Uma atualização que merece a atenção dos desenvolvedores! A família de modelos de base Dola, da ByteDance, lançou em 28 de abril de 2026 o seu primeiro modelo de compreensão "Omnimodal" (全模态): o Seed-2.0-lite-260428. Ele oferece suporte nativo para quatro modalidades de entrada: vídeo, imagem, áudio e texto. Este é o primeiro modelo da família Dola Seed capaz de "ver e ouvir" simultaneamente, trazendo melhorias significativas em tarefas de Agentes, codificação (Coding) e interfaces gráficas (GUI). Este artigo, baseado nas especificações oficiais do BytePlus ModelArk e nos benchmarks públicos do ByteDance Seed, além de testes práticos via APIYI (apiyi.com), explora as capacidades do modelo, os detalhes da compreensão de áudio e seus cenários de aplicação típicos.
一、O que é o Seed-2.0-lite-260428: Posicionamento central e pontos de atualização
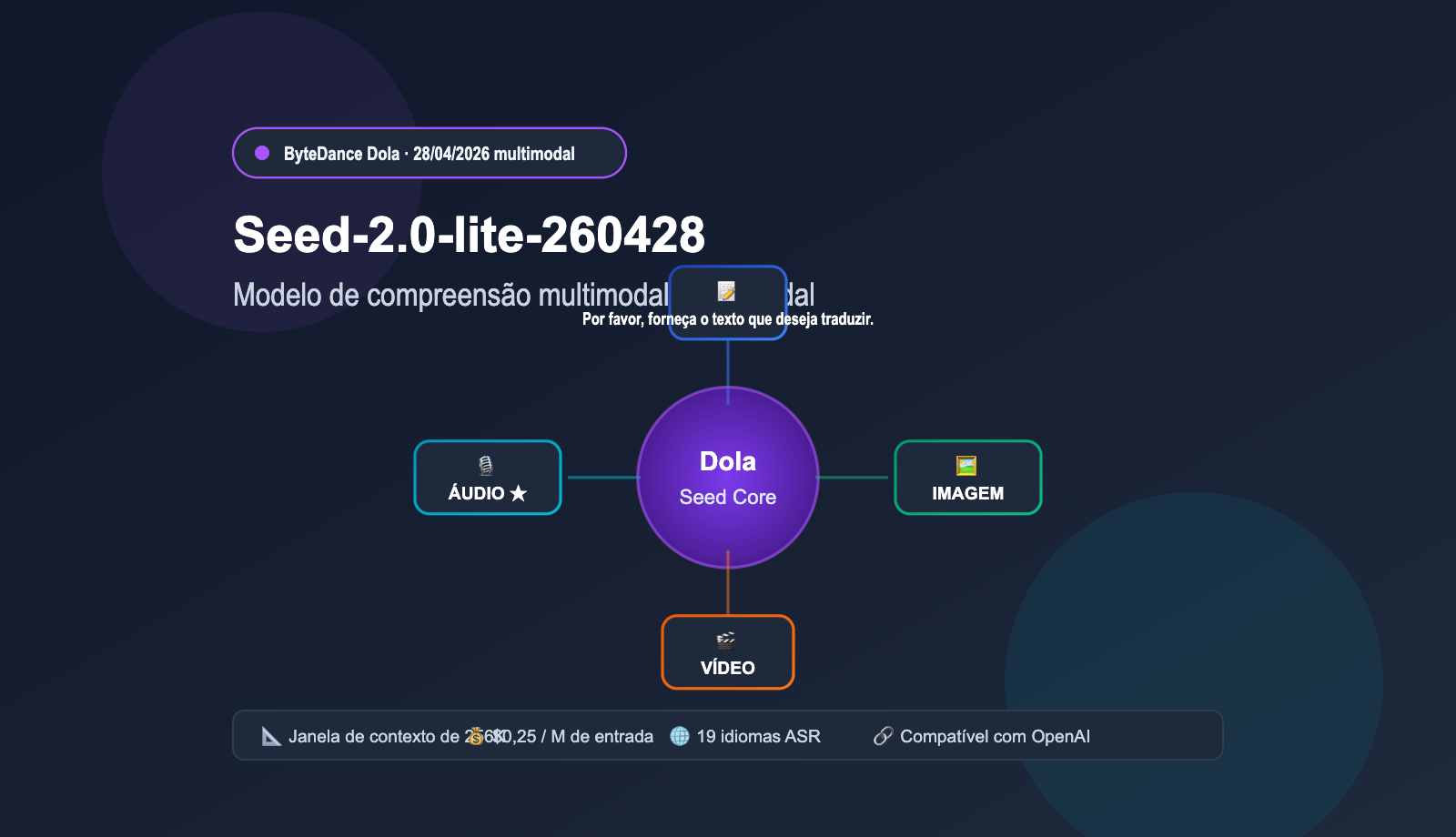
O Seed-2.0-lite-260428 é uma iteração importante lançada pela ByteDance Seed em 28 de abril de 2026. O modelo de base segue o Seed-2.0-Lite lançado no início de março, mas, pela primeira vez, adiciona a "entrada de áudio" como uma capacidade nativa, elevando esta linha de produtos ao estágio de "Omnimodal" real. O código "260428" no nome do modelo refere-se à data de lançamento.
1.1 O primeiro modelo omnimodal da família Dola da ByteDance
Na família Dola Seed anterior, as capacidades de texto e multimodais eram tratadas em ramificações separadas. O Seed-2.0-lite-260428 unifica o processamento de vídeo, imagem, áudio e texto no mesmo modelo, o que significa que ele pode "ver cenas de vídeo" e "ouvir conteúdo de áudio" simultaneamente, realizando julgamentos conjuntos e recuperação temporal. Essa arquitetura unificada é crucial para aplicações de Agentes, pois muitas tarefas reais (como moderação de vídeo, resumos de reuniões e controle de qualidade de atendimento ao cliente) exigem naturalmente um raciocínio multimodal.
1.2 Visão geral das especificações principais do modelo
A tabela abaixo resume os parâmetros principais do Seed-2.0-lite-260428 no BytePlus ModelArk, facilitando a verificação de compatibilidade com as necessidades do seu negócio.
| Especificação | Parâmetro |
|---|---|
| ID do modelo API | seed-2-0-lite-260428 |
| Família de modelos | ByteDance Seed / Dola |
| Data de lançamento | 28/04/2026 |
| Janela de contexto | 262.144 tokens (aprox. 256K) |
| Saída máxima | 131.072 tokens (aprox. 128K) |
| Modalidades de entrada | Texto + Imagem + Vídeo + Áudio |
| Preço de entrada | $0,25 / M tokens |
| Preço de saída | $2,00 / M tokens |
| Compatibilidade de interface | API compatível com OpenAI |
II. As 4 capacidades fundamentais de compreensão multimodal do Seed-2.0-lite-260428
A capacidade multimodal do modelo não se resume a apenas "conectar" várias entradas, mas sim realizar um raciocínio conjunto por meio de uma representação unificada. A documentação oficial resume suas capacidades principais em quatro pilares.
2.1 Raciocínio conjunto de áudio e vídeo e recuperação temporal
O modelo consegue analisar simultaneamente informações visuais e de áudio em vídeos, determinando com precisão se a "imagem vista" e o "som ouvido" são consistentes. Por exemplo, ele pode julgar se a expressão facial de uma pessoa em um vídeo condiz com a emoção da fala, ou se os movimentos dos objetos na tela correspondem aos efeitos sonoros corretos. Essa capacidade de alinhamento audiovisual é extremamente útil em cenários como moderação de vídeo e detecção de deepfakes.
2.2 Decomposição profunda de vídeo e rastreamento de longa duração
Para vídeos longos, o Seed-2.0-lite-260428 suporta a extração de pistas cruciais em múltiplos segmentos temporais, rastreando continuamente o progresso de personagens e eventos. Ele realiza raciocínios de várias etapas entre múltiplos quadros para reconstruir relações de eventos e o contexto comportamental. Comparado à abordagem tradicional de descrição quadro a quadro, sua capacidade de "compreensão de longa duração" é mais adequada para tarefas como revisão de vídeos de monitoramento e assistência na edição de documentários.
2.3 Agente aprimorado e capacidades de codificação
O modelo possui uma capacidade de execução estável e confiável em tarefas complexas de longa duração, além de habilidades de desenvolvimento full-stack. Isso significa que os desenvolvedores podem integrá-lo a frameworks de agentes para executar um ciclo completo que inclui planejamento, invocação de ferramentas, revisão de passos históricos e geração de código, sem a necessidade de dividir a tarefa entre vários modelos diferentes.
2.4 Interface unificada para compreensão de GUI e execução de operações
A capacidade de GUI é integrada à mesma interface; o modelo pode entender capturas de tela (botões, formulários, menus) e emitir comandos de operação (clicar em coordenadas, digitar texto). Isso representa um upgrade direto de capacidade para testes automatizados, agentes de desktop e aplicações de RPA.
III. Análise profunda da capacidade de compreensão de áudio do Seed-2.0-lite-260428
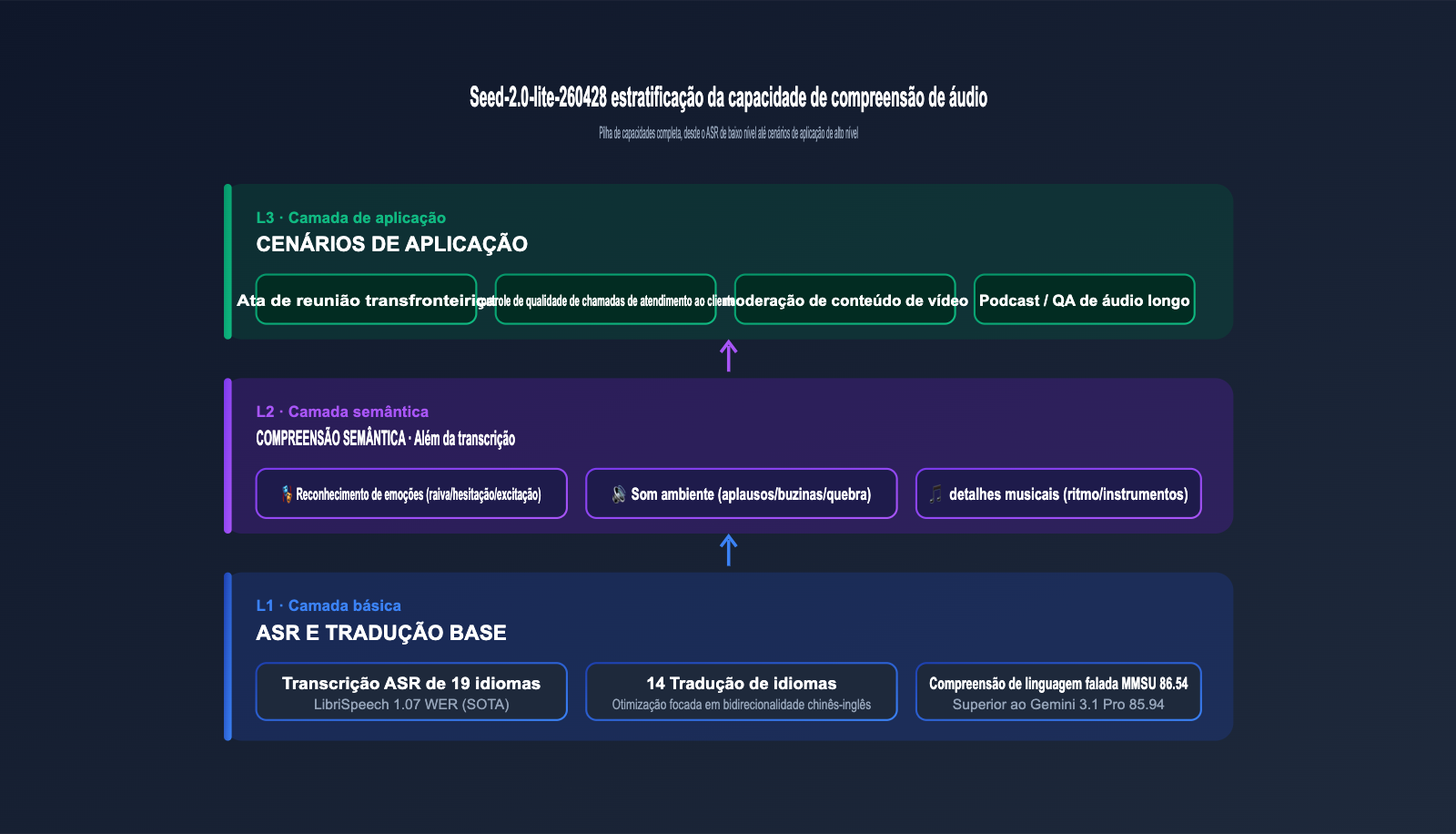
O áudio é o maior diferencial desta atualização, por isso vamos detalhá-lo separadamente. O modelo apresentou resultados impressionantes em vários benchmarks de áudio convencionais.
3.1 Pontuações em benchmarks de áudio convencionais
A tabela abaixo resume os resultados dos benchmarks divulgados oficialmente pela ByteDance para o Seed, abrangendo três dimensões: reconhecimento de fala (ASR), compreensão de linguagem falada e fala em ambientes ruidosos.
| Benchmark | Tipo de tarefa | Seed-2.0-lite-260428 |
|---|---|---|
| LibriSpeech test-clean | ASR em inglês (limpo) | 1.07 WER |
| LibriSpeech test-other | ASR em inglês (ruído) | 2.17 WER |
| WenetSpeech test-net | ASR em chinês (web) | 4.47 WER |
| WenetSpeech test-meeting | ASR em reuniões (chinês) | 5.31 WER |
| Fleurs (15 idiomas) | ASR multilíngue | 74.70 |
| MMSU | Compreensão de linguagem falada | 86.54 |
| WildSpeech | Fala em ambiente ruidoso | 75.81 |
O WER de 1.07 no LibriSpeech test-clean já está no nível de ponta da indústria, superando resultados similares do Whisper large-v3 público; as pontuações no MMSU e WildSpeech também são ligeiramente superiores aos dados públicos do Gemini 3.1 Pro, indicando que o modelo atinge um nível de flagship convencional no aspecto de "compreensão", e não apenas em "ditado".
3.2 Transcrição em 19 idiomas e tradução entre 14 idiomas
A documentação oficial afirma que o modelo suporta transcrição de áudio em 19 idiomas e tradução mútua entre 14 idiomas, com a tradução bidirecional chinês-inglês listada como uma prioridade de otimização. Isso significa que, para uma mesma gravação de reunião multilíngue, o modelo pode gerar legendas e traduções em um idioma unificado, sendo ideal para equipes transfronteiriças, atendimento ao cliente de e-commerce internacional, entre outros cenários.
3.3 Indo além da "transcrição": emoções, sons ambientais e detalhes musicais
A maior diferença em relação aos modelos ASR tradicionais é que o Seed-2.0-lite-260428 também consegue capturar informações semânticas além do "conteúdo textual": flutuações emocionais do falante (raiva, hesitação, excitação), sons de fundo (vidro quebrando, aplausos, buzinas de carro) e detalhes musicais (ritmo, instrumentos, estilo). Essas dimensões têm valor direto para negócios como controle de qualidade de atendimento, moderação de conteúdo e recomendação de música.
🎯 Sugestão de integração: Em cenários que exigem a colaboração de "áudio + texto", como atas de reuniões transfronteiriças, controle de qualidade de atendimento e moderação de conteúdo de vídeo, recomendamos chamar o Seed-2.0-lite-260428 diretamente via APIYI (apiyi.com). Com um único
base_url, você obtém os benefícios duplos de raciocínio multimodal e uma janela de contexto de 256K, sem a necessidade de construir sua própria infraestrutura de áudio.
IV. Comparativo do Seed-2.0-lite-260428 com os principais modelos multimodais
Para entender o posicionamento deste modelo em 2026, a melhor forma é compará-lo com os principais modelos multimodais de referência da mesma época, como o GPT-4o e o Gemini 3 Pro.
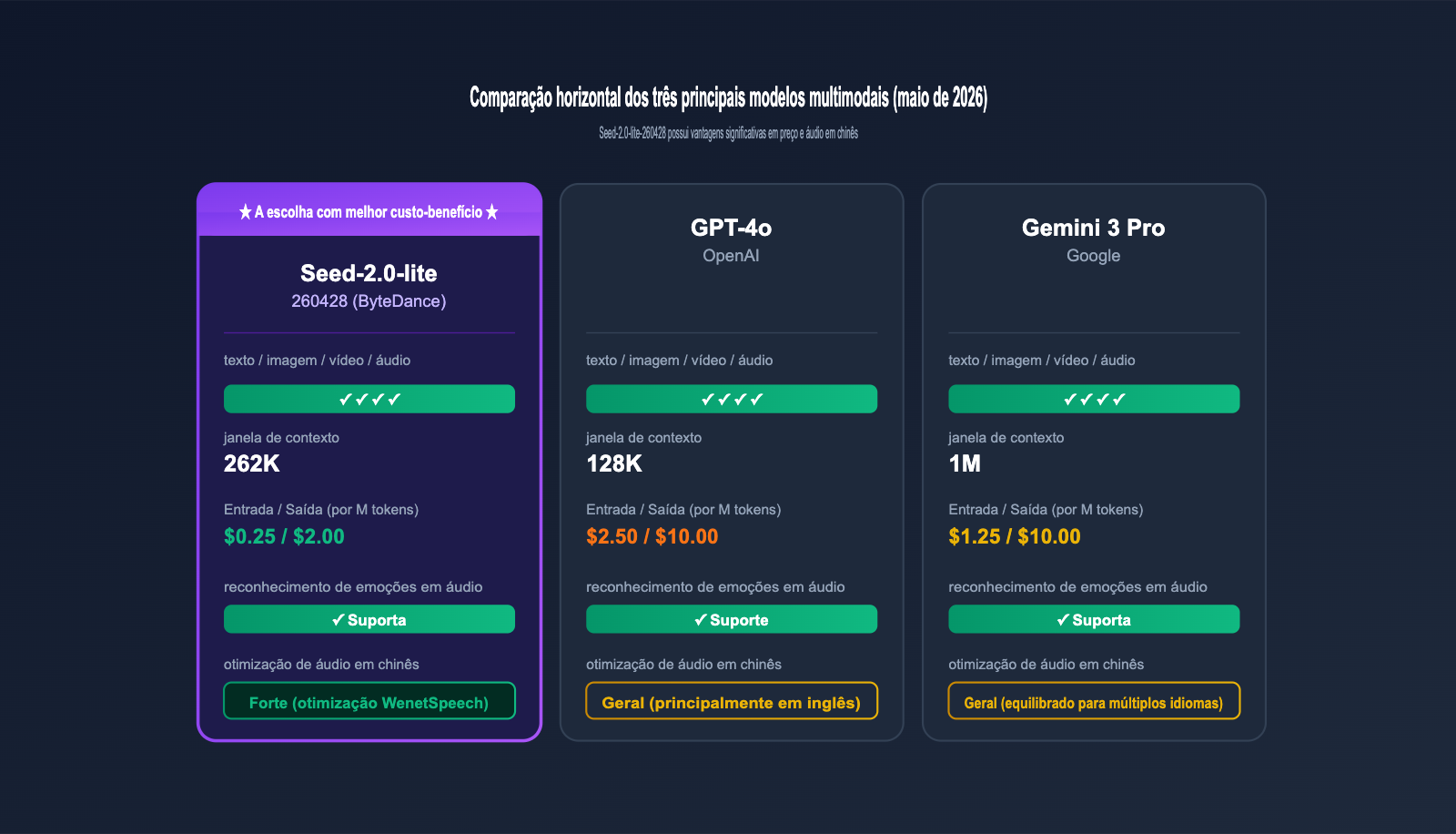
4.1 Comparação de capacidades dos modelos multimodais
| Dimensão | Seed-2.0-lite-260428 | GPT-4o | Gemini 3 Pro |
|---|---|---|---|
| Entrada de texto | ✓ | ✓ | ✓ |
| Entrada de imagem | ✓ | ✓ | ✓ |
| Entrada de vídeo | ✓ | ✓ | ✓ |
| Entrada de áudio | ✓ | ✓ | ✓ |
| Janela de contexto | 262K | 128K | 1M |
| Preço de entrada / M | $0.25 | $2.50 | $1.25 |
| Preço de saída / M | $2.00 | $10.00 | $10.00 |
| Reconhecimento de emoção em áudio | ✓ | ✓ | ✓ |
| Otimização de áudio em chinês | Forte (Otimizado WenetSpeech) | Comum | Comum |
Como podemos observar, o principal diferencial do Seed-2.0-lite-260428 é a combinação de "preço + áudio em chinês + 256K de janela de contexto". Isso o torna extremamente competitivo em tarefas como processamento de áudio e vídeo em vários idiomas e resumos de reuniões longas. O GPT-4o e o Gemini 3 Pro ainda mantêm vantagem na capacidade abrangente em inglês e na amplitude do ecossistema, sendo ideais para cenários de uso geral.
🎯 Sugestão de escolha: Se o seu negócio foca principalmente em processamento de áudio e vídeo em chinês e você é sensível a custos, o Seed-2.0-lite-260428 é uma escolha com excelente custo-benefício atualmente. Se o foco for inglês ou geração criativa multilíngue intensa, você pode utilizar o gateway unificado da APIYI (apiyi.com) para acessar esses três modelos de ponta e rotear as chamadas conforme o cenário.
V. Guia de início rápido para invocar o Seed-2.0-lite-260428 via APIYI
O modelo é totalmente compatível com a interface no estilo OpenAI, o que torna o custo de migração extremamente baixo. Abaixo, apresentamos um exemplo minimalista de invocação para converter um segmento de imagem ou áudio em uma descrição estruturada.
5.1 Exemplo mínimo de interface compatível com OpenAI
from openai import OpenAI
client = OpenAI(
api_key="<APIYI_API_KEY>",
base_url="https://vip.apiyi.com/v1"
)
# Realiza a invocação do modelo
response = client.chat.completions.create(
model="seed-2-0-lite-260428",
messages=[
{"role": "user", "content": [
{"type": "text", "text": "Por favor, descreva o conteúdo, o tom e os sons de fundo deste áudio."},
{"type": "input_audio", "audio": {"data": "<base64-or-url>", "format": "mp3"}}
]}
]
)
print(response.choices[0].message.content)
Ao apontar a base_url para o endpoint de acesso unificado da APIYI (apiyi.com) e alternar o model, você pode invocar o Seed-2.0-lite-260428 e outros modelos multimodais usando o mesmo SDK, sem a necessidade de reescrever o código da sua aplicação.
5.2 Cenários de aplicação típicos para o Seed-2.0-lite-260428
A tabela abaixo organiza alguns cenários típicos e os benefícios que eles obtêm com a característica de "inferência unificada de áudio + vídeo + texto" deste modelo.
| Cenário de Aplicação | Capacidade Chave | Valor de Negócio |
|---|---|---|
| Atas de reuniões globais | ASR em 19 idiomas + tradução em 14 idiomas + janela de contexto de 256K | Geração de atas bilíngues com um clique |
| Controle de qualidade de atendimento | Reconhecimento de emoções + detecção de som ambiente + análise de áudio longo | Marcação automática de raiva/interrupções/tempo excedido |
| Moderação de conteúdo de vídeo | Inferência conjunta de áudio e vídeo + rastreamento de longa duração | Identificação sincronizada de cenas perigosas e sons suspeitos |
| QA de podcasts / vídeos longos | Janela de contexto de 256K + transcrição de áudio | Perguntas e respostas diretas sobre horas de conteúdo de áudio |
| Automação de Agent de desktop | Compreensão de GUI + invocação de ferramentas | Conclusão de fluxos de trabalho complexos entre aplicações |
VI. Perguntas frequentes sobre o Seed-2.0-lite-260428
6.1 Como preencher o campo 'model' durante a invocação da API?
Basta preencher com seed-2-0-lite-260428. Observe que há hifens no meio, não sublinhados; o sufixo 260428 é o número da versão (28/04/2026) e não deve ser omitido, caso contrário, você poderá ser roteado para uma versão antiga. A lista de modelos pode ser consultada no painel da APIYI (apiyi.com) para garantir que esteja alinhada com o lançamento mais recente.
6.2 Quais formatos e durações de áudio são suportados?
O modelo segue a convenção do campo input_audio no estilo OpenAI, suportando formatos comuns como MP3, WAV, M4A e FLAC. A duração máxima e a taxa de amostragem específicas devem seguir a documentação oficial do ModelArk; recomendamos que a entrada única não exceda 30 minutos para garantir a estabilidade da inferência. Áudios muito longos podem ser segmentados antes da entrada e os resultados combinados posteriormente.
6.3 Qual a diferença entre este e o Seed-2.0-Lite sem o sufixo 260428?
A versão sem sufixo é o Seed-2.0-Lite original lançado em 10 de março, que suporta apenas texto, imagem e vídeo; a versão 260428 é a atualização multimodal completa lançada em 28 de abril, que adiciona entrada de áudio e capacidade de inferência conjunta de áudio e vídeo. Se o seu negócio utiliza áudio, você deve usar a versão com sufixo.
6.4 A cobrança é feita por token ou por duração de áudio?
O modelo é cobrado de forma unificada por token, e o áudio é codificado internamente em tokens para o cálculo. O preço atual é de $0,25 por milhão de tokens de entrada e $2,00 por milhão de tokens de saída. O número de tokens correspondente a um segmento de áudio pode ser verificado no "Histórico de Faturas" no painel da APIYI (apiyi.com), facilitando a estimativa e otimização de custos.
6.5 O modelo suporta saída em streaming e Function Call?
Sim, totalmente. O Seed-2.0-lite-260428 é compatível com os campos stream=true e tools do protocolo padrão OpenAI Chat Completions, podendo ser integrado diretamente a frameworks populares como LangChain, LangGraph e OpenAI Agents SDK, sem necessidade de modificações especiais.
VII. Conclusão: Modelos multimodais completos levam as aplicações à era da "inferência unificada"
O valor do Seed-2.0-lite-260428 não reside apenas em "adicionar uma capacidade de áudio", mas sim em unificar vídeo, imagem, áudio e texto em um único modelo para realizar a inferência. Para negócios que são inerentemente multimodais (como reuniões, atendimento ao cliente, moderação de conteúdo, análise de vídeo e automação de agentes), essa "inferência unificada" representa uma simplificação arquitetônica real: não é mais necessário combinar três modelos distintos de ASR, visão e texto, nem se preocupar com a perda de contexto entre modelos.
Do ponto de vista de custo e cenários em chinês, este modelo possui uma vantagem de custo-benefício muito clara entre os principais modelos topo de linha. O preço de $0,25 / M de tokens de entrada torna o processamento de áudio e vídeo em larga escala viável na engenharia, e a janela de contexto de 256K é suficiente para cobrir cenários de áudio e vídeo de longa duração.
Se você precisar invocar o Seed-2.0-lite-260428 e outros modelos multimodais de ponta sob a mesma base_url, acesse a documentação oficial da APIYI em apiyi.com para conferir exemplos completos de integração e a lista de modelos disponíveis.
Autor: Equipe APIYI — Fornecendo continuamente serviços estáveis e eficientes de proxy de API e roteamento de múltiplos modelos para desenvolvedores de IA em todo o mundo. Para mais detalhes, visite apiyi.com