Recentemente, um projeto open source no GitHub chamado ARIS-Code alcançou silenciosamente mais de 8.400 estrelas e 783 forks. Ele foi desenvolvido pelo programador wanshuiyin, baseado na versão open source do Claude Code, e seu nome completo é Auto-Research-In-Sleep (Pesquisa Automática Durante o Sono). Isso não é apenas marketing — ele realmente permite que o Claude Code execute experimentos, pesquise literatura e edite artigos automaticamente enquanto você dorme, fazendo com que, ao acordar, seu progresso de trabalho tenha avançado significativamente.
As discussões que o ARIS-Code gerou na comunidade acadêmica são particularmente notáveis: três estudos de caso de artigos da comunidade divulgados pelo autor mostram que os rascunhos produzidos atingiram uma pontuação de 7-8/10 em revisões por IA, tendo sido submetidos a conferências de topo em Ciência da Computação, como a AAAI 2026 e a IEEE TGRS. Isso significa que a pesquisa científica totalmente automatizada por IA não está mais apenas no nível de demonstração, mas possui capacidade real de produzir artigos para submissão.
Neste artigo, faremos uma análise profunda da arquitetura central do ARIS-Code, suas 42 habilidades (Skills) integradas e a forma específica de conectá-lo aos modelos Claude através de um serviço proxy de API no Brasil, ajudando você a decidir se esta ferramenta se encaixa no seu fluxo de trabalho científico.
🎯 Dica importante: Como o ARIS-Code é uma iteração baseada na versão open source do Claude Code, seu executor só pode ser conectado a modelos da série Claude (Sonnet/Opus/Haiku). Ele não suporta as séries GPT ou Gemini como executor principal. Recomendamos conectar os modelos Claude através da plataforma APIYI (apiyi.com), que é compatível com o protocolo nativo da Anthropic, oferece acesso estável no Brasil, cobrança por uso e não exige cartão de crédito internacional.
O que é o projeto ARIS-Code: Auto-Research-In-Sleep
O ARIS (Auto-Research-In-Sleep) é um sistema de fluxo de trabalho de pesquisa autônomo voltado para pesquisadores acadêmicos de ML/IA. O projeto está disponível no GitHub: github.com/wanshuiyin/Auto-claude-code-research-in-sleep. Seu objetivo de design é muito claro: permitir que o pesquisador complete todo o processo — "revisão de literatura → geração de ideias → execução de experimentos → redação de artigos → resposta a revisões (Rebuttal)" — com o mínimo de intervenção humana, libertando o pesquisador do trabalho braçal repetitivo.
A essência do ARIS-Code é uma biblioteca de metodologias. Todo o sistema consiste em arquivos Markdown puros (SKILL.md); não há frameworks para instalar, bancos de dados para manter ou Docker para configurar. Cada Skill é uma instrução de fluxo de trabalho que pode ser lida por qualquer agente de LLM. Portanto, você pode trocar o executor do Claude Code por Codex CLI, OpenClaw, Cursor, Trae ou qualquer outra ferramenta que suporte o modo Agente, e o fluxo de trabalho continuará funcionando.
Esse design de "dependência zero e sem bloqueio" é o maior diferencial do ARIS-Code em relação a outras ferramentas de IA para pesquisa. Essencialmente, ele torna o processo científico "explícito" em forma de engenharia de comando, em vez de encapsulá-lo em uma ferramenta de caixa preta. Isso é extremamente significativo para pesquisadores, pois significa que o fluxo de trabalho é legível, modificável e transferível, sem ficar preso a um produto comercial específico.
Vale ressaltar que o repositório do ARIS-Code já acumulou 719 commits e o projeto continua em rápida evolução. Nos últimos três meses, foram adicionadas várias Skills de alto valor, como paper-talk (geração de apresentações para conferências), resubmit-pipeline (fluxo de trabalho para ressubmissão após rejeição) e kill-argument (geração de contra-argumentos adversários), tornando todo o ecossistema muito ativo.
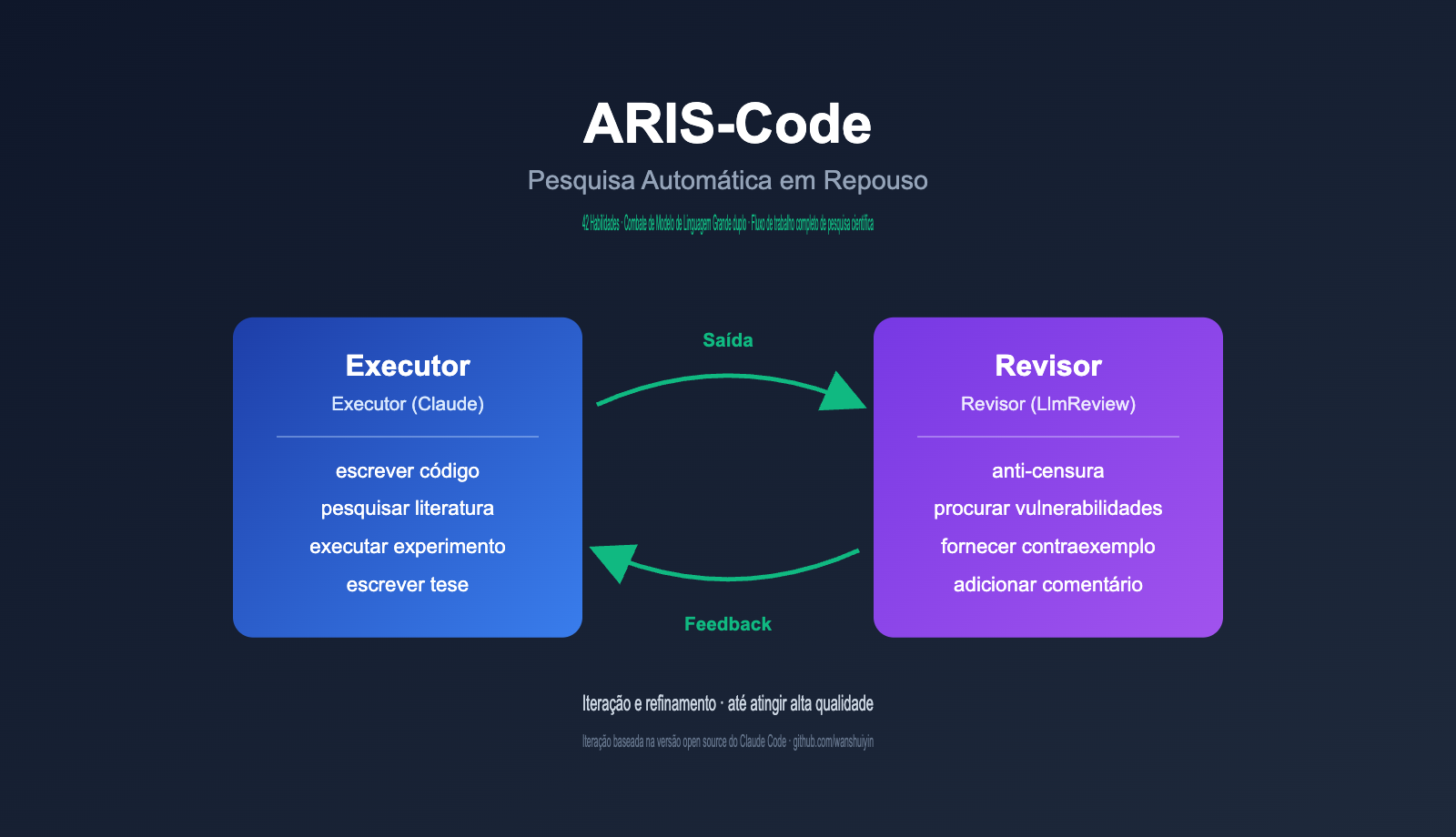
Arquitetura Central do ARIS-Code: Revisão Adversarial de Modelo Duplo Executor-Reviewer
O valor de engenharia mais crítico do ARIS-Code reside na sua arquitetura adversarial de modelo duplo, que é a diferença fundamental entre ele e outros assistentes de pesquisa no mercado. O autor do projeto apresenta uma observação muito profunda no README: a auto-revisão de modelo único possui fraquezas estruturais, pois quando o mesmo modelo executa a tarefa e revisa o resultado, ele reproduz sistematicamente seus próprios pontos cegos, formando uma armadilha de otimização local.
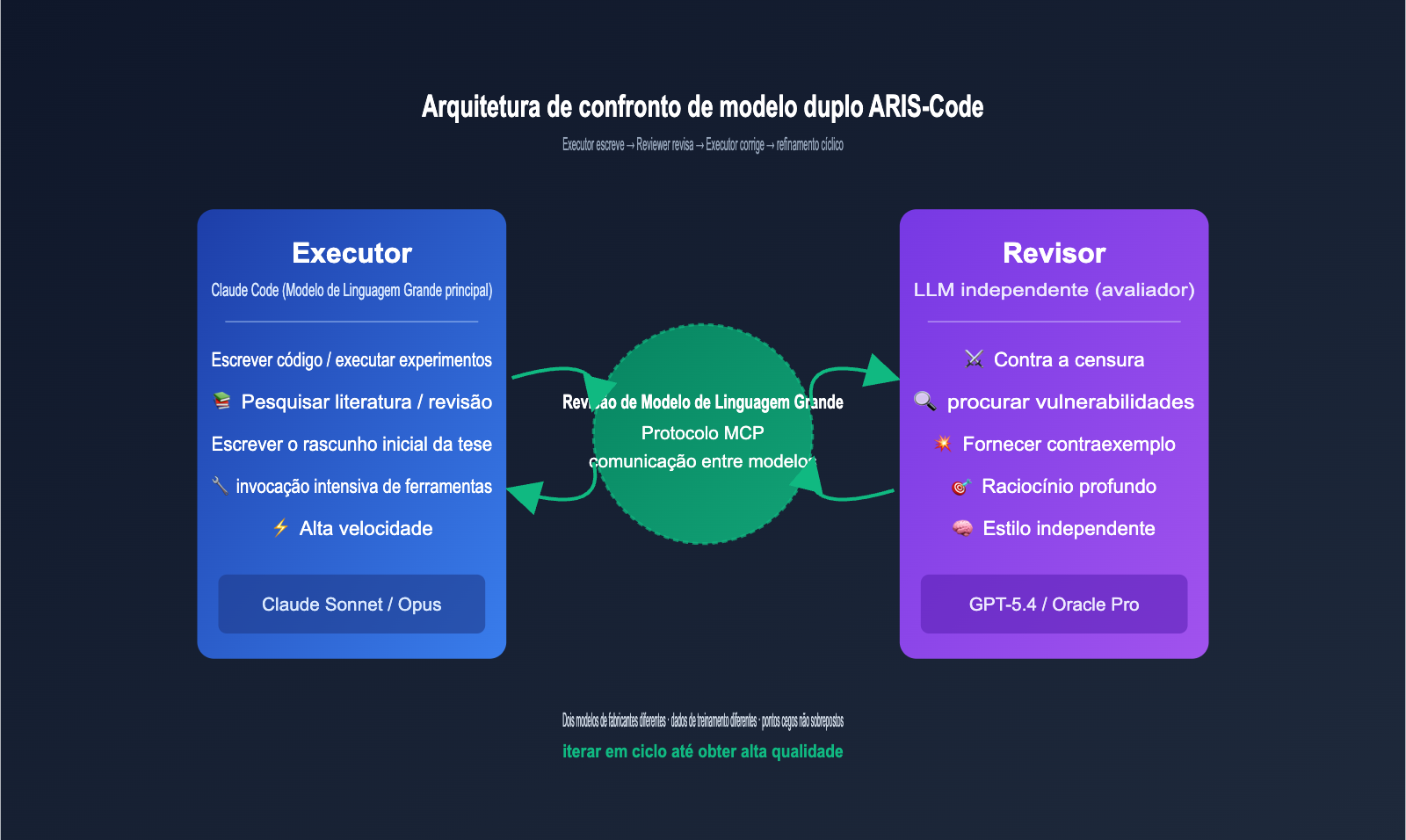
A solução proposta pelo ARIS-Code é delegar o poder de revisão a um modelo completamente independente. A divisão de papéis é a seguinte:
| Papel | Seleção de Modelo | Definição de Responsabilidade | Tendência de Capacidade Recomendada |
|---|---|---|---|
| Executor | Claude Sonnet / Opus | Execução principal: escrever código, pesquisar literatura, rodar experimentos, redigir artigos | Alta velocidade, contexto longo, invocação de ferramentas estável |
| Reviewer | GPT-5.4 (Codex MCP) / Oracle Pro | Revisão adversarial: encontrar vulnerabilidades, questionar conclusões, propor contraexemplos | Raciocínio profundo, crítico, estilo independente |
| Mecanismo de Coordenação | Cadeia de ferramentas LlmReview | Comunicação entre modelos, persistência de estado | Passagem transparente via protocolo MCP |
Todo o fluxo de trabalho pode ser resumido em um ciclo simples: Executor escreve → Reviewer avalia → Executor corrige → nova avaliação e correção, até que o Reviewer dê o veredito de aprovação. Este ciclo é eficaz porque os dois modelos vêm de fabricantes diferentes, possuem dados de treinamento distintos e estilos de raciocínio diferentes, garantindo que seus pontos cegos não se sobreponham.
Para evitar que alucinações de LLM contaminem as conclusões científicas, o ARIS-Code também projetou uma cadeia de auditoria de evidências em várias camadas: experiment-audit (integridade do código) → result-to-claim (resultado para afirmação) → paper-claim-audit (auditoria de afirmação do artigo) → citation-audit (verificação de citações). Cada camada possui um veredito JSON independente e um hash SHA256 para verificação de reprodutibilidade; esse rigor de engenharia é bastante raro em ferramentas de IA para pesquisa científica.
🔧 Sugestão de configuração: Se você deseja reproduzir totalmente a arquitetura de modelo duplo do ARIS-Code, recomendamos obter as chaves API do Claude e da série GPT simultaneamente através do serviço proxy de API da APIYI (apiyi.com). Uma única plataforma atende a dois conjuntos de interfaces, sem a necessidade de abrir contas no exterior ou vincular cartões de crédito separadamente.
ARIS-Code: 42 Skills integradas para todo o pipeline de pesquisa
O que mais impressiona no ARIS-Code são suas mais de 42 Skills integradas. Essas Skills não são pequenas ferramentas isoladas, mas sim um pipeline que cobre todo o ciclo de vida da pesquisa científica. Classifiquei-as por estágio do fluxo de trabalho abaixo:
| Estágio do Fluxo de Trabalho | Skills Representativas | Capacidade Principal |
|---|---|---|
| Descoberta de Ideias | research-lit / novelty-check / idea-creator / idea-discovery | Busca de literatura em múltiplas fontes, verificação de novidade entre modelos, geração de 8-12 ideias candidatas |
| Experimentação | experiment-bridge / experiment-queue / run-experiment | Revisão de código → implantação em GPU → orquestração de múltiplas sementes → tratamento automático de OOM |
| Revisão Automática | auto-review-loop / research-review / experiment-audit | 4 rodadas de melhoria iterativa, revisão por pares estruturada, verificação de integridade de código |
| Escrita de Artigos | paper-writing / paper-claim-audit / proof-checker / citation-audit | Narrativa → LaTeX → PDF, auditoria de afirmações, verificação de provas, verificação de citações |
| Resposta a Rebuttal | rebuttal | Análise de comentários de revisores → redação de resposta → testes de estresse |
| Meta-capacidades | research-wiki / meta-optimize / deepxiv | Base de conhecimento persistente, otimização de ciclo externo, fontes de literatura alternativas |
A Skill mais prática é a experiment-bridge, que conecta "revisão de código → implantação remota em GPU → início de experimento → coleta de resultados" em um único pipeline. Quando o Reviewer sugere "aqui é necessário fazer um experimento de ablação", o Executor escreve automaticamente o script, faz rsync para o nó de GPU, inicia o treinamento, monitora os logs e coleta os resultados, sem que o pesquisador precise intervir manualmente.
Outra Skill que merece destaque é a citation-audit, que elimina a maior dor de cabeça ao escrever artigos com LLMs — a alucinação de citações — conectando-se a bancos de dados reais como DBLP e CrossRef. Cada BibTeX vem de um banco de dados real, não inventado pelo modelo. Este é um requisito básico para a escrita acadêmica; qualquer citação fictícia pode levar à rejeição direta do artigo.
Os pesquisadores também apreciam muito a research-wiki, uma base de conhecimento persistente entre sessões que acumula notas de leitura, rascunhos de ideias e registros de experimentos fracassados, formando uma memória de pesquisa privada em constante crescimento. Quando você retorna a uma linha de pesquisa após três meses, não precisa reler todos os artigos relacionados; o assistente de IA já preservou o contexto para você.
💡 Dica de uso: Chamar qualquer uma das Skills consome muitos tokens da API do Claude, especialmente em tarefas de geração de texto longo como a escrita de artigos (paper-writing). Recomendamos acessar o modelo Claude via apiyi.com, pois a plataforma suporta cobrança por uso e oferece monitoramento completo do consumo de tokens, facilitando a estimativa de custos por artigo.
Guia completo de configuração: Conectando o ARIS-Code ao APIYI
Como o executor do ARIS-Code é baseado na versão open source do Claude Code, ele aceita apenas o protocolo de API nativo da Anthropic. Isso significa que modelos das séries GPT e Gemini não podem ser usados como Executor. Esta é uma restrição rígida e o ponto de maior confusão para muitos desenvolvedores durante a primeira implantação.
O processo de configuração para acessar modelos Claude via APIYI é muito simples e pode ser resumido em 5 etapas:
# Passo 1: Clonar o repositório do projeto
git clone https://github.com/wanshuiyin/Auto-claude-code-research-in-sleep
cd Auto-claude-code-research-in-sleep
# Passo 2: Instalar as Skills no diretório de configuração local do Claude Code
mkdir -p ~/.claude/skills/
cp -r skills/* ~/.claude/skills/
# Passo 3: Configurar o endereço do serviço proxy de API da APIYI (passo fundamental)
export ANTHROPIC_BASE_URL="https://vip.apiyi.com"
export ANTHROPIC_AUTH_TOKEN="Sua chave API da APIYI"
# Passo 4: Iniciar o Claude Code
claude
# Passo 5: Invocar qualquer Skill dentro do Claude Code
# Exemplo: /research-pipeline "factorized gap in discrete diffusion LMs"
O ponto mais crítico aqui é o Passo 3, onde definimos a variável de ambiente ANTHROPIC_BASE_URL. Ela instrui o Claude Code a não solicitar o endpoint oficial da Anthropic, mas sim o gateway de proxy. A interface desse gateway é totalmente compatível com o protocolo nativo da Anthropic, portanto, as Skills integradas ao ARIS-Code não precisam de nenhuma modificação no código; todos os recursos, incluindo chamadas de ferramentas, streaming de saída e cadeias de pensamento (thinking), são transmitidos de forma transparente.
Se você também precisar implantar o lado do Reviewer (Codex MCP), o processo é:
# Instalar o Codex MCP para o lado de revisão
npm install -g @openai/codex
codex setup # Aqui também é possível inserir o endereço do proxy para modelos GPT
claude mcp add codex -s user -- codex mcp-server
Para pesquisadores que desejam replicar totalmente os efeitos de nível de artigo científico do ARIS-Code, o projeto também oferece uma solução de acesso Oracle MCP ao GPT-5.4 Pro como um Reviewer avançado. Esta solução é muito útil na fase de finalização de artigos sérios, pois a profundidade crítica e a capacidade de construção de contraexemplos da versão Pro são significativamente superiores à versão básica.
🚀 Solução de acesso unificado: A plataforma APIYI (apiyi.com) suporta simultaneamente a série Claude (Sonnet 4.5/Opus 4), a série GPT (GPT-5/o4), a série Gemini (Gemini 3 Pro) e outros modelos convencionais. Uma única chave API pode conduzir tanto o Executor quanto o Reviewer do ARIS-Code, o que é muito conveniente para a gestão de custos e consolidação de registros de invocação de equipes de pesquisa.
Níveis de esforço do ARIS-Code e estratégias de configuração de GPU
O ARIS-Code oferece 4 níveis de Effort Level para equilibrar custo e qualidade, um design altamente voltado para a engenharia. Diferentes estágios de pesquisa exigem níveis de profundidade muito distintos; na fase inicial de exploração, não há necessidade de gastar muitos tokens, enquanto na fase final de submissão, é necessário levar a qualidade ao extremo.
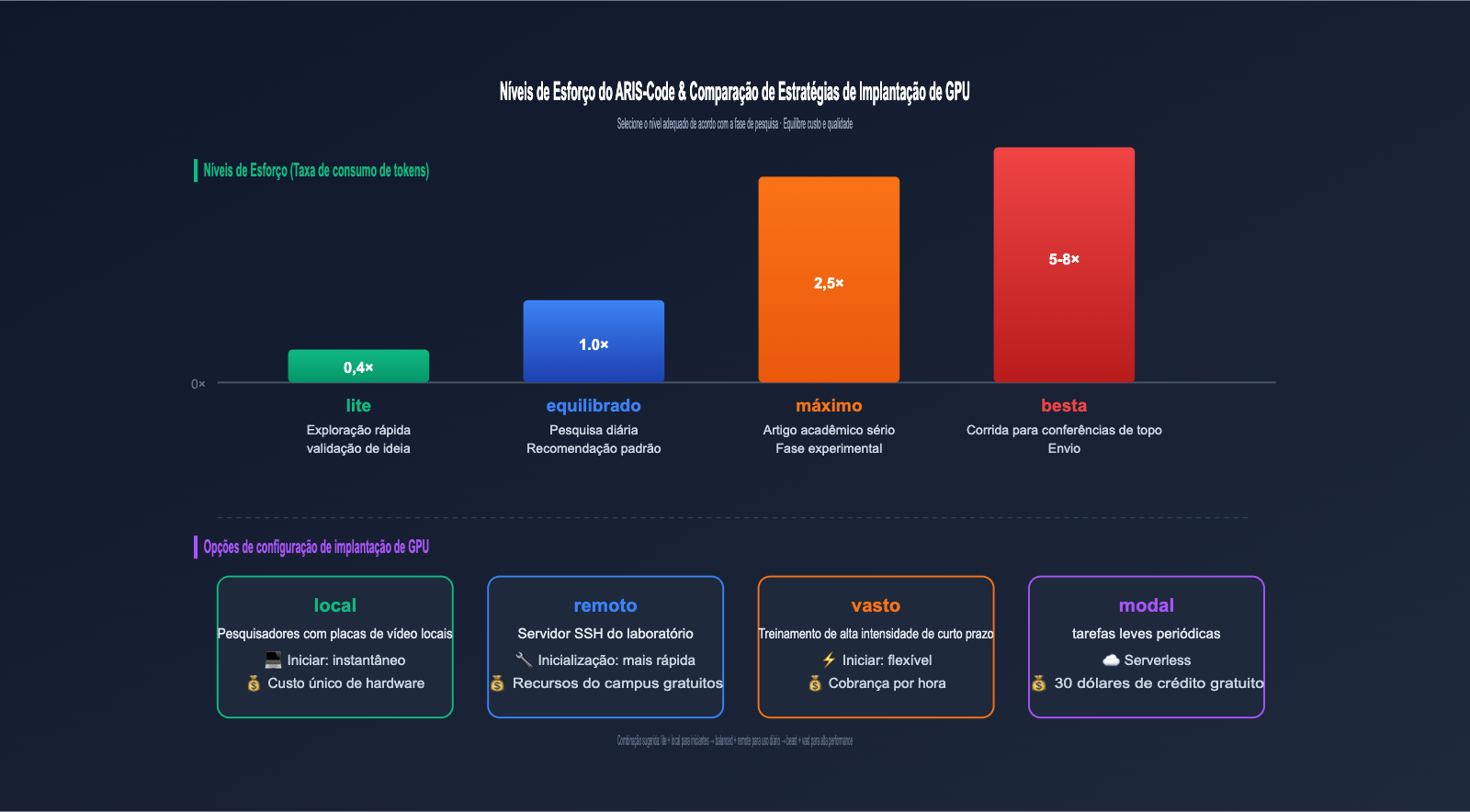
| Effort Level | Multiplicador de Tokens | Cenário de aplicação | Estimativa por invocação |
|---|---|---|---|
| lite | 0.4× | Exploração rápida, validação de ideias | Muito baixo |
| balanced | 1.0× | Fluxo de pesquisa diário padrão | Padrão |
| max | 2.5× | Fase de experimentos de artigos sérios | Médio-alto |
| beast | 5-8× | Sprint para conferências, Modo de submissão | Alto |
Para GPU, o ARIS-Code também oferece 4 opções de configuração, atendendo tanto quem prefere rodar localmente quanto quem prefere a nuvem:
| Configuração de GPU | Cenário de aplicação | Característica de custo |
|---|---|---|
| local | Pesquisadores com placa de vídeo local | Custo de hardware único |
| remote | Servidor SSH de laboratório | Recursos acadêmicos gratuitos |
| vast | Treinamento de alta intensidade a curto prazo | Cobrança por hora, flexível |
| modal | Tarefas leves periódicas | Serverless, 30 dólares de crédito gratuito |
💰 Sugestão de controle de custos: Se você está começando a experimentar o ARIS-Code, recomendo usar lite + local primeiro para validar o fluxo, direcionando a invocação do modelo pelo proxy apiyi.com para facilitar o cálculo do uso de tokens. Após estabilizar o processo, suba para o modo max ou beast para pesquisas sérias; isso evita desperdiçar custos elevados de tokens devido a erros de configuração iniciais.
Fluxo de trabalho prático com ARIS-Code: De uma frase a um artigo científico
O que torna o ARIS-Code realmente impressionante é o seu pipeline de ponta a ponta /research-pipeline. Este Skill encadeia todas as etapas mencionadas anteriormente em um único comando. Você só precisa fornecer uma descrição da direção da pesquisa e o sistema gerará automaticamente um rascunho em 8 a 24 horas.
A forma típica de invocação é a seguinte:
# Cenário 1: Direção totalmente nova, começando do zero
/research-pipeline "factorized gap in discrete diffusion LMs"
# Cenário 2: Melhorar um artigo existente
/research-pipeline "improve method X" \
--ref-paper https://arxiv.org/abs/2406.04329 \
--base-repo https://github.com/org/project
# Cenário 3: Apenas Rebuttal
/rebuttal "paper/ + reviews" --venue ICML --char-limit 5000
Durante a execução, o ARIS-Code segue um processo metódico: revisão de literatura → geração de ideias → verificação de novidade → design experimental → agendamento de GPU → coleta de resultados → redação do artigo → auditoria de citações → formatação. Quando encontra pontos de decisão ambíguos, ele pausa e aguarda um checkpoint humano. Na configuração padrão, --AUTO_PROCEED false permite que você intervenha manualmente após cada rodada de feedback do revisor.
O ARIS-Code também oferece um parâmetro style-ref muito útil. Você pode especificar um artigo de referência de estilo (por exemplo, o melhor artigo histórico da mesma conferência) e o sistema imitará sua estrutura e ritmo narrativo, sem copiar parágrafos específicos. Para pesquisadores que buscam "taxa de aceitação em conferências", isso é quase uma vantagem desleal, já que as exigências implícitas dos revisores de conferências de elite sobre o estilo do artigo são muitas vezes mais difíceis de dominar do que o conteúdo em si.
Outro detalhe técnico que vale a pena notar é que o ARIS-Code integra sincronização bidirecional com o Overleaf, monitoramento de curvas de treinamento no W&B, notificações móveis via Lark/Feishu e outros sistemas externos. Quando um experimento na GPU atinge um ponto de inflexão crítico, você recebe uma notificação imediata no celular, permitindo que você "faça pesquisa enquanto dorme".
📊 Dados de desempenho: Três casos de artigos da comunidade divulgados pelo autor do projeto mostram que os artigos produzidos pelo ARIS-Code alcançaram notas de 7-8/10 em avaliações de IA (conferências de CS, AAAI 2026, IEEE TGRS). No entanto, o autor alerta explicitamente que revisores humanos trazem perspectivas que os sistemas de revisão por IA não conseguem captar, portanto, a ferramenta não substitui totalmente a supervisão humana.
FAQ: Perguntas frequentes sobre o ARIS-Code
Q1: Por que o ARIS-Code não pode usar o GPT-5 como Executor?
Como o ARIS-Code é um fork iterado da versão open source do Claude Code, sua camada de execução está totalmente vinculada ao protocolo de API nativo da Anthropic, incluindo o formato de chamada de ferramentas, formato de saída em streaming e formato de cadeia de pensamento. Se quiser trocar o executor, seria necessário usar uma distribuição do OpenClaw ou Codex CLI, mas isso já não seria o ARIS-Code original. Recomendamos acessar o modelo Claude diretamente via apiyi.com, que é a solução mais simples.
Q2: Quantos tokens são necessários para rodar um artigo completo?
No modo beast, uma execução completa do /research-pipeline consome cerca de 5 a 15 milhões de tokens (entrada + saída), o que, convertido para os preços do Claude Sonnet, fica na faixa de algumas dezenas a centenas de reais. O modo balanced pode reduzir esse consumo para 2 a 5 milhões de tokens. O custo específico depende da complexidade do experimento e das rodadas de iteração.
Q3: É possível usar o ARIS-Code sem uma GPU local?
Com certeza. O ARIS-Code foi projetado com dois modos de GPU em nuvem: vast e modal. O modal ainda oferece 30 dólares em créditos gratuitos, o que é mais do que suficiente para rodar experimentos leves. Se você estiver fazendo apenas artigos teóricos (/proof-writer + /formula-derivation), nem precisará de GPU.
Q4: O Revisor precisa ser o GPT-5.4 na arquitetura de modelo duplo?
Não é obrigatório. O projeto suporta a substituição por GLM, MiniMax, Kimi ou qualquer outro modelo compatível com o protocolo OpenAI. Recomendamos obter vários modelos candidatos a revisor através de plataformas de agregação como a apiyi.com, o que facilita a realização de testes A/B para encontrar o LLM crítico mais adequado à sua área. Alguns pesquisadores relataram que, em artigos de raciocínio matemático, o Gemini 3 Pro funciona surpreendentemente bem como revisor, enquanto o GPT-5.4 continua sendo a escolha preferencial para artigos de otimização de engenharia.
Q5: O ARIS-Code é adequado para estudantes de graduação ou iniciantes?
É mais adequado para pós-graduandos e pesquisadores com certa experiência. O motivo é que a qualidade da saída depende muito do julgamento do pesquisador sobre a área; por exemplo, quando um revisor apresenta um contraexemplo, você precisa julgar se aquilo é realmente uma falha crítica ou um problema irrelevante. Iniciantes sem experiência podem ser facilmente desviados pela IA.
Q6: O que fazer se a rede estiver instável ao rodar o ARIS-Code no Brasil?
A conexão direta com a interface oficial da Anthropic pode sofrer redefinições ou timeouts, o que faria com que tarefas longas do research-pipeline falhassem no meio do caminho. Uma solução madura é alternar a ANTHROPIC_BASE_URL para um serviço proxy de API implantado localmente ou em um servidor estável. Dessa forma, o ARIS-Code pode rodar continuamente por 8 horas no modo beast sem ser interrompido por oscilações de rede, o que é crucial para experimentos contínuos.
Resumo
O surgimento do ARIS-Code valida uma tendência importante: as ferramentas de produtividade científica na era dos Modelos de Linguagem Grande estão evoluindo de "assistentes pontuais" para a "automação completa de fluxos de trabalho". Sua arquitetura de modelo duplo Executor-Reviewer, os 42 Skills de fluxo de trabalho e o design em Markdown com dependência zero formam, juntos, uma estrutura metodológica extremamente madura.
Para pesquisadores no Brasil, o maior obstáculo para adotar o ARIS-Code não é a curva de aprendizado técnica, mas a estabilidade na invocação dos modelos Claude. Recomendamos o acesso à série de modelos Claude através da plataforma apiyi.com, aproveitando simultaneamente a série de modelos GPT para a função de Reviewer. Assim, uma única plataforma pode cobrir todas as necessidades de modelos do fluxo de trabalho do ARIS-Code, tornando o faturamento e a centralização dos logs de invocação muito mais práticos. Além disso, a estabilidade dos nós de IDC garante que o cenário principal de "rodar experimentos enquanto dorme" não seja interrompido por problemas de rede.
Se você está se preparando para submeter artigos a conferências de alto nível, ou tem uma linha de pesquisa que deseja validar, mas não tem tempo para iterações manuais, vale a pena dedicar um fim de semana para testar o ARIS-Code — se você acordar e encontrar um primeiro rascunho pronto, esse investimento de tempo terá valido muito a pena.
📌 Autor: Equipe APIYI — Focada a longo prazo em serviços de API para Modelos de Linguagem Grande e ecossistema de desenvolvedores. Para mais casos de uso de integração multimodal com Claude/GPT/Gemini, consulte a central de documentação em apiyi.com.