ملاحظة من الكاتب: سنقوم هنا بتحليل رسالة الخطأ IMAGE_SAFETY التي يعيدها Nano Banana Pro API، مع استعراض آلية التصفية الأمنية المزدوجة، ومنطق احتساب الرموز (Token)، و8 استراتيجيات عملية لرفع معدل نجاح توليد الصور.
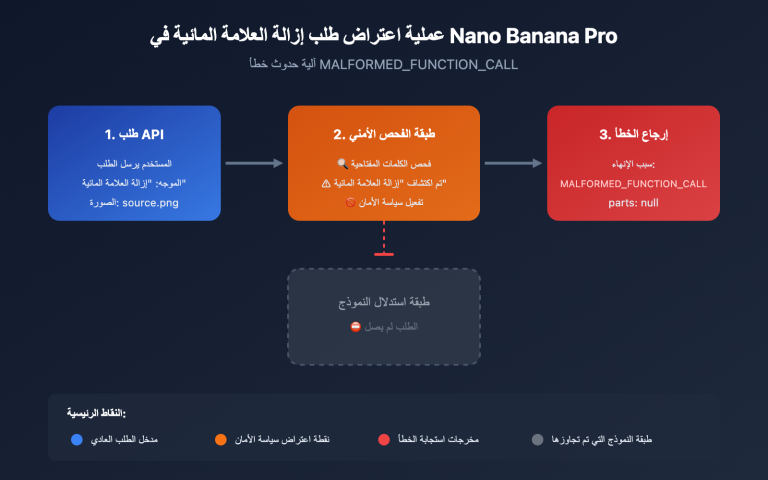
عند استخدام Nano Banana Pro API لتوليد الصور، قد تصادف هذا الرد المحير: رغم خلو الموجه (Prompt) من أي محتوى حساس، إلا أنك تتلقى finishReason: IMAGE_SAFETY، مما يعني أن مرشح الأمان قد قام بحظر الصورة. والأكثر غرابة هو أن الرد يتضمن thoughtsTokenCount: 173، مما يشير إلى أن النموذج قد أتم عملية التفكير، ولكن تم "إعدام" الصورة في اللحظة الأخيرة. سنقوم في هذا المقال بتفكيك حقول هذا الخطأ، وتوضيح آلية عمل مرشحات الأمان المزدوجة لدى Google، وكيفية احتساب التكلفة عند حدوث الحظر، وكيفية تحسين الموجه لزيادة نسبة النجاح.
القيمة الجوهرية: بعد قراءة هذا المقال، ستفهم دلالة كل حقل في خطأ IMAGE_SAFETY، وستعرف ما إذا كنت ستتحمل تكلفة عند حدوث الحظر، وكيفية رفع معدل النجاح إلى 70-80% عبر تحسين الموجه.

تحليل خطأ IMAGE_SAFETY: شرح تفصيلي لكل حقل
لنبدأ بتوضيح معنى كل حقل في هذا الرد:
| الحقل | القيمة | المعنى |
|---|---|---|
content.parts |
null |
لم يتم إرجاع أي محتوى (تم حظر الصورة) |
finishReason |
IMAGE_SAFETY |
تم تفعيل مرشح أمان المخرجات من المستوى الثاني |
finishMessage |
"Unable to show…" | رسالة Google الرسمية: انتهاك سياسة استخدام الذكاء الاصطناعي التوليدي |
promptTokenCount |
276 | استهلك الإدخال 276 رمزاً (Token) |
candidatesTokenCount |
0 | عدد رموز المخرجات هو 0 (تم حظر الصورة، لم يتم توليد أي مخرجات) |
totalTokenCount |
449 | إجمالي 449 رمزاً (276 إدخال + 173 تفكير) |
thoughtsTokenCount |
173 | استهلكت عملية تفكير النموذج 173 رمزاً |
promptTokensDetails |
TEXT:18, IMAGE:258 | 18 رمزاً نصياً + 258 رمزاً للصورة (الصورة المرجعية) |
modelVersion |
gemini-3-pro-image-preview | نموذج Nano Banana Pro |
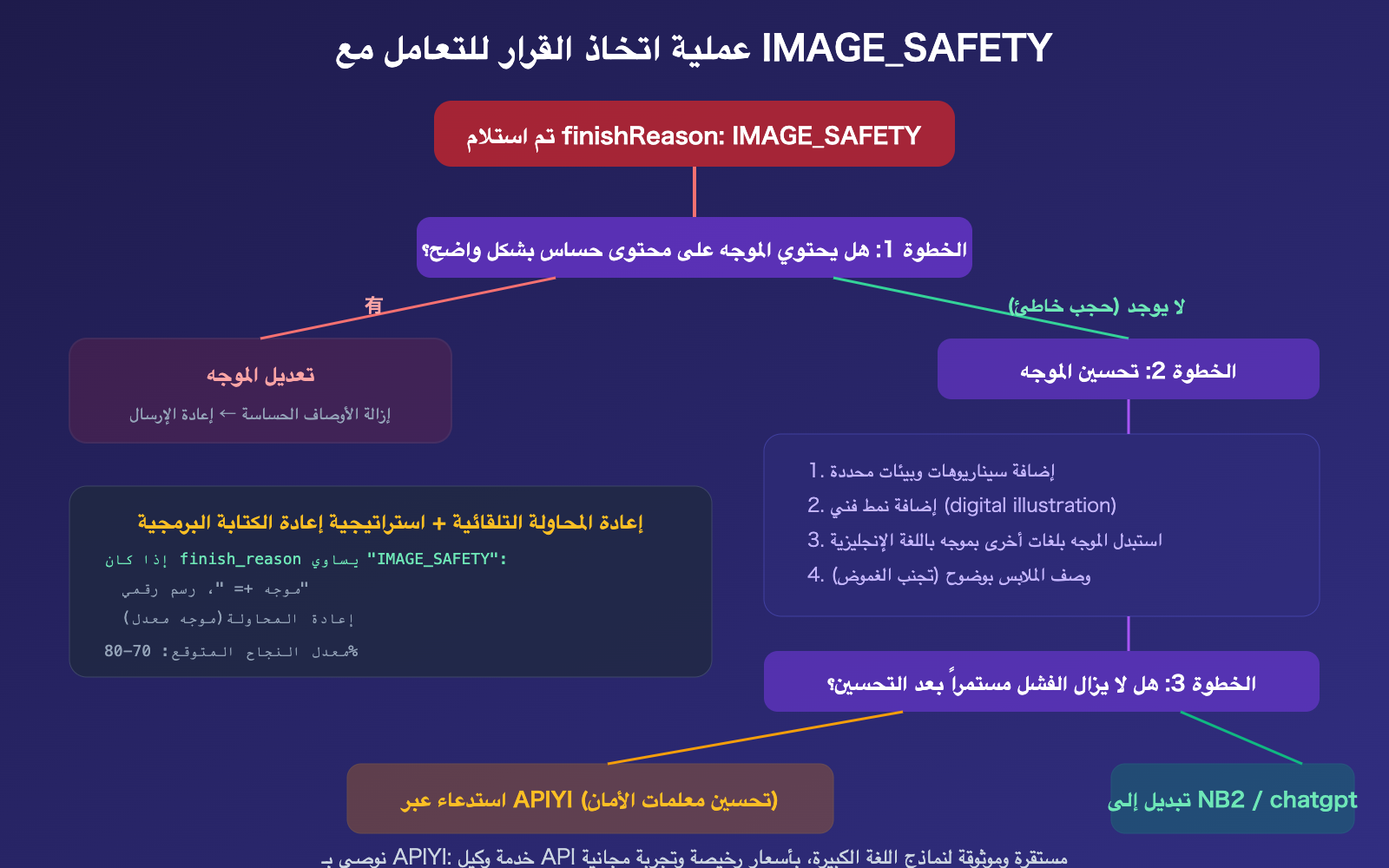
أهم 3 إشارات في خطأ IMAGE_SAFETY
الإشارة الأولى: thoughtsTokenCount: 173 — النموذج فكّر بالفعل
هذا يعني أن الموجه (Prompt) الخاص بك قد اجتاز فحص الأمان الأول (عند الإدخال)، وبدأ النموذج عملية الاستنتاج (التفكير)، بل وبدأ في توليد الصورة، ولكن تم حظرها بواسطة مرشح الأمان الثاني عند المخرجات النهائية. المشكلة ليست في الموجه، بل في المحتوى الذي "حاول النموذج رسمه".
الإشارة الثانية: candidatesTokenCount: 0 — المخرجات صفر
بعد حظر الصورة، يتم احتساب رموز المخرجات كـ 0. وفقاً لـ Google، "لن يتم محاسبتك على الصور المحظورة". لكن انتبه: ما إذا كانت رموز الإدخال (276) ورموز التفكير (173) سيتم محاسبتك عليها أم لا، يعتمد على منطق الفوترة الخاص بهم.
الإشارة الثالثة: IMAGE: 258 — لقد أدخلت صورة مرجعية
يحتوي طلبك على صورة مرجعية (استهلكت 258 رمزاً للصورة). هذا يعني أنك ربما تقوم بعملية تحويل صورة إلى صورة (image-to-image)، وليس مجرد توليد صورة من نص. عادةً ما تكون مرشحات الأمان في سيناريوهات تحرير الصور أكثر صرامة من النص البحت، لأن الصورة المرجعية نفسها تخضع لفحص الأمان.
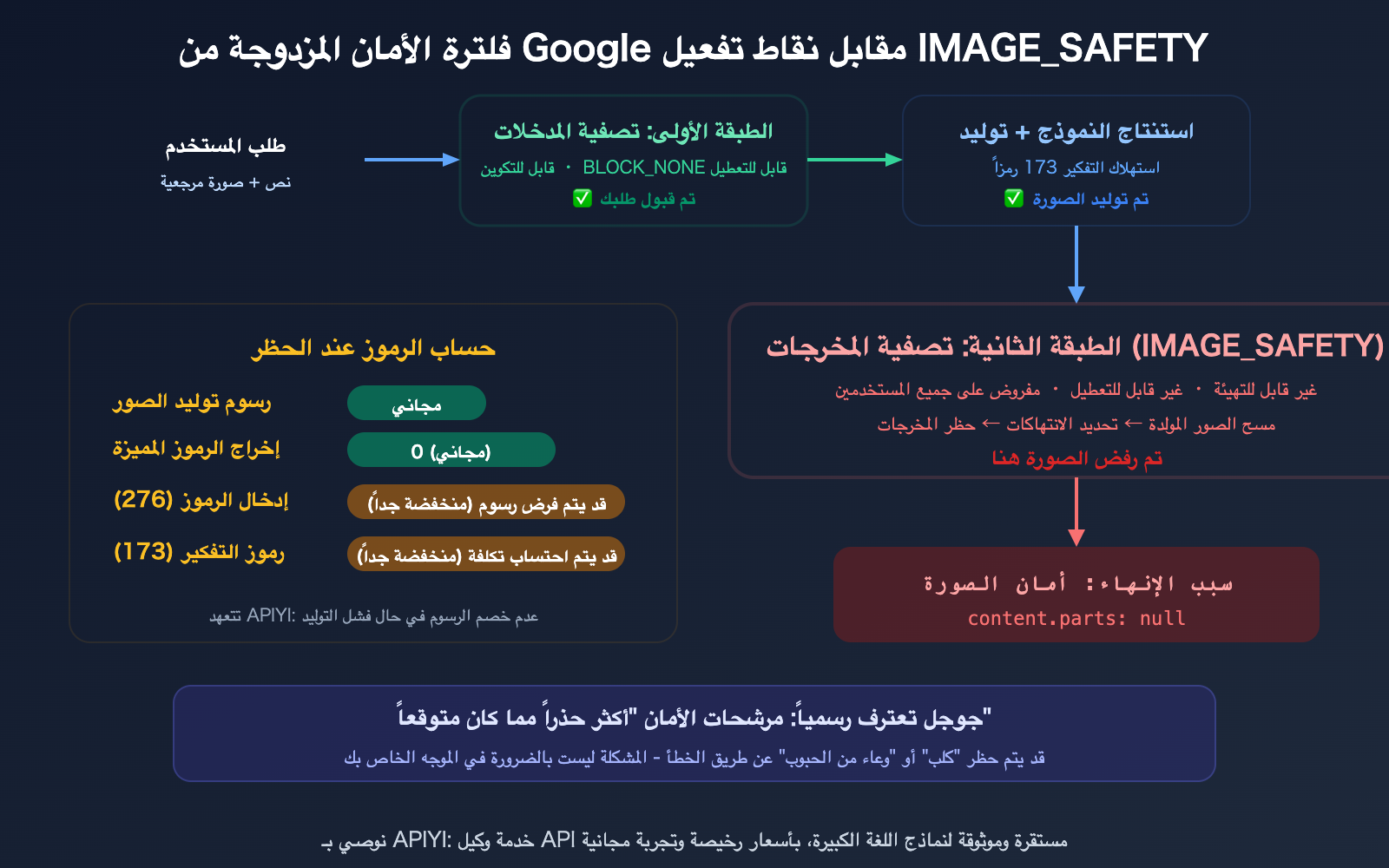
آلية فلترة الأمان المزدوجة من Google
لفهم خطأ IMAGE_SAFETY، يجب أن تدرك أن نظام أمان Google ليس طبقة واحدة، بل طبقتان — والطبقة الثانية لا يمكنك إيقاف تشغيلها.
الطبقة الأولى: إعدادات أمان الإدخال القابلة للتهيئة
| البُعد | الوصف | هل هي قابلة للتهيئة؟ |
|---|---|---|
| موقع الفلترة | جانب الإدخال (الموجه) | نعم |
| كائن الفلترة | النص والصور التي يرسلها المستخدم | نعم |
| الإعداد المتاح | BLOCK_NONE (بدون حظر) | نعم |
| التصرف عند التفعيل | رفض الطلب مباشرة، لا يتم استهلاك رموز | — |
يمكنك ضبط safety_settings على BLOCK_NONE عبر معاملات الـ API لتقليل حساسية الفلترة في الطبقة الأولى.
الطبقة الثانية: فلترة أمان المخرجات غير القابلة للتهيئة
| البُعد | الوصف | هل هي قابلة للتهيئة؟ |
|---|---|---|
| موقع الفلترة | جانب المخرجات (الصورة المولدة) | لا |
| كائن الفلترة | محتوى الصورة التي يولدها النموذج | لا |
| إمكانية الإيقاف | لا، مفعلة إجبارياً لجميع المستخدمين | لا |
| التصرف عند التفعيل | finishReason: IMAGE_SAFETY، parts: null |
— |
خطأ IMAGE_SAFETY يعني تفعيل الطبقة الثانية. لقد اجتاز الموجه الخاص بك الطبقة الأولى، وأكمل النموذج التفكير (173 رمزاً)، وولد الصورة، ولكن تم حظرها قبل المخرجات النهائية.
تعترف Google رسمياً بأن هذا المرشح "أصبح أكثر حذراً مما توقعنا"، مما أدى إلى الكثير من الحظر الخاطئ — حتى كلمات مثل "كلب" أو "وعاء من الحبوب" قد يتم حظرها.
هل يتم خصم الرصيد عند حظر الطلب بواسطة IMAGE_SAFETY؟
هذا هو السؤال العملي الذي يشغل بال معظم المطورين.
قواعد فوترة IMAGE_SAFETY في Nano Banana Pro
| بند الفوترة | هل يتم الخصم عند الحظر؟ | ملاحظات |
|---|---|---|
| رسوم توليد الصور | لا يتم الخصم | صرحت Google بوضوح: "لن يتم محاسبتك على الصور المحظورة" |
| رموز المخرجات (Output Token) | لا يتم الخصم | candidatesTokenCount: 0، لا توجد مخرجات يعني لا توجد تكلفة |
| رموز المدخلات (Input Token) | قد يتم الخصم (ضئيل جداً) | 276 رمزاً × $0.25/مليون ≈ $0.00007 (يمكن تجاهلها) |
| رموز التفكير (Thinking Token) | يعتمد على منطق الفوترة | 173 رمزاً، قد تدرجها Gemini API ضمن المرشحين (candidates) |
الخلاصة: عند الحظر بواسطة IMAGE_SAFETY، لا يتم احتساب التكاليف الرئيسية (رسوم توليد الصور ورسوم رموز المخرجات). أما تكلفة رموز المدخلات فهي ضئيلة جداً (أقل من واحد من عشرة آلاف من الدولار)، ويمكن اعتبارها مهملة.
ضمان إضافي من APIYI: عند الاستدعاء عبر APIYI (apiyi.com)، لا يتم خصم الرصيد في حال فشل التوليد — بما في ذلك حالات الحظر بواسطة IMAGE_SAFETY. أنت تدفع فقط مقابل الصور التي يتم توليدها بنجاح.
8 طرق لزيادة معدل نجاح تجاوز IMAGE_SAFETY
بما أن طبقة الأمان الثانية لا يمكن إيقاف تشغيلها، يمكننا فقط تحسين معدل النجاح من خلال طرق غير مباشرة.
الطريقة الأولى: ضبط BLOCK_NONE لإيقاف الطبقة الأولى
تأكد أولاً من أن الطبقة الأولى لن تقوم بأي حظر إضافي:
from google.genai import types
# إعدادات الأمان لتعطيل الحظر في الطبقة الأولى
safety_settings = [
types.SafetySetting(
category="HARM_CATEGORY_HARASSMENT",
threshold="BLOCK_NONE"
),
types.SafetySetting(
category="HARM_CATEGORY_HATE_SPEECH",
threshold="BLOCK_NONE"
),
types.SafetySetting(
category="HARM_CATEGORY_SEXUALLY_EXPLICIT",
threshold="BLOCK_NONE"
),
types.SafetySetting(
category="HARM_CATEGORY_DANGEROUS_CONTENT",
threshold="BLOCK_NONE"
),
]
الطريقة الثانية: إضافة تفاصيل محددة للموجه (Prompt)
الموجهات الغامضة أكثر عرضة لتفعيل مرشحات الأمان. إضافة تفاصيل محددة يمكن أن توجه النموذج لتوليد صور "أكثر أماناً":
❌ "امرأة"
→ قد يولد النموذج محتوى يعتبره المرشح غير لائق
✅ "امرأة ترتدي بدلة رسمية، تعمل في مكتب عصري،
إضاءة طبيعية، أسلوب رسم رقمي"
→ مشهد محدد + وصف الملابس + أسلوب فني → زيادة كبيرة في معدل النجاح
الطرق من الثالثة إلى الثامنة: استراتيجيات التحسين المتقدمة
| الطريقة | الإجراء | التأثير المتوقع |
|---|---|---|
| الطريقة 3: إضافة أسلوب فني | إضافة "digital illustration style" أو "watercolor style" في النهاية | تقليل الواقعية → تقليل احتمالية الحظر |
| الطريقة 4: تحديد سياق البيئة | إضافة وصف مشهد واضح ("في الحديقة"، "في المكتب") | تقييد مساحة حرية النموذج |
| الطريقة 5: تجنب وصف كشف الجلد | استخدام "formal attire" أو "winter clothing" بدلاً من وصف غامض | تجنب المناطق الحساسة مباشرة |
| الطريقة 6: استخدام موجهات بالإنجليزية | معايرة مرشحات الأمان بالإنجليزية أكثر دقة من اللغات الأخرى | تقليل الحظر الخاطئ |
| الطريقة 7: إعادة المحاولة التلقائية | إعادة صياغة الموجه تلقائياً بعد الفشل | تحسين معدل النجاح الإجمالي |
| الطريقة 8: الاستدعاء عبر APIYI | APIYI توفر إعدادات محسنة لمعايير الأمان | معدل نجاح أعلى بشكل عام |
مقارنة الموجهات قبل وبعد التحسين
| المشهد | قبل التحسين (معدل نجاح منخفض) | بعد التحسين (معدل نجاح مرتفع) |
|---|---|---|
| شخصيات | "فتاة ترتدي ملابس سباحة" | "امرأة ترتدي ملابس رياضية تتدرب في صالة ألعاب، أسلوب رسم رقمي" |
| طعام | "شريحة لحم" | "شريحة لحم متوسطة النضج على طبق أبيض، طاولة مطعم، تصوير طعام احترافي" |
| حيوانات | "كلب" | "كلب جولدن ريتريفر يمسك قرصاً طائراً في حديقة، شمس الظهيرة، أسلوب رسم رقمي" |
| تجارة إلكترونية | "عارضة ملابس داخلية" | "صورة مسطحة لملابس رياضية بيضاء، خلفية بيضاء نقية، بدون عارضة، تصوير منتجات" |
🎯 المبدأ الأساسي: كلما كان الموجه أكثر تحديداً = مساحة أقل لحرية النموذج = احتمالية أقل لتفعيل مرشحات الأمان. إضافة وسم أسلوب فني (مثل "digital illustration") يمكن أن يقلل من الحظر المرتبط بالواقعية.
معدل النجاح عند الاستدعاء عبر APIYI (apiyi.com) عادة ما يكون أعلى من الاتصال المباشر بـ Google API، لأن المنصة قامت بتحسين إعدادات معايير الأمان.
الأسئلة الشائعة
س1: لماذا يتم حظر نفس الموجه أحياناً بينما ينجح في أحيان أخرى؟
لأن فحص الأمان في الطبقة الثانية يتم على الصورة المولدة، وليس على الموجه. مع نفس الموجه، تختلف الصور التي يولدها النموذج في كل مرة قليلاً (بسبب العشوائية في نماذج الانتشار)، وقد تصادف بعض النتائج عتبة مرشح الأمان. لذا، فإن إعادة محاولة استخدام نفس الموجه قد تنجح أحياناً؛ لأن النموذج صادف أن قام بتوليد صورة "أكثر أماناً".
س2: هل من الطبيعي أن تكون قيمة thoughtsTokenCount أكبر من 0 بينما تكون candidatesTokenCount تساوي 0؟
نعم، هذا طبيعي. وهذا يوضح بالضبط أن الحظر حدث في الطبقة الثانية (مرحلة المخرجات): لقد أكمل النموذج عملية التفكير (Thinking) وقام بتوليد الصورة، ولكن تم حظر الصورة بواسطة مرشح الأمان قبل إخراجها النهائي. تم استهلاك رموز التفكير (173)، ولكن بما أنه لم يتم إخراج الصورة فعلياً، يتم احتساب رموز المخرجات كـ 0. هذا نمط استجابة خاص بـ IMAGE_SAFETY، وهو يختلف عن حظر الطبقة الأولى (حيث تكون قيمة thoughtsTokenCount أيضاً 0).
س3: ماذا أفعل إذا كانت صور الملابس الداخلية/ملابس السباحة الخاصة بالتجارة الإلكترونية تتعرض للحظر بشكل متكرر؟
هذا سيناريو شائع للحظر الخاطئ. توجد تقارير كثيرة في منتديات مطوري Google حول "صور تجارة إلكترونية لملابس داخلية غير إباحية تظهر خطأ IMAGE_SAFETY". الاقتراحات هي: 1) استخدام صور مسطحة للمنتج (بدون عارض أزياء) بدلاً من صور العارضين؛ 2) تحديد "product flat lay, no model, white background" بوضوح في الموجه؛ 3) الاستدعاء عبر APIYI (apiyi.com)، حيث تم تحسين إعدادات معلمات الأمان للمنصة لتناسب سيناريوهات التجارة الإلكترونية.
س4: هل يتم خصم رصيد عند حظر الطلبات عبر APIYI؟
لا. تلتزم APIYI بعدم الخصم في حال فشل التوليد، بما في ذلك حالات حظر IMAGE_SAFETY. أنت تدفع فقط مقابل الصور التي يتم توليدها بنجاح. هذا يتوافق مع منطق الفوترة الرسمي لـ Google API (الصور المحظورة لا يتم تحصيل رسوم عليها)، ولكن APIYI تضمن ذلك بشكل إضافي، بحيث لا يتم حتى احتساب التكاليف الطفيفة لرموز الإدخال.
الخلاصة
النقاط الجوهرية حول خطأ IMAGE_SAFETY في Nano Banana Pro:
- جوهر الخطأ هو تصفية المخرجات في الطبقة الثانية: موجهك اجتاز الطبقة الأولى، وأكمل النموذج عملية التفكير (173 رمزاً)، وتم توليد الصورة بالفعل، ولكن تم حظرها عند الإخراج النهائي بواسطة مرشح أمان الطبقة الثانية الذي لا يمكن تعطيله.
- لا يتم الخصم عند الحظر: تعني
candidatesTokenCount: 0أن رموز المخرجات لا تُحسب، وقد صرحت Google بوضوح أنها "لا تفرض رسوماً على الصور المحظورة"، والاستدعاء عبر APIYI يوفر ضماناً إضافياً بعدم الخصم عند الفشل. - تحسين الموجه يمكن أن يرفع نسبة النجاح إلى 70-80%: المبدأ الأساسي هو "كلما كنت أكثر تحديداً، زاد الأمان"؛ أضف تفاصيل المشهد، النمط الفني، وصف الملابس، واستخدم الموجهات باللغة الإنجليزية.
نوصي بالاستدعاء عبر APIYI (apiyi.com) لاستخدام Nano Banana Pro، حيث ستحصل على إعدادات أمان محسنة، ضمان عدم الخصم عند الفشل، وخصم بنسبة 28%، مما يقلل من تأثير الحظر الخاطئ لـ IMAGE_SAFETY على أعمالك.
📚 المراجع
-
وثائق إعدادات الأمان لـ Gemini API: شرح رسمي لمعلمات إعدادات الأمان
- الرابط:
ai.google.dev/gemini-api/docs/safety-settings - الوصف: تتضمن إعداد
BLOCK_NONEوقائمة فئات الأمان.
- الرابط:
-
دليل الإصلاح الكامل لخطأ IMAGE_SAFETY في Nano Banana Pro: 8 طرق لزيادة معدل النجاح
- الرابط:
help.apiyi.com/en/nano-banana-pro-image-safety-error-fix-guide-en.html - الوصف: يتضمن قوالب تحسين الموجه وحلولاً مخصصة حسب السيناريو.
- الرابط:
-
نقاش IMAGE_SAFETY في منتدى مطوري Google AI: تقارير المجتمع والردود الرسمية
- الرابط:
discuss.ai.google.dev/t/nano-banana-is-unusable-because-of-the-new-safety-filters/132366 - الوصف: اعترفت Google بأن المرشحات "حذرة للغاية".
- الرابط:
-
مركز وثائق APIYI: ضمان عدم الخصم عند فشل Nano Banana Pro
- الرابط:
docs.apiyi.com - الوصف: يتضمن تحسين معلمات الأمان وأدلة التكوين لسيناريوهات التجارة الإلكترونية.
- الرابط:
المؤلف: الفريق التقني لـ APIYI
تبادل الخبرات: نرحب بمناقشاتكم في قسم التعليقات، ولمزيد من المعلومات يمكنكم زيارة مركز وثائق APIYI على docs.apiyi.com.