プロジェクトでOpenAIのGPT、AnthropicのClaude、GoogleのGeminiを同時に使用していて、モデルごとにSDKが異なり、APIの形式もバラバラ、エラーハンドリングの方法まで違う……そんな悩みを抱えたことはありませんか?モデルを一つ変えるだけで、コードを大幅に書き直さなければならない状況です。
これこそが、LiteLLMが解決する課題です。簡単に言えば、LiteLLMはAI大規模言語モデルの「万能翻訳機」です。一つの呼び出し方(OpenAI形式)を覚えるだけで、100以上のモデルベンダーそれぞれのAPI形式に自動で変換してくれます。
コアバリュー: 本記事を読めば、LiteLLMとは何か、なぜAIエージェントフレームワークがこぞって採用しているのか、そして5分で使い始める方法が理解できます。
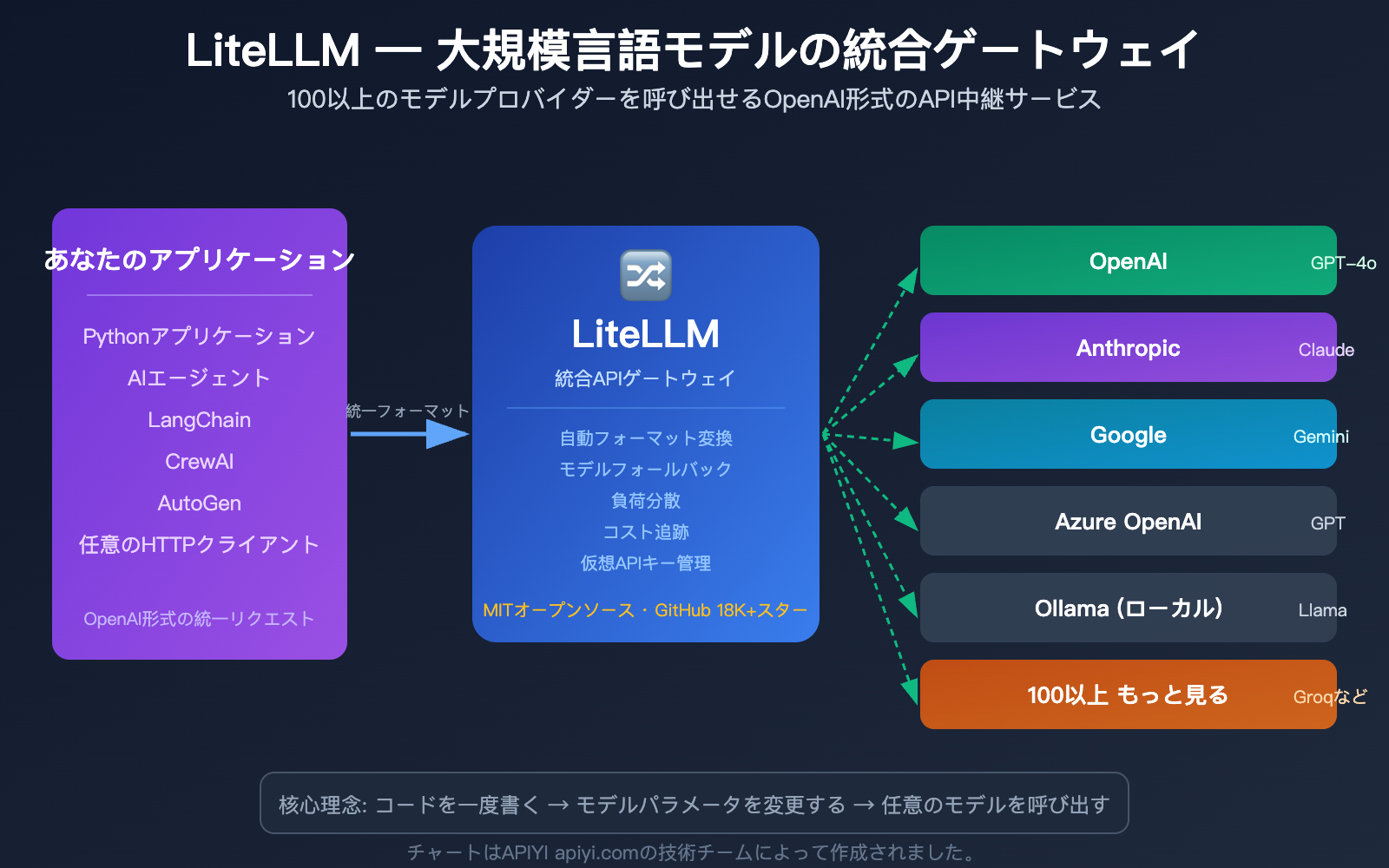
LiteLLMとは:5つのコアコンセプト
使い始める前に、LiteLLMの5つのコアコンセプトを分かりやすく解説します。これらを理解しておけば、その後の操作は非常にスムーズになります。
| コアコンセプト | 分かりやすい説明 | 解決する課題 |
|---|---|---|
| 統一インターフェース | すべてのモデルを同じ方法で呼び出す | モデルごとにSDKを覚える必要がない |
| Provider(プロバイダー) | OpenAIやAnthropicなどのモデルベンダー | ベンダーごとの接続管理 |
| Fallback(故障転送) | モデルAが停止しても自動的にモデルBへ切り替え | サービスの継続性を保証 |
| Virtual Key(仮想キー) | チームメンバーに「サブアカウント」を発行 | 利用量と予算の管理 |
| Proxy(プロキシゲートウェイ) | 独立して動作する中継サーバー | 言語やツールを選ばず接続可能 |
LiteLLMが解決する課題とは?
LiteLLMがない世界を想像してみてください。
OpenAIの呼び出し:
from openai import OpenAI
client = OpenAI(api_key="sk-xxx")
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": "こんにちは"}]
)
Anthropicの呼び出し:
import anthropic
client = anthropic.Anthropic(api_key="sk-ant-xxx")
response = client.messages.create(
model="claude-sonnet-4-20250514",
max_tokens=1024, # Anthropicでは必須
messages=[{"role": "user", "content": "こんにちは"}]
)
Google Geminiの呼び出し:
import google.generativeai as genai
genai.configure(api_key="AIza-xxx")
model = genai.GenerativeModel("gemini-2.0-flash")
response = model.generate_content("こんにちは")
お分かりでしょうか?3つのモデルに対して、3つのSDK、3つの書き方です。もしプロジェクトでモデルの切り替えに対応しようとすると、コード内は if provider == "openai"... elif provider == "anthropic"... といった条件分岐だらけになってしまいます。
LiteLLMがあれば:
import litellm
# OpenAIの呼び出し
response = litellm.completion(model="gpt-4o", messages=[{"role": "user", "content": "こんにちは"}])
# Anthropicの呼び出し —— 同じ書き方
response = litellm.completion(model="anthropic/claude-sonnet-4-6", messages=[{"role": "user", "content": "こんにちは"}])
# Geminiの呼び出し —— これも同じ書き方
response = litellm.completion(model="gemini/gemini-2.0-flash", messages=[{"role": "user", "content": "こんにちは"}])
litellm.completion() を一つ使い、modelパラメータを変えるだけです。LiteLLMが裏側で自動的に形式変換、パラメータ調整、レスポンスの標準化を行ってくれます。
🎯 技術的なアドバイス: LiteLLMの統一インターフェースという理念は、APIYI (apiyi.com) と似ています。どちらも一つのインターフェースで複数のモデルを呼び出せます。違いは、LiteLLMはオープンソースの自己ホスト型ソリューションであるのに対し、APIYIはデプロイ不要のマネージドサービスである点です。チームの技術力に合わせて最適な方を選択してください。
title: "LiteLLM の2つの使用モードを徹底解説"
description: "LiteLLMのSDKモードとProxyモードの違いを分かりやすく解説。個人開発から企業でのチーム運用まで、最適な選択肢を見つけるためのガイドです。"
LiteLLM の2つの使用モードを徹底解説
LiteLLM には、用途に応じて使い分けられる2つの使用モードがあります。それぞれの違いを理解することが、プロジェクトに最適な導入方法を選ぶ鍵となります。
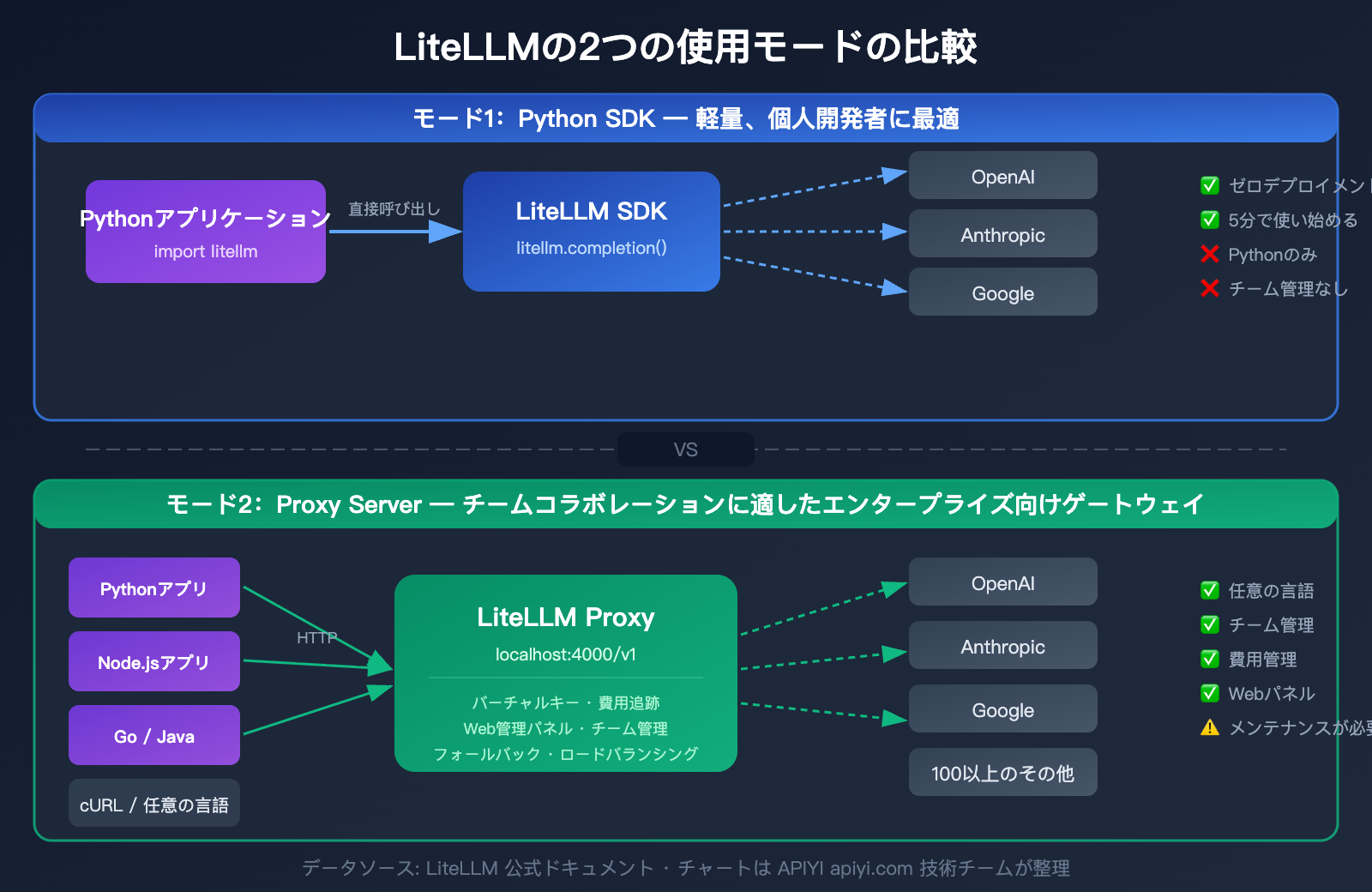
模式一:Python SDK(軽量モード)
Python コード内で litellm パッケージをインポートし、関数を呼び出す感覚で利用できます。
適用シーン:
- 個人開発者
- 純粋な Python プロジェクト
- プロトタイプの迅速な検証
- チーム管理機能が不要な場合
インストール:
pip install litellm
基本的な使い方:
import litellm
import os
# APIキーの設定(環境変数経由)
os.environ["OPENAI_API_KEY"] = "sk-あなたのキー"
os.environ["ANTHROPIC_API_KEY"] = "sk-ant-あなたのキー"
# 任意のモデルを呼び出し
response = litellm.completion(
model="gpt-4o",
messages=[{"role": "user", "content": "APIゲートウェイとは何かを説明してください"}]
)
print(response.choices[0].message.content)
模式二:Proxy Server(エンタープライズ向けゲートウェイ)
独立したサーバーとして動作し、OpenAI 互換の HTTP インターフェースを公開します。HTTP リクエストを送信できる言語やツールであれば、何でも利用可能です。
適用シーン:
- チーム開発
- 多言語プロジェクト(Java、Go、Node.js など)
- コスト追跡や予算管理が必要な場合
- チームごとに仮想キーを割り当てたい場合
- AI エージェントフレームワークへの組み込み
インストールと起動:
# インストール
pip install 'litellm[proxy]'
# 設定ファイルを使用して起動
litellm --config config.yaml --port 4000
# または Docker を使用
docker run -p 4000:4000 \
-e OPENAI_API_KEY=sk-xxx \
ghcr.io/berriai/litellm:main-latest
起動後は、OpenAI を呼び出すのと同じ感覚で利用できます:
from openai import OpenAI
# base_url を LiteLLM Proxy に向ける
client = OpenAI(
api_key="sk-あなたの仮想キー",
base_url="http://localhost:4000/v1"
)
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": "こんにちは"}]
)
LiteLLM SDK と Proxy モードの比較
| 比較項目 | Python SDK | Proxy Server |
|---|---|---|
| インストール方法 | pip install litellm |
pip install 'litellm[proxy]' または Docker |
| 呼び出し方法 | Python 関数呼び出し | HTTP API(言語不問) |
| 設定方法 | コード内で設定 | config.yaml 設定ファイル |
| 仮想キー管理 | 非対応 | 対応(予算上限設定可) |
| Web 管理パネル | なし | あり(可視化管理) |
| チーム管理 | 非対応 | 対応(ユーザー/チーム/予算) |
| コスト追跡 | 基本的(コードレベル) | 完全(データベース永続化) |
| デプロイの複雑さ | デプロイ不要 | サーバー運用が必要 |
| 推奨ユーザー | 個人開発者 | チーム/企業 |
💡 選択のアドバイス: 個人開発でプロトタイプを検証するなら、SDK モードなら5分で導入できます。チームでの利用や本番環境であれば、Proxy モードが適しています。もちろん、サーバーの構築や運用を避けたい場合は、APIYI (apiyi.com) のようなホスティング型の統合インターフェースサービスを利用すれば、すぐに使い始めることができます。
LiteLLM クイックスタートガイド
LiteLLM をゼロから使い始めるための完全な手順を解説します。
LiteLLM SDK モードのクイックスタート
ステップ 1:インストール
pip install litellm
ステップ 2:環境変数の設定
# macOS / Linux
export OPENAI_API_KEY="sk-あなたのキー"
export ANTHROPIC_API_KEY="sk-ant-あなたのキー"
# Windows
set OPENAI_API_KEY=sk-あなたのキー
ステップ 3:コードの記述
import litellm
# 基本的な呼び出し
response = litellm.completion(
model="gpt-4o",
messages=[
{"role": "system", "content": "あなたは技術アシスタントです"},
{"role": "user", "content": "LLMゲートウェイとは何ですか?"}
],
temperature=0.7
)
print(response.choices[0].message.content)
print(f"トークン使用量: {response.usage.total_tokens}")
print(f"推定コスト: ${response._hidden_params.get('response_cost', 'N/A')}")
完全なコードを表示:フォールバックとストリーミング出力
import litellm
import os
os.environ["OPENAI_API_KEY"] = "sk-あなたのキー"
os.environ["ANTHROPIC_API_KEY"] = "sk-ant-あなたのキー"
# フォールバック付きの呼び出し:GPT-4oが失敗すると自動的にClaudeへ切り替え
response = litellm.completion(
model="gpt-4o",
messages=[{"role": "user", "content": "RESTful APIについて説明して"}],
fallbacks=["anthropic/claude-sonnet-4-6"],
num_retries=2
)
# ストリーミング出力
stream = litellm.completion(
model="gpt-4o",
messages=[{"role": "user", "content": "プログラミングについての詩を書いて"}],
stream=True
)
for chunk in stream:
content = chunk.choices[0].delta.content
if content:
print(content, end="", flush=True)
LiteLLM Proxy モードのクイックスタート
ステップ 1:設定ファイル config.yaml の作成
model_list:
- model_name: gpt-4o
litellm_params:
model: openai/gpt-4o
api_key: os.environ/OPENAI_API_KEY
- model_name: claude-sonnet
litellm_params:
model: anthropic/claude-sonnet-4-6
api_key: os.environ/ANTHROPIC_API_KEY
- model_name: gemini-flash
litellm_params:
model: gemini/gemini-2.0-flash
api_key: os.environ/GEMINI_API_KEY
litellm_settings:
drop_params: true
num_retries: 3
general_settings:
master_key: sk-my-master-key
ステップ 2:Proxy の起動
litellm --config config.yaml --port 4000
ステップ 3:標準の OpenAI SDK を使用した呼び出し
from openai import OpenAI
client = OpenAI(
api_key="sk-my-master-key",
base_url="http://localhost:4000/v1"
)
# GPT-4o を呼び出し(LiteLLM Proxy 経由)
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": "こんにちは"}]
)
print(response.choices[0].message.content)
cURL で直接呼び出すことも可能です:
curl http://localhost:4000/v1/chat/completions \
-H "Authorization: Bearer sk-my-master-key" \
-H "Content-Type: application/json" \
-d '{
"model": "claude-sonnet",
"messages": [{"role": "user", "content": "Hello"}]
}'
🚀 クイックスタート: LiteLLM Proxy はサーバーと APIキーの管理を自分で行う必要があります。デプロイ不要で統一されたインターフェースをすぐに使いたい場合は、APIYI (apiyi.com) をお試しください。OpenAI 互換フォーマットで 100 以上のモデルをサポートしており、インフラ構築は一切不要です。
AI Agent における LiteLLM の核心的な役割
多くの初心者が疑問に思う点ですが、なぜ主要な AI Agent フレームワークのほとんどが LiteLLM をサポート、あるいは推奨しているのでしょうか?
なぜ AI Agent に LiteLLM が必要なのか?
AI Agent(インテリジェント・エージェント)がタスクを実行する際、多くの場合以下の機能が必要になります:
- モデルの使い分け:単純なタスクには安価な小型モデル、複雑な推論には大規模言語モデルを使用。
- 自動フェイルオーバー:主力モデルがレート制限やダウンタイムに陥った際、自動的に予備モデルへ切り替え。
- コスト管理:複数の Agent が並行稼働する際、トークン消費量を一元的に追跡・制限。
- チームコラボレーション:異なる開発者の Agent 間で API リソースプールを共有。
LiteLLM はこれらのニーズを完璧に満たします。Agent とモデルの間の「スケジューリングセンター」として機能するからです。
LiteLLM と主要 AI Agent フレームワークの統合
| Agent フレームワーク | 統合方法 | 代表的な用途 |
|---|---|---|
| LangChain / LangGraph | SDK 内蔵サポート | ChatLiteLLM を LLM バックエンドとして利用 |
| CrewAI | Proxy 接続 | 複数 Agent でモデルリソースプールを共有 |
| AutoGen(Microsoft) | Proxy 接続 | OpenAI 互換エンドポイント経由で接続 |
| Dify | カスタムプロバイダー | OpenAI 互換エンドポイントとして設定 |
| Open WebUI | Proxy 接続 | バックエンド API エンドポイント |
| Aider | Proxy 接続 | コード生成 Agent のモデル層 |
| Continue.dev | Proxy 接続 | IDE 内 AI コーディングアシスタントのバックエンド |
マルチ Agent システムにおける LiteLLM の典型的なアーキテクチャ
マルチ Agent システムにおいて、LiteLLM Proxy は通常以下のように動作します:
- プランニング Agent → Claude Opus(強力な推論モデル)を呼び出し
- 実行 Agent → GPT-4o(性能バランス重視)を呼び出し
- 検証 Agent → GPT-4o-mini(高速・低コスト)を呼び出し
- 要約 Agent → Gemini Flash(大容量コンテキストウィンドウ)を呼び出し
すべての Agent が同一の LiteLLM Proxy エンドポイントを介して呼び出しを行い、Proxy が自動的に適切なバックエンドモデルへルーティングします。管理者はダッシュボードを通じて、すべての Agent のトークン使用量やコストを一元管理できます。
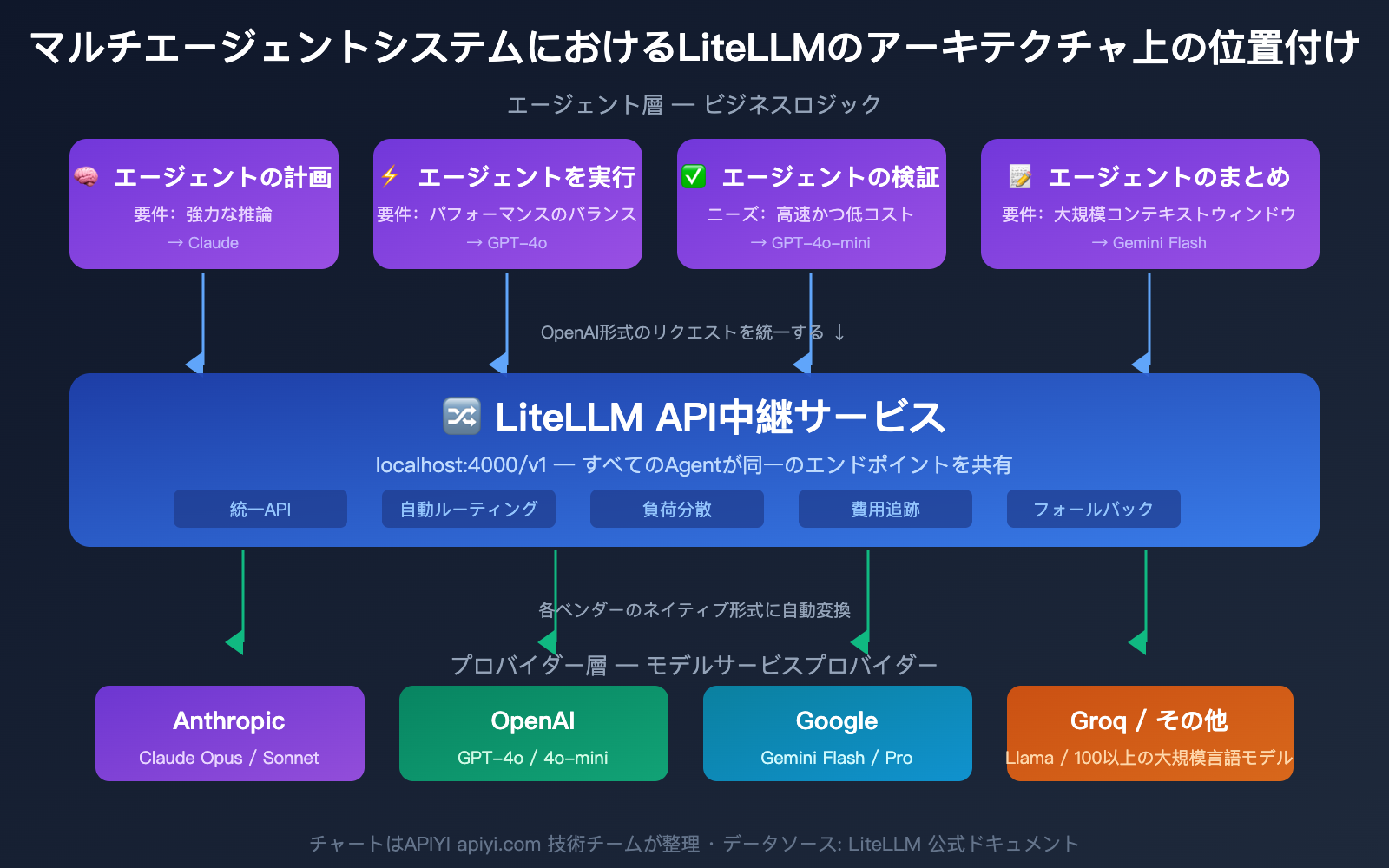
🎯 技術的アドバイス: 本番環境のマルチ Agent システムにおいて、LiteLLM Proxy はコスト追跡やキャッシュ機能を完全に活用するために PostgreSQL と Redis を組み合わせる必要があります。チーム規模が小さい場合や、追加のインフラを運用したくない場合は、APIYI (apiyi.com) をご検討ください。同様の統一インターフェース機能を提供し、コスト追跡や使用量統計も内蔵しているため、データベースを別途デプロイする必要はありません。
title: "LiteLLM 高度な機能の徹底解説:本番環境での活用術"
description: "LiteLLMの基礎をマスターした方に向け、本番環境で必須となる「モデルのフォールバック」「負荷分散」「コスト管理」などの高度な機能を詳しく解説します。"
LiteLLM 高度な機能の徹底解説
基礎的な使い方を習得した後は、以下の3つの高度な機能を活用することで、本番環境での安定性と運用効率を大幅に向上させることができます。
高度な機能1:モデル Fallback(フォールバック)
メインのモデルでレート制限、タイムアウト、またはエラーが発生した場合、LiteLLMは自動的に予備のモデルに切り替え、サービスの中断を防ぎます。
SDK での Fallback 設定:
response = litellm.completion(
model="gpt-4o",
messages=messages,
fallbacks=["anthropic/claude-sonnet-4-6", "gemini/gemini-2.0-flash"],
num_retries=2
)
実行ロジック:まず GPT-4o を試行 → 失敗すれば Claude Sonnet を試行 → それも失敗すれば Gemini Flash を試行します。
Proxy での Fallback 設定(config.yaml):
litellm_settings:
fallbacks:
- gpt-4o: [claude-sonnet, gemini-flash]
- claude-sonnet: [gpt-4o, gemini-flash]
高度な機能2:負荷分散(ロードバランシング)
同じモデル名に対して複数のバックエンドデプロイメントを設定し、LiteLLM が自動的にリクエストを振り分けます。
model_list:
# 同じモデル名で、2つの異なるバックエンド
- model_name: gpt-4o
litellm_params:
model: openai/gpt-4o
api_key: os.environ/OPENAI_KEY_1
- model_name: gpt-4o
litellm_params:
model: azure/gpt-4o-deployment
api_key: os.environ/AZURE_KEY_1
api_base: https://my-azure.openai.azure.com
router_settings:
routing_strategy: least-busy # 負荷の低い順に優先
# その他の戦略: simple-shuffle, latency-based
呼び出し時に model="gpt-4o" を指定するだけで、LiteLLM が OpenAI 直結と Azure デプロイメント間で自動的にトラフィックを分散します。
高度な機能3:コスト追跡と仮想 Key
仮想 Key の生成(Proxy モード):
curl http://localhost:4000/key/generate \
-H "Authorization: Bearer sk-master-key" \
-H "Content-Type: application/json" \
-d '{
"max_budget": 50.0,
"budget_duration": "monthly",
"models": ["gpt-4o", "claude-sonnet"],
"metadata": {"user": "developer-01"}
}'
これにより、月額予算が $50 に制限され、GPT-4o と Claude Sonnet のみにアクセス可能な仮想 Key が生成されます。
コスト追跡:
LiteLLM には各モデルの料金表が組み込まれており、API 呼び出しごとに自動でコストを計算します。Proxy 管理パネルから以下を確認可能です:
- モデルごとの合計コスト
- ユーザー/チームごとの詳細な利用料金
- 期間別のコスト推移
- トークン使用量統計
💰 コスト最適化: LiteLLM のコスト追跡機能を使えば、どのモデル呼び出しが最もコストがかかっているかを把握できます。APIYI (apiyi.com) の価格優位性を活用すれば、同じモデル呼び出しでもよりお得な価格で利用でき、AI アプリの運用コストをさらに削減可能です。
LiteLLM がサポートする 100 以上のモデルプロバイダー一覧
LiteLLM は非常に多くのプロバイダーをサポートしています。代表的なものは以下の通りです:
| カテゴリ | プロバイダー | モデル接頭辞 | 代表的なモデル |
|---|---|---|---|
| 商用大規模言語モデル | OpenAI | openai/ |
GPT-4o, GPT-4o-mini, o3 |
| Anthropic | anthropic/ |
Claude Opus 4, Sonnet 4, Haiku | |
gemini/ |
Gemini 2.0 Flash, Gemini 2.5 Pro | ||
| クラウドプラットフォーム | Azure OpenAI | azure/ |
Azure デプロイの GPT シリーズ |
| AWS Bedrock | bedrock/ |
Bedrock ホストの Claude/Llama | |
| Google Vertex AI | vertex_ai/ |
Vertex ホストの Gemini | |
| 推論高速化 | Groq | groq/ |
Llama 3.1 70B (超高速推論) |
| Together AI | together_ai/ |
各種オープンソースモデル | |
| Fireworks AI | fireworks_ai/ |
高性能推論 | |
| ローカルデプロイ | Ollama | ollama/ |
ローカル実行の Llama/Mistral |
| vLLM | openai/ (カスタム base) |
セルフホスト推論エンジン | |
| 国産モデル | Deepseek | deepseek/ |
Deepseek Chat/Coder |
| 検索拡張 | Perplexity | perplexity/ |
Sonar Pro |
| アグリゲーション | OpenRouter | openrouter/ |
各種モデル |
🎯 選択のアドバイス: モデルの選択はユースケースによって異なります。どのモデルを使うべきか迷った場合は、APIYI (apiyi.com) プラットフォームで各モデルの効果を素早くテストしてみてください。同プラットフォームも、上記モデルの多くに対して OpenAI 互換インターフェースでの呼び出しをサポートしています。

LiteLLM よくある質問(FAQ)
Q1: LiteLLMとOpenAI SDKを直接使うのとでは何が違いますか?
OpenAI SDKはOpenAIのモデルしか呼び出せません。一方、LiteLLMはOpenAI SDKをベースに拡張されており、Anthropic、Google、Azureなど100以上のモデルプロバイダーを同じコード形式で呼び出すことができます。プロジェクトでOpenAIのモデルしか使わないのであれば、OpenAI SDKを直接使うのが一番です。しかし、複数のモデルへの対応、フェイルオーバー、コスト管理が必要な場合は、LiteLLMの方が適しています。
Q2: LiteLLMは無料ですか?
LiteLLMのコア機能は完全にオープンソースで無料(MITライセンス)です。ただし、注意点として、LiteLLM自体は無料ですが、呼び出すモデルのAPIには料金が発生します。OpenAIやAnthropicなどの公式サイトからAPIキーを取得し、モデル呼び出し料金を支払う必要があります。複数のAPIキーを個別に管理したくない場合は、APIYI(apiyi.com)のような統合インターフェースプラットフォームを利用して、キー管理を簡略化することも可能です。
Q3: LiteLLM Proxyにはどのようなサーバー構成が必要ですか?
LiteLLM Proxy自体は非常に軽量で、1コア・1GBメモリのサーバーでも動作します。ただし、コスト追跡や仮想キー管理などのフル機能が必要な場合は、PostgreSQLデータベースとRedisが必要です。本番環境では、最低でも2コア・4GBメモリ + PostgreSQL + Redisの構成を推奨します。
Q4: LiteLLMとOpenRouterの違いは何ですか?
最大の違いは、LiteLLMは「オープンソースのセルフホスト型」であり、OpenRouterは「マネージドサービス(ホスティングサービス)」である点です。
- LiteLLM: 無料で、自分でデプロイし、APIキーを管理し、データフローを完全に制御できます。
- OpenRouter: すぐに使えますが、API呼び出し価格に上乗せ料金があり、データは第三者を経由します。
データプライバシーを重視する場合や、独自のAPIキーを持っている場合はLiteLLMがおすすめです。デプロイの手間を省いてすぐに使いたい場合は、APIYI(apiyi.com)のようなホスティングソリューションを検討してみてください。
Q5: LiteLLMはストリーミング出力に対応していますか?
はい、対応しています。SDKモードでもProxyモードでも、LiteLLMはSSEストリーミング出力を完全にサポートしています。すべてのプロバイダーのストリーミングレスポンスは、OpenAI形式のチャンクに統一されるため、一貫したストリーミング体験が保証されます。
# ストリーミング出力の例
stream = litellm.completion(
model="gpt-4o",
messages=[{"role": "user", "content": "物語を書いてください"}],
stream=True
)
for chunk in stream:
print(chunk.choices[0].delta.content or "", end="")
Q6: 初心者はSDKモードとProxyモードのどちらを選ぶべきですか?
Python開発者で学習を始めたばかりであれば、SDKモードから始めるのが最も簡単です。pip install litellm を実行して数行コードを書くだけで動作します。チーム開発や多言語対応、本番環境へのデプロイが必要になった段階で、Proxyモードへ移行するのが良いでしょう。どちらのモードもコアとなる呼び出し方法は同じなので、移行コストは非常に低いです。
Q7: LiteLLMのconfig.yaml設定ファイルはどこに置けばいいですか?
決まった場所はありません。Proxyを起動する際に --config パラメータでパスを指定するだけです:
litellm --config /path/to/your/config.yaml
一般的には、プロジェクトのルートディレクトリや専用の設定ディレクトリに置くことを推奨します。Dockerでデプロイする場合は、ボリュームマウントを使用してコンテナ内に配置してください。
LiteLLM 迅速な意思決定ガイド
あなたの状況に合わせて、最適なソリューションを選択してください:
| あなたの状況 | 推奨ソリューション | 理由 |
|---|---|---|
| 個人開発者、Pythonプロジェクト | LiteLLM SDK | デプロイ不要、5分で開始可能 |
| チーム開発、予算管理が必要 | LiteLLM Proxy | 仮想キー + コスト追跡 |
| インフラを自前で構築したくない | APIYI (apiyi.com) | ホスティングサービス、すぐに利用可能 |
| マルチエージェントシステム | LiteLLM Proxy | 統合ルーティング + 負荷分散 |
| OpenAIモデルのみを使用 | OpenAI SDKを直接使用 | 追加レイヤーが不要 |
| データプライバシーを重視 | LiteLLM セルフホスト | データが第三者を経由しない |
まとめ
LiteLLM は、AI アプリケーション開発において非常に実用的なインフラストラクチャツールです。その核心的な価値を一言で言えば、**「OpenAI 形式のコードを一つ書くだけで、100社以上のモデルプロバイダーの API を呼び出せる」**という点にあります。
初心者の方が押さえておくべきポイントは以下の通りです:
- LiteLLM は「翻訳機」:統一された形式のリクエストを、各モデル固有の API 形式へと変換してくれます。
- 2つのモード:SDK(軽量な Python パッケージ)と Proxy(独立したゲートウェイサーバー)の2種類があります。
- 核心的な価値:統一インターフェース、フォールバック、負荷分散、コスト追跡機能を提供します。
- Agent フレームワークの標準装備:LangChain、CrewAI、AutoGen など、主要なフレームワークのほとんどが LiteLLM をサポートしています。
- 完全オープンソースかつ無料:MIT ライセンスであり、自前でデプロイする場合の費用は一切かかりません。
もし LiteLLM Proxy を自前で運用するコストが高いと感じる場合は、APIYI (apiyi.com) のようなマネージド型の統一インターフェースサービスを利用するのも手です。一つの API キーで主要なモデルすべてを呼び出せるため、デプロイや運用の負担を大幅に軽減できます。
執筆者: APIYI 技術チーム
技術交流: APIYI (apiyi.com) にアクセスして、AI モデル呼び出しのチュートリアルや技術サポートをご覧ください。
更新日: 2026年4月
適用バージョン: LiteLLM v1.x+
参考資料:
- LiteLLM 公式ドキュメント: docs.litellm.ai
- LiteLLM GitHub リポジトリ: github.com/BerriAI/litellm
- LiteLLM 公式サイト: litellm.ai
- BerriAI 公式サイト: berri.ai