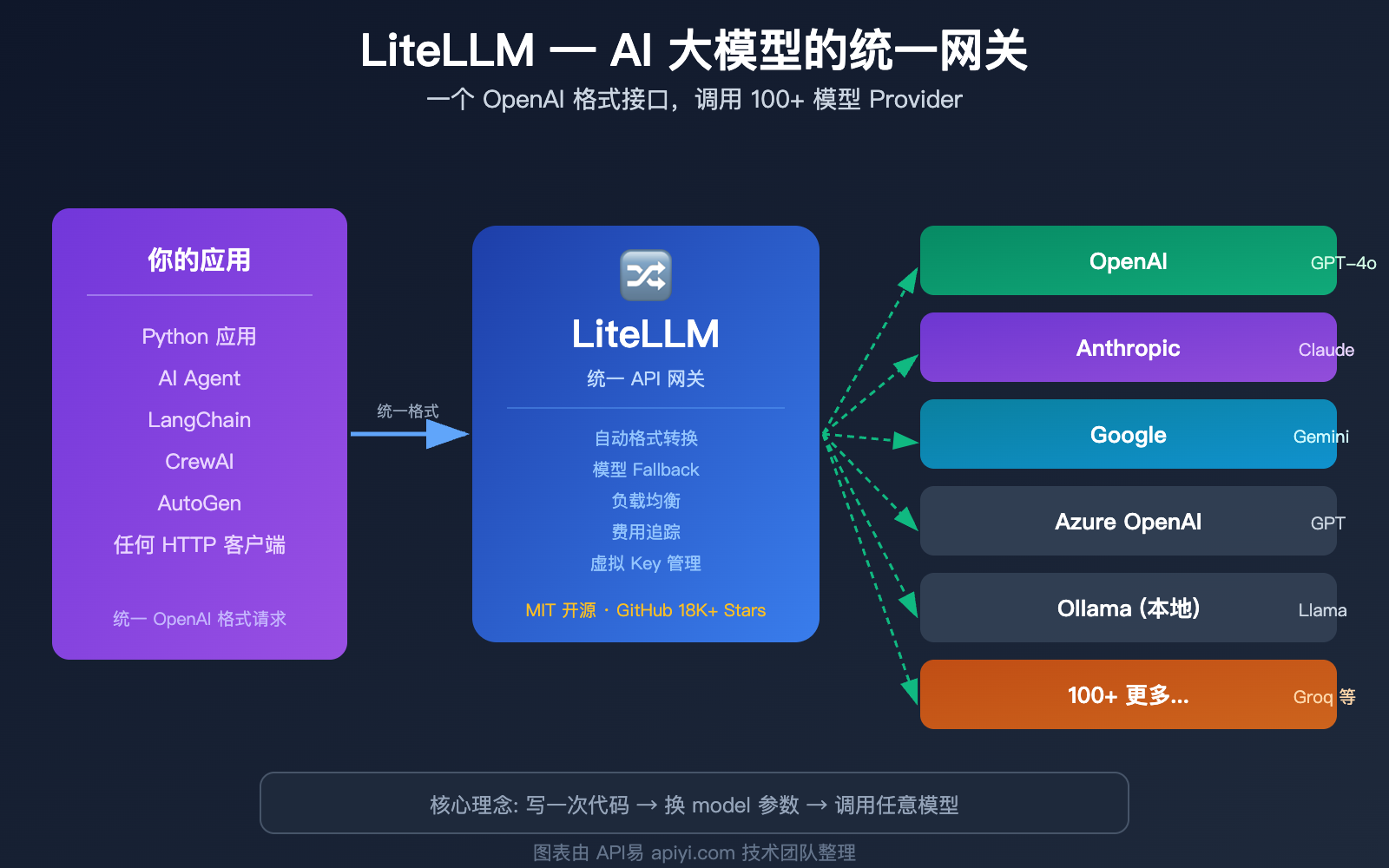
你有没有遇到过这样的烦恼:项目里同时用了 OpenAI 的 GPT、Anthropic 的 Claude、Google 的 Gemini,每个模型的 SDK 不一样,API 格式不一样,连错误处理方式都不一样?改一次模型,代码要改一大片?
这就是 LiteLLM 要解决的问题。简单说,LiteLLM 就是 AI 大模型的「万能翻译器」——你只需要学会一种调用方式(OpenAI 格式),它帮你翻译成 100 多个模型厂商各自的 API 格式。
核心价值: 读完本文,你将理解 LiteLLM 是什么、为什么 AI Agent 框架都在用它、以及如何在 5 分钟内上手使用。
LiteLLM 是什么:5 个核心概念
在开始使用之前,先用最通俗的方式理解 LiteLLM 的 5 个核心概念。这些概念搞清楚了,后续操作就水到渠成。
| 核心概念 | 通俗解释 | 解决的问题 |
|---|---|---|
| 统一接口 | 所有模型用同一种方式调用 | 不用为每个模型学一套 SDK |
| Provider(提供商) | OpenAI、Anthropic 等模型厂商 | 管理不同厂商的连接方式 |
| Fallback(故障转移) | 模型 A 挂了自动切到模型 B | 保证服务不中断 |
| Virtual Key(虚拟密钥) | 给团队成员发"子账号" | 控制用量和预算 |
| Proxy(代理网关) | 独立运行的中转服务器 | 任何语言、任何工具都能接入 |
LiteLLM 解决了什么痛点?
想象一下没有 LiteLLM 的世界:
调用 OpenAI:
from openai import OpenAI
client = OpenAI(api_key="sk-xxx")
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": "你好"}]
)
调用 Anthropic:
import anthropic
client = anthropic.Anthropic(api_key="sk-ant-xxx")
response = client.messages.create(
model="claude-sonnet-4-20250514",
max_tokens=1024, # Anthropic 必须指定
messages=[{"role": "user", "content": "你好"}]
)
调用 Google Gemini:
import google.generativeai as genai
genai.configure(api_key="AIza-xxx")
model = genai.GenerativeModel("gemini-2.0-flash")
response = model.generate_content("你好")
看到了吗?三个模型,三套 SDK,三种写法。如果你的项目要支持模型切换,代码里就到处是 if provider == "openai"... elif provider == "anthropic"... 的条件判断。
有了 LiteLLM 之后:
import litellm
# 调用 OpenAI
response = litellm.completion(model="gpt-4o", messages=[{"role": "user", "content": "你好"}])
# 调用 Anthropic —— 同样的写法
response = litellm.completion(model="anthropic/claude-sonnet-4-6", messages=[{"role": "user", "content": "你好"}])
# 调用 Gemini —— 还是同样的写法
response = litellm.completion(model="gemini/gemini-2.0-flash", messages=[{"role": "user", "content": "你好"}])
一个 litellm.completion(),换个 model 参数就行了。LiteLLM 在背后自动完成格式转换、参数适配、响应标准化。
🎯 技术建议: LiteLLM 的统一接口理念和 API易 apiyi.com 类似——都是一个接口调用多种模型。区别在于 LiteLLM 是开源自部署方案,API易 是无需部署的托管服务。可以根据团队技术能力选择适合的方案。
LiteLLM 两种使用模式详解
LiteLLM 提供两种使用模式,适合不同场景。理解这两种模式的区别,是选择正确使用方式的关键。
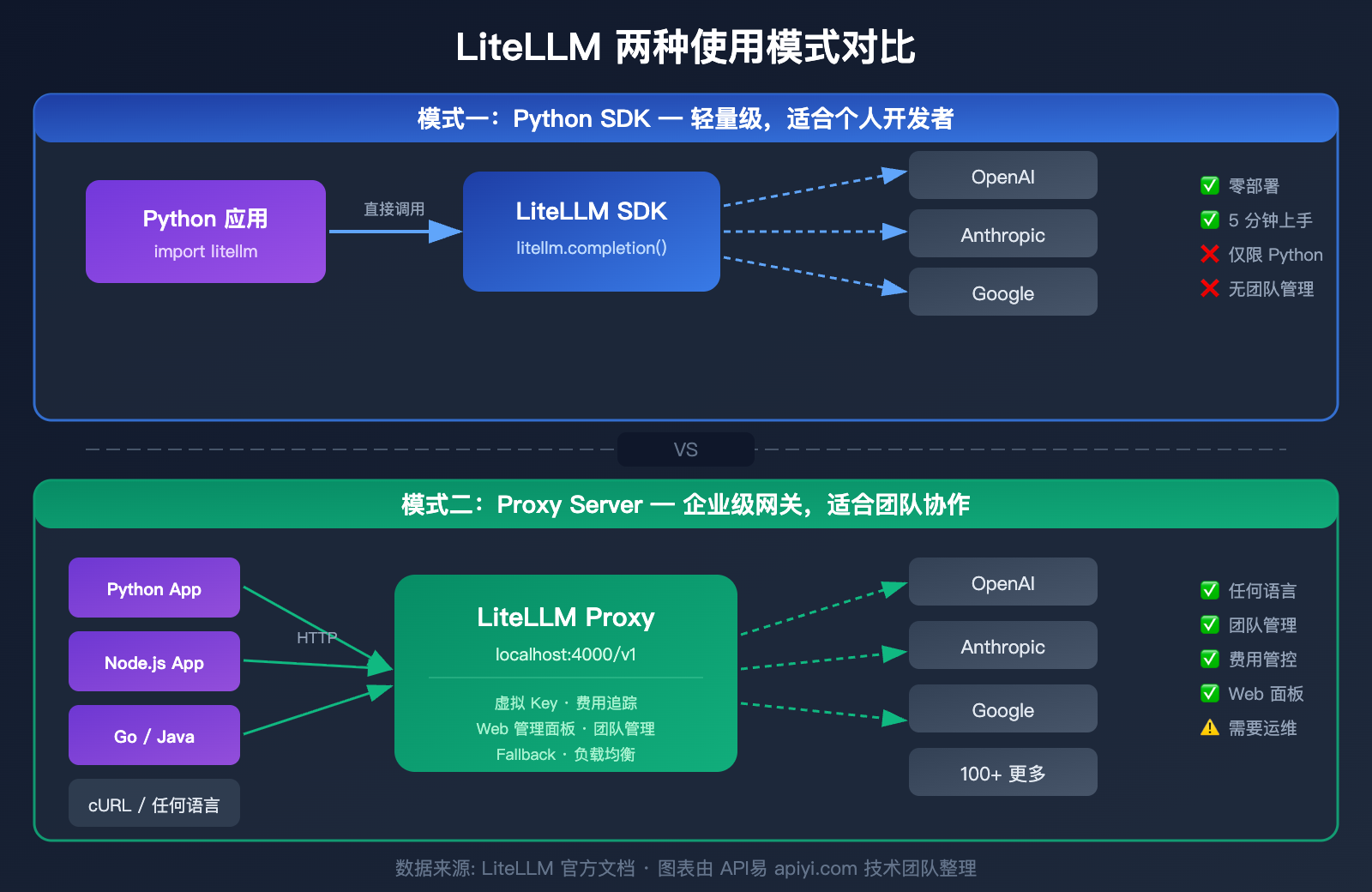
模式一:Python SDK(轻量级)
直接在 Python 代码中导入 litellm 包,像调用函数一样使用。
适用场景:
- 个人开发者
- 纯 Python 项目
- 快速原型验证
- 不需要团队管理功能
安装:
pip install litellm
基本用法:
import litellm
import os
# 设置 API Key(通过环境变量)
os.environ["OPENAI_API_KEY"] = "sk-你的密钥"
os.environ["ANTHROPIC_API_KEY"] = "sk-ant-你的密钥"
# 调用任意模型
response = litellm.completion(
model="gpt-4o",
messages=[{"role": "user", "content": "解释什么是 API 网关"}]
)
print(response.choices[0].message.content)
模式二:Proxy Server(企业级网关)
作为独立服务器运行,对外暴露 OpenAI 兼容的 HTTP 接口。任何编程语言、任何工具,只要能发 HTTP 请求就能用。
适用场景:
- 团队协作
- 多语言项目(Java、Go、Node.js 等)
- 需要费用追踪和预算管理
- 需要为不同团队分配虚拟 Key
- 接入 AI Agent 框架
安装和启动:
# 安装
pip install 'litellm[proxy]'
# 使用配置文件启动
litellm --config config.yaml --port 4000
# 或用 Docker
docker run -p 4000:4000 \
-e OPENAI_API_KEY=sk-xxx \
ghcr.io/berriai/litellm:main-latest
启动后,任何应用都可以像调用 OpenAI 一样调用它:
from openai import OpenAI
# 把 base_url 指向 LiteLLM Proxy
client = OpenAI(
api_key="sk-你的虚拟Key",
base_url="http://localhost:4000/v1"
)
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": "你好"}]
)
LiteLLM SDK 与 Proxy 模式对比
| 对比维度 | Python SDK | Proxy Server |
|---|---|---|
| 安装方式 | pip install litellm |
pip install 'litellm[proxy]' 或 Docker |
| 调用方式 | Python 函数调用 | HTTP API(任何语言) |
| 配置方式 | 代码中设置 | config.yaml 配置文件 |
| 虚拟 Key 管理 | 不支持 | 支持,可设预算上限 |
| Web 管理面板 | 无 | 有,可视化管理 |
| 团队管理 | 不支持 | 支持用户/团队/预算 |
| 费用追踪 | 基础(代码级) | 完整(数据库持久化) |
| 部署复杂度 | 零部署 | 需要服务器运维 |
| 适合人群 | 个人开发者 | 团队/企业 |
💡 选择建议: 如果你是个人开发者做原型验证,SDK 模式 5 分钟就能跑起来。如果是团队使用或生产环境,Proxy 模式更合适。当然,如果不想自己部署和维护服务器,也可以直接使用 API易 apiyi.com 这类托管式统一接口服务,开箱即用。
LiteLLM 快速上手教程
以下是从零开始使用 LiteLLM 的完整步骤。
LiteLLM SDK 模式快速上手
第 1 步:安装
pip install litellm
第 2 步:设置环境变量
# macOS / Linux
export OPENAI_API_KEY="sk-你的密钥"
export ANTHROPIC_API_KEY="sk-ant-你的密钥"
# Windows
set OPENAI_API_KEY=sk-你的密钥
第 3 步:编写代码
import litellm
# 基础调用
response = litellm.completion(
model="gpt-4o",
messages=[
{"role": "system", "content": "你是一个技术助手"},
{"role": "user", "content": "什么是 LLM 网关?"}
],
temperature=0.7
)
print(response.choices[0].message.content)
print(f"Token 用量: {response.usage.total_tokens}")
print(f"预估费用: ${response._hidden_params.get('response_cost', 'N/A')}")
查看完整代码:带 Fallback 和流式输出
import litellm
import os
os.environ["OPENAI_API_KEY"] = "sk-你的密钥"
os.environ["ANTHROPIC_API_KEY"] = "sk-ant-你的密钥"
# 带 Fallback 的调用:GPT-4o 失败自动切到 Claude
response = litellm.completion(
model="gpt-4o",
messages=[{"role": "user", "content": "解释 RESTful API"}],
fallbacks=["anthropic/claude-sonnet-4-6"],
num_retries=2
)
# 流式输出
stream = litellm.completion(
model="gpt-4o",
messages=[{"role": "user", "content": "写一首关于编程的诗"}],
stream=True
)
for chunk in stream:
content = chunk.choices[0].delta.content
if content:
print(content, end="", flush=True)
LiteLLM Proxy 模式快速上手
第 1 步:创建配置文件 config.yaml
model_list:
- model_name: gpt-4o
litellm_params:
model: openai/gpt-4o
api_key: os.environ/OPENAI_API_KEY
- model_name: claude-sonnet
litellm_params:
model: anthropic/claude-sonnet-4-6
api_key: os.environ/ANTHROPIC_API_KEY
- model_name: gemini-flash
litellm_params:
model: gemini/gemini-2.0-flash
api_key: os.environ/GEMINI_API_KEY
litellm_settings:
drop_params: true
num_retries: 3
general_settings:
master_key: sk-my-master-key
第 2 步:启动 Proxy
litellm --config config.yaml --port 4000
第 3 步:使用标准 OpenAI SDK 调用
from openai import OpenAI
client = OpenAI(
api_key="sk-my-master-key",
base_url="http://localhost:4000/v1"
)
# 调用 GPT-4o(通过 LiteLLM Proxy)
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": "你好"}]
)
print(response.choices[0].message.content)
也可以用 cURL 直接调用:
curl http://localhost:4000/v1/chat/completions \
-H "Authorization: Bearer sk-my-master-key" \
-H "Content-Type: application/json" \
-d '{
"model": "claude-sonnet",
"messages": [{"role": "user", "content": "Hello"}]
}'
🚀 快速开始: LiteLLM Proxy 需要自己管理服务器和 API Key。如果你希望免部署直接使用统一接口,可以试试 API易 apiyi.com,同样支持 OpenAI 兼容格式调用 100+ 模型,无需搭建任何基础设施。
LiteLLM 在 AI Agent 中的核心作用
这是很多新人好奇的问题:为什么几乎所有主流 AI Agent 框架都支持甚至推荐使用 LiteLLM?
为什么 AI Agent 需要 LiteLLM?
AI Agent(智能代理)在执行任务时,经常需要:
- 调用不同模型:简单任务用便宜的小模型,复杂推理用大模型
- 自动降级:主力模型限速或宕机时,自动切换到备用模型
- 控制成本:多个 Agent 并行运行,需要统一追踪和限制 Token 开销
- 团队协作:不同开发者的 Agent 共享 API 资源池
LiteLLM 完美解决了这些需求。它充当 Agent 和模型之间的「调度中心」。
LiteLLM 与主流 AI Agent 框架的集成
| Agent 框架 | 集成方式 | 典型用法 |
|---|---|---|
| LangChain / LangGraph | SDK 内置支持 | ChatLiteLLM 作为 LLM 后端 |
| CrewAI | Proxy 连接 | 多 Agent 共享模型资源池 |
| AutoGen(微软) | Proxy 连接 | 通过 OpenAI 兼容端点接入 |
| Dify | 自定义 Provider | 配置为 OpenAI 兼容端点 |
| Open WebUI | Proxy 连接 | 后端 API 端点 |
| Aider | Proxy 连接 | 代码生成 Agent 的模型层 |
| Continue.dev | Proxy 连接 | IDE 中的 AI 编码助手后端 |
LiteLLM 在多 Agent 系统中的典型架构
在一个多 Agent 系统中,LiteLLM Proxy 通常这样工作:
- 规划 Agent → 调用 Claude Opus(强推理模型)
- 执行 Agent → 调用 GPT-4o(均衡性能)
- 校验 Agent → 调用 GPT-4o-mini(快速低成本)
- 总结 Agent → 调用 Gemini Flash(大上下文窗口)
所有 Agent 都通过同一个 LiteLLM Proxy 端点调用,Proxy 自动路由到正确的后端模型。管理员通过 Dashboard 统一查看所有 Agent 的 Token 用量和费用。
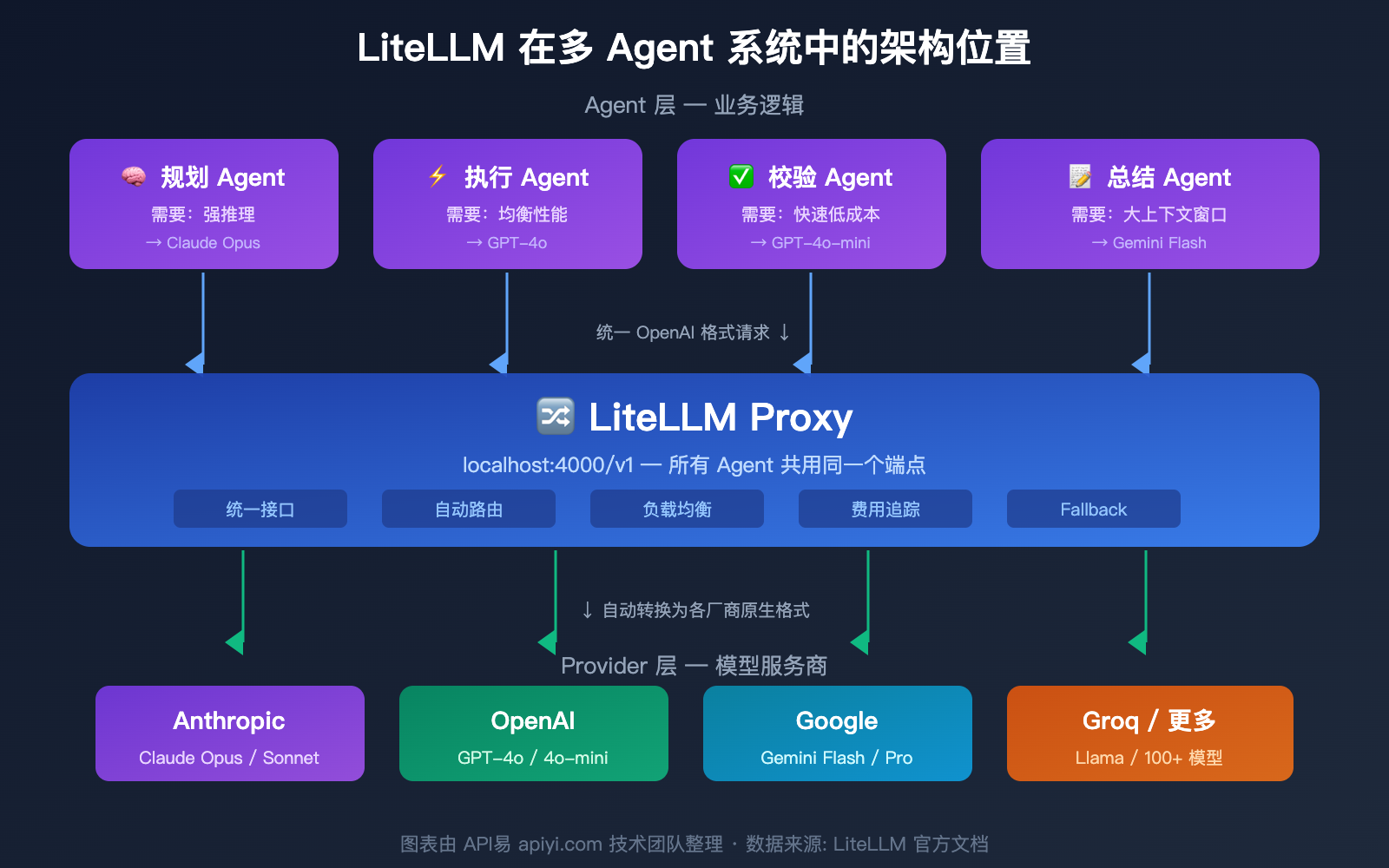
🎯 技术建议: 在生产环境的多 Agent 系统中,LiteLLM Proxy 需要搭配 PostgreSQL 和 Redis 才能完整使用费用追踪和缓存功能。如果你的团队规模较小或不想运维额外基础设施,API易 apiyi.com 提供类似的统一接口能力,且内置了费用追踪和用量统计,无需额外部署数据库。
LiteLLM 进阶功能详解
掌握了基础用法之后,以下 3 个进阶功能是生产环境中最常用的。
进阶功能一:模型 Fallback(故障转移)
当主力模型出现限速、超时或报错时,LiteLLM 自动切换到备用模型,保证服务不中断。
SDK 中配置 Fallback:
response = litellm.completion(
model="gpt-4o",
messages=messages,
fallbacks=["anthropic/claude-sonnet-4-6", "gemini/gemini-2.0-flash"],
num_retries=2
)
执行逻辑:先试 GPT-4o → 失败则试 Claude Sonnet → 再失败试 Gemini Flash。
Proxy 中配置 Fallback(config.yaml):
litellm_settings:
fallbacks:
- gpt-4o: [claude-sonnet, gemini-flash]
- claude-sonnet: [gpt-4o, gemini-flash]
进阶功能二:负载均衡
同一个模型名称配置多个后端部署,LiteLLM 自动分配请求。
model_list:
# 同一个模型名,两个不同的后端
- model_name: gpt-4o
litellm_params:
model: openai/gpt-4o
api_key: os.environ/OPENAI_KEY_1
- model_name: gpt-4o
litellm_params:
model: azure/gpt-4o-deployment
api_key: os.environ/AZURE_KEY_1
api_base: https://my-azure.openai.azure.com
router_settings:
routing_strategy: least-busy # 最少繁忙优先
# 其他策略: simple-shuffle, latency-based
调用时只需指定 model="gpt-4o",LiteLLM 自动在 OpenAI 直连和 Azure 部署之间分流。
进阶功能三:费用追踪和虚拟 Key
生成虚拟 Key(Proxy 模式):
curl http://localhost:4000/key/generate \
-H "Authorization: Bearer sk-master-key" \
-H "Content-Type: application/json" \
-d '{
"max_budget": 50.0,
"budget_duration": "monthly",
"models": ["gpt-4o", "claude-sonnet"],
"metadata": {"user": "developer-01"}
}'
这会生成一个虚拟 Key,该 Key 每月最多花费 $50,只能调用 GPT-4o 和 Claude Sonnet。
费用追踪:
LiteLLM 内置了各模型的价格表,每次 API 调用自动计算费用。在 Proxy 管理面板中可以查看:
- 按模型统计的总花费
- 按用户/团队的花费明细
- 按时间段的费用趋势
- Token 用量统计
💰 成本优化: LiteLLM 的费用追踪功能可以帮你发现哪些模型调用最费钱。配合 API易 apiyi.com 的定价优势,同样的模型调用可能获得更优惠的价格,进一步降低 AI 应用的运营成本。
LiteLLM 支持的 100+ 模型 Provider 一览
LiteLLM 支持的 Provider 数量非常庞大。以下是最常用的几类:
| 类别 | Provider | 模型前缀 | 代表模型 |
|---|---|---|---|
| 商业大模型 | OpenAI | openai/ |
GPT-4o, GPT-4o-mini, o3 |
| Anthropic | anthropic/ |
Claude Opus 4, Sonnet 4, Haiku | |
gemini/ |
Gemini 2.0 Flash, Gemini 2.5 Pro | ||
| 云平台 | Azure OpenAI | azure/ |
Azure 部署的 GPT 系列 |
| AWS Bedrock | bedrock/ |
Bedrock 托管的 Claude/Llama | |
| Google Vertex AI | vertex_ai/ |
Vertex 托管的 Gemini | |
| 推理加速 | Groq | groq/ |
Llama 3.1 70B (超快推理) |
| Together AI | together_ai/ |
各类开源模型 | |
| Fireworks AI | fireworks_ai/ |
高性能推理 | |
| 本地部署 | Ollama | ollama/ |
本地运行的 Llama/Mistral |
| vLLM | openai/ (自定义 base) |
自托管推理引擎 | |
| 国产模型 | Deepseek | deepseek/ |
Deepseek Chat/Coder |
| 搜索增强 | Perplexity | perplexity/ |
Sonar Pro |
| 聚合平台 | OpenRouter | openrouter/ |
各类模型 |
🎯 选择建议: 模型选择取决于具体场景。如果你不确定该用哪个模型,可以通过 API易 apiyi.com 平台快速测试不同模型的效果,该平台同样支持上述大部分模型的 OpenAI 兼容接口调用。

LiteLLM 常见问题 FAQ
Q1: LiteLLM 和直接用 OpenAI SDK 有什么区别?
OpenAI SDK 只能调用 OpenAI 的模型。LiteLLM 在 OpenAI SDK 的基础上做了扩展,让你用同样的代码格式调用 Anthropic、Google、Azure 等 100+ 个模型 Provider。如果你的项目只用 OpenAI 模型,直接用 OpenAI SDK 即可。但如果需要多模型支持、故障转移或费用管控,LiteLLM 是更好的选择。
Q2: LiteLLM 免费吗?
LiteLLM 的核心功能完全开源免费(MIT 许可证)。但需要注意:LiteLLM 本身免费,但它调用的模型 API 是需要付费的。你需要自己从 OpenAI、Anthropic 等官方获取 API Key 并支付模型调用费用。如果不想分别管理多个 API Key,也可以使用 API易 apiyi.com 等统一接口平台来简化密钥管理。
Q3: LiteLLM Proxy 需要什么服务器配置?
LiteLLM Proxy 本身很轻量,1 核 1G 内存的服务器就能跑。但如果需要完整功能(费用追踪、虚拟 Key 管理),还需要 PostgreSQL 数据库和 Redis。生产环境建议至少 2 核 4G + PostgreSQL + Redis。
Q4: LiteLLM 和 OpenRouter 有什么区别?
最大的区别:LiteLLM 是开源自部署方案,OpenRouter 是托管服务。
- LiteLLM:免费,自己部署,自己管理 API Key,完全控制数据流向
- OpenRouter:即开即用,但在 API 调用价格上有加价,数据经过第三方
如果你重视数据隐私或有自己的 API Key,选 LiteLLM。如果想零部署快速使用,可以考虑 API易 apiyi.com 等托管方案。
Q5: LiteLLM 支持流式输出(Streaming)吗?
支持。无论是 SDK 还是 Proxy 模式,LiteLLM 都完整支持 SSE 流式输出。所有 Provider 的流式响应都会被统一转换为 OpenAI 格式的 chunk,确保一致的流式体验。
stream = litellm.completion(
model="gpt-4o",
messages=[{"role": "user", "content": "写一个故事"}],
stream=True
)
for chunk in stream:
print(chunk.choices[0].delta.content or "", end="")
Q6: 新手应该选 SDK 模式还是 Proxy 模式?
如果你是 Python 开发者,刚开始学习,从 SDK 模式入手最简单——pip install litellm 然后写几行代码就能跑。等到需要团队协作、多语言接入或生产部署时,再迁移到 Proxy 模式。两种模式的核心调用方式是一致的,迁移成本很低。
Q7: LiteLLM 的 config.yaml 配置文件放在哪里?
没有固定位置。启动 Proxy 时通过 --config 参数指定路径即可:
litellm --config /path/to/your/config.yaml
一般建议放在项目根目录或专门的配置目录。如果用 Docker 部署,通过 volume 挂载进容器。
LiteLLM 快速决策指南
根据你的实际情况,选择最合适的方案:
| 你的情况 | 推荐方案 | 理由 |
|---|---|---|
| 个人开发者,Python 项目 | LiteLLM SDK | 零部署,5 分钟上手 |
| 团队开发,需要预算管控 | LiteLLM Proxy | 虚拟 Key + 费用追踪 |
| 不想自建基础设施 | API易 apiyi.com | 托管服务,开箱即用 |
| 多 Agent 系统 | LiteLLM Proxy | 统一路由 + 负载均衡 |
| 只用 OpenAI 模型 | 直接用 OpenAI SDK | 无需额外层 |
| 注重数据隐私 | LiteLLM 自部署 | 数据不经过第三方 |
总结
LiteLLM 是 AI 应用开发中一个非常实用的基础设施工具。它的核心价值就一句话:用一套 OpenAI 格式的代码,调用 100+ 家模型厂商的 API。
对于新人来说,记住这几个要点:
- LiteLLM 是「翻译器」:帮你把统一格式的请求翻译成各家模型的 API 格式
- 两种模式:SDK(轻量 Python 包)和 Proxy(独立网关服务器)
- 核心价值:统一接口 + Fallback + 负载均衡 + 费用追踪
- Agent 框架标配:LangChain、CrewAI、AutoGen 等几乎都支持 LiteLLM
- 完全开源免费:MIT 许可证,自部署无任何费用
如果你觉得自部署 LiteLLM Proxy 的运维成本较高,也可以直接使用 API易 apiyi.com 这类托管式统一接口服务,同样实现一个 Key 调用所有主流模型的效果,省去部署和运维的负担。
本文作者: APIYI 技术团队
技术交流: 访问 API易 apiyi.com 获取更多 AI 模型调用教程和技术支持
更新日期: 2026 年 4 月
适用版本: LiteLLM v1.x+
参考资料:
- LiteLLM 官方文档: docs.litellm.ai
- LiteLLM GitHub 仓库: github.com/BerriAI/litellm
- LiteLLM 官网: litellm.ai
- BerriAI 官网: berri.ai