Le modèle Claude Opus 4.7 a été officiellement lancé le 16 avril 2026, et dès le lendemain, la communauté était déjà divisée. Si les benchmarks officiels affirment qu'il surpasse la version 4.6 dans 12 tests sur 14, de nombreux développeurs sur GitHub et X se plaignent de performances en retrait, certains allant même jusqu'à le qualifier de "version 4.6 pré-modifiée déguisée en nouvelle version".
Cet article s'appuie sur les données officielles d'Anthropic, des tests indépendants et les retours directs de la communauté pour évaluer en profondeur Claude Opus 4.7 selon 8 dimensions : capacités de codage, reconnaissance visuelle, contexte étendu, changements de Tokenizer, budgets de tâches, etc., afin de vous aider à décider s'il est temps de migrer.
Valeur ajoutée : Après lecture, vous saurez si Claude Opus 4.7 représente une mise à niveau ou une régression pour vos cas d'usage, et comment éviter les risques liés à la migration.

Contexte et informations clés sur le lancement de Claude Opus 4.7
Claude Opus 4.7 est le modèle phare lancé par Anthropic le 16 avril 2026. Il conserve la tarification de 5 $/25 $ par million de jetons de la version 4.6, tout en établissant de nouveaux records sur plusieurs benchmarks. Cependant, il s'accompagne de changements systémiques tels qu'une refonte du Tokenizer, une baisse significative du benchmark de contexte étendu MRCR, et un nouveau niveau d'inférence "xhigh", autant d'éléments qui impactent directement les performances réelles en entreprise.
Aperçu rapide de Claude Opus 4.7
| Élément | Détails |
|---|---|
| Date de lancement | 16 avril 2026 |
| Éditeur | Anthropic |
| Prix d'entrée | 5 $ / million de jetons (identique à la 4.6) |
| Prix de sortie | 25 $ / million de jetons (identique à la 4.6) |
| Fenêtre de contexte | 1M de jetons (tarification standard) |
| Résolution d'image max. | 2576px côté long / 3,75 mégapixels |
| Nouveau niveau d'inférence | xhigh (entre high et max) |
| Fonctionnalité expérimentale | Task Budgets (en bêta publique) |
| Canaux disponibles | API Claude, Amazon Bedrock, Google Vertex AI, Microsoft Foundry |
🎯 Conseil technique : Avant de migrer officiellement vers Claude Opus 4.7, nous vous recommandons d'effectuer des tests comparatifs en parallèle entre la 4.6 et la 4.7 via la plateforme APIYI (apiyi.com). Cette plateforme offre une interface unifiée où le changement de modèle ne nécessite que la modification d'un paramètre, permettant d'identifier rapidement les écarts de performance.
Points forts de la mise à niveau de Claude Opus 4.7
Les améliorations mises en avant par Anthropic se concentrent principalement sur quatre axes :
- Capacités en génie logiciel nettement renforcées : Le score SWE-bench Verified passe de 80,8 % à 87,6 %, et le SWE-bench Pro bondit de 53,4 % à 64,3 %.
- Amélioration majeure de la compréhension visuelle : Prise en charge d'images haute résolution jusqu'à 3,75 mégapixels, avec un benchmark visuel passant de 54,5 % à 98,5 %.
- Renforcement de l'utilisation des outils (Agentic) : Le benchmark MCP-Atlas enregistre la plus forte progression, avec un gain de 13 points sans outils.
- Suivi des instructions plus précis : Un traitement plus robuste des instructions ambiguës et une exécution plus rigoureuse.
Cependant, les retours réels de la communauté racontent une tout autre histoire.
Analyse détaillée des fonctionnalités de Claude Opus 4.7
Les évolutions majeures de Claude Opus 4.7 ne concernent pas uniquement les capacités du modèle, mais touchent également à des ajustements importants au niveau de la livraison. Comprendre ces changements est crucial pour évaluer correctement les performances du modèle.

Les quatre changements systémiques de Claude Opus 4.7
| Module fonctionnel | Performances 4.6 | Évolution 4.7 | Impact métier |
|---|---|---|---|
| Tokenizer | Segmentation standard | 1,0 à 1,35× de tokens pour le même texte | Augmentation potentielle de 35% de la facture |
| Niveaux d'inférence | low / medium / high / max | Ajout de xhigh (par défaut sur Claude Code) | Inférence plus granulaire |
| Budgets de tâche | N/A | Version bêta, contrôle global des tokens | Coûts des boucles d'agents maîtrisés |
| Entrée visuelle | Env. 1,15 million de px | Env. 3,75 millions de px (3×) | Support des captures et plans HD |
| MRCR contexte long | 78,3 % | 32,2 % | Baisse importante du rappel long |
| SWE-bench Verified | 80,8 % | 87,6 % | Amélioration significative du code |
Le coût invisible du nouveau Tokenizer
Le changement le plus critique, bien que souvent négligé, dans Claude Opus 4.7 est la refonte du Tokenizer. La documentation officielle est claire : le même texte est désormais converti en 1,0 à 1,35 fois plus de tokens que dans la version 4.6. Cela implique que :
- La longueur de votre invite reste inchangée, mais la facturation des tokens en entrée peut grimper de 35 %.
- En mode d'inférence
xhighoumax, les tokens en sortie peuvent également augmenter significativement. - Vos limites
max_tokensdéfinies pour la version 4.6 doivent être intégralement retestées. - La logique client permettant d'estimer le nombre de tokens à partir du nombre de caractères doit être réécrite.
💰 Optimisation des coûts : Pour les environnements de production sensibles au coût des tokens, nous recommandons vivement d'effectuer une simulation avec votre trafic réel sur la plateforme APIYI (apiyi.com) avant de migrer vers Claude Opus 4.7. La plateforme permet un suivi précis et une surveillance en temps réel pour quantifier précisément l'impact budgétaire de cette migration.
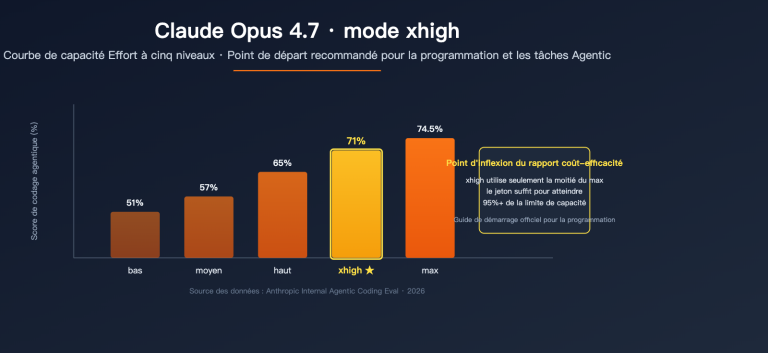
Stratégies d'utilisation du mode d'inférence xhigh
Le mode xhigh est une nouveauté d'Opus 4.7, se situant entre high et max. Anthropic préconise son utilisation par défaut pour les tâches de codage et les agents, c'est d'ailleurs le mode par défaut pour toutes les offres Claude Code.
Cas d'usage selon les niveaux d'inférence :
| Niveau | Tâches adaptées | Latence | Recommandation |
|---|---|---|---|
low |
Questions simples, formatage | Minimale | Haute concurrence, faible complexité |
medium |
Génération de code standard | Faible | Assistance au développement |
high |
Code complexe, conception technique | Moyenne | Tâches d'agents classiques |
xhigh |
Débogage difficile, refactoring | Moyenne-Haute | Recommandé : Codage (Claude Code, etc.) |
max |
Raisonnement complexe extrême | Élevée | Recherche, tâches non critiques en latence |
Budgets de tâche : La fin des coûts incontrôlés pour les agents
La fonctionnalité "Task Budgets", introduite en version bêta dans Opus 4.7, résout enfin le problème persistant du contrôle de la consommation de tokens lors des boucles d'agents. Son fonctionnement :
- Le développeur définit un budget total de tokens avant de lancer la boucle.
- Le modèle intègre un compte à rebours budgétaire à chaque réponse.
- Le modèle ajuste automatiquement sa profondeur de réflexion et le nombre d'appels aux outils en fonction du solde restant.
- Avant épuisement du budget, le modèle priorise la finalisation de la tâche principale pour conclure proprement.
Cette fonctionnalité, couplée à la nouvelle interface redact-thinking-2026-02-12, constitue une réelle avancée pour la gouvernance des coûts liés à l'usage des agents.
Panorama des données de test du Claude Opus 4.7
Cette section constitue le cœur de cet article. Nous avons compilé les benchmarks officiels d'Anthropic, les évaluations indépendantes de tiers ainsi que les données de re-test de la communauté pour mettre en lumière l'écart réel entre Claude Opus 4.7 et 4.6.
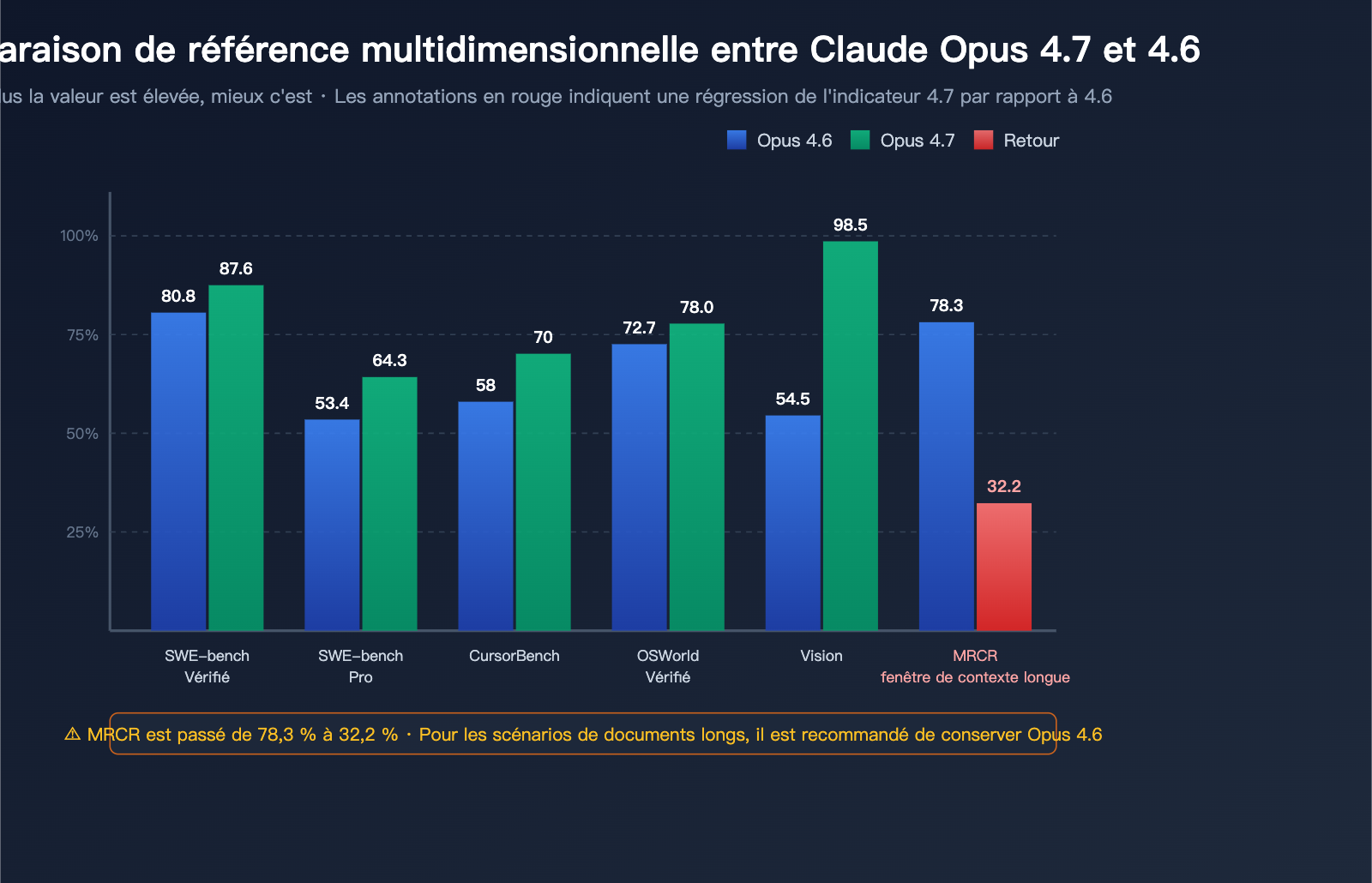
Capacités de codage : le 4.7 domine largement
| Benchmark de codage | Opus 4.6 | Opus 4.7 | Amélioration | Note |
|---|---|---|---|---|
| SWE-bench Verified | 80,8 % | 87,6 % | +6,8 pt | Résolution réelle de tickets GitHub |
| SWE-bench Pro | 53,4 % | 64,3 % | +10,9 pt | Variantes multilingues plus complexes |
| CursorBench | 58 % | 70 % | +12 pt | Tâches de codage réelles dans l'IDE |
| OSWorld-Verified | 72,7 % | 78,0 % | +5,3 pt | Manipulation système et usage PC |
| MCP-Atlas (sans outils) | — | +13 pt | Plus forte hausse | Tâches de chaînes d'outils agentiques |
| MCP-Atlas (avec outils) | — | +6 pt | Amélioration nette | Précision d'invocation d'outils |
En matière de codage, le Claude Opus 4.7 est bel et bien le modèle public le plus puissant du T2 2026. Avec un score de 64,3 % sur SWE-bench Pro, il reprend la première place des classements en codage agentique.
🚀 Démarrage rapide : Si vous souhaitez tester immédiatement les capacités de codage de Claude Opus 4.7, vous pouvez l'invoquer via la plateforme APIYI (apiyi.com). Celle-ci propose des interfaces totalement compatibles avec l'API officielle de Claude, prend en charge le format standard du SDK OpenAI et minimise les coûts de migration.
Benchmarks visuels et fenêtre de contexte : un bilan contrasté
| Benchmark | Opus 4.6 | Opus 4.7 | Évolution | Évaluation |
|---|---|---|---|---|
| Reconnaissance visuelle (général) | 54,5 % | 98,5 % | +44 pt | Quasi-mutation |
| Résolution d'image max. | ~1,15 MP | ~3,75 MP | 3× | Gère les captures d'écran 4K |
| Rappel long contexte MRCR | 78,3 % | 32,2 % | -46,1 pt | Régression sévère |
Le MRCR (Multi-Round Context Recall) est le benchmark standard pour évaluer la capacité de rappel dans des contextes longs. Sur cet indicateur, Opus 4.7 chute brutalement, passant de 78,3 % à 32,2 %. Il ne s'agit pas d'une simple fluctuation, mais d'une régression structurelle.
Ce chiffre explique pourquoi de nombreux développeurs se plaignent : "On fournit au modèle 800 lignes de documentation de workflow, il prétend les avoir lues, mais ses réponses n'ont aucun rapport avec le contenu."
Benchmarks vs expérience réelle : pourquoi un tel clivage ?
Des scores élevés ne garantissent pas une meilleure performance sur les cas d'usage réels. Opus 4.7 suscite de nombreux retours négatifs au sein de la communauté pour plusieurs raisons :
- Inflation des jetons (tokens) : Pour une même tâche, la consommation de jetons augmente sans que le gain de capacité ne compense systématiquement le coût.
- Suivi des instructions trop littéral : Alors que le 4.6 savait "comprendre l'intention", le 4.7 exécute tout au pied de la lettre, ce qui peut rendre vos invites (prompts) existantes inopérantes.
- Effondrement MRCR : La baisse des capacités de recherche dans de longs documents pose problème lors du traitement de larges bases de code ou de contrats.
- Faux positifs avec Claude Code : Certains développeurs signalent que la version 4.7 qualifie parfois par erreur du code sain de "malveillant" et refuse de l'éditer.
💡 Conseil de sélection : Le choix entre Claude Opus 4.7 et le maintien du 4.6 dépend principalement de vos cas d'usage métier critiques. Nous vous recommandons d'effectuer des tests de charge en parallèle sur les deux versions via la plateforme APIYI (apiyi.com), qui permet l'invocation unifiée de plusieurs modèles, facilitant ainsi les comparaisons et les basculements rapides.
Expérience réelle avec Claude Opus 4.7
Au-delà des benchmarks, les retours d'Anthropic et de la communauté des développeurs sur les performances d'Opus 4.7 dans les flux de travail réels sont radicalement différents.
La position officielle d'Anthropic
Dans son annonce, Anthropic a mis en avant quatre améliorations majeures d'Opus 4.7 par rapport à la version 4.6 :
- Meilleure performance des pipelines d'ingénierie : les utilisateurs peuvent désormais confier en toute confiance à la version 4.7 les "tâches complexes" qui nécessitaient auparavant une supervision étroite.
- Meilleure gestion des problèmes ambigus : une plus grande robustesse face aux besoins mal définis.
- Résolution de problèmes plus complète : le modèle ne s'arrête plus en cours de route.
- Suivi des instructions plus précis : une rigueur accrue sur les détails.
Boris Cherny, responsable de Claude Code, a déclaré après le lancement qu'Opus 4.7 était "plus intelligent, plus autonome et plus précis" que la 4.6, tout en admettant qu'il fallait quelques jours d'adaptation pour exploiter pleinement ses nouvelles capacités.
Les retours réels de la communauté des développeurs
Sur des plateformes comme GitHub, Hacker News ou X, les retours des développeurs sont nettement plus critiques :
Plainte 1 : Explosion de la consommation de jetons (tokens)
En raison du nouveau tokenizer, la même entrée est décomposée en davantage de jetons sur Opus 4.7. Si l'on ajoute l'augmentation des jetons de sortie dans le mode xhigh, certains utilisateurs signalent des hausses de facture allant jusqu'à 40 %. Ce phénomène est ironiquement surnommé "AI Shrinkflation" (la shrinkflation de l'IA).
Plainte 2 : Désastre sur le traitement de longs documents
Plusieurs développeurs rapportent qu'après avoir soumis de longs documents à Opus 4.7, le modèle prétend les avoir lus, mais génère un contenu sans rapport avec le document. Cela concorde parfaitement avec la chute du MRCR, passé de 78,3 % à 32,2 %.
Plainte 3 : Claude Code identifie à tort du code comme malveillant
Dans l'issue #47483, plusieurs ingénieurs signalent que Claude Opus 4.7 marque des portions de code de lecture/écriture de fichiers tout à fait normales comme étant des logiciels malveillants (malware), refusant ainsi d'exécuter des requêtes d'édition basiques.
Plainte 4 : Baisse de compatibilité des invites (prompts)
Les invites qui fonctionnaient parfaitement sur la 4.6 voient leur qualité de sortie diminuer lors de la migration vers la 4.7. La raison est que la 4.7 exécute les instructions de manière strictement littérale, là où la 4.6 savait "lire entre les lignes".
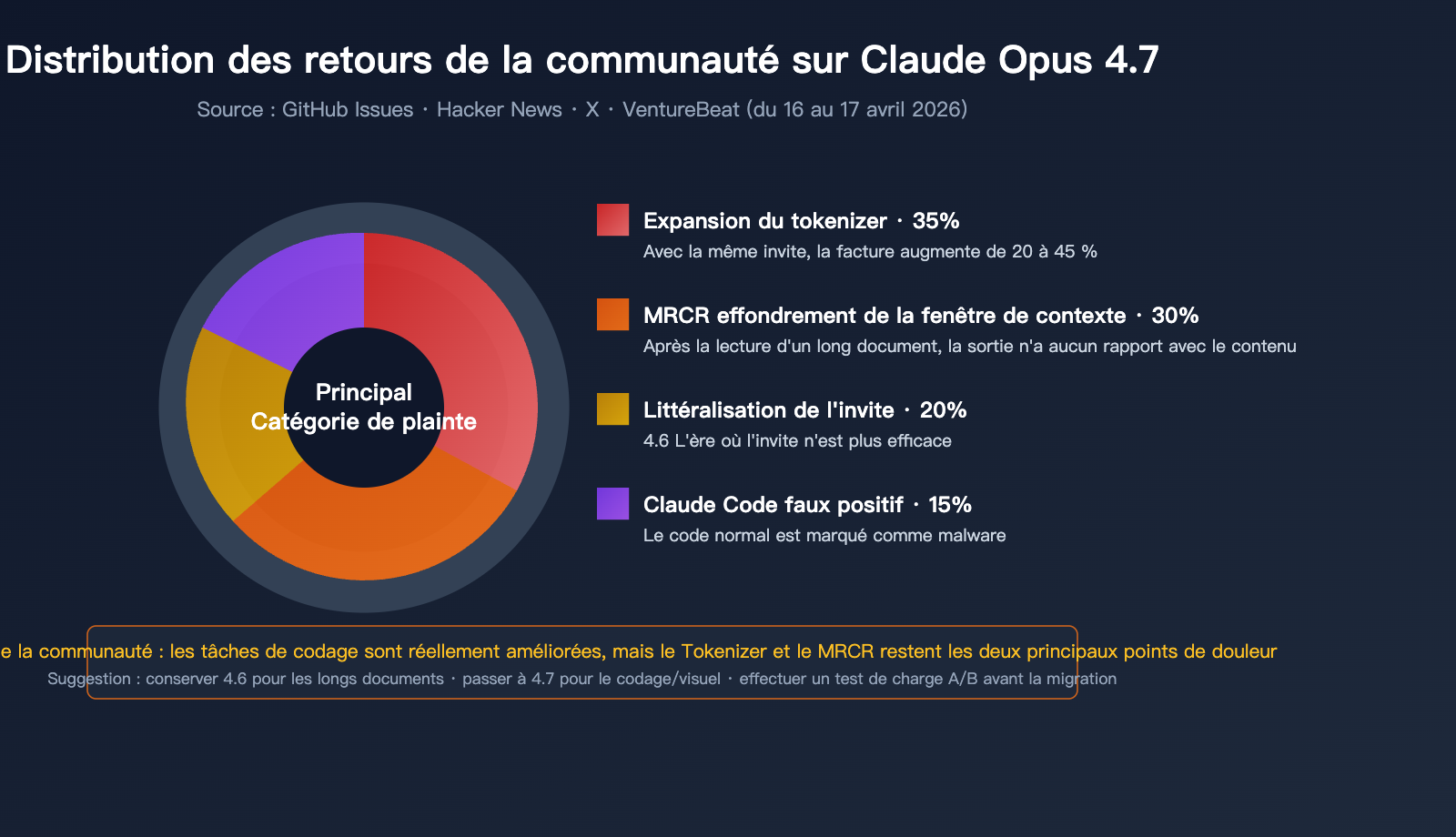
Notation par scénario pour Claude Opus 4.7
Basé sur les données réelles et les retours de la communauté, voici une évaluation d'Opus 4.7 selon différents cas d'usage :
| Scénario d'utilisation | Note Opus 4.6 | Note Opus 4.7 | Évolution | Conseil |
|---|---|---|---|---|
| Refactorisation de code court/moyen | 8/10 | 9/10 | ↑ | Migrer immédiatement |
| Flux de travail agentique complexe | 7,5/10 | 9/10 | ↑ | Migrer immédiatement |
| Revue de code sur grands dépôts | 8/10 | 6,5/10 | ↓ | Continuer avec la 4.6 |
| Résumé et Q&A sur longs documents | 8,5/10 | 5/10 | ↓↓ | Continuer avec la 4.6 |
| Compréhension d'images HD | 6,5/10 | 9,5/10 | ↑↑ | Migrer immédiatement |
| Conversation et rédaction courante | 9/10 | 9/10 | → | Au choix |
| Production sensible aux coûts | 9/10 | 7/10 | ↓ | Continuer avec la 4.6 |
| Prototypage et expérimentation | 8/10 | 8,5/10 | ↑ | Migrer |
Analyse approfondie des avantages et inconvénients de Claude Opus 4.7
Après avoir comparé les données et l'expérience utilisateur, nous pouvons dresser un bilan clair.
Les quatre avantages majeurs de Claude Opus 4.7
Avantage 1 : Amélioration significative des capacités de codage réelles
Les scores de 87,6 % sur SWE-bench Verified et 64,3 % sur SWE-bench Pro ne sont pas que des chiffres ; ils représentent de véritables tâches de correction d'issues GitHub. Cela signifie qu'Opus 4.7 peut réellement remplacer davantage de travail humain sur les tâches de codage de petite et moyenne envergure.
Avantage 2 : Transformation de la compréhension visuelle
L'entrée d'images haute résolution (3,75 mégapixels) permet à Opus 4.7 de traiter directement des captures d'écran 4K, des maquettes de design, des scans PDF et d'autres contenus visuels denses. C'est une avancée majeure pour la gamme Claude.
Avantage 3 : Les "Task Budgets" pour la gestion des coûts des agents
Pendant longtemps, la consommation incontrôlée de jetons dans les boucles d'agents a été un frein majeur pour les entreprises. Les "Task Budgets" offrent enfin aux développeurs une capacité de contrôle budgétaire global et précis.
Avantage 4 : Le mode xhigh offre un meilleur équilibre entre raisonnement et latence
L'ajout d'un palier entre "high" et "max" permet aux développeurs d'ajuster leur usage de manière flexible selon les exigences de SLA dans un même scénario.
Les quatre limites principales de Claude Opus 4.7
Limite 1 : L'inflation du Tokenizer entraîne une hausse des coûts réels
Même à prix unitaire constant, l'inflation de 35 % des jetons, combinée à l'augmentation des sorties en mode xhigh, peut rendre la facture réelle 20 à 45 % plus élevée qu'avec la 4.6.
Solution : Retester tous les chemins de code avec l'interface de comptage de jetons avant toute migration.
Limite 2 : Effondrement de la capacité de rappel (recall) sur longs contextes
C'est le problème le plus critique. Lors du traitement de longs documents, de grandes bases de code ou de longues conversations, la précision du rappel d'Opus 4.7 chute brutalement.
Solution : Continuer à utiliser Opus 4.6 pour les longs documents ou adopter une stratégie RAG + découpage.
Limite 3 : Suivi des instructions trop littéral
Les invites existantes peuvent produire des résultats inattendus.
Solution : Réécrire systématiquement les invites, supprimer les intentions implicites et utiliser des contraintes explicites.
Limite 4 : Augmentation des erreurs de jugement et des hallucinations dans certains scénarios
La communauté rapporte largement des problèmes tels que les erreurs de jugement de Claude Code sur le code ou les hallucinations sur les longs documents.
Solution : Accompagner les tâches critiques d'une vérification humaine et utiliser une validation croisée multi-modèles pour les logiques essentielles.
🎯 Conseil de migration : Si votre activité implique à la fois du codage sur des tâches courtes et le traitement de longs documents, nous vous recommandons d'utiliser la plateforme APIYI (apiyi.com) pour router les différentes versions de Claude selon le scénario. Cette plateforme permet une invocation unifiée de plusieurs modèles, vous permettant de combiner de manière flexible Opus 4.6 (pour le long contexte) et 4.7 (pour le codage/visuel) au sein d'un même projet, évitant ainsi la baisse de performance liée à une migration "tout ou rien".
Pratique de l'invocation de l'API Claude Opus 4.7
Au-delà de l'analyse théorique, nous vous proposons des exemples de code opérationnels pour vous aider à prendre en main rapidement Claude Opus 4.7.
Exemple minimaliste (Compatible avec le SDK OpenAI)
import openai
client = openai.OpenAI(
api_key="VOTRE_CLE_API",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=[
{"role": "user", "content": "Veuillez écrire un exemple de crawler concurrent en Python"}
],
temperature=0.7,
max_tokens=4096
)
print(response.choices[0].message.content)
Voir le code complet (incluant le mode de raisonnement xhigh, les budgets de tâches et la gestion des erreurs)
import openai
import time
from typing import Optional
class ClaudeOpusClient:
"""Wrapper complet pour l'invocation de Claude Opus 4.7"""
def __init__(self, api_key: str, base_url: str = "https://api.apiyi.com/v1"):
self.client = openai.OpenAI(
api_key=api_key,
base_url=base_url
)
def generate(
self,
prompt: str,
model: str = "claude-opus-4-7",
effort: str = "xhigh",
task_budget: Optional[int] = None,
max_retries: int = 3
) -> str:
"""Appelle Claude Opus 4.7 avec prise en charge des nouvelles fonctionnalités"""
extra_headers = {}
if task_budget:
extra_headers["task-budget-tokens"] = str(task_budget)
if effort:
extra_headers["reasoning-effort"] = effort
for attempt in range(max_retries):
try:
response = self.client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
max_tokens=8192,
extra_headers=extra_headers,
timeout=120
)
return response.choices[0].message.content
except openai.RateLimitError:
wait = 2 ** attempt
print(f"Limite de taux atteinte, attente de {wait}s...")
time.sleep(wait)
except openai.APIError as e:
print(f"Erreur API : {e}")
if attempt == max_retries - 1:
raise
time.sleep(1)
raise RuntimeError("Nombre maximal de tentatives dépassé")
def compare_versions(self, prompt: str) -> dict:
"""Appelle simultanément les versions 4.6 et 4.7 pour comparaison"""
results = {}
for model in ["claude-opus-4-6", "claude-opus-4-7"]:
start = time.time()
results[model] = {
"output": self.generate(prompt, model=model),
"latency": time.time() - start
}
return results
if __name__ == "__main__":
client = ClaudeOpusClient(api_key="VOTRE_CLE_API")
result = client.generate(
prompt="Refactorise ce code Python pour le rendre asynchrone et concurrent",
effort="xhigh",
task_budget=50000
)
print(result)
🚀 Démarrage rapide : Le
base_urldans le code ci-dessus pointe vers la plateforme APIYI (apiyi.com). Cette plateforme fournit une interface entièrement compatible avec l'API officielle de Claude, tout en permettant l'invocation parallèle de Claude Opus 4.7 et 4.6, facilitant ainsi les tests A/B durant la période de migration.
Liste de contrôle pour une migration réussie
Étapes indispensables pour passer d'Opus 4.6 à 4.7 :
# 1. Tester à nouveau les limites de max_tokens (changement de Tokenizer)
from openai import OpenAI
client = OpenAI(
api_key="VOTRE_CLE_API",
base_url="https://api.apiyi.com/v1"
)
# Appeler les deux modèles avec la même invite et enregistrer la consommation réelle de jetons
for model in ["claude-opus-4-6", "claude-opus-4-7"]:
resp = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": VOTRE_INVITE}],
max_tokens=4096
)
print(f"{model} : entrée={resp.usage.prompt_tokens}, sortie={resp.usage.completion_tokens}")
# 2. Tester les scénarios de longs documents (effondrement MRCR)
# Il est conseillé de conserver les tâches sur documents longs pour la version 4.6 ou d'utiliser le découpage RAG
# 3. Auditer les intentions implicites dans vos invites
# La version 4.7 suit les instructions à la lettre : remplacez l'interprétation d'intention par des contraintes explicites
FAQ sur Claude Opus 4.7
Q1 : Claude Opus 4.7 est-il vraiment meilleur que le 4.6 ?
La réponse dépend du cas d'usage :
- Tâches de programmation courtes/moyennes : Le 4.7 est nettement meilleur (SWE-bench Verified +6,8 pts, CursorBench +12 pts)
- Tâches visuelles haute définition : Le 4.7 surpasse largement le 4.6 (benchmark visuel passant de 54,5 % à 98,5 %)
- Chaînes d'outils Agentic : Le 4.7 est plus performant (MCP-Atlas +13 pts)
- Recherche en contexte étendu : Le 4.6 est nettement meilleur (MRCR 78,3 % contre 32,2 %)
- Sensibilité aux coûts : Le 4.6 est plus avantageux (le gonflement des jetons du 4.7 peut atteindre 35 %)
Si vous avez besoin d'invoquer les deux versions en parallèle, nous vous recommandons d'utiliser la plateforme APIYI (apiyi.com) pour acheminer vos requêtes vers la version appropriée selon vos besoins métier. La plateforme permet d'appeler toute la série de modèles Claude avec une seule clé API.
Q2 : Pourquoi certains disent-ils que Claude Opus 4.7 est moins performant que le 4.6 ?
Il y a quatre raisons principales :
- Refonte du Tokenizer : Pour une même tâche, la consommation de jetons peut augmenter jusqu'à 35 %, sans que le gain en capacités ne compense forcément ce surcoût.
- Chute dans le contexte étendu (MRCR) : Le passage de 78,3 % à 32,2 % représente un recul significatif pour le traitement de longs documents.
- Respect littéral des instructions : Les invites basées sur une « intention implicite » conçues pour la 4.6 peuvent échouer sur la 4.7.
- Faux positifs avec Claude Code : Certains développeurs signalent que du code tout à fait sain est parfois marqué comme malveillant.
Ce ne sont pas des impressions, mais de réelles différences d'expérience dues à des changements structurels.
Q3 : Comment migrer en toute sécurité de la version 4.6 vers la 4.7 ?
Méthode en trois étapes :
- Test en charge parallèle : Appelez simultanément la 4.6 et la 4.7 sur 5 à 10 % de votre trafic de production pour comparer la qualité des résultats, la latence et les coûts.
- Routage par scénario : Continuez à utiliser la 4.6 pour les longs documents et les grandes bases de code ; basculez sur la 4.7 pour le codage court et les tâches visuelles.
- Déploiement progressif : Augmentez la charge de 10 % → 30 % → 50 % → 100 %, en observant chaque étape pendant 3 à 7 jours.
Nous recommandons d'utiliser la plateforme APIYI (apiyi.com) pour ces tests de migration, car elle permet un routage flexible des modèles et une répartition intelligente du trafic.
Q4 : Quand faut-il utiliser le niveau « xhigh » de Claude Opus 4.7 ?
Anthropic recommande d'utiliser « xhigh » par défaut pour les tâches de programmation et les agents. Cas d'utilisation :
- Refactorisation de code complexe
- Débogage de bugs sur plusieurs fichiers
- Génération de tests unitaires à grande échelle
- Tâches impliquant des chaînes d'outils Agentic complexes
Cas où il faut l'éviter :
- Questions-réponses simples (le niveau « medium » suffit)
- Requêtes à haute concurrence (la latence du « xhigh » est plus élevée)
- Tâches sensibles au coût (le nombre de jetons en sortie augmente nettement)
Q5 : Comment utiliser les budgets de tâches (Task Budgets) et dans quel contexte ?
Les Task Budgets sont une fonctionnalité en version bêta, transmise via un en-tête HTTP :
task-budget-tokens: 50000
Cas d'utilisation :
- Boucles d'agents à long cycle (pour contrôler le coût total)
- SaaS multi-locataires (pour limiter le budget par utilisateur)
- Tâches d'automatisation CI/CD (pour plafonner le nombre de jetons par job)
Le modèle ajuste automatiquement sa profondeur de réflexion en fonction du budget restant, terminant la tâche proprement avant épuisement du budget pour éviter un échec en milieu de processus.
Q6 : Les capacités visuelles de Claude Opus 4.7 sont-elles vraiment aussi puissantes ?
Oui, et c'est l'une des évolutions les plus marquantes de la version 4.7 :
- Résolution maximale : Augmentation de 1,15 million à 3,75 millions de pixels (×3).
- Benchmark visuel : Bond de 54,5 % à 98,5 %.
- Capacités pratiques : Capacité à lire directement des captures d'écran 4K, des schémas d'architecture, des maquettes d'UI et des documents numérisés en PDF.
Pour les équipes de développement frontend, de prototypage de design ou de numérisation documentaire, il s'agit d'une mise à jour qui change radicalement la donne.
À qui s'adresse Claude Opus 4.7 ? Conseils de décision
Sur la base de notre analyse complète, voici nos recommandations d'utilisation claires :
Scénarios pour une migration immédiate vers Claude Opus 4.7
- ✅ Codage et refactorisation de fichiers courts à moyens : Les données de SWE-bench et CursorBench parlent d'elles-mêmes.
- ✅ Flux de travail Agentic complexes : Bénéficie du double apport de MCP-Atlas et des Task Budgets.
- ✅ Traitement d'images haute définition : La capacité visuelle de 3,75 MP représente un changement qualitatif.
- ✅ Développement rapide de prototypes : Le niveau xhigh excelle sur les tâches de complexité moyenne.
Scénarios pour continuer à utiliser Claude Opus 4.6
- 🔒 Résumé et questions-réponses sur documents longs : L'effondrement MRCR est inévitable.
- 🔒 Revue de code à l'échelle d'un dépôt : La capacité de rappel sur contexte long est plus stable.
- 🔒 Sensibilité extrême aux coûts des jetons (tokens) : Le tokenizer de la version 4.6 est plus économique.
- 🔒 Production stable déjà en place : Il est déconseillé d'introduire des risques de régression juste pour suivre la nouveauté.
Stratégie recommandée pour un usage mixte
Pour la plupart des équipes, le routage par scénario est plus pragmatique qu'une "migration totale" :
- Documents longs → Opus 4.6
- Codage/Visuel/Agent → Opus 4.7
- Gérez les deux versions via une passerelle unifiée pour réduire les risques de migration.
💡 Conseil final : Le choix entre Claude Opus 4.7 et le maintien de la version 4.6 dépend principalement de vos cas d'usage spécifiques. Nous vous recommandons d'effectuer des tests comparatifs réels via la plateforme APIYI (apiyi.com). Cette plateforme prend en charge l'invocation du modèle via une interface unifiée pour plusieurs modèles grand public, facilitant ainsi les comparaisons et les basculements rapides, tout en préservant la flexibilité de votre activité lors de la transition.
Conclusion
Claude Opus 4.7 est une "mise à jour de compromis" typique : elle réalise un véritable bond en avant en matière de codage, de vision et de capacités Agentic, mais au prix de sacrifices notables sur le rappel en contexte long, l'efficacité des jetons et la compatibilité des invites.
Le débat au sein de la communauté dès le premier jour n'est pas infondé : Opus 4.7 est à la fois un nouveau modèle puissant et un ajustement architectural coûteux. Pour les développeurs, la question n'est pas de savoir "s'il faut migrer", mais "dans quels scénarios migrer".
- Si vous travaillez sur des tâches de code complexes ou de l'analyse visuelle haute définition, la 4.7 est le meilleur choix pour le T2 2026.
- Si votre cœur de métier repose sur le traitement de documents longs ou sur une inférence sensible aux coûts, conservez la 4.6 pour le moment.
- Lors de la migration, nous recommandons vivement des tests de charge en parallèle pour éviter les régressions cachées liées à une approche "tout ou rien".
Nous vous recommandons de tester rapidement Claude Opus 4.7 et 4.6 via la plateforme APIYI (apiyi.com). Elle offre une interface unifiée, un suivi de facturation en temps réel et des capacités de routage multi-modèles, ce qui en fait le choix idéal pour vos tests de migration et votre mise en production.
Références
-
Annonce officielle d'Anthropic : Présentation officielle de Claude Opus 4.7
- Lien :
anthropic.com/news/claude-opus-4-7 - Description : Capacités principales et détails de tarification officiels.
- Lien :
-
Documentation officielle de l'API Claude : Guide de migration vers Claude Opus 4.7
- Lien :
platform.claude.com/docs/en/about-claude/models/migration-guide - Description : Conseils de migration officiels et explications sur les changements du tokenizer.
- Lien :
-
Blog de lancement AWS Bedrock : Claude Opus 4.7 disponible sur Amazon Bedrock
- Lien :
aws.amazon.com/blogs/aws/introducing-anthropics-claude-opus-4-7-model-in-amazon-bedrock - Description : Instructions de déploiement sur les plateformes cloud tierces.
- Lien :
-
Analyse comparative Vellum AI : Analyse approfondie des benchmarks de Claude Opus 4.7
- Lien :
vellum.ai/blog/claude-opus-4-7-benchmarks-explained - Description : Évaluation indépendante par un tiers.
- Lien :
-
GitHub Issue #47483 : Retours de la communauté sur Claude Opus
- Lien :
github.com/anthropics/claude-code/issues/47483 - Description : Retours d'expérience de première main de la part des développeurs.
- Lien :
Auteur : Équipe technique APIYI
Date de publication : 17/04/2026
Modèles concernés : Claude Opus 4.7 / Claude Opus 4.6
Échanges techniques : N'hésitez pas à obtenir des crédits de test via APIYI (apiyi.com) pour comparer par vous-même les différences entre les versions de Claude.