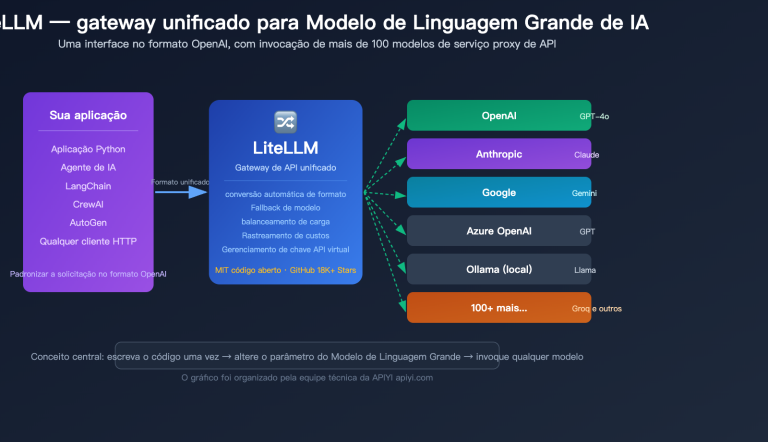
Recentemente, o Cookbook oficial da OpenAI, em parceria com a Fractional AI, lançou um estudo de caso prático extremamente robusto: o uso de IA para a auditoria automática de recibos de reembolso. À primeira vista, parece uma tarefa comum de OCR, mas, ao explorar o notebook, percebemos que se trata de um verdadeiro guia metodológico sobre "como levar aplicações de IA do protótipo à produção". É, também, o exemplo open-source mais completo sobre o Eval-Driven System Design (Design de Sistema Orientado por Avaliação), um dos temas mais discutidos atualmente na indústria.
O mais interessante é que essa metodologia não resolve apenas problemas técnicos, mas sim uma questão fundamental que assombra todos os engenheiros de IA: como ter certeza de que a alteração que fiz no comando realmente melhorou o sistema, ou se apenas parece que melhorou? Este artigo desmembra o caso de auditoria de recibos da OpenAI de forma simples, extraindo 5 lições de engenharia valiosas para qualquer desenvolvedor de aplicações de IA.
🎯 Guia Rápido: O caso vem do diretório
eval_driven_system_designno cookbook.openai.com, criado pela equipe da Fractional AI (Hugh Wimberly / Joshua Marker / Eddie Siegel) em conjunto com Shikhar Kwatra, da OpenAI. O código completo está disponível no repositório oficial do Cookbook da OpenAI e pode ser reproduzido sem alterações usando serviços proxy de API como o APIYI (apiyi.com), sendo ideal para desenvolvedores brasileiros estudarem o fluxo completo.
O contexto de negócio do caso de auditoria de recibos: Por que isso é um problema real?
Antes de entrar na parte técnica, vamos esclarecer o contexto comercial. Este não é um problema artificial criado apenas para demonstrar uma API, mas um cenário corporativo real com números de ROI claros.
| Dimensão de Negócio | Valor | Significado |
|---|---|---|
| Volume anual | ~ 1 milhão de recibos | Escala típica de média empresa |
| Custo de processamento por IA | $0,20 | Taxa de invocação do modelo |
| Custo de auditoria humana | $2,00 | Revisão por equipe financeira |
| Multa por erro de auditoria | $30 / recibo | Penalidades fiscais/compliance |
| Taxa atual de auditoria humana | 5% | Apenas casos complexos |
Ao multiplicar esses números, percebemos que um aumento de apenas 1% na precisão da auditoria, em um volume de 1 milhão de recibos, representa centenas de milhares de dólares em ganhos anuais. É isso que a equipe da Fractional AI enfatiza ao falar sobre "vincular métricas de avaliação ao impacto financeiro (Dollar Impact)" — não se trata de apenas buscar números, mas de garantir que cada alteração no comando corresponda a um impacto positivo no balanço da empresa.
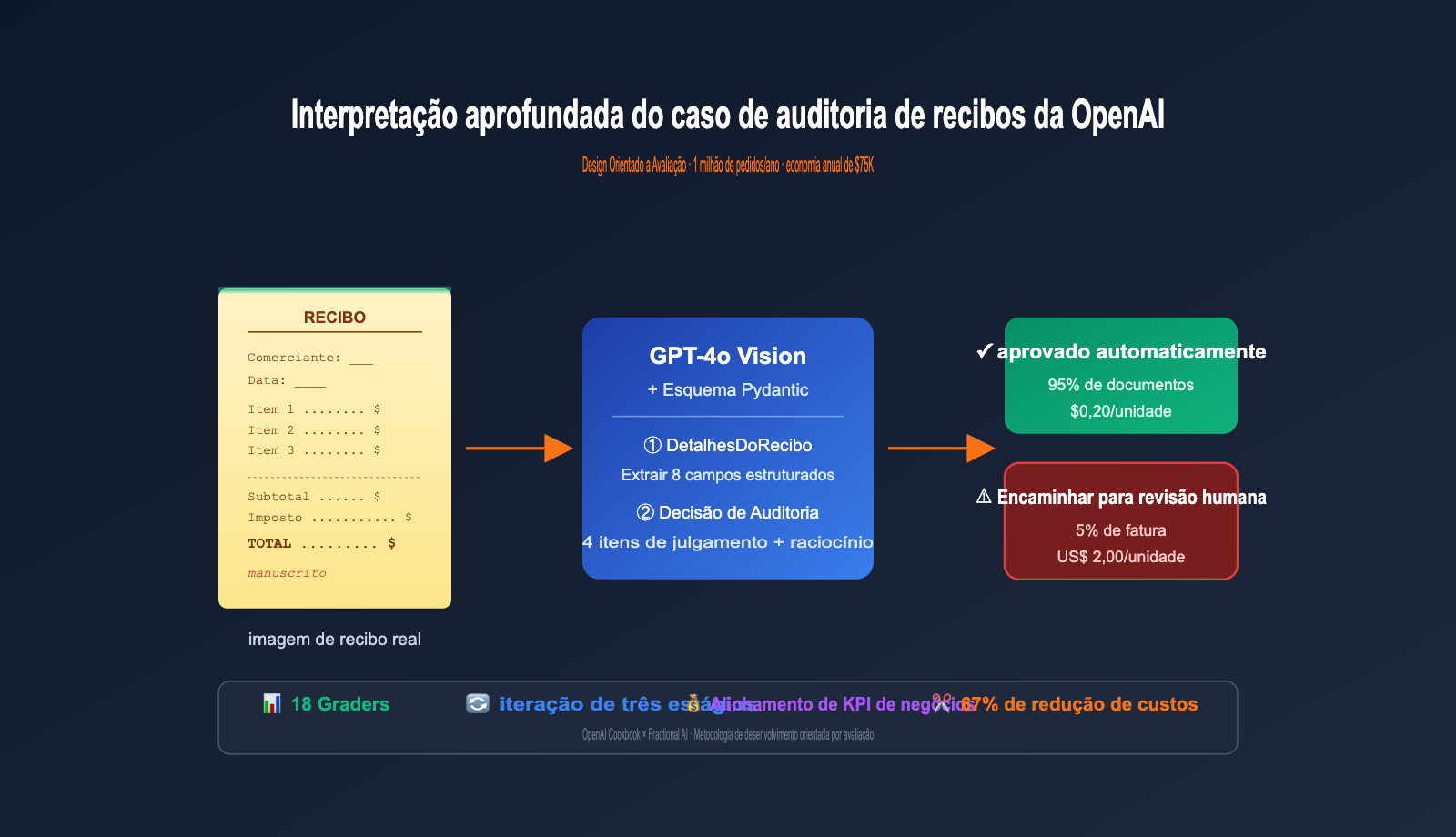
O objetivo de todo o sistema de IA é muito claro: usar o GPT-4o para auditar automaticamente a maioria dos recibos, enviando apenas os de "baixa confiança" para revisão humana, reduzindo tanto os custos de auditoria quanto o risco de falhas. Parece simples, mas o diabo mora nos detalhes.
O que é Eval-Driven Design: uma metodologia que você só entende depois de errar
Se você perguntar a 100 engenheiros de IA "como vocês verificam se o prompt está correto", 99 dirão "executo alguns exemplos e vejo se a saída parece certa". Isso é o que a equipe da Fractional AI critica como vibe-coding (ajuste baseado em intuição), e é exatamente o modo de desenvolvimento que o Eval-Driven Design (doravante EDD) pretende substituir.
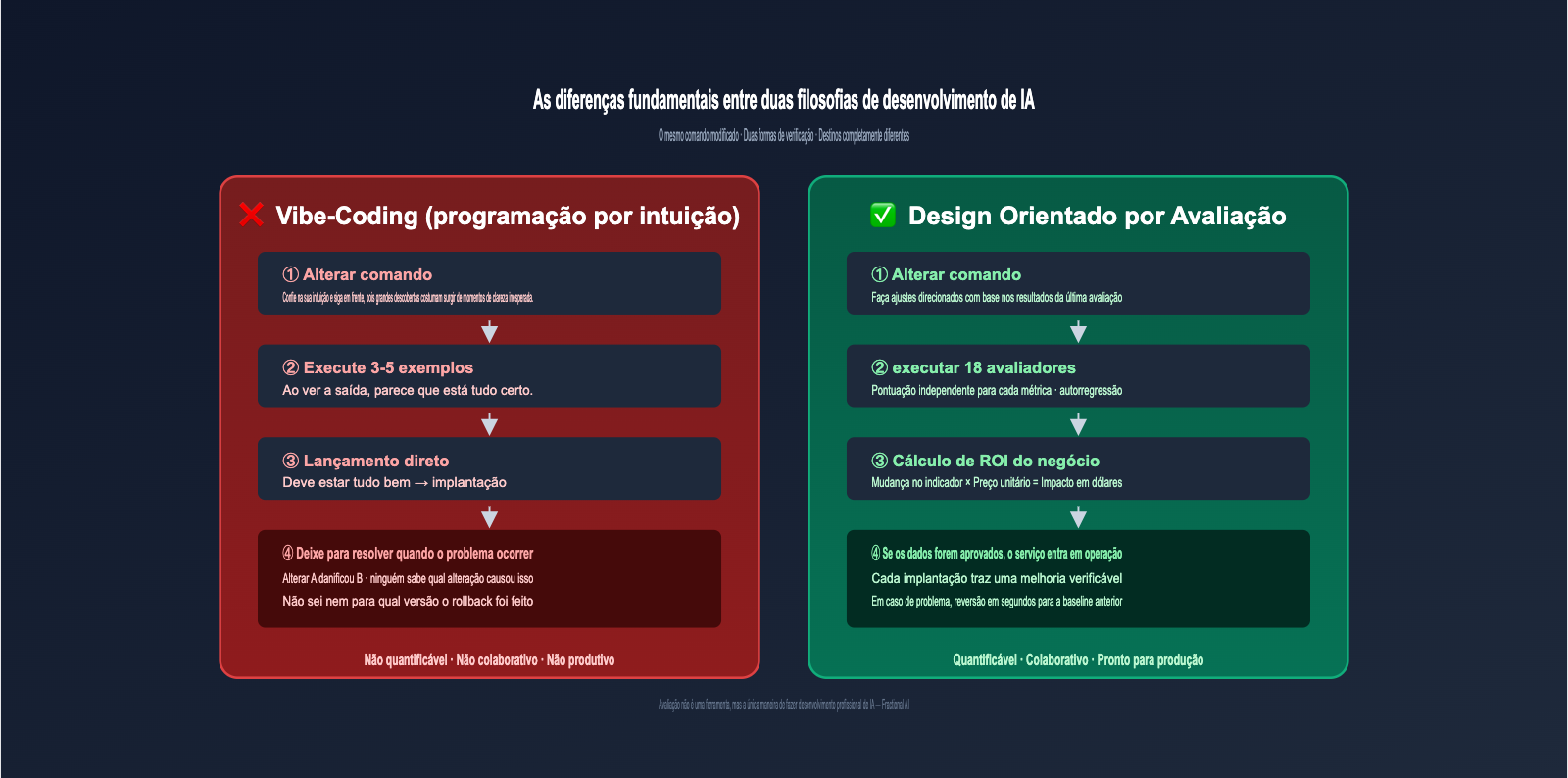
A diferença entre as duas abordagens pode ser resumida na tabela abaixo:
| Dimensão de Comparação | Vibe-Coding (Ajuste por intuição) | Eval-Driven Design (Avaliação orientada) |
|---|---|---|
| Método de verificação | Executa 3-5 exemplos e observa | Executa 20-100+ amostras anotadas e calcula métricas |
| Decisão de mudança | "Parece que melhorou" | "A precisão subiu de 78% para 85%" |
| Alinhamento de negócio | Baseado em "sentimento" | Convertido diretamente em impacto financeiro |
| Risco de regressão | Alterar A pode quebrar B sem ninguém saber | Conjunto completo de métricas validado automaticamente |
| Escalabilidade de colaboração | Apenas o autor original entende | Qualquer engenheiro pode depurar |
A Fractional AI tem uma frase amplamente citada: "Avaliação não é uma ferramenta, é a única maneira de fazer desenvolvimento de IA profissional". Soa exagerado, mas em cenários críticos como auditoria de recibos, não ter avaliações é como jogar na loteria em produção; ninguém se sente seguro para realizar o deploy.
💡 Analogia: O Eval-Driven Design é como uma prova com gabarito, onde você consegue calcular quanto cada alteração aumentou a "nota final". O Vibe-Coding é como responder questões por intuição, sem saber se a mudança melhorou ou piorou o resultado. IA de nível de produção deve ser o primeiro caso.
Fluxo de implementação em três etapas do caso de auditoria de recibos da OpenAI
O OpenAI Cookbook divide todo o caso em três etapas muito claras, um fluxo que pode ser aplicado a quase qualquer aplicação de IA que envolva "entrada de imagem/documento + saída de decisão estruturada".
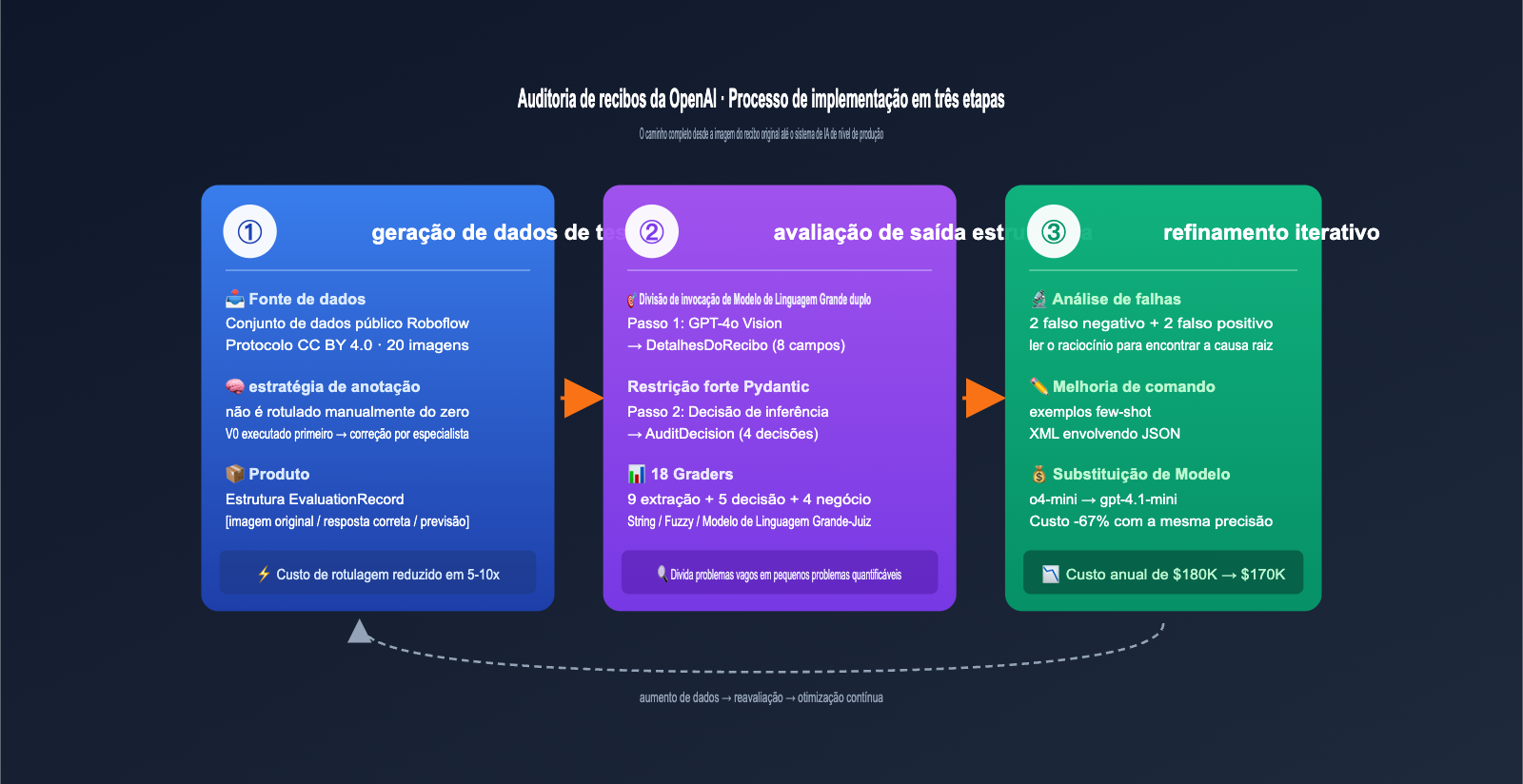
Abaixo, explico cada etapa de forma simples.
Etapa 1: Geração de dados de teste, economizando 80% do custo de anotação de forma inteligente
Se você acha que a equipe começou do zero anotando manualmente milhares de imagens de recibos, subestimou a capacidade dos engenheiros de serem eficientes. A Fractional AI usou uma estratégia muito inteligente: deixe o modelo V0 rodar primeiro e depois peça a um especialista para corrigir.
O fluxo é o seguinte: pegue 20 recibos reais de um conjunto de dados público do Roboflow (licença CC BY 4.0) e envie diretamente para uma versão simples do GPT-4o + fluxo de extração Pydantic para obter a saída V0. Em seguida, peça a um especialista financeiro para "encontrar e corrigir erros" nessa saída, em vez de digitar os dados do zero.
Esse método de "gerar primeiro, corrigir depois" aumentou a eficiência do especialista em 5 a 10 vezes, pois a maioria dos campos já foi identificada corretamente pelo V0, restando ao especialista apenas corrigir o que estava errado. O registro de avaliação (EvaluationRecord) resultante é elegante e registra "caminho da imagem original, detalhes corretos, detalhes previstos pelo modelo, decisão de auditoria correta e decisão de auditoria prevista pelo modelo", cobrindo todo o pipeline.
🔧 Dica de reutilização: Essa estratégia de anotação "V0 roda primeiro → especialista corrige" pode ser aplicada a quase todos os estágios de inicialização de aplicações de IA. Você só precisa rodar a saída V0 rapidamente através de uma plataforma de serviço proxy de API da OpenAI para concentrar o esforço do especialista na parte mais valiosa: a tomada de decisão.
Etapa 2: Avaliação de saída estruturada, Pydantic é o verdadeiro herói
Todo o sistema de IA é composto por duas invocações de LLM encadeadas; esse design de separação de responsabilidades é uma das essências do EDD.
async def extract_receipt_details(
image_path: str, model: str = "o4-mini"
) -> ReceiptDetails:
"""Passo 1: Extrair informações estruturadas do recibo da imagem"""
response = await client.responses.parse(
model=model,
input=[{"role": "user", "content": [
{"type": "input_text", "text": prompt},
{"type": "input_image", "image_url": data_url}
]}],
text_format=ReceiptDetails # Restrição forte do modelo Pydantic
)
return response.output_parsed
async def evaluate_receipt_for_audit(
receipt_details: ReceiptDetails, model: str = "o4-mini"
) -> AuditDecision:
"""Passo 2: Tomar decisão de auditoria com base em dados estruturados"""
# ... Invocar LLM para produzir o modelo Pydantic AuditDecision
Por que dividir em duas etapas? Porque os requisitos de capacidade para essas duas tarefas são completamente diferentes: a primeira etapa é "ler a imagem" (visão + extração de informações), a segunda é "julgamento lógico" (raciocínio e decisão). Misturá-las em um único comando não só confunde os limites da tarefa para o modelo, como também torna impossível depurar onde o erro ocorreu.
O design dos campos dos modelos Pydantic ReceiptDetails e AuditDecision é a parte mais valiosa deste caso:
| Modelo | Campos Chave | Significado de Negócio |
|---|---|---|
| ReceiptDetails | merchant / location / time / items / subtotal / tax / total / handwritten_notes | Todas as informações visíveis no recibo |
| AuditDecision | not_travel_related / amount_over_limit / math_error / handwritten_x / reasoning / needs_audit | 4 condições de julgamento + processo de raciocínio + conclusão final |
Preste atenção especial ao campo reasoning no AuditDecision — ele força o modelo a escrever o processo de raciocínio antes de dar a decisão final, o que é fundamental para avaliações posteriores de "cadeia de pensamento" (chain-of-thought). Observe também que needs_audit é um OR lógico dos quatro campos booleanos anteriores; esse design de "pontuar itens primeiro e sintetizar a decisão depois" permite que as métricas de avaliação sejam divididas de forma muito granular.
🚀 Dica de integração: O método
client.responses.parse()acima é a interface de saída estruturada mais recente da OpenAI, que permite restringir o formato de saída diretamente ao modelo Pydantic, eliminando quase completamente o risco de falha na análise JSON. Recomendamos o uso de plataformas de serviço proxy de API da OpenAI como a apiyi.com, pois essa interface exige versões específicas do SDK, e o gateway garante que o protocolo esteja sempre atualizado.
Etapa 3: Iteração e refinamento, 18 avaliadores tornam as mudanças quantificáveis
Esta etapa é onde o EDD realmente brilha. A equipe da Fractional AI configurou 18 métricas de avaliação independentes (graders) para o sistema de auditoria de recibos, decompondo a questão vaga de "o sistema é bom?" em 18 pequenas questões quantificáveis.
Esses 18 avaliadores são divididos em três categorias:
| Tipo de Grader | Métricas Representativas | Método de Avaliação |
|---|---|---|
| Precisão de Extração (9) | Nome do comerciante / Endereço / Correspondência do total | Correspondência exata de string / Correspondência difusa |
| Precisão da Decisão (5) | Determinação de viagem / Excesso de limite / Erro de cálculo / Reconhecimento de X manuscrito / Decisão final | Precisão de classificação binária |
| Métricas de Negócio (4) | Itens ausentes / Itens extras / Precisão dos itens / Qualidade do raciocínio | LLM-como-Juiz (nota 0-10) |
A avaliação inicial em 20 amostras encontrou 2 falsos negativos + 2 falsos positivos. Esse número parece pequeno, mas em uma escala de 1 milhão de recibos por ano, representa milhares de auditorias perdidas. A abordagem da equipe da Fractional foi extremamente técnica:
- Análise de causa raiz: Analisar o campo
reasoningde cada erro para identificar onde o modelo travou. - Ajuste direcionado do comando: Adicionar exemplos (few-shot), definir claramente "relacionado a viagens" e envolver exemplos JSON em XML.
- Executar novamente o conjunto de avaliação: Verificar se a mudança realmente corrigiu o bug sem introduzir novos.
- Experimentos de substituição de modelo: Executar o mesmo comando no o4-mini e no gpt-4.1-mini para escolher o melhor ROI.
O resultado final foi impressionante: ao mudar do o4-mini para o gpt-4.1-mini, o custo caiu 67%, reduzindo o custo anual de cerca de $180 mil para $170 mil, com a precisão praticamente inalterada. Sem um conjunto de avaliação completo, quem teria coragem de tomar essa decisão de redução de custos?
📊 Insight chave: Os 18 avaliadores não servem apenas para preencher números, mas para decompor um problema aparentemente imensurável ("a IA é precisa ou não?") em 18 problemas menores que podem ser corrigidos e medidos independentemente. Na apiyi.com, você também pode criar sistemas de avaliação semelhantes usando a API de Avaliações da OpenAI, com interfaces totalmente compatíveis com a oficial.
5 Lições de Engenharia do Caso de Auditoria de Recibos da OpenAI
Após ler o caso completo, extraí 5 lições que são universais para qualquer aplicação de IA. São experiências adquiridas com investimento real.
Lição 1: Vincule a avaliação ao dólar, não busque 100% em todas as métricas
O caso traz uma descoberta contraintuitiva: o aumento da precisão na identificação do nome do estabelecimento quase não tem impacto na decisão final de auditoria, pois as regras de auditoria não dependem do nome do local. Se a equipe se esforçar para elevar a identificação do nome de 92% para 98%, estará desperdiçando recursos de engenharia.
Por outro lado, erros na identificação do "X" manuscrito causam uma perda anual de cerca de US$ 75.000 em auditorias perdidas, sendo este o indicador de maior prioridade. Portanto, a escolha das métricas deve sempre responder a uma pergunta: "Quanto dinheiro eu economizo ao corrigir este erro?"
Lição 2: Primeiro faça funcionar com o modelo mais potente, depois pense em economizar
Na fase V0 do caso, a equipe escolheu diretamente o o4-mini, o modelo mais potente da época. Não foi porque não se importavam com o custo, mas porque sabiam que fazer um modelo incapaz funcionar é muito mais difícil do que fazer um modelo supercapacitado funcionar de forma barata. Primeiro, valide a lógica de negócio e estabeleça um sistema de avaliação completo; só depois faça experimentos de substituição de modelo. Essa ordem não pode ser invertida.
Lição 3: Separe a extração da tomada de decisão, não tente criar um comando universal
Muitos iniciantes pensam: "Seria tão barato obter a conclusão de 'precisa de auditoria' diretamente da imagem em uma única chamada!". Mas esse design tem dois defeitos fatais: impossibilidade de depuração (se der erro, você não sabe se foi na leitura da imagem ou na lógica de julgamento) e falta de reusabilidade (o resultado da extração só serve para essa decisão). Dividir em duas etapas pode parecer uma chamada de API a mais, mas, na prática, aumenta a manutenibilidade de todo o sistema em uma ordem de grandeza.
Lição 4: A avaliação por cadeia de pensamento (Chain-of-Thought) detecta o risco de "acertar pelos motivos errados"
O campo reasoning, que parece redundante no AuditDecision, foi usado durante a avaliação para identificar uma situação perigosa: o modelo deu a resposta final correta, mas o processo de raciocínio estava errado. Esse tipo de "acerto por sorte" não aparece em amostras pequenas, mas causa falhas em larga escala assim que a distribuição dos dados muda ligeiramente. Forçar a saída do raciocínio e usar um LLM-as-Judge para avaliar a qualidade desse raciocínio é um seguro indispensável para aplicações de IA em produção.
Lição 5: O custo de rotulagem pode ser reduzido com engenharia
Não se deixe intimidar pelo estereótipo de que "projetos de IA exigem volumes massivos de dados rotulados". A estratégia de usar 20 exemplos + correções de especialistas sobre a saída da V0 já é suficiente para sustentar um conjunto de avaliação útil. O segredo é garantir que o conjunto de avaliação seja consistente com a distribuição real dos dados de negócio, em vez de perseguir a quantidade de amostras. A experiência da Fractional foi usar a saída inicial da V0 como "rotulagem semente", o que aumentou a eficiência em 5 a 10 vezes em comparação com a rotulagem manual do zero.
Considerações para replicar o caso de auditoria de recibos da OpenAI no Brasil
Desenvolvedores que desejam replicar este cookbook precisam resolver três questões: é possível acessar os novos modelos como o o4-mini / gpt-4.1-mini?, é possível usar a interface mais recente responses.parse?, e é possível acessar o endpoint da API de Evals?.
A conexão direta com a OpenAI no Brasil pode ser instável, especialmente com interfaces de imagem, que, devido ao tamanho do payload, possuem uma taxa de falha maior que as de texto. Usar um serviço proxy de API oficial resolve esses três problemas praticamente de uma vez. A única alteração necessária no código é a base_url:
from openai import AsyncOpenAI
client = AsyncOpenAI(
base_url="https://vip.apiyi.com/v1", # A única linha que precisa ser alterada
api_key="Sua chave API da APIYI"
)
# Todo o código subsequente é idêntico ao do cookbook
response = await client.responses.parse(
model="gpt-4.1-mini",
input=[...],
text_format=ReceiptDetails
)
Essa é a diferença fundamental entre um "proxy oficial da OpenAI" e uma "API compatível com OpenAI": o primeiro garante que as interfaces estejam sincronizadas com a oficial, enquanto o segundo apenas suporta as interfaces básicas, podendo não oferecer suporte a capacidades avançadas como responses.parse ou a API de Evals. Ao replicar casos oficiais como este cookbook, escolher um proxy oficial evita uma série de problemas de compatibilidade.
FAQ sobre o caso de auditoria de recibos da OpenAI
Q1: Este método só pode ser usado para recibos?
De jeito nenhum. O design orientado a avaliação (Eval-Driven Design) aplica-se a qualquer cenário onde a "entrada é relativamente aberta e a saída requer uma decisão estruturada": revisão de contratos, triagem de imagens médicas, controle de qualidade de atendimento ao cliente, triagem de currículos e detecção de fraudes podem utilizar este fluxo de três etapas. O que não muda é o design do esquema Pydantic e do avaliador (grader).
Q2: 18 graders não é muito para uma equipe pequena?
Você pode começar com 5 a 6 graders principais, como a precisão da decisão final e a precisão da extração de campos-chave. O importante não é a quantidade, mas que cada grader corresponda a um padrão de falha específico. Recomendamos executar uma pequena amostra com o GPT-4o no console do apiyi.com e, após validar o fluxo de negócio, expandir as dimensões de avaliação.
Q3: Usar o o4-mini diretamente na V0 não fica muito caro?
Na fase V0, o volume de chamadas geralmente é de dezenas a centenas, com um custo total de poucos dólares a algumas dezenas de dólares, o que é perfeitamente suportável. Onde você realmente economiza é no ambiente de produção com milhões de chamadas; nessa altura, você já terá um conjunto de avaliação completo para realizar experimentos de substituição de modelos, assim como no caso em que a transição de o4-mini para gpt-4.1-mini reduziu os custos em 67%.
Q4: Como é o desempenho do GPT-4o Vision ao ler recibos manuscritos em chinês?
A precisão para recibos impressos em inglês é muito alta (95%+), e para impressos em chinês também é boa (90%+). Já para manuscritos em chinês, depende da clareza da caligrafia. Sugerimos usar 100 amostras reais para criar um conjunto de avaliação, em vez de confiar apenas em vídeos de demonstração. O custo de chamar o GPT-4o Vision via API oficial é o mesmo, sendo ideal para experimentos de avaliação em larga escala.
Q5: Se eu não tiver permissão da Evals API, posso rodar este cookbook?
Sim. A Evals API serve principalmente para hospedar a configuração e o gerenciamento dos graders no OpenAI; a lógica de avaliação real pode ser executada por você mesmo em Python com a mesma eficácia. As funções de grader no cookbook são todas de código aberto, basta copiar e usar localmente. Se o volume do seu negócio aumentar, considere migrar para a Evals gerenciada.
Q6: Qual a diferença entre usar este caso via APIYI e a oficial?
O protocolo de interface, as versões do modelo e o suporte a parâmetros são totalmente sincronizados com a OpenAI oficial; este é o compromisso central do nosso "serviço proxy de API". A diferença reside principalmente na rede: conexões diretas com a OpenAI a partir da China frequentemente sofrem falhas de handshake SSL e timeouts, enquanto o gateway do serviço proxy de API é implantado em data centers locais, o que melhora significativamente a estabilidade de interfaces de imagem. Isso é crucial para executar tarefas de avaliação de longa duração.
Conclusão
O caso de auditoria de recibos da OpenAI merece ser estudado repetidamente porque decompõe a proposta abstrata de "como usar IA para resolver um problema de negócio real" em três etapas, 18 métricas de avaliação e práticas de engenharia quantificáveis em dólares. Este é o modelo de engenharia de IA que mais falta na comunidade atualmente.
Se você está criando qualquer aplicação de IA que envolva "entrada de documentos/imagens e saída de decisões estruturadas", recomendamos fortemente que execute este cookbook na íntegra. Não apenas leia, coloque a mão na massa; o verdadeiro valor do design orientado a avaliação só é sentido no momento em que você vê as métricas mudarem. Recomendamos reproduzir o caso diretamente através de uma plataforma de serviço proxy de API como o apiyi.com, o que poupa todo o trabalho de depuração de ambiente e permite que você concentre sua energia na metodologia em si.
Ao gravar o conceito de "orientado a avaliação" no seu fluxo de desenvolvimento, seu sistema de IA deixa de ser um brinquedo que "parece funcionar" e se torna um produto de engenharia "pronto para produção e com ROI calculado". A diferença entre os dois pode ser de US$ 75.000.
📌 Autor: Equipe APIYI — Acompanhamos de perto as práticas de engenharia de APIs multimodais da OpenAI / Anthropic / Google. Para mais interpretações práticas de cookbooks e guias de acesso via serviço proxy de API, consulte a central de documentos em apiyi.com.