Модель Claude Opus 4.7 была официально представлена 16 апреля 2026 года, и уже на второй день после запуска сообщество разделилось на два лагеря. Согласно официальным бенчмаркам, модель показывает лучшие результаты в 12 из 14 тестов по сравнению с версией 4.6. Однако многие разработчики на GitHub и в X жалуются, что в реальности производительность ниже, и некоторые даже называют её «замаскированной предрелизной версией 4.6».
В этой статье мы подробно разберем Claude Opus 4.7, основываясь на официальных данных Anthropic, независимых тестах и отзывах сообщества. Мы оценим её по 8 параметрам, включая возможности кодинга, распознавание визуальных данных, работу с длинным контекстом, изменения в токенизаторе и Task Budgets, чтобы вы могли решить, стоит ли переходить на неё прямо сейчас.
Главный вывод: Прочитав статью, вы поймете, является ли переход на Claude Opus 4.7 апгрейдом или даунгрейдом для ваших задач, а также узнаете, как избежать рисков при миграции.

Предыстория выпуска Claude Opus 4.7 и ключевая информация
Claude Opus 4.7 — это флагманская модель, выпущенная Anthropic 16 апреля 2026 года. Она сохранила ценообразование своего предшественника (5/25 долларов за миллион токенов) и установила новые рекорды в ряде бенчмарков. Однако её релиз сопровождался такими системными изменениями, как рефакторинг токенизатора, значительное падение показателей в бенчмарке длинного контекста MRCR и появление нового режима вывода xhigh. Эти изменения напрямую влияют на производительность в реальных бизнес-задачах.
Краткий обзор Claude Opus 4.7
| Параметр | Подробности |
|---|---|
| Дата выпуска | 16 апреля 2026 г. |
| Разработчик | Anthropic |
| Цена на вход | $5 / млн токенов (как у 4.6) |
| Цена на выход | $25 / млн токенов (как у 4.6) |
| Контекстное окно | 1 млн токенов (стандарт) |
| Макс. разрешение изображения | 2576 пикселей (по длинной стороне) / 3,75 Мп |
| Новые режимы вывода | xhigh (между high и max) |
| Новые экспериментальные функции | Task Budgets (в режиме публичного тестирования) |
| Доступные каналы | Claude API, Amazon Bedrock, Google Vertex AI, Microsoft Foundry |
🎯 Технический совет: Прежде чем переходить на Claude Opus 4.7, рекомендуем запустить параллельное тестирование 4.6 и 4.7 через сервис-прокси API APIYI (apiyi.com). Платформа предоставляет унифицированный интерфейс, где для переключения модели достаточно просто поменять параметр, что позволяет быстро выявить разницу в производительности.
Основные улучшения Claude Opus 4.7
Официально Anthropic делает упор на четыре направления улучшений:
- Значительное усиление навыков разработки ПО: показатель SWE-bench Verified вырос с 80,8% до 87,6%, а SWE-bench Pro — с 53,4% до 64,3%.
- Скачок в визуальном понимании: поддержка изображений высокого разрешения до 3,75 Мп, визуальные бенчмарки выросли с 54,5% до 98,5%.
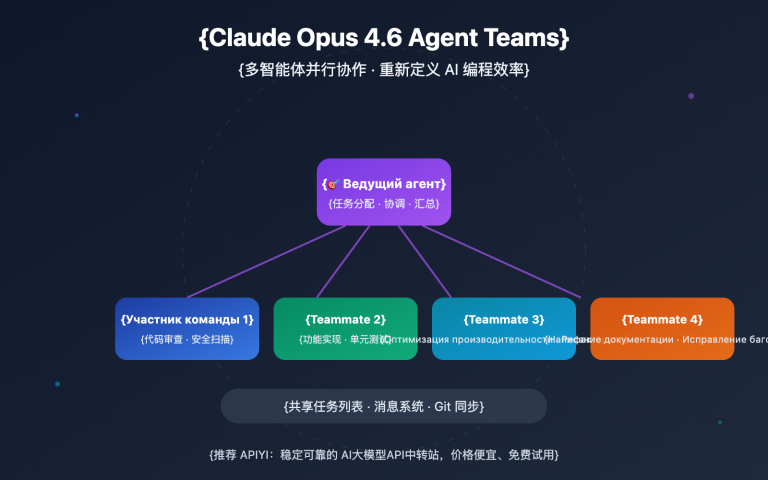
- Улучшенная работа с агентскими инструментами: максимальный прирост в бенчмарке MCP-Atlas, улучшение на 13 пунктов без использования инструментов.
- Более точное следование инструкциям: модель стала надежнее обрабатывать неоднозначные запросы и точнее выполнять указания.
Однако реальные отзывы сообщества показывают ситуацию с другой стороны.
Детальный разбор ключевых функций Claude Opus 4.7
Ключевые изменения в Claude Opus 4.7 касаются не только возможностей самой модели, но и важных корректировок на уровне доставки. Понимание этих изменений критически важно для корректной оценки производительности модели.
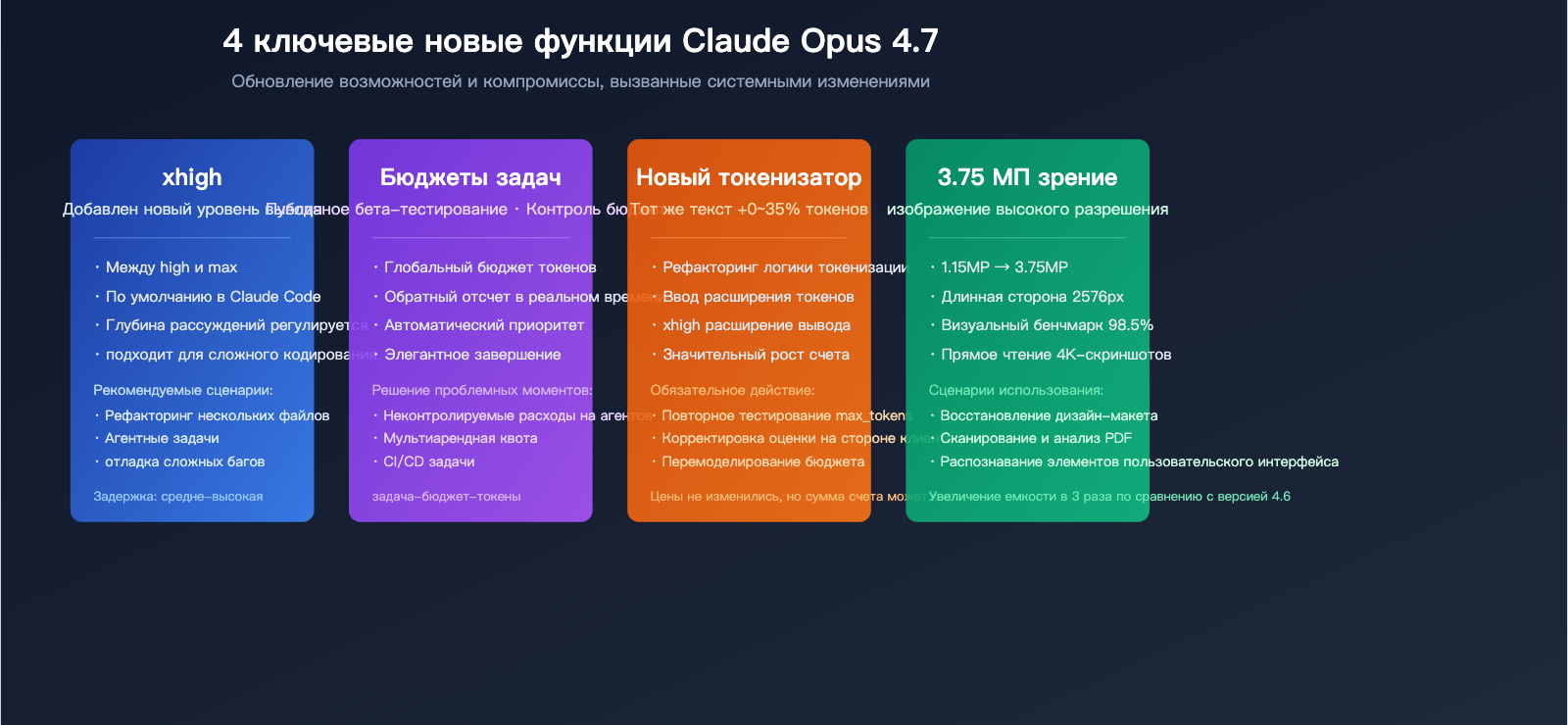
Четыре системных изменения в Claude Opus 4.7
| Функциональный модуль | Версия 4.6 | Изменения в 4.7 | Влияние на бизнес |
|---|---|---|---|
| Токенизатор | Стандартная токенизация | 1.0–1.35× токенов на тот же текст | Реальный счет может вырасти на 35% |
| Уровни рассуждений | low / medium / high / max | Добавлен xhigh (по умолчанию в Claude Code) | Более точная настройка глубины и задержки |
| Task Budgets | Отсутствует | Бета-версия, контроль бюджета токенов | Контролируемая стоимость циклов Agent |
| Визуальный ввод | ~1.15 млн пикселей | ~3.75 млн пикселей (3×) | Поддержка скриншотов и чертежей в HD |
| Длинный контекст (MRCR) | 78.3% | 32.2% | Значительное снижение качества извлечения данных |
| SWE-bench Verified | 80.8% | 87.6% | Существенный рост в реальных задачах по кодингу |
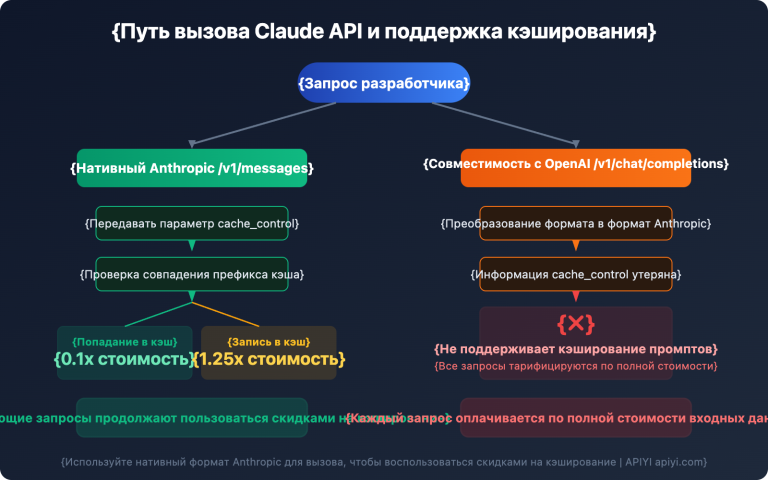
Скрытые расходы при изменении токенизатора
Самое важное, но при этом часто упускаемое из виду изменение в Claude Opus 4.7 — это рефакторинг токенизатора. В официальной документации четко указано: один и тот же входной текст в версии 4.7 преобразуется в количество токенов, в 1.0–1.35 раза превышающее объем для версии 4.6. Это означает следующее:
- Длина вашего промпта осталась прежней, но расходы на входящие токены могут вырасти до 35%.
- На уровнях рассуждений xhigh или max объем выходных токенов также может существенно увеличиться.
- Ранее заданные лимиты
max_tokens(на базе версии 4.6) требуют полного повторного тестирования. - Логику клиентских приложений, оценивающих токены на основе количества символов, нужно переписать.
💰 Оптимизация затрат: для производственных сред, чувствительных к стоимости токенов, перед миграцией на Claude Opus 4.7 настоятельно рекомендуется провести пробный расчет на реальном трафике через платформу APIYI apiyi.com. Платформа поддерживает гибкие запросы биллинга и мониторинг в реальном времени, что упрощает количественную оценку дополнительных расходов после миграции.
Стратегия использования уровня рассуждений xhigh
xhigh — это новый уровень рассуждений в Opus 4.7, расположенный между high и max. Anthropic рекомендует использовать xhigh по умолчанию для задач программирования и работы агентов; именно этот уровень является стандартным для всех пакетов Claude Code.
Сценарии использования различных уровней рассуждений:
| Уровень | Подходящие задачи | Задержка | Рекомендации |
|---|---|---|---|
low |
Простые вопросы, смена формата | Минимальная | Высоконагруженные, простые задачи |
medium |
Обычная генерация кода | Низкая | Помощь в повседневной разработке |
high |
Сложный код, технический дизайн | Средняя | Стандартные задачи Agent |
xhigh |
Отладка, масштабный рефакторинг | Средне-высокая | Рекомендуется: Claude Code и разработка |
max |
Экстремально сложные рассуждения | Высокая | Исследовательские задачи, некритичные ко времени |
Task Budgets: конец неконтролируемым расходам агентов
Task Budgets — это функция, представленная в бета-версии Opus 4.7, которая решает давнюю проблему невозможности контроля общего потребления токенов при циклической работе агентов. Принцип работы:
- Разработчик перед запуском цикла агента задает общий бюджет токенов.
- На каждом этапе ответа модель видит «обратный отсчет» бюджета.
- Модель автоматически корректирует глубину размышлений и количество вызовов инструментов в зависимости от остатка бюджета.
- До исчерпания лимита модель отдает приоритет выполнению основных задач и корректному завершению работы.
Эта функция в сочетании с новым заголовком UI redact-thinking-2026-02-12 является существенным шагом вперед в управлении затратами на работу агентов.
Обзор результатов тестирования Claude Opus 4.7
Этот раздел — сердце нашей статьи. Мы собрали официальные бенчмарки Anthropic, независимые оценки сторонних экспертов и данные повторных тестов сообщества, чтобы показать реальную разницу между Claude Opus 4.7 и 4.6.
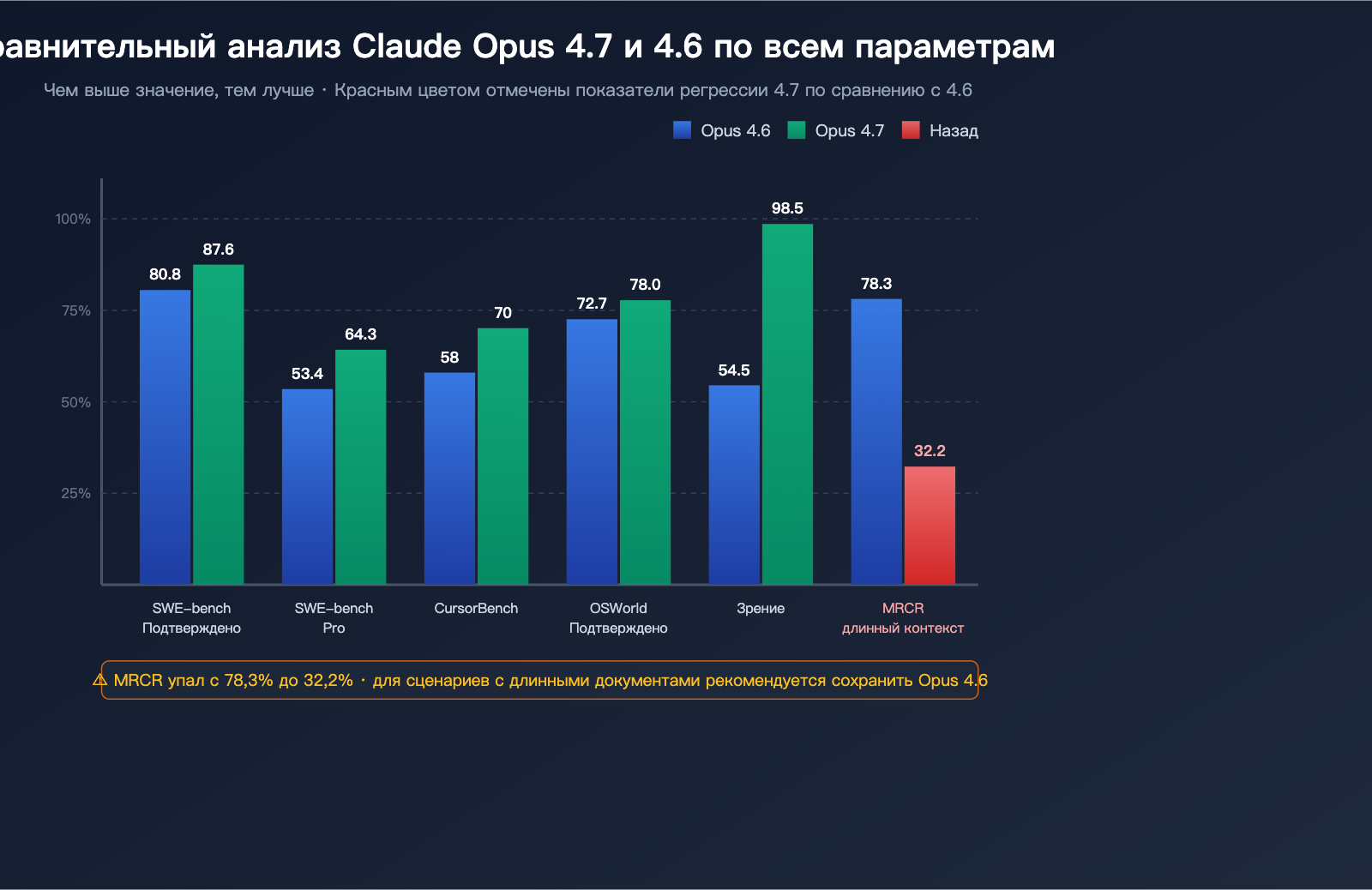
Бенчмарки кодинга: 4.7 — безоговорочный лидер
| Бенчмарк кодинга | Opus 4.6 | Opus 4.7 | Прирост | Примечание |
|---|---|---|---|---|
| SWE-bench Verified | 80.8% | 87.6% | +6.8 п.п. | Исправление реальных GitHub Issues |
| SWE-bench Pro | 53.4% | 64.3% | +10.9 п.п. | Более сложный вариант на разных языках |
| CursorBench | 58% | 70% | +12 п.п. | Реальные задачи в IDE |
| OSWorld-Verified | 72.7% | 78.0% | +5.3 п.п. | Работа с десктопом и компьютером |
| MCP-Atlas (без инструментов) | — | +13 п.п. | Макс. прирост | Задачи для агентов |
| MCP-Atlas (с инструментами) | — | +6 п.п. | Заметный рост | Точность вызова инструментов |
В сфере программирования Claude Opus 4.7 — безусловно, самая мощная публичная модель на второй квартал 2026 года. Результат 64.3% в SWE-bench Pro позволил ей вернуть себе лидерство в агентском кодинге.
🚀 Быстрый старт: Если вы хотите немедленно протестировать возможности кодинга Claude Opus 4.7, вы можете использовать сервис-прокси API APIYI (apiyi.com). Он предоставляет интерфейс, полностью совместимый с официальным API Claude, поддерживает стандартный формат OpenAI SDK, что делает переход максимально простым.
Визуальные возможности и контекстное окно: резкий контраст
| Бенчмарк | Opus 4.6 | Opus 4.7 | Изменение | Оценка |
|---|---|---|---|---|
| Визуальное распознавание | 54.5% | 98.5% | +44 п.п. | Почти качественный скачок |
| Макс. разрешение изображений | ~1.15 Мп | ~3.75 Мп | 3× | Поддержка скриншотов 4K |
| MRCR (длинный контекст) | 78.3% | 32.2% | -46.1 п.п. | Серьезный регресс |
MRCR (Multi-Round Context Recall) — стандартный бенчмарк для оценки работы с длинным контекстом. Показатель Opus 4.7 рухнул с 78.3% до 32.2%. Это не просто колебание, а структурная деградация.
Эти цифры объясняют, почему многие разработчики жалуются: «Я скормил модели 800 страниц документации, она подтвердила, что прочитала, но ответы никак не связаны с текстом».
Бенчмарки против реальности: почему оценки так разнятся?
Высокие баллы в тестах не всегда означают лидерство в реальных задачах. Opus 4.7 получил много негативных отзывов от сообщества по нескольким причинам:
- Раздувание токенов: на те же задачи уходит больше токенов, но прирост качества не всегда оправдывает затраты.
- Слишком буквальное следование инструкциям: если 4.6 умела «понимать намерение», то 4.7 выполняет всё буквально, из-за чего старые промпты могут перестать работать.
- Провал MRCR: способность находить информацию в длинных документах снизилась, что критично при работе с большими кодовыми базами или контрактами.
- Ложные срабатывания в Claude Code: некоторые разработчики сообщают, что 4.7 ошибочно помечает нормальный код как вредоносный и отказывается его редактировать.
💡 Совет по выбору: Выбор между Claude Opus 4.7 и 4.6 зависит от ваших задач. Мы рекомендуем провести нагрузочное тестирование обеих версий через сервис-прокси API APIYI (apiyi.com). Платформа поддерживает единый интерфейс для разных моделей, что позволяет быстро сравнивать их и переключаться между ними.
Реальный опыт использования Claude Opus 4.7
Помимо бенчмарков, Anthropic и сообщество разработчиков представили совершенно разные отзывы о работе Opus 4.7 в реальных рабочих процессах.
Официальная позиция Anthropic
В анонсе Anthropic сделала акцент на четырех ключевых улучшениях Opus 4.7 по сравнению с версией 4.6:
- Более высокая производительность в инженерных пайплайнах: пользователи могут смело доверять модели «сложную работу», которая раньше требовала строгого контроля.
- Улучшенная обработка размытых запросов: модель стала стабильнее при работе с нечетко сформулированными задачами.
- Более глубокое решение проблем: модель не бросает задачу на полпути.
- Более точное следование инструкциям: строгое соблюдение деталей.
Борис Черный, руководитель проекта Claude Code, после релиза заявил, что Opus 4.7 «умнее, обладает более выраженными агентными способностями и точнее», чем 4.6, но признал, что потребуется несколько дней на адаптацию, чтобы в полной мере раскрыть её новые возможности.
Реальные отзывы сообщества разработчиков
На таких платформах, как GitHub, Hacker News и X, отзывы разработчиков оказались заметно более скептичными:
Жалоба 1: Резкий рост потребления токенов
Из-за нового токенизатора один и тот же ввод в Opus 4.7 разбивается на большее количество токенов. В сочетании с увеличением выходных токенов в режиме xhigh, некоторые пользователи сообщают о росте счетов до 40%. Это в шутку называют «AI Shrinkflation» (инфляция при уменьшении объема).
Жалоба 2: Катастрофа при обработке длинных документов
Многие разработчики сообщают: после загрузки длинных документов в Opus 4.7 модель утверждает, что прочитала их, но сгенерированный контент не имеет ничего общего с содержанием документа. Это коррелирует с падением показателя MRCR с 78,3% до 32,2%.
Жалоба 3: Claude Code ошибочно принимает код за вредоносный
В Issue #47483 многие инженеры жалуются: Claude Opus 4.7 помечает обычный код для чтения/записи файлов как вредоносное ПО (malware) и отказывается выполнять базовые запросы на редактирование.
Жалоба 4: Снижение совместимости промптов
Промпты, которые отлично работали на 4.6, после миграции на 4.7 показывают худшее качество вывода. Причина в том, что 4.7 строго следует буквальным инструкциям, тогда как 4.6 умел «читать между строк».
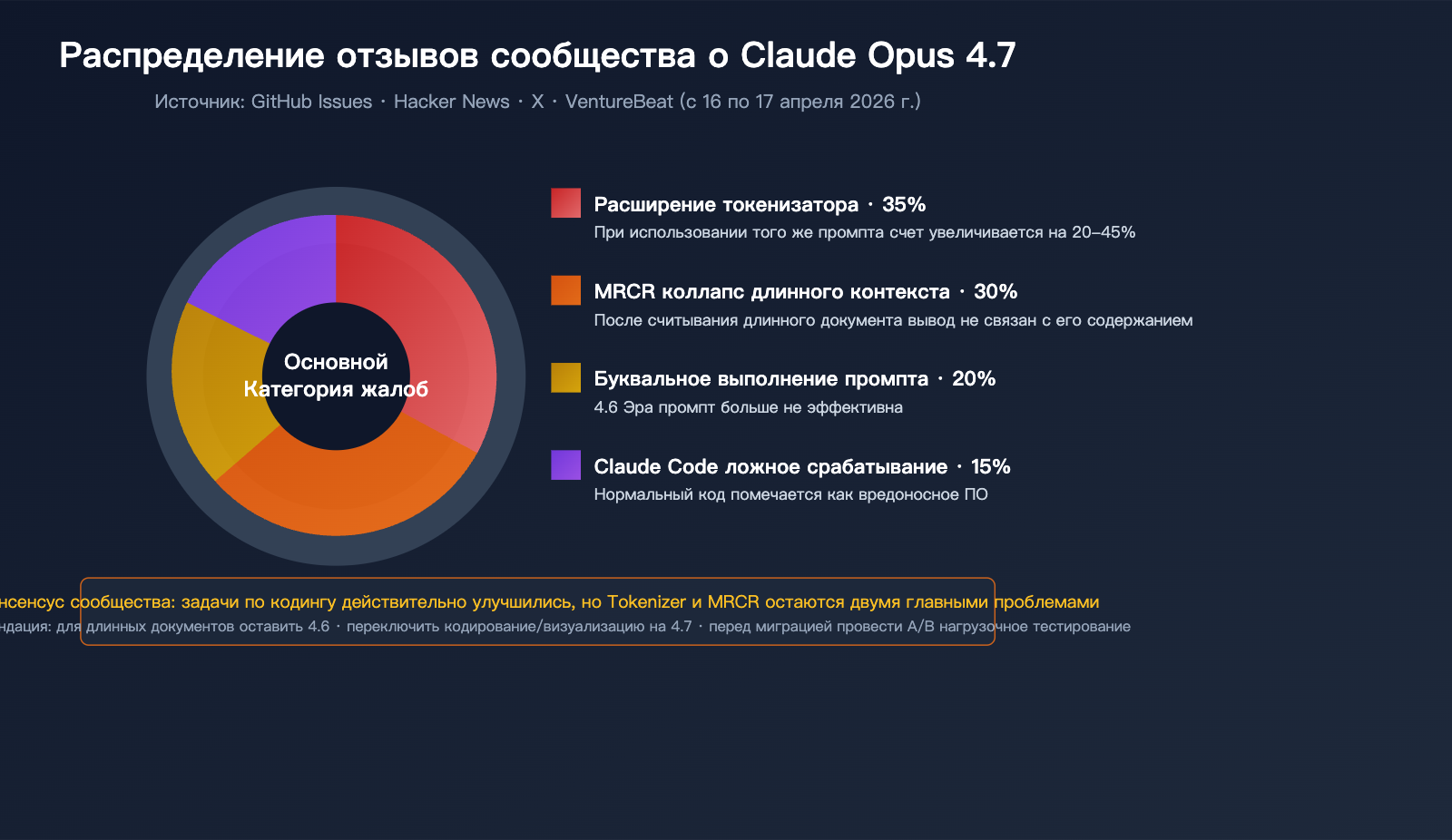
Оценка Claude Opus 4.7 по сценариям использования
Основываясь на данных тестирования и отзывах сообщества, мы оценили работу Opus 4.7 в различных сценариях:
| Сценарий использования | Оценка Opus 4.6 | Оценка Opus 4.7 | Изменение | Рекомендация |
|---|---|---|---|---|
| Рефакторинг кода (короткие файлы) | 8/10 | 9/10 | ↑ | Срочно мигрировать |
| Сложные агентные рабочие процессы | 7.5/10 | 9/10 | ↑ | Срочно мигрировать |
| Обзор кода в крупных репозиториях | 8/10 | 6.5/10 | ↓ | Продолжать использовать 4.6 |
| Резюмирование и ответы по длинным документам | 8.5/10 | 5/10 | ↓↓ | Продолжать использовать 4.6 |
| Анализ изображений высокого разрешения | 6.5/10 | 9.5/10 | ↑↑ | Срочно мигрировать |
| Обычный диалог и написание текстов | 9/10 | 9/10 | → | Любая версия |
| Производство, чувствительное к затратам | 9/10 | 7/10 | ↓ | Продолжать использовать 4.6 |
| Прототипирование и эксперименты | 8/10 | 8.5/10 | ↑ | Мигрировать |
Глубокий анализ плюсов и минусов Claude Opus 4.7
После сравнения данных и пользовательского опыта можно подвести итоги.
Четыре ключевых преимущества Claude Opus 4.7
Преимущество 1: Значительное улучшение навыков программирования
Результаты SWE-bench Verified (87,6%) и SWE-bench Pro (64,3%) — это не просто цифры, а реальные задачи по исправлению проблем на GitHub. Это означает, что Opus 4.7 действительно может заменить больше человеческого труда при выполнении задач по написанию кода.
Преимущество 2: Качественный скачок в визуальном понимании
Ввод изображений высокого разрешения (3,75 мегапикселя) позволяет Opus 4.7 напрямую обрабатывать 4K-скриншоты, дизайн-макеты, PDF-сканы и другой контент с высокой плотностью визуальных данных. Это важный прорыв для серии Claude.
Преимущество 3: Task Budgets для контроля затрат агентов
Долгое время неконтролируемое потребление токенов в агентных циклах было главным препятствием для внедрения в корпоративной среде. Task Budgets впервые дают разработчикам возможность точного глобального контроля бюджета.
Преимущество 4: Режим xhigh для баланса между рассуждением и задержкой
Появление дополнительного режима между high и max означает, что разработчики могут гибко настраивать модель под требования SLA в рамках одного и того же сценария.
Четыре основных ограничения Claude Opus 4.7
Ограничение 1: Рост реальных затрат из-за токенизатора
Даже при неизменной цене за токен, 35% «раздувание» токенов плюс расширение вывода в режиме xhigh могут привести к тому, что реальный счет будет на 20–45% выше, чем у 4.6.
Решение: перед миграцией перепроверьте все пути кода с помощью API подсчета токенов.
Ограничение 2: Проблемы с MRCR и контекстным окном
Это самая критическая проблема. При обработке длинных документов, больших кодовых баз и длинных диалогов точность извлечения данных у Opus 4.7 резко падает.
Решение: для сценариев с длинными документами продолжайте использовать Opus 4.6 или используйте стратегию RAG + разбиение на части.
Ограничение 3: Слишком буквальное следование инструкциям
Ваши старые промпты могут давать неожиданные результаты.
Решение: систематически переписывайте промпты, убирая скрытые намеки и переходя к явным ограничениям.
Ограничение 4: Рост ошибок и галлюцинаций в ряде сценариев
Сообщество сообщает об ошибках Claude Code, галлюцинациях в длинных документах и т.д.
Решение: для критических задач используйте проверку человеком, а для ключевой логики — перекрестную проверку несколькими моделями.
🎯 Рекомендация по миграции: Если ваш бизнес связан как с написанием кода, так и с обработкой длинных документов, рекомендуем использовать платформу APIYI (apiyi.com) для маршрутизации между версиями Claude в зависимости от задачи. Платформа поддерживает унифицированный вызов моделей, позволяя гибко сочетать Opus 4.6 (для длинного контекста) и 4.7 (для кода/визуальных задач) в одном проекте, избегая падения производительности при «слепой» миграции.
Практика вызова API Claude Opus 4.7
Помимо теоретического анализа, мы подготовили примеры реально работающего кода, которые помогут вам быстро начать работу с Claude Opus 4.7.
Минималистичный пример (совместимость с OpenAI SDK)
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=[
{"role": "user", "content": "Напиши пример параллельного парсера на Python"}
],
temperature=0.7,
max_tokens=4096
)
print(response.choices[0].message.content)
Посмотреть полный код (включая режим рассуждений xhigh, бюджеты задач и обработку ошибок)
import openai
import time
from typing import Optional
class ClaudeOpusClient:
"""Класс-обертка для вызова Claude Opus 4.7"""
def __init__(self, api_key: str, base_url: str = "https://api.apiyi.com/v1"):
self.client = openai.OpenAI(
api_key=api_key,
base_url=base_url
)
def generate(
self,
prompt: str,
model: str = "claude-opus-4-7",
effort: str = "xhigh",
task_budget: Optional[int] = None,
max_retries: int = 3
) -> str:
"""Вызов Claude Opus 4.7 с поддержкой новых функций"""
extra_headers = {}
if task_budget:
extra_headers["task-budget-tokens"] = str(task_budget)
if effort:
extra_headers["reasoning-effort"] = effort
for attempt in range(max_retries):
try:
response = self.client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
max_tokens=8192,
extra_headers=extra_headers,
timeout=120
)
return response.choices[0].message.content
except openai.RateLimitError:
wait = 2 ** attempt
print(f"Превышен лимит запросов, ожидание {wait}с...")
time.sleep(wait)
except openai.APIError as e:
print(f"Ошибка API: {e}")
if attempt == max_retries - 1:
raise
time.sleep(1)
raise RuntimeError("Максимальное количество попыток превышено")
def compare_versions(self, prompt: str) -> dict:
"""Одновременный вызов 4.6 и 4.7 для сравнения"""
results = {}
for model in ["claude-opus-4-6", "claude-opus-4-7"]:
start = time.time()
results[model] = {
"output": self.generate(prompt, model=model),
"latency": time.time() - start
}
return results
if __name__ == "__main__":
client = ClaudeOpusClient(api_key="YOUR_API_KEY")
result = client.generate(
prompt="Отрефактори этот код на Python, добавив поддержку асинхронности",
effort="xhigh",
task_budget=50000
)
print(result)
🚀 Быстрый старт:
base_urlв коде выше указывает на платформу APIYI (apiyi.com). Она предоставляет интерфейс, полностью совместимый с официальным API Claude, и поддерживает параллельный вызов моделей Claude Opus 4.7 и 4.6, что очень удобно для A/B тестирования при миграции.
Чек-лист для миграции
Что нужно сделать при переходе с Opus 4.6 на 4.7:
# 1. Перепроверьте лимиты max_tokens (изменения в токенизаторе)
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
# Вызовите оба метода для одного промпта, чтобы замерить реальный расход токенов
for model in ["claude-opus-4-6", "claude-opus-4-7"]:
resp = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": YOUR_PROMPT}],
max_tokens=4096
)
print(f"{model}: вход={resp.usage.prompt_tokens}, выход={resp.usage.completion_tokens}")
# 2. Протестируйте работу с длинными документами (спад MRCR)
# Рекомендуется оставить задачи с длинными документами на модели 4.6 или использовать фрагментирование через RAG
# 3. Проверьте скрытые намерения в промптах
# 4.7 работает строго буквально, поэтому «чтение мыслей» лучше заменить на четкие ограничения
Часто задаваемые вопросы (FAQ) по Claude Opus 4.7
Q1: Действительно ли Claude Opus 4.7 лучше, чем 4.6?
Зависит от задачи:
- Короткие и средние задачи по написанию кода: 4.7 заметно лучше (SWE-bench Verified +6.8 п.п., CursorBench +12 п.п.)
- Работа с изображениями высокого разрешения: 4.7 намного опережает 4.6 (визуальные бенчмарки выросли с 54.5% до 98.5%)
- Агентные цепочки инструментов: 4.7 сильнее (MCP-Atlas +13 п.п.)
- Поиск по длинному контексту: 4.6 значительно лучше (MRCR 78.3% против 32.2%)
- Чувствительность к стоимости: 4.6 выгоднее (в 4.7 расход токенов может увеличиться до 35%)
Если вам нужно использовать обе версии в разных сценариях, рекомендуем платформу APIYI (apiyi.com). Она позволяет маршрутизировать запросы и использовать один API-ключ для всех моделей Claude.
Q2: Почему некоторые говорят, что Claude Opus 4.7 хуже 4.6?
Основные причины:
- Рефакторинг токенизатора: Расход токенов на одну и ту же задачу вырос до 35%, при этом прирост возможностей не всегда оправдывает такие затраты.
- Провал MRCR на длинном контексте: Падение с 78.3% до 32.2% — серьезный регресс в работе с длинными документами.
- Чрезмерное следование инструкциям: Промпты эпохи 4.6, основанные на "понимании намерений", часто не срабатывают в 4.7.
- Ошибки в Claude Code: Разработчики жалуются на ложные срабатывания, когда обычный код помечается как вредоносный.
Это не иллюзия, а реальные изменения в работе модели.
Q3: Как безопасно мигрировать с Opus 4.6 на 4.7?
Трехэтапный подход:
- Параллельное нагрузочное тестирование: Запускайте 4.6 и 4.7 на 5–10% производственного трафика, сравнивая качество вывода, задержки и стоимость.
- Маршрутизация по сценариям: Оставьте длинные документы и большие кодовые базы на 4.6, а кодинг и визуальные задачи переведите на 4.7.
- Постепенное масштабирование: Увеличивайте долю трафика (10% → 30% → 50% → 100%), наблюдая за результатами в течение 3–7 дней.
Используйте для этого платформу APIYI (apiyi.com) — она поддерживает гибкую маршрутизацию моделей и распределение трафика.
Q4: Когда использовать режим xhigh в Claude Opus 4.7?
Anthropic рекомендует по умолчанию использовать xhigh для задач по написанию кода и агентных операций:
- Сложный рефакторинг кода.
- Отладка багов в проектах из множества файлов.
- Генерация масштабных юнит-тестов.
- Агентные цепочки из множества шагов.
Не рекомендуется:
- Для простых вопросов (хватит и medium).
- При высокой нагрузке (xhigh имеет большую задержку).
- Если бюджет строго ограничен (xhigh ощутимо увеличивает количество выходных токенов).
Q5: Как использовать Task Budgets и зачем они нужны?
Task Budgets — это функция, доступная через HTTP-заголовок:
task-budget-tokens: 50000
Когда это полезно:
- Долгие агентные циклы (контроль общих затрат).
- SaaS с несколькими арендаторами (ограничение бюджета для каждого пользователя).
- Автоматизация CI/CD (ограничение лимита токенов на каждую задачу).
Модель автоматически регулирует глубину своих рассуждений в зависимости от остатка бюджета, стараясь корректно завершить работу до того, как лимит будет исчерпан.
Q6: Действительно ли визуальные возможности Claude Opus 4.7 так хороши?
Да, это одно из самых заметных обновлений в 4.7:
- Максимальное разрешение: выросло с 1.15 Мп до 3.75 Мп (в 3 раза).
- Визуальные бенчмарки: скачок с 54.5% до 98.5%.
- Практическая польза: модель способна читать 4K-скриншоты, архитектурные схемы, макеты интерфейсов и сканы PDF.
Для команд, занимающихся фронтенд-разработкой, версткой по макетам или цифровизацией документов, это обновление может кардинально изменить рабочий процесс.
Кому подойдет Claude Opus 4.7? Рекомендации по выбору
Основываясь на всестороннем анализе, мы подготовили четкие рекомендации по использованию:
Сценарии для немедленного перехода на Claude Opus 4.7
- ✅ Написание и рефакторинг кода (средние и короткие файлы): данные SWE-bench и CursorBench говорят сами за себя.
- ✅ Сложные агентские рабочие процессы: двойное преимущество благодаря MCP-Atlas и Task Budgets.
- ✅ Обработка изображений высокого разрешения: визуальные возможности в 3,75 Мп — это качественный скачок.
- ✅ Быстрая разработка прототипов: режим xhigh отлично справляется с задачами средней сложности.
Сценарии, где стоит остаться на Claude Opus 4.6
- 🔒 Саммари и ответы по длинным документам: просадка MRCR неизбежна.
- 🔒 Анализ кода на уровне крупных репозиториев: стабильность извлечения данных из длинного контекста выше.
- 🔒 Критическая чувствительность к стоимости токенов: токенизатор 4.6 более экономичен.
- 🔒 Стабильные рабочие процессы: не рекомендуем гнаться за новинками, если это создает риск регрессии.
Рекомендуемая стратегия гибридного использования
Для большинства команд маршрутизация по сценариям будет эффективнее, чем «полный переход»:
- Задачи с длинными документами → Opus 4.6
- Программирование/визуальные задачи/агенты → Opus 4.7
- Управляйте обеими версиями через единый шлюз, чтобы снизить риски при миграции.
💡 Итоговый совет: выбор между Claude Opus 4.7 и 4.6 зависит от ваших конкретных задач. Мы рекомендуем провести практическое тестирование через платформу APIYI (apiyi.com). Платформа поддерживает унифицированный интерфейс для вызова различных моделей, что позволяет быстро сравнивать их и переключаться между ними, сохраняя гибкость вашего бизнеса.
Резюме
Claude Opus 4.7 — это типичное «обновление с компромиссами»: модель совершила настоящий прорыв в программировании, визуальных задачах и агентских способностях, но заплатила за это снижением качества извлечения данных из длинного контекста, эффективностью токенов и совместимостью промптов.
Обсуждения в сообществе в день релиза возникли не на пустом месте — Opus 4.7 это и мощная новая модель, и архитектурная перестройка, требующая определенных жертв. Для разработчиков вопрос не в том, «переходить или нет», а в том, «в каких сценариях переходить».
- Если вы занимаетесь сложными задачами по программированию или анализом изображений высокого разрешения, 4.7 — лучший выбор на второй квартал 2026 года.
- Если ваш основной бизнес связан с обработкой длинных документов или вы чувствительны к стоимости вывода, пока оставьте 4.6.
- В процессе миграции настоятельно рекомендуем проводить параллельное нагрузочное тестирование, чтобы избежать скрытых регрессий, вызванных «резким переходом».
Рекомендуем быстро протестировать Claude Opus 4.7 и 4.6 через платформу APIYI (apiyi.com). Платформа предоставляет унифицированный API, мониторинг расходов в реальном времени и возможности маршрутизации между моделями — это идеальное решение для тестирования миграции и внедрения в продакшн.
Справочные материалы
-
Официальный анонс Anthropic: Представление Claude Opus 4.7
- Ссылка:
anthropic.com/news/claude-opus-4-7 - Описание: Официальная информация о ключевых возможностях и ценообразовании.
- Ссылка:
-
Официальная документация Claude API: Руководство по миграции на Claude Opus 4.7
- Ссылка:
platform.claude.com/docs/en/about-claude/models/migration-guide - Описание: Официальные рекомендации по миграции и информация об изменениях в токенизаторе.
- Ссылка:
-
Блог AWS Bedrock: Запуск Claude Opus 4.7 в Amazon Bedrock
- Ссылка:
aws.amazon.com/blogs/aws/introducing-anthropics-claude-opus-4-7-model-in-amazon-bedrock - Описание: Инструкции по развертыванию на сторонних облачных платформах.
- Ссылка:
-
Бенчмарк-анализ Vellum AI: Глубокий разбор тестов Claude Opus 4.7
- Ссылка:
vellum.ai/blog/claude-opus-4-7-benchmarks-explained - Описание: Независимая оценка производительности модели.
- Ссылка:
-
GitHub Issue #47483: Отзывы сообщества о Claude Opus
- Ссылка:
github.com/anthropics/claude-code/issues/47483 - Описание: Первые впечатления и обратная связь от разработчиков.
- Ссылка:
Автор: Техническая команда APIYI
Дата публикации: 17.04.2026
Применимые модели: Claude Opus 4.7 / Claude Opus 4.6
Техническое сообщество: Приглашаем вас получить тестовые лимиты через APIYI (apiyi.com), чтобы самостоятельно сравнить различия между версиями Claude.