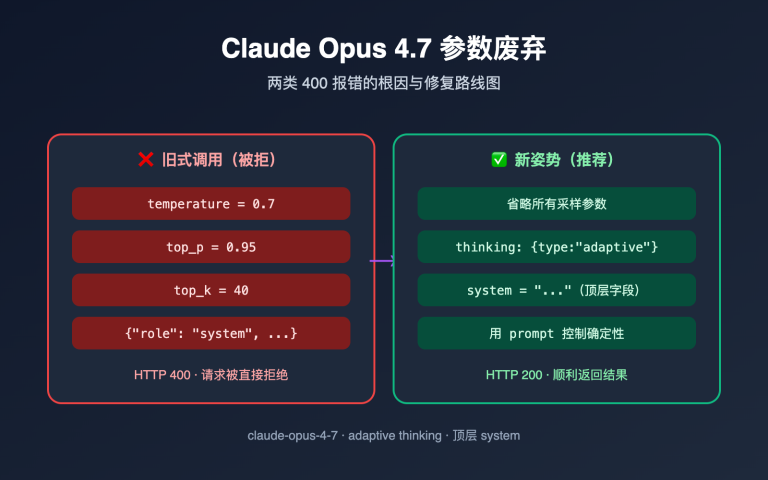
Claude Opus 4.7 于 2026 年 4 月 16 日正式发布,上线第二天社区就出现两极分化的讨论。官方基准声称它在 14 项测试中有 12 项优于 4.6,但大量开发者在 GitHub 和 X 上抱怨它表现不如 4.6,甚至有人将其称为 "伪装成新版本的预改版 4.6"。
本文基于 Anthropic 官方数据、第三方独立测试与社区一手反馈,从编码能力、视觉识别、长上下文、Tokenizer 变化、Task Budgets 等 8 个维度深度评测 Claude Opus 4.7,帮你判断是否值得立刻迁移。
核心价值: 看完本文,你将知道 Claude Opus 4.7 在你的业务场景下究竟是升级还是降级,以及如何规避迁移风险。

Claude Opus 4.7 发布背景与核心信息
Claude Opus 4.7 是 Anthropic 在 2026 年 4 月 16 日推出的旗舰模型,继承了 Opus 4.6 的 $5/$25 每百万 Token 的定价,并在多项基准上创造新纪录。但它同时伴随着 Tokenizer 重构、MRCR 长上下文基准大幅下滑、新 xhigh 推理档位等多项系统性变化,这些变化直接影响了真实业务表现。
Claude Opus 4.7 发布速览
| 信息项 | 详情 |
|---|---|
| 发布日期 | 2026 年 4 月 16 日 |
| 发布方 | Anthropic |
| 输入价格 | $5 / 百万 Token(与 4.6 持平) |
| 输出价格 | $25 / 百万 Token(与 4.6 持平) |
| 上下文窗口 | 1M Token(标准定价) |
| 最大图像分辨率 | 2576px 长边 / 3.75 百万像素 |
| 新增推理档位 | xhigh(介于 high 与 max 之间) |
| 新增实验功能 | Task Budgets(公测中) |
| 可用渠道 | Claude API、Amazon Bedrock、Google Vertex AI、Microsoft Foundry |
🎯 技术建议: 在正式迁移 Claude Opus 4.7 之前,建议通过 API易 apiyi.com 平台同时调用 4.6 和 4.7 进行并行对比测试。该平台提供统一接口,切换模型仅需修改参数,可以快速定位性能差异。
Claude Opus 4.7 核心升级点
Anthropic 官方宣传的升级主要集中在以下四个方向:
- 软件工程能力显著增强:SWE-bench Verified 从 80.8% 提升至 87.6%,SWE-bench Pro 从 53.4% 跃升至 64.3%
- 视觉理解能力跨越式提升:支持 3.75 百万像素的高分辨率图像,视觉基准从 54.5% 提升到 98.5%
- Agentic 工具使用能力强化:MCP-Atlas 基准获得单项最大提升,无工具条件下提升 13 点
- 指令遵循更精准:对模糊指令的处理更稳健,执行更彻底
然而,社区的真实反馈却显示出另一面的故事。
Claude Opus 4.7 核心功能详解
Claude Opus 4.7 的核心功能改动不仅体现在模型能力上,还包括交付层面的重要调整。理解这些变化对正确评估模型表现至关重要。
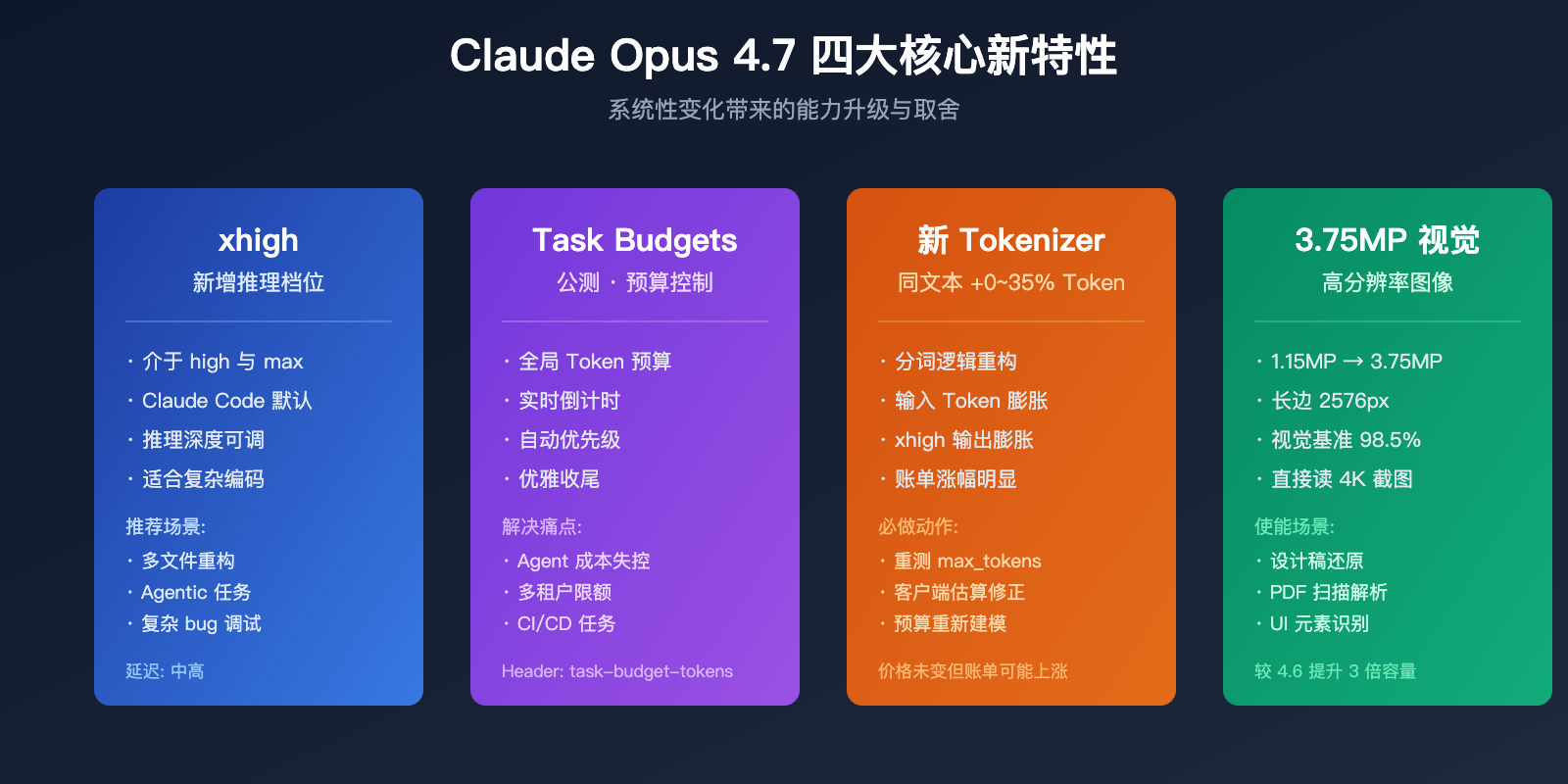
Claude Opus 4.7 的四大系统性变化
| 功能模块 | 4.6 表现 | 4.7 变化 | 业务影响 |
|---|---|---|---|
| Tokenizer | 原版 Token 分词 | 同样文本产出 1.0–1.35× Token | 实际账单可能上涨 35% |
| 推理档位 | low / medium / high / max | 新增 xhigh(Claude Code 默认) | 推理深度与延迟更精细 |
| Task Budgets | 无 | 公测版,全局 Token 预算控制 | Agent 循环成本可控 |
| 视觉输入 | 约 1.15 百万像素 | 约 3.75 百万像素(3×) | 可处理高清截图、图纸 |
| 长上下文 MRCR | 78.3% | 32.2% | 长文档召回大幅下降 |
| SWE-bench Verified | 80.8% | 87.6% | 真实代码任务大幅提升 |
Tokenizer 变化的隐性成本
Claude Opus 4.7 最重要、但最容易被忽视的变化是 Tokenizer 重构。官方文档明确指出:同样的输入文本,在 4.7 上被映射为 4.6 的 1.0 到 1.35 倍 Token 数量。这意味着:
- 你的 Prompt 长度没变,但 Input Token 计费可能多出 35%
- 在 xhigh 或 max 推理档位下,输出 Token 同样可能显著膨胀
- 之前基于 4.6 设定的
max_tokens上限需要全面重测 - 客户端基于字符数估算 Token 的逻辑需要重写
💰 成本优化: 对于 Token 成本敏感的生产环境,在迁移到 Claude Opus 4.7 之前,强烈建议先在 API易 apiyi.com 平台做一轮真实流量的账单对比。该平台支持灵活的计费查询和实时监控,便于量化迁移带来的实际成本增量。
xhigh 推理档位的使用策略
xhigh 是 Opus 4.7 新引入的推理档位,位于 high 和 max 之间。Anthropic 推荐在编码和 Agentic 任务中默认使用 xhigh,这也是 Claude Code 所有套餐的默认档位。
不同推理档位的适用场景:
| 推理档位 | 适用任务 | 延迟 | 推荐使用场景 |
|---|---|---|---|
low |
简单问答、格式转换 | 最低 | 高并发、低复杂度任务 |
medium |
普通代码生成 | 低 | 常规开发辅助 |
high |
复杂代码、技术设计 | 中 | 常规 Agentic 任务 |
xhigh |
困难调试、大规模重构 | 中高 | 推荐:Claude Code 等编码场景 |
max |
极端复杂推理 | 高 | 研究类、非时延敏感任务 |
Task Budgets:Agent 循环成本的终结者
Task Budgets 是 Opus 4.7 引入的公测功能,解决了长期以来 Agent 循环难以控制总 Token 消耗的痛点。工作机制:
- 开发者在启动 Agent 循环前,设定整体 Token 预算
- 模型在每一轮响应中都能看到预算倒计时
- 模型自动根据剩余预算调整思考深度和工具调用次数
- 预算耗尽前,模型会优先完成核心任务并优雅收尾
这个功能配合新的 redact-thinking-2026-02-12 UI 头部,对 Agent 成本治理是一个实质性改进。
Claude Opus 4.7 实测数据全景
这一节是本文的核心。我们汇总了 Anthropic 官方基准、第三方独立评测以及社区复测数据,呈现 Claude Opus 4.7 与 4.6 的真实差距。
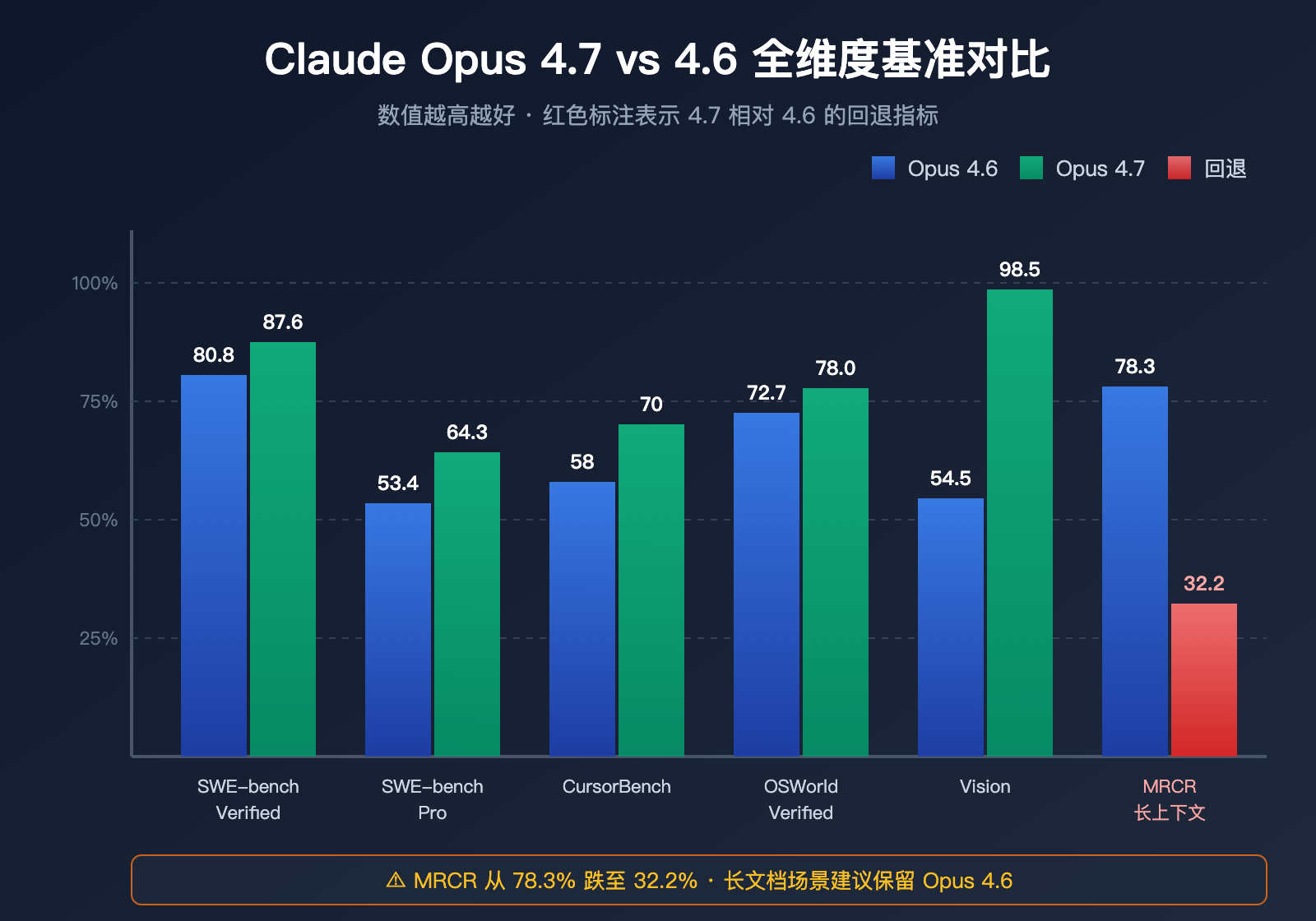
编码能力基准:4.7 全面领先
| 编码基准 | Opus 4.6 | Opus 4.7 | 提升幅度 | 说明 |
|---|---|---|---|---|
| SWE-bench Verified | 80.8% | 87.6% | +6.8pt | 真实 GitHub Issue 修复任务 |
| SWE-bench Pro | 53.4% | 64.3% | +10.9pt | 多语言难度更高变体 |
| CursorBench | 58% | 70% | +12pt | IDE 内真实编码任务 |
| OSWorld-Verified | 72.7% | 78.0% | +5.3pt | 桌面操作与计算机使用 |
| MCP-Atlas(无工具) | — | +13pt | 单项最大提升 | Agentic 工具链任务 |
| MCP-Atlas(有工具) | — | +6pt | 明显提升 | 工具调用精度 |
在编码领域,Claude Opus 4.7 确实是 2026 年 Q2 的最强公开模型,SWE-bench Pro 64.3% 的成绩让它重新夺回 Agentic 编码榜首。
🚀 快速开始: 如果你希望立即体验 Claude Opus 4.7 的编码能力,可通过 API易 apiyi.com 平台直接调用,该平台提供与 Claude 官方 API 完全兼容的接口,支持统一的 OpenAI SDK 格式,迁移成本极低。
视觉与长上下文基准:两极分化
| 基准 | Opus 4.6 | Opus 4.7 | 变化 | 评价 |
|---|---|---|---|---|
| 视觉识别(通用) | 54.5% | 98.5% | +44pt | 接近质变 |
| 最大图像分辨率 | ~1.15 MP | ~3.75 MP | 3× | 可处理 4K 截图 |
| MRCR 长上下文召回 | 78.3% | 32.2% | -46.1pt | 严重倒退 |
MRCR(Multi-Round Context Recall)是评估长上下文检索能力的标准基准。Opus 4.7 在这一指标上从 78.3% 断崖式下跌到 32.2%,这不是一般的波动,而是结构性倒退。
这个数字解释了为什么大量开发者抱怨"喂给模型 800 行工作流文档,它说自己读了,但输出内容跟文档完全无关"。
基准 vs 真实体验:为什么评价两极分化?
基准跑分领先不代表真实业务表现领先。Opus 4.7 在社区中出现大量负面反馈,原因包括:
- Tokenizer 膨胀:同样任务 Token 消耗增加,但能力提升不一定覆盖成本
- 指令遵循过于字面化:4.6 习惯"理解意图",4.7 严格按字面执行,原有 Prompt 可能失效
- MRCR 塌陷:长文档检索能力下降,处理大型代码库、合同文档时问题明显
- Claude Code 误报:部分开发者反馈 4.7 会把正常代码误判为恶意代码并拒绝编辑
💡 选择建议: 选择 Claude Opus 4.7 还是继续使用 4.6 主要取决于你的核心业务场景。我们建议通过 API易 apiyi.com 平台对两个版本并行压测后再做决策,该平台支持多模型统一接口调用,便于快速对比和切换。
Claude Opus 4.7 真实使用体验
基准数据之外,Anthropic 和开发者社区对 Opus 4.7 在实际工作流中的表现给出了截然不同的反馈。
Anthropic 官方立场
Anthropic 在发布公告中强调 Opus 4.7 相对 4.6 的四项核心改进:
- 更强的工程流水线表现:用户可以把以前需要严密监督的"硬活"放心交给 4.7
- 更好的模糊问题处理能力:对于定义不清的需求更稳健
- 更彻底的问题解决:不会半途而废
- 更精准的指令遵循:对细节要求严格
Claude Code 负责人 Boris Cherny 在发布后公开表示,Opus 4.7 比 4.6 "更智能、更具 Agentic 能力、更精确",但承认需要几天时间适应,才能充分发挥其新能力。
开发者社区的真实反馈
在 GitHub、Hacker News、X 等平台上,开发者的反馈则明显负面:
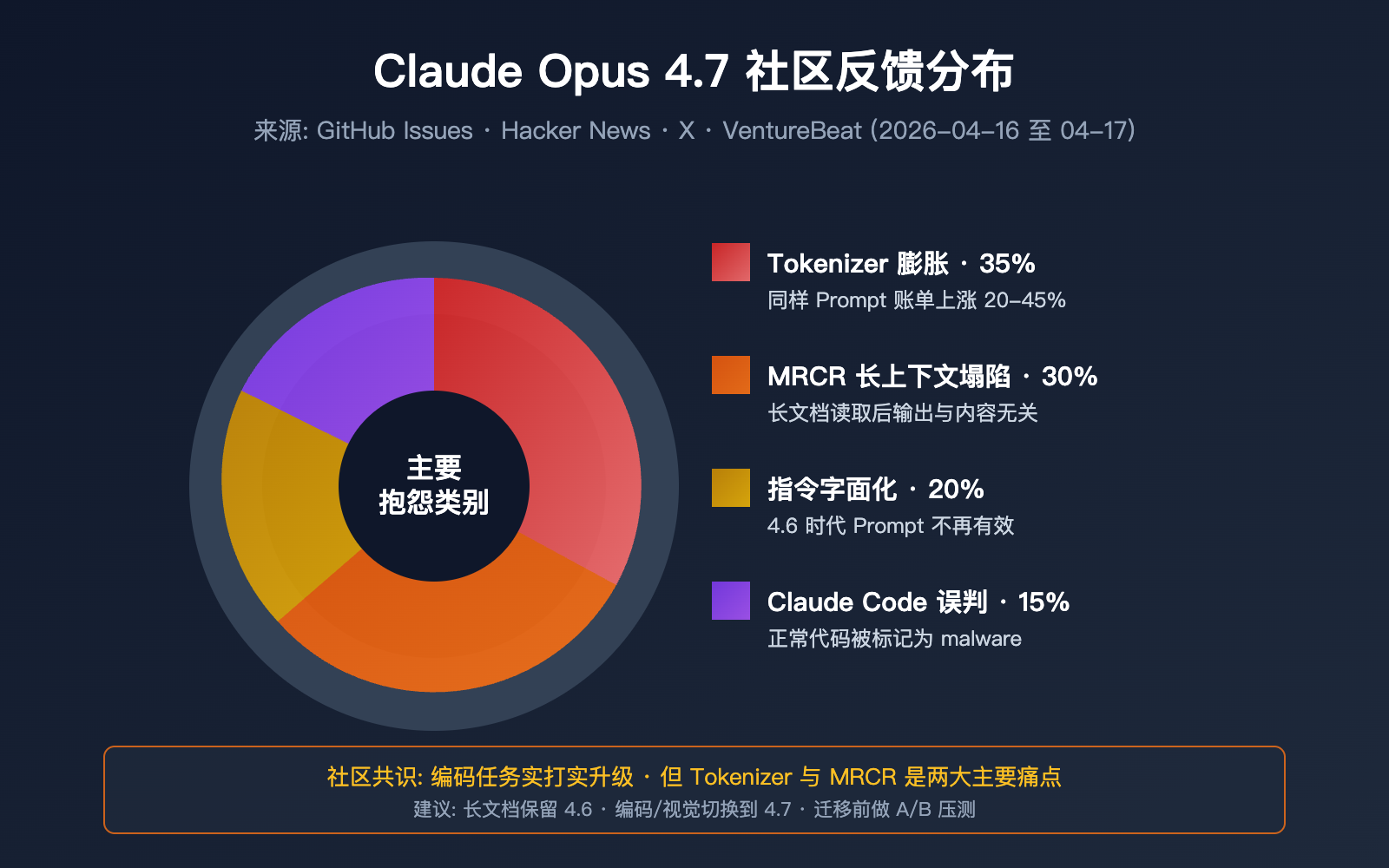
抱怨 1:Token 消耗飞涨
由于新 Tokenizer,同样的输入在 Opus 4.7 上会被分解为更多 Token。加上 xhigh 档位下输出 Token 增加,部分用户反馈账单涨幅高达 40%。这被戏称为 "AI Shrinkflation"(AI 缩水通胀)。
抱怨 2:长文档处理灾难
多位开发者报告:向 Opus 4.7 输入长文档后,模型声称已读,但生成内容与文档实质无关。这与 MRCR 从 78.3% 跌至 32.2% 高度吻合。
抱怨 3:Claude Code 误判代码为恶意
Issue #47483 中多位工程师反馈:Claude Opus 4.7 会把一段正常的文件读写代码标记为 malware,拒绝完成基础的编辑请求。
抱怨 4:Prompt 兼容性下降
在 4.6 上运行良好的 Prompt,迁移到 4.7 后输出质量反而下降。原因是 4.7 严格按字面执行指令,而 4.6 会自动"读出弦外之音"。
Claude Opus 4.7 真实场景分场景评分
基于实测数据与社区反馈,对 Opus 4.7 在不同场景下的表现进行打分:
| 使用场景 | Opus 4.6 评分 | Opus 4.7 评分 | 变化 | 建议 |
|---|---|---|---|---|
| 中短文件代码重构 | 8/10 | 9/10 | ↑ | 立即迁移 |
| 复杂 Agentic 工作流 | 7.5/10 | 9/10 | ↑ | 立即迁移 |
| 大型仓库代码审查 | 8/10 | 6.5/10 | ↓ | 继续使用 4.6 |
| 长文档摘要与问答 | 8.5/10 | 5/10 | ↓↓ | 继续使用 4.6 |
| 高清图像理解 | 6.5/10 | 9.5/10 | ↑↑ | 立即迁移 |
| 常规对话与写作 | 9/10 | 9/10 | → | 任选 |
| 成本敏感型生产 | 9/10 | 7/10 | ↓ | 继续使用 4.6 |
| 原型开发与实验 | 8/10 | 8.5/10 | ↑ | 迁移 |
Claude Opus 4.7 优缺点深度分析
在完成数据与体验对比后,我们可以给出更清晰的优缺点总结。
Claude Opus 4.7 的四大核心优势
优势 1:真实编码能力显著提升
SWE-bench Verified 87.6% 和 SWE-bench Pro 64.3% 不是跑分游戏,而是实打实的真实 GitHub Issue 修复任务。这意味着 Opus 4.7 在处理中小型代码任务时,确实能替代更多人力。
优势 2:视觉理解实现质变
高分辨率图像输入(3.75 百万像素)让 Opus 4.7 可以直接处理 4K 截图、设计图、PDF 扫描件等高密度视觉内容。这是 Claude 系列的重大突破。
优势 3:Task Budgets 解决 Agent 成本治理
长期以来,Agent 循环中 Token 消耗失控是企业落地的主要阻力。Task Budgets 让开发者第一次有了精细的全局预算控制能力。
优势 4:xhigh 档位提供更精细的推理/延迟平衡
在 high 和 max 之间多了一档选择,意味着开发者可以在同一场景下根据 SLA 需求灵活调整。
Claude Opus 4.7 的四大主要局限
局限 1:Tokenizer 膨胀导致实际成本上涨
即使单价不变,35% 的 Token 膨胀加上 xhigh 档位的输出扩张,实际账单可能比 4.6 高出 20–45%。
应对方案:迁移前使用 Token 计数接口重测所有代码路径。
局限 2:MRCR 长上下文召回能力塌陷
这是最致命的问题。处理长文档、大代码库、长对话时,Opus 4.7 召回准确率断崖式下降。
应对方案:长文档场景继续使用 Opus 4.6,或改用 RAG + 分块策略。
局限 3:指令遵循过于字面
原有 Prompt 可能出现意料之外的输出变化。
应对方案:系统化重写 Prompt,去除隐含意图,改用显式约束。
局限 4:部分场景误判与幻觉增加
Claude Code 误判代码、长文档幻觉等问题社区广泛反馈。
应对方案:核心任务配合人工审核,关键逻辑使用多模型交叉验证。
🎯 迁移建议: 如果你的业务同时涉及短任务编码和长文档处理,推荐通过 API易 apiyi.com 平台按场景路由不同 Claude 版本。该平台支持多模型统一调用,可在同一项目中灵活搭配 Opus 4.6(长上下文)与 4.7(编码/视觉),避免"一刀切"迁移带来的性能回退。
Claude Opus 4.7 API 调用实战
理论分析之外,我们给出实际可运行的代码示例,帮助你快速上手 Claude Opus 4.7。
极简示例(OpenAI SDK 兼容)
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=[
{"role": "user", "content": "请用 Python 写一个并发爬虫示例"}
],
temperature=0.7,
max_tokens=4096
)
print(response.choices[0].message.content)
查看完整代码(含 xhigh 推理档位、Task Budgets 和错误处理)
import openai
import time
from typing import Optional
class ClaudeOpusClient:
"""Claude Opus 4.7 完整调用封装"""
def __init__(self, api_key: str, base_url: str = "https://api.apiyi.com/v1"):
self.client = openai.OpenAI(
api_key=api_key,
base_url=base_url
)
def generate(
self,
prompt: str,
model: str = "claude-opus-4-7",
effort: str = "xhigh",
task_budget: Optional[int] = None,
max_retries: int = 3
) -> str:
"""调用 Claude Opus 4.7 并支持新特性"""
extra_headers = {}
if task_budget:
extra_headers["task-budget-tokens"] = str(task_budget)
if effort:
extra_headers["reasoning-effort"] = effort
for attempt in range(max_retries):
try:
response = self.client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
max_tokens=8192,
extra_headers=extra_headers,
timeout=120
)
return response.choices[0].message.content
except openai.RateLimitError:
wait = 2 ** attempt
print(f"速率限制,等待 {wait}s...")
time.sleep(wait)
except openai.APIError as e:
print(f"API 错误: {e}")
if attempt == max_retries - 1:
raise
time.sleep(1)
raise RuntimeError("Max retries exceeded")
def compare_versions(self, prompt: str) -> dict:
"""同时调用 4.6 和 4.7 进行对比"""
results = {}
for model in ["claude-opus-4-6", "claude-opus-4-7"]:
start = time.time()
results[model] = {
"output": self.generate(prompt, model=model),
"latency": time.time() - start
}
return results
if __name__ == "__main__":
client = ClaudeOpusClient(api_key="YOUR_API_KEY")
result = client.generate(
prompt="重构这段 Python 代码,使其支持异步并发",
effort="xhigh",
task_budget=50000
)
print(result)
🚀 快速开始: 上述代码中的
base_url指向 API易 apiyi.com 平台。该平台提供与 Claude 官方完全兼容的接口格式,同时支持 Claude Opus 4.7 与 4.6 的并行调用,便于在迁移期进行 A/B 测试。
关键迁移检查清单
从 Opus 4.6 迁移到 4.7 的必做步骤:
# 1. 重测 max_tokens 上限(Tokenizer 变化)
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
# 对核心 Prompt 用两个模型分别调用,记录实际 Token 消耗
for model in ["claude-opus-4-6", "claude-opus-4-7"]:
resp = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": YOUR_PROMPT}],
max_tokens=4096
)
print(f"{model}: input={resp.usage.prompt_tokens}, output={resp.usage.completion_tokens}")
# 2. 重测长文档场景(MRCR 塌陷)
# 建议把长文档任务保留在 4.6 上,或改用 RAG 分块
# 3. 审计 Prompt 隐含意图
# 4.7 严格字面执行,需要把"读懂意图"改为显式约束
Claude Opus 4.7 常见问题 FAQ
Q1: Claude Opus 4.7 真的比 4.6 更好吗?
分场景讨论:
- 中短编码任务:4.7 明显更好(SWE-bench Verified +6.8pt,CursorBench +12pt)
- 高清视觉任务:4.7 远超 4.6(视觉基准从 54.5% 到 98.5%)
- Agentic 工具链:4.7 更强(MCP-Atlas 提升 13pt)
- 长上下文检索:4.6 明显更好(MRCR 78.3% vs 32.2%)
- 成本敏感型:4.6 更优(4.7 Token 膨胀可达 35%)
如果你需要跨场景并行调用两个版本,推荐通过 API易 apiyi.com 平台按业务路由选择合适版本,该平台支持一套 API Key 调用全部 Claude 系列模型。
Q2: 为什么有人说 Claude Opus 4.7 不如 4.6?
主要原因有四个:
- Tokenizer 重构:同样任务 Token 消耗最多增加 35%,但能力提升未必能抵消成本
- MRCR 长上下文断崖:从 78.3% 跌至 32.2%,长文档处理严重退步
- 指令遵循过于字面:4.6 时代"读出意图"的 Prompt 在 4.7 上容易失效
- Claude Code 偶发误判:部分开发者反馈正常代码被标记为恶意
这些不是错觉,而是结构性变化带来的真实体验差异。
Q3: 如何安全地从 Opus 4.6 迁移到 4.7?
三步迁移法:
- 并行压测:在生产流量 5–10% 上同时调用 4.6 和 4.7,对比输出质量、延迟、成本
- 按场景路由:长文档、大代码库继续用 4.6;中短编码、视觉任务切到 4.7
- 逐步放量:从 10% → 30% → 50% → 100%,每一档观察 3–7 天
推荐使用 API易 apiyi.com 平台进行此类迁移测试,该平台支持灵活的模型路由和流量分配。
Q4: Claude Opus 4.7 的 xhigh 档位应该什么时候用?
Anthropic 官方推荐在编码和 Agentic 任务中默认使用 xhigh。适用场景:
- 复杂代码重构
- 多文件 bug 调试
- 大规模单元测试生成
- Agentic 多步工具链任务
不适用场景:
- 简单问答(用 medium 即可)
- 高并发请求(xhigh 延迟较高)
- 成本敏感型任务(xhigh 输出 Token 显著增加)
Q5: Task Budgets 怎么用?适合什么场景?
Task Budgets 是公测功能,通过 HTTP Header 传递:
task-budget-tokens: 50000
适用场景:
- 长周期 Agent 循环(需要控制总成本)
- 多租户 SaaS(给每个用户限制预算)
- CI/CD 自动化任务(设定每个 Job 的 Token 上限)
模型会根据剩余预算自动调整思考深度,在预算耗尽前优雅收尾,避免中途失败。
Q6: Claude Opus 4.7 的视觉能力真的有那么强吗?
是的,且这是 4.7 最显著的升级之一:
- 最大分辨率:从 1.15 百万像素提升到 3.75 百万像素(3×)
- 视觉基准:从 54.5% 跃升到 98.5%
- 实用能力:可以直接读懂 4K 截图、架构图、UI 设计稿、PDF 扫描件
对做前端开发、设计稿还原、文档数字化的团队来说,这是一个可以改变工作流的升级。
Claude Opus 4.7 适合谁?决策建议
基于全文分析,我们给出明确的使用建议:
立即迁移到 Claude Opus 4.7 的场景
- ✅ 中短文件编码与重构:SWE-bench 与 CursorBench 数据说明一切
- ✅ 复杂 Agentic 工作流:MCP-Atlas 和 Task Budgets 的双重加持
- ✅ 高清图像处理:3.75 MP 的视觉能力是质变
- ✅ 原型快速开发:xhigh 档位对中等复杂度任务表现出色
继续使用 Claude Opus 4.6 的场景
- 🔒 长文档摘要与问答:MRCR 塌陷不可回避
- 🔒 大型仓库级代码审查:长上下文召回能力更稳定
- 🔒 Token 成本极度敏感:4.6 Tokenizer 更经济
- 🔒 已跑通的稳定生产:不建议为了追新而引入回归风险
混合使用的推荐策略
对大多数团队来说,按场景路由比"全部迁移"更实用:
- 长文档相关 → Opus 4.6
- 编码/视觉/Agent → Opus 4.7
- 通过统一网关管理两个版本,降低迁移风险
💡 最终建议: 选择 Claude Opus 4.7 还是继续使用 4.6 主要取决于您的具体应用场景。我们建议通过 API易 apiyi.com 平台进行实际对比测试。该平台支持多种主流模型的统一接口调用,便于快速对比和切换,让你在迁移过程中保持业务灵活性。
总结
Claude Opus 4.7 是一款典型的"取舍型升级":它在编码、视觉、Agentic 能力上实现了真正的跨越,但在长上下文召回、Token 效率、Prompt 兼容性上付出了明显代价。
上线首日的社区议论并非空穴来风——Opus 4.7 既是强大的新模型,也是一次有代价的架构调整。对于开发者来说,关键不是"是否迁移",而是"在哪些场景下迁移"。
- 如果你在做复杂代码任务或高清视觉分析,4.7 是 2026 年 Q2 的最佳选择
- 如果你的核心业务是长文档处理或成本敏感型推理,暂时保留 4.6
- 在迁移过程中,强烈建议并行压测,避免"一刀切"带来的隐性回退
推荐通过 API易 apiyi.com 平台快速体验 Claude Opus 4.7 与 4.6,该平台提供统一接口、实时账单监控、多模型路由能力,是迁移测试与生产落地的理想选择。
参考资料
-
Anthropic 官方发布公告:Claude Opus 4.7 正式介绍
- 链接:
anthropic.com/news/claude-opus-4-7 - 说明: 官方核心能力与定价说明
- 链接:
-
Claude API 官方文档:Claude Opus 4.7 迁移指南
- 链接:
platform.claude.com/docs/en/about-claude/models/migration-guide - 说明: 官方迁移建议与 Tokenizer 变化说明
- 链接:
-
AWS Bedrock 发布博客:Claude Opus 4.7 在 Amazon Bedrock 上线
- 链接:
aws.amazon.com/blogs/aws/introducing-anthropics-claude-opus-4-7-model-in-amazon-bedrock - 说明: 第三方云平台部署说明
- 链接:
-
Vellum AI 基准分析:Claude Opus 4.7 基准深度解读
- 链接:
vellum.ai/blog/claude-opus-4-7-benchmarks-explained - 说明: 第三方独立基准评估
- 链接:
-
GitHub Issue #47483:Claude Opus 社区回归反馈
- 链接:
github.com/anthropics/claude-code/issues/47483 - 说明: 开发者一手体验反馈
- 链接:
作者: APIYI 技术团队
发布日期: 2026-04-17
适用模型: Claude Opus 4.7 / Claude Opus 4.6
技术交流: 欢迎通过 API易 apiyi.com 获取测试额度,亲测对比 Claude 各版本差异