최근 OpenAI 공식 Cookbook이 Fractional AI와 협력하여 매우 수준 높은 실전 사례를 공개했습니다. 바로 'AI를 활용한 영수증 자동 심사'입니다. 처음 들으면 단순한 OCR 작업처럼 보이지만, 노트북을 열어보면 이 프로젝트가 단순한 데모를 넘어 AI 애플리케이션을 실제 프로덕션 환경으로 끌어올리기 위한 '방법론의 성경'임을 알 수 있습니다. 특히 현재 업계에서 가장 뜨거운 주제인 **Eval-Driven System Design(평가 기반 시스템 설계)**의 가장 완벽한 오픈소스 예제이기도 합니다.
더 흥미로운 점은 이 방법론이 기술적인 문제를 넘어, 모든 AI 엔지니어를 괴롭히는 근본적인 질문을 해결한다는 것입니다. "내가 수정한 프롬프트가 정말로 좋아진 것일까, 아니면 그냥 좋아 보이는 것일까?" 이 글에서는 OpenAI의 영수증 심사 사례를 통해 모든 AI 애플리케이션 개발자에게 영감을 줄 5가지 엔지니어링 경험을 알기 쉽게 풀어보겠습니다.
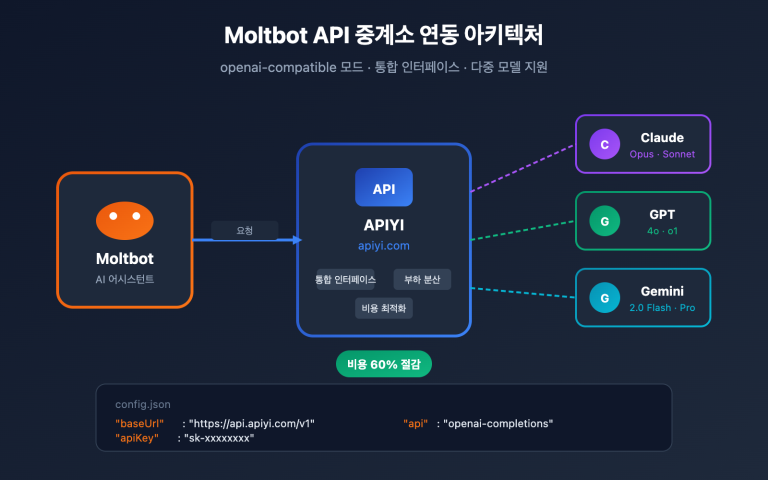
🎯 빠른 가이드: 이 사례는 cookbook.openai.com의 eval_driven_system_design 디렉토리에서 확인할 수 있으며, Fractional AI 팀(Hugh Wimberly, Joshua Marker, Eddie Siegel)과 OpenAI의 Shikhar Kwatra가 공동 작성했습니다. 전체 코드는 OpenAI 공식 Cookbook 저장소에 있으며, APIYI(apiyi.com)와 같은 OpenAI 공식 중계 서비스를 사용하면 코드 수정 없이 전체 프로세스를 그대로 재현할 수 있어 국내 개발자가 학습하기에 최적입니다.
OpenAI 영수증 심사 사례의 비즈니스 배경: 왜 이것이 진짜 문제인가?
기술적인 내용을 다루기 전에, 이 사례의 비즈니스 배경부터 명확히 짚고 넘어가겠습니다. 이는 단순히 API를 보여주기 위해 만든 장난감 같은 문제가 아니라, 명확한 ROI(투자 대비 수익) 수치가 존재하는 매우 현실적인 기업용 시나리오입니다.
| 비즈니스 항목 | 수치 | 의미 |
|---|---|---|
| 연간 처리량 | 약 100만 장 | 중견 기업의 전형적인 규모 |
| AI 장당 처리 비용 | $0.20 | 모델 호출 비용 |
| 인건비(수동 심사) | $2.00 | 재무 담당자의 검토 비용 |
| 심사 누락 과태료 | $30 / 건 | 규정 준수/세무 처벌 |
| 현재 수동 심사율 | 5% | 난도가 높은 영수증 위주 |
이 수치들을 곱해보면, 심사 정확도를 단 1%만 높여도 100만 장 규모에서는 수십만 달러의 연간 수익이 발생한다는 것을 알 수 있습니다. 이것이 바로 Fractional AI 팀이 강조하는 "평가 지표를 달러 가치와 연결(Dollar Impact)"하는 이유입니다. 단순히 지표를 올리는 것이 아니라, 프롬프트의 모든 변경 사항이 실제 비즈니스 장부와 연결되도록 하는 것입니다.
전체 AI 시스템의 목표는 매우 명확합니다. GPT-4o를 사용하여 대부분의 영수증을 자동으로 심사하고, '낮은 신뢰도'의 영수증만 사람에게 전달하여 심사 비용과 누락 위험을 모두 낮추는 것입니다. 말은 쉽지만, 악마는 디테일에 숨어 있습니다.
Eval-Driven Design이란 무엇인가: 뼈아픈 경험으로 얻은 방법론
만약 100명의 AI 엔지니어에게 "프롬프트가 잘 수정되었는지 어떻게 검증하나요?"라고 묻는다면, 99명은 "몇 가지 예시를 돌려보고 느낌이 괜찮은지 확인해요"라고 답할 것입니다. Fractional AI 팀이 비판하는 **vibe-coding(감으로 코딩하기)**이 바로 이것이며, Eval-Driven Design(이하 EDD)이 완전히 대체하고자 하는 개발 방식입니다.
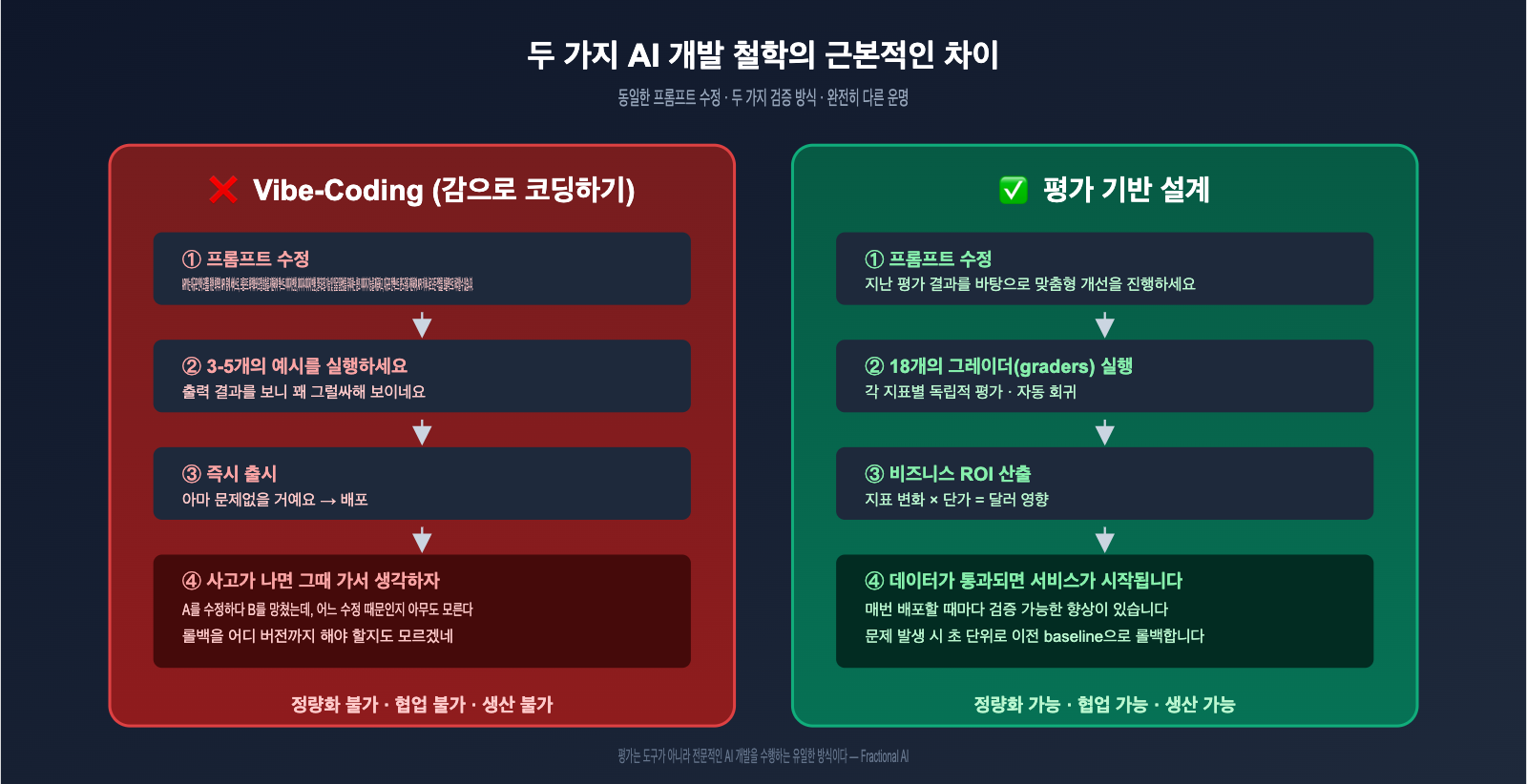
두 개발 방식의 차이는 아래 표와 같습니다:
| 비교 항목 | Vibe-Coding (감으로 조정) | Eval-Driven Design (평가 기반) |
|---|---|---|
| 검증 방식 | 3~5개 예시 출력 확인 | 20~100개 이상의 샘플로 지표 계산 |
| 수정 판단 | "왠지 좋아진 것 같음" | "정확도 78% → 85% 향상" |
| 비즈니스 정렬 | 감에 의존 | 달러 단위의 비즈니스 영향으로 환산 |
| 회귀 위험 | A 수정 시 B가 망가져도 모름 | 전체 지표 자동 테스트 수행 |
| 협업 확장성 | 작성자만 이해 가능 | 모든 엔지니어가 디버깅 가능 |
Fractional AI의 글에는 이런 유명한 문구가 있습니다: "평가는 도구가 아니라, 전문적인 AI 개발을 위한 유일한 방법이다." 이 말이 과장처럼 들릴 수 있지만, 영수증 검토와 같은 비즈니스 핵심 시나리오에서 평가(evals)가 없다면 프로덕션 환경에서 도박을 하는 것과 다름없으며, 누구도 안심하고 배포할 수 없습니다.
💡 비유: Eval-Driven Design은 표준 답안이 있는 시험과 같습니다. 수정할 때마다 '총점'이 얼마나 올랐는지 계산할 수 있죠. 반면 Vibe-Coding은 감으로 문제를 푸는 것과 같아서, 수정한 뒤에 좋아졌는지 나빠졌는지 알 수 없습니다. 프로덕션급 AI는 반드시 전자여야 합니다.
OpenAI 영수증 검토 사례의 3단계 구현 프로세스
OpenAI Cookbook은 전체 사례를 3단계로 명확히 나누었습니다. 이 프로세스는 '이미지/문서 입력 + 구조화된 의사결정 출력'이 필요한 모든 AI 애플리케이션에 적용할 수 있습니다.
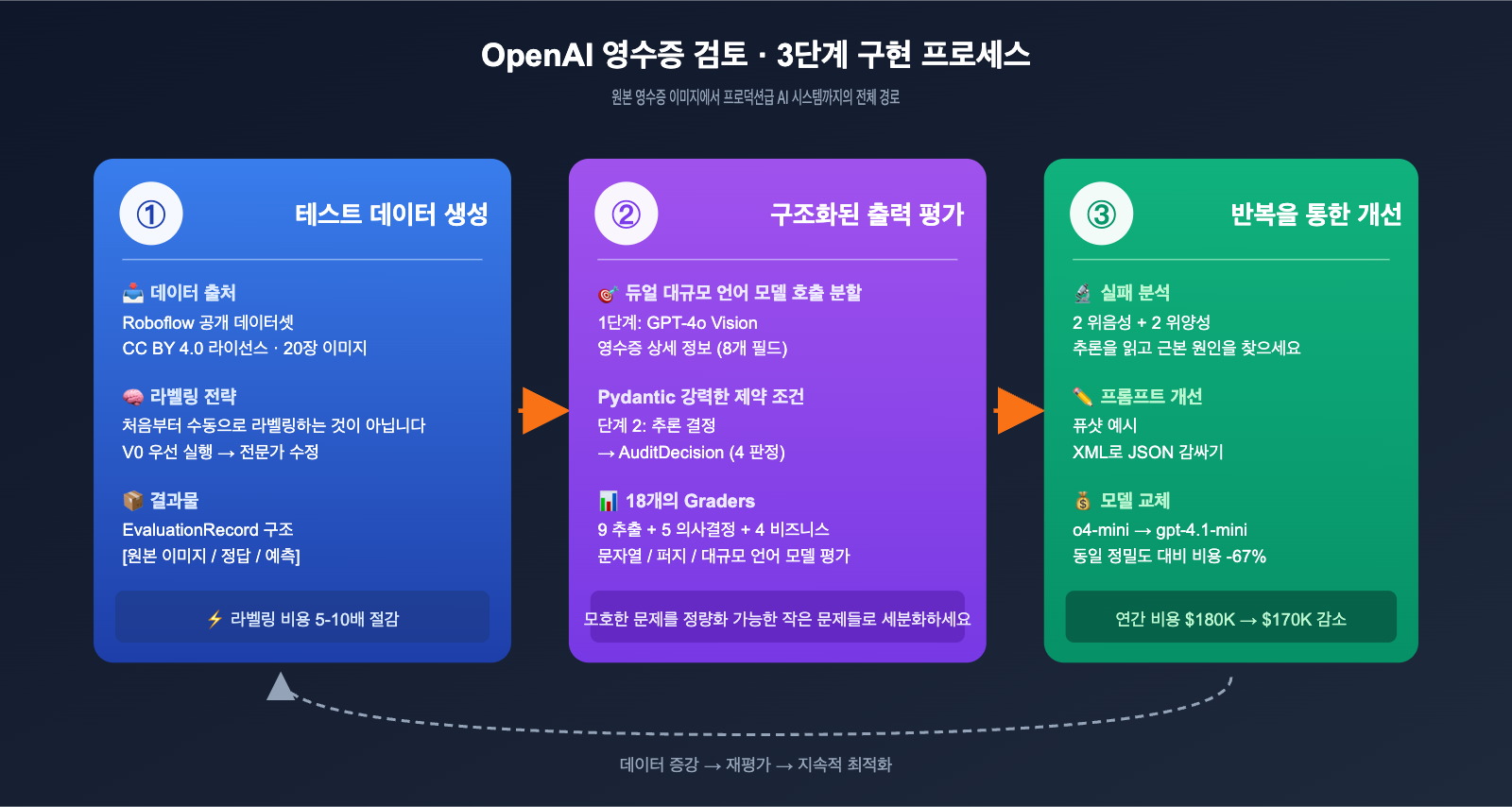
각 단계를 알기 쉽게 설명해 드리겠습니다.
1단계: 테스트 데이터 생성, 라벨링 비용 80% 절감하기
팀이 처음부터 수천 장의 영수증 이미지를 수작업으로 라벨링한다고 생각했다면, 엔지니어의 '효율성 추구'를 너무 과소평가한 것입니다. Fractional AI는 아주 영리한 전략을 사용했습니다. V0 모델로 먼저 돌리고, 전문가가 수정하는 방식입니다.
구체적인 프로세스는 이렇습니다. Roboflow 공개 데이터셋에서 영수증 이미지 20장을 가져와 간단한 GPT-4o + Pydantic 추출 파이프라인에 넣어 V0 출력을 얻습니다. 그다음 재무 전문가가 이 결과물을 바탕으로 '오류 수정'만 수행합니다. 처음부터 일일이 입력하는 것보다 훨씬 빠르죠. 이 방식은 전문가의 시간 효율을 5~10배 높여줍니다.
🔧 재사용 팁: 이 'V0 선실행 → 전문가 수정' 라벨링 전략은 모든 AI 애플리케이션의 초기 단계에 적용할 수 있습니다. APIYI와 같은 OpenAI API 중계 서비스를 통해 빠르게 V0 출력을 뽑아내고, 전문가의 에너지를 가장 중요한 판단 작업에 집중시키세요.
2단계: 구조화된 출력 평가, Pydantic은 진정한 영웅
전체 AI 시스템은 두 번의 LLM 호출로 구성됩니다. 이러한 책임 분리(Separation of Concerns) 설계는 EDD의 핵심입니다.
async def extract_receipt_details(
image_path: str, model: str = "o4-mini"
) -> ReceiptDetails:
"""1단계: 이미지에서 구조화된 영수증 정보 추출"""
response = await client.responses.parse(
model=model,
input=[{"role": "user", "content": [
{"type": "input_text", "text": prompt},
{"type": "input_image", "image_url": data_url}
]}],
text_format=ReceiptDetails # Pydantic 모델로 강력한 제약
)
return response.output_parsed
async def evaluate_receipt_for_audit(
receipt_details: ReceiptDetails, model: str = "o4-mini"
) -> AuditDecision:
"""2단계: 구조화된 데이터를 기반으로 감사 결정"""
# ... LLM을 호출하여 AuditDecision Pydantic 모델 출력
왜 두 단계로 나눌까요? 두 작업의 요구 능력이 완전히 다르기 때문입니다. **1단계는 '이미지 읽기 및 정보 추출(Vision)', 2단계는 '논리적 판단(Reasoning)'**입니다. 이를 하나의 프롬프트에 섞으면 모델이 작업 경계를 혼동하기 쉽고, 디버깅도 어려워집니다.
| 모델 | 주요 필드 | 비즈니스 의미 |
|---|---|---|
| ReceiptDetails | merchant / location / time / items / subtotal / tax / total / handwritten_notes | 영수증의 모든 정보 |
| AuditDecision | not_travel_related / amount_over_limit / math_error / handwritten_x / reasoning / needs_audit | 감사 4대 항목 + 추론 과정 + 최종 결론 |
특히 reasoning 필드는 모델이 최종 결정을 내리기 전에 추론 과정을 작성하도록 강제하는데, 이는 나중에 Chain-of-Thought 평가를 수행하는 데 핵심이 됩니다.
🚀 연동 팁: 위 코드의
client.responses.parse()는 OpenAI의 최신 구조화된 출력 인터페이스로, Pydantic 모델을 직접 출력 형식으로 지정할 수 있어 JSON 파싱 오류를 거의 제거합니다. SDK 버전 요구사항이 있으므로, 프로토콜이 항상 최신으로 유지되는 APIYI 같은 API 중계 서비스를 이용하는 것을 추천합니다.
3단계: 반복적인 정교화, 18개의 Grader로 수치화된 개선
이 단계가 EDD가 빛을 발하는 순간입니다. Fractional AI 팀은 18개의 독립적인 평가 지표(grader)를 설정하여 '시스템이 좋은가?'라는 모호한 질문을 18개의 정량화 가능한 작은 문제로 분해했습니다.
이 18개의 grader는 크게 세 가지 유형으로 나뉩니다:
| Grader 유형 | 대표 지표 | 평가 방식 |
|---|---|---|
| 추출 정확도 (9개) | 상점명 / 주소 / 총액 일치 | 문자열 정확/유사 일치 |
| 감사 결정 정확도 (5개) | 출장 관련 / 한도 초과 / 계산 오류 등 | 이진 분류 정확도 |
| 비즈니스 정렬 지표 (4개) | 상품 누락 / 상품 초과 / 추론 품질 | LLM-as-Judge (0~10점) |
초기 평가에서 20개의 샘플 중 4개의 오류가 발견되었습니다. 연간 100만 건의 거래 규모라면 수천 건의 누락이 발생한다는 뜻입니다. 팀은 이를 매우 엔지니어링적인 방식으로 해결했습니다:
- 근본 원인 분석: 오류 사례의
reasoning필드를 보고 모델이 어디서 막혔는지 파악 - 프롬프트 수정: Few-shot 예시 추가, 정의 명확화, JSON 예시를 XML로 감싸기 등
- 재평가: 수정 사항이 새로운 버그를 유발하지 않았는지 검증
- 모델 교체 실험: 동일 프롬프트로 o4-mini와 gpt-4.1-mini를 비교하여 ROI가 높은 모델 선택
결과는 놀라웠습니다. o4-mini에서 gpt-4.1-mini로 전환하여 정확도는 거의 유지하면서 비용을 67% 절감했습니다. 완벽한 평가 데이터셋이 없었다면 누가 이런 비용 절감 결정을 내릴 수 있었을까요?
📊 핵심 통찰: 18개의 grader는 단순히 숫자를 채우기 위한 것이 아니라, 'AI가 정확한가?'라는 거대한 질문을 독립적으로 측정하고 수정 가능한 작은 단위로 쪼갠 것입니다. APIYI에서 OpenAI Evals API를 활용하면 이와 유사한 grader 체계를 구축할 수 있으며, 공식 인터페이스와 완벽하게 호환됩니다.
OpenAI 영수증 검토 사례에서 얻는 5가지 엔지니어링 교훈
전체 사례를 읽고 나서, 모든 AI 애플리케이션에 공통으로 적용할 수 있는 5가지 교훈을 정리해 보았습니다. 이는 실제 비용을 지불하며 얻은 값진 경험들입니다.
교훈 1: 평가 지표를 달러(비용)와 연결하세요. 모든 지표를 100%로 만들려 하지 마세요.
사례에는 매우 반직관적인 발견이 하나 있습니다. 상점 이름 인식 정확도가 높아져도 최종 검토 결정에는 거의 영향을 주지 않는다는 점입니다. 검토 규칙이 상점 이름에 의존하지 않기 때문이죠. 만약 팀이 상점 이름 인식률을 92%에서 98%로 올리는 데 집착한다면, 이는 엔지니어링 자원을 낭비하는 것입니다.
반대로, 수기로 작성된 "X" 표시를 잘못 인식하여 발생하는 누락 검토 손실은 연간 약 75,000달러에 달하며, 이것이야말로 최우선으로 해결해야 할 지표입니다. 따라서 지표를 선택할 때는 항상 스스로에게 물어봐야 합니다. "이 오류를 수정하면 비용을 얼마나 절감할 수 있는가?"
교훈 2: 가장 강력한 모델로 먼저 성공시키고, 그 다음에 비용 절감을 고려하세요.
사례의 V0 단계에서 당시 가장 강력했던 모델인 o4-mini를 선택한 이유는 팀이 비용을 신경 쓰지 않아서가 아닙니다. 능력이 부족한 모델을 억지로 작동시키는 것이, 성능이 넘치는 모델을 저렴하게 작동시키는 것보다 훨씬 어렵다는 사실을 알고 있었기 때문입니다. 비즈니스 로직을 먼저 성공시키고 완전한 평가 체계를 구축한 뒤, 모델 교체 실험을 진행하는 순서는 절대 바뀌어서는 안 됩니다.
교훈 3: 데이터 추출과 의사결정은 반드시 분리하세요. 만능 프롬프트를 만들려는 욕심은 버리세요.
많은 초보자가 "한 번의 호출로 이미지에서 바로 '검토 필요 여부'를 결론 내리면 비용이 절약되지 않을까?"라고 생각합니다. 하지만 이런 설계에는 두 가지 치명적인 결함이 있습니다. 디버깅이 불가능하다는 점(오류 발생 시 이미지 인식 문제인지 로직 판단 문제인지 알 수 없음), 그리고 재사용이 불가능하다는 점(추출 결과가 이 결정에만 사용됨)입니다. 두 단계로 나누면 API 호출을 한 번 더 하는 것처럼 보이지만, 실제로는 시스템 전체의 유지보수성을 한 차원 높여줍니다.
교훈 4: Chain-of-Thought 평가는 "정답이지만 이유는 틀린" 위험을 잡아냅니다.
AuditDecision에 포함된 다소 중복되어 보이는 reasoning 필드는 평가 과정에서 매우 중요한 역할을 합니다. 모델이 최종 정답은 맞혔지만 추론 과정이 틀린 위험한 상황을 식별해 내기 때문입니다. 이러한 "운에 의한 정답"은 소규모 샘플에서는 드러나지 않지만, 데이터 분포가 조금만 바뀌어도 대규모 오류로 이어집니다. 추론 과정을 강제로 출력하게 하고 LLM-as-Judge를 통해 추론 품질을 평가하는 것은 생산급 AI 애플리케이션의 필수 보험입니다.
교훈 5: 라벨링 비용은 엔지니어링으로 낮출 수 있습니다.
"AI 프로젝트에는 방대한 라벨링 데이터가 필요하다"는 고정관념에 겁먹지 마세요. 20개의 샘플과 전문가가 수정한 V0 출력물만으로도 유용한 평가 세트를 구성할 수 있습니다. 핵심은 평가 세트가 실제 비즈니스 데이터 분포와 일치하도록 만드는 것이지, 샘플의 양을 늘리는 것이 아닙니다. Fractional의 경험에 따르면 초기 V0 출력을 "시드 라벨링"으로 활용하는 것이 처음부터 수동으로 라벨링하는 것보다 효율이 5~10배 높았습니다.
국내에서 OpenAI 영수증 검토 사례를 재현할 때 주의사항
국내 개발자가 이 쿡북을 재현하려면 세 가지 문제를 해결해야 합니다. o4-mini / gpt-4.1-mini 같은 최신 모델을 호출할 수 있는가, 최신 인터페이스인 responses.parse를 사용할 수 있는가, 그리고 Evals API 엔드포인트를 호출할 수 있는가입니다.
국내에서 OpenAI에 직접 연결하는 것은 매우 불안정합니다. 특히 이미지 관련 인터페이스는 페이로드가 크기 때문에 텍스트 인터페이스보다 실패율이 훨씬 높습니다. APIYI와 같은 API 중계 서비스를 사용하면 base_url 한 줄만 수정하여 이 세 가지 문제를 한 번에 해결할 수 있습니다.
from openai import AsyncOpenAI
client = AsyncOpenAI(
base_url="https://vip.apiyi.com/v1", # 수정해야 할 유일한 한 줄
api_key="당신의 APIYI 키"
)
# 이후 모든 코드는 쿡북과 동일하게 작성
response = await client.responses.parse(
model="gpt-4.1-mini",
input=[...],
text_format=ReceiptDetails
)
이것이 바로 "OpenAI 공식 API 중계"와 일반적인 "OpenAI 호환 API"의 결정적인 차이입니다. 전자는 인터페이스가 OpenAI 공식과 동기화됨을 보장하지만, 후자는 기본 인터페이스만 호환되므로 responses.parse나 Evals API 같은 고급 기능은 지원하지 않을 수 있습니다. 이와 같은 공식 사례를 재현할 때는 공식 API 중계 서비스를 선택해야 호환성 문제로 인한 고생을 피할 수 있습니다.
OpenAI 영수증 검토 사례 FAQ
Q1: 이 방법은 영수증에만 사용할 수 있나요?
전혀 그렇지 않습니다. '평가 주도 설계(Eval-Driven Design)'는 "입력은 비교적 개방적이고, 출력은 구조화된 의사결정이 필요한" 모든 시나리오에 적용할 수 있습니다. 계약서 검토, 의료 영상 분류, 고객 상담 품질 관리, 채용 이력서 필터링, 사기 탐지 등에도 이 3단계 프로세스를 그대로 적용할 수 있습니다. 핵심은 Pydantic 스키마와 평가자(grader) 설계에 있습니다.
Q2: 18개의 평가자(grader)는 너무 많지 않나요? 소규모 팀이 감당할 수 있을까요?
최종 결정 정확도나 핵심 필드 추출 정확도와 같은 5~6개의 핵심 평가자부터 시작해도 충분합니다. 중요한 것은 개수가 아니라 각 평가자가 구체적인 실패 패턴에 대응하는지입니다. 처음에는 apiyi.com 콘솔에서 GPT-4o로 소량의 샘플을 테스트하고, 비즈니스 로직이 안정화된 후에 평가 차원을 확장하는 것을 추천합니다.
Q3: V0 단계에서 바로 o4-mini를 사용하면 너무 비싸지 않을까요?
V0 단계의 호출량은 보통 수십에서 수백 회 수준이므로, 총비용은 몇 달러에서 수십 달러 정도로 충분히 감당 가능한 수준입니다. 비용 절감이 중요한 것은 프로덕션 환경의 백만 단위 호출 시점입니다. 그때는 이미 완성된 평가 세트가 있어 모델 교체 실험이 가능합니다. 사례에서처럼 o4-mini에서 gpt-4.1-mini로 전환하여 비용을 67% 절감할 수 있는 것과 같습니다.
Q4: GPT-4o Vision으로 한글 수기 영수증을 읽으면 결과가 어떤가요?
영문 인쇄 영수증의 정확도는 매우 높고(95% 이상), 한글 인쇄 영수증도 준수한 편(90% 이상)입니다. 한글 수기 영수증은 글씨의 선명도에 따라 다릅니다. 데모 영상만 믿기보다는 실제 샘플 100장을 활용해 직접 평가 세트를 구축해 보길 권장합니다. 공식 API를 통해 GPT-4o Vision을 호출하는 비용은 공식과 동일하므로 대규모 평가 실험에 적합합니다.
Q5: Evals API 권한이 없어도 이 쿡북을 실행할 수 있나요?
네, 가능합니다. Evals API는 주로 평가자 설정과 실행 관리를 OpenAI에 위탁하는 방식일 뿐, 실제 평가 로직은 Python으로 직접 구현해도 동일하게 작동합니다. 쿡북에 포함된 평가자 함수는 모두 공개되어 있으니 로컬 환경에 복사해서 바로 사용하세요. 이후 비즈니스 규모가 커지면 그때 관리형 Evals로 이전하는 것을 고려해도 늦지 않습니다.
Q6: APIYI를 통해 이 사례를 실행하는 것과 공식 API의 차이점은 무엇인가요?
인터페이스 프로토콜, 모델 버전, 파라미터 지원 등 모든 면에서 OpenAI 공식과 완벽하게 동기화됩니다. 이것이 바로 '공식 중계(官转)'의 핵심 약속입니다. 차이점은 네트워크 환경에 있습니다. 국내에서 OpenAI에 직접 연결하면 SSL 핸드셰이크 실패나 타임아웃이 자주 발생하지만, APIYI 게이트웨이는 국내 IDC에 배포되어 있어 이미지 관련 인터페이스의 안정성이 훨씬 뛰어납니다. 이는 장시간 평가 작업을 수행할 때 매우 중요합니다.
요약
OpenAI 영수증 검토 사례가 반복해서 읽을 가치가 있는 이유는 "AI로 실제 비즈니스 문제를 해결하는 방법"이라는 추상적인 명제를 3단계 프로세스, 18개의 평가지표, 달러 단위로 환산 가능한 엔지니어링 실무로 분해했기 때문입니다. 이는 현재 한국어권 커뮤니티에서 가장 필요한 AI 엔지니어링 교본입니다.
문서나 이미지를 입력받아 구조화된 의사결정을 출력하는 AI 애플리케이션을 개발 중이라면, 이 쿡북을 처음부터 끝까지 직접 실행해 보길 강력히 추천합니다. 눈으로만 보지 말고 직접 해보세요. '평가 주도 설계'의 진정한 가치는 지표가 변하는 순간 체감할 수 있습니다. apiyi.com과 같은 OpenAI 공식 중계 API 플랫폼을 활용하면 환경 설정의 번거로움 없이 방법론 자체에 집중할 수 있습니다.
'평가 주도'라는 네 글자를 개발 프로세스에 새기면, 당신의 AI 시스템은 "그럴듯해 보이는" 장난감에서 "프로덕션에 투입해 ROI를 계산할 수 있는" 엔지니어링 결과물로 업그레이드될 것입니다. 그 차이가 바로 75,000달러의 가치를 만들지도 모릅니다.
📌 저자: APIYI Team — OpenAI / Anthropic / Google 멀티모달 API의 엔지니어링 사례를 지속적으로 추적합니다. 더 많은 쿡북 실전 가이드와 공식 중계 API 연동 방법은 apiyi.com 문서 센터에서 확인하세요.