релиз от 28 апреля с поддержкой аудиовхода и совместного аудио-видео анализа. Если в вашем проекте используется аудио, обязательно используйте версию с суффиксом.
6.4 Тарификация идет по токенам или по длительности аудио?
Тарификация единая — по токенам. Аудио внутри системы кодируется в токены, которые и участвуют в расчете. Текущая цена: $0.25 за 1 млн токенов на входе и $2.00 за 1 млн на выходе. Количество токенов для конкретной аудиозаписи можно посмотреть в разделе «История счетов» в консоли APIYI, что удобно для прогнозирования и оптимизации расходов.
6.5 Поддерживаются ли потоковый вывод (streaming) и Function Call?
Да, полностью. Seed-2.0-lite-260428 совместима со стандартным протоколом OpenAI Chat Completions, включая параметры stream=true и tools. Вы можете легко интегрировать её в LangChain, LangGraph, OpenAI Agents SDK и другие популярные фреймворки без каких-либо доработок.
VII. Итоги: полнофункциональные модели открывают эру «унифицированного вывода» в мультимодальных приложениях
Ценность Seed-2.0-lite-260428 заключается не просто в «добавлении аудиовозможностей», а в объединении видео, изображений, аудио и текста в рамках одной модели для выполнения вывода. Для задач, которые по своей природе являются кросс-модальными (конференции, клиентская поддержка, модерация контента, видеоаналитика, автоматизация агентов), такой «унифицированный вывод» означает реальное упрощение архитектуры: больше не нужно объединять три разные модели (ASR, визуальную и текстовую), и можно не беспокоиться о потере контекста при переключении между ними.
Если оценивать стоимость и работу с китайским языком, то эта модель обладает явным преимуществом в соотношении цены и качества среди флагманских решений. Цена $0,25 за 1 млн входных токенов делает масштабную обработку аудио и видео технически доступной, а контекстное окно в 256 тыс. токенов вполне достаточно для обработки многочасовых аудиозаписей и длинных видеороликов.
Если вам нужно использовать Seed-2.0-lite-260428 в связке с другими флагманскими мультимодальными моделями через единый base_url, посетите официальную документацию APIYI на сайте apiyi.com, где вы найдете полные примеры интеграции и список доступных моделей.
Автор: Команда APIYI — мы продолжаем предоставлять разработчикам ИИ по всему миру стабильные и эффективные услуги сервис-прокси API и маршрутизации между моделями. Подробности на сайте apiyi.com