Знакома ли вам ситуация, когда в проекте одновременно используются GPT от OpenAI, Claude от Anthropic и Gemini от Google, и у каждого из них свои SDK, форматы API и даже способы обработки ошибок? Стоит сменить модель, как приходится переписывать половину кода.
Именно эту проблему решает LiteLLM. Если в двух словах: LiteLLM — это «универсальный переводчик» для больших языковых моделей. Вам достаточно освоить один способ вызова (формат OpenAI), а библиотека сама переведет его в API-форматы более чем 100 различных провайдеров.
Ключевая ценность: из этой статьи вы узнаете, что такое LiteLLM, почему его используют все современные фреймворки для AI-агентов и как начать работу с ним буквально за 5 минут.

Что такое LiteLLM: 5 ключевых концепций
Прежде чем начать, давайте разберемся с 5 основными концепциями LiteLLM на простом языке. Как только вы их поймете, дальнейшая работа пойдет как по маслу.
| Ключевая концепция | Простое объяснение | Какую проблему решает |
|---|---|---|
| Единый интерфейс | Все модели вызываются одинаково | Не нужно учить отдельный SDK для каждой модели |
| Provider (Провайдер) | Вендоры моделей: OpenAI, Anthropic и др. | Управление способами подключения к разным вендорам |
| Fallback (Отказоустойчивость) | Автоматическое переключение на модель B, если модель А упала | Гарантия непрерывности сервиса |
| Virtual Key (Виртуальный ключ) | Выдача «субаккаунтов» членам команды | Контроль использования и бюджета |
| Proxy (Прокси-шлюз) | Автономный сервис-прокси API | Доступ из любого языка программирования и любого инструмента |
Какие «боли» решает LiteLLM?
Представьте мир без LiteLLM:
Вызов OpenAI:
from openai import OpenAI
client = OpenAI(api_key="sk-xxx")
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": "Привет"}]
)
Вызов Anthropic:
import anthropic
client = anthropic.Anthropic(api_key="sk-ant-xxx")
response = client.messages.create(
model="claude-sonnet-4-20250514",
max_tokens=1024, # Для Anthropic это обязательно
messages=[{"role": "user", "content": "Привет"}]
)
Вызов Google Gemini:
import google.generativeai as genai
genai.configure(api_key="AIza-xxx")
model = genai.GenerativeModel("gemini-2.0-flash")
response = model.generate_content("Привет")
Видите? Три модели, три разных SDK, три разных способа написания кода. Если ваш проект должен поддерживать переключение между моделями, код будет переполнен условиями вроде if provider == "openai"... elif provider == "anthropic"....
С LiteLLM всё проще:
import litellm
# Вызов OpenAI
response = litellm.completion(model="gpt-4o", messages=[{"role": "user", "content": "Привет"}])
# Вызов Anthropic — тот же самый синтаксис
response = litellm.completion(model="anthropic/claude-sonnet-4-6", messages=[{"role": "user", "content": "Привет"}])
# Вызов Gemini — всё еще тот же синтаксис
response = litellm.completion(model="gemini/gemini-2.0-flash", messages=[{"role": "user", "content": "Привет"}])
Один метод litellm.completion(), просто меняете параметр model. LiteLLM автоматически выполняет преобразование форматов, адаптацию параметров и стандартизацию ответов.
🎯 Технический совет: Концепция единого интерфейса LiteLLM похожа на APIYI (apiyi.com) — оба решения позволяют вызывать множество моделей через один интерфейс. Разница в том, что LiteLLM — это open-source решение для самостоятельного развертывания, а APIYI — это хостинг-сервис, который не требует настройки. Выбирайте подходящий вариант в зависимости от технических возможностей вашей команды.
Подробный разбор двух режимов использования LiteLLM
LiteLLM предлагает два режима работы для разных сценариев. Понимание разницы между ними — ключ к правильному выбору.
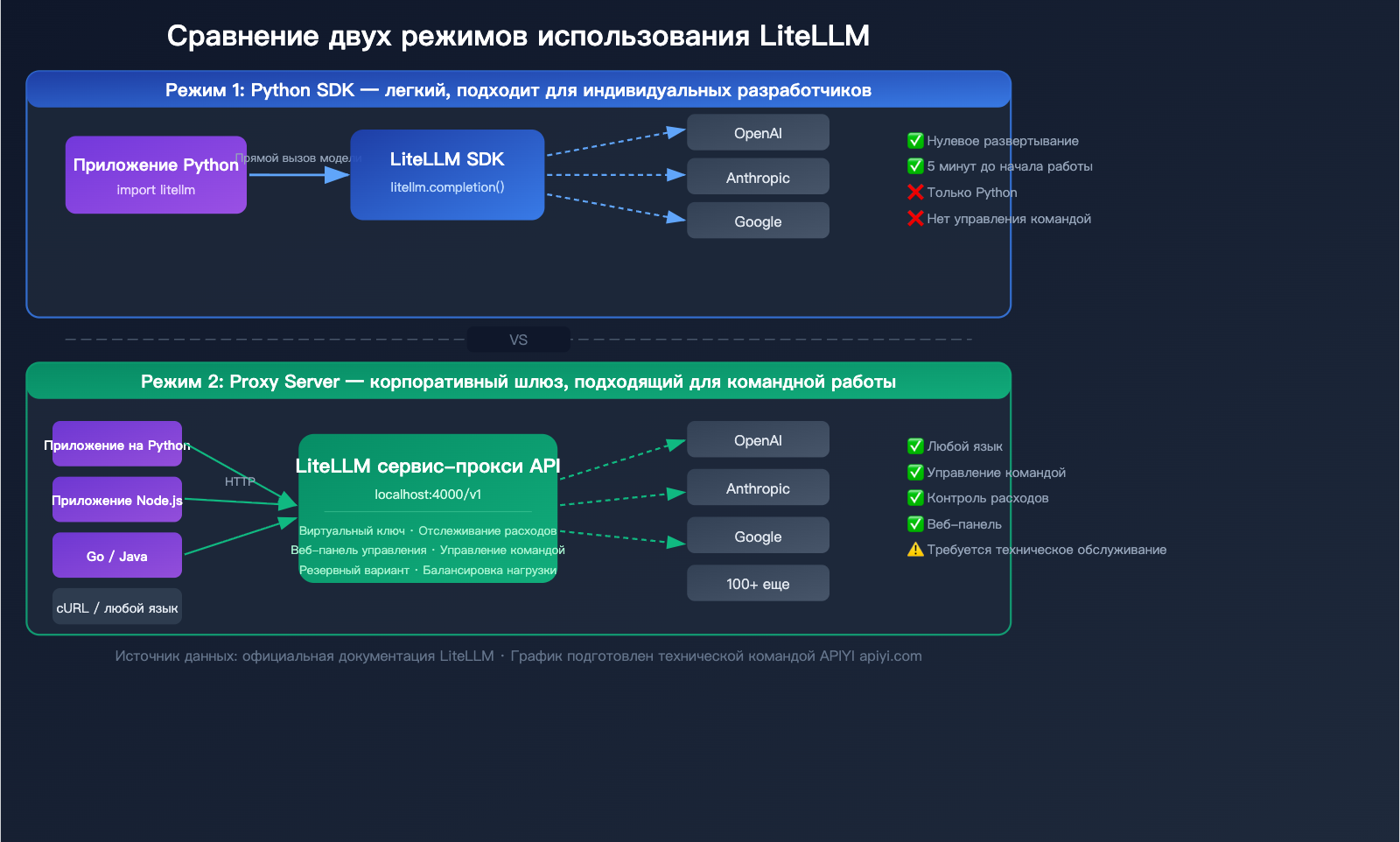
Режим 1: Python SDK (легковесный)
Импортируйте пакет litellm прямо в ваш Python-код и используйте его как обычную функцию.
Подходящие сценарии:
- Индивидуальные разработчики
- Чисто Python-проекты
- Быстрая проверка прототипов
- Не требуются функции корпоративного управления
Установка:
pip install litellm
Базовое использование:
import litellm
import os
# Установка API-ключа (через переменные окружения)
os.environ["OPENAI_API_KEY"] = "sk-ваш_ключ"
os.environ["ANTHROPIC_API_KEY"] = "sk-ant-ваш_ключ"
# Вызов любой модели
response = litellm.completion(
model="gpt-4o",
messages=[{"role": "user", "content": "Объясни, что такое API-шлюз"}]
)
print(response.choices[0].message.content)
Режим 2: Proxy Server (корпоративный шлюз)
Работает как отдельный сервер, предоставляющий HTTP-интерфейс, совместимый с OpenAI. Любой язык программирования, любой инструмент — всё, что может отправлять HTTP-запросы, будет работать.
Подходящие сценарии:
- Командная работа
- Мультиязычные проекты (Java, Go, Node.js и др.)
- Необходимость отслеживания расходов и управления бюджетом
- Необходимость выдачи виртуальных ключей разным командам
- Интеграция с фреймворками AI Agent
Установка и запуск:
# Установка
pip install 'litellm[proxy]'
# Запуск с файлом конфигурации
litellm --config config.yaml --port 4000
# Или через Docker
docker run -p 4000:4000 \
-e OPENAI_API_KEY=sk-xxx \
ghcr.io/berriai/litellm:main-latest
После запуска любое приложение может обращаться к нему так же, как к OpenAI:
from openai import OpenAI
# Указываем base_url на LiteLLM Proxy
client = OpenAI(
api_key="sk-ваш_виртуальный_ключ",
base_url="http://localhost:4000/v1"
)
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": "Привет"}]
)
Сравнение LiteLLM SDK и режима Proxy
| Параметр сравнения | Python SDK | Proxy Server |
|---|---|---|
| Способ установки | pip install litellm |
pip install 'litellm[proxy]' или Docker |
| Способ вызова | Вызов функции Python | HTTP API (любой язык) |
| Конфигурация | Настройка в коде | Файл config.yaml |
| Управление вирт. ключами | Не поддерживается | Поддерживается, с лимитами бюджета |
| Веб-панель управления | Нет | Есть, визуальное управление |
| Управление командой | Нет | Да (пользователи/команды/бюджеты) |
| Отслеживание расходов | Базовое (на уровне кода) | Полное (с сохранением в БД) |
| Сложность развертывания | Нулевая | Требуется обслуживание сервера |
| Для кого | Индивидуальные разработчики | Команды/компании |
💡 Совет по выбору: Если вы индивидуальный разработчик и делаете прототип, режим SDK запустится за 5 минут. Если же это командная работа или продакшн-среда, режим Proxy подходит лучше. Конечно, если вы не хотите самостоятельно развертывать и обслуживать сервер, вы также можете воспользоваться хостинг-сервисом с единым интерфейсом, таким как APIYI (apiyi.com), который готов к работе сразу после подключения.
Руководство по быстрому старту LiteLLM
Ниже представлены полные шаги для начала работы с LiteLLM с нуля.
Быстрый старт в режиме LiteLLM SDK
Шаг 1: Установка
pip install litellm
Шаг 2: Настройка переменных окружения
# macOS / Linux
export OPENAI_API_KEY="sk-ваш-ключ"
export ANTHROPIC_API_KEY="sk-ant-ваш-ключ"
# Windows
set OPENAI_API_KEY=sk-ваш-ключ
Шаг 3: Написание кода
import litellm
# Базовый вызов
response = litellm.completion(
model="gpt-4o",
messages=[
{"role": "system", "content": "Ты — технический ассистент"},
{"role": "user", "content": "Что такое LLM-шлюз?"}
],
temperature=0.7
)
print(response.choices[0].message.content)
print(f"Расход токенов: {response.usage.total_tokens}")
print(f"Оценочная стоимость: ${response._hidden_params.get('response_cost', 'N/A')}")
Посмотреть полный код: с Fallback и потоковым выводом
import litellm
import os
os.environ["OPENAI_API_KEY"] = "sk-ваш-ключ"
os.environ["ANTHROPIC_API_KEY"] = "sk-ant-ваш-ключ"
# Вызов с Fallback: если GPT-4o не ответит, автоматически переключится на Claude
response = litellm.completion(
model="gpt-4o",
messages=[{"role": "user", "content": "Объясни, что такое RESTful API"}],
fallbacks=["anthropic/claude-sonnet-4-6"],
num_retries=2
)
# Потоковый вывод
stream = litellm.completion(
model="gpt-4o",
messages=[{"role": "user", "content": "Напиши стихотворение о программировании"}],
stream=True
)
for chunk in stream:
content = chunk.choices[0].delta.content
if content:
print(content, end="", flush=True)
Быстрый старт в режиме LiteLLM Proxy
Шаг 1: Создание файла конфигурации config.yaml
model_list:
- model_name: gpt-4o
litellm_params:
model: openai/gpt-4o
api_key: os.environ/OPENAI_API_KEY
- model_name: claude-sonnet
litellm_params:
model: anthropic/claude-sonnet-4-6
api_key: os.environ/ANTHROPIC_API_KEY
- model_name: gemini-flash
litellm_params:
model: gemini/gemini-2.0-flash
api_key: os.environ/GEMINI_API_KEY
litellm_settings:
drop_params: true
num_retries: 3
general_settings:
master_key: sk-my-master-key
Шаг 2: Запуск Proxy
litellm --config config.yaml --port 4000
Шаг 3: Вызов через стандартный OpenAI SDK
from openai import OpenAI
client = OpenAI(
api_key="sk-my-master-key",
base_url="http://localhost:4000/v1"
)
# Вызов GPT-4o (через LiteLLM Proxy)
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": "Привет"}]
)
print(response.choices[0].message.content)
Также можно использовать cURL для прямого вызова:
curl http://localhost:4000/v1/chat/completions \
-H "Authorization: Bearer sk-my-master-key" \
-H "Content-Type: application/json" \
-d '{
"model": "claude-sonnet",
"messages": [{"role": "user", "content": "Hello"}]
}'
🚀 Быстрый старт: LiteLLM Proxy требует самостоятельного управления сервером и API-ключами. Если вы хотите использовать единый интерфейс без развертывания, попробуйте APIYI (apiyi.com). Он поддерживает вызов более 100 моделей через формат, совместимый с OpenAI, без необходимости настраивать инфраструктуру.
Ключевая роль LiteLLM в AI-агентах
Это частый вопрос новичков: почему почти все популярные фреймворки для AI-агентов поддерживают или даже рекомендуют использовать LiteLLM?
Зачем AI-агентам нужен LiteLLM?
При выполнении задач AI-агентам часто требуется:
- Вызов разных моделей: простые задачи — для дешевых моделей, сложные рассуждения — для мощных.
- Автоматическое понижение уровня (Fallback): при ограничении скорости или сбое основной модели — автоматическое переключение на резервную.
- Контроль затрат: при параллельной работе нескольких агентов необходимо отслеживать и ограничивать расход токенов.
- Командная работа: возможность для разных разработчиков совместно использовать пул API-ресурсов.
LiteLLM идеально решает эти задачи, выступая в роли «центра управления» между агентом и моделями.
Интеграция LiteLLM с популярными фреймворками
| Фреймворк агентов | Способ интеграции | Типичное использование |
|---|---|---|
| LangChain / LangGraph | Встроенная поддержка SDK | ChatLiteLLM как LLM-бэкенд |
| CrewAI | Подключение через Proxy | Общий пул моделей для нескольких агентов |
| AutoGen (Microsoft) | Подключение через Proxy | Доступ через эндпоинт, совместимый с OpenAI |
| Dify | Пользовательский провайдер | Настройка как эндпоинта, совместимого с OpenAI |
| Open WebUI | Подключение через Proxy | Бэкенд API-эндпоинт |
| Aider | Подключение через Proxy | Модельный слой для агента генерации кода |
| Continue.dev | Подключение через Proxy | Бэкенд для AI-помощника в IDE |
Типичная архитектура LiteLLM в мультиагентных системах
В системе с несколькими агентами LiteLLM Proxy обычно работает так:
- Агент планирования → вызывает Claude Opus (модель с сильной логикой)
- Агент исполнения → вызывает GPT-4o (сбалансированная производительность)
- Агент проверки → вызывает GPT-4o-mini (быстро и дешево)
- Агент суммаризации → вызывает Gemini Flash (большое контекстное окно)
Все агенты обращаются к одному эндпоинту LiteLLM Proxy, который автоматически направляет запрос к нужной модели. Администратор через дашборд видит общий расход токенов и затраты всех агентов.
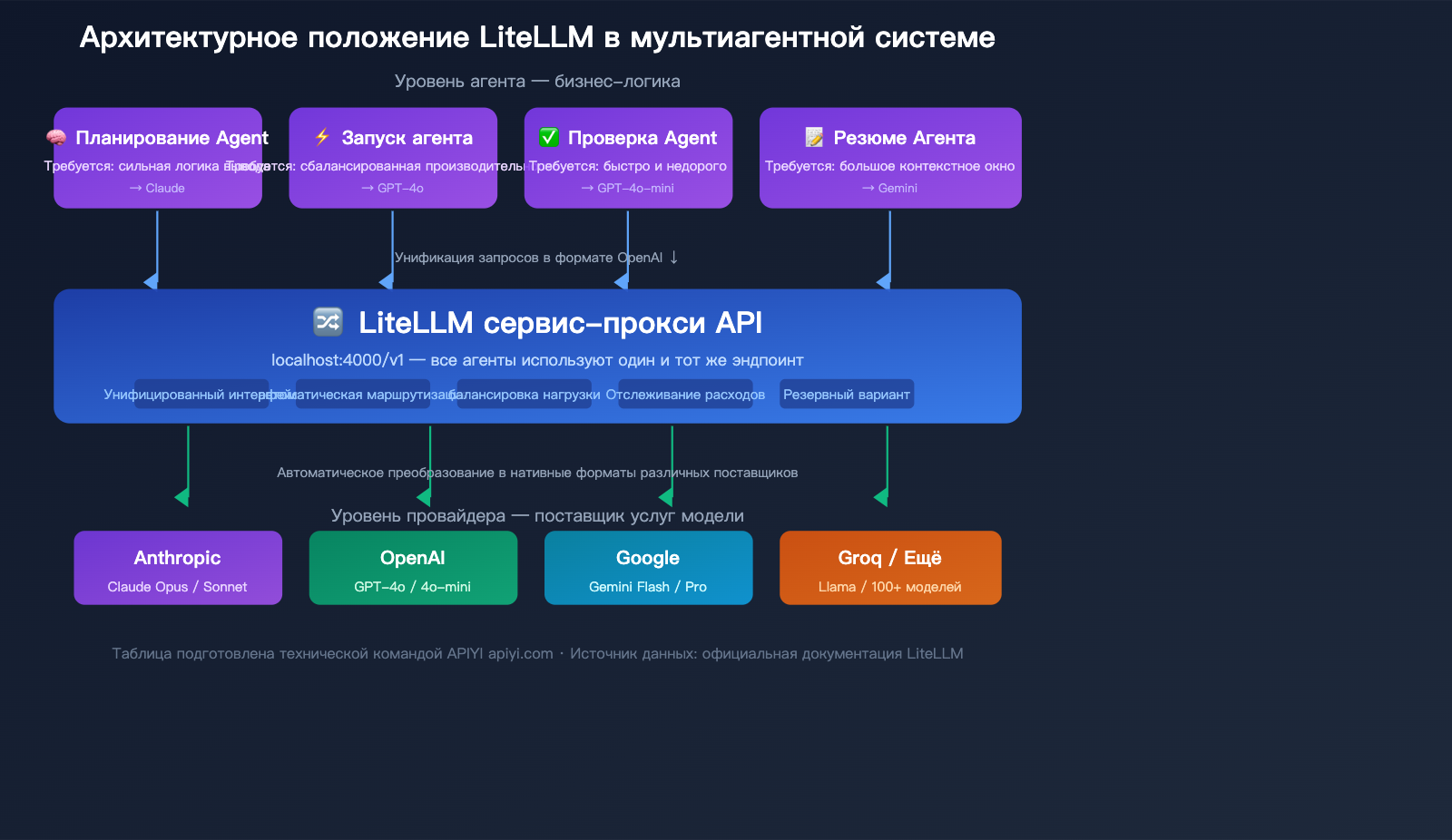
🎯 Технический совет: В продакшн-системах с несколькими агентами LiteLLM Proxy требует использования PostgreSQL и Redis для полноценной работы функций отслеживания затрат и кэширования. Если ваша команда невелика или вы не хотите заниматься обслуживанием дополнительной инфраструктуры, APIYI (apiyi.com) предоставляет аналогичные возможности единого интерфейса со встроенным отслеживанием расходов и статистики использования без необходимости развертывания баз данных.
Подробный разбор продвинутых функций LiteLLM
После того как вы освоили базовое использование, стоит обратить внимание на эти 3 продвинутые функции, которые чаще всего применяются в продакшене.
Продвинутая функция №1: Fallback моделей (отказоустойчивость)
Когда основная модель сталкивается с лимитами скорости, таймаутами или ошибками, LiteLLM автоматически переключается на резервную модель, чтобы сервис продолжал работать без перебоев.
Настройка Fallback в SDK:
response = litellm.completion(
model="gpt-4o",
messages=messages,
fallbacks=["anthropic/claude-sonnet-4-6", "gemini/gemini-2.0-flash"],
num_retries=2
)
Логика работы: сначала пробуем GPT-4o → если ошибка, пробуем Claude Sonnet → если снова ошибка, пробуем Gemini Flash.
Настройка Fallback в Proxy (config.yaml):
litellm_settings:
fallbacks:
- gpt-4o: [claude-sonnet, gemini-flash]
- claude-sonnet: [gpt-4o, gemini-flash]
Продвинутая функция №2: Балансировка нагрузки
Если у вас настроено несколько бэкендов для одной и той же модели, LiteLLM будет автоматически распределять запросы между ними.
model_list:
# Одно имя модели, два разных бэкенда
- model_name: gpt-4o
litellm_params:
model: openai/gpt-4o
api_key: os.environ/OPENAI_KEY_1
- model_name: gpt-4o
litellm_params:
model: azure/gpt-4o-deployment
api_key: os.environ/AZURE_KEY_1
api_base: https://my-azure.openai.azure.com
router_settings:
routing_strategy: least-busy # Приоритет наименее загруженному
# Другие стратегии: simple-shuffle, latency-based
При вызове достаточно указать model="gpt-4o", и LiteLLM сам распределит трафик между прямым подключением к OpenAI и развертыванием в Azure.
Продвинутая функция №3: Отслеживание расходов и виртуальные ключи
Генерация виртуального ключа (режим Proxy):
curl http://localhost:4000/key/generate \
-H "Authorization: Bearer sk-master-key" \
-H "Content-Type: application/json" \
-d '{
"max_budget": 50.0,
"budget_duration": "monthly",
"models": ["gpt-4o", "claude-sonnet"],
"metadata": {"user": "developer-01"}
}'
Это создаст виртуальный ключ с лимитом $50 в месяц, который можно использовать только для вызова GPT-4o и Claude Sonnet.
Отслеживание расходов:
LiteLLM имеет встроенные прайс-листы для каждой модели, поэтому стоимость каждого вызова API рассчитывается автоматически. В панели управления Proxy можно посмотреть:
- Общие расходы по моделям
- Детализацию расходов по пользователям/командам
- Динамику затрат по времени
- Статистику использования токенов
💰 Оптимизация затрат: Функция отслеживания расходов в LiteLLM поможет вам выявить самые дорогие вызовы моделей. В сочетании с ценовыми преимуществами APIYI (apiyi.com) вы можете получить более выгодные тарифы на те же модели, что еще сильнее снизит операционные расходы на ваши AI-приложения.
Обзор 100+ провайдеров моделей, поддерживаемых LiteLLM
LiteLLM поддерживает огромное количество провайдеров. Вот основные категории:
| Категория | Провайдер | Префикс модели | Примеры моделей |
|---|---|---|---|
| Коммерческие модели | OpenAI | openai/ |
GPT-4o, GPT-4o-mini, o3 |
| Anthropic | anthropic/ |
Claude Opus 4, Sonnet 4, Haiku | |
gemini/ |
Gemini 2.0 Flash, Gemini 2.5 Pro | ||
| Облачные платформы | Azure OpenAI | azure/ |
GPT-серия в Azure |
| AWS Bedrock | bedrock/ |
Claude/Llama в Bedrock | |
| Google Vertex AI | vertex_ai/ |
Gemini в Vertex AI | |
| Ускорение инференса | Groq | groq/ |
Llama 3.1 70B (сверхбыстрый) |
| Together AI | together_ai/ |
Различные open-source модели | |
| Fireworks AI | fireworks_ai/ |
Высокопроизводительный инференс | |
| Локальный запуск | Ollama | ollama/ |
Llama/Mistral локально |
| vLLM | openai/ (своя base) |
Самостоятельный движок инференса | |
| Китайские модели | Deepseek | deepseek/ |
Deepseek Chat/Coder |
| Поиск с ИИ | Perplexity | perplexity/ |
Sonar Pro |
| Агрегаторы | OpenRouter | openrouter/ |
Различные модели |
🎯 Совет по выбору: Выбор модели зависит от конкретной задачи. Если вы не уверены, что использовать, протестируйте разные модели через платформу APIYI (apiyi.com) — она также поддерживает вызовы через совместимый с OpenAI интерфейс для большинства вышеуказанных моделей.

FAQ по LiteLLM
Q1: В чем разница между LiteLLM и использованием OpenAI SDK напрямую?
OpenAI SDK позволяет работать только с моделями OpenAI. LiteLLM расширяет возможности OpenAI SDK, позволяя использовать тот же формат кода для вызова более 100 провайдеров моделей, таких как Anthropic, Google, Azure и другие. Если ваш проект использует только модели OpenAI, достаточно стандартного SDK. Но если вам нужна поддержка нескольких моделей, отказоустойчивость или контроль расходов, LiteLLM станет лучшим выбором.
Q2: LiteLLM бесплатный?
Основные функции LiteLLM полностью открыты и бесплатны (лицензия MIT). Однако важно помнить: сам LiteLLM бесплатен, но API моделей, которые он вызывает, платные. Вам нужно самостоятельно получить API-ключи от OpenAI, Anthropic и других официальных провайдеров и оплачивать вызовы моделей. Если вы не хотите управлять множеством ключей по отдельности, можно использовать единые платформы API, такие как APIYI (apiyi.com), для упрощения управления ключами.
Q3: Какие требования к серверу для LiteLLM Proxy?
LiteLLM Proxy довольно легкий, его можно запустить даже на сервере с 1 ядром и 1 ГБ оперативной памяти. Но если вам нужны расширенные функции (отслеживание расходов, управление виртуальными ключами), потребуются базы данных PostgreSQL и Redis. Для продакшн-среды рекомендуется минимум 2 ядра, 4 ГБ ОЗУ, PostgreSQL и Redis.
Q4: В чем разница между LiteLLM и OpenRouter?
Главное отличие: LiteLLM — это решение с открытым исходным кодом для самостоятельного развертывания, а OpenRouter — это управляемый сервис.
- LiteLLM: бесплатно, вы разворачиваете сами, сами управляете API-ключами и полностью контролируете поток данных.
- OpenRouter: готовое решение «из коробки», но с наценкой на стоимость вызовов API, а данные проходят через третью сторону.
Если вы цените конфиденциальность данных или у вас есть свои API-ключи, выбирайте LiteLLM. Если хотите быстро начать работу без развертывания инфраструктуры, рассмотрите управляемые решения, такие как APIYI (apiyi.com).
Q5: Поддерживает ли LiteLLM потоковую передачу (Streaming)?
Да. Как в режиме SDK, так и в режиме Proxy, LiteLLM полностью поддерживает потоковую передачу SSE. Потоковые ответы от всех провайдеров унифицируются в формат чанков OpenAI, что обеспечивает единообразие при работе со стримингом.
# Пример потоковой передачи
stream = litellm.completion(
model="gpt-4o",
messages=[{"role": "user", "content": "Напиши рассказ"}],
stream=True
)
for chunk in stream:
print(chunk.choices[0].delta.content or "", end="")
Q6: Что выбрать новичку: режим SDK или режим Proxy?
Если вы Python-разработчик и только начинаете обучение, проще всего начать с режима SDK — pip install litellm и пара строк кода, и всё готово. Когда возникнет необходимость в командной работе, поддержке нескольких языков или деплое в продакшн, вы сможете перейти на режим Proxy. Основной способ вызова в обоих режимах идентичен, поэтому миграция будет очень простой.
Q7: Где хранить файл конфигурации config.yaml для LiteLLM?
Фиксированного места нет. При запуске Proxy просто укажите путь через параметр --config:
litellm --config /path/to/your/config.yaml
Обычно рекомендуется хранить его в корне проекта или в специальной папке конфигураций. Если вы используете Docker, примонтируйте файл в контейнер через volume.
Краткое руководство по выбору LiteLLM
Выберите наиболее подходящий вариант в зависимости от ваших задач:
| Ваша ситуация | Рекомендуемое решение | Почему? |
|---|---|---|
| Индивидуальный разработчик, Python-проект | LiteLLM SDK | Без развертывания, старт за 5 минут |
| Командная разработка, нужен контроль бюджета | LiteLLM Proxy | Виртуальные ключи + отслеживание расходов |
| Не хотите настраивать инфраструктуру | APIYI (apiyi.com) | Управляемый сервис, готово к работе |
| Мультиагентные системы | LiteLLM Proxy | Единая маршрутизация + балансировка нагрузки |
| Используете только модели OpenAI | OpenAI SDK напрямую | Нет нужды в дополнительном слое |
| Важна конфиденциальность данных | LiteLLM (self-hosted) | Данные не проходят через третьих лиц |
Резюме
LiteLLM — это невероятно полезный инфраструктурный инструмент для разработки AI-приложений. Его главная ценность заключается в одной фразе: используйте один формат кода OpenAI для вызова API более 100 различных поставщиков моделей.
Для новичков стоит запомнить несколько ключевых моментов:
- LiteLLM — это «переводчик»: он помогает переводить запросы в едином формате в специфические API-форматы каждой отдельной модели.
- Два режима работы: SDK (легкий Python-пакет) и Proxy (отдельный сервер-шлюз).
- Ключевые преимущества: унифицированный интерфейс, механизмы Fallback (резервного копирования), балансировка нагрузки и отслеживание расходов.
- Стандарт для Agent-фреймворков: почти все популярные инструменты, такие как LangChain, CrewAI, AutoGen и другие, поддерживают LiteLLM.
- Полностью открытый исходный код: лицензия MIT, никаких затрат при самостоятельном развертывании.
Если вы считаете, что расходы на поддержку собственного LiteLLM Proxy слишком высоки, вы можете воспользоваться услугами хостинг-сервисов, таких как APIYI (apiyi.com). Они предоставляют аналогичный единый интерфейс, позволяя вызывать все основные модели с помощью одного API-ключа, что избавляет вас от необходимости заниматься развертыванием и обслуживанием инфраструктуры.
Автор статьи: Техническая команда APIYI
Техническое сообщество: Посетите APIYI (apiyi.com) для получения дополнительных руководств по вызову AI-моделей и технической поддержки.
Дата обновления: Апрель 2026 г.
Версия: LiteLLM v1.x+
Справочные материалы:
- Официальная документация LiteLLM: docs.litellm.ai
- Репозиторий LiteLLM на GitHub: github.com/BerriAI/litellm
- Официальный сайт LiteLLM: litellm.ai
- Официальный сайт BerriAI: berri.ai