OpenAI의 GPT, Anthropic의 Claude, Google의 Gemini를 프로젝트에 동시에 사용하면서, 모델마다 제각각인 SDK와 API 형식, 그리고 서로 다른 에러 처리 방식 때문에 골치 아팠던 적 있으신가요? 모델 하나만 바꿔도 코드 전체를 수정해야 하는 상황 말이죠.
이런 고민을 해결해 주는 것이 바로 LiteLLM입니다. 간단히 말해, LiteLLM은 AI 대규모 언어 모델을 위한 '만능 번역기'입니다. 여러분은 단 하나의 호출 방식(OpenAI 형식)만 익히면, LiteLLM이 알아서 100여 개 모델 업체의 각기 다른 API 형식으로 변환해 줍니다.
핵심 가치: 이 글을 읽고 나면 LiteLLM이 무엇인지, 왜 AI 에이전트 프레임워크들이 이를 필수로 사용하는지, 그리고 5분 만에 시작하는 방법을 완벽히 이해하게 될 것입니다.

LiteLLM이란 무엇인가: 5가지 핵심 개념
본격적으로 사용하기 전에, LiteLLM의 5가지 핵심 개념을 가장 쉬운 방식으로 이해해 봅시다. 이 개념들만 확실히 잡으면 이후 작업은 일사천리입니다.
| 핵심 개념 | 쉬운 설명 | 해결하는 문제 |
|---|---|---|
| 통합 인터페이스 | 모든 모델을 동일한 방식으로 호출 | 모델마다 SDK를 따로 배울 필요 없음 |
| Provider(제공업체) | OpenAI, Anthropic 등 모델 제조사 | 업체별 연결 방식 관리 |
| Fallback(장애 조치) | 모델 A가 죽으면 자동으로 모델 B로 전환 | 서비스 중단 방지 |
| Virtual Key(가상 키) | 팀원에게 '하위 계정' 발급 | 사용량 및 예산 제어 |
| Proxy(프록시 게이트웨이) | 독립적으로 실행되는 중계 서버 | 어떤 언어, 어떤 도구든 연결 가능 |
LiteLLM은 어떤 고충을 해결할까요?
LiteLLM이 없는 세상을 상상해 보세요.
OpenAI 호출:
from openai import OpenAI
client = OpenAI(api_key="sk-xxx")
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": "안녕하세요"}]
)
Anthropic 호출:
import anthropic
client = anthropic.Anthropic(api_key="sk-ant-xxx")
response = client.messages.create(
model="claude-sonnet-4-20250514",
max_tokens=1024, # Anthropic은 필수 지정
messages=[{"role": "user", "content": "안녕하세요"}]
)
Google Gemini 호출:
import google.generativeai as genai
genai.configure(api_key="AIza-xxx")
model = genai.GenerativeModel("gemini-2.0-flash")
response = model.generate_content("안녕하세요")
보이시나요? 모델 3개에 SDK 3개, 작성법도 3가지입니다. 프로젝트에서 모델을 교체해야 한다면 코드 곳곳에 if provider == "openai"... elif provider == "anthropic"... 같은 조건문이 가득하게 될 겁니다.
LiteLLM을 사용하면:
import litellm
# OpenAI 호출
response = litellm.completion(model="gpt-4o", messages=[{"role": "user", "content": "안녕하세요"}])
# Anthropic 호출 — 동일한 작성법
response = litellm.completion(model="anthropic/claude-sonnet-4-6", messages=[{"role": "user", "content": "안녕하세요"}])
# Gemini 호출 — 역시 동일한 작성법
response = litellm.completion(model="gemini/gemini-2.0-flash", messages=[{"role": "user", "content": "안녕하세요"}])
litellm.completion() 하나면 충분합니다. model 파라미터만 바꾸면 되죠. LiteLLM이 내부적으로 형식 변환, 파라미터 조정, 응답 표준화를 자동으로 처리합니다.
🎯 기술 제안: LiteLLM의 통합 인터페이스 철학은 APIYI(apiyi.com)와 유사합니다. 둘 다 하나의 인터페이스로 여러 모델을 호출할 수 있죠. 차이점은 LiteLLM은 오픈소스 기반의 직접 배포형 솔루션이고, APIYI는 별도의 배포가 필요 없는 관리형 서비스라는 점입니다. 팀의 기술 역량에 맞춰 적절한 방식을 선택해 보세요.
LiteLLM 두 가지 사용 모드 상세 가이드
LiteLLM은 다양한 환경에 맞춰 사용할 수 있도록 두 가지 모드를 제공합니다. 이 두 모드의 차이점을 이해하는 것이 올바른 사용 방식을 선택하는 핵심입니다.
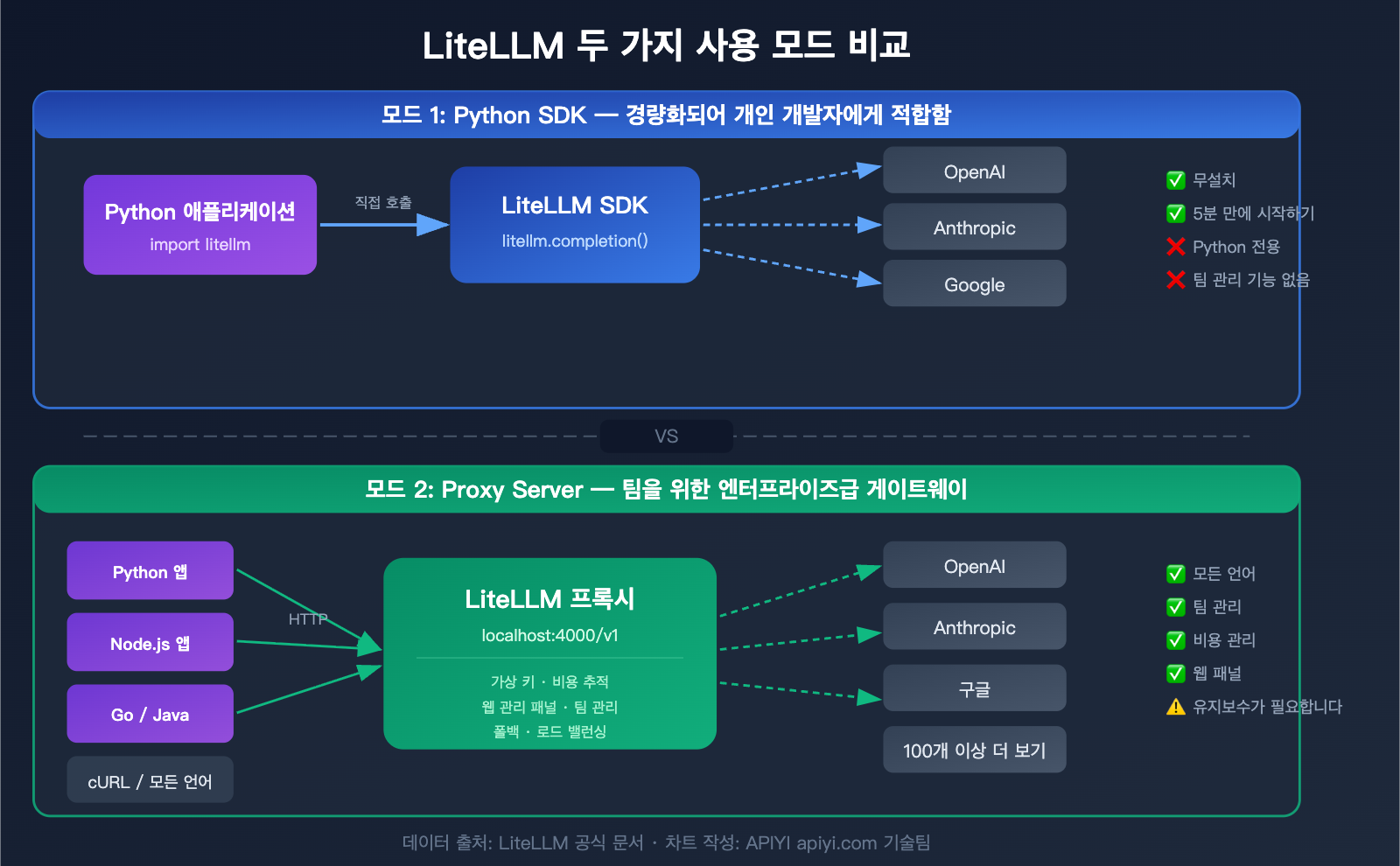
모드 1: Python SDK (경량형)
Python 코드에서 litellm 패키지를 직접 임포트하여 함수 호출하듯 간편하게 사용할 수 있습니다.
적합한 상황:
- 개인 개발자
- 순수 Python 프로젝트
- 빠른 프로토타입 검증
- 별도의 팀 관리 기능이 필요 없는 경우
설치:
pip install litellm
기본 사용법:
import litellm
import os
# API 키 설정 (환경 변수 사용)
os.environ["OPENAI_API_KEY"] = "sk-당신의키"
os.environ["ANTHROPIC_API_KEY"] = "sk-ant-당신의키"
# 원하는 모델 호출
response = litellm.completion(
model="gpt-4o",
messages=[{"role": "user", "content": "API 게이트웨이가 무엇인지 설명해줘"}]
)
print(response.choices[0].message.content)
모드 2: Proxy Server (엔터프라이즈급 게이트웨이)
독립적인 서버로 실행되며, 외부에는 OpenAI와 호환되는 HTTP 인터페이스를 제공합니다. HTTP 요청을 보낼 수 있는 모든 프로그래밍 언어나 도구에서 사용할 수 있습니다.
적합한 상황:
- 팀 단위 협업
- 다국어 프로젝트 (Java, Go, Node.js 등)
- 비용 추적 및 예산 관리가 필요한 경우
- 팀별로 가상 키를 할당해야 하는 경우
- AI 에이전트 프레임워크 연동
설치 및 실행:
# 설치
pip install 'litellm[proxy]'
# 설정 파일로 실행
litellm --config config.yaml --port 4000
# 또는 Docker 사용
docker run -p 4000:4000 \
-e OPENAI_API_KEY=sk-xxx \
ghcr.io/berriai/litellm:main-latest
실행 후, 어떤 애플리케이션이든 OpenAI를 호출하는 것과 동일한 방식으로 사용할 수 있습니다.
from openai import OpenAI
# base_url을 LiteLLM Proxy로 지정
client = OpenAI(
api_key="sk-당신의가상키",
base_url="http://localhost:4000/v1"
)
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": "안녕하세요"}]
)
LiteLLM SDK vs Proxy 모드 비교
| 비교 항목 | Python SDK | Proxy Server |
|---|---|---|
| 설치 방식 | pip install litellm |
pip install 'litellm[proxy]' 또는 Docker |
| 호출 방식 | Python 함수 호출 | HTTP API (모든 언어) |
| 설정 방식 | 코드 내 설정 | config.yaml 설정 파일 |
| 가상 키 관리 | 지원 안 함 | 지원 (예산 한도 설정 가능) |
| 웹 관리 패널 | 없음 | 있음 (시각적 관리) |
| 팀 관리 | 지원 안 함 | 지원 (사용자/팀/예산) |
| 비용 추적 | 기초 (코드 레벨) | 완전 (데이터베이스 영구 저장) |
| 배포 복잡도 | 배포 불필요 | 서버 운영 필요 |
| 권장 대상 | 개인 개발자 | 팀/기업 |
💡 선택 팁: 개인 개발자가 프로토타입을 검증하는 단계라면 SDK 모드로 5분 만에 시작해 보세요. 팀 단위로 사용하거나 운영 환경이라면 Proxy 모드가 훨씬 적합합니다. 물론, 직접 서버를 배포하고 유지 관리하는 것이 번거롭다면 APIYI(apiyi.com)와 같은 관리형 통합 인터페이스 서비스를 사용하여 바로 시작할 수도 있습니다.
LiteLLM 퀵 스타트 가이드
LiteLLM을 처음부터 시작하는 전체 단계를 정리해 드립니다.
LiteLLM SDK 모드 퀵 스타트
1단계: 설치
pip install litellm
2단계: 환경 변수 설정
# macOS / Linux
export OPENAI_API_KEY="sk-당신의키"
export ANTHROPIC_API_KEY="sk-ant-당신의키"
# Windows
set OPENAI_API_KEY=sk-당신의키
3단계: 코드 작성
import litellm
# 기본 호출
response = litellm.completion(
model="gpt-4o",
messages=[
{"role": "system", "content": "당신은 기술 어시스턴트입니다."},
{"role": "user", "content": "LLM 게이트웨이란 무엇인가요?"}
],
temperature=0.7
)
print(response.choices[0].message.content)
print(f"토큰 사용량: {response.usage.total_tokens}")
print(f"예상 비용: ${response._hidden_params.get('response_cost', 'N/A')}")
전체 코드 보기: Fallback 및 스트리밍 출력 포함
import litellm
import os
os.environ["OPENAI_API_KEY"] = "sk-당신의키"
os.environ["ANTHROPIC_API_KEY"] = "sk-ant-당신의키"
# Fallback 호출: GPT-4o 실패 시 자동으로 Claude로 전환
response = litellm.completion(
model="gpt-4o",
messages=[{"role": "user", "content": "RESTful API를 설명해주세요"}],
fallbacks=["anthropic/claude-sonnet-4-6"],
num_retries=2
)
# 스트리밍 출력
stream = litellm.completion(
model="gpt-4o",
messages=[{"role": "user", "content": "프로그래밍에 관한 시를 써줘"}],
stream=True
)
for chunk in stream:
content = chunk.choices[0].delta.content
if content:
print(content, end="", flush=True)
LiteLLM Proxy 모드 퀵 스타트
1단계: 설정 파일 config.yaml 생성
model_list:
- model_name: gpt-4o
litellm_params:
model: openai/gpt-4o
api_key: os.environ/OPENAI_API_KEY
- model_name: claude-sonnet
litellm_params:
model: anthropic/claude-sonnet-4-6
api_key: os.environ/ANTHROPIC_API_KEY
- model_name: gemini-flash
litellm_params:
model: gemini/gemini-2.0-flash
api_key: os.environ/GEMINI_API_KEY
litellm_settings:
drop_params: true
num_retries: 3
general_settings:
master_key: sk-my-master-key
2단계: Proxy 실행
litellm --config config.yaml --port 4000
3단계: 표준 OpenAI SDK를 사용한 호출
from openai import OpenAI
client = OpenAI(
api_key="sk-my-master-key",
base_url="http://localhost:4000/v1"
)
# GPT-4o 호출 (LiteLLM Proxy 경유)
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": "안녕하세요"}]
)
print(response.choices[0].message.content)
cURL을 사용하여 직접 호출할 수도 있습니다:
curl http://localhost:4000/v1/chat/completions \
-H "Authorization: Bearer sk-my-master-key" \
-H "Content-Type: application/json" \
-d '{
"model": "claude-sonnet",
"messages": [{"role": "user", "content": "Hello"}]
}'
🚀 빠른 시작: LiteLLM Proxy는 서버와 API 키를 직접 관리해야 합니다. 배포 없이 통합 인터페이스를 바로 사용하고 싶다면 APIYI(apiyi.com)를 확인해 보세요. 인프라 구축 없이도 100개 이상의 모델을 OpenAI 호환 형식으로 바로 호출할 수 있습니다.
AI 에이전트에서 LiteLLM의 핵심 역할
많은 초보자가 궁금해하는 점입니다. 왜 거의 모든 주류 AI 에이전트 프레임워크가 LiteLLM을 지원하거나 권장할까요?
AI 에이전트에 LiteLLM이 필요한 이유
AI 에이전트는 작업을 수행할 때 다음과 같은 기능이 자주 필요합니다:
- 다양한 모델 호출: 간단한 작업은 저렴한 소형 모델로, 복잡한 추론은 대규모 언어 모델로 처리
- 자동 장애 조치(Fallback): 주력 모델의 속도 제한이나 서버 다운 시 자동으로 예비 모델로 전환
- 비용 제어: 여러 에이전트가 동시에 실행될 때 토큰 비용을 통합 추적하고 제한
- 팀 협업: 여러 개발자의 에이전트가 API 리소스 풀을 공유
LiteLLM은 이러한 요구사항을 완벽하게 해결합니다. 에이전트와 모델 사이의 '스케줄링 센터' 역할을 수행하는 것이죠.
LiteLLM과 주요 AI 에이전트 프레임워크 통합
| 에이전트 프레임워크 | 통합 방식 | 일반적인 활용 |
|---|---|---|
| LangChain / LangGraph | SDK 내장 지원 | ChatLiteLLM을 LLM 백엔드로 사용 |
| CrewAI | Proxy 연결 | 다중 에이전트 모델 리소스 풀 공유 |
| AutoGen (Microsoft) | Proxy 연결 | OpenAI 호환 엔드포인트로 접속 |
| Dify | 사용자 정의 Provider | OpenAI 호환 엔드포인트로 설정 |
| Open WebUI | Proxy 연결 | 백엔드 API 엔드포인트 |
| Aider | Proxy 연결 | 코드 생성 에이전트의 모델 계층 |
| Continue.dev | Proxy 연결 | IDE 내 AI 코딩 어시스턴트 백엔드 |
다중 에이전트 시스템에서의 LiteLLM 일반적인 아키텍처
다중 에이전트 시스템에서 LiteLLM Proxy는 보통 다음과 같이 작동합니다:
- 기획 에이전트 → Claude Opus 호출 (고성능 추론 모델)
- 실행 에이전트 → GPT-4o 호출 (성능 균형)
- 검증 에이전트 → GPT-4o-mini 호출 (빠르고 저렴한 비용)
- 요약 에이전트 → Gemini Flash 호출 (대규모 컨텍스트 윈도우)
모든 에이전트는 동일한 LiteLLM Proxy 엔드포인트를 통해 호출되며, Proxy가 자동으로 올바른 백엔드 모델로 라우팅합니다. 관리자는 대시보드를 통해 모든 에이전트의 토큰 사용량과 비용을 한눈에 확인할 수 있습니다.
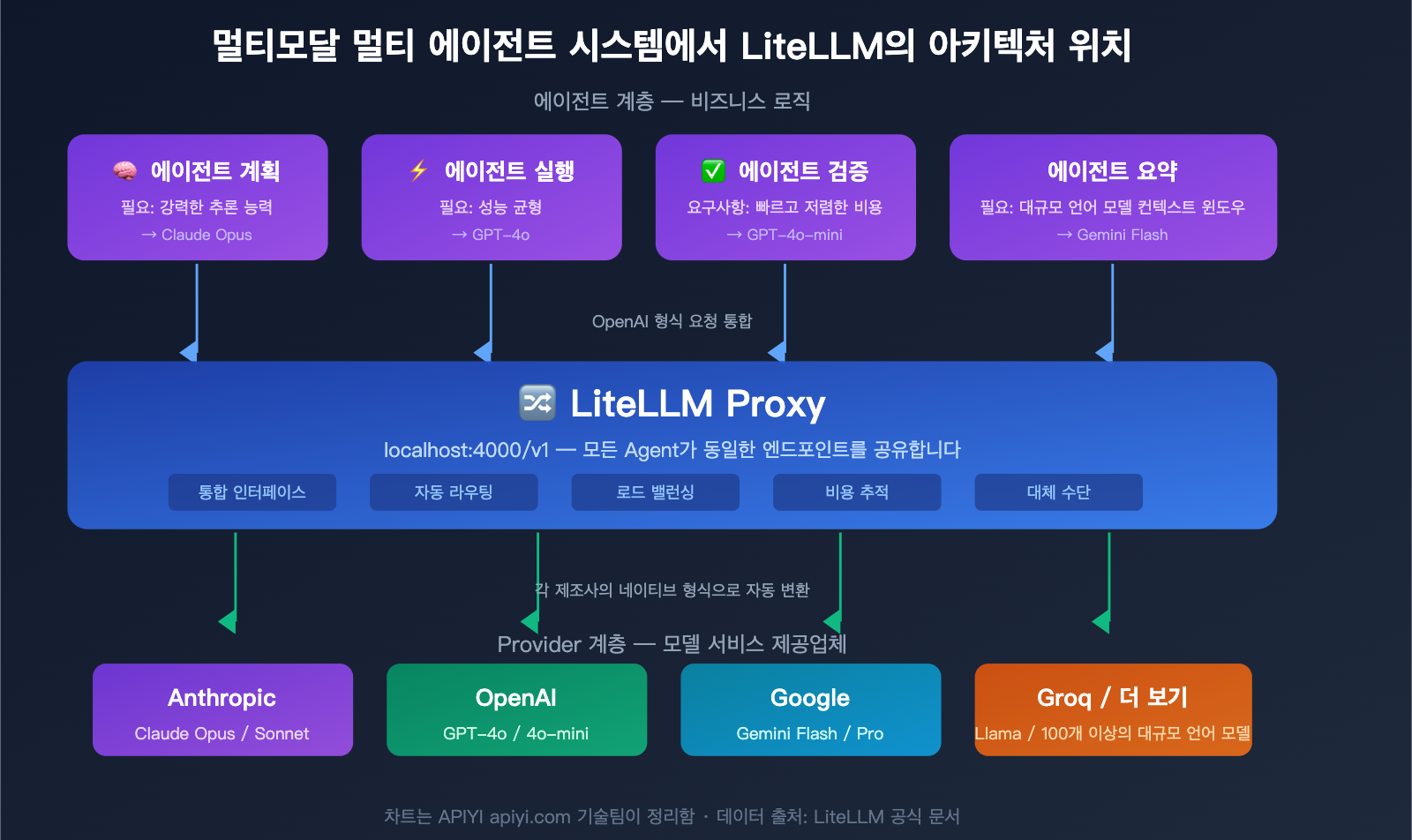
🎯 기술 제안: 프로덕션 환경의 다중 에이전트 시스템에서 LiteLLM Proxy를 사용하려면 비용 추적 및 캐싱 기능을 위해 PostgreSQL과 Redis가 필요합니다. 팀 규모가 작거나 추가 인프라를 운영하고 싶지 않다면, APIYI(apiyi.com)를 고려해 보세요. 비용 추적과 사용량 통계가 내장된 통합 인터페이스를 제공하므로 별도의 데이터베이스를 배포할 필요가 없습니다.
LiteLLM 고급 기능 상세 가이드
기본적인 사용법을 익히셨다면, 이제 프로덕션 환경에서 가장 자주 쓰이는 3가지 고급 기능을 살펴볼 차례입니다.
고급 기능 1: 모델 Fallback (장애 조치)
주력 모델에서 속도 제한, 타임아웃 또는 오류가 발생할 때, LiteLLM이 자동으로 예비 모델로 전환하여 서비스 중단을 방지합니다.
SDK에서 Fallback 설정:
response = litellm.completion(
model="gpt-4o",
messages=messages,
fallbacks=["anthropic/claude-sonnet-4-6", "gemini/gemini-2.0-flash"],
num_retries=2
)
실행 로직: GPT-4o 우선 시도 → 실패 시 Claude Sonnet 시도 → 다시 실패 시 Gemini Flash 시도.
Proxy에서 Fallback 설정 (config.yaml):
litellm_settings:
fallbacks:
- gpt-4o: [claude-sonnet, gemini-flash]
- claude-sonnet: [gpt-4o, gemini-flash]
고급 기능 2: 로드 밸런싱
하나의 모델 이름에 여러 백엔드 배포를 설정하면, LiteLLM이 요청을 자동으로 분산 처리합니다.
model_list:
# 동일한 모델명에 두 개의 다른 백엔드 설정
- model_name: gpt-4o
litellm_params:
model: openai/gpt-4o
api_key: os.environ/OPENAI_KEY_1
- model_name: gpt-4o
litellm_params:
model: azure/gpt-4o-deployment
api_key: os.environ/AZURE_KEY_1
api_base: https://my-azure.openai.azure.com
router_settings:
routing_strategy: least-busy # 부하가 가장 적은 모델 우선
# 기타 전략: simple-shuffle, latency-based
호출 시 model="gpt-4o"만 지정하면, LiteLLM이 알아서 OpenAI 직연동과 Azure 배포 사이에서 트래픽을 분산합니다.
고급 기능 3: 비용 추적 및 가상 키
가상 키 생성 (Proxy 모드):
curl http://localhost:4000/key/generate \
-H "Authorization: Bearer sk-master-key" \
-H "Content-Type: application/json" \
-d '{
"max_budget": 50.0,
"budget_duration": "monthly",
"models": ["gpt-4o", "claude-sonnet"],
"metadata": {"user": "developer-01"}
}'
이렇게 하면 월간 예산이 50달러로 제한되고, GPT-4o와 Claude Sonnet만 호출할 수 있는 가상 키가 생성됩니다.
비용 추적:
LiteLLM은 모델별 가격표를 내장하고 있어 API 호출 시마다 비용을 자동으로 계산합니다. Proxy 관리 대시보드에서 다음을 확인할 수 있습니다:
- 모델별 총 사용 비용
- 사용자/팀별 상세 비용 내역
- 기간별 비용 추이
- 토큰 사용량 통계
💰 비용 최적화: LiteLLM의 비용 추적 기능을 활용하면 어떤 모델 호출이 가장 많은 비용을 차지하는지 쉽게 파악할 수 있습니다. APIYI(apiyi.com)의 가격 경쟁력과 결합하면, 동일한 모델 호출이라도 더 저렴한 가격으로 이용할 수 있어 AI 애플리케이션 운영 비용을 획기적으로 낮출 수 있습니다.
LiteLLM이 지원하는 100개 이상의 모델 Provider 목록
LiteLLM은 매우 방대한 Provider를 지원합니다. 가장 자주 사용되는 카테고리는 다음과 같습니다:
| 카테고리 | Provider | 모델 접두사 | 대표 모델 |
|---|---|---|---|
| 상업용 대규모 언어 모델 | OpenAI | openai/ |
GPT-4o, GPT-4o-mini, o3 |
| Anthropic | anthropic/ |
Claude Opus 4, Sonnet 4, Haiku | |
gemini/ |
Gemini 2.0 Flash, Gemini 2.5 Pro | ||
| 클라우드 플랫폼 | Azure OpenAI | azure/ |
Azure 배포 GPT 시리즈 |
| AWS Bedrock | bedrock/ |
Bedrock 호스팅 Claude/Llama | |
| Google Vertex AI | vertex_ai/ |
Vertex 호스팅 Gemini | |
| 추론 가속 | Groq | groq/ |
Llama 3.1 70B (초고속 추론) |
| Together AI | together_ai/ |
각종 오픈소스 모델 | |
| Fireworks AI | fireworks_ai/ |
고성능 추론 | |
| 로컬 배포 | Ollama | ollama/ |
로컬 구동 Llama/Mistral |
| vLLM | openai/ (사용자 정의 base) |
자체 호스팅 추론 엔진 | |
| 국산 모델 | Deepseek | deepseek/ |
Deepseek Chat/Coder |
| 검색 증강 | Perplexity | perplexity/ |
Sonar Pro |
| 통합 플랫폼 | OpenRouter | openrouter/ |
각종 모델 |
🎯 선택 가이드: 모델 선택은 구체적인 상황에 따라 달라집니다. 어떤 모델을 써야 할지 고민된다면 APIYI(apiyi.com) 플랫폼에서 다양한 모델의 성능을 빠르게 테스트해 보세요. 해당 플랫폼 또한 위 모델 대부분에 대해 OpenAI 호환 인터페이스 호출을 지원합니다.

LiteLLM 자주 묻는 질문(FAQ)
Q1: LiteLLM과 OpenAI SDK를 직접 사용하는 것의 차이점은 무엇인가요?
OpenAI SDK는 OpenAI 모델만 호출할 수 있습니다. 반면 LiteLLM은 OpenAI SDK를 기반으로 확장되어 Anthropic, Google, Azure 등 100개 이상의 모델 제공업체를 동일한 코드 형식으로 호출할 수 있게 해줍니다. 프로젝트에서 OpenAI 모델만 사용한다면 OpenAI SDK를 직접 사용해도 충분합니다. 하지만 다중 모델 지원, 장애 조치(Failover) 또는 비용 관리가 필요하다면 LiteLLM이 더 나은 선택입니다.
Q2: LiteLLM은 무료인가요?
LiteLLM의 핵심 기능은 완전히 오픈 소스이며 무료(MIT 라이선스)입니다. 단, 주의할 점은 LiteLLM 자체는 무료이지만, 이를 통해 호출하는 모델 API는 유료라는 점입니다. OpenAI, Anthropic 등 공식 홈페이지에서 직접 API 키를 발급받아 모델 호출 비용을 지불해야 합니다. 여러 API 키를 각각 관리하기 번거롭다면 APIYI(apiyi.com)와 같은 통합 인터페이스 플랫폼을 사용하여 키 관리를 간소화할 수도 있습니다.
Q3: LiteLLM Proxy를 실행하려면 어떤 서버 사양이 필요한가요?
LiteLLM Proxy 자체는 매우 가벼워서 1코어 1GB 메모리 서버에서도 충분히 실행 가능합니다. 다만 비용 추적, 가상 키 관리 등 전체 기능을 사용하려면 PostgreSQL 데이터베이스와 Redis가 필요합니다. 운영 환경에서는 최소 2코어 4GB + PostgreSQL + Redis 구성을 권장합니다.
Q4: LiteLLM과 OpenRouter의 차이점은 무엇인가요?
가장 큰 차이점은 LiteLLM은 오픈 소스 자가 배포 솔루션이고, OpenRouter는 관리형 서비스라는 점입니다.
- LiteLLM: 무료, 직접 배포, 직접 API 키 관리, 데이터 흐름을 완전히 제어 가능
- OpenRouter: 즉시 사용 가능, 단 API 호출 가격에 수수료가 포함되며 데이터가 제3자를 거침
데이터 프라이버시를 중요하게 생각하거나 이미 보유한 API 키가 있다면 LiteLLM을 선택하세요. 별도의 배포 없이 빠르게 사용하고 싶다면 APIYI(apiyi.com)와 같은 관리형 솔루션을 고려해 보세요.
Q5: LiteLLM은 스트리밍 출력을 지원하나요?
네, 지원합니다. SDK 모드든 Proxy 모드든 LiteLLM은 SSE 스트리밍 출력을 완벽하게 지원합니다. 모든 제공업체의 스트리밍 응답은 일관된 스트리밍 경험을 위해 OpenAI 형식의 덩어리(chunk)로 통일되어 변환됩니다.
# 스트리밍 예제 코드
stream = litellm.completion(
model="gpt-4o",
messages=[{"role": "user", "content": "이야기를 하나 써줘"}],
stream=True
)
for chunk in stream:
print(chunk.choices[0].delta.content or "", end="")
Q6: 초보자는 SDK 모드와 Proxy 모드 중 무엇을 선택해야 하나요?
Python 개발자이고 이제 막 배우기 시작했다면 SDK 모드로 시작하는 것이 가장 간단합니다. pip install litellm 명령어로 설치한 뒤 몇 줄의 코드만으로 바로 실행할 수 있습니다. 팀 협업, 다중 언어 지원 또는 운영 배포가 필요할 때 Proxy 모드로 전환해도 늦지 않습니다. 두 모드의 핵심 호출 방식은 동일하므로 전환 비용은 매우 낮습니다.
Q7: LiteLLM의 config.yaml 설정 파일은 어디에 두어야 하나요?
정해진 위치는 없습니다. Proxy를 시작할 때 --config 매개변수로 경로를 지정하면 됩니다:
litellm --config /path/to/your/config.yaml
일반적으로 프로젝트 루트 디렉토리나 별도의 설정 디렉토리에 두는 것을 권장합니다. Docker로 배포하는 경우 볼륨 마운트를 통해 컨테이너 내부로 전달하세요.
LiteLLM 빠른 의사결정 가이드
현재 상황에 맞춰 가장 적합한 솔루션을 선택하세요:
| 상황 | 추천 솔루션 | 이유 |
|---|---|---|
| 개인 개발자, Python 프로젝트 | LiteLLM SDK | 배포 불필요, 5분 만에 시작 |
| 팀 개발, 예산 관리 필요 | LiteLLM Proxy | 가상 키 + 비용 추적 |
| 인프라 구축을 원치 않음 | APIYI (apiyi.com) | 관리형 서비스, 즉시 사용 가능 |
| 다중 에이전트 시스템 | LiteLLM Proxy | 통합 라우팅 + 로드 밸런싱 |
| OpenAI 모델만 사용 | OpenAI SDK 직접 사용 | 추가 계층 불필요 |
| 데이터 프라이버시 중요 | LiteLLM 자가 배포 | 데이터가 제3자를 거치지 않음 |
요약
LiteLLM은 AI 애플리케이션 개발에서 매우 유용한 인프라 도구입니다. 핵심 가치를 한 문장으로 정리하자면, **"OpenAI 형식의 코드 하나로 100개 이상의 모델 제공업체 API를 호출할 수 있다"**는 점입니다.
초보자라면 다음 핵심 사항들을 기억하세요:
- LiteLLM은 '번역기'입니다: 통일된 형식의 요청을 각 모델의 API 형식으로 변환해 줍니다.
- 두 가지 모드: SDK(경량 파이썬 패키지)와 Proxy(독립형 게이트웨이 서버) 모드를 지원합니다.
- 핵심 가치: 통합 인터페이스, Fallback(대체 모델 전환), 로드 밸런싱, 비용 추적 기능을 제공합니다.
- 에이전트 프레임워크의 표준: LangChain, CrewAI, AutoGen 등 거의 모든 프레임워크가 LiteLLM을 지원합니다.
- 완전 오픈소스 무료: MIT 라이선스를 따르며, 자체 배포 시 비용이 전혀 들지 않습니다.
만약 LiteLLM Proxy를 직접 배포하고 운영하는 것이 부담스럽다면, APIYI(apiyi.com)와 같은 관리형 통합 인터페이스 서비스를 사용해 보세요. 하나의 API 키로 모든 주요 모델을 호출할 수 있어 배포 및 운영 부담을 덜 수 있습니다.
작성자: APIYI 기술팀
기술 교류: APIYI(apiyi.com)를 방문하여 더 많은 AI 모델 호출 튜토리얼과 기술 지원을 받아보세요.
업데이트 날짜: 2026년 4월
적용 버전: LiteLLM v1.x+
참고 자료:
- LiteLLM 공식 문서: docs.litellm.ai
- LiteLLM GitHub 저장소: github.com/BerriAI/litellm
- LiteLLM 공식 웹사이트: litellm.ai
- BerriAI 공식 웹사이트: berri.ai