تم إطلاق نموذج Claude Opus 4.7 في 16 أبريل 2026، وأثار إطلاقه جدلاً واسعاً في المجتمع التقني منذ اليوم التالي. في حين تدعي الاختبارات القياسية الرسمية تفوقه على نسخة 4.6 في 12 من أصل 14 اختباراً، اشتكى عدد كبير من المطورين على منصتي GitHub وX من أن أداءه أقل من النسخة السابقة، حتى أن البعض وصفه بأنه "نسخة 4.6 معدلة مسبقاً ومتنكرة في زي إصدار جديد".
يعتمد هذا المقال على البيانات الرسمية من Anthropic، والاختبارات المستقلة، وردود فعل المجتمع المباشرة، لنقدم تقييماً متعمقاً لنموذج Claude Opus 4.7 عبر 8 أبعاد، تشمل القدرة على البرمجة، التعرف البصري، نافذة السياق الطويلة، تغييرات الـ Tokenizer، وميزانيات المهام، لمساعدتك في اتخاذ قرار بشأن ما إذا كنت ستنتقل إليه فوراً.
القيمة الجوهرية: بعد قراءة هذا المقال، ستعرف ما إذا كان Claude Opus 4.7 يمثل ترقية أم تراجعاً لسيناريوهات عملك، وكيفية تجنب مخاطر الترحيل.
خلفية إطلاق Claude Opus 4.7 ومعلوماته الأساسية
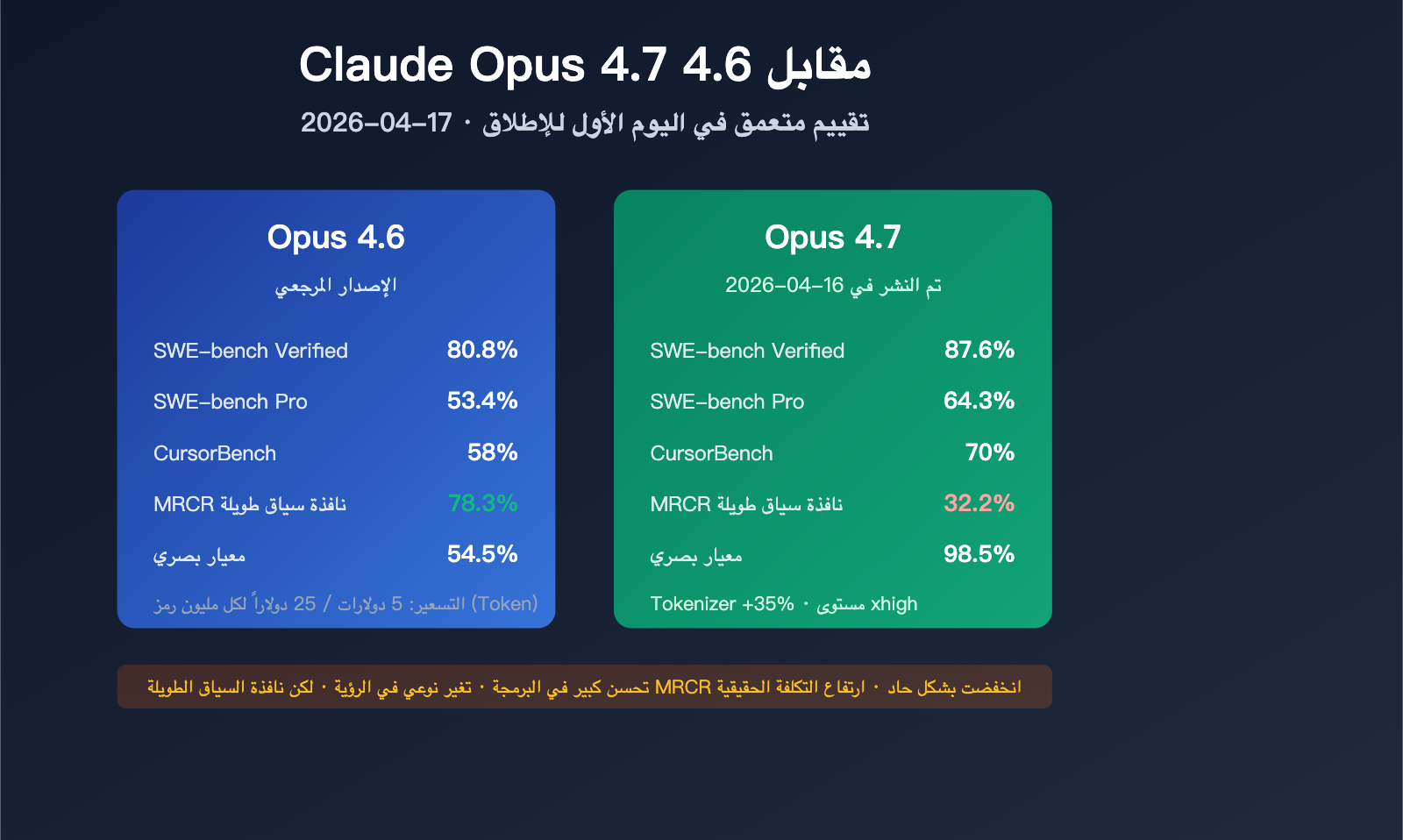
يعتبر Claude Opus 4.7 النموذج الرائد الذي أطلقته شركة Anthropic في 16 أبريل 2026، وقد ورث هيكل تسعير 5 دولارات/25 دولاراً لكل مليون Token من نموذج Opus 4.6، كما سجل أرقاماً قياسية في العديد من الاختبارات المعيارية. ومع ذلك، فقد ترافق إطلاقه مع تغييرات منهجية عديدة، مثل إعادة هيكلة الـ Tokenizer، وانخفاض حاد في أداء معيار سياق MRCR الطويل، وإضافة مستوى استنتاج جديد باسم xhigh، وهي تغييرات أثرت بشكل مباشر على الأداء الفعلي في بيئات العمل.
نظرة سريعة على إطلاق Claude Opus 4.7
| عنصر المعلومات | التفاصيل |
|---|---|
| تاريخ الإصدار | 16 أبريل 2026 |
| الجهة المطلقة | Anthropic |
| سعر الإدخال | 5 دولارات / مليون Token (مساوٍ لـ 4.6) |
| سعر الإخراج | 25 دولاراً / مليون Token (مساوٍ لـ 4.6) |
| نافذة السياق | 1 مليون Token (تسعير قياسي) |
| أقصى دقة للصورة | 2576 بكسل للجانب الطويل / 3.75 مليون بكسل |
| مستويات استنتاج جديدة | xhigh (بين high و max) |
| ميزات تجريبية | ميزانيات المهام (Task Budgets – تجربة عامة) |
| القنوات المتاحة | Claude API, Amazon Bedrock, Google Vertex AI, Microsoft Foundry |
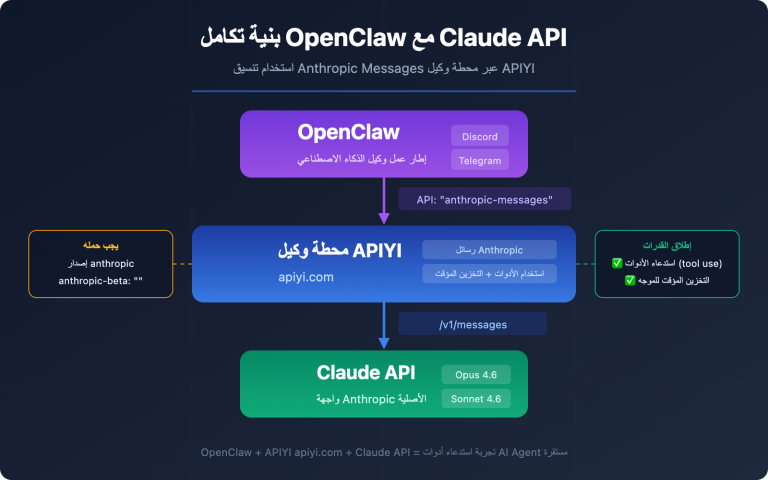
🎯 نصيحة تقنية: قبل الترحيل الرسمي إلى Claude Opus 4.7، ننصح بإجراء اختبارات مقارنة متوازية بين 4.6 و4.7 من خلال منصة APIYI على apiyi.com. توفر هذه المنصة واجهة موحدة، حيث يتطلب تبديل النموذج تعديل المعلمات فقط، مما يساعدك في تحديد اختلافات الأداء بسرعة.
نقاط الترقية الجوهرية في Claude Opus 4.7
تركز التحديثات التي روجت لها Anthropic بشكل رسمي على الاتجاهات الأربعة التالية:
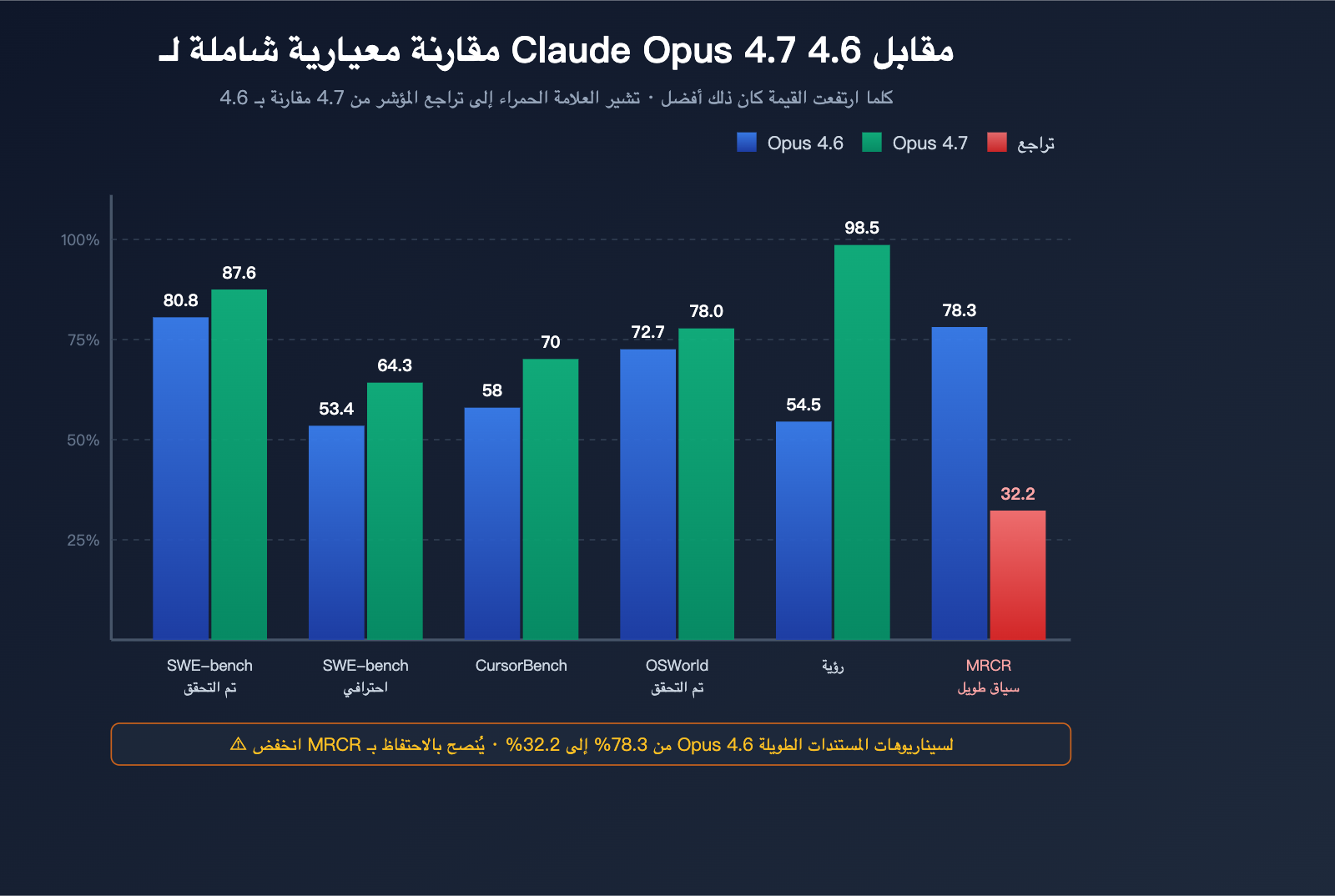
- تعزيز كبير في قدرات هندسة البرمجيات: ارتفعت نتيجة SWE-bench Verified من 80.8% إلى 87.6%، ونتيجة SWE-bench Pro من 53.4% إلى 64.3%.
- قفزة نوعية في قدرات الفهم البصري: دعم دقة عالية تصل إلى 3.75 مليون بكسل، مع ارتفاع المعيار البصري من 54.5% إلى 98.5%.
- تعزيز قدرات استخدام الأدوات (Agentic): حقق معيار MCP-Atlas أكبر تحسن في فئة واحدة، بزيادة قدرها 13 نقطة في حال عدم وجود أدوات.
- دقة أكبر في اتباع التعليمات: تعامل أكثر قوة مع التعليمات الغامضة وتنفيذ أكثر دقة للمهام.
ومع ذلك، تظهر ردود الفعل الواقعية من المجتمع جانباً آخر من القصة.
تفصيل الميزات الأساسية لـ Claude Opus 4.7
لا تقتصر التغييرات الجوهرية في Claude Opus 4.7 على قدرات النموذج فحسب، بل تشمل أيضاً تعديلات مهمة في مستوى التسليم. يعد فهم هذه التغييرات أمراً بالغ الأهمية لتقييم أداء النموذج بشكل صحيح.

أربعة تغييرات نظامية في Claude Opus 4.7
| وحدة الميزة | الأداء في 4.6 | التغيير في 4.7 | التأثير على العمل |
|---|---|---|---|
| المُرمِّز (Tokenizer) | تقسيم الرموز الأصلي | تنتج نفس النصوص 1.0–1.35 ضعف من الرموز | قد ترتفع الفاتورة الفعلية بنسبة 35% |
| مستوى الاستنتاج | low / medium / high / max | إضافة xhigh (الافتراضي في Claude Code) | عمق الاستنتاج وزمن الاستجابة أكثر دقة |
| ميزانيات المهام | لا يوجد | إصدار تجريبي عام، تحكم في ميزانية الرموز العالمية | تكاليف دورة الوكيل (Agent) قابلة للتحكم |
| إدخال الرؤية | حوالي 1.15 مليون بكسل | حوالي 3.75 مليون بكسل (3 أضعاف) | القدرة على معالجة لقطات الشاشة والرسومات عالية الدقة |
| سياق طويل MRCR | 78.3% | 32.2% | انخفاض كبير في استرجاع الوثائق الطويلة |
| SWE-bench Verified | 80.8% | 87.6% | تحسن كبير في مهام البرمجة الواقعية |
التكاليف الضمنية لتغييرات المُرمِّز (Tokenizer)
أهم تغيير في Claude Opus 4.7، والأكثر عرضة للتجاهل، هو إعادة هيكلة المُرمِّز. توضح الوثائق الرسمية أن النص المدخل نفسه يتم تعيينه في 4.7 إلى ما يتراوح بين 1.0 و1.35 ضعف عدد الرموز مقارنة بـ 4.6. هذا يعني:
- طول الموجه (Prompt) الخاص بك لم يتغير، ولكن قد تزيد تكاليف رموز الإدخال بنسبة 35%.
- في مستويات استنتاج xhigh أو max، قد تتضخم رموز الإخراج بشكل ملحوظ أيضاً.
- ستحتاج إلى إعادة اختبار شاملة لحدود
max_tokensالمحددة مسبقاً بناءً على 4.6. - يجب إعادة كتابة منطق تقدير الرموز بناءً على عدد الحروف في جانب العميل.
💰 تحسين التكلفة: بالنسبة لبيئات الإنتاج الحساسة لتكاليف الرموز، نوصي بشدة بإجراء جولة من مقارنة الفواتير لحركة المرور الحقيقية عبر منصة APIYI (apiyi.com) قبل الانتقال إلى Claude Opus 4.7. تدعم المنصة استعلامات الفوترة المرنة والمراقبة اللحظية، مما يسهل قياس زيادة التكلفة الفعلية الناتجة عن الانتقال.
استراتيجية استخدام مستوى الاستنتاج xhigh
يعد xhigh مستوى استنتاج جديد تم تقديمه في Opus 4.7، ويقع بين high و max. توصي Anthropic باستخدام xhigh افتراضياً في مهام البرمجة والمهام المتعلقة بالوكلاء (Agentic tasks)، وهو أيضاً المستوى الافتراضي لجميع باقات Claude Code.
سيناريوهات الاستخدام لمستويات الاستنتاج المختلفة:
| مستوى الاستنتاج | المهام المناسبة | زمن الاستجابة | سيناريو الاستخدام الموصى به |
|---|---|---|---|
low |
أسئلة بسيطة، تحويل التنسيق | أدنى | مهام ذات تزامن عالٍ وتعقيد منخفض |
medium |
توليد كود عادي | منخفض | مساعدة التطوير الروتينية |
high |
كود معقد، تصميم تقني | متوسط | مهام الوكيل (Agentic) المعتادة |
xhigh |
تصحيح الأخطاء الصعب، إعادة هيكلة واسعة | متوسط إلى عالٍ | موصى به: سيناريوهات البرمجة مثل Claude Code |
max |
استنتاج معقد للغاية | عالٍ | المهام البحثية، والمهام غير الحساسة للوقت |
ميزانيات المهام (Task Budgets): القضاء على تكاليف دورة الوكيل
تعد Task Budgets ميزة تجريبية عامة قدمتها Opus 4.7، وهي تعالج نقطة الألم المتمثلة في صعوبة التحكم في إجمالي استهلاك الرموز لدورات الوكيل. آلية العمل:
- يقوم المطور بتعيين ميزانية إجمالية للرموز قبل بدء دورة الوكيل.
- يمكن للنموذج رؤية العد التنازلي للميزانية في كل دورة استجابة.
- يقوم النموذج تلقائياً بتعديل عمق التفكير وعدد استدعاءات الأدوات بناءً على الميزانية المتبقية.
- قبل نفاد الميزانية، يعطي النموذج الأولوية لإكمال المهام الأساسية وينتهي بأناقة.
هذه الميزة، بالتزامن مع واجهة redact-thinking-2026-02-12 الجديدة، تمثل تحسيناً جوهرياً في إدارة تكاليف الوكلاء (Agent).
نظرة شاملة على نتائج اختبارات Claude Opus 4.7
هذا القسم هو جوهر هذا المقال، حيث قمنا بتجميع المعايير الرسمية من Anthropic، والتقييمات المستقلة من جهات خارجية، وبيانات الاختبارات المجتمعية لنعرض لك الفوارق الحقيقية بين Claude Opus 4.7 و 4.6.
معيار القدرة على البرمجة: تفوق شامل لـ 4.7
| معيار البرمجة | Opus 4.6 | Opus 4.7 | نسبة التحسن | ملاحظات |
|---|---|---|---|---|
| SWE-bench Verified | 80.8% | 87.6% | +6.8pt | مهام إصلاح مشكلات GitHub الحقيقية |
| SWE-bench Pro | 53.4% | 64.3% | +10.9pt | نسخة أكثر صعوبة ومتعددة اللغات |
| CursorBench | 58% | 70% | +12pt | مهام برمجة حقيقية داخل بيئة التطوير |
| OSWorld-Verified | 72.7% | 78.0% | +5.3pt | التعامل مع سطح المكتب واستخدام الحاسوب |
| MCP-Atlas (بدون أدوات) | — | +13pt | أكبر تحسن في بند واحد | مهام سلاسل أدوات الوكلاء (Agentic) |
| MCP-Atlas (مع أدوات) | — | +6pt | تحسن ملحوظ | دقة استدعاء الأدوات |
في مجال البرمجة، يُعد Claude Opus 4.7 بالفعل أقوى نموذج متاح للجمهور في الربع الثاني من عام 2026، حيث تعيده نتيجته في SWE-bench Pro البالغة 64.3% إلى صدارة قائمة نماذج البرمجة الوكيلية (Agentic).
🚀 ابدأ بسرعة: إذا كنت ترغب في تجربة قدرات البرمجة في Claude Opus 4.7 فوراً، يمكنك استدعاؤه مباشرة عبر منصة APIYI apiyi.com، التي توفر واجهة متوافقة تماماً مع API الرسمي لـ Claude، وتدعم تنسيق OpenAI SDK الموحد، مما يجعل عملية النقل سهلة للغاية.
معايير الرؤية والسياق الطويل: تباين حاد
| المعيار | Opus 4.6 | Opus 4.7 | التغيير | التقييم |
|---|---|---|---|---|
| التعرف البصري (عام) | 54.5% | 98.5% | +44pt | قفزة نوعية |
| أقصى دقة للصور | ~1.15 ميجابكسل | ~3.75 ميجابكسل | 3 أضعاف | يدعم لقطات شاشة 4K |
| استرجاع السياق الطويل MRCR | 78.3% | 32.2% | -46.1pt | تراجع حاد |
يعد MRCR (استرجاع السياق متعدد الجولات) المعيار القياسي لتقييم القدرة على استرجاع المعلومات من سياق طويل. شهد Opus 4.7 انخفاضاً حاداً في هذا المؤشر من 78.3% إلى 32.2%، وهو ليس مجرد تذبذب عابر، بل تراجع بنيوي.
هذا الرقم يفسر سبب شكوى العديد من المطورين من أنهم "يقدمون للنموذج 800 سطر من وثائق سير العمل، فيؤكد أنه قرأها، لكن المخرجات لا علاقة لها بالوثائق نهائياً".
المعايير مقابل التجربة الفعلية: لماذا تباينت التقييمات؟
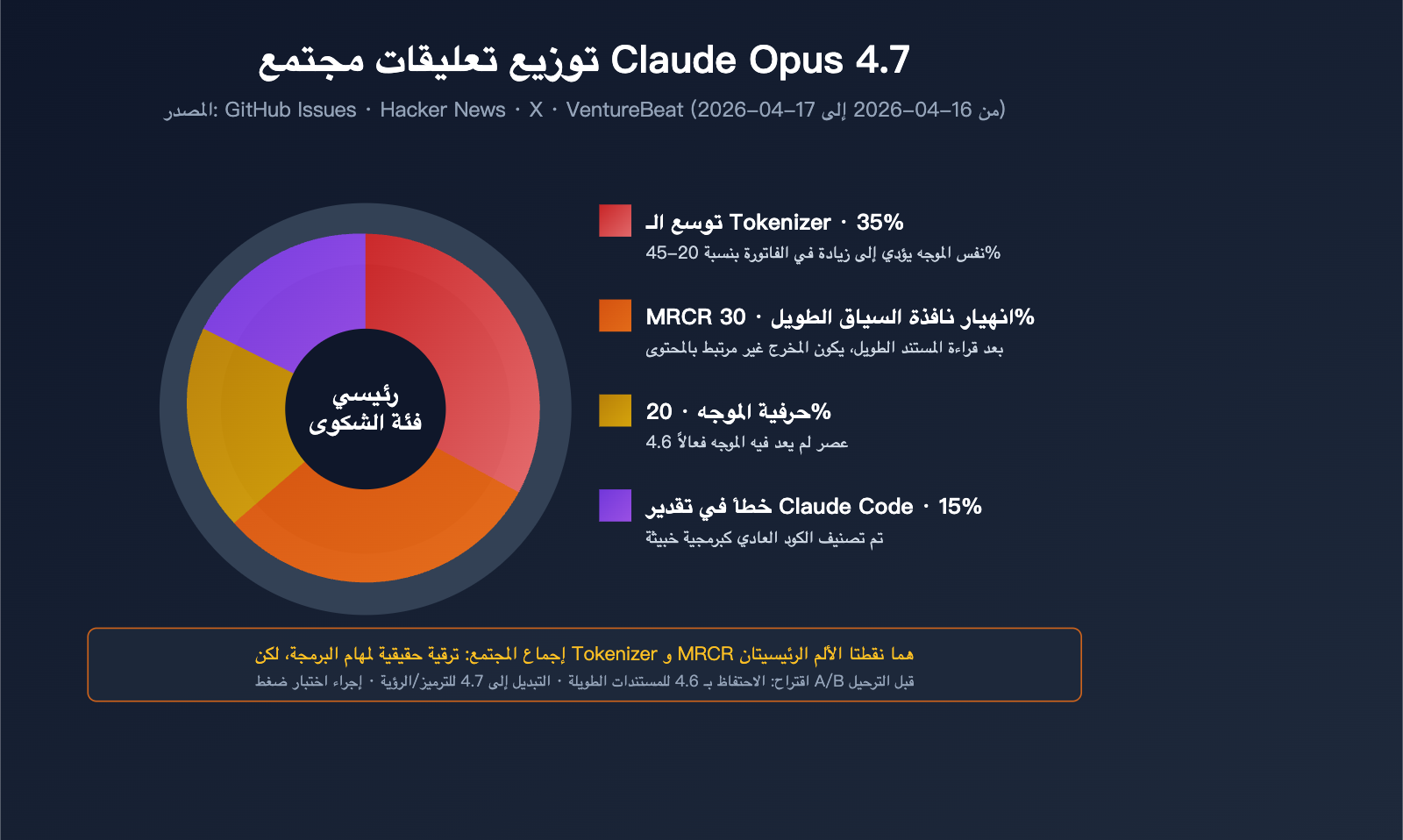
تصدر نتائج الاختبارات لا يعني بالضرورة تفوق الأداء في الأعمال الحقيقية. ظهرت تعليقات سلبية كثيرة حول Opus 4.7 في المجتمع، وذلك للأسباب التالية:
- تضخم الـ Token: استهلاك أعلى للرموز في نفس المهمة، دون أن يقابل ذلك بالضرورة تحسن موازٍ في القيمة مقابل التكلفة.
- الالتزام الحرفي بالموجه (Prompt): كان 4.6 يتمتع بـ "فهم النوايا"، بينما 4.7 ينفذ الموجه حرفياً، مما قد يجعل الموجهات (Prompts) القديمة أقل فعالية.
- انهيار MRCR: تراجع قدرة استرجاع المستندات الطويلة، مما يسبب مشكلات واضحة عند التعامل مع قواعد البيانات الضخمة أو المستندات القانونية.
- الإنذارات الكاذبة في Claude Code: أفاد بعض المطورين بأن 4.7 قد يصنف الأكواد البرمجية العادية كأكواد ضارة ويرفض تعديلها.
💡 نصيحة الاختيار: يعتمد اختيارك بين Claude Opus 4.7 أو الاستمرار في 4.6 بشكل أساسي على طبيعة عملك الأساسية. ننصحك بإجراء اختبارات ضغط متوازية للنسختين عبر منصة APIYI apiyi.com قبل اتخاذ القرار، حيث تدعم المنصة استدعاء واجهات موحدة لنماذج متعددة، مما يسهل عملية المقارنة والتبديل السريع.
تجربة الاستخدام الفعلية لـ Claude Opus 4.7
بعيداً عن بيانات القياس المعيارية، قدمت شركة Anthropic ومجتمع المطورين آراءً متباينة بشكل حاد حول أداء Opus 4.7 في سير العمل الفعلي.
الموقف الرسمي لشركة Anthropic
في إعلان الإصدار، ركزت Anthropic على أربعة تحسينات جوهرية في Opus 4.7 مقارنة بـ 4.6:
- أداء أقوى في خطوط إنتاج البرمجيات: يمكن للمستخدمين الآن الوثوق بـ 4.7 في "المهام الشاقة" التي كانت تتطلب إشرافاً دقيقاً سابقاً.
- قدرة أفضل على التعامل مع المشكلات الغامضة: أداء أكثر استقراراً مع المتطلبات غير محددة المعالم.
- حل جذري للمشكلات: لا يتوقف النموذج عن العمل قبل إتمام المهمة.
- التزام أدق بالموجّهات: اهتمام صارم بالتفاصيل.
وقد صرح بوريس تشيرني، المسؤول عن Claude Code، بعد الإصدار بأن Opus 4.7 "أكثر ذكاءً، وأكثر قدرة على العمل كوكيل (Agentic)، وأكثر دقة" من 4.6، لكنه أقر بأن الأمر يتطلب بضعة أيام من التكيف للاستفادة الكاملة من قدراته الجديدة.
ردود الفعل الفعلية من مجتمع المطورين
على منصات مثل GitHub وHacker News وX، كانت ردود فعل المطورين سلبية بشكل ملحوظ:
الشكوى 1: ارتفاع استهلاك الـ Token بشكل صاروخي
بسبب المرمّز (Tokenizer) الجديد، يتم تقسيم المدخلات نفسها إلى عدد أكبر من الـ Token في Opus 4.7. وإذا أضفنا زيادة الـ Token في المخرجات ضمن فئة xhigh، فقد أبلغ بعض المستخدمين عن زيادة في الفواتير تصل إلى 40%. وقد أُطلق على هذا ساخراً اسم "تضخم انكماش الذكاء الاصطناعي" (AI Shrinkflation).
الشكوى 2: كارثة معالجة المستندات الطويلة
أفاد العديد من المطورين أنهم عند إدخال مستندات طويلة إلى Opus 4.7، يدعي النموذج أنه قرأها، لكن المحتوى الذي يولده لا علاقة له بجوهر المستند. وهذا يتوافق تماماً مع انخفاض معدل MRCR من 78.3% إلى 32.2%.
الشكوى 3: Claude Code يصنف الكود البرمجي خطأً على أنه ضار
في الإصدار رقم #47483، أفاد العديد من المهندسين أن Claude Opus 4.7 يضع علامة "برمجيات خبيثة" (malware) على كود برمجي عادي لقراءة وكتابة الملفات، ويرفض إكمال طلبات التعديل الأساسية.
الشكوى 4: انخفاض توافقية الموجّهات (Prompt)
الموجّهات التي كانت تعمل بشكل جيد على 4.6، انخفضت جودة مخرجاتها عند نقلها إلى 4.7. والسبب هو أن 4.7 ينفذ التعليمات حرفياً وبصرامة، بينما كان 4.6 يمتلك قدرة تلقائية على "فهم ما بين السطور".
تقييم Claude Opus 4.7 حسب سيناريوهات الاستخدام
بناءً على بيانات الاختبار الفعلية وآراء المجتمع، إليك تقييم أداء Opus 4.7 في سيناريوهات مختلفة:
| سيناريو الاستخدام | تقييم Opus 4.6 | تقييم Opus 4.7 | التغير | التوصية |
|---|---|---|---|---|
| إعادة هيكلة الكود للملفات القصيرة والمتوسطة | 8/10 | 9/10 | ↑ | الانتقال فوراً |
| سير عمل الوكيل (Agentic) المعقد | 7.5/10 | 9/10 | ↑ | الانتقال فوراً |
| مراجعة الكود للمستودعات الضخمة | 8/10 | 6.5/10 | ↓ | استمر في استخدام 4.6 |
| تلخيص المستندات الطويلة والأسئلة والأجوبة | 8.5/10 | 5/10 | ↓↓ | استمر في استخدام 4.6 |
| فهم الصور عالية الدقة | 6.5/10 | 9.5/10 | ↑↑ | الانتقال فوراً |
| المحادثات والكتابة العامة | 9/10 | 9/10 | → | أي منهما مناسب |
| الإنتاج الحساس للتكلفة | 9/10 | 7/10 | ↓ | استمر في استخدام 4.6 |
| تطوير النماذج الأولية والتجارب | 8/10 | 8.5/10 | ↑ | الانتقال |
تحليل معمق لمميزات وعيوب Claude Opus 4.7
بعد الانتهاء من مقارنة البيانات والتجربة، يمكننا تقديم ملخص أوضح للمميزات والعيوب.
المزايا الأربع الجوهرية لنموذج Claude Opus 4.7
الميزة 1: تحسن ملحوظ في قدرات البرمجة الفعلية
نتائج 87.6% في SWE-bench Verified و64.3% في SWE-bench Pro ليست مجرد أرقام، بل هي مهام حقيقية لإصلاح مشكلات GitHub. وهذا يعني أن Opus 4.7 قادر بالفعل على استبدال المزيد من الجهد البشري عند التعامل مع مهام البرمجة الصغيرة والمتوسطة.
الميزة 2: طفرة نوعية في الفهم البصري
بفضل مدخلات الصور عالية الدقة (3.75 ميجابكسل)، أصبح Opus 4.7 قادراً على معالجة لقطات الشاشة بدقة 4K، ومخططات التصميم، ومستندات PDF الممسوحة ضوئياً وغيرها من المحتويات البصرية عالية الكثافة. هذه قفزة كبيرة لسلسلة Claude.
الميزة 3: ميزانية المهام (Task Budgets) لحوكمة تكاليف الوكلاء (Agents)
لطالما كان استهلاك الرموز (Tokens) غير المنضبط في حلقات عمل الوكلاء عائقاً رئيسياً أمام التبني المؤسسي. تمنح ميزانية المهام للمطورين لأول مرة قدرة دقيقة على التحكم في الميزانية العالمية.
الميزة 4: مستوى xhigh يوفر توازناً أدق بين الاستنتاج وزمن الاستجابة
إضافة خيار جديد بين مستويي high و max يعني أن المطورين يمكنهم تعديل الأداء بمرونة بناءً على متطلبات اتفاقية مستوى الخدمة (SLA) في نفس السيناريو.
القيود الأربع الرئيسية لنموذج Claude Opus 4.7
القيد 1: تضخم الرموز (Tokenizer) يؤدي إلى ارتفاع التكلفة الفعلية
حتى مع ثبات سعر الوحدة، فإن تضخم الرموز بنسبة 35% بالإضافة إلى توسع المخرجات في مستوى xhigh قد يجعل الفاتورة الفعلية أعلى بنسبة 20–45% مقارنة بـ 4.6.
الحل: أعد اختبار جميع مسارات الكود باستخدام واجهة عد الرموز قبل الترحيل.
القيد 2: انهيار قدرة استرجاع السياق الطويل (MRCR)
هذه هي المشكلة الأكثر خطورة. عند معالجة المستندات الطويلة، أو قواعد الأكواد الضخمة، أو المحادثات الطويلة، تنخفض دقة الاسترجاع في Opus 4.7 بشكل حاد.
الحل: استمر في استخدام Opus 4.6 لسيناريوهات المستندات الطويلة، أو استخدم استراتيجية RAG + التجزئة.
القيد 3: الالتزام الحرفي المفرط بالتعليمات
قد تؤدي الموجهات (Prompts) القديمة إلى مخرجات غير متوقعة.
الحل: أعد كتابة الموجهات بشكل منهجي، وتخلص من النوايا الضمنية، واستخدم قيوداً صريحة.
القيد 4: زيادة في الأحكام الخاطئة والهلوسة في بعض السيناريوهات
أبلغ المجتمع عن مشكلات واسعة النطاق تتعلق بأخطاء Claude Code في فهم الأكواد وهلوسة المستندات الطويلة.
الحل: اعتمد على المراجعة البشرية للمهام الجوهرية، واستخدم التحقق المتقاطع بين عدة نماذج للمنطق الحساس.
🎯 نصيحة الترحيل: إذا كان عملك يتضمن كلاً من مهام البرمجة القصيرة ومعالجة المستندات الطويلة، نوصي باستخدام منصة APIYI (apiyi.com) لتوجيه الطلبات إلى إصدارات Claude المختلفة حسب السيناريو. تدعم المنصة استدعاء نماذج متعددة بشكل موحد، مما يسمح لك بالجمع بمرونة بين Opus 4.6 (للسياق الطويل) و4.7 (للبرمجة/الرؤية) في نفس المشروع، وتجنب تراجع الأداء الناتج عن الترحيل الشامل.
تجربة استدعاء API لنموذج Claude Opus 4.7
بعيداً عن التحليل النظري، نقدم لك نموذج كود عملي لمساعدتك على البدء بسرعة مع Claude Opus 4.7.
مثال مبسط (متوافق مع OpenAI SDK)
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=[
{"role": "user", "content": "يرجى كتابة مثال لبرنامج زاحف (Crawler) متزامن باستخدام Python"}
],
temperature=0.7,
max_tokens=4096
)
print(response.choices[0].message.content)
عرض الكود الكامل (يتضمن مستوى الاستنتاج xhigh، وميزانية المهام، ومعالجة الأخطاء)
import openai
import time
from typing import Optional
class ClaudeOpusClient:
"""تغليف كامل لاستدعاء Claude Opus 4.7"""
def __init__(self, api_key: str, base_url: str = "https://api.apiyi.com/v1"):
self.client = openai.OpenAI(
api_key=api_key,
base_url=base_url
)
def generate(
self,
prompt: str,
model: str = "claude-opus-4-7",
effort: str = "xhigh",
task_budget: Optional[int] = None,
max_retries: int = 3
) -> str:
"""استدعاء Claude Opus 4.7 مع دعم الميزات الجديدة"""
extra_headers = {}
if task_budget:
extra_headers["task-budget-tokens"] = str(task_budget)
if effort:
extra_headers["reasoning-effort"] = effort
for attempt in range(max_retries):
try:
response = self.client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
max_tokens=8192,
extra_headers=extra_headers,
timeout=120
)
return response.choices[0].message.content
except openai.RateLimitError:
wait = 2 ** attempt
print(f"تم تجاوز حد السرعة، الانتظار لـ {wait} ثانية...")
time.sleep(wait)
except openai.APIError as e:
print(f"خطأ في API: {e}")
if attempt == max_retries - 1:
raise
time.sleep(1)
raise RuntimeError("تم تجاوز الحد الأقصى للمحاولات")
def compare_versions(self, prompt: str) -> dict:
"""استدعاء 4.6 و 4.7 للمقارنة"""
results = {}
for model in ["claude-opus-4-6", "claude-opus-4-7"]:
start = time.time()
results[model] = {
"output": self.generate(prompt, model=model),
"latency": time.time() - start
}
return results
if __name__ == "__main__":
client = ClaudeOpusClient(api_key="YOUR_API_KEY")
result = client.generate(
prompt="أعد هيكلة كود Python هذا ليدعم التزامن غير المتزامن (Async)",
effort="xhigh",
task_budget=50000
)
print(result)
🚀 ابدأ بسرعة: يشير
base_urlفي الكود أعلاه إلى منصة APIYI (apiyi.com). توفر المنصة تنسيق واجهة متوافق تماماً مع Claude الرسمي، وتدعم الاستدعاء المتوازي لـ Claude Opus 4.7 و4.6، مما يسهل إجراء اختبارات A/B أثناء فترة الترحيل.
قائمة التحقق الأساسية للترحيل
الخطوات الضرورية عند الترحيل من Opus 4.6 إلى 4.7:
# 1. إعادة اختبار الحد الأقصى لـ max_tokens (بسبب تغير الـ Tokenizer)
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
# استدعاء الموجه الأساسي بالنموذجين وتسجيل استهلاك الرموز الفعلي
for model in ["claude-opus-4-6", "claude-opus-4-7"]:
resp = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": YOUR_PROMPT}],
max_tokens=4096
)
print(f"{model}: input={resp.usage.prompt_tokens}, output={resp.usage.completion_tokens}")
# 2. إعادة اختبار سيناريوهات المستندات الطويلة (بسبب انهيار MRCR)
# نوصي بالاحتفاظ بمهام المستندات الطويلة على 4.6، أو استخدام التجزئة عبر RAG
# 3. تدقيق النوايا الضمنية في الموجهات
# 4.7 ينفذ التعليمات حرفياً، لذا يجب تحويل "فهم النية" إلى قيود صريحة
الأسئلة الشائعة حول Claude Opus 4.7
س1: هل Claude Opus 4.7 أفضل حقاً من 4.6؟
يعتمد الأمر على طبيعة المهام:
- مهام البرمجة المتوسطة والقصيرة: 4.7 أفضل بشكل ملحوظ (تحسن بمقدار +6.8 نقطة في SWE-bench Verified، و+12 نقطة في CursorBench).
- مهام الرؤية الحاسوبية عالية الدقة: 4.7 يتفوق بمراحل على 4.6 (قفزت دقة المعايير البصرية من 54.5% إلى 98.5%).
- سلاسل أدوات الوكلاء (Agentic): 4.7 أقوى (تحسن بمقدار 13 نقطة في MCP-Atlas).
- استرجاع السياق الطويل: 4.6 أفضل بشكل واضح (78.3% مقابل 32.2% في اختبار MRCR).
- حساسية التكلفة: 4.6 أكثر كفاءة (استهلاك الرموز في 4.7 قد يرتفع بنسبة تصل إلى 35%).
إذا كنت بحاجة إلى استدعاء كلا الإصدارين بالتوازي حسب طبيعة العمل، نوصي باستخدام منصة APIYI (apiyi.com) التي تتيح توجيه الطلبات للنموذج المناسب، وتدعم استخدام مفتاح API واحد للوصول إلى كافة نماذج سلسلة Claude.
س2: لماذا يقول البعض إن Claude Opus 4.7 أقل كفاءة من 4.6؟
هناك أربعة أسباب رئيسية:
- إعادة هيكلة الـ Tokenizer: استهلاك الرموز لنفس المهمة قد يرتفع بنسبة تصل إلى 35%، لكن التحسن في القدرات قد لا يبرر هذه التكلفة دائماً.
- تراجع في السياق الطويل (MRCR): انخفضت النسبة من 78.3% إلى 32.2%، مما يعني تراجعاً كبيراً في معالجة المستندات الطويلة.
- الالتزام الحرفي بالتعليمات: الموجهات (Prompts) التي كانت تعتمد على "فهم النوايا" في 4.6 قد لا تعمل بنفس الكفاءة في 4.7.
- أخطاء عرضية في Claude Code: أفاد بعض المطورين بأنه يتم تصنيف الأكواد البرمجية السليمة كأكواد ضارة أحياناً.
هذه ليست مجرد انطباعات، بل هي فروقات حقيقية في التجربة ناتجة عن تغييرات هيكلية.
س3: كيف يمكن الانتقال بأمان من Opus 4.6 إلى 4.7؟
اتبع استراتيجية الانتقال من ثلاث خطوات:
- اختبار الضغط المتوازي: قم باستدعاء 4.6 و4.7 في 5–10% من حركة المرور الإنتاجية، وقارن بين جودة المخرجات، وزمن الاستجابة، والتكلفة.
- التوجيه حسب السيناريو: استمر في استخدام 4.6 للمستندات الطويلة والمستودعات البرمجية الضخمة، وانتقل إلى 4.7 لمهام البرمجة المتوسطة والمهام البصرية.
- زيادة النسبة تدريجياً: ابدأ بـ 10% ← 30% ← 50% ← 100%، مع مراقبة النتائج لمدة 3–7 أيام في كل مرحلة.
نوصي باستخدام منصة APIYI (apiyi.com) لإجراء اختبارات الانتقال هذه، حيث توفر المنصة مرونة عالية في توجيه النماذج وتوزيع حركة المرور.
س4: متى يجب استخدام مستوى xhigh في Claude Opus 4.7؟
توصي Anthropic باستخدام xhigh افتراضياً في مهام البرمجة والمهام التي تعتمد على الوكلاء (Agentic). حالات الاستخدام المناسبة:
- إعادة هيكلة الأكواد المعقدة.
- تصحيح الأخطاء في ملفات متعددة.
- توليد اختبارات الوحدات (Unit Tests) واسعة النطاق.
- مهام سلاسل الأدوات المتعددة للوكلاء.
حالات غير مناسبة:
- الأسئلة والأجوبة البسيطة (يكفي استخدام medium).
- الطلبات ذات التزامن العالي (زمن استجابة xhigh مرتفع).
- المهام الحساسة للتكلفة (يزداد استهلاك الرموز بشكل ملحوظ في xhigh).
س5: كيف يمكن استخدام ميزانيات المهام (Task Budgets)؟ وما هي حالات استخدامها؟
ميزانيات المهام هي ميزة تجريبية يتم تمريرها عبر ترويسة HTTP:
task-budget-tokens: 50000
حالات الاستخدام المناسبة:
- دورات الوكلاء طويلة الأمد (للتحكم في التكلفة الإجمالية).
- تطبيقات SaaS متعددة المستأجرين (لفرض قيود على ميزانية كل مستخدم).
- مهام أتمتة CI/CD (تحديد سقف للرموز لكل وظيفة).
يقوم النموذج تلقائياً بتعديل عمق التفكير بناءً على الميزانية المتبقية، وينهي المهمة بشكل أنيق قبل نفاد الميزانية، مما يمنع الفشل المفاجئ.
س6: هل قدرات الرؤية في Claude Opus 4.7 قوية حقاً؟
نعم، وهي واحدة من أبرز ترقيات 4.7:
- أقصى دقة: ارتفعت من 1.15 ميجابكسل إلى 3.75 ميجابكسل (3 أضعاف).
- المعايير البصرية: قفزت من 54.5% إلى 98.5%.
- القدرات العملية: يمكن للنموذج قراءة لقطات الشاشة بدقة 4K، والمخططات المعمارية، وتصاميم واجهات المستخدم، وملفات PDF الممسوحة ضوئياً.
بالنسبة لفرق تطوير الواجهات الأمامية، وتصميم المنتجات، ورقمنة المستندات، تعد هذه الترقية نقلة نوعية في سير العمل.
لمن يصلح Claude Opus 4.7؟ نصائح لاتخاذ القرار
بناءً على التحليل الشامل، نقدم التوصيات التالية:
حالات الانتقال الفوري إلى Claude Opus 4.7
- ✅ برمجة وإعادة هيكلة الملفات المتوسطة والقصيرة: بيانات SWE-bench وCursorBench تؤكد تفوقه.
- ✅ سير عمل الوكلاء المعقد: بفضل دعم MCP-Atlas وميزانيات المهام.
- ✅ معالجة الصور عالية الدقة: قدرات الرؤية بدقة 3.75 ميجابكسل تمثل تغييراً جذرياً.
- ✅ التطوير السريع للنماذج الأولية: مستوى xhigh يقدم أداءً ممتازاً للمهام متوسطة التعقيد.
حالات الاستمرار في استخدام Claude Opus 4.6
- 🔒 تلخيص المستندات الطويلة والأسئلة والأجوبة: بسبب التراجع في أداء MRCR.
- 🔒 مراجعة الأكواد البرمجية للمستودعات الضخمة: قدرة استرجاع السياق الطويل أكثر استقراراً.
- 🔒 الحساسية الشديدة لتكلفة الرموز: الـ Tokenizer في 4.6 أكثر اقتصادية.
- 🔒 الأنظمة الإنتاجية المستقرة: لا ننصح بالمخاطرة بالتغيير لمجرد تجربة الجديد.
استراتيجية الاستخدام المختلط
بالنسبة لمعظم الفرق، فإن التوجيه حسب السيناريو أكثر عملية من "الانتقال الكلي":
- المستندات الطويلة → Opus 4.6
- البرمجة/الرؤية/الوكلاء → Opus 4.7
- استخدم بوابة موحدة لإدارة كلا الإصدارين لتقليل مخاطر الانتقال.
💡 نصيحة أخيرة: يعتمد اختيارك بين Claude Opus 4.7 و4.6 بشكل أساسي على سيناريو تطبيقك الخاص. نوصي بإجراء اختبارات مقارنة فعلية عبر منصة APIYI (apiyi.com)، حيث تدعم المنصة واجهة موحدة لاستدعاء النماذج الرئيسية، مما يسهل عليك المقارنة والتبديل السريع لضمان مرونة أعمالك.
الخلاصة
يُعد نموذج Claude Opus 4.7 "ترقية قائمة على المقايضات" بامتياز: فقد حقق قفزة نوعية في البرمجة، والقدرات البصرية، وقدرات الوكيل (Agentic)، لكنه دفع ثمن ذلك في جوانب استرجاع السياق الطويل، وكفاءة الرموز (Tokens)، والتوافق مع الموجهات (Prompts).
لم تكن النقاشات المجتمعية في اليوم الأول من إطلاقه بلا أساس؛ فنموذج Opus 4.7 هو نموذج قوي وجديد، ولكنه يمثل في الوقت ذاته تعديلاً معمارياً له تكلفته. بالنسبة للمطورين، السؤال الجوهري ليس "هل يجب الانتقال إليه؟"، بل "في أي سيناريوهات يجب الانتقال إليه؟".
- إذا كنت تعمل على مهام برمجية معقدة أو تحليل بصري عالي الدقة، فإن 4.7 هو الخيار الأفضل للربع الثاني من عام 2026.
- إذا كانت أعمالك الأساسية تعتمد على معالجة المستندات الطويلة أو الاستنتاج الحساس للتكلفة، فمن الأفضل الاحتفاظ بـ 4.6 مؤقتاً.
- أثناء عملية الانتقال، نوصي بشدة بإجراء اختبارات ضغط متوازية لتجنب التراجعات الضمنية الناتجة عن التغيير الشامل والمفاجئ.
ننصحكم باستخدام منصة APIYI (apiyi.com) لتجربة Claude Opus 4.7 و4.6 بسرعة، حيث توفر المنصة واجهة موحدة، ومراقبة فورية للفواتير، وقدرات توجيه بين نماذج متعددة، مما يجعلها الخيار الأمثل لاختبارات الانتقال والتشغيل الفعلي.
المراجع
-
إعلان Anthropic الرسمي: مقدمة حول Claude Opus 4.7
- الرابط:
anthropic.com/news/claude-opus-4-7 - الوصف: القدرات الأساسية للنموذج ومعلومات التسعير الرسمية.
- الرابط:
-
وثائق Claude API الرسمية: دليل الانتقال إلى Claude Opus 4.7
- الرابط:
platform.claude.com/docs/en/about-claude/models/migration-guide - الوصف: توصيات الانتقال الرسمية وشرح التغييرات في المُرمّز (Tokenizer).
- الرابط:
-
مدونة AWS Bedrock: إطلاق Claude Opus 4.7 على Amazon Bedrock
- الرابط:
aws.amazon.com/blogs/aws/introducing-anthropics-claude-opus-4-7-model-in-amazon-bedrock - الوصف: تعليمات النشر على المنصات السحابية الخارجية.
- الرابط:
-
تحليل المرجعية من Vellum AI: تفسير معمق لمعايير أداء Claude Opus 4.7
- الرابط:
vellum.ai/blog/claude-opus-4-7-benchmarks-explained - الوصف: تقييم مرجعي مستقل من طرف ثالث.
- الرابط:
-
GitHub Issue #47483: تعليقات المجتمع حول Claude Opus
- الرابط:
github.com/anthropics/claude-code/issues/47483 - الوصف: آراء وتجارب المطورين المباشرة.
- الرابط:
الكاتب: فريق APIYI التقني
تاريخ النشر: 2026-04-17
النماذج المشمولة: Claude Opus 4.7 / Claude Opus 4.6
للتواصل التقني: نرحب بكم في منصة APIYI (apiyi.com) للحصول على حصص اختبارية ومقارنة الفروقات بين إصدارات Claude بأنفسكم.