هل سبق لك أن واجهت هذا الإزعاج: مشروعك يستخدم GPT من OpenAI، وClaude من Anthropic، وGemini من Google في آنٍ واحد، وكل نموذج له حزمة تطوير (SDK) مختلفة، وتنسيق API مختلف، وحتى طريقة معالجة الأخطاء تختلف؟ هل تضطر لتعديل جزء كبير من الكود في كل مرة تغير فيها النموذج؟
هذه هي المشكلة التي يحلها LiteLLM. ببساطة، LiteLLM هو "المترجم الشامل" لنماذج اللغة الكبيرة؛ حيث تحتاج فقط إلى تعلم طريقة استدعاء واحدة (تنسيق OpenAI)، وسيقوم هو بترجمتها إلى تنسيقات API الخاصة بأكثر من 100 مزود للنماذج.
القيمة الجوهرية: بعد قراءة هذا المقال، ستفهم ماهية LiteLLM، ولماذا تستخدمه أطر عمل وكلاء الذكاء الاصطناعي (AI Agent)، وكيف تبدأ استخدامه في 5 دقائق.

ما هو LiteLLM: 5 مفاهيم أساسية
قبل البدء في الاستخدام، دعنا نفهم المفاهيم الخمسة الأساسية لـ LiteLLM بأبسط طريقة ممكنة. بمجرد استيعاب هذه المفاهيم، ستصبح الخطوات التالية بديهية وسهلة.
| المفهوم الأساسي | الشرح المبسط | المشكلة التي يحلها |
|---|---|---|
| واجهة موحدة | استدعاء جميع النماذج بنفس الطريقة | لا حاجة لتعلم SDK خاص لكل نموذج |
| المزود (Provider) | شركات النماذج مثل OpenAI وAnthropic | إدارة طرق الاتصال بمختلف الشركات |
| تجاوز الفشل (Fallback) | التحويل التلقائي للنموذج "ب" إذا تعطل "أ" | ضمان عدم انقطاع الخدمة |
| المفتاح الافتراضي (Virtual Key) | إصدار "حسابات فرعية" لأعضاء الفريق | التحكم في الاستهلاك والميزانية |
| بوابة الوكيل (Proxy) | خادم وسيط يعمل بشكل مستقل | إمكانية الربط بأي لغة برمجة أو أداة |
ما هي المشكلات التي يحلها LiteLLM؟
تخيل العالم بدون LiteLLM:
استدعاء OpenAI:
from openai import OpenAI
client = OpenAI(api_key="sk-xxx")
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": "你好"}]
)
استدعاء Anthropic:
import anthropic
client = anthropic.Anthropic(api_key="sk-ant-xxx")
response = client.messages.create(
model="claude-sonnet-4-20250514",
max_tokens=1024, # Anthropic يتطلب تحديد هذا
messages=[{"role": "user", "content": "你好"}]
)
استدعاء Google Gemini:
import google.generativeai as genai
genai.configure(api_key="AIza-xxx")
model = genai.GenerativeModel("gemini-2.0-flash")
response = model.generate_content("你好")
هل لاحظت؟ ثلاثة نماذج، ثلاث مجموعات SDK، وثلاث طرق كتابة مختلفة. إذا كان مشروعك يحتاج إلى دعم التبديل بين النماذج، فستمتلئ شيفرتك البرمجية بشروط if provider == "openai"... elif provider == "anthropic"....
مع وجود LiteLLM:
import litellm
# استدعاء OpenAI
response = litellm.completion(model="gpt-4o", messages=[{"role": "user", "content": "你好"}])
# استدعاء Anthropic — بنفس طريقة الكتابة
response = litellm.completion(model="anthropic/claude-sonnet-4-6", messages=[{"role": "user", "content": "你好"}])
# استدعاء Gemini — بنفس طريقة الكتابة أيضاً
response = litellm.completion(model="gemini/gemini-2.0-flash", messages=[{"role": "user", "content": "你好"}])
أمر واحد litellm.completion()، وكل ما عليك فعله هو تغيير معامل model. يقوم LiteLLM في الخلفية بإتمام تحويل التنسيق، ومواءمة المعاملات، وتوحيد معايير الاستجابة.
🎯 نصيحة تقنية: فلسفة الواجهة الموحدة في LiteLLM تشبه خدمة APIYI (apiyi.com)؛ فكلاهما يوفر واجهة واحدة لاستدعاء نماذج متعددة. الفرق هو أن LiteLLM حل مفتوح المصدر يتطلب استضافة ذاتية، بينما APIYI هي خدمة مدارة لا تتطلب أي إعدادات. يمكنك اختيار الحل الأنسب بناءً على القدرات التقنية لفريقك.
شرح نمطي استخدام LiteLLM
يوفر LiteLLM نمطين للاستخدام، يناسب كل منهما سيناريوهات مختلفة. فهم الفرق بين هذين النمطين هو المفتاح لاختيار الطريقة الصحيحة.
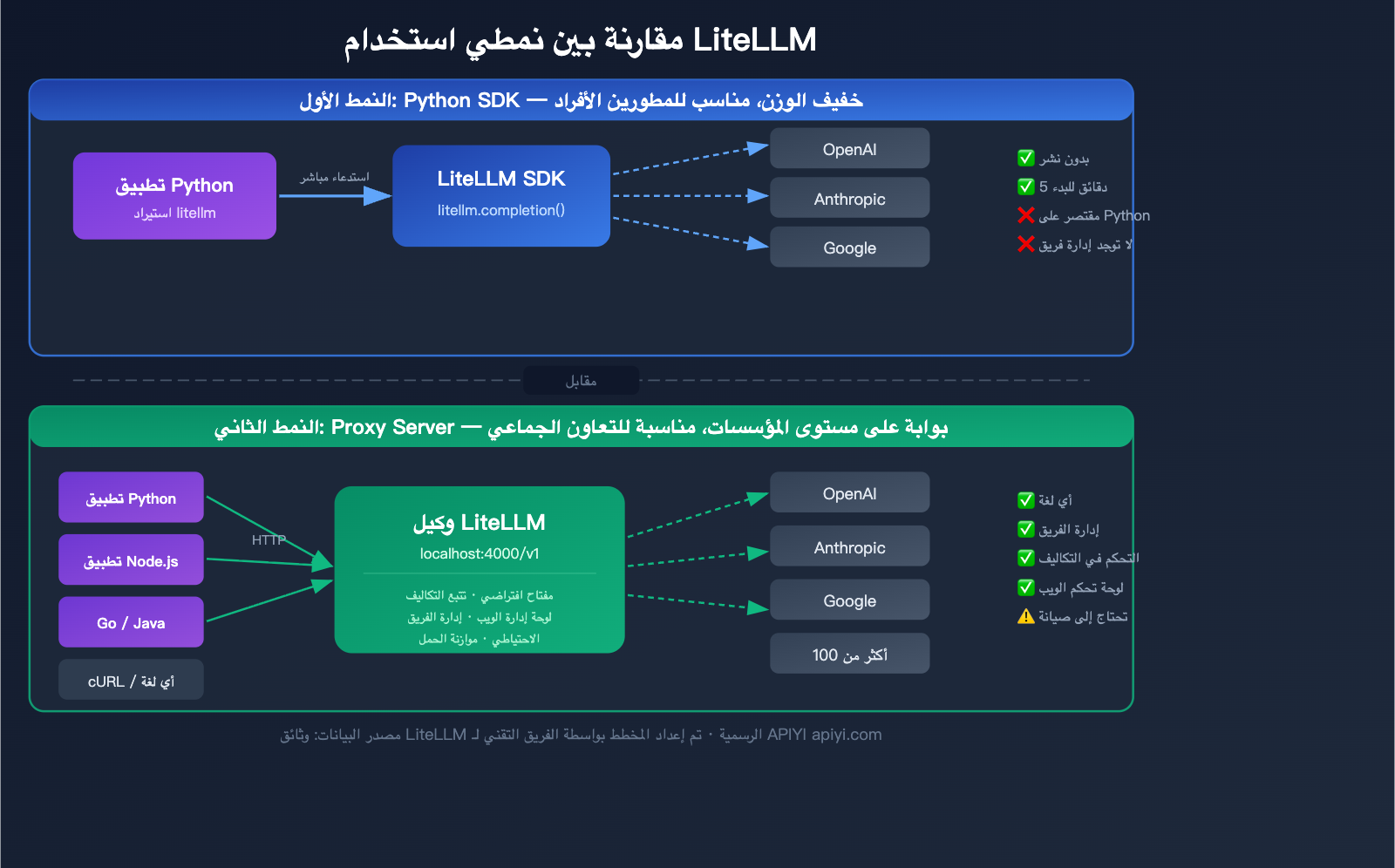
النمط الأول: Python SDK (خفيف الوزن)
قم باستيراد حزمة litellm مباشرة في شيفرة Python الخاصة بك واستخدمها كما تستخدم أي دالة برمجية.
سيناريوهات الاستخدام:
- المطورون الأفراد
- مشاريع Python البحتة
- التحقق السريع من النماذج الأولية
- المشاريع التي لا تتطلب ميزات إدارة الفريق
التثبيت:
pip install litellm
الاستخدام الأساسي:
import litellm
import os
# إعداد مفتاح API (عبر متغيرات البيئة)
os.environ["OPENAI_API_KEY"] = "sk-مفتاحك"
os.environ["ANTHROPIC_API_KEY"] = "sk-ant-مفتاحك"
# استدعاء أي نموذج
response = litellm.completion(
model="gpt-4o",
messages=[{"role": "user", "content": "اشرح ما هي بوابة API"}]
)
print(response.choices[0].message.content)
النمط الثاني: Proxy Server (بوابة على مستوى المؤسسات)
يعمل كخادم مستقل، ويوفر واجهة HTTP متوافقة مع OpenAI. يمكن لأي لغة برمجة أو أداة قادرة على إرسال طلبات HTTP استخدامه.
سيناريوهات الاستخدام:
- العمل الجماعي
- المشاريع متعددة اللغات (Java, Go, Node.js, إلخ)
- الحاجة إلى تتبع التكاليف وإدارة الميزانية
- الحاجة إلى إصدار مفاتيح افتراضية لفرق مختلفة
- الربط مع أطر عمل الوكلاء الذكاء الاصطناعي (AI Agent)
التثبيت والتشغيل:
# التثبيت
pip install 'litellm[proxy]'
# التشغيل باستخدام ملف الإعدادات
litellm --config config.yaml --port 4000
# أو باستخدام Docker
docker run -p 4000:4000 \
-e OPENAI_API_KEY=sk-xxx \
ghcr.io/berriai/litellm:main-latest
بعد التشغيل، يمكن لأي تطبيق استدعاؤه تماماً كما يستدعي OpenAI:
from openai import OpenAI
# توجيه base_url إلى LiteLLM Proxy
client = OpenAI(
api_key="sk-مفتاحك_الافتراضي",
base_url="http://localhost:4000/v1"
)
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": "你好"}]
)
مقارنة بين نمطي SDK و Proxy في LiteLLM
| وجه المقارنة | Python SDK | Proxy Server |
|---|---|---|
| طريقة التثبيت | pip install litellm |
pip install 'litellm[proxy]' أو Docker |
| طريقة الاستدعاء | استدعاء دالة Python | HTTP API (أي لغة) |
| طريقة الإعداد | داخل الشيفرة البرمجية | ملف إعدادات config.yaml |
| إدارة المفاتيح الافتراضية | غير مدعوم | مدعوم، مع إمكانية تحديد سقف للميزانية |
| لوحة تحكم ويب | لا يوجد | يوجد، إدارة مرئية |
| إدارة الفريق | غير مدعوم | مدعوم (مستخدمين/فرق/ميزانيات) |
| تتبع التكاليف | أساسي (على مستوى الشيفرة) | كامل (تخزين دائم في قاعدة بيانات) |
| تعقيد النشر | لا يتطلب نشر | يتطلب صيانة خادم |
| الفئة المستهدفة | المطورون الأفراد | الفرق/المؤسسات |
💡 نصيحة للاختيار: إذا كنت مطوراً فرداً تقوم بالتحقق من نموذج أولي، فإن نمط SDK سيعمل معك في 5 دقائق. أما إذا كان الاستخدام ضمن فريق أو في بيئة إنتاجية، فإن نمط Proxy هو الأنسب. وبالطبع، إذا كنت لا ترغب في نشر وصيانة الخادم بنفسك، يمكنك استخدام خدمات الواجهة الموحدة المدارة مثل APIYI (apiyi.com) التي توفر حلولاً جاهزة للاستخدام الفوري.
دليل البدء السريع لـ LiteLLM
إليك الخطوات الكاملة للبدء في استخدام LiteLLM من الصفر.
البدء السريع بنمط SDK لـ LiteLLM
الخطوة 1: التثبيت
pip install litellm
الخطوة 2: إعداد متغيرات البيئة
# macOS / Linux
export OPENAI_API_KEY="sk-مفتاحك"
export ANTHROPIC_API_KEY="sk-ant-مفتاحك"
# Windows
set OPENAI_API_KEY=sk-مفتاحك
الخطوة 3: كتابة الكود
import litellm
# استدعاء أساسي
response = litellm.completion(
model="gpt-4o",
messages=[
{"role": "system", "content": "أنت مساعد تقني"},
{"role": "user", "content": "ما هي بوابة LLM؟"}
],
temperature=0.7
)
print(response.choices[0].message.content)
print(f"استهلاك التوكن: {response.usage.total_tokens}")
print(f"التكلفة المقدرة: ${response._hidden_params.get('response_cost', 'N/A')}")
عرض الكود الكامل: مع خاصية Fallback والمخرجات المتدفقة (Streaming)
import litellm
import os
os.environ["OPENAI_API_KEY"] = "sk-مفتاحك"
os.environ["ANTHROPIC_API_KEY"] = "sk-ant-مفتاحك"
# استدعاء مع Fallback: في حال فشل GPT-4o يتم التبديل تلقائياً إلى Claude
response = litellm.completion(
model="gpt-4o",
messages=[{"role": "user", "content": "اشرح RESTful API"}],
fallbacks=["anthropic/claude-sonnet-4-6"],
num_retries=2
)
# المخرجات المتدفقة
stream = litellm.completion(
model="gpt-4o",
messages=[{"role": "user", "content": "اكتب قصيدة عن البرمجة"}],
stream=True
)
for chunk in stream:
content = chunk.choices[0].delta.content
if content:
print(content, end="", flush=True)
البدء السريع بنمط Proxy لـ LiteLLM
الخطوة 1: إنشاء ملف الإعدادات config.yaml
model_list:
- model_name: gpt-4o
litellm_params:
model: openai/gpt-4o
api_key: os.environ/OPENAI_API_KEY
- model_name: claude-sonnet
litellm_params:
model: anthropic/claude-sonnet-4-6
api_key: os.environ/ANTHROPIC_API_KEY
- model_name: gemini-flash
litellm_params:
model: gemini/gemini-2.0-flash
api_key: os.environ/GEMINI_API_KEY
litellm_settings:
drop_params: true
num_retries: 3
general_settings:
master_key: sk-my-master-key
الخطوة 2: تشغيل Proxy
litellm --config config.yaml --port 4000
الخطوة 3: الاستدعاء باستخدام OpenAI SDK القياسي
from openai import OpenAI
client = OpenAI(
api_key="sk-my-master-key",
base_url="http://localhost:4000/v1"
)
# استدعاء GPT-4o (عبر LiteLLM Proxy)
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": "مرحباً"}]
)
print(response.choices[0].message.content)
يمكنك أيضاً الاستدعاء مباشرة باستخدام cURL:
curl http://localhost:4000/v1/chat/completions \
-H "Authorization: Bearer sk-my-master-key" \
-H "Content-Type: application/json" \
-d '{
"model": "claude-sonnet",
"messages": [{"role": "user", "content": "Hello"}]
}'
🚀 بداية سريعة: يتطلب LiteLLM Proxy إدارة الخادم ومفتاح API بنفسك. إذا كنت ترغب في استخدام واجهة موحدة دون الحاجة للنشر، يمكنك تجربة APIYI على apiyi.com، حيث يدعم تنسيق OpenAI المتوافق لأكثر من 100 نموذج دون الحاجة لإعداد أي بنية تحتية.
الدور الجوهري لـ LiteLLM في وكلاء الذكاء الاصطناعي (AI Agents)
هذا سؤال يطرحه الكثير من المبتدئين: لماذا تدعم جميع أطر عمل وكلاء الذكاء الاصطناعي تقريباً LiteLLM أو حتى توصي به؟
لماذا يحتاج وكيل الذكاء الاصطناعي إلى LiteLLM؟
يحتاج وكيل الذكاء الاصطناعي (AI Agent) عند تنفيذ المهام غالباً إلى:
- استدعاء نماذج مختلفة: استخدام نماذج صغيرة رخيصة للمهام البسيطة، ونماذج لغة كبيرة للاستنتاج المعقد.
- الخفض التلقائي (Fallback): التبديل تلقائياً إلى نموذج احتياطي عند تعطل النموذج الرئيسي أو تجاوز حدود السرعة.
- التحكم في التكاليف: عند تشغيل عدة وكلاء بالتوازي، يلزم تتبع وتحديد استهلاك التوكن بشكل موحد.
- التعاون الجماعي: مشاركة مجموعة موارد API بين مطورين مختلفين.
يحل LiteLLM هذه الاحتياجات بشكل مثالي، حيث يعمل كـ "مركز جدولة" بين الوكيل والنموذج.
تكامل LiteLLM مع أطر عمل وكلاء الذكاء الاصطناعي الرئيسية
| إطار عمل الوكيل | طريقة التكامل | الاستخدام النموذجي |
|---|---|---|
| LangChain / LangGraph | دعم مدمج في SDK | ChatLiteLLM كخلفية لـ LLM |
| CrewAI | اتصال Proxy | مشاركة مجموعة موارد النماذج بين عدة وكلاء |
| AutoGen (Microsoft) | اتصال Proxy | الاتصال عبر نقطة نهاية متوافقة مع OpenAI |
| Dify | مزود مخصص (Provider) | الإعداد كنقطة نهاية متوافقة مع OpenAI |
| Open WebUI | اتصال Proxy | نقطة نهاية API للخلفية |
| Aider | اتصال Proxy | طبقة النماذج لوكيل توليد الكود |
| Continue.dev | اتصال Proxy | خلفية مساعد البرمجة بالذكاء الاصطناعي في IDE |
البنية النموذجية لـ LiteLLM في أنظمة الوكلاء المتعددة
في نظام الوكلاء المتعددة، يعمل LiteLLM Proxy عادةً كالتالي:
- وكيل التخطيط → يستدعي Claude Opus (نموذج استنتاج قوي)
- وكيل التنفيذ → يستدعي GPT-4o (أداء متوازن)
- وكيل التحقق → يستدعي GPT-4o-mini (سريع ومنخفض التكلفة)
- وكيل التلخيص → يستدعي Gemini Flash (نافذة سياق كبيرة)
يستدعي جميع الوكلاء نفس نقطة نهاية LiteLLM Proxy، ويقوم Proxy تلقائياً بتوجيه الطلب إلى النموذج الخلفي الصحيح. ويمكن للمسؤولين عرض استهلاك التوكن والتكاليف لجميع الوكلاء عبر لوحة تحكم موحدة.
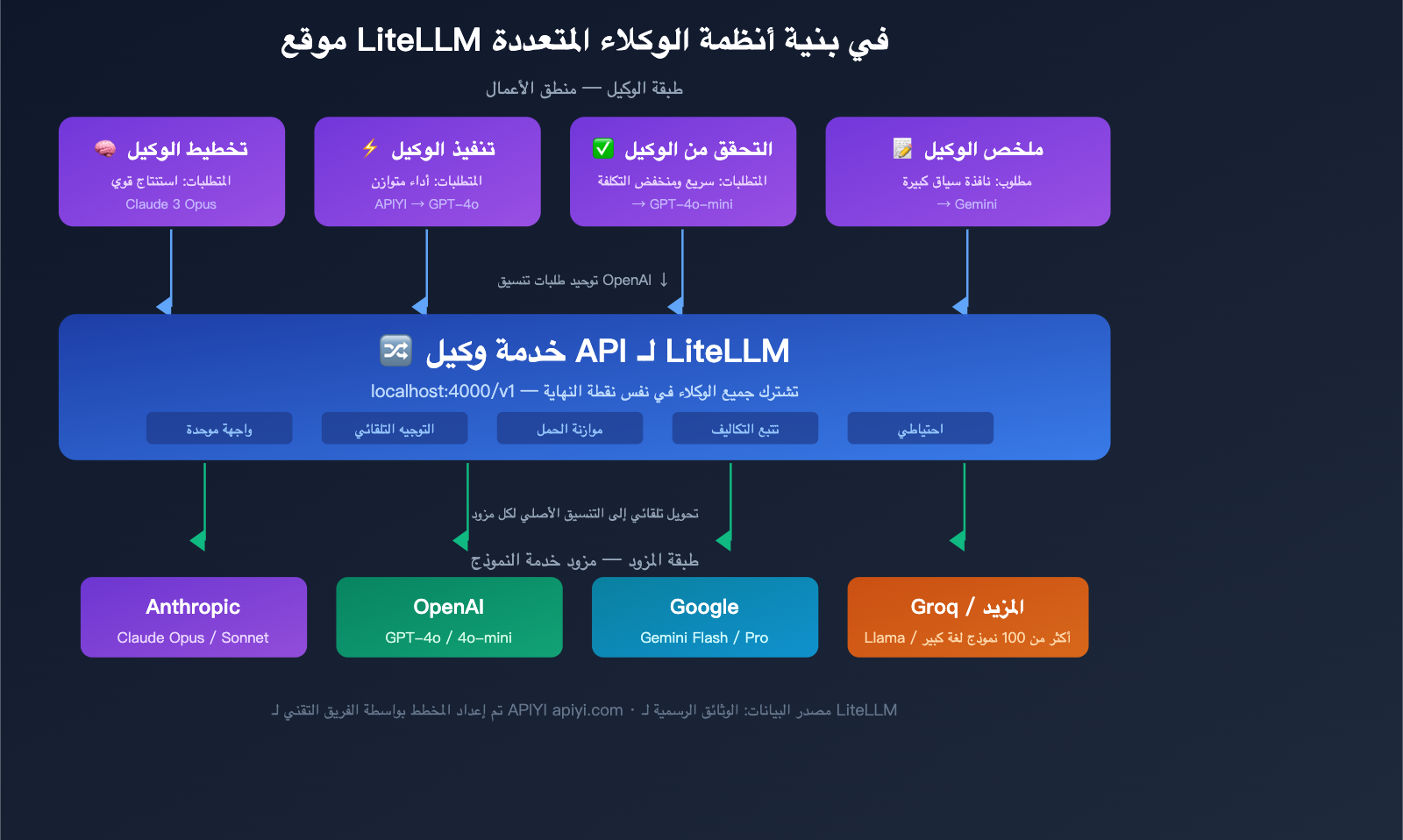
🎯 نصيحة تقنية: في أنظمة الوكلاء المتعددة في بيئة الإنتاج، يحتاج LiteLLM Proxy إلى الاقتران بـ PostgreSQL و Redis للاستفادة الكاملة من ميزات تتبع التكاليف والتخزين المؤقت. إذا كان حجم فريقك صغيراً أو لا ترغب في صيانة بنية تحتية إضافية، فإن APIYI على apiyi.com يوفر قدرات واجهة موحدة مماثلة، مع تتبع مدمج للتكاليف وإحصائيات الاستخدام، دون الحاجة لنشر قواعد بيانات إضافية.
شرح مفصل للميزات المتقدمة في LiteLLM
بعد إتقان الاستخدام الأساسي، إليك 3 ميزات متقدمة هي الأكثر استخداماً في بيئات الإنتاج.
الميزة المتقدمة الأولى: التبديل عند الفشل (Fallback)
عندما يواجه النموذج الرئيسي قيوداً في السرعة، أو انتهاء مهلة، أو أخطاء، يقوم LiteLLM بالتبديل تلقائياً إلى نموذج احتياطي لضمان عدم انقطاع الخدمة.
تكوين التبديل عند الفشل في SDK:
response = litellm.completion(
model="gpt-4o",
messages=messages,
fallbacks=["anthropic/claude-sonnet-4-6", "gemini/gemini-2.0-flash"],
num_retries=2
)
منطق التنفيذ: تجربة GPT-4o أولاً ← في حال الفشل يتم تجربة Claude Sonnet ← وفي حال الفشل مجدداً يتم تجربة Gemini Flash.
تكوين التبديل عند الفشل في Proxy (ملف config.yaml):
litellm_settings:
fallbacks:
- gpt-4o: [claude-sonnet, gemini-flash]
- claude-sonnet: [gpt-4o, gemini-flash]
الميزة المتقدمة الثانية: موازنة الحمل (Load Balancing)
يمكنك تكوين عدة عمليات نشر (Backends) لنفس اسم النموذج، وسيقوم LiteLLM بتوزيع الطلبات تلقائياً.
model_list:
# نفس اسم النموذج، مع خلفيتين مختلفتين
- model_name: gpt-4o
litellm_params:
model: openai/gpt-4o
api_key: os.environ/OPENAI_KEY_1
- model_name: gpt-4o
litellm_params:
model: azure/gpt-4o-deployment
api_key: os.environ/AZURE_KEY_1
api_base: https://my-azure.openai.azure.com
router_settings:
routing_strategy: least-busy # الأولوية للأقل انشغالاً
# استراتيجيات أخرى: simple-shuffle, latency-based
عند الاستدعاء، ما عليك سوى تحديد model="gpt-4o"، وسيقوم LiteLLM تلقائياً بتوزيع الحمل بين الاتصال المباشر بـ OpenAI ونشر Azure.
الميزة المتقدمة الثالثة: تتبع التكاليف والمفاتيح الافتراضية
إنشاء مفتاح افتراضي (وضع Proxy):
curl http://localhost:4000/key/generate \
-H "Authorization: Bearer sk-master-key" \
-H "Content-Type: application/json" \
-d '{
"max_budget": 50.0,
"budget_duration": "monthly",
"models": ["gpt-4o", "claude-sonnet"],
"metadata": {"user": "developer-01"}
}'
سيؤدي هذا إلى إنشاء مفتاح افتراضي بحد أقصى للإنفاق يبلغ 50 دولاراً شهرياً، ولا يمكنه استدعاء سوى GPT-4o و Claude Sonnet.
تتبع التكاليف:
يحتوي LiteLLM على قائمة أسعار مدمجة لكل نموذج، ويقوم بحساب التكلفة تلقائياً مع كل استدعاء API. يمكنك الاطلاع على ذلك في لوحة إدارة Proxy:
- إجمالي التكاليف حسب النموذج
- تفاصيل التكاليف حسب المستخدم/الفريق
- اتجاهات التكاليف بمرور الوقت
- إحصائيات استخدام الرموز (Token)
💰 تحسين التكلفة: يمكن لميزة تتبع التكاليف في LiteLLM مساعدتك في اكتشاف أكثر استدعاءات النماذج تكلفة. وبالاقتران مع ميزات التسعير في APIYI (apiyi.com)، يمكنك الحصول على أسعار أكثر تنافسية لنفس استدعاءات النماذج، مما يقلل من تكاليف تشغيل تطبيقات الذكاء الاصطناعي الخاصة بك.
نظرة عامة على أكثر من 100 مزود نماذج مدعوم في LiteLLM
يدعم LiteLLM عدداً هائلاً من المزودين. إليك أهم الفئات المستخدمة:
| الفئة | المزود | بادئة النموذج | نماذج تمثيلية |
|---|---|---|---|
| نماذج تجارية كبيرة | OpenAI | openai/ |
GPT-4o, GPT-4o-mini, o3 |
| Anthropic | anthropic/ |
Claude Opus 4, Sonnet 4, Haiku | |
gemini/ |
Gemini 2.0 Flash, Gemini 2.5 Pro | ||
| منصات سحابية | Azure OpenAI | azure/ |
سلسلة GPT المنشورة على Azure |
| AWS Bedrock | bedrock/ |
نماذج Claude/Llama المستضافة على Bedrock | |
| Google Vertex AI | vertex_ai/ |
نماذج Gemini المستضافة على Vertex | |
| تسريع الاستنتاج | Groq | groq/ |
Llama 3.1 70B (استنتاج فائق السرعة) |
| Together AI | together_ai/ |
نماذج مفتوحة المصدر متنوعة | |
| Fireworks AI | fireworks_ai/ |
استنتاج عالي الأداء | |
| النشر المحلي | Ollama | ollama/ |
نماذج Llama/Mistral تعمل محلياً |
| vLLM | openai/ (قاعدة مخصصة) |
محرك استنتاج مستضاف ذاتياً | |
| نماذج محلية | Deepseek | deepseek/ |
Deepseek Chat/Coder |
| تعزيز البحث | Perplexity | perplexity/ |
Sonar Pro |
| منصات التجميع | OpenRouter | openrouter/ |
نماذج متنوعة |
🎯 نصيحة للاختيار: يعتمد اختيار النموذج على سيناريو الاستخدام المحدد. إذا لم تكن متأكداً من النموذج الأنسب، يمكنك اختبار أداء النماذج المختلفة بسرعة عبر منصة APIYI (apiyi.com)، التي تدعم أيضاً استدعاء واجهة برمجة التطبيقات المتوافقة مع OpenAI لمعظم النماذج المذكورة أعلاه.

الأسئلة الشائعة حول LiteLLM (FAQ)
س1: ما الفرق بين LiteLLM واستخدام OpenAI SDK مباشرة؟
تسمح لك OpenAI SDK باستدعاء نماذج OpenAI فقط. أما LiteLLM فهي توسعة مبنية فوق OpenAI SDK، تتيح لك استخدام نفس تنسيق الكود لاستدعاء أكثر من 100 مزود نماذج آخر مثل Anthropic وGoogle وAzure وغيرها. إذا كان مشروعك يعتمد على نماذج OpenAI فقط، فاستخدام OpenAI SDK مباشرة يكفي. ولكن إذا كنت بحاجة إلى دعم نماذج متعددة، أو ميزات تجاوز الفشل (Failover)، أو التحكم في التكاليف، فإن LiteLLM هي الخيار الأفضل.
س2: هل LiteLLM مجانية؟
الوظائف الأساسية لـ LiteLLM مفتوحة المصدر ومجانية بالكامل (ترخيص MIT). لكن تجدر الإشارة إلى أن LiteLLM نفسها مجانية، بينما استدعاء نماذج API التي تستخدمها يتطلب دفع رسوم. يجب عليك الحصول على مفتاح API الخاص بك من OpenAI أو Anthropic أو غيرهم ودفع تكاليف استدعاء النموذج. إذا كنت لا ترغب في إدارة مفاتيح API متعددة بشكل منفصل، يمكنك استخدام منصات واجهة موحدة مثل APIYI (apiyi.com) لتبسيط إدارة المفاتيح.
س3: ما هي مواصفات الخادم المطلوبة لـ LiteLLM Proxy؟
خادم LiteLLM Proxy خفيف جداً، ويمكن تشغيله على خادم بذاكرة وصول عشوائي (RAM) سعة 1 جيجابايت ونواة واحدة. ولكن إذا كنت بحاجة إلى الوظائف الكاملة (تتبع التكاليف، إدارة المفاتيح الافتراضية)، فستحتاج أيضاً إلى قاعدة بيانات PostgreSQL وRedis. بالنسبة لبيئة الإنتاج، نوصي بحد أدنى من 2 نواة و4 جيجابايت من الذاكرة + PostgreSQL + Redis.
س4: ما الفرق بين LiteLLM وOpenRouter؟
الفرق الأكبر هو: LiteLLM هو حل مفتوح المصدر يمكنك استضافته ذاتياً، بينما OpenRouter هي خدمة مدارة.
- LiteLLM: مجانية، تقوم باستضافتها بنفسك، تدير مفاتيح API الخاصة بك، وتتحكم بالكامل في تدفق البيانات.
- OpenRouter: جاهزة للاستخدام الفوري، ولكن هناك زيادة في أسعار استدعاءات API، وتمر البيانات عبر طرف ثالث.
إذا كنت تهتم بخصوصية البيانات أو لديك مفاتيح API خاصة بك، اختر LiteLLM. إذا كنت تريد استخداماً سريعاً دون أي عمليات نشر، يمكنك التفكير في الحلول المدارة مثل APIYI (apiyi.com).
س5: هل تدعم LiteLLM مخرجات البث (Streaming)؟
نعم، تدعمها. سواء في وضع SDK أو وضع Proxy، تدعم LiteLLM بالكامل مخرجات البث عبر SSE. يتم تحويل استجابات البث لجميع المزودين بشكل موحد إلى تنسيق chunk الخاص بـ OpenAI، مما يضمن تجربة بث متسقة.
# مثال على استخدام البث
stream = litellm.completion(
model="gpt-4o",
messages=[{"role": "user", "content": "اكتب قصة"}],
stream=True
)
for chunk in stream:
print(chunk.choices[0].delta.content or "", end="")
س6: هل يجب على المبتدئ اختيار وضع SDK أم وضع Proxy؟
إذا كنت مطور Python وبدأت للتو في التعلم، فإن البدء بوضع SDK هو الأسهل؛ حيث يكفي pip install litellm ثم كتابة بضعة أسطر من الكود للبدء. عندما تحتاج إلى تعاون الفريق، أو دمج لغات متعددة، أو النشر في بيئة الإنتاج، يمكنك الانتقال إلى وضع Proxy. طريقة الاستدعاء الأساسية في كلا الوضعين متطابقة، لذا فإن تكلفة الانتقال منخفضة جداً.
س7: أين يتم وضع ملف الإعدادات config.yaml الخاص بـ LiteLLM؟
لا يوجد موقع ثابت. عند تشغيل Proxy، يمكنك تحديد المسار عبر المعامل --config:
litellm --config /path/to/your/config.yaml
يُفضل عادةً وضعه في المجلد الرئيسي للمشروع أو في مجلد مخصص للإعدادات. إذا كنت تستخدم Docker للنشر، يمكنك ربط الملف داخل الحاوية (Volume).
دليل اتخاذ القرار السريع لـ LiteLLM
بناءً على وضعك الحالي، اختر الحل الأنسب لك:
| وضعك الحالي | الحل الموصى به | السبب |
|---|---|---|
| مطور فردي، مشروع Python | LiteLLM SDK | لا يحتاج نشر، جاهز في 5 دقائق |
| تطوير فريق، حاجة للتحكم في الميزانية | LiteLLM Proxy | مفاتيح افتراضية + تتبع التكاليف |
| لا ترغب في بناء بنية تحتية ذاتية | APIYI (apiyi.com) | خدمة مدارة، جاهزة للاستخدام |
| نظام متعدد الوكلاء (Agents) | LiteLLM Proxy | توجيه موحد + موازنة الحمل |
| استخدام نماذج OpenAI فقط | OpenAI SDK مباشرة | لا حاجة لطبقة إضافية |
| التركيز على خصوصية البيانات | LiteLLM (استضافة ذاتية) | البيانات لا تمر عبر طرف ثالث |
ملخص
تُعد LiteLLM أداة بنية تحتية عملية للغاية في تطوير تطبيقات الذكاء الاصطناعي. وتتلخص قيمتها الجوهرية في جملة واحدة: استخدم مجموعة واحدة من الأكواد بتنسيق OpenAI لاستدعاء واجهات برمجة التطبيقات (API) لأكثر من 100 مزود للنماذج.
بالنسبة للمبتدئين، إليكم النقاط الأساسية التي يجب تذكرها:
- LiteLLM هي "مترجم": تساعدك في ترجمة الطلبات ذات التنسيق الموحد إلى تنسيقات API الخاصة بكل نموذج.
- وضعان للعمل: وضع SDK (حزمة Python خفيفة) ووضع Proxy (خادم بوابة مستقل).
- القيمة الجوهرية: واجهة موحدة + آلية التراجع (Fallback) + موازنة الأحمال + تتبع التكاليف.
- معيار أساسي لإطارات عمل الوكلاء (Agent): تدعمها جميع الإطارات تقريبًا مثل LangChain وCrewAI وAutoGen.
- مفتوحة المصدر ومجانية بالكامل: مرخصة بموجب MIT، ولا توجد أي تكاليف عند النشر الذاتي.
إذا كنت تجد أن تكاليف التشغيل والصيانة لنشر LiteLLM Proxy ذاتياً مرتفعة، يمكنك استخدام خدمات الواجهة الموحدة المُدارة مثل APIYI (apiyi.com)، والتي تتيح لك تحقيق نفس النتيجة باستخدام مفتاح API واحد لاستدعاء جميع النماذج الرئيسية، مما يوفر عليك عناء النشر والصيانة.
كاتب المقال: الفريق التقني لـ APIYI
للتواصل التقني: تفضل بزيارة APIYI على apiyi.com للحصول على المزيد من دروس استدعاء نماذج الذكاء الاصطناعي والدعم الفني.
تاريخ التحديث: أبريل 2026
الإصدار المتوافق: LiteLLM v1.x+
مراجع:
- التوثيق الرسمي لـ LiteLLM: docs.litellm.ai
- مستودع LiteLLM على GitHub: github.com/BerriAI/litellm
- الموقع الرسمي لـ LiteLLM: litellm.ai
- الموقع الرسمي لـ BerriAI: berri.ai