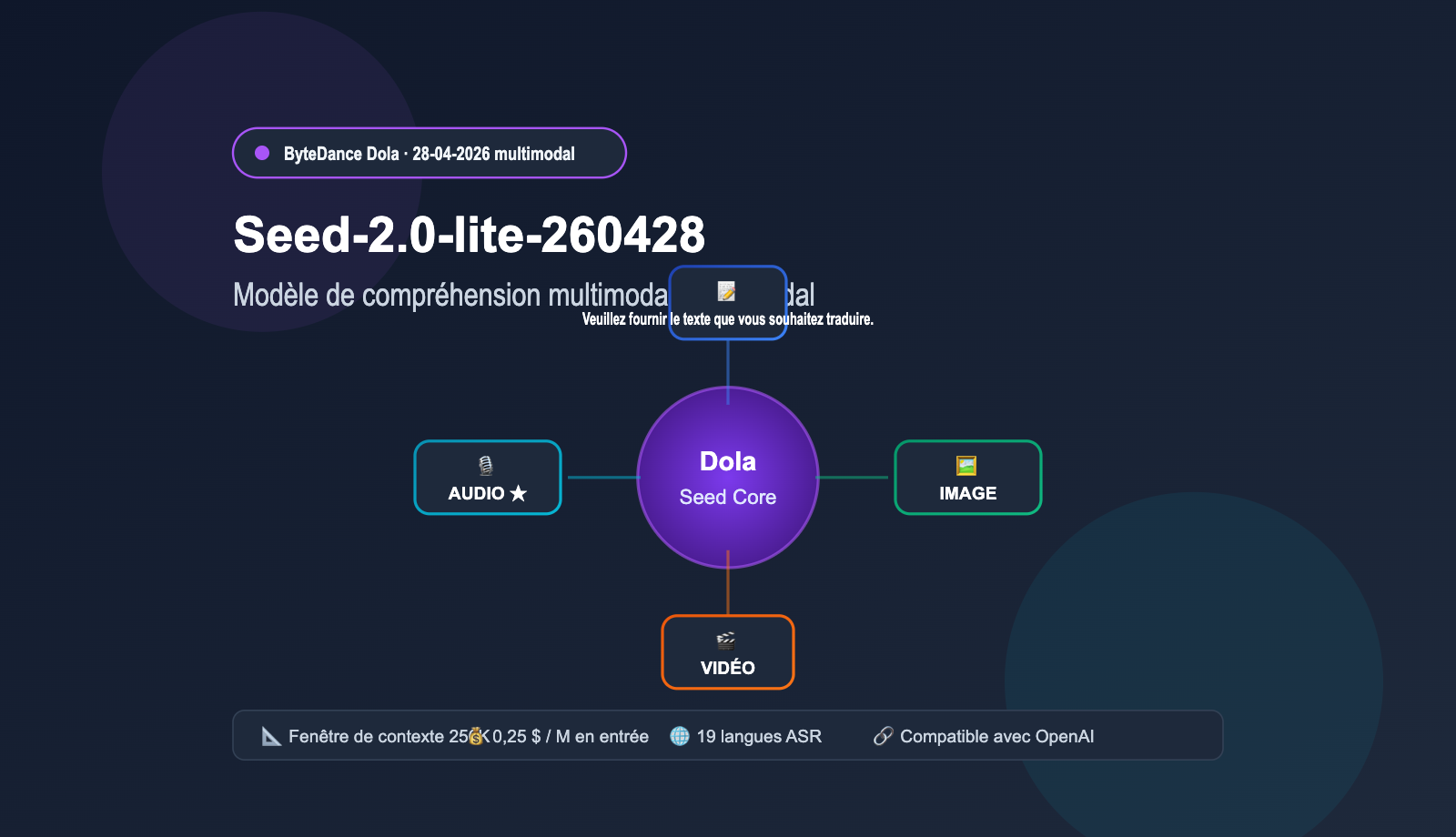
Voici une mise à jour qui mérite toute l'attention des développeurs : la famille de modèles de base Dola de ByteDance a lancé, le 28 avril 2026, son premier modèle de compréhension « omnimodale » : Seed-2.0-lite-260428. Il prend en charge nativement quatre types d'entrées : vidéo, image, audio et texte. C'est le premier modèle de la famille Dola Seed capable de « voir et d'entendre », avec des améliorations simultanées sur les tâches d'Agent, de codage et d'interface graphique (GUI). Cet article, basé sur les spécifications officielles de BytePlus ModelArk, les benchmarks publics de ByteDance Seed et nos tests pratiques via APIYI (apiyi.com), détaille les capacités du modèle, les subtilités de la compréhension audio et les scénarios d'application typiques.
I. Qu'est-ce que Seed-2.0-lite-260428 : positionnement et points clés de la mise à jour
Seed-2.0-lite-260428 est une itération majeure de ByteDance Seed publiée le 28 avril 2026. Le modèle de base reprend le Seed-2.0-Lite sorti début mars, mais intègre pour la première fois l'« entrée audio » en tant que capacité native, propulsant cette gamme de produits vers une phase véritablement « omnimodale ». Le suffixe 260428 dans le nom du modèle correspond à la date de version du 28 avril 2026.
1.1 Le premier modèle omnimodal de la famille Dola de ByteDance
Dans la famille Dola Seed précédente, les capacités textuelles et multimodales étaient séparées dans des branches distinctes. Seed-2.0-lite-260428 unifie l'inférence vidéo, image, audio et texte au sein d'un même modèle, ce qui signifie qu'il peut simultanément « voir des séquences vidéo » et « écouter du contenu audio » pour effectuer des jugements combinés et une recherche temporelle. Cette architecture unifiée est cruciale pour les applications de type Agent, car de nombreuses tâches réelles (comme la modération vidéo, le résumé de réunions ou le contrôle qualité du service client) nécessitent naturellement un raisonnement intermodal.
1.2 Aperçu des spécifications clés du modèle
Le tableau ci-dessous récapitule les paramètres essentiels de Seed-2.0-lite-260428 sur BytePlus ModelArk, permettant aux lecteurs de déterminer rapidement s'il répond aux besoins de leur activité.
| Élément de spécification | Paramètre spécifique |
|---|---|
| ID du modèle API | seed-2-0-lite-260428 |
| Famille de modèles | ByteDance Seed / Dola |
| Date de publication | 28-04-2026 |
| Fenêtre de contexte | 262 144 jetons (environ 256K) |
| Sortie maximale | 131 072 jetons (environ 128K) |
| Modalités d'entrée | Texte + Image + Vidéo + Audio |
| Prix d'entrée | 0,25 $ / M jetons |
| Prix de sortie | 2,00 $ / M jetons |
| Compatibilité d'interface | API compatible OpenAI |
II. Les 4 capacités clés de compréhension multimodale du Seed-2.0-lite-260428
La capacité multimodale de ce modèle ne consiste pas simplement à "connecter" différentes entrées, mais à effectuer un raisonnement conjoint via une représentation unifiée. La documentation officielle résume ses capacités fondamentales en quatre axes.
2.1 Raisonnement conjoint audio-vidéo et recherche temporelle
Le modèle peut analyser simultanément les informations visuelles et audio d'une vidéo pour déterminer avec précision si "l'image vue" et le "son entendu" sont cohérents. Par exemple, il peut détecter si les expressions faciales d'une personne dans une vidéo correspondent à l'émotion de son discours, ou si les actions des objets à l'écran sont synchronisées avec les effets sonores. Cette capacité d'alignement audio-vidéo est extrêmement utile pour des scénarios comme la modération vidéo ou la détection de deepfakes.
2.2 Décomposition vidéo approfondie et suivi temporel long
Pour les vidéos longues, le Seed-2.0-lite-260428 permet d'extraire des indices clés sur plusieurs segments temporels, de suivre en continu l'évolution des personnages et des événements, et d'effectuer un raisonnement en plusieurs étapes entre les images pour reconstruire les relations et le contexte comportemental. Contrairement aux méthodes traditionnelles de description image par image, sa capacité de "compréhension temporelle longue" est mieux adaptée aux tâches telles que la relecture de vidéos de surveillance ou l'assistance au montage de documentaires.
2.3 Agent amélioré et capacités de codage
Le modèle fait preuve d'une exécution stable et fiable sur des tâches temporelles complexes et possède des capacités de développement full-stack approfondies. Cela signifie que les développeurs peuvent l'intégrer dans un framework d'Agent pour exécuter une boucle complète incluant la planification, l'appel d'outils, la consultation de l'historique et la génération de code, sans avoir à diviser la tâche entre plusieurs modèles différents.
2.4 Interface unifiée pour la compréhension et l'exécution d'actions GUI
La capacité GUI est intégrée dans une interface unique : le modèle peut à la fois comprendre les captures d'écran (boutons, formulaires, menus) et générer des instructions d'action (coordonnées de clic, saisie de texte). Il s'agit d'une mise à niveau directe pour les tests automatisés, les agents de bureau et les applications de type RPA.
III. Analyse approfondie des capacités de compréhension audio du Seed-2.0-lite-260428
L'audio est la plus grande différenciation de cette mise à jour, nous allons donc nous y attarder. Le modèle a obtenu des résultats impressionnants sur plusieurs benchmarks audio majeurs.
3.1 Scores de référence sur les benchmarks audio courants
Le tableau ci-dessous résume les résultats officiels publiés par ByteDance Seed, couvrant trois dimensions : la reconnaissance vocale (ASR), la compréhension du langage parlé et les scénarios vocaux en conditions réelles.
| Benchmark | Type de tâche | Seed-2.0-lite-260428 |
|---|---|---|
| LibriSpeech test-clean | ASR anglais (propre) | 1.07 WER |
| LibriSpeech test-other | ASR anglais (bruit) | 2.17 WER |
| WenetSpeech test-net | ASR chinois (web) | 4.47 WER |
| WenetSpeech test-meeting | ASR réunion chinois | 5.31 WER |
| Fleurs (15 langues) | ASR multilingue | 74.70 |
| MMSU | Compréhension orale | 86.54 |
| WildSpeech | Parole en conditions réelles | 75.81 |
Un WER de 1.07 sur LibriSpeech test-clean se situe au sommet de l'industrie, surpassant les résultats du Whisper large-v3 public. Les scores MMSU et WildSpeech sont également légèrement supérieurs aux données publiques du Gemini 3.1 Pro, ce qui prouve que le modèle atteint un niveau de "compréhension" digne des fleurons du marché, et ne se limite pas à de la simple "dictée".
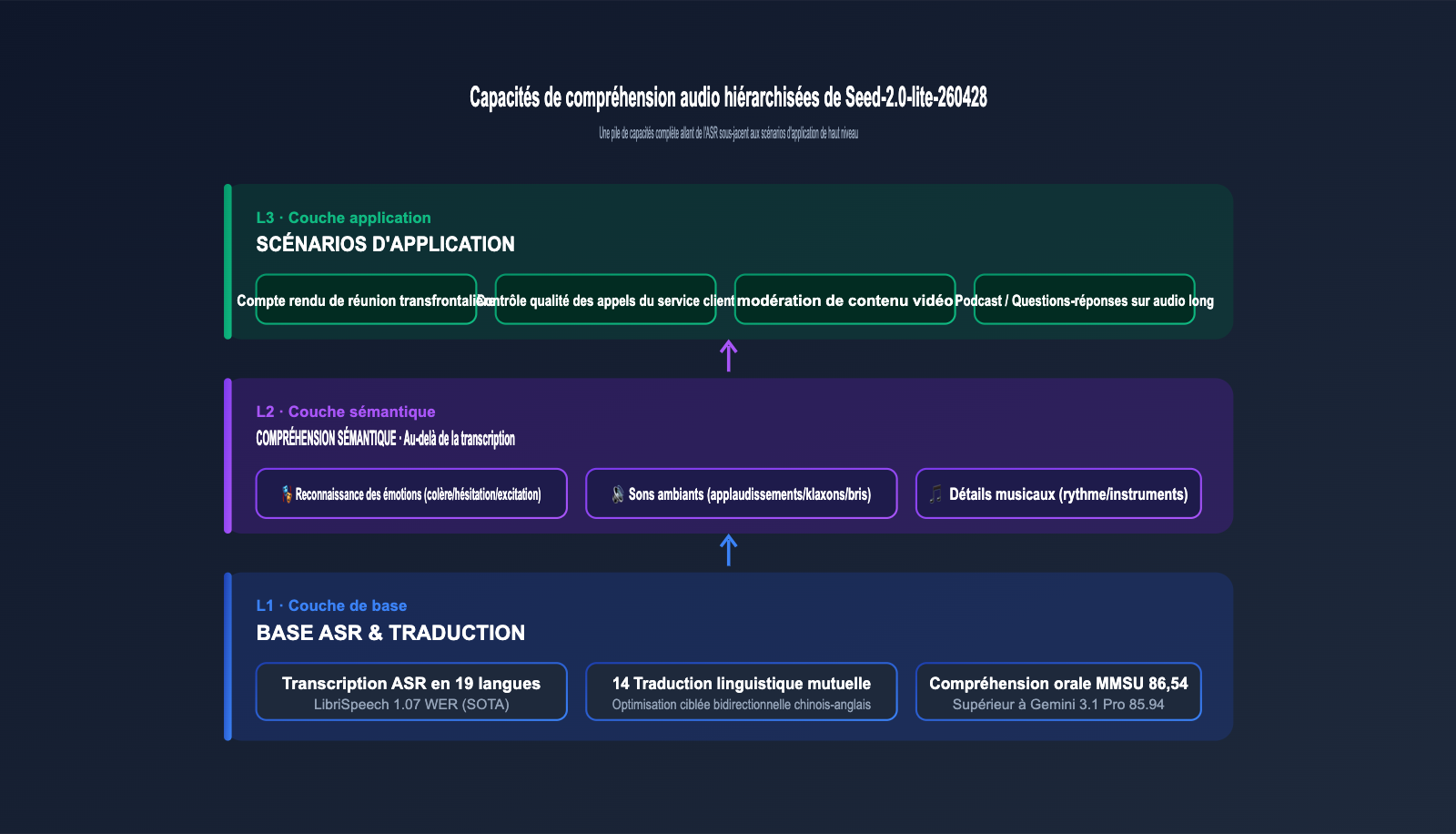
3.2 Transcription en 19 langues et traduction entre 14 langues
La documentation officielle indique que le modèle prend en charge la transcription vocale en 19 langues et la traduction entre 14 langues, la traduction bidirectionnelle chinois-anglais étant un axe d'optimisation prioritaire. Cela signifie que pour un même enregistrement de réunion multilingue, le modèle peut générer des sous-titres et des traductions dans une langue unifiée, ce qui est idéal pour les équipes internationales ou le service client e-commerce transfrontalier.
3.3 Au-delà de la "transcription" : émotions, sons ambiants et détails musicaux
La différence majeure avec les modèles ASR traditionnels est que le Seed-2.0-lite-260428 peut capturer des informations sémantiques au-delà du simple "contenu textuel" : les fluctuations émotionnelles du locuteur (colère, hésitation, excitation), les sons ambiants (verre brisé, applaudissements, klaxons) et les détails musicaux (rythme, instruments, style). Ces dimensions ont une valeur directe pour le contrôle qualité du service client, la modération de contenu ou la recommandation musicale.
🎯 Conseil d'intégration : Pour les scénarios nécessitant une synergie "audio + texte" tels que les comptes-rendus de réunions internationales, le contrôle qualité du service client ou la modération de contenu vidéo, nous vous recommandons d'appeler le Seed-2.0-lite-260428 directement via APIYI apiyi.com. Une seule
base_urlsuffit pour bénéficier à la fois du raisonnement multimodal et d'une fenêtre de contexte de 256K, sans avoir à construire votre propre pipeline audio.
IV. Analyse comparative du modèle Seed-2.0-lite-260428 et des principaux modèles multimodaux
Pour évaluer la position de ce modèle en 2026, la meilleure approche consiste à le comparer aux fleurons multimodaux de la même période, tels que GPT-4o et Gemini 3 Pro.
4.1 Comparaison des capacités des principaux modèles multimodaux
| Dimension | Seed-2.0-lite-260428 | GPT-4o | Gemini 3 Pro |
|---|---|---|---|
| Entrée texte | ✓ | ✓ | ✓ |
| Entrée image | ✓ | ✓ | ✓ |
| Entrée vidéo | ✓ | ✓ | ✓ |
| Entrée audio | ✓ | ✓ | ✓ |
| Fenêtre de contexte | 262K | 128K | 1M |
| Prix d'entrée / M | 0,25 $ | 2,50 $ | 1,25 $ |
| Prix de sortie / M | 2,00 $ | 10,00 $ | 10,00 $ |
| Reconnaissance émotionnelle audio | ✓ | ✓ | ✓ |
| Optimisation audio chinois | Forte (optimisé WenetSpeech) | Moyenne | Moyenne |
Comme on peut le constater, l'avantage principal du Seed-2.0-lite-260428 réside dans sa combinaison « prix + audio chinois + fenêtre de contexte de 256K ». Il offre un rapport coût-efficacité particulièrement remarquable pour le traitement audio et vidéo multilingue ainsi que pour la synthèse de réunions longues. GPT-4o et Gemini 3 Pro conservent toutefois l'avantage en termes de capacités globales en anglais et d'étendue de leur écosystème, ce qui les rend plus adaptés aux scénarios généralistes.

🎯 Conseils de sélection : Si votre activité se concentre principalement sur le traitement audio et vidéo en chinois et que vous êtes sensible aux coûts, le Seed-2.0-lite-260428 est actuellement un choix au rapport qualité-prix extrêmement élevé. Si vous travaillez principalement en anglais ou si vous avez des besoins intensifs en génération créative multilingue, vous pouvez utiliser la passerelle unifiée APIYI apiyi.com pour accéder simultanément à ces trois modèles phares et effectuer un routage selon le scénario.
V. Démarrage rapide avec Seed-2.0-lite-260428 via APIYI
Le modèle est entièrement compatible avec l'interface de style OpenAI, ce qui rend la migration extrêmement simple. Voici un exemple minimal d'invocation pour convertir un segment d'image ou d'audio en une description structurée.
5.1 Exemple minimal pour l'interface compatible OpenAI
from openai import OpenAI
client = OpenAI(
api_key="<APIYI_API_KEY>",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="seed-2-0-lite-260428",
messages=[
{"role": "user", "content": [
{"type": "text", "text": "Veuillez décrire le contenu, l'émotion et les sons d'ambiance de cet audio."},
{"type": "input_audio", "audio": {"data": "<base64-ou-url>", "format": "mp3"}}
]}
]
)
print(response.choices[0].message.content)
En pointant base_url vers le point d'accès unifié d'APIYI (apiyi.com) et en changeant simplement le model, vous pouvez invoquer Seed-2.0-lite-260428 ainsi que d'autres modèles multimodaux au sein du même SDK, sans avoir à réécrire votre code métier.
5.2 Scénarios d'application typiques pour Seed-2.0-lite-260428
Le tableau ci-dessous répertorie plusieurs scénarios types et les bénéfices tirés de la capacité de "raisonnement unifié audio + vidéo + texte" de ce modèle.
| Scénario d'application | Capacités clés | Valeur métier |
|---|---|---|
| Comptes-rendus de réunions internationales | ASR 19 langues + traduction 14 langues + fenêtre de contexte 256K | Comptes-rendus bilingues en un clic |
| Contrôle qualité des appels clients | Reconnaissance des émotions + détection de bruit ambiant + analyse audio longue | Marquage automatique : colère/interruption/dépassement |
| Modération de contenu vidéo | Raisonnement audio-vidéo combiné + suivi temporel long | Identification synchrone d'images dangereuses et sons suspects |
| QA pour podcasts / vidéos longues | Fenêtre de contexte 256K + transcription audio | Questions-réponses directes sur des heures d'audio |
| Automatisation d'agent de bureau | Compréhension de l'interface graphique + invocation d'outils | Exécution de flux de travail complexes entre applications |
VI. FAQ sur Seed-2.0-lite-260428
6.1 Comment remplir le champ "model" lors de l'appel API ?
Indiquez simplement seed-2-0-lite-260428. Notez qu'il s'agit de traits d'union et non de traits de soulignement ; le suffixe 260428 correspond au numéro de version (28 avril 2026) et ne doit pas être omis, sous peine d'être routé vers une ancienne version. La liste des modèles est consultable sur la console APIYI (apiyi.com) pour garantir une correspondance avec les dernières versions publiées.
6.2 Quels formats et durées audio sont pris en charge ?
Le modèle respecte la convention du champ input_audio de style OpenAI ; les formats courants MP3, WAV, M4A et FLAC sont supportés. La durée maximale et le taux d'échantillonnage dépendent de la documentation officielle de ModelArk. Il est recommandé de ne pas dépasser 30 minutes par entrée pour garantir la stabilité de l'inférence. Pour les audios très longs, vous pouvez les segmenter puis fusionner les résultats.
6.3 Quelle est la différence avec la version Seed-2.0-Lite sans le suffixe 260428 ?
La version sans suffixe est le Seed-2.0-Lite original publié le 10 mars, qui ne supporte que le texte, les images et la vidéo. La version 260428, publiée le 28 avril, est une mise à jour multimodale complète ajoutant l'entrée audio et le raisonnement combiné audio-vidéo. Si votre activité nécessite l'utilisation de l'audio, vous devez impérativement utiliser la version avec suffixe.
6.4 La facturation se fait-elle au token ou à la durée audio ?
Le modèle est facturé uniformément au token ; l'audio est encodé en interne sous forme de tokens avant d'être traité. La tarification actuelle est de 0,25 $ par million de tokens en entrée et 2,00 $ par million en sortie. Le nombre de tokens correspondant à un segment audio peut être consulté dans le "Journal de facturation" de la console APIYI, ce qui facilite l'estimation et l'optimisation des coûts.
6.5 Le streaming et l'appel de fonctions (Function Call) sont-ils supportés ?
Tout à fait. Seed-2.0-lite-260428 est compatible avec les champs stream=true et tools du protocole standard OpenAI Chat Completions. Vous pouvez l'intégrer directement dans des frameworks populaires comme LangChain, LangGraph ou le SDK OpenAI Agents sans modification particulière.
VII. Conclusion : Les modèles omnimodaux font entrer les applications multimodales dans l'ère de l'« inférence unifiée »
La valeur de Seed-2.0-lite-260428 ne réside pas seulement dans l'ajout d'une capacité audio, mais dans sa faculté à unifier l'inférence de la vidéo, de l'image, de l'audio et du texte au sein d'un seul et même modèle. Pour les métiers intrinsèquement multimodaux (réunions, service client, modération de contenu, analyse vidéo, automatisation par agents), cette « inférence unifiée » représente une véritable simplification architecturale : il n'est plus nécessaire d'assembler trois modèles distincts pour l'ASR, la vision et le texte, et l'on ne craint plus la perte de contexte entre les différents modèles.
En termes de coûts et d'adaptation au contexte chinois, ce modèle offre un rapport performance-prix très compétitif parmi les fleurons actuels. Son tarif de 0,25 $ / M en entrée rend le traitement audio et vidéo à grande échelle techniquement viable, tandis que sa fenêtre de contexte de 256K est largement suffisante pour couvrir des scénarios impliquant plusieurs heures d'audio ou de vidéo.
Si vous souhaitez invoquer de manière unifiée Seed-2.0-lite-260428 ainsi que les principaux modèles multimodaux du marché sous une même base_url, vous pouvez consulter la documentation officielle d'APIYI sur apiyi.com pour accéder aux exemples d'intégration complets et à la liste des modèles.
Auteur : APIYI Team — Nous fournissons en continu aux développeurs IA du monde entier un service proxy API stable et performant ainsi qu'un routage multi-modèles. Pour plus de détails, visitez apiyi.com