У знаний любой большой языковой модели есть «дата отсечки», а реальные бизнес-задачи требуют данных «здесь и сейчас». В 2025 году компания Anthropic официально представила нативный инструмент web_search, а в 2026 году обновила его до версии web_search_20260209 с поддержкой динамической фильтрации. Теперь подключение Claude API к интернету превратилось из «танцев с бубном» при самосборке в добавление одной строки параметров.
В этой статье мы систематизируем актуальные способы реализации поиска в интернете через Claude API в 2026 году. Разберем параметры, тарификацию, ограничения и шаблоны кода для официальных инструментов web_search / web_fetch, а также сравним их с использованием сторонних MCP и самописных RAG-систем. В конце статьи вы найдете пример интеграции через сервис-прокси APIYI (apiyi.com) — достаточно заменить base_url и api_key, чтобы запустить процесс в РФ без лишних сложностей.
Ключевые аспекты поиска в интернете через Claude API
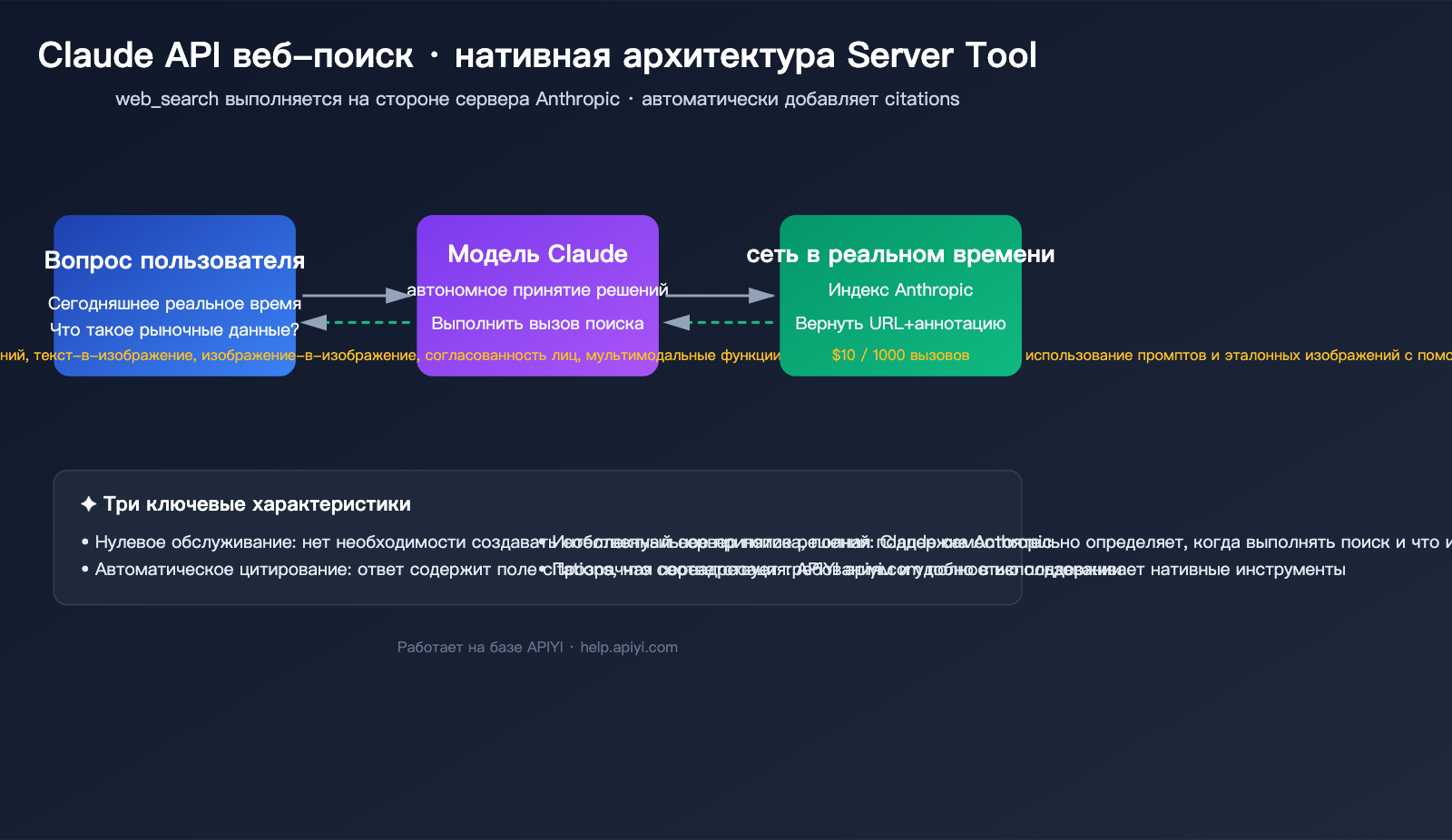
Прежде чем переходить к коду, давайте разберемся с основами. Поиск в интернете через Claude API — это, по сути, серверный инструмент (Server Tool), предоставляемый Anthropic. Это означает, что поиск выполняется на стороне облака Anthropic: вам не нужно подключать API Google или Bing и не нужно разворачивать собственные парсеры.
Краткий обзор трех основных подходов
| Подход | Сложность интеграции | Стоимость | Актуальность | Ссылки и комплаенс |
|---|---|---|---|---|
Официальный web_search |
★☆☆ (одно поле tool) | $10 / 1000 запросов + токены | Высокая (индексы Anthropic) | Автоматические ссылки |
| Сторонний MCP (напр. Brave/Tavily) | ★★☆ (нужен MCP server) | Тарифы стороннего API | Средняя-высокая | Нужно настраивать самому |
| Свой (Google CSE + вызов инструментов) | ★★★ (свой tool + парсинг) | Квоты Google API | Средняя | Полный контроль |
🎯 Совет по выбору: Если ваша цель — «научить Claude отвечать на свежие события и дополнять ответы актуальными данными», официальный
web_search— лучшее решение на сегодня. Никакого обслуживания, автоматические ссылки и поддержка топовых моделей, таких как Sonnet 4.6 / Opus 4.7. Мы рекомендуем подключаться через сервис-прокси APIYI (apiyi.com), чтобы использовать все возможности официальных интерфейсов Anthropic без необходимости в VPN.
Матрица моделей с поддержкой поиска
Не все модели Claude поддерживают web_search. Новая версия web_search_20260209 предъявляет четкие требования к моделям:
| Модель | Базовая версия web_search_20250305 |
Версия с динамической фильтрацией web_search_20260209 |
|---|---|---|
| Claude Opus 4.7 | ✅ | ✅ |
| Claude Opus 4.6 | ✅ | ✅ |
| Claude Sonnet 4.6 | ✅ | ✅ |
| Claude Sonnet 4.5 | ✅ | ❌ |
| Claude Haiku 4.5 | ✅ | ❌ |
Динамическая фильтрация (Dynamic Filtering) — это главное обновление 2026 года: перед тем как результаты поиска попадут в контекстное окно, Claude использует инструмент выполнения кода, чтобы отфильтровать их и оставить только релевантные фрагменты. Это значительно экономит токены при поиске по длинным документам или обзорам технических статей.
Подробный разбор официальных инструментов для веб-поиска в Claude API
Anthropic предоставляет два взаимодополняющих нативных инструмента. Понимание границ их возможностей — залог эффективного использования веб-поиска в Claude API.
Разделение задач: web_search и web_fetch
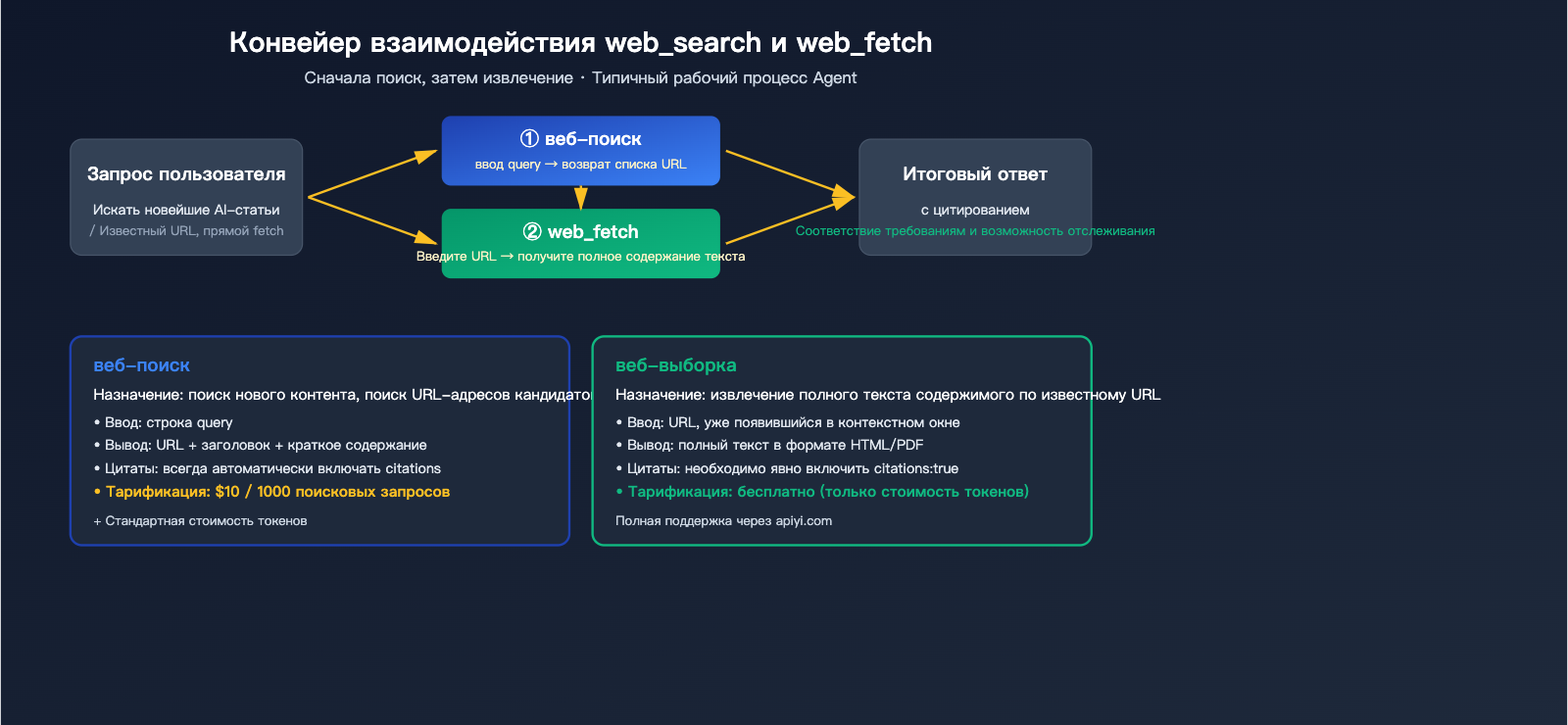
| Инструмент | Назначение | Входные данные | Выходные данные | Тарификация |
|---|---|---|---|---|
web_search |
Поиск новой информации | Строка запроса | URL + заголовок + аннотация | $10 / 1000 запросов |
web_fetch |
Извлечение текста страницы | Строка URL | Полный текст HTML/PDF | Бесплатно (оплата только за токены) |
🎯 Совет по архитектуре: Типичный рабочий процесс агента выглядит так: «сначала search, затем fetch» —
web_searchнаходит подходящие страницы, аweb_fetchвытягивает полный текст из наиболее релевантных. Если пользователь уже предоставил URL (например, «проанализируй статью example.com/article»), используйте сразуweb_fetch, чтобы не тратить лимиты на поиск. В APIYI (apiyi.com) оба инструмента поддерживаются «из коробки», дополнительная настройка не требуется.
Полное описание параметров инструмента web_search
В таблице ниже приведены официальные параметры JSON. Используйте их в зависимости от ваших задач:
| Параметр | Тип | Обязательный | По умолчанию | Описание |
|---|---|---|---|---|
type |
string | ✅ | — | Фиксированное значение: web_search_20250305 или web_search_20260209 |
name |
string | ✅ | — | Фиксированное значение: web_search |
max_uses |
integer | ❌ | Без ограничений | Максимальное количество поисков за один запрос |
allowed_domains |
string[] | ❌ | — | Разрешенные домены (взаимоисключающий с blocked) |
blocked_domains |
string[] | ❌ | — | Запрещенные домены |
user_location |
object | ❌ | — | Геолокация пользователя для локализации поиска |
Структура объекта user_location:
{
"type": "approximate",
"city": "Shanghai",
"region": "Shanghai",
"country": "CN",
"timezone": "Asia/Shanghai"
}
Обработка ошибок при веб-поиске в Claude API
При сбое поиска API Anthropic по-прежнему возвращает HTTP 200, а информация об ошибке встраивается в тело ответа в поле web_search_tool_result. Обязательно обрабатывайте эти коды в коде вашего клиента:
| Код ошибки | Значение | Рекомендация |
|---|---|---|
too_many_requests |
Превышен лимит запросов | Сделайте паузу и повторите, уменьшите параллелизм |
max_uses_exceeded |
Превышен лимит max_uses |
Увеличьте лимит или разбейте запрос |
query_too_long |
Запрос слишком длинный | Сократите или перепишите поисковый запрос |
invalid_input |
Ошибка формата параметров | Проверьте структуру JSON |
unavailable |
Внутренняя ошибка Anthropic | Повторите попытку через короткое время |
⚠️ Важно о тарификации: Ошибочные запросы
web_searchне тарифицируются. Однако, если вы уже совершили успешный поиск, а последующий вызов завершился ошибкой, предыдущий успешный вызов будет списан по тарифу $10 / 1000 запросов. Рекомендуем проверять детализацию расходов в личном кабинете APIYI (apiyi.com) для отслеживания аномалий.
Быстрый старт: Claude API с поиском в интернете
Давайте запустим полный цикл работы с минимумом кода. Все примеры используют прозрачный прокси-сервис APIYI (apiyi.com) — вам не нужно менять бизнес-логику, достаточно просто указать base_url на узел прокси и заменить ANTHROPIC_API_KEY на ключ от APIYI.
Минимальный пример cURL
Минимально рабочий запрос к Claude API с поиском в интернете:
curl https://vip.apiyi.com/v1/messages \
-H "x-api-key: $APIYI_API_KEY" \
-H "anthropic-version: 2023-06-01" \
-H "content-type: application/json" \
-d '{
"model": "claude-sonnet-4-6",
"max_tokens": 1024,
"messages": [
{"role": "user", "content": "Перечисли на китайском языке последние модели, выпущенные OpenAI в апреле 2026 года"}
],
"tools": [{
"type": "web_search_20250305",
"name": "web_search",
"max_uses": 5
}]
}'
Структура ответа будет содержать три блока: текст решения Claude, server_tool_use (фактический поисковый запрос), web_search_tool_result (список URL) и итоговый текст ответа с citations (ссылками на источники).
Полный пример Python SDK (с использованием web_fetch)
import anthropic
client = anthropic.Anthropic(
base_url="https://vip.apiyi.com",
api_key="sk-your-apiyi-key",
)
response = client.messages.create(
model="claude-opus-4-7",
max_tokens=4096,
messages=[{
"role": "user",
"content": "Найди статьи об оценке AI Agent за последний месяц и сделай подробное резюме самой актуальной из них"
}],
tools=[
{
"type": "web_search_20260209",
"name": "web_search"
},
{
"type": "web_fetch_20260209",
"name": "web_fetch",
"max_uses": 3,
"citations": {"enabled": True}
}
]
)
for block in response.content:
if block.type == "text":
print(block.text)
elif block.type == "server_tool_use":
print(f"[Вызов инструмента] {block.name}: {block.input}")
🎯 Совет по коду: Выше использована динамическая комбинация
web_search_20260209+web_fetch_20260209. В связке с Claude Opus 4.7 это позволяет значительно снизить расход токенов при работе с длинными документами. Если вам нужен простой ответ в реальном времени, замените модель наclaude-sonnet-4-6и используйте базовую версиюweb_search_20250305— это будет дешевле. Все вызовы проходят через APIYI (apiyi.com), стабильность такая же, как у оригинала.
Пример на TypeScript / Node.js
import Anthropic from "@anthropic-ai/sdk";
const client = new Anthropic({
baseURL: "https://vip.apiyi.com",
apiKey: process.env.APIYI_API_KEY,
});
const response = await client.messages.create({
model: "claude-sonnet-4-6",
max_tokens: 2048,
messages: [
{ role: "user", content: "Какая сегодня погода в Шанхае?" }
],
tools: [{
type: "web_search_20250305",
name: "web_search",
max_uses: 3,
user_location: {
type: "approximate",
city: "Shanghai",
region: "Shanghai",
country: "CN",
timezone: "Asia/Shanghai"
}
}]
});
console.log(response.content);
Обработка потокового ответа (Streaming)
При включении stream: true процесс поиска будет передаваться в реальном времени через SSE-события. Во время выполнения поиска возникнет небольшая «пауза» — это нормально, так как Claude ожидает завершения поиска на стороне сервера Anthropic:
with client.messages.stream(
model="claude-sonnet-4-6",
max_tokens=2048,
messages=[{"role": "user", "content": "Узнай актуальные цены на Claude 4.7"}],
tools=[{"type": "web_search_20250305", "name": "web_search", "max_uses": 2}]
) as stream:
for event in stream:
if event.type == "content_block_start":
block = event.content_block
if block.type == "server_tool_use":
print(f"\n[Поиск] Запрос отправлен, ожидаем результат...")
elif block.type == "web_search_tool_result":
print(f"[Поиск завершен] Найдено результатов: {len(block.content)}")
elif event.type == "content_block_delta":
if hasattr(event.delta, "text"):
print(event.delta.text, end="", flush=True)
Сравнение подходов к поиску в интернете через Claude API
Разобравшись с официальным интерфейсом, вернемся к выбору архитектуры. Существует три пути реализации поиска в интернете для Claude API, каждый из которых подходит для своих задач.
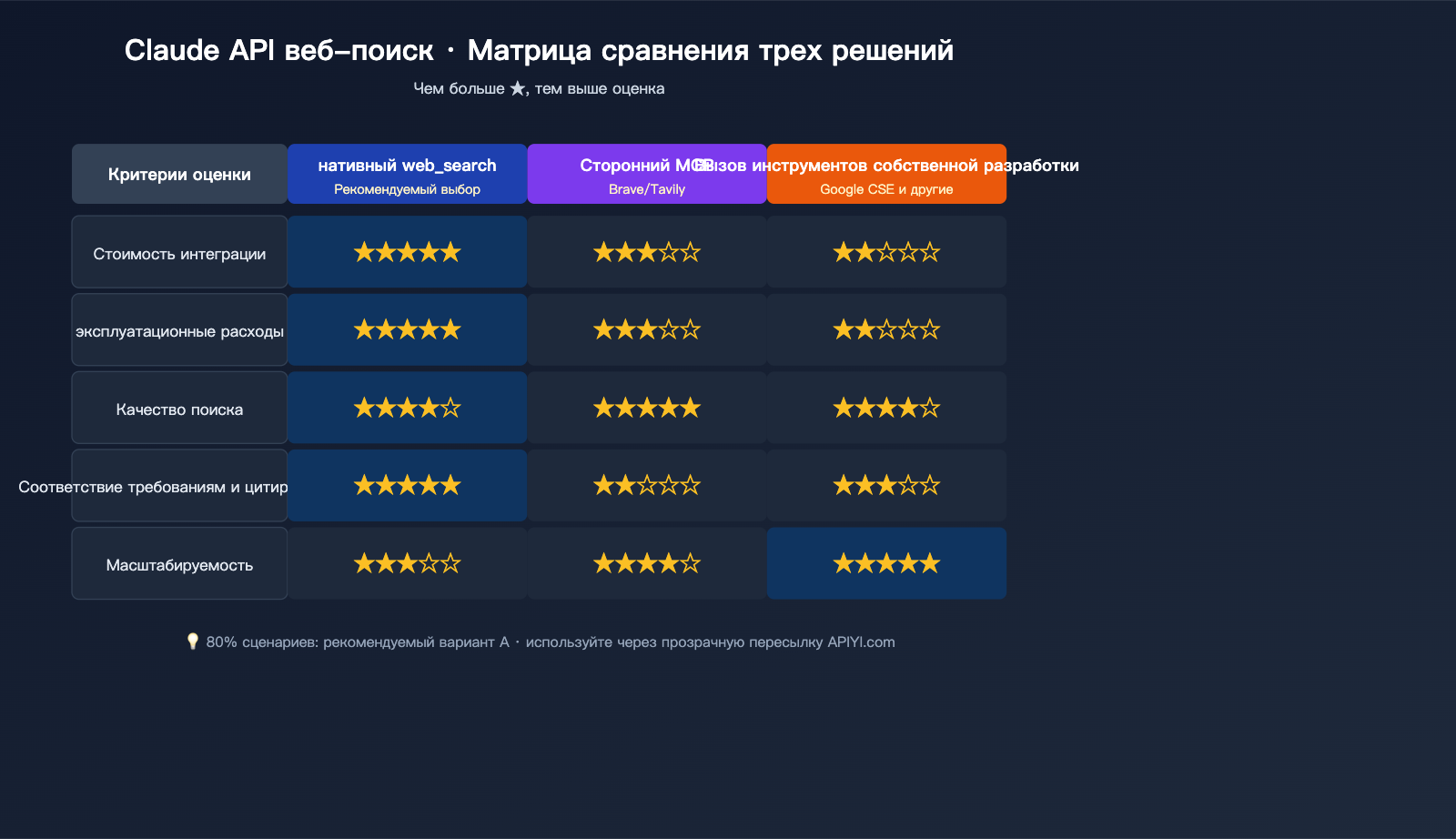
Вариант А: Официальный нативный web_search (рекомендуемый выбор)
Преимущества:
- Нулевое обслуживание: не нужно строить свой сервер, всё на стороне Anthropic.
- Автоматические ссылки: каждый ответ содержит
citations, что удобно для проверки фактов. - Интеграция с моделью: Claude сам решает, когда и что искать.
- Прозрачная тарификация: $10 за 1000 запросов, включено в общий счет Anthropic.
Недостатки:
- Поддерживаются только источники, проиндексированные Anthropic (нельзя сменить поисковик).
- Ограничения по версиям моделей (Haiku/старые версии Sonnet поддерживают только базовый поиск).
Сценарии: 90% универсальных диалоговых агентов, помощники, исследовательские задачи.
Вариант B: Сторонние MCP-сервисы (Brave/Tavily/Serper и др.)
Через Model Context Protocol можно запустить локальный или удаленный MCP-сервер и внедрить возможности поиска в Claude:
# Пример для Tavily MCP, сначала нужно выполнить npm install -g @tavily/mcp-server
claude mcp add tavily-search npx -- @tavily/mcp-server
Преимущества:
- Свобода выбора поискового бэкенда (Brave для приватности, Tavily для LLM-дружелюбности).
- Кастомизация: можно очищать результаты или добавлять метаданные.
- Нативная поддержка в клиентах типа Claude Code, Cursor.
Недостатки:
- Нужно поддерживать процесс MCP-сервера.
- Результаты поиска не генерируют автоматически
citationsпо стандарту Anthropic. - Нужно самостоятельно управлять лимитами и оплатой сторонних API.
Сценарии: Если у вас уже есть корпоративный аккаунт Brave/Tavily или требуются специфические настройки поиска.
Вариант C: Собственный вызов инструментов (Google CSE + Custom Tool)
Классический подход — вы сами определяете tool, вызываете Google Custom Search / Bing API в коде бэкенда и вставляете результаты обратно в messages:
tools = [{
"name": "google_search",
"description": "Поиск в Google и возврат топ-N результатов",
"input_schema": {
"type": "object",
"properties": {
"query": {"type": "string"}
},
"required": ["query"]
}
}]
Преимущества: Полный контроль, возможность подключения к корпоративной сети или закрытым базам знаний.
Недостатки: Вы берете на себя проектирование промптов, ранжирование результатов, генерацию ссылок и обработку ошибок. Claude не будет вызывать поиск «автоматически» — нужно явно направлять его через системный промпт.
Сценарии: Корпоративные задачи с высокими требованиями к комплаенсу, кастомизации и работе с приватными данными.
Дерево принятия решений
| Ваша потребность | Рекомендуемый вариант |
|---|---|
| Хочу быстро запустить, без особых требований | Вариант А (нативный web_search) |
| Нужно сменить поисковый бэкенд (приватность/комплаенс) | Вариант B (сторонний MCP) |
| Нужно работать с приватными данными | Вариант C (свой инструмент + RAG) |
| Нестабильный доступ к Anthropic из РФ | Вариант A + прокси APIYI (apiyi.com) |
🎯 Особое примечание для разработчиков из РФ: Официальный API Anthropic может работать нестабильно, к тому же требуется зарубежный номер для регистрации. Мы рекомендуем использовать прозрачный прокси-сервис APIYI (apiyi.com) — он полностью передает все Server Tool от Anthropic (включая
web_search/web_fetch/code_execution). Ваш код не требует изменений, просто заменитеbase_urlнаhttps://vip.apiyi.com, аapi_keyна ключ от APIYI.
Продвинутое использование веб-поиска в Claude API
Белый список доменов: «вертикальный поиск»
Хотите, чтобы Claude искал информацию только на определенных ресурсах? Используйте allowed_domains:
tools=[{
"type": "web_search_20250305",
"name": "web_search",
"max_uses": 5,
"allowed_domains": [
"docs.python.org",
"pypi.org",
"github.com"
]
}]
Несколько важных нюансов:
allowed_domainsиblocked_domainsне могут использоваться одновременно.- Поддомены требуют точного совпадения:
docs.example.comне будет включатьapi.example.com. - Ограничения на уровне запроса должны соответствовать настройкам организации; вы не можете расширить права, установленные администратором.
Включение цитирования для web_fetch
В web_search цитирование включено по умолчанию, а для web_fetch его нужно активировать явно:
{
"type": "web_fetch_20250910",
"name": "web_fetch",
"max_uses": 5,
"citations": {"enabled": True},
"max_content_tokens": 50000
}
Параметр max_content_tokens нужен для обрезки слишком длинных документов, чтобы не переполнить контекстное окно. Ориентировочные объемы:
| Тип контента | Размер | Прибл. токенов |
|---|---|---|
| Обычная веб-страница | 10 КБ | ~2 500 |
| Крупная документация | 100 КБ | ~25 000 |
| PDF с научными статьями | 500 КБ | ~125 000 |
Использование encrypted_content в многоходовых диалогах
Каждый результат web_search содержит поле encrypted_content. Если вы хотите, чтобы Claude ссылался на предыдущие результаты в рамках одного диалога, обязательно передавайте это поле обратно — иначе контекст цитирования будет потерян.
messages.append({
"role": "assistant",
"content": previous_response.content # Сохраняем полностью, включая encrypted_content
})
messages.append({
"role": "user",
"content": "Проанализируй подробнее вторую статью, которую мы только что нашли"
})
🎯 Совет инженера: При интеграции через фреймворки (например, LangChain или LlamaIndex) обязательно проверяйте, передает ли фреймворк все блоки ответа Claude. Многие из них «очищают» поля вроде
server_tool_use, из-за чего цитирование перестает работать. Мы рекомендуем работать напрямую через SDK Anthropic и использовать сервис-прокси API APIYI (apiyi.com) — это гарантирует полное соответствие официальному поведению API.
Практические сценарии использования веб-поиска в Claude API
Теорию разобрали, теперь перейдем к лучшим практикам для реальных бизнес-задач.
Сценарий 1: Ассистент для новостей в реальном времени
Пользователь спрашивает о ситуации на фондовом рынке — нужны актуальные данные. Стратегия настройки:
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=1024,
system="Ты финансовый ассистент. При вопросах о курсах и новостях обязательно используй web_search. Ответ должен содержать ссылки.",
messages=[{"role": "user", "content": "Какой индекс Шанхайской биржи на закрытии? Есть ли рост?"}],
tools=[{
"type": "web_search_20250305",
"name": "web_search",
"max_uses": 3,
"allowed_domains": ["sina.com.cn", "eastmoney.com", "163.com"],
"user_location": {
"type": "approximate",
"country": "CN",
"timezone": "Asia/Shanghai"
}
}]
)
Главное: используйте allowed_domains для выбора авторитетных источников и user_location, чтобы Claude отдавал приоритет результатам на нужном языке.
Сценарий 2: RAG для технической документации
Позвольте Claude искать ответы в официальных руководствах:
response = client.messages.create(
model="claude-opus-4-7",
max_tokens=4096,
messages=[{
"role": "user",
"content": "Как реализовать WebSocket heartbeat в FastAPI? Дай полный пример"
}],
tools=[
{
"type": "web_search_20260209",
"name": "web_search",
"max_uses": 5,
"allowed_domains": [
"fastapi.tiangolo.com",
"docs.python.org",
"github.com",
"stackoverflow.com"
]
},
{
"type": "web_fetch_20260209",
"name": "web_fetch",
"max_uses": 3,
"citations": {"enabled": True}
}
]
)
Главное: используйте web_search_20260209 для фильтрации мусора, а затем web_fetch для получения полного текста документации.
Сценарий 3: Ассистент для научных исследований
Для задач, требующих строгих ссылок и анализа длинного контекста, рекомендуем Opus 4.7 + связку инструментов:
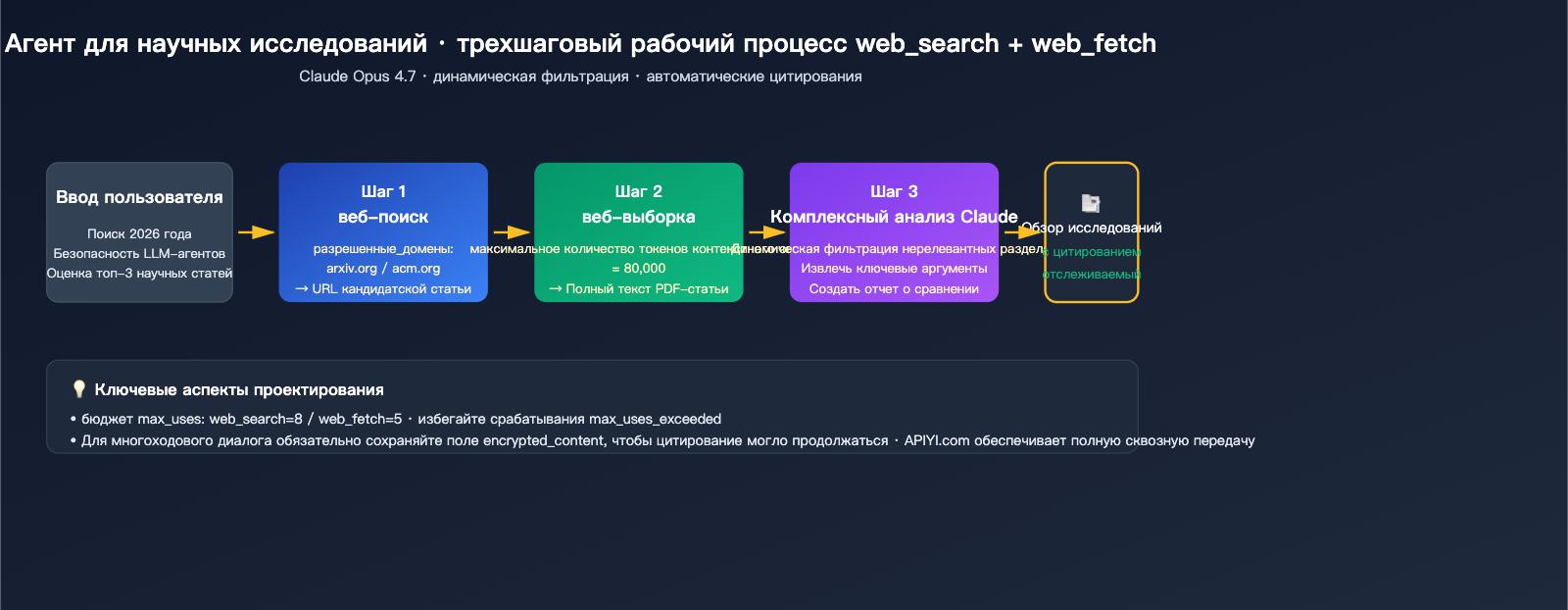
response = client.messages.create(
model="claude-opus-4-7",
max_tokens=8192,
messages=[{
"role": "user",
"content": "Найди статьи 2026 года по оценке безопасности LLM-агентов, выбери топ-3 и сравни их"
}],
tools=[
{
"type": "web_search_20260209",
"name": "web_search",
"max_uses": 8,
"allowed_domains": ["arxiv.org", "openreview.net", "acm.org"]
},
{
"type": "web_fetch_20260209",
"name": "web_fetch",
"max_uses": 5,
"citations": {"enabled": True},
"max_content_tokens": 80000
}
]
)
🎯 Рекомендация: У каждого бизнес-процесса свои требования к качеству поиска и затратам. Мы советуем создавать отдельные API-ключи для каждого сценария на платформе APIYI (apiyi.com). Это позволит удобно разделять статистику использования, мониторить количество поисковых запросов и расход токенов, вместо того чтобы смешивать все данные в одну кучу.
Инженерные практики для работы с поиском через Claude API
Запустить демо — это одно, но чтобы внедрить поиск в интернете через Claude API в продакшн, придется преодолеть несколько подводных камней.
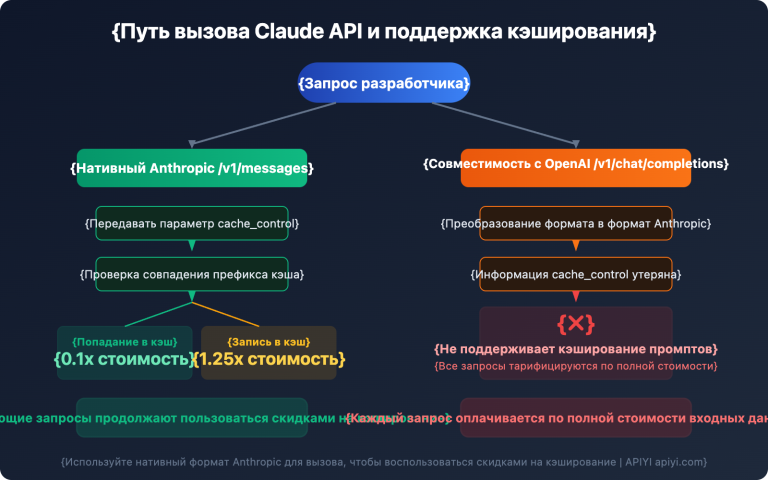
Практика 1: Оптимизация затрат через prompt caching
Определения Server Tool могут быть короткими, но в сочетании с системным промптом они создают заметные фиксированные расходы. Включите prompt caching:
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=2048,
system=[{
"type": "text",
"text": "Ты профессиональный исследовательский ассистент...(здесь пропущено 500 слов системного промпта)",
"cache_control": {"type": "ephemeral"}
}],
messages=[...],
tools=[
{
"type": "web_search_20250305",
"name": "web_search",
"max_uses": 5,
"cache_control": {"type": "ephemeral"}
}
]
)
Результаты тестов: при повторных запросах в течение 5 минут затраты на токены для системной части и инструментов снижаются на 90%.
Практика 2: Потоковые ответы для предотвращения таймаутов
Одно выполнение web_search может занимать 5–15 секунд. Если у вашего бэкенда (шлюза или клиента) есть лимит ожидания в 30 секунд, обязательно используйте stream=True, чтобы поддерживать соединение активным через потоковые «пульсы» (heartbeats).
Практика 3: Согласованность в многоходовых диалогах (encrypted_content)
В длинных диалогах Claude может ссылаться на результаты предыдущих поисков. Обязательно сохраняйте полный массив content всех предыдущих сообщений ассистента в каждом запросе, не ограничивайтесь только полем text:
# ❌ Неправильно
messages.append({"role": "assistant", "content": response.content[-1].text})
# ✅ Правильно
messages.append({"role": "assistant", "content": response.content})
Практика 4: Лимиты скорости и стратегия повторных попыток
Лимиты скорости для web_search независимы от обычного API сообщений. Рекомендую реализовать на уровне SDK логику повторов с экспоненциальной задержкой:
| Код ошибки | Стратегия повтора | Макс. попыток |
|---|---|---|
too_many_requests |
Экспоненциальная задержка (2с/4с/8с) | 3 |
unavailable |
Фиксированная задержка (5с) | 2 |
max_uses_exceeded |
Не повторять, увеличить max_uses | — |
query_too_long |
Не повторять, обрезать запрос | — |
🎯 Совет для продакшна: Логируйте все ошибки
web_searchв систему мониторинга и анализируйте долюtoo_many_requests— это ключевой показатель того, нужно ли масштабировать систему. При использовании платформы APIYI (apiyi.com) вы можете отслеживать успешность запросов и среднее время отклика прямо в консоли.
FAQ: Часто задаваемые вопросы по поиску в Claude API
Q1: Поддерживает ли сервис-прокси APIYI нативный web_search? Нужно ли менять код?
Да, поддерживает, и менять код не нужно. APIYI (apiyi.com) использует архитектуру прозрачной передачи, полностью пропуская все официальные Server Tool от Anthropic. Вам достаточно изменить base_url на https://vip.apiyi.com и заменить api_key на ключ от APIYI. Весь ваш код, работающий с официальным API, заработает без единой правки — включая web_search, web_fetch, code_execution и другие нативные инструменты.
Q2: Как тарифицируется web_search? Дорого ли $10 за 1000 запросов?
Один поиск = $0.01, независимо от количества найденных результатов. Неудачные поиски не тарифицируются. Для сравнения: Tavily — $0.005/поиск, Brave — $0.006/поиск, Google CSE — $0.005/запрос (после исчерпания бесплатного лимита). Нативный web_search чуть дороже, но он избавляет от инженерных затрат на поддержку MCP-серверов и соблюдение правил цитирования, что в итоге выгоднее для небольших команд.
Q3: Почему я получаю ошибку max_uses_exceeded?
Claude может вызывать web_search несколько раз за один диалог (он сам решает, сколько раз нужно искать). Если вы установили "max_uses": 1, а для ответа на вопрос требуется 3 поиска, возникнет эта ошибка. Для сложных вопросов рекомендую выделять бюджет в 5–10 использований, а для простых — 1–2.
Q4: Умеет ли web_search искать на китайских сайтах?
Да. В основе web_search лежит индекс Anthropic в реальном времени, который отлично покрывает китайский контент (включая WeChat, Zhihu, CSDN и т.д.). Если нужно ограничиться только китайскими сайтами, используйте белый список allowed_domains.
Q5: Поиск потребляет много токенов при анализе длинных статей, как оптимизировать?
Три направления оптимизации:
- Используйте
web_search_20260209с динамической фильтрацией (требуется Claude Opus/Sonnet 4.6+), чтобы автоматически отсекать лишние фрагменты. - Используйте параметр
max_content_tokensвweb_fetch, чтобы ограничить объем данных с одной страницы. - Включите prompt caching для кэширования определений инструментов и системных промптов.
Q6: Можно ли совмещать сторонние MCP-решения и нативный web_search?
Да. Claude может использовать несколько инструментов одновременно, но важно четко описать различия в описании инструментов — например, опишите tavily_search как «поиск научных статей», а нативный web_search как «поиск по общим веб-страницам». Claude сам выберет нужный. Однако, чтобы избежать путаницы, мы рекомендуем использовать один поисковый инструмент для одной задачи.
Q7: Что делать, если поиск через Claude API не работает из Китая?
Есть две основные причины: нестабильное соединение с API Anthropic и блокировка IP-адресов из материкового Китая на стороне Anthropic при выполнении web_search. Самое простое решение — использовать прокси APIYI (apiyi.com). Все запросы web_search будут перенаправлены через зарубежные узлы APIYI к Anthropic, а ответы вернутся обратно, обеспечивая такую же стабильность, как при прямом подключении из-за границы.
Итоги и рекомендации по выбору решений для веб-поиска через Claude API
Оглядываясь назад, можно сказать, что веб-поиск через Claude API в 2026 году стал настолько зрелым, что работает по принципу «подключил и пользуйся». Если коротко:
✅ В 80% проектов достаточно официального нативного
web_search— это простая настройка, корректные ссылки и поддержка от самой Anthropic. Оставшиеся 20% сценариев с жесткими требованиями к кастомизации стоит оставить для сторонних MCP или собственных инструментов.
Чек-лист для внедрения
Если вы планируете добавить веб-поиск в Claude API в свой проект уже сегодня:
- Выбор модели: для общих задач используйте
claude-sonnet-4-6(лучшее соотношение цены и качества), для сложных исследований —claude-opus-4-7. - Выбор версии инструмента: отдавайте предпочтение
web_search_20260209(с динамической фильтрацией), для старых моделей используйтеweb_search_20250305. - Настройка
max_uses: для простых вопросов достаточно 1–3 вызовов, для глубоких исследований — 5–10. - Использование
web_fetch: если требуется анализ полного текста, комбинируйте поиск сweb_fetchдля извлечения контента со страниц. - Настройка доступа: из РФ используйте сервис-прокси API APIYI (apiyi.com) для прозрачной передачи запросов — без VPN и правок в коде.
🎯 Финальный совет: суть веб-поиска в Claude API не в том, «работает он или нет», а в том, как найти баланс между качеством результатов поиска, стоимостью токенов и задержкой ответа. Мы рекомендуем сначала прогнать несколько реальных бизнес-кейсов через платформу APIYI (apiyi.com), оценить количество поисковых запросов и расход токенов за диалог, а затем решать, стоит ли внедрять продвинутые оптимизации вроде кэширования промптов или динамической фильтрации. Платформа поддерживает всю линейку моделей Claude и нативные серверные инструменты, что идеально подходит для быстрой итерации.
Автор: Техническая команда APIYI | Больше практических руководств по Claude API на help.apiyi.com