Você está usando o OpenClaw no seu fluxo de trabalho diário, mas toda vez que vê a conta da API no fim do mês, sente um aperto no peito — $300, $500 ou até mais de $600?
O problema não é você, é o design de arquitetura do OpenClaw. Uma instância do OpenClaw sem otimização envia uma grande quantidade de "conteúdo desnecessário" para o modelo de IA em cada tarefa, desperdiçando Tokens à toa.
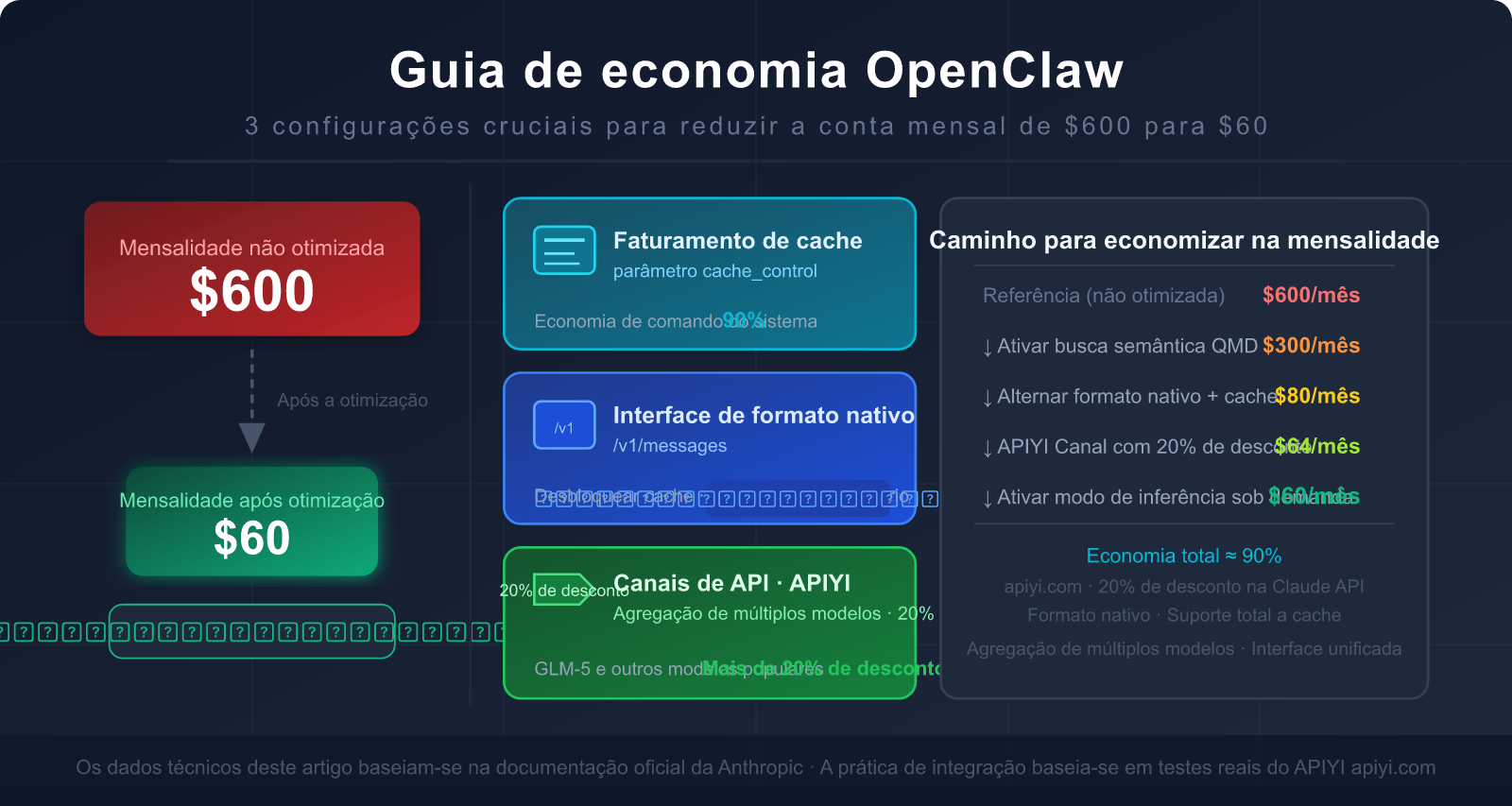
A boa notícia é: algumas configurações fundamentais podem reduzir sua fatura em 80-90%, e a maioria das pessoas não conhece a dica mais valiosa — usar a interface de formato nativo do Claude, em vez do modo de compatibilidade OpenAI.
Este artigo analisa profundamente a causa raiz do alto consumo de Tokens no OpenClaw e ensina passo a passo como acertar na escolha da interface, configurar o cache e escolher os canais de API certos para baixar sua fatura mensal de $600 para apenas $60.
1. Por que o OpenClaw consome tanto Token: 3 motivos principais
Motivo 1: Reenvio de todo o histórico de diálogo em cada requisição
Este é o motivo mais ignorado, mas o que causa o maior impacto.
O OpenClaw foi projetado seguindo o princípio do "contexto completo": toda vez que ele faz uma requisição ao modelo de IA, ele envia todas as mensagens do histórico desde o início da conversa. É assim que o modelo consegue "lembrar" do que foi feito ou dito anteriormente.
Veja um exemplo:
Rodada 1: Usuário envia 50 tokens, IA responde 200 tokens → 250 tokens enviados nesta vez
Rodada 2: Usuário envia 50 tokens, IA responde 200 tokens → 500 tokens enviados (incluindo rodada 1)
Rodada 3: Usuário envia 50 tokens, IA responde 200 tokens → 750 tokens enviados (incluindo rodadas 1+2)
...
Rodada 10: Na prática, apenas 250 tokens novos foram gerados, mas o volume enviado já é de 2.500 tokens
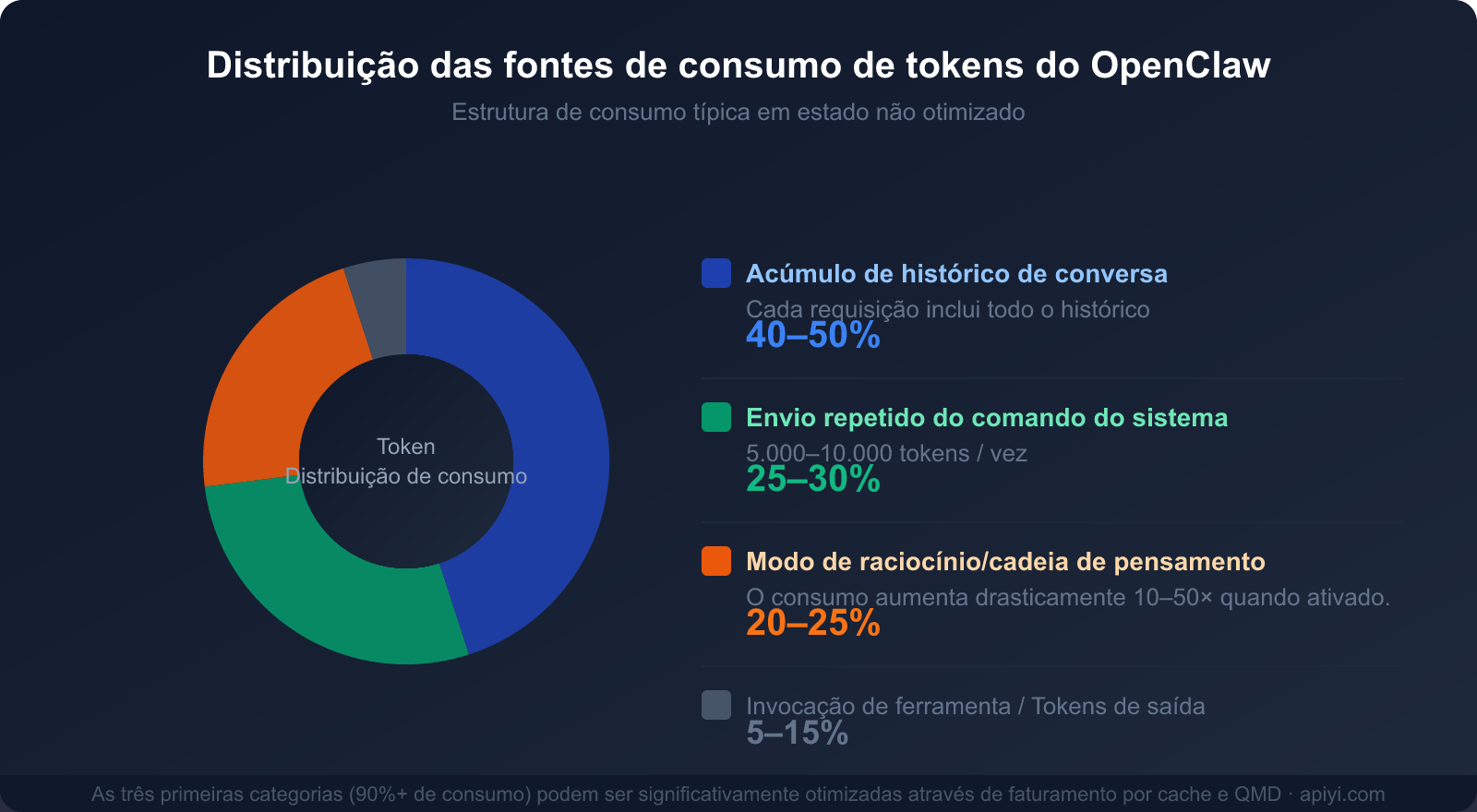
Em um fluxo de trabalho do OpenClaw que lida com tarefas complexas, esse "efeito bola de neve" faz com que o consumo de tokens cresça em progressão geométrica. O histórico de contexto geralmente representa de 40% a 50% do consumo total de tokens.
Motivo 2: O System Prompt é reenviado todas as vezes
O System Prompt (comando do sistema) do OpenClaw define a identidade do Agent, seus limites de capacidade, a lista de ferramentas disponíveis, normas de conduta e outros conteúdos essenciais. Geralmente, ele fica entre 5.000 e 10.000 tokens.
O problema crucial: esse System Prompt gigantesco é enviado integralmente em cada chamada de API.
Suponha que você use o OpenClaw para processar 50 tarefas por dia, e cada System Prompt tenha 8.000 tokens:
Consumo diário de System Prompt = 50 × 8.000 = 400.000 tokens
Consumo mensal ≈ 12.000.000 tokens (apenas com System Prompt!)
Considerando o preço de entrada do Claude Sonnet 4.6 (US$ 3 por milhão de tokens), apenas o System Prompt custaria US$ 36 por mês. E isso sem contar o conteúdo da conversa e a saída gerada.
Motivo 3: O modo de raciocínio aumenta o consumo de tokens em 10 a 50 vezes
Quando o OpenClaw encontra uma tarefa complexa, ele ativa a "Cadeia de Pensamento" ou "Modo de Raciocínio" (Thinking/Reasoning). Esse modo faz com que a IA "pense bem antes de falar", o que aumenta a qualidade da resposta — mas o preço é um aumento explosivo no consumo de tokens.
Características do consumo de tokens de raciocínio:
- O processo de pensamento gera uma grande quantidade de tokens intermediários (geralmente invisíveis, mas faturados).
- O processo de raciocínio de uma tarefa complexa pode gerar entre 10.000 e 50.000 tokens.
- Se não for controlado, algumas tarefas complexas podem esgotar o orçamento de um dia inteiro.
| Cenário de consumo de Token | Modo Normal | Modo de Raciocínio | Diferença de Magnitude |
|---|---|---|---|
| Tarefas simples de Q&A | ~500 tokens | ~2.000 tokens | 4 vezes |
| Fluxo de processamento de e-mails | ~2.000 tokens | ~15.000 tokens | 7,5 vezes |
| Tarefas de análise de código | ~5.000 tokens | ~80.000 tokens | 16 vezes |
| Pesquisas complexas de várias etapas | ~10.000 tokens | ~200.000 tokens | 20 vezes+ |
🎯 Diagnóstico rápido: Se a sua fatura do OpenClaw estiver anormalmente alta, verifique primeiro o uso do modo de raciocínio nos logs de tokens.
Desativar o modo de raciocínio para tarefas desnecessárias é uma das formas mais imediatas de economizar.
Mudar para um modelo mais adequado também pode reduzir drasticamente os custos — através da APIYI (apiyi.com), você pode alternar e testar diferentes modelos rapidamente.
Proporção de consumo dos três principais motivos
Entender essas três principais fontes de consumo é o primeiro passo para criar uma estratégia de economia:
| Fonte de Consumo | Proporção do Consumo Total | Otimizável? | Principais Métodos de Otimização |
|---|---|---|---|
| Histórico de diálogo (acúmulo de contexto) | 40-50% | ✅ Altamente otimizável | Cache, limpeza periódica, QMD |
| Reenvio do System Prompt | 25-30% | ✅ Altamente otimizável | Faturamento por cache (economiza 90%) |
| Modo de Raciocínio/Chain of Thought | 20-25% | ✅ Sob demanda | Ativar apenas para tarefas complexas |
| Chamadas de ferramentas e saída | 5-15% | ⚡ Otimização limitada | Simplificar descrições de ferramentas |
II. A ferramenta matadora para economizar: Prompt Caching do Claude
O que é o Prompt Caching do Claude
O Prompt Caching (Cache de Comandos) do Claude é uma funcionalidade nativa lançada pela Anthropic no final de 2024. A lógica central é: armazenar no servidor o conteúdo enviado repetidamente com frequência; as chamadas subsequentes leem diretamente do cache em vez de processar tudo de novo.
O preço da leitura do cache: apenas 10% do preço de entrada normal (90% de economia)
Isso significa que: cada vez que você envia um System Prompt de 8.000 tokens, após ativar o cache, as repetições que atingirem o cache serão cobradas como apenas 800 tokens. Para usuários do OpenClaw que enviam dezenas de requisições por dia, essa otimização sozinha pode economizar centenas de dólares por mês.
Estrutura completa de preços do Prompt Caching
| Tipo de Cache | Multiplicador de Custo | Tempo de Validade | Cenário de Uso |
|---|---|---|---|
| Token de entrada normal | 1× Preço base | Sem cache | Processamento novo a cada vez |
| Escrita no cache (Primeira vez) | 1.25× | 5 min TTL | Criação do cache |
| Escrita no cache (Longa duração) | 2× | 1 hora TTL | Cenários de chamadas frequentes |
| Leitura de cache (Hit) | 0.1× (90% de economia) | Dentro da validade | Requisições repetidas |
Exemplo de cálculo de economia real:
Cenário: System Prompt do OpenClaw com 8.000 tokens
50 chamadas por dia, sendo 48 com acerto no cache (hit)
Sem usar cache: 50 × 8.000 = 400.000 tokens
Custo = 400.000 × $3/1M = $1.20/dia = $36/mês
Com cache: 2 escritas: 2 × 8.000 × 1.25 = 20.000 tokens = $0.06
48 acertos: 48 × 8.000 × 0.1 = 38.400 tokens = $0.12
Custo diário ≈ $0.18 → Mensal ≈ $5.40
Economia: $36 - $5.40 = $30.60/mês (apenas no System Prompt)
Proporção de economia: 85%
Como ativar o Prompt Caching no OpenClaw
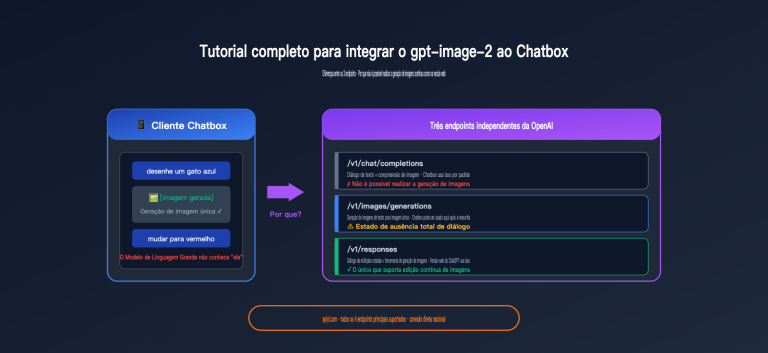
A ativação do cache tem um pré-requisito essencial: você deve usar a interface no formato nativo da Anthropic (/v1/messages), e não o modo de compatibilidade OpenAI (/v1/chat/completions).
Forma correta de configuração (Exemplo em Python SDK):
import anthropic
# É necessário usar o SDK nativo da Anthropic, não o da OpenAI
client = anthropic.Anthropic(
api_key="sua-chave-api",
base_url="https://api.apiyi.com/v1" # APIYI suporta o formato nativo da Anthropic
)
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=4096,
system=[
{
"type": "text",
"text": "Você é um assistente de IA profissional...[System Prompt de 8000 tokens]",
"cache_control": {"type": "ephemeral"} # ← Chave: marca este conteúdo como candidato ao cache
}
],
messages=[
{"role": "user", "content": "Ajude-me a organizar os e-mails de hoje"}
]
)
Restrições técnicas do cache:
- É possível definir no máximo 4 pontos de interrupção de cache (marcações
cache_control) - Série Sonnet: conteúdo mínimo cacheável ≥ 1.024 tokens
- Opus / Haiku 4.5: conteúdo mínimo cacheável ≥ 4.096 tokens
- Modelos que suportam cache: Claude Opus 4, Sonnet 4.6, Sonnet 4.5, Sonnet 4, Sonnet 3.7, Haiku 4.5, Haiku 3.5, Haiku 3, etc.
🎯 Dica Importante: A APIYI (apiyi.com) oferece suporte total para chamadas no formato nativo da Anthropic, incluindo o parâmetro
cache_control. Ao usar o formato nativo para chamar modelos Claude na APIYI, você aproveita o Prompt Caching (até 90% de economia) + o desconto de 20% da APIYI, gerando um efeito cumulativo impressionante.
III. Conhecimento Crítico: Por que o modo de compatibilidade OpenAI não economiza Tokens
Este é o ponto onde a maioria dos usuários do OpenClaw costuma cair em ciladas.
A diferença fundamental entre os dois formatos de interface
Muitas ferramentas de IA de terceiros e serviços de proxy oferecem o modo de compatibilidade OpenAI para facilitar a vida do usuário — ou seja, usar o formato de interface /v1/chat/completions da OpenAI para chamar modelos que não são da OpenAI, como o Claude.
Na superfície, isso permite que o usuário use "um único código para todos os modelos". Mas há uma falha fatal:
O formato de interface /v1/chat/completions não possui um lugar para o parâmetro cache_control — pois esta é uma funcionalidade nativa exclusiva da Anthropic.
Quando você chama o Claude através do formato compatível com OpenAI:
- Sua requisição é convertida para o formato OpenAI.
- O serviço proxy/intermediário a converte de volta para o formato nativo da Anthropic.
- No entanto, a informação do
cache_controljá foi perdida no primeiro passo. - O servidor do Claude recebe uma requisição sem marcação de cache e cobra o valor integral dos tokens todas as vezes.
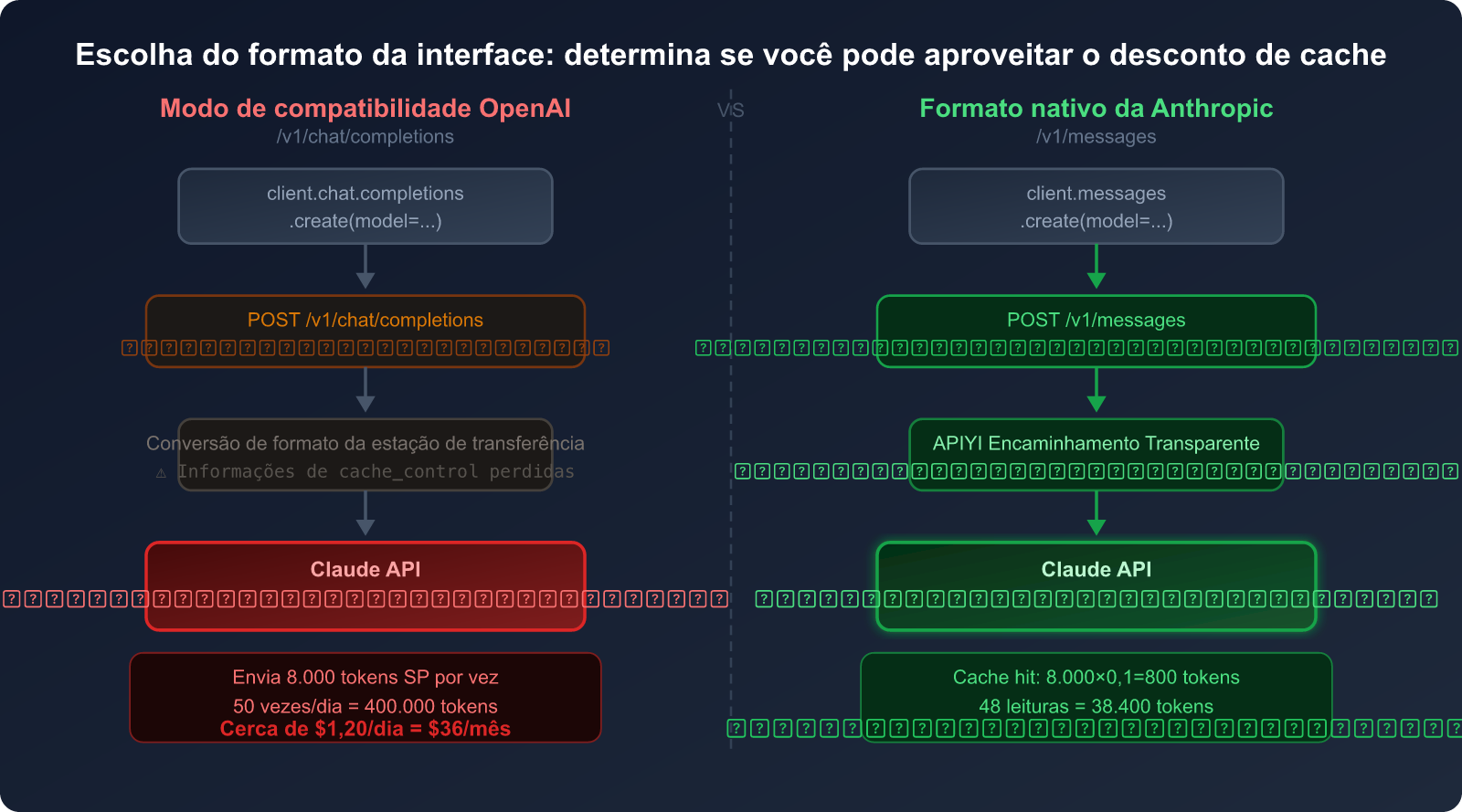
Comparação: Modo de Compatibilidade OpenAI vs Formato Nativo Anthropic
| Dimensão de Comparação | Modo de Compatibilidade OpenAI | Formato Nativo Anthropic |
|---|---|---|
| Caminho da Interface | /v1/chat/completions |
/v1/messages |
| Suporte a Cache do Claude | ❌ Não suportado | ✅ Suporte total |
Parâmetro cache_control |
❌ Campo inexistente | ✅ Suporta 4 pontos de interrupção |
| Cobrança do System Prompt | 💸 Valor integral (Preço 1×) | 💰 Leitura de cache (Preço 0.1×) |
| Complexidade do Código | Baixa (código genérico) | Média (requer SDK Anthropic) |
| Efeito de Economia (Alta Frequência) | 0% | Até 90% |
Problemas adicionais de implantações não originais
Além da questão do formato da interface, há outra situação que gera confusão: modelos com o "mesmo nome" implantados por provedores de nuvem não são iguais ao original.
Tomando o GLM-5 (Zhipu AI) como exemplo:
- API original no site z.ai: Suporta a funcionalidade de cache de comandos desenvolvida pela Zhipu.
- GLM-5 implantado na Alibaba Cloud / Tencent Cloud, etc.: Utiliza o gateway de API do provedor de nuvem e não possui a funcionalidade de cache original.
Isso não é um problema do GLM-5, mas sim um problema comum de implantações não originais: ao hospedar modelos, os provedores de nuvem geralmente expõem apenas a API de chat padrão e não transmitem as características privadas do fabricante original (como o cache de comandos).
Analogia: É como comprar um produto através de um revendedor; você pode não ter acesso aos serviços de pós-venda exclusivos oferecidos diretamente pelo fabricante oficial.
Impacto Real:
Cenário: 50 chamadas por dia, System Prompt de 6.000 tokens
API Original (com suporte a cache):
Escrita: 2 vezes × 6.000 × 1.25 = 15.000 tokens
Leitura: 48 vezes × 6.000 × 0.1 = 28.800 tokens
Consumo equivalente ≈ 43.800 tokens/dia
API Não Original (sem cache):
Valor integral: 50 vezes × 6.000 = 300.000 tokens/dia
Diferença: O consumo sem cache é 6,85 vezes maior do que com cache.
IV. Comparação de APIs Originais: Como escolher a melhor solução de acesso para o OpenClaw
Comparação de quatro soluções de acesso
| Solução de acesso | Preço (relativo ao original) | Suporte a cache | Suporte a múltiplos modelos | Cenário de uso |
|---|---|---|---|---|
| API oficial da Anthropic | 100% (preço original) | ✅ Completo | ❌ Apenas Claude | Orçamento folgado, usuário exclusivo de Claude |
| APIYI (formato nativo Anthropic) | 80% (20% de desconto) | ✅ Completo | ✅ Múltiplos modelos | Recomendado: Economia + Troca flexível |
| Proxy genérico (compatível com OpenAI) | 85-95% variável | ❌ Não suportado | ✅ Múltiplos modelos | Quando não se usa o cache do Claude |
| Implementação não original (Cloud Providers) | 90-110% variável | ❌ Não suportado | ❌ Modelo único | Cenários com requisitos de conformidade corporativa |
A lógica dupla de economia da APIYI
A vantagem da APIYI nos modelos Claude reside em: suportar simultaneamente o formato nativo da Anthropic e oferecer 20% de desconto.
A combinação desses dois pontos significa:
Usuário comum (Preço original + compatibilidade OpenAI, sem cache):
Consumo mensal de Tokens de System Prompt: 12.000.000 tokens
Custo = 12.000.000 × $3/1M = $36
Usuário APIYI (20% de desconto + formato nativo + cache):
Tokens faturados reais ≈ 1.440.000 tokens (após cache)
Custo = 1.440.000 × $3×0.8/1M = $3,46
Economia total = ($36 - $3,46) / $36 ≈ 90%
🎯 Sugestão de seleção: Se você usa o OpenClaw e escolhe principalmente o Claude como modelo,
é altamente recomendável acessar pelo formato nativo da Anthropic via APIYI (apiyi.com).
O preço base com 20% de desconto + os 90% economizados pelo cache podem reduzir sua fatura em 85-90%.
Além disso, a APIYI suporta GLM-5, GPT e outros modelos, facilitando a troca para comparar resultados a qualquer momento.
V. Guia Completo de Economia no OpenClaw: 5 passos para execução imediata
Passo 1: Mudar para a interface de formato nativo da Anthropic
Este é o passo mais importante, pois determina diretamente se você poderá aproveitar o faturamento por cache.
Método de configuração no OpenClaw:
Na configuração de modelos do OpenClaw (config.json), localize o campo models.providers e adicione a APIYI como provedor seguindo o formato abaixo. A chave é definir o campo api como "anthropic-messages", para que o formato nativo da Anthropic seja utilizado e o faturamento por cache seja suportado:
{
"models": {
"providers": {
"apiyi": {
"baseUrl": "https://api.apiyi.com",
"apiKey": "sk-insira-seu-token-aqui",
"api": "anthropic-messages",
"headers": {
"anthropic-version": "2023-06-01",
"anthropic-beta": ""
},
"models": [
{
"id": "claude-sonnet-4-6",
"name": "claude-sonnet-4-6",
"reasoning": false,
"input": ["text"],
"contextWindow": 200000,
"maxTokens": 16384
},
{
"id": "claude-sonnet-4-6-thinking",
"name": "claude-sonnet-4-6-thinking",
"reasoning": false,
"input": ["text"],
"contextWindow": 200000,
"maxTokens": 16384
}
]
}
}
}
}
Explicação dos pontos principais:
"api": "anthropic-messages"← O mais crítico, especifica o uso do formato nativo/v1/messagesem vez do formato compatível/v1/chat/completions."baseUrl": "https://api.apiyi.com"← Base URL da APIYI (não é necessário adicionar/v1, o OpenClaw fará a concatenação automaticamente)."anthropic-version": "2023-06-01"← Cabeçalho da versão da API Anthropic; a ausência deste cabeçalho causará falha na requisição.contextWindow: 200000← O Claude Sonnet 4.6 suporta uma janela de contexto de 200K.
Verificar se o cache está funcionando:
Verifique os campos cache_read_input_tokens e cache_creation_input_tokens nos cabeçalhos de resposta da API ou nos logs. Se houver valores, o cache está ativo:
# Validando a resposta do cache
response = client.messages.create(...)
# Verificando o campo usage
print(response.usage)
# Exemplo de saída:
# Usage(
# input_tokens=150, # Tokens novos nesta chamada
# cache_creation_input_tokens=8000, # Primeira gravação no cache (faturado a 1.25×)
# cache_read_input_tokens=0, # Hit de cache subsequente (faturado a 0.1×)
# output_tokens=300
# )
🎯 Forma de acesso: Após se registrar e obter sua chave API em apiyi.com,
basta configurar obase_urlparahttps://api.apiyi.com/v1para usar o formato nativo da Anthropic.
Não é necessário alterar outros códigos, e o faturamento por cache do Claude entrará em vigor imediatamente.
Passo 2: Posicionar os pontos de interrupção de cache corretamente
A localização do ponto de interrupção do cache (cache_control) é vital. Você deve colocar em cache conteúdos que são "grandes e fixos":
# Melhores práticas: Cache do comando de sistema + definições de ferramentas
response = client.messages.create(
model="claude-sonnet-4-6",
system=[
{
"type": "text",
"text": SYSTEM_PROMPT, # Comando de sistema principal de 5.000-10.000 tokens
"cache_control": {"type": "ephemeral"} # Ponto de interrupção 1
},
{
"type": "text",
"text": TOOL_DEFINITIONS, # Lista de ferramentas (geralmente grande também)
"cache_control": {"type": "ephemeral"} # Ponto de interrupção 2
}
],
messages=conversation_history, # Histórico de conversa (não cacheado, muda sempre)
...
)
Pontos principais da estratégia de cache:
- ✅ Ideal para cache: Comandos de sistema, definições de ferramentas, grandes blocos de documentos estáticos, conteúdo de documentos recuperados via RAG.
- ❌ Não recomendado para cache: Mensagens atuais do usuário, conteúdo gerado dinamicamente, dados que mudam a cada interação.
- ⚠️ Atenção à ordem: O cache funciona por correspondência de prefixo; o conteúdo estático deve ser colocado no início da sequência de mensagens.
Passo 3: Ativar o QMD para reduzir o tamanho do contexto
O QMD (Quick Memory Database) é a função de busca semântica local do OpenClaw. Veja como funciona:
Modo tradicional:
Envia [Todo o histórico da conversa] a cada vez → Consome muitos Tokens
Modo QMD:
Cria um banco de dados vetorial local → Busca os fragmentos históricos mais relevantes
Envia apenas as [3-5 mensagens históricas mais relevantes] por vez → Economiza 60-97% de Tokens
Efeito real de economia do QMD: De acordo com a documentação oficial do OpenClaw, o QMD pode atingir uma economia de 60-97% de Tokens, dependendo do volume do histórico de conversa e do tipo de tarefa.
Como ativar (Interface de configurações do OpenClaw):
- Settings → Memory → Enable QMD
- Defina o caminho de armazenamento do QMD (local, os dados não são enviados para a nuvem)
- Defina o limite de relevância (recomendado acima de 0.7 para evitar ruídos do histórico)
Passo 4: Escolher o modelo adequado de acordo com o tipo de tarefa
Nem todas as tarefas exigem o modelo mais potente. A alocação correta de modelos é a chave para o controle de custos:
Estratégia de classificação de tarefas:
Tarefas simples (Lembretes de agenda, conversão de formato, busca simples)
→ Use o Claude Haiku 4.5 (mais rápido, mais barato)
→ Custa cerca de 1/5 do preço do Sonnet
Tarefas médias (Processamento de e-mails, organização de arquivos, revisão de código)
→ Use o Claude Sonnet 4.6 (equilibrado)
→ Taxa de sucesso de 86.9% (1º lugar no PinchBench)
Tarefas complexas (Análise de arquitetura, pesquisa em múltiplas etapas, raciocínio complexo)
→ Use o Claude Opus 4.6 (raciocínio mais forte)
→ Ative o modo de raciocínio apenas quando for realmente necessário
Passo 5: Limpar o contexto periodicamente
O histórico de conversa é uma das maiores fontes de consumo de Tokens (40-50%). Sugestões:
- Definir um número máximo de rodadas de contexto: Resumir e limpar o histórico automaticamente após 15-20 rodadas.
- Limpeza manual após concluir uma tarefa: Redefinir o contexto antes de iniciar uma nova tarefa.
- Ativar a função de compressão de sessão do OpenClaw: Usar IA para comprimir históricos longos em resumos.
Estimativa do efeito combinado das cinco etapas de otimização
Com base em um usuário com uso moderado do OpenClaw (custo mensal não otimizado de aprox. $300-600), veja o efeito esperado após as cinco etapas:
| Etapa de otimização | Fonte de consumo alvo | Proporção de economia esperada | Dificuldade de execução |
|---|---|---|---|
| 1. Mudar para formato nativo Anthropic | Faturamento repetido de System Prompt | Economia de 85-90% (na parte de SP) | ⭐ Baixa (mudar base_url) |
| 2. Configurar pontos de cache | Definições de ferramentas + Docs estáticos | Economia de 80-90% (na parte de ferramentas) | ⭐⭐ Baixa-Média |
| 3. Ativar QMD | Tokens de histórico de conversa | Economia de 60-97% (na parte de histórico) | ⭐⭐ Baixa-Média |
| 4. Classificação de modelos por tarefa | Custo total de Tokens | Economia de 30-70% (diferença de preço entre modelos) | ⭐⭐⭐ Média |
| 5. Limpeza periódica de contexto | Efeito bola de neve do histórico | Economia de 20-40% (ganho a longo prazo) | ⭐ Baixa |
🎯 Sugestão de prioridade: O Passo 1 (mudar para formato nativo) e o Passo 3 (ativar QMD) são os dois passos com maior retorno e operação mais simples.
Recomenda-se priorizar esses dois, o que geralmente reduz a fatura em 60-80% imediatamente.
Ao acessar o Claude via APIYI (apiyi.com), o Passo 1 requer apenas a alteração de uma linha na configuração dobase_url, concluída em menos de 5 minutos.
6. Configuração Prática: Exemplo completo de OpenClaw + APIYI + Cache do Claude
Abaixo está um exemplo completo e otimizado de configuração do OpenClaw, ideal para a maioria dos usuários reutilizarem diretamente:
import anthropic
# Usando o formato nativo da Anthropic via APIYI
client = anthropic.Anthropic(
api_key="sk-your-apiyi-key", # Chave API do APIYI (obtenha em apiyi.com)
base_url="https://api.apiyi.com/v1"
)
# Define o comando do sistema (conteúdo grande, ideal para cache)
SYSTEM_PROMPT = """
Você é um assistente de IA profissional rodando na plataforma OpenClaw.
Suas responsabilidades incluem: gerenciar agendas, processar e-mails, organizar arquivos, auxiliar no desenvolvimento de código...
[Geralmente contém de 5.000 a 10.000 tokens de instruções detalhadas]
"""
# Define a lista de ferramentas (também um conteúdo fixo grande, ideal para cache)
TOOL_DEFINITIONS = """
Ferramentas disponíveis: calendar_api, email_api, file_system, code_runner...
[Descrição detalhada das ferramentas, geralmente de 2.000 a 5.000 tokens]
"""
def call_openclaw_with_cache(conversation_history: list, user_message: str):
"""Invocação do modelo via API do OpenClaw otimizada com cache ativado"""
response = client.messages.create(
model="claude-sonnet-4-6", # Primeiro lugar no PinchBench
max_tokens=4096,
# Comando do sistema: marcando pontos de interrupção do cache
system=[
{
"type": "text",
"text": SYSTEM_PROMPT,
"cache_control": {"type": "ephemeral"} # Ponto de cache 1
},
{
"type": "text",
"text": TOOL_DEFINITIONS,
"cache_control": {"type": "ephemeral"} # Ponto de cache 2
}
],
# Histórico de conversa + nova mensagem
messages=[
*conversation_history, # Mensagens de histórico (não cacheadas, mudam a cada vez)
{"role": "user", "content": user_message}
]
)
# Imprime o uso de tokens (para monitorar a eficácia da otimização)
usage = response.usage
print(f"Tokens de entrada: {usage.input_tokens}")
print(f"Escrita em cache: {usage.cache_creation_input_tokens}")
print(f"Leitura de cache: {usage.cache_read_input_tokens}")
print(f"Tokens de saída: {usage.output_tokens}")
return response.content[0].text
🎯 Início Rápido: Substitua a
api_keyno código acima pela chave que você obteve ao se registrar no APIYI (apiyi.com). Sem outras modificações, você poderá usar imediatamente a combinação do formato nativo da Anthropic + tarifação de cache + os 20% de desconto do APIYI.
Perguntas Frequentes (FAQ)
P: O APIYI realmente suporta o formato nativo da Anthropic (/v1/messages)?
Sim, o APIYI (apiyi.com) suporta simultaneamente dois formatos de interface:
- Formato nativo da Anthropic:
/v1/messages(suporta tarifação de cache) - Formato compatível com OpenAI:
/v1/chat/completions(facilita o uso de código genérico)
Para modelos Claude, recomenda-se fortemente o uso do formato nativo da Anthropic, pois só assim é possível aproveitar a tarifação de cache. Basta usar o SDK Python da anthropic e apontar o base_url para o APIYI.
🎯 Acesse APIYI (apiyi.com) para registrar uma conta; no console, você encontrará exemplos de código para ambos os formatos.
P: O TTL de cache de 5 minutos é suficiente? Como saber se preciso de um TTL de 1 hora?
Isso depende da sua frequência de chamadas:
- Se as suas chamadas ao OpenClaw ocorrem em intervalos < 5 minutos (como no processamento contínuo de um fluxo de tarefas), o TTL padrão de 5 minutos é suficiente.
- Se o intervalo entre chamadas estiver entre 5 minutos e 1 hora (como pausas após processar um lote de tarefas), considere o TTL de 1 hora (o custo é o dobro do preço de escrita, mas a taxa de acerto do cache será maior).
- Se o intervalo for > 1 hora, o cache perde o sentido, sendo melhor reescrever a cada vez.
P: Quais são as dicas para economizar ao usar modelos chineses como o GLM-5?
A funcionalidade de cache do GLM-5 requer chamadas via API nativa do site oficial da Zhipu AI (z.ai); implantações de terceiros, como no Alibaba Cloud, não podem utilizá-la.
O APIYI também suporta modelos chineses como o GLM-5 com preços com 20% de desconto ou mais, facilitando a comparação de desempenho entre modelos com uma interface unificada durante a fase de testes. Após determinar o modelo ideal para o seu cenário, você pode decidir se continua com o APIYI ou se conecta diretamente ao fabricante original.
P: Já estou usando um serviço proxy de API de terceiros, quão difícil é migrar para uma plataforma que suporta o formato nativo?
O custo de migração é muito baixo. A única coisa que precisa ser alterada são dois parâmetros no código:
# Antes da migração (Formato compatível com OpenAI)
from openai import OpenAI
client = OpenAI(api_key="sk-xxx", base_url="endereço_do_proxy_antigo")
response = client.chat.completions.create(model="claude-sonnet-4-6", ...)
# Depois da migração (Formato nativo Anthropic, com suporte a cache)
import anthropic
client = anthropic.Anthropic(
api_key="sk-NovaChaveAPIYI", # ← Troque pela chave do APIYI
base_url="https://api.apiyi.com/v1" # ← Troque pelo endereço do APIYI
)
response = client.messages.create(model="claude-sonnet-4-6", ...)
# Depois, basta adicionar cache_control no parâmetro system para ativar o cache
O trabalho principal consiste em mudar chat.completions.create para messages.create. O formato da mensagem tem diferenças sutis (a estrutura role/content é consistente, mas o system muda de uma string para uma lista de objetos). Geralmente, a migração pode ser concluída em menos de meio dia.
P: Como verificar se minha instância do OpenClaw ativou o cache com sucesso?
O método mais direto: ao fazer duas chamadas consecutivas, observe o objeto usage na resposta da API:
- Primeira chamada:
cache_creation_input_tokensterá um valor (escrita em cache). - Segunda chamada:
cache_read_input_tokensterá um valor (acerto de cache).
Se o cache_read_input_tokens da segunda chamada for igual ao número de tokens do seu Comando do Sistema (System Prompt), significa que o cache está funcionando plenamente.
P: O modo de raciocínio/pensamento (Extended Thinking) deve ser obrigatoriamente desativado?
Não precisa ser totalmente desativado, mas deve ser usado conforme a necessidade. Estratégia recomendada:
- Tarefas simples (classificação de e-mails, agendamentos): desative o modo de raciocínio.
- Tarefas médias (revisão de código, resumo de informações): desative por padrão, ative se houver dificuldade.
- Tarefas complexas (decisões de arquitetura, pesquisa em várias etapas): ative, mas defina um limite razoável de
budget_tokens.
Na API do Claude, você pode limitar o consumo máximo de tokens do modo de raciocínio através de thinking: {"type": "enabled", "budget_tokens": 5000}.
Resumo: A lógica central de economia do OpenClaw
Vamos resumir todas as estratégias de economia em um único gráfico:
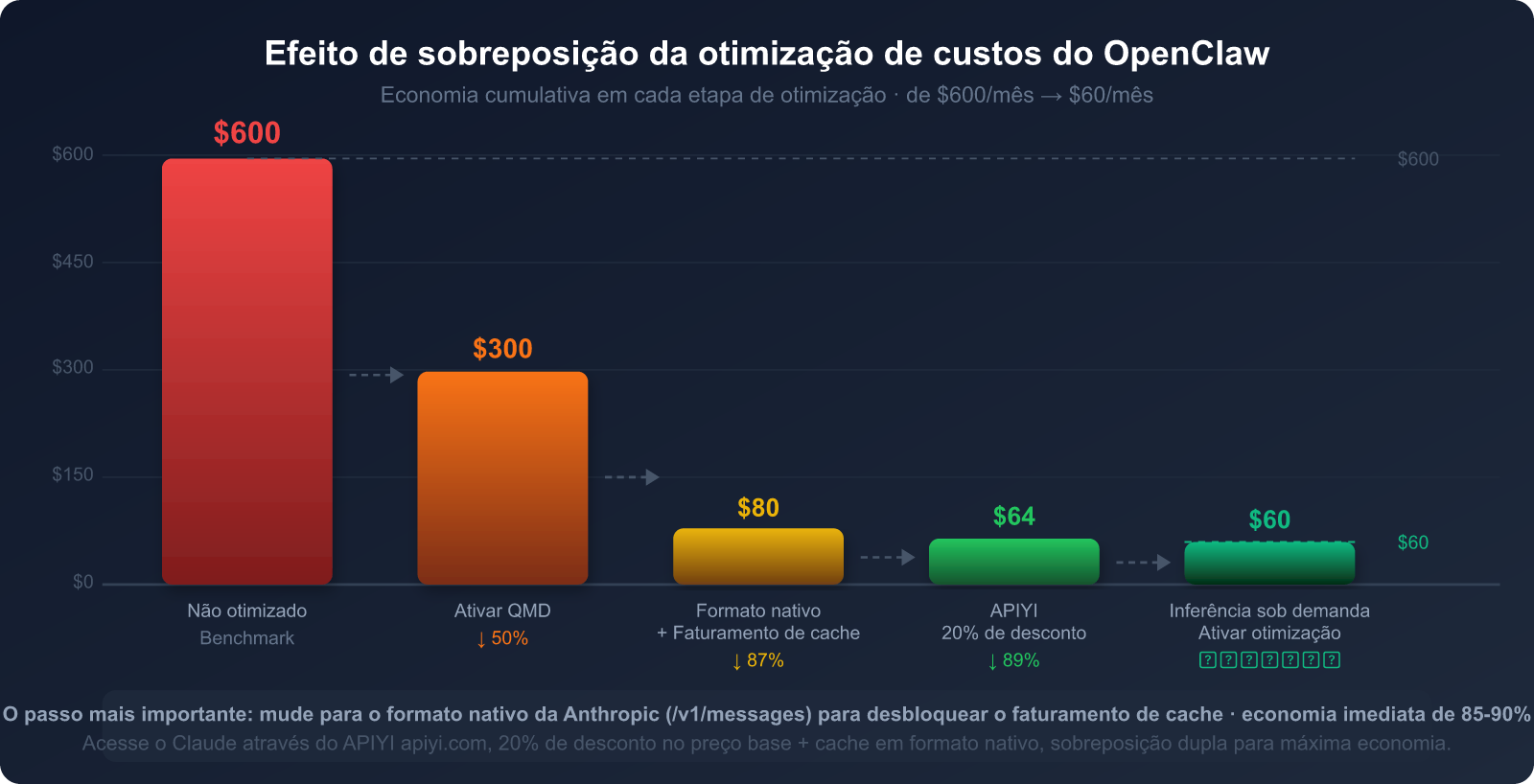
Relembrando os pontos principais deste artigo:
As três principais causas de alto consumo:
- Reenvio do histórico de conversa a cada interação (representa 40-50% do consumo)
- Reenvio do System Prompt a cada vez (representa 25-30%)
- Uso desenfreado do modo de raciocínio (representa 20-25%)
As estratégias de economia mais eficazes:
- 🥇 Faturamento por cache do Claude: economize até 90% (obrigatório usar o formato nativo da Anthropic)
- 🥈 Busca semântica local QMD: economize de 60% a 97% de tokens de contexto histórico
- 🥉 Classificação de modelos por tarefa: use Haiku para tarefas leves e Sonnet/Opus para tarefas pesadas
- Canal de API: escolha a APIYI: preço base com 20% de desconto + suporte ao formato nativo
Um insight fundamental:
O formato compatível com OpenAI (
/v1/chat/completions) não consegue transmitir ocache_control.
Mesmo chamando o Claude via proxy, você não aproveitará o desconto de cache.
Para economizar, você DEVE usar o formato nativo da Anthropic (/v1/messages).
🎯 Ação imediata: Acesse apiyi.com para se cadastrar e obter uma chave API que suporte o formato nativo da Anthropic.
Mude abase_urlparahttps://api.apiyi.com/v1. A migração leva menos de 3 minutos e você verá uma queda significativa na fatura de tokens no mesmo dia. Com modelos Claude 20% mais baratos e uma interface unificada para múltiplos modelos, a APIYI é a melhor escolha para usuários do OpenClaw reduzirem custos e aumentarem a eficiência.
Todos os dados de preços de API neste artigo são baseados em informações públicas de março de 2026; os preços reais estão sujeitos aos anúncios oficiais de cada plataforma.
Autor: Equipe APIYI | Para mais dicas de uso do OpenClaw, visite a Central de Ajuda da APIYI em apiyi.com