"爲什麼 Gemini 3.1 Pro Preview 又卡了?""429 RESOURCE_EXHAUSTED 到底怎麼回事?"——如果你最近在使用 Google 最新的 Gemini 3.1 Pro Preview API,這兩個問題可能每天都會遇到。首次 Token 響應時間(TTFT)高達 41 秒、429 錯誤在付費用戶中也頻繁出現、Preview 模型的全局共享配額讓資源爭搶雪上加霜。
這不是你的代碼有問題,而是 Gemini 3.1 Pro Preview 當前階段的普遍現象。Google AI 開發者論壇、GitHub Issues 上充滿了類似的反饋帖。
核心價值:本文不提供"一招解決"的萬能方案——因爲確實沒有。但我們會從技術層面拆解卡頓和 429 錯誤的 5 大根本原因,分享 7 種社區驗證過的應對方案,幫你在當前階段更好地使用這個確實很強的模型。

Gemini 3.1 Pro Preview 到底有多強?先看數據
在討論問題之前,有必要先了解這個模型爲什麼值得忍受這些困擾。Gemini 3.1 Pro Preview 於 2026 年 2 月 19 日發佈,是 Google 目前最強的推理模型。
| 指標 | Gemini 3.1 Pro Preview | 對比基準 |
|---|---|---|
| ARC-AGI-2 得分 | 77.1%(驗證) | Gemini 3 Pro 的 2 倍+ |
| GPQA Diamond | 94.3% | 該基準歷史最高分 |
| 基準排名 | 18 項基準中 12+ 項第一 | 編碼、推理、Agent 任務 |
| 上下文窗口 | 1,048,576 tokens(1M) | 業界頂級 |
| 最大輸出 | 65,536 tokens(64K) | 遠超多數競品 |
| 輸入模態 | 文本+圖像+語音+視頻+代碼 | 原生多模態 |
| 輸出速度 | ~108 tokens/秒 | 中等水平 |
| TTFT(首 Token) | ~41.54 秒 | 同類模型中位數僅 2.65 秒 |
| 定價(輸入) | $2.00/M tokens | 中等偏高 |
| 定價(輸出) | $12.00/M tokens | 較高 |
| 智能指數 | 57 分 | 遠超中位數 31 分 |
數據來源:Artificial Analysis(artificialanalysis.ai)、Google 官方博客
一句話總結:Gemini 3.1 Pro Preview 是當前最聰明的公開模型之一,但也是最慢的之一。這不完全是缺陷——它的"慢"部分源於設計選擇。
Gemini 3.1 Pro Preview 卡頓的 5 大原因
原因一:Deep Think 深度思考——慢是"故意的"
Gemini 3.1 Pro Preview 引入了"Deep Think"功能——模型會刻意放慢速度以進行更深層的推理。Google 提供了 thinking_level 參數,支持 4 個級別:low、medium(新增)、high、max。
默認情況下,模型傾向於使用較高的思考級別,這直接導致了 TTFT 高達 41.54 秒——而同類模型的中位數僅爲 2.65 秒,差距超過 15 倍。
換句話說:你等待的那 40 秒,模型不是在"卡",而是在"想"。
有開發者在 Medium 上發表文章標題就叫:"Gemini 3.1 Pro Isn't Faster, It's Deeper"(Gemini 3.1 Pro 不是更快,而是更深)。這是一個設計哲學的取捨——Google 選擇了用速度換取推理深度。
原因二:Preview 模型的全局共享配額
這是最容易被忽視但影響最大的因素。
Preview(預覽版)模型使用"動態共享配額"(Dynamic Shared Quota)——所有用戶共享全局容量池。這意味着即使你個人的使用量遠低於限額,當全球其他用戶的總請求量過大時,你一樣會被限流。
Preview 模型 vs GA(正式版)模型的關鍵差異:
| 對比維度 | Preview 模型 | GA(正式版)模型 |
|---|---|---|
| 服務器容量 | 較低,有限分配 | 充足,按需擴展 |
| 配額機制 | 動態共享配額 | 獨立配額 |
| 穩定性保證 | 無,可能隨時變化 | 有 SLA 保證 |
| 限流行爲 | 全局擁堵時也會觸發 | 僅個人超限時觸發 |
| 可用週期 | 隨時可能下線 | 長期維護 |
這解釋了一個常見困惑:"我明明沒超限額,爲什麼還是 429?"——因爲配額不只看你一個人的用量。
原因三:Google 2025 年底大幅削減免費層限額
2025 年 12 月,Google 對 Gemini API 免費層的限額進行了高達 80% 的削減。雖然 Gemini 3.1 Pro Preview 本身不提供免費層訪問(僅限付費用戶),但這次削減間接推動大量開發者湧向付費層的 Preview 模型,加劇了資源爭搶。
免費層當前限額(2026 年 3 月數據):
| 模型 | RPM(每分鐘請求) | RPD(每日請求) | TPM(每分鐘 Token) |
|---|---|---|---|
| Gemini 2.5 Pro | 5 | 100 | 250,000 |
| Gemini 2.5 Flash | 10 | 250 | 250,000 |
| Flash-Lite | 15 | 1,000 | 250,000 |
| Gemini 3.1 Pro Preview | 不可用 | 不可用 | 不可用 |
對比付費 Tier 1:Gemini 2.5 Flash 從 10 RPM 跳升到 2,000 RPM——差距達 200 倍。但即便是付費層,3.1 Pro Preview 的實際限額也常常"感覺比文檔說的更嚴格"。
原因四:"幽靈 429"Bug——已知但未完全修復
Google 開發者論壇上有一個被廣泛討論的 Bug:"Ghost 429"。
症狀是:從免費層升級到付費 Tier 1 後的 24-48 小時內,即使儀表板顯示使用量爲零或接近零,仍然會頻繁收到 429 RESOURCE_EXHAUSTED 錯誤。
Google 已經在開發者論壇上確認了這個 Bug 的存在,並解釋是配額計算系統在賬戶升級後的不正確計算導致的。臨時解決方案是等待 24-48 小時讓系統重新校準。
這個 Bug 主要影響:
- 最近從免費層升級到 Tier 1 的用戶
- 最近創建新項目並啓用計費的用戶
原因五:高峯時段的服務器擁堵
根據社區反饋,Gemini 3.1 Pro Preview 在以下時段的延遲和 429 錯誤率明顯更高:
- 太平洋時間 9:00 AM – 6:00 PM(北京時間次日凌晨 1:00 – 10:00)
- 這與美國工作日高峯完全重合
在高峯期,部分請求的延遲甚至高達 104 秒,503 服務不可用錯誤也時有發生。GitHub Issues #22160 記錄了"使用 gemini-3.1-pro 模型時出現極高延遲或無響應"的問題。
🎯 實際體驗:如果你在國內使用 Gemini API 遇到頻繁卡頓,除了上述原因外,網絡延遲也是一個因素。通過 API易 apiyi.com 等聚合平臺調用可以利用優化後的網絡路由,減少一部分傳輸延遲。

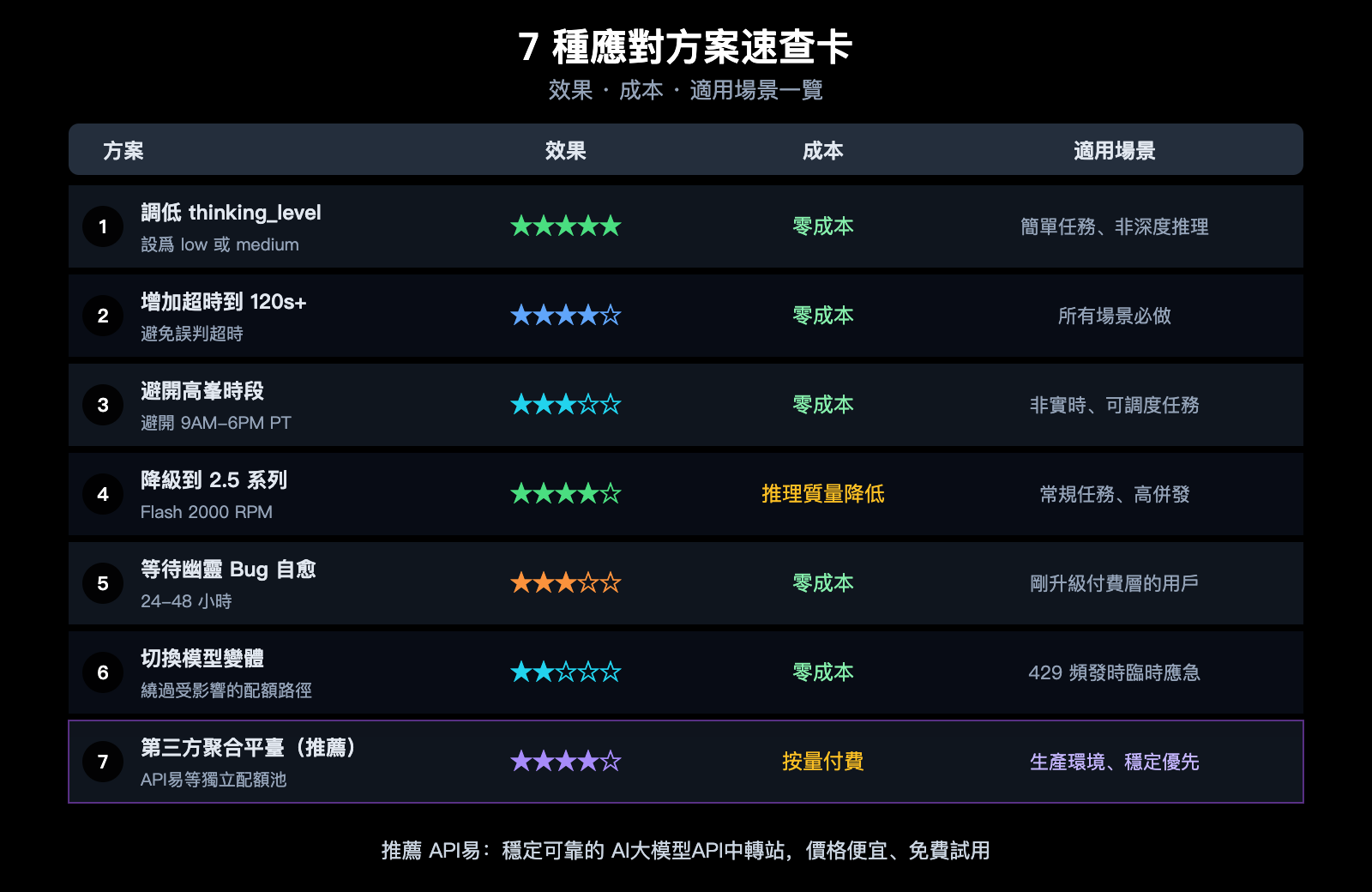
7 種應對 Gemini 3.1 Pro Preview 卡頓和 429 錯誤的方案
聲明:以下方案來自開發者社區的實踐分享,並非 Google 官方推薦。效果因具體場景而異,不保證完全解決問題。
方案一:調整 thinking_level 參數
這是最直接的提速手段。將 thinking_level 設置爲 low,可以大幅縮短 TTFT:
import openai
client = openai.OpenAI(
api_key="your-api-key",
base_url="https://api.apiyi.com/v1" # API易統一接口
)
response = client.chat.completions.create(
model="gemini-3.1-pro-preview",
messages=[
{"role": "user", "content": "用 3 句話解釋量子計算"}
],
extra_body={
"thinking_level": "low" # 可選: low / medium / high / max
}
)
print(response.choices[0].message.content)
| thinking_level | TTFT 估算 | 推理深度 | 適用場景 |
|---|---|---|---|
| low | 5-10 秒 | 基礎推理 | 簡單問答、摘要、分類 |
| medium | 15-25 秒 | 中等推理 | 日常編碼、內容生成 |
| high | 30-45 秒 | 深度推理 | 複雜分析、數學證明 |
| max | 45-100+ 秒 | 最深推理 | 極難推理、科研級任務 |
取捨:low 更快但推理質量下降;如果你用 3.1 Pro 就是爲了它的深度推理能力,那降低 thinking_level 可能得不償失。
方案二:增加客戶端超時時間
大多數 HTTP 客戶端和 SDK 的默認超時時間是 30 秒——但 Gemini 3.1 Pro Preview 的正常 TTFT 就可能超過 40 秒。建議將超時設置爲 至少 120 秒:
import httpx
import openai
# 設置 120 秒超時
http_client = httpx.Client(timeout=120.0)
client = openai.OpenAI(
api_key="your-api-key",
base_url="https://api.apiyi.com/v1",
http_client=http_client
)
方案三:避開高峯時段
如果你的任務不要求實時響應,嘗試在以下時段調用 API:
- 太平洋時間 6:00 PM – 9:00 AM(北京時間 10:00 AM – 次日 1:00 AM)
- 週末全天通常比工作日更穩定
- RPD(每日請求)配額在太平洋時間午夜重置
方案四:降級到 Gemini 2.5 Pro / 2.5 Flash
不是所有任務都需要 3.1 Pro 的推理深度。對於常規任務,Gemini 2.5 系列仍然是可靠的選擇:
- Gemini 2.5 Flash:免費層 10 RPM,付費層高達 2,000 RPM,速度快得多
- Gemini 2.5 Pro:免費層 5 RPM,能力仍然很強
在 3.1 Pro 頻繁 429 時,2.5 系列是最現成的降級方案。
方案五:等待"幽靈 429"Bug 自愈
如果你剛從免費層升級到 Tier 1,或者剛創建新項目並啓用計費:
- 等待 24-48 小時讓配額系統重新校準
- 期間使用其他模型或平臺作爲過渡
- 如果 48 小時後仍有問題,在 Google AI 開發者論壇提交 Issue
方案六:切換模型變體繞過限流
Google 開發者論壇上有一個被驗證有效的技巧:切換到同系列的不同模型變體,有時可以繞過受影響的配額路徑。
例如:
- 如果
gemini-3.1-pro-preview報 429,嘗試gemini-3.1-flash-preview(如果可用) - 不同模型變體可能走不同的配額計算路徑
方案七:使用第三方 API 聚合平臺
第三方平臺通常有獨立的配額池,不受 Google 官方 API 的全局共享配額限制。這是社區中被越來越多開發者採用的方案。
查看完整代碼(含自動降級和錯誤重試邏輯)
import openai
import time
# 通過 API易 聚合平臺調用,獨立配額池
client = openai.OpenAI(
api_key="your-api-key",
base_url="https://api.apiyi.com/v1"
)
# 模型降級鏈:優先用最強的,429 時自動降級
model_fallback = [
"gemini-3.1-pro-preview",
"gemini-2.5-pro",
"gemini-2.5-flash",
]
def call_with_fallback(prompt, max_retries=3):
for model in model_fallback:
for attempt in range(max_retries):
try:
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
max_tokens=2000,
timeout=120
)
return {
"model": model,
"content": response.choices[0].message.content,
"attempt": attempt + 1
}
except openai.RateLimitError:
wait = 2 ** attempt
print(f"[{model}] 429 限流,等待 {wait}s 後重試...")
time.sleep(wait)
except openai.APITimeoutError:
print(f"[{model}] 超時,嘗試下一個模型...")
break
return {"error": "所有模型均不可用"}
result = call_with_fallback("分析 Transformer 注意力機制的計算複雜度")
print(f"使用模型: {result.get('model')}")
print(f"回覆: {result.get('content', result.get('error'))}")
🚀 推薦方案:通過 API易 apiyi.com 平臺調用 Gemini 3.1 Pro Preview 等 Google 模型,可以利用平臺的獨立配額池和多通道路由,減少 429 錯誤的發生概率。註冊即送免費額度,同時支持 Claude、GPT、Gemini 等多家模型的統一調用。
一個未解的問題:Preview 模型到底值不值得用?
這是一個沒有標準答案的問題,但值得每個開發者思考。
支持使用的理由:
- 3.1 Pro Preview 在 18 項基準中 12+ 項排名第一
- GPQA Diamond 94.3% 是歷史最高分
- Deep Think 帶來的推理深度確實是獨一無二的
- 提前適應最新模型,在 GA 版本發佈時有先發優勢
反對使用的理由:
- TTFT 41 秒,不適合實時交互場景
- 429 錯誤頻發,生產環境不穩定
- Preview 模型可能隨時變更或下線(Gemini 3 Pro Preview 已於 2026.03.09 停服)
- 無 SLA 保證,出問題只能自認倒黴
中間路線:在開發和測試階段使用 3.1 Pro Preview 驗證效果,在生產環境中使用 2.5 系列或其他穩定模型,等 3.1 Pro 正式版(GA)發佈後再切換。
💡 務實建議:如果你的應用場景需要深度推理且能接受高延遲,3.1 Pro Preview 值得嘗試。如果需要穩定和速度,2.5 Flash 是更務實的選擇。我們建議通過 API易 apiyi.com 同時接入多個 Gemini 模型版本,在實際場景中對比效果後做決策。
常見問題
Q1:429 RESOURCE_EXHAUSTED 錯誤是不是因爲我的免費額度用完了?
不一定。429 錯誤有多種觸發原因:個人超限(RPM/RPD/TPM)、全局共享配額擁堵、以及"幽靈 429"Bug。特別是 Preview 模型使用動態共享配額,即使你的個人使用量遠低於限額,全球擁堵時也會被限流。建議先在 Google AI Studio 中查看你的實際用量,確認是否真的超限。如果儀表板顯示用量很低但仍報 429,大概率是共享配額或 Bug 導致的。
Q2:付費升級到 Tier 1 能解決 429 問題嗎?
能緩解但不能完全解決。付費層的限額確實大幅提升(例如 Flash 從 10 RPM 跳到 2,000 RPM),但 3.1 Pro Preview 的共享配額機制在付費層同樣生效。而且剛升級時可能遭遇"幽靈 429"Bug,需要等 24-48 小時穩定。對於需要更高配額的場景,通過 API易 apiyi.com 等聚合平臺調用可以利用獨立配額池,減少被限流的概率。
Q3:Gemini 3.1 Pro 的正式版(GA)什麼時候發佈?
Google 尚未公佈具體日期。參考歷史節奏,Preview 到 GA 通常需要 2-4 個月。3.1 Pro Preview 於 2026 年 2 月 19 日發佈,樂觀估計 GA 版本可能在 2026 年 Q2 末至 Q3 發佈。GA 版本將有獨立配額(非共享)、SLA 保證和更充足的服務器容量。目前可以通過 API易 apiyi.com 免費測試 Gemini 全系列模型的調用效果。
總結:與 Gemini 3.1 Pro Preview 的"不完美"共處
Gemini 3.1 Pro Preview 是一個很強但很"難伺候"的模型。它的 GPQA Diamond 94.3% 和 ARC-AGI-2 77.1% 證明了它的推理能力確實是當前頂級,但 41 秒的 TTFT 和頻繁的 429 錯誤也讓日常使用充滿挑戰。
核心原因:Deep Think 的設計取捨、Preview 模型的全局共享配額、以及 Google 在免費層限額大幅削減後帶來的生態連鎖反應。
務實應對:
- 非深度推理任務,設置
thinking_level: "low"或降級到 2.5 系列 - 增加超時到 120 秒+,避免誤判超時
- 用第三方聚合平臺(如 API易 apiyi.com)獲取獨立配額池
- 等待 GA 版本發佈後再用於生產環境
這些問題大概率會在 GA 版本中得到改善。在那之前,我們能做的就是——瞭解它的脾氣,用對的方式去使用它。
作者:APIYI Team | Gemini、Claude、GPT 全系列模型 API 統一調用,歡迎訪問 API易 apiyi.com 獲取免費測試額度
📚 參考資料
-
Google 官方 – Gemini API 速率限制文檔:各模型限額詳情
- 鏈接:
ai.google.dev/gemini-api/docs/rate-limits - 說明: 免費層和付費層的 RPM/RPD/TPM 限額對照表
- 鏈接:
-
Google AI 開發者論壇 – 429 錯誤討論串:社區反饋彙總
- 鏈接:
discuss.ai.google.dev - 說明: 包含"幽靈 429"Bug 確認和臨時解決方案
- 鏈接:
-
GitHub Issue #22160 – Gemini 3.1 Pro 極高延遲:開發者反饋
- 鏈接:
github.com/google-gemini/gemini-cli/issues/22160 - 說明: 延遲數據和社區討論
- 鏈接:
-
Artificial Analysis – Gemini 3.1 Pro Preview 評測:獨立基準測試
- 鏈接:
artificialanalysis.ai/models/gemini-3-1-pro-preview - 說明: TTFT、輸出速度、智能指數等客觀數據
- 鏈接:
-
Vertex AI 官方文檔 – 429 錯誤碼說明:Google 雲平臺錯誤處理
- 鏈接:
docs.cloud.google.com/vertex-ai/generative-ai/docs/provisioned-throughput/error-code-429 - 說明: 官方的錯誤原因分類和建議處理方式
- 鏈接: