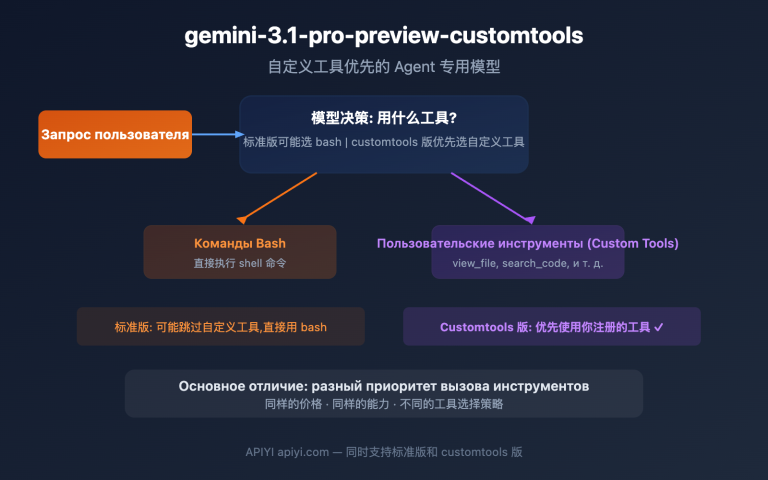
Многие команды, интегрирующие Gemini API для задач компьютерного зрения, сталкиваются с одним и тем же недоумением: при отправке одного и того же изображения и промпта в веб-версию gemini.google.com модель точно распознает детали и выдает структурированный ответ. Однако при переходе на API gemini-3.5-flash результат оказывается заметно хуже, а иногда и вовсе пропускает ключевую информацию. Эта разница в ощущениях «веб-версия мощная, а API слабый» вовсе не означает, что саму модель «урезали». Просто вы увидели разрыв в инженерной реализации между веб-интерфейсом и API.
Эта статья раскрывает один ключевой вывод: веб-версия Gemini — это комплексный агент, который автоматически выполняет оптимизацию промптов, многошаговое рассуждение, вызов инструментов и проверку результатов. Вызов через API — это работа с «голой» моделью, где вы получаете ровно то, что отправили. Поняв эту разницу, вы сможете освоить 6 приемов повышения эффективности API, которые позволят добиться стабильного качества распознавания, не уступающего официальному сайту.

Почему Gemini API уступает веб-версии: разрыв между агентом и «голой» моделью
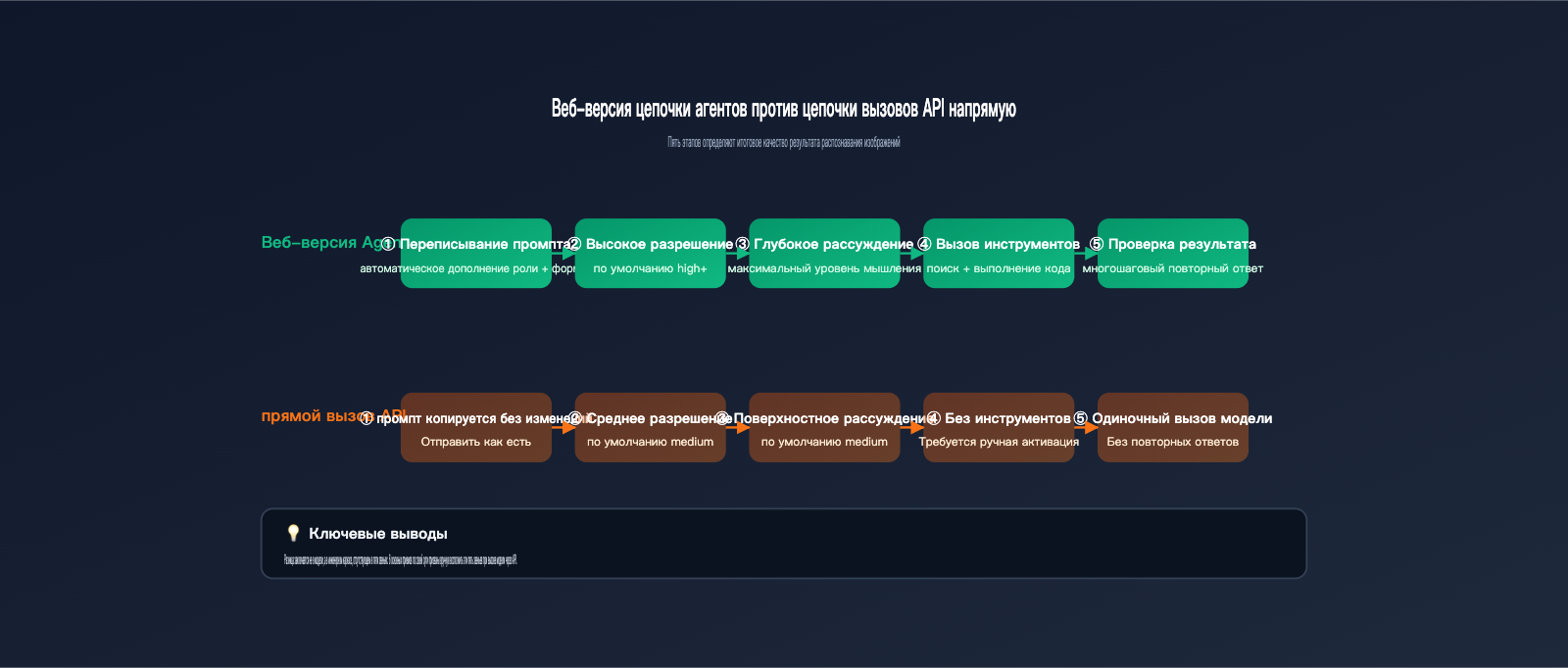
Чтобы прояснить эту разницу, нужно сначала понять, сколько всего делает gemini.google.com с момента загрузки вами изображения до получения ответа. Исходя из документации Google по агентному зрению и наших наблюдений на APIYI (apiyi.com) за разницей в откликах сайта и API, веб-версия по сути является продуктовым агентом, построенным вокруг базовой модели. Она как минимум выполняет 5 вещей, о которых вы не просили явно:
- Автоматически переписывает ваш промпт, дополняя его ролью, задачей и форматом вывода.
- Внутри системы обрабатывает изображения в более высоком разрешении, чтобы детали не превращались в «мыло».
- По умолчанию включает высокий бюджет на рассуждения (аналог
thinking_level=high), давая модели время «подумать». - При необходимости вызывает встроенные инструменты, такие как выполнение кода или поиск в интернете, для перекрестной проверки фактов.
- Форматирует результат и принимает решение о «перезапуске» ответа, если модель выдала что-то невнятное.
Когда вы вызываете API напрямую, ничего из этого не происходит автоматически. Иными словами, вы используете полноценную «модель», но лишаетесь целого «инженерного каркаса». В таблице ниже четко видны различия между двумя способами использования:
| Параметр сравнения | Веб-версия gemini.google.com | API gemini-3.5-flash |
|---|---|---|
| Обработка промпта | Автоматическая правка, дополнение роли и формата | Полное соответствие вводу пользователя |
| Разрешение изображений | Высокое по умолчанию | Среднее по умолчанию (нужно настраивать) |
| Бюджет рассуждений | Высокий, без явных ограничений | Средний, настраивается через thinking_level |
| Вызов инструментов | Включены (поиск, код) | Выключены по умолчанию |
| Проверка результата | Многошаговая проверка агентом | Однократный вывод, без проверки |
| Прозрачность оплаты | Включено в подписку | Потокеновая оплата (за токен) |
Мы рекомендуем использовать такие шлюзы, как APIYI (apiyi.com), чтобы одновременно прогонять одно и то же изображение и промпт через API gemini-3.5-flash, Claude Opus и GPT-5.5. Это позволит быстро понять, упирается ли задача в возможности модели или в инженерную цепочку.
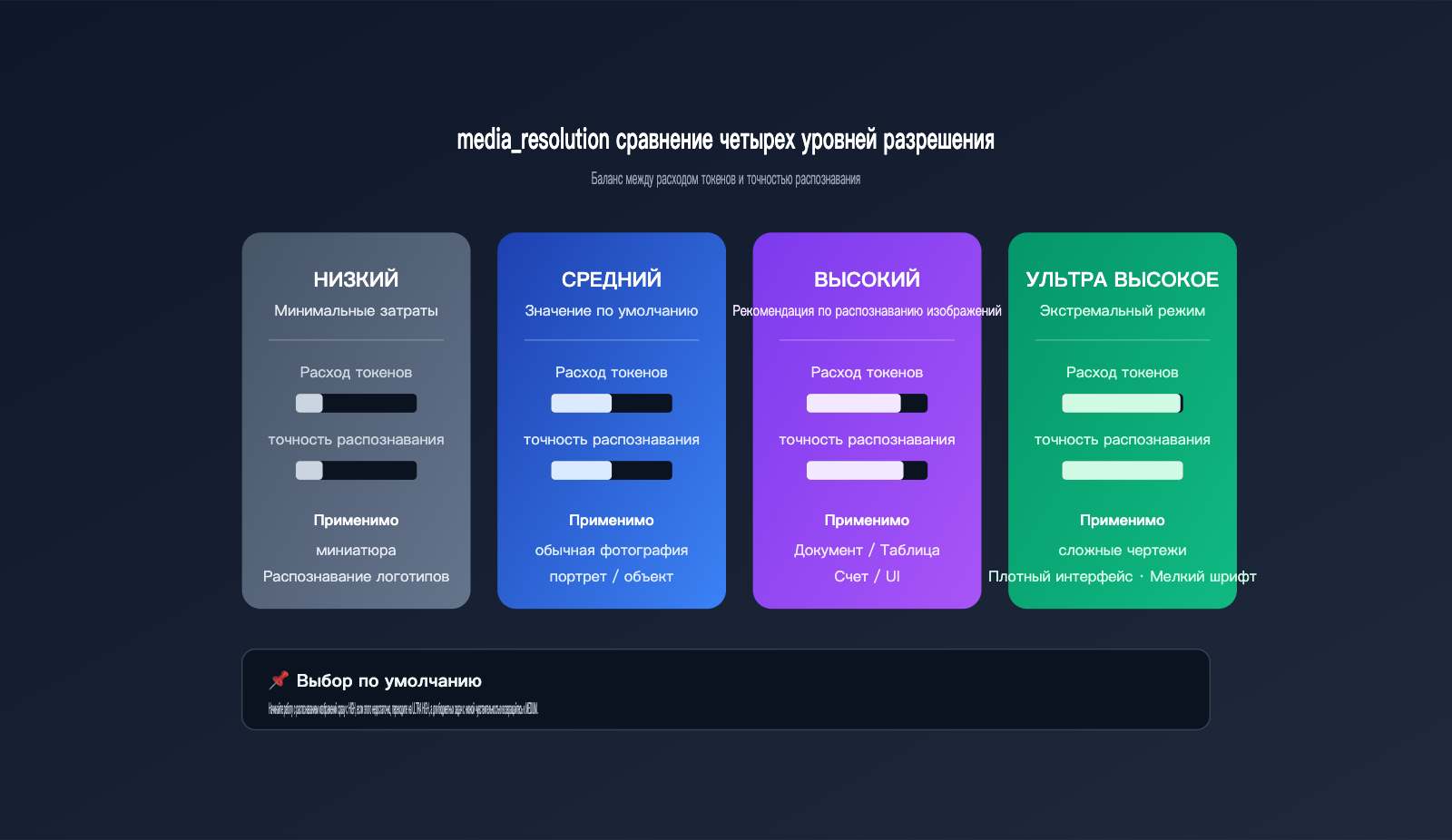
Лайфхак №1 для Gemini API: повышаем параметр media_resolution
Начиная с 3-й серии, в Gemini появился параметр media_resolution, который напрямую определяет, сколько токенов API выделит на «рассматривание» изображения. У него есть четыре уровня: low, medium, high и ultra high, причем по умолчанию обычно стоит medium. Если вам нужно распознать мелкий текст, чеки, принципиальные схемы или скриншоты интерфейсов с кучей деталей, medium часто не хватает: модель сжимает картинку в грубую карту признаков, из-за чего детали теряются.
В таблице ниже показаны различия между уровнями, чтобы вы могли выбрать подходящий под свою задачу:
| Уровень разрешения | Расход токенов | Сценарии использования | Типичные проблемы |
|---|---|---|---|
| low | Минимальный | Миниатюры, логотипы | Мелкий текст почти не виден |
| medium (по умолч.) | Средний | Обычные фото, портреты | Детали размыты |
| high | Высокий | Документы, таблицы, чеки | Информация в основном читаема |
| ultra high | Максимальный | Сложные чертежи, плотный UI | Близко к качеству веб-версии |
Для задач распознавания изображений перевод параметра с medium на high обычно сразу повышает точность на порядок. Если бюджет позволяет, а задача действительно включает мелкий текст или плотные таблицы, смело ставьте ultra high.
# Вызов gemini-3.5-flash через APIYI с явным указанием высокого разрешения
from google import genai
from google.genai import types
client = genai.Client(
api_key="YOUR_APIYI_KEY",
http_options={"base_url": "https://api.apiyi.com"}
)
resp = client.models.generate_content(
model="gemini-3.5-flash",
contents=[image_part, "Извлеки весь видимый текст и представь его в виде таблицы"],
config=types.GenerateContentConfig(
media_resolution="MEDIA_RESOLUTION_HIGH"
)
)
print(resp.text)
При использовании сервиса-прокси APIYI (apiyi.com) параметры передаются напрямую в API без лишних оберток, так что можете смело использовать значения из официальной документации.
Лайфхак №2 для Gemini API: принудительно включаем thinking_level=high
В Gemini 3.5 Flash появился параметр thinking_level, который управляет глубиной внутренних рассуждений модели перед выдачей ответа. В задачах распознавания «думать дольше» и «думать внимательнее» — это часто решающий фактор между правильным ответом и ошибкой. По умолчанию API настроен на скорость, а не на качество, поэтому для распознавания рекомендуем ставить high. Это позволит модели тратить больше времени на пространственные рассуждения и подсчет объектов, как в веб-интерфейсе.
| thinking_level | Рекомендуемые сценарии | Ощутимая разница |
|---|---|---|
| low | Простые диалоги, определение стиля | Быстро, но грубо |
| medium | Обычные вопросы и ответы | Средний уровень |
| high (рекомендуется) | Документы, чеки, подсчет, логика | Близко к веб-версии |
Официальная документация также отмечает контринтуитивный момент: при использовании thinking_level=high промпт стоит писать более прямо и лаконично. Избегайте старых приемов вроде «пожалуйста, рассуждай пошагово» или «учти все возможные варианты». Для моделей 3-й серии это избыточно и может привести к «переанализу».
🎯 Совет по настройке: используйте комбинацию
media_resolution=HIGHиthinking_level=highкак стандартный шаблон для задач распознавания в APIYI (apiyi.com). В дальнейшем можно подстраивать параметры под конкретную бизнес-задачу, чтобы не тратить время на постоянные эксперименты.
Лайфхак Gemini API №3: переносим инструкции в system_instruction, а не в user prompt
Еще одна частая ошибка при работе с API — сваливать всё в одну кучу в user prompt: описание роли, задачу, формат вывода и сам вопрос пользователя. Такой подход заставляет модель каждый раз заново «переваривать» весь контекст. В веб-версии для этого есть «системный промпт», который кэшируется и используется повторно — в API нужно делать так же.
Правильный подход — поместить ваши «постоянные инструкции» в system_instruction:
config = types.GenerateContentConfig(
media_resolution="MEDIA_RESOLUTION_HIGH",
thinking_level="high",
system_instruction=(
"Ты — строгий ассистент по анализу изображений."
"Отвечай, опираясь только на детали, явно видимые на изображении, не делай домыслов."
"Выводи данные в структурированном JSON с полями: entities/attributes/text."
)
)
Это дает два преимущества: во-первых, модель отвечает по единым правилам, что делает результат стабильнее. Во-вторых, при включенном System Prompt Caching расходы на ввод могут снизиться до 10 раз, что крайне выгодно для пакетной обработки изображений. В панели управления APIYI (apiyi.com) можно отслеживать коэффициент попаданий в кэш (cache hit rate) для каждой модели, чтобы оценивать эффективность оптимизации.
Лайфхак Gemini API №4: включаем выполнение кода, чтобы модель могла «рассмотреть детали»
В анонсе Agentic Vision для Gemini 3 Flash компания Google привела четкие данные: использование инструментов для выполнения кода поверх базовой модели дает прирост качества в задачах анализа изображений на 5–10%. Принцип прост: модель генерирует Python-код, чтобы обрезать, увеличить, повернуть изображение или считать значения пикселей, а затем анализирует полученные фрагменты. Именно это по умолчанию делает веб-версия.
В API выполнение кода по умолчанию отключено, его нужно активировать явно:
config = types.GenerateContentConfig(
media_resolution="MEDIA_RESOLUTION_HIGH",
thinking_level="high",
tools=[types.Tool(code_execution=types.ToolCodeExecution())]
)
resp = client.models.generate_content(
model="gemini-3.5-flash",
contents=[image_part, "Посчитай количество всех красных кнопок на изображении и укажи их расположение"],
config=config
)
Для задач вроде подсчета объектов, пространственного мышления или анализа плотных UI-интерфейсов — это самый эффективный способ оптимизации. Мы в APIYI (apiyi.com) заметили, что при включении выполнения кода общая задержка (latency) немного возрастает, поэтому рекомендуем включать эту функцию по умолчанию для асинхронных задач, а в синхронных — использовать по необходимости.
Советы по работе с Gemini API №5: для больших изображений используйте File API, а не base64
Если размер изображения превышает несколько мегабайт, многие команды просто встраивают его в тело запроса в формате base64. С небольшими файлами это работает отлично, но как только общий объем запроса переваливает за 20 МБ, срабатывают ограничения Gemini. В результате часть изображений может быть молчаливо сжата, что неизбежно ведет к падению качества распознавания.
Официальные рекомендации по выбору способа передачи данных довольно прозрачны:
| Размер изображения | Рекомендуемый способ передачи | Причина |
|---|---|---|
| Менее 5 МБ | Встраивание base64 | Легкие запросы, простота вызова |
| 5–20 МБ | Загрузка через File API | Предотвращение раздувания объема запроса |
| Более 20 МБ | Обязательно File API | Кодирование base64 может повредить запрос |
| Повторное использование | Рекомендуется File API | Загрузка один раз, многократное использование, экономия токенов |
Еще один плюс File API заключается в том, что одно и то же изображение можно использовать в нескольких запросах, что избавляет от лишних затрат на повторную загрузку. При использовании шлюза APIYI (apiyi.com) эндпоинт File API работает с той же группой учетных данных, поэтому вам не нужно создавать отдельный аккаунт Google Cloud для загрузки изображений.
Совет по Gemini API №6: создаем цепочку агентов для многошаговой проверки
После освоения первых пяти советов ваши одиночные вызовы API станут по качеству почти такими же, как в веб-интерфейсе. Но у веб-версии есть «секретное оружие»: многошаговая проверка. После генерации ответа модель проводит второй этап рассуждений, чтобы подтвердить ключевые факты, и если возникают сомнения, она «переписывает» ответ. В API готового переключателя для этого нет, поэтому нужно собрать простую цепочку агентов самостоятельно.
Минимально рабочая двухшаговая цепочка выглядит так:
- Первый вызов: просим
gemini-3.5-flashсгенерировать структурированный результат распознавания (вывод в формате JSON). - Второй вызов: отправляем результат первого шага вместе с исходным изображением и задаем вопрос: «Основываясь на этом изображении, являются ли все следующие утверждения верными?»
Если на втором этапе выявляется хоть одно «неверное» поле, запускается третий этап — «пересдача». Эту цепочку можно реализовать через APIYI (apiyi.com), используя один и тот же base_url и API-ключ без необходимости в дополнительных сервисах. Для задач, где критична точность (обработка договоров, вспомогательная разметка медицинских изображений, проверка на соответствие требованиям безопасности), многошаговая проверка — это тот самый шаг, который позволяет поднять точность с 90% до 98%.
| Тип задачи | Рекомендуемая цепочка | Параметры одного шага |
|---|---|---|
| Общие вопросы по изображениям | Один шаг | high + thinking_high |
| Извлечение данных из документов | Один шаг + проверка JSON | ultra high + thinking_high |
| Сложный подсчет объектов | Два шага + выполнение кода | high + thinking_high + tools |
| Задачи с высокими требованиями к точности | Три шага (распознавание → проверка → пересдача) | ultra high + thinking_high + tools |
Шаблон параметров: объединяем 6 советов в один многоразовый вызов
Чтобы вам было проще начать, вот «шаблон по умолчанию для задач распознавания», в котором уже объединены все 6 советов. Это отличная отправная точка для большинства бизнес-задач:
from google import genai
from google.genai import types
client = genai.Client(
api_key="YOUR_APIYI_KEY",
http_options={"base_url": "https://api.apiyi.com"}
)
SYSTEM = (
"Ты — строгий ассистент по анализу изображений. Ссылайся только на то, "
"что четко видно на изображении, не делай домыслов. Выводи строго JSON "
"с полями entities/attributes/text."
)
config = types.GenerateContentConfig(
media_resolution="MEDIA_RESOLUTION_HIGH",
thinking_level="high",
system_instruction=SYSTEM,
tools=[types.Tool(code_execution=types.ToolCodeExecution())],
response_mime_type="application/json"
)
resp = client.models.generate_content(
model="gemini-3.5-flash",
contents=[image_part, "Распознай это изображение согласно требованиям SYSTEM"],
config=config
)
print(resp.text)
При реальном развертывании рекомендую вынести этот шаблон в единый слой вызова SDK на стороне APIYI (apiyi.com). Бизнес-подразделения будут передавать только изображение и вопрос, а параметры будут автоматически подставляться шлюзом — это избавит каждую команду от необходимости наступать на одни и те же грабли.

Часто задаваемые вопросы (FAQ): Разница между Gemini API и веб-версией при распознавании изображений
В1: Станет ли API работать не хуже веб-версии, если включить все эти параметры?
В большинстве бизнес-задач вы добьетесь паритета с веб-версией. Однако в редких, особо сложных случаях (очень мелкий текст, плохое освещение, специфические художественные стили) результаты могут быть чуть слабее, так как веб-версия дополнительно использует внутренние, непубличные конвейеры (Pipeline) улучшения изображений. Для таких сценариев вы можете использовать APIYI (apiyi.com) для сравнения с визуальными моделями других вендоров, чтобы подобрать наиболее подходящую модель для вашей задачи.
В2: Увеличит ли thinking_level=high стоимость в два раза?
Это увеличит расход токенов на внутренние рассуждения (reasoning), но повлияет только на этап генерации ответа. К тому же, в задачах распознавания изображений основную часть стоимости обычно составляют токены самого изображения. Прирост точности, который дает установка thinking на high, значительно перевешивает дополнительные расходы, особенно если это заменяет ручную проверку данных.
В3: Как изменить base_url? Я использую официальный Google SDK.
SDK google-genai позволяет перенаправить запросы на шлюз APIYI (apiyi.com) через параметр http_options={"base_url": "https://api.apiyi.com"}. Используйте API-ключ, сгенерированный в панели управления APIYI — отдельный проект в Google Cloud не требуется.
В4: Можно ли решить проблему только оптимизацией промпта?
Потолок эффективности при настройке только промпта довольно низкий: он не покрывает такие аспекты, как разрешение, глубина рассуждений или вызов инструментов — то есть возможности, находящиеся «вне модели». Из 6 советов в этой статье только третий касается промптов, остальные 5 — это инженерные рычаги управления.
В5: Что делать, если API постоянно пропускает «китайские водяные знаки» на изображениях, которые веб-версия распознает без проблем?
Распознавание мелких деталей, таких как водяные знаки, часто зависит от комбинации высокого разрешения и выполнения кода (code execution) для обрезки изображения. Установите media_resolution на ultra high, включите code execution и используйте двухэтапную проверку — это обычно обеспечивает стабильное распознавание.
Итог: переносим инженерные возможности веб-версии в API
Вернемся к главному вопросу: почему качество распознавания Gemini API уступает веб-версии? Ответ не в том, что модель стала слабее, а в том, что веб-версия обладает мощным инженерным «каркасом». Когда вы напрямую вызываете API gemini-3.5-flash, вам приходится самостоятельно компенсировать отсутствие автоматической переработки промптов, настройки разрешения, бюджета на рассуждения, вызова инструментов и проверки результатов. Суть наших 6 советов заключается в том, чтобы «перенести то, что веб-версия делает за вас, в вашу собственную цепочку вызовов API».
Практический путь прост: сначала выкрутите media_resolution и thinking_level на максимум, перенесите инструкции в system_instruction и включите кэширование. Для сложных задач распознавания активируйте code execution, для больших изображений используйте File API, и, наконец, используйте двух- или трехэтапную цепочку агентов для обеспечения высокой точности. После такой «комбо-атаки» вернитесь в панель управления APIYI (apiyi.com), чтобы сравнить точность и задержку — большинство команд смогут сократить разрыв между «веб-версией и API» до уровня, практически незаметного глазу.
📌 Авторство: статья подготовлена технической командой APIYI (apiyi.com). Больше практических руководств по интеграции и настройке моделей серий Gemini, Claude и GPT вы найдете в справочном центре APIYI.