智谱AI在 2026 年 2 月 11 日正式发布了 GLM-5,这是目前参数规模最大的开源大语言模型之一。GLM-5 采用 744B MoE 混合专家架构,每次推理激活 40B 参数,在推理、编码和 Agent 任务上达到了开源模型的最佳水平。
核心价值: 读完本文,你将掌握 GLM-5 的技术架构原理、API 调用方法、Thinking 推理模式配置,以及如何在实际项目中发挥这个 744B 开源旗舰模型的最大价值。
GLM-5 核心参数一览
在深入技术细节之前,先看一下 GLM-5 的关键参数:
| 参数 | 数值 | 说明 |
|---|---|---|
| 总参数量 | 744B (7440 亿) | 当前最大开源模型之一 |
| 活跃参数 | 40B (400 亿) | 每次推理实际使用 |
| 架构类型 | MoE 混合专家 | 256 专家,每 token 激活 8 个 |
| 上下文窗口 | 200,000 tokens | 支持超长文档处理 |
| 最大输出 | 128,000 tokens | 满足长文本生成需求 |
| 预训练数据 | 28.5T tokens | 较上代增加 24% |
| 许可证 | Apache-2.0 | 完全开源,支持商业使用 |
| 训练硬件 | 华为昇腾芯片 | 全国产算力,不依赖海外硬件 |
GLM-5 的一个显著特点是它完全基于华为昇腾芯片和 MindSpore 框架训练,实现了对国产算力栈的完整验证。这对于国内开发者来说,意味着技术栈的自主可控又多了一个强有力的选择。
GLM 系列版本演进
GLM-5 是智谱AI GLM 系列的第五代产品,每一代都有显著的能力跃升:
| 版本 | 发布时间 | 参数规模 | 核心突破 |
|---|---|---|---|
| GLM-4 | 2024-01 | 未公开 | 多模态基础能力 |
| GLM-4.5 | 2025-03 | 355B (32B 活跃) | MoE 架构首次引入 |
| GLM-4.5-X | 2025-06 | 同上 | 强化推理,旗舰定位 |
| GLM-4.7 | 2025-10 | 未公开 | Thinking 推理模式 |
| GLM-4.7-FlashX | 2025-12 | 未公开 | 超低成本快速推理 |
| GLM-5 | 2026-02 | 744B (40B 活跃) | Agent 能力突破,幻觉率降 56% |
从 GLM-4.5 的 355B 到 GLM-5 的 744B,总参数量翻了一倍多;活跃参数从 32B 提升到 40B,增幅 25%;预训练数据从 23T 增加到 28.5T tokens。这些数字背后是智谱AI在算力、数据和算法三个维度上的全面投入。
🚀 快速体验: GLM-5 已上线 APIYI apiyi.com,价格与官网一致,充值加赠活动下来大约可以享受 8 折优惠,适合想要快速体验这款 744B 旗舰模型的开发者。
GLM-5 MoE 아키텍처 기술 분석
GLM-5가 MoE 아키텍처를 선택한 이유
MoE(Mixture of Experts, 전문가 혼합)는 현재 대규모 언어 모델 확장의 주류 기술 노선입니다. 모든 파라미터가 매번 추론에 참여하는 Dense 아키텍처와 달리, MoE 아키텍처는 각 토큰을 처리할 때 전문가 네트워크의 일부분만 활성화합니다. 이를 통해 대규모 언어 모델의 지식 용량을 유지하면서도 추론 비용을 획기적으로 낮출 수 있습니다.
GLM-5의 MoE 아키텍처 설계는 다음과 같은 핵심 특성을 가지고 있습니다:
| 아키텍처 특성 | GLM-5 구현 | 기술적 가치 |
|---|---|---|
| 전문가 총수 | 256개 | 방대한 지식 용량 확보 |
| 토큰당 활성화 | 8개 전문가 | 높은 추론 효율성 |
| 희소율(Sparsity) | 5.9% | 전체 중 극히 일부 파라미터만 사용 |
| 어텐션 메커니즘 | DSA + MLA | 배포 비용 절감 |
| 메모리 최적화 | MLA로 33% 감소 | 비디오 메모리 점유율 낮춤 |
간단히 말해, GLM-5는 744B라는 거대한 파라미터를 가지고 있지만, 매 추론 시에는 약 5.9%인 40B만 활성화합니다. 이는 동일한 규모의 Dense 모델보다 추론 비용이 훨씬 저렴하면서도, 744B 파라미터가 담고 있는 풍부한 지식을 그대로 활용할 수 있음을 의미합니다.
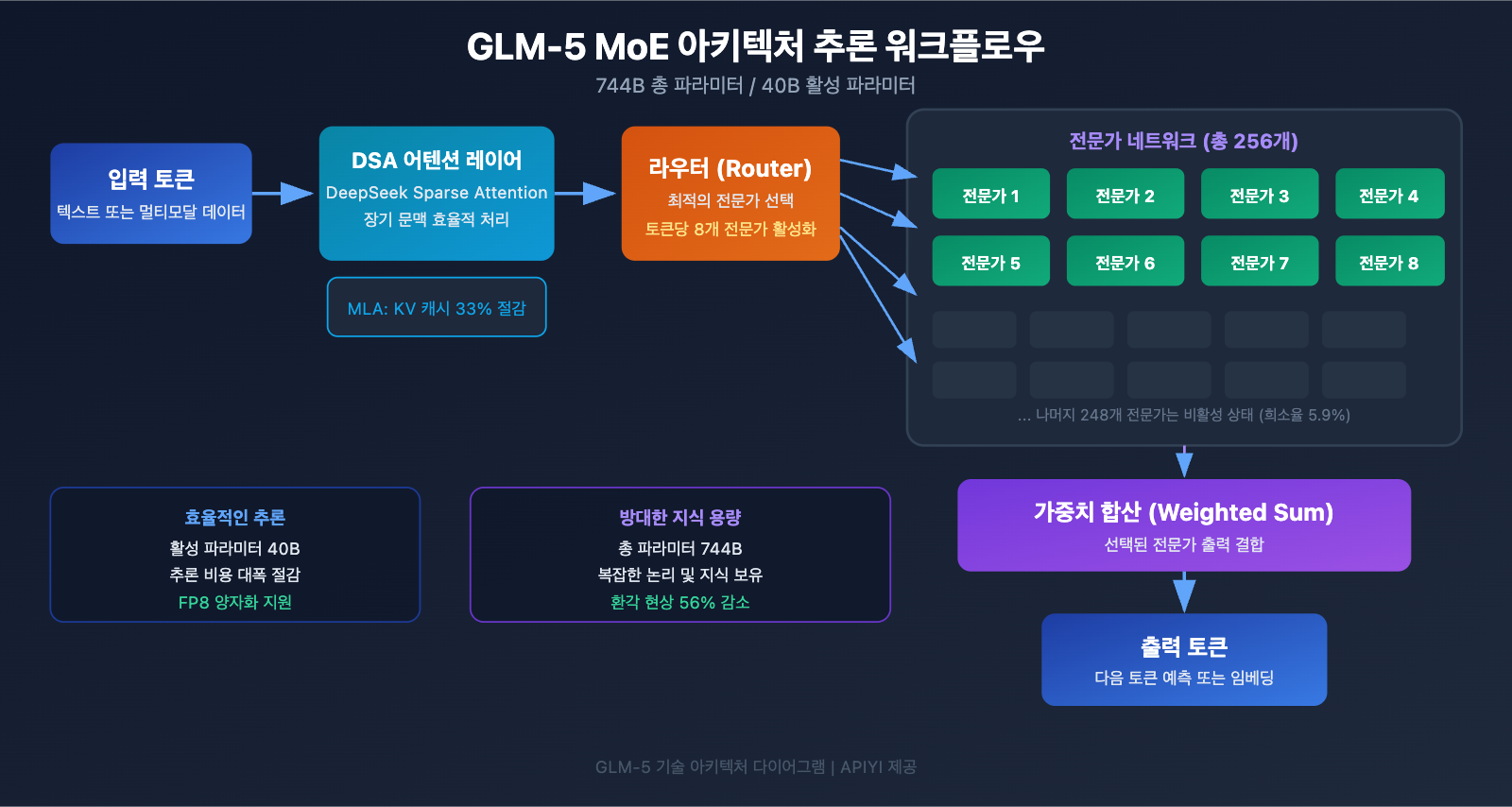
GLM-5의 DeepSeek Sparse Attention (DSA)
GLM-5는 DeepSeek Sparse Attention 메커니즘을 통합했습니다. 이 기술은 긴 문맥(Long Context) 처리 능력을 유지하면서도 배포 비용을 현저히 낮춰줍니다. Multi-head Latent Attention (MLA)과 결합하여, GLM-5는 200K 토큰에 달하는 초장기 문맥 윈도우에서도 효율적으로 작동합니다.
구체적으로 살펴보면:
- DSA (DeepSeek Sparse Attention): 희소 어텐션 패턴을 통해 어텐션 계산의 복잡도를 줄입니다. 기존의 Full Attention 메커니즘은 200K 토큰을 처리할 때 계산량이 방대하지만, DSA는 핵심 토큰 위치에 선택적으로 집중하여 정보의 완전성을 유지하면서도 계산 비용을 절감합니다.
- MLA (Multi-head Latent Attention): 어텐션 헤드의 KV 캐시를 잠재 공간(Latent Space)으로 압축하여 메모리 점유율을 약 33% 줄입니다. 긴 문맥 시나리오에서 KV 캐시는 보통 비디오 메모리 소모의 주범인데, MLA가 이 병목 현상을 효과적으로 완화해 줍니다.
이 두 기술의 결합은 다음과 같은 의미를 갖습니다. 744B 규모의 거대 모델임에도 불구하고, FP8 양자화를 거치면 단 8장의 GPU만으로도 구동이 가능해져 배포 문턱이 대폭 낮아졌습니다.
GLM-5 사후 학습: Slime 비동기 RL 시스템
GLM-5는 사후 학습(Post-training)을 위해 "Slime"이라 불리는 새로운 비동기 강화 학습(RL) 인프라를 채택했습니다. 전통적인 RL 학습은 생성, 평가, 업데이트 단계 사이에 많은 대기 시간이 발생하는 효율성 병목 현상이 있었습니다. Slime은 이러한 단계들을 비동기화하여 더 세밀한 사후 학습 반복을 구현하고 학습 처리량을 대폭 끌어올렸습니다.
기존 RL 학습 프로세스에서는 모델이 한 배치의 추론을 마치고 평가 결과를 기다린 뒤 파라미터를 업데이트하는 직렬 방식을 사용했습니다. 반면 Slime은 이 세 단계를 독립적인 비동기 파이프라인으로 분리하여 추론, 평가, 업데이트가 병렬로 진행되도록 함으로써 학습 효율을 획기적으로 개선했습니다.
이러한 기술적 개선은 GLM-5의 환각률(Hallucination rate) 감소로 직결되었습니다. 이전 세대 대비 환각 현상이 56%나 줄어들었는데, 이는 더 충분한 사후 학습 반복을 통해 모델의 사실 정확성이 눈에 띄게 개선되었음을 보여줍니다.
GLM-5와 Dense 아키텍처의 비교
MoE 아키텍처의 장점을 더 잘 이해하기 위해, GLM-5를 가상의 동일 규모 Dense 모델과 비교해 보겠습니다:
| 비교 차원 | GLM-5 (744B MoE) | 가상의 744B Dense | 실제 차이 |
|---|---|---|---|
| 추론 시 활성 파라미터 | 40B (5.9%) | 744B (100%) | MoE가 94% 적음 |
| 추론 비디오 메모리 요구량 | 8x GPU (FP8) | 약 96x GPU | MoE가 현저히 낮음 |
| 추론 속도 | 비교적 빠름 | 매우 느림 | MoE가 실제 배포에 적합 |
| 지식 용량 | 744B 전체 지식 | 744B 전체 지식 | 대등함 |
| 전문화 능력 | 작업별 최적 전문가 활용 | 통합 처리 | MoE가 더 정교함 |
| 학습 비용 | 높지만 통제 가능 | 극도로 높음 | MoE의 가성비가 우수 |
MoE 아키텍처의 핵심 강점은 744B 파라미터의 지식 용량을 보유하면서도, 단 40B 파라미터 수준의 추론 비용으로 높은 효율성을 달성했다는 점입니다. 이것이 바로 GLM-5가 최첨단 성능을 유지하면서도 동급 폐쇄형 모델보다 훨씬 저렴한 가격을 제공할 수 있는 비결입니다.
GLM-5 API 호출 빠른 시작
GLM-5 API 요청 파라미터 상세 설명
코드를 작성하기 전에 먼저 GLM-5의 API 파라미터 설정을 살펴보겠습니다.
| 파라미터 | 타입 | 필수 여부 | 기본값 | 설명 |
|---|---|---|---|---|
model |
string | ✅ | – | "glm-5"로 고정 |
messages |
array | ✅ | – | 표준 채팅 형식 메시지 |
max_tokens |
int | ❌ | 4096 | 최대 출력 토큰 수 (상한 128K) |
temperature |
float | ❌ | 1.0 | 샘플링 온도, 낮을수록 결과가 확정적임 |
top_p |
float | ❌ | 1.0 | 핵 샘플링(Nucleus sampling) 파라미터 |
stream |
bool | ❌ | false | 스트리밍 출력 여부 |
thinking |
object | ❌ | disabled | {"type": "enabled"}로 설정 시 추론 활성화 |
tools |
array | ❌ | – | Function Calling 도구 정의 |
tool_choice |
string | ❌ | auto | 도구 선택 전략 |
GLM-5 초간단 호출 예시
GLM-5는 OpenAI SDK 인터페이스 형식과 호환되므로, base_url과 model 파라미터만 변경하면 빠르게 연동할 수 있어요.
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # APIYI 통합 인터페이스
)
response = client.chat.completions.create(
model="glm-5",
messages=[
{"role": "system", "content": "당신은 숙련된 AI 기술 전문가입니다."},
{"role": "user", "content": "MoE(Experts의 혼합) 아키텍처의 작동 원리와 장점을 설명해 주세요."}
],
temperature=0.7,
max_tokens=4096
)
print(response.choices[0].message.content)
위 코드가 GLM-5의 가장 기본적인 호출 방식입니다. 모델 ID는 glm-5를 사용하며, 인터페이스는 OpenAI의 chat.completions 형식과 완벽하게 호환됩니다. 기존 프로젝트에서 단 두 개의 파라미터만 수정하면 바로 마이그레이션이 가능해요.
GLM-5 Thinking 추론 모드
GLM-5는 DeepSeek R1이나 Claude의 확장 사고 능력과 유사한 'Thinking 추론 모드'를 지원합니다. 이 모드를 활성화하면 모델이 답변하기 전에 내부적으로 체인 추론(Chain-of-Thought)을 수행하여, 복잡한 수학, 논리 및 프로그래밍 문제에서 성능이 눈에 띄게 향상됩니다.
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # APIYI 통합 인터페이스
)
response = client.chat.completions.create(
model="glm-5",
messages=[
{"role": "user", "content": "증명: 모든 양의 정수 n에 대하여, n^3 - n은 6으로 나누어 떨어진다."}
],
extra_body={
"thinking": {"type": "enabled"}
},
temperature=1.0 # Thinking 모드에서는 1.0 사용을 권장합니다
)
print(response.choices[0].message.content)
GLM-5 Thinking 모드 사용 가이드:
| 시나리오 | Thinking 활성화 여부 | 권장 temperature | 설명 |
|---|---|---|---|
| 수학 증명/경시 대회 문제 | ✅ 활성화 | 1.0 | 깊은 추론이 필요함 |
| 코드 디버깅/아키텍처 설계 | ✅ 활성화 | 1.0 | 체계적인 분석이 필요함 |
| 논리 추론/분석 | ✅ 활성화 | 1.0 | 단계별 사고가 필요함 |
| 일상 대화/글쓰기 | ❌ 비활성화 | 0.5-0.7 | 복잡한 추론이 필요하지 않음 |
| 정보 추출/요약 | ❌ 비활성화 | 0.3-0.5 | 안정적인 출력이 중요함 |
| 창의적 콘텐츠 생성 | ❌ 비활성화 | 0.8-1.0 | 다양성이 필요함 |
GLM-5 스트리밍 출력
실시간 상호작용이 필요한 상황을 위해 GLM-5는 스트리밍 출력을 지원합니다. 사용자는 모델이 답변을 생성하는 동안 결과를 실시간으로 확인할 수 있어요.
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
stream = client.chat.completions.create(
model="glm-5",
messages=[
{"role": "user", "content": "Python으로 캐시 기능이 포함된 HTTP 클라이언트를 구현해 줘."}
],
stream=True,
temperature=0.6
)
for chunk in stream:
if chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="", flush=True)
GLM-5 Function Calling 및 에이전트 구축
GLM-5는 에이전트(Agent) 시스템 구축의 핵심 역량인 Function Calling을 기본적으로 지원합니다. GLM-5는 'HLE w/ Tools' 벤치마크에서 50.4%의 성적을 거두며 Claude Opus(43.4%)를 추월했는데, 이는 도구 호출과 작업 오케스트레이션 능력이 매우 뛰어나다는 것을 증명합니다.
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
tools = [
{
"type": "function",
"function": {
"name": "search_documents",
"description": "지식 베이스에서 관련 문서 검색",
"parameters": {
"type": "object",
"properties": {
"query": {"type": "string", "description": "검색 키워드"},
"top_k": {"type": "integer", "description": "반환할 결과 수", "default": 5}
},
"required": ["query"]
}
}
},
{
"type": "function",
"function": {
"name": "execute_code",
"description": "샌드박스 환경에서 Python 코드 실행",
"parameters": {
"type": "object",
"properties": {
"code": {"type": "string", "description": "실행할 Python 코드"},
"timeout": {"type": "integer", "description": "제한 시간(초)", "default": 30}
},
"required": ["code"]
}
}
}
]
response = client.chat.completions.create(
model="glm-5",
messages=[
{"role": "system", "content": "당신은 문서를 검색하고 코드를 실행할 수 있는 AI 비서입니다."},
{"role": "user", "content": "GLM-5의 기술 사양을 찾아보고, 코드를 사용해 성능 비교 차트를 그려 줘."}
],
tools=tools,
tool_choice="auto"
)
# 도구 호출 처리
message = response.choices[0].message
if message.tool_calls:
for tool_call in message.tool_calls:
print(f"도구 호출: {tool_call.function.name}")
print(f"파라미터: {tool_call.function.arguments}")
cURL 호출 예시 보기
curl https://api.apiyi.com/v1/chat/completions \
-H "Authorization: Bearer $API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "glm-5",
"messages": [
{"role": "system", "content": "당신은 숙련된 소프트웨어 엔지니어입니다."},
{"role": "user", "content": "분산 작업 스케줄링 시스템의 아키텍처를 설계해 주세요."}
],
"max_tokens": 8192,
"temperature": 0.7,
"stream": true
}'
🎯 기술 제언: GLM-5는 OpenAI SDK 형식과 호환되므로, 기존 프로젝트에서
base_url과model두 파라미터만 수정하면 바로 마이그레이션할 수 있습니다. APIYI(apiyi.com) 플랫폼을 통해 호출하면 통합 인터페이스 관리와 충전 추가 증정 혜택을 누릴 수 있습니다.
GLM-5 벤치마크 성능 실측
GLM-5 핵심 벤치마크 데이터
GLM-5는 여러 주요 벤치마크에서 오픈소스 모델 중 최상위 수준의 성능을 보여주었습니다.
| 벤치마크 | GLM-5 | Claude Opus 4.5 | GPT-5 | 테스트 내용 |
|---|---|---|---|---|
| MMLU | 85.0% | 88.7% | 90.2% | 57개 학과 지식 |
| MMLU Pro | 70.4% | – | – | 강화된 다학제 지식 |
| GPQA | 68.2% | 71.4% | 73.1% | 대학원 수준 과학 |
| HumanEval | 90.0% | 93.2% | 92.5% | Python 프로그래밍 |
| MATH | 88.0% | 90.1% | 91.3% | 수학적 추론 |
| GSM8k | 97.0% | 98.2% | 98.5% | 수학 문장제 문제 |
| AIME 2026 I | 92.7% | 93.3% | – | 수학 경시 대회 |
| SWE-bench | 77.8% | 80.9% | 80.0% | 실제 소프트웨어 공학 |
| HLE w/ Tools | 50.4% | 43.4% | – | 도구 활용 추론 |
| IFEval | 88.0% | – | – | 지시어 준수 |
| Terminal-Bench | 56.2% | 57.9% | – | 터미널 조작 |
GLM-5 성능 분석: 4대 핵심 강점
벤치마크 데이터를 통해 몇 가지 주목할 만한 점을 발견할 수 있습니다.
1. GLM-5 에이전트 능력: HLE w/ Tools에서 폐쇄형 모델 추월
GLM-5는 Humanity's Last Exam(도구 활용 포함)에서 50.4%의 성적을 거두며 Claude Opus의 43.4%를 앞질렀고, Kimi K2.5(51.8%)에 이어 2위를 차지했습니다. 이는 GLM-5가 계획 수립, 도구 호출, 반복적 문제 해결이 필요한 복잡한 에이전트 시나리오에서 이미 최첨단 모델 수준에 도달했음을 보여줍니다.
이 결과는 GLM-5의 설계 철학과 일치합니다. 아키텍처부터 사후 학습(Post-training)까지 에이전트 워크플로우에 최적화되어 있기 때문이죠. AI 에이전트 시스템을 구축하려는 개발자에게 GLM-5는 매우 매력적인 오픈소스 선택지입니다.
2. GLM-5 코딩 능력: 1티어 그룹 진입
HumanEval 90%, SWE-bench Verified 77.8%라는 수치는 GLM-5가 코드 생성 및 실제 소프트웨어 공학 작업에서 Claude Opus(80.9%)와 GPT-5(80.0%) 수준에 매우 근접했음을 의미합니다. 특히 오픈소스 모델로서 SWE-bench 77.8%를 달성한 것은 큰 돌파구입니다. 이는 GLM-5가 실제 GitHub 이슈를 이해하고, 코드 문제를 진단하며, 유효한 수정안을 제출할 수 있는 능력을 갖췄음을 뜻합니다.
3. GLM-5 수학적 추론: 한계치에 근접
AIME 2026 I에서 GLM-5는 92.7%를 기록하며 Claude Opus에 단 0.6%포인트 차이로 뒤처졌습니다. GSM8k 97%는 중등 난이도의 수학 문제에서 GLM-5가 매우 신뢰할 수 있음을 보여주며, MATH 88% 역시 최상위권 성적입니다.
4. GLM-5 환각 제어: 대폭 감소
공식 데이터에 따르면, GLM-5는 이전 세대 모델 대비 환각률이 56% 감소했습니다. 이는 Slime 비동기 RL 시스템을 통한 충분한 사후 학습 반복 덕분입니다. 높은 정확도가 요구되는 정보 추출, 문서 요약, 지식 베이스 기반 Q&A 시나리오에서 낮은 환각률은 곧 신뢰할 수 있는 출력 품질로 이어집니다.
GLM-5와 동급 오픈소스 모델의 포지셔닝
현재 오픈소스 대규모 언어 모델 경쟁 구도에서 GLM-5의 포지셔닝은 명확합니다.
| 모델 | 파라미터 규모 | 아키텍처 | 핵심 강점 | 라이선스 |
|---|---|---|---|---|
| GLM-5 | 744B (활성 40B) | MoE | 에이전트 + 낮은 환각 | Apache-2.0 |
| DeepSeek V3 | 671B (활성 37B) | MoE | 가성비 + 추론 | MIT |
| Llama 4 Maverick | 400B (활성 17B) | MoE | 멀티모달 + 생태계 | Llama License |
| Qwen 3 | 235B | Dense | 다국어 + 도구 활용 | Apache-2.0 |
GLM-5의 차별화된 강점은 세 가지 측면에서 나타납니다. 에이전트 워크플로우에 특화된 최적화(HLE w/ Tools 선두), 극도로 낮은 환각률(56% 감소), 그리고 독자적인 컴퓨팅 파워로 훈련되어 공급망 안정성을 확보했다는 점입니다. 최첨단 오픈소스 모델을 도입하려는 기업이라면 GLM-5를 반드시 주목해야 할 옵션으로 추천합니다.
GLM-5 가격 및 비용 분석
GLM-5 공식 가격 책정
| 과금 유형 | Z.ai 공식 가격 | OpenRouter 가격 | 설명 |
|---|---|---|---|
| 입력 토큰 | $1.00/M | $0.80/M | 백만(M) 입력 토큰당 |
| 출력 토큰 | $3.20/M | $2.56/M | 백만(M) 출력 토큰당 |
| 캐시 입력 | $0.20/M | $0.16/M | 캐시 적중 시 입력 가격 |
| 캐시 저장 | 한시적 무료 | – | 캐시 데이터 저장 비용 |
GLM-5 및 경쟁 모델 가격 비교
GLM-5의 가격 책정 전략은 특히 폐쇄형 최첨단 모델과 비교했을 때 매우 경쟁력이 있습니다.
| 모델 | 입력 ($/M) | 출력 ($/M) | GLM-5 대비 비용 | 모델 포지셔닝 |
|---|---|---|---|---|
| GLM-5 | $1.00 | $3.20 | 기준 | 오픈 소스 플래그십 |
| Claude Opus 4.6 | $5.00 | $25.00 | 약 5-8배 | 폐쇄형 플래그십 |
| GPT-5 | $1.25 | $10.00 | 약 1.3-3배 | 폐쇄형 플래그십 |
| DeepSeek V3 | $0.27 | $1.10 | 약 0.3배 | 오픈 소스 가성비 |
| GLM-4.7 | $0.60 | $2.20 | 약 0.6-0.7배 | 이전 세대 플래그십 |
| GLM-4.7-FlashX | $0.07 | $0.40 | 약 0.07-0.13배 | 초저비용 |
가격 측면에서 보면, GLM-5는 GPT-5와 DeepSeek V3 사이에 위치합니다. 대부분의 폐쇄형 최첨단 모델보다는 훨씬 저렴하지만, 경량 오픈 소스 모델보다는 약간 비싼 편이죠. 744B라는 거대한 파라미터 규모와 오픈 소스 중 최강의 성능을 고려하면 상당히 합리적인 가격대라고 할 수 있습니다.
GLM 전체 제품 라인업 및 가격 책정
만약 GLM-5가 여러분의 사용 시나리오에 완벽히 맞지 않는다면, 지푸(Zhipu)에서 제공하는 다양한 제품 라인업 중에서 선택할 수 있습니다.
| 모델 | 입력 ($/M) | 출력 ($/M) | 적용 시나리오 |
|---|---|---|---|
| GLM-5 | $1.00 | $3.20 | 복잡한 추론, 에이전트, 긴 문서 |
| GLM-5-Code | $1.20 | $5.00 | 코드 개발 전용 |
| GLM-4.7 | $0.60 | $2.20 | 중간 난이도 범용 작업 |
| GLM-4.7-FlashX | $0.07 | $0.40 | 고빈도 저비용 호출 |
| GLM-4.5-Air | $0.20 | $1.10 | 경량 및 균형 |
| GLM-4.7/4.5-Flash | 무료 | 무료 | 입문용 체험 및 간단한 작업 |
💰 비용 최적화: GLM-5는 현재 APIYI(apiyi.com)에 출시되었으며, 가격은 Z.ai 공식 가격과 동일합니다. 플랫폼 충전 보너스 이벤트를 활용하면 실제 사용 비용을 공식 가격의 약 80% 수준으로 낮출 수 있어, 지속적인 호출이 필요한 팀이나 개발자에게 적합합니다.
GLM-5 적용 시나리오 및 모델 선택 제안
GLM-5는 어떤 상황에 적합할까요?
GLM-5의 기술적 특징과 벤치마크 성능을 바탕으로 추천하는 구체적인 시나리오는 다음과 같습니다.
강력 추천 시나리오:
- 에이전트(Agent) 워크플로우: GLM-5는 장기적인 에이전트 작업을 위해 설계되었습니다. HLE w/ Tools에서 50.4%를 기록하며 Claude Opus를 능가했으므로, 자율적인 계획 수립과 도구 호출이 필요한 에이전트 시스템 구축에 최적입니다.
- 코드 엔지니어링 작업: HumanEval 90%, SWE-bench 77.8%의 성능으로 코드 생성, 버그 수정, 코드 리뷰 및 아키텍처 설계 업무를 훌륭히 수행합니다.
- 수학 및 과학적 추론: AIME 92.7%, MATH 88%를 기록하여 수학적 증명, 공식 유도 및 과학 계산에 적합합니다.
- 초장문 문서 분석: 200K 컨텍스트 윈도우를 통해 전체 코드 베이스, 기술 문서, 법률 계약서 등 매우 긴 텍스트를 처리할 수 있습니다.
- 낮은 환각(Hallucination) 현상의 Q&A: 환각률을 56% 줄여 지식 베이스 기반의 Q&A, 문서 요약 등 높은 정확도가 요구되는 시나리오에 적합합니다.
다른 대안을 고려해 볼 만한 시나리오:
- 멀티모달 작업: GLM-5 본체는 텍스트만 지원합니다. 이미지 이해가 필요하다면 GLM-4.6V와 같은 시각 모델을 선택하세요.
- 극강의 저지연성: 744B MoE 모델의 추론 속도는 소형 모델만큼 빠르지 않습니다. 고빈도 저지연 시나리오에서는 GLM-4.7-FlashX 사용을 권장합니다.
- 초저비용 대량 처리: 대량의 텍스트를 처리해야 하는데 품질 요구 사항이 아주 높지 않다면, DeepSeek V3나 GLM-4.7-FlashX가 비용 면에서 더 유리합니다.
GLM-5 vs GLM-4.7 모델 선택 비교
| 비교 항목 | GLM-5 | GLM-4.7 | 선택 제안 |
|---|---|---|---|
| 파라미터 규모 | 744B (활성 40B) | 미공개 | GLM-5가 더 큼 |
| 추론 능력 | AIME 92.7% | ~85% | 복잡한 추론은 GLM-5 |
| 에이전트 능력 | HLE w/ Tools 50.4% | ~38% | 에이전트 작업은 GLM-5 |
| 코딩 능력 | HumanEval 90% | ~85% | 코드 개발은 GLM-5 |
| 환각 제어 | 56% 감소 | 기준 | 높은 정확도는 GLM-5 |
| 입력 가격 | $1.00/M | $0.60/M | 비용에 민감하면 GLM-4.7 |
| 출력 가격 | $3.20/M | $2.20/M | 비용에 민감하면 GLM-4.7 |
| 컨텍스트 길이 | 200K | 128K+ | 긴 문서는 GLM-5 |
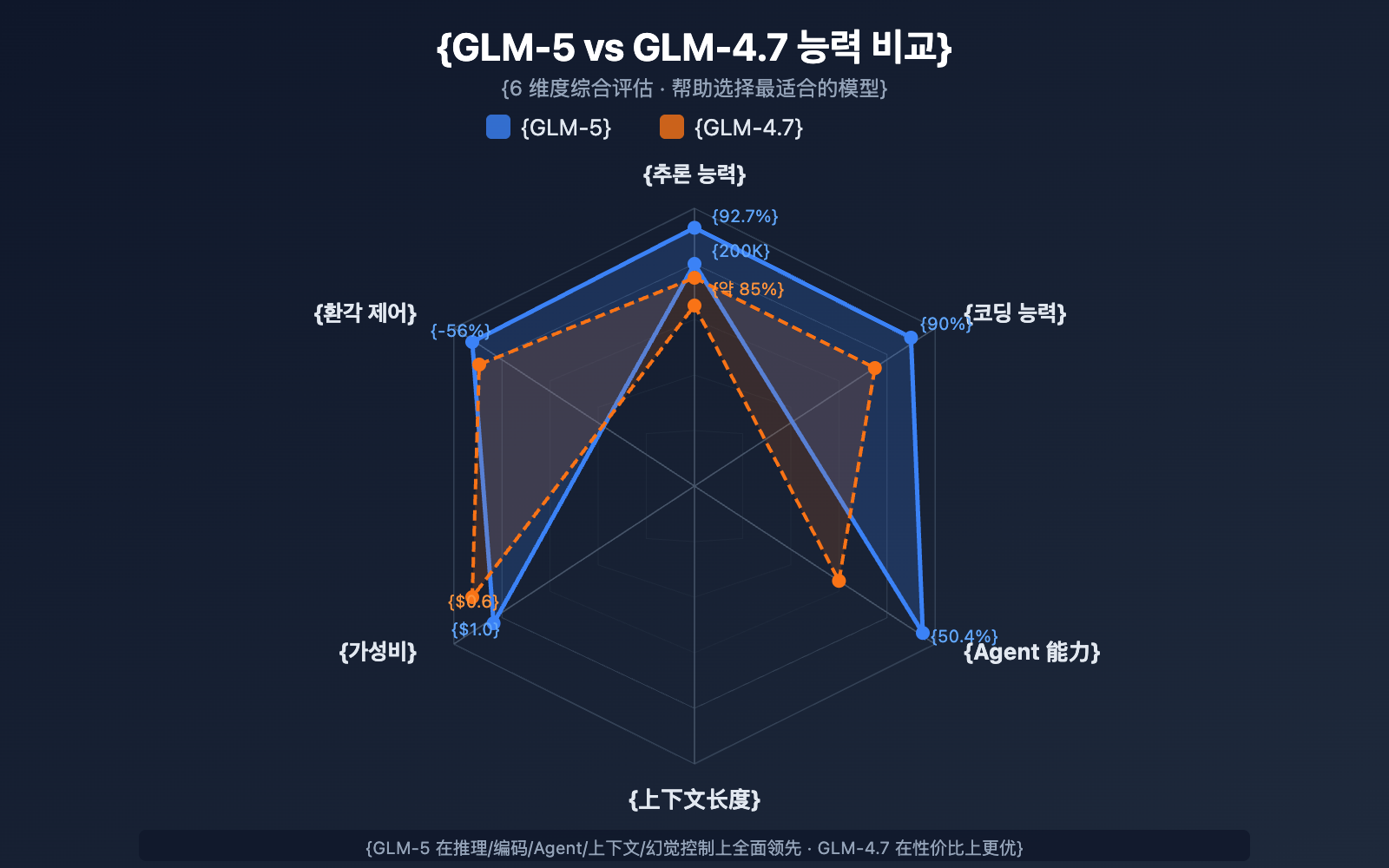
💡 선택 제안: 프로젝트에 최상위 추론 능력, 에이전트 워크플로우 또는 초장문 컨텍스트 처리가 필요하다면 GLM-5가 더 나은 선택입니다. 예산이 한정되어 있고 작업 난이도가 적절하다면 GLM-4.7도 훌륭한 가성비 대안이 될 수 있습니다. 두 모델 모두 APIYI(apiyi.com) 플랫폼을 통해 호출할 수 있어, 언제든 필요에 따라 전환하며 테스트하기 편리합니다.
GLM-5 API 호출 자주 묻는 질문 (FAQ)
Q1: GLM-5와 GLM-5-Code의 차이점은 무엇인가요?
GLM-5는 범용 플래그십 모델(입력 $1.00/M, 출력 $3.20/M)로, 다양한 텍스트 작업에 적합합니다. GLM-5-Code는 코드 전용 강화 버전(입력 $1.20/M, 출력 $5.00/M)으로, 코드 생성, 디버깅 및 엔지니어링 작업에 최적화되어 있습니다. 주요 사용 시나리오가 코드 개발이라면 GLM-5-Code를 사용해 보시는 것을 추천드려요. 두 모델 모두 통일된 OpenAI 호환 인터페이스를 통해 호출할 수 있습니다.
Q2: GLM-5의 Thinking 모드가 출력 속도에 영향을 주나요?
네, 영향을 줍니다. Thinking 모드에서 GLM-5는 내부 추론 과정을 먼저 생성한 후 최종 답변을 출력하기 때문에 첫 토큰 지연 시간(TTFT)이 늘어납니다. 간단한 질문의 경우 빠른 응답을 위해 Thinking 모드를 끄는 것이 좋고, 복잡한 수학, 프로그래밍, 논리 문제는 속도는 조금 느리더라도 정확도가 눈에 띄게 향상되므로 켜는 것을 권장합니다.
Q3: GPT-4나 Claude에서 GLM-5로 마이그레이션할 때 코드를 얼마나 수정해야 하나요?
마이그레이션은 매우 간단합니다. 다음 두 가지 파라미터만 수정하면 돼요:
base_url을 APIYI의 인터페이스 주소인https://api.apiyi.com/v1로 변경합니다.model파라미터를"glm-5"로 변경합니다.
GLM-5는 system/user/assistant 역할, 스트리밍 출력, Function Calling 등 OpenAI SDK의 chat.completions 인터페이스 형식을 완벽하게 지원합니다. 통합 API 중개 플랫폼을 이용하면 하나의 API Key로 여러 제조사의 모델을 교체하며 호출할 수 있어 A/B 테스트를 진행하기에도 매우 편리합니다.
Q4: GLM-5는 이미지 입력을 지원하나요?
지원하지 않습니다. GLM-5 본체는 순수 텍스트 모델로 이미지, 오디오, 비디오 입력을 지원하지 않아요. 이미지 이해 능력이 필요하다면 Zhipu AI의 GLM-4.6V 또는 GLM-4.5V와 같은 비전 변형 모델을 사용해 보세요.
Q5: GLM-5의 컨텍스트 캐싱(Context Caching) 기능은 어떻게 사용하나요?
GLM-5는 컨텍스트 캐싱을 지원하며, 캐싱된 입력 가격은 정상 입력의 1/5 수준인 $0.20/M입니다. 긴 대화나 동일한 접두사(prefix)를 반복해서 처리해야 하는 상황에서 캐싱 기능을 사용하면 비용을 획기적으로 낮출 수 있습니다. 캐시 저장 비용은 현재 한시적으로 무료입니다. 다회차 대화에서 시스템은 중복되는 컨텍스트 접두사를 자동으로 인식하여 캐싱합니다.
Q6: GLM-5의 최대 출력 길이는 얼마인가요?
GLM-5는 최대 128,000 토큰의 출력 길이를 지원합니다. 대부분의 시나리오에서는 기본값인 4096 토큰으로도 충분합니다. 전체 기술 문서나 긴 코드 블록과 같이 긴 텍스트 생성이 필요한 경우 max_tokens 파라미터를 통해 조정할 수 있습니다. 다만 출력이 길어질수록 토큰 소모와 대기 시간도 그만큼 늘어난다는 점에 유의해 주세요.
GLM-5 API 호출 베스트 프랙티스
실제로 GLM-5를 사용할 때, 다음의 실무 경험들을 참고하면 더 좋은 결과를 얻을 수 있습니다.
GLM-5 System 프롬프트 최적화
GLM-5는 system 프롬프트에 대한 반응도가 매우 높습니다. system 프롬프트를 잘 설계하면 출력 품질을 크게 높일 수 있어요.
# 추천: 명확한 역할 정의 + 출력 형식 요구
messages = [
{
"role": "system",
"content": """당신은 베테랑 분산 시스템 아키텍트입니다.
다음 규칙을 준수해 주세요:
1. 답변은 구조화하여 Markdown 형식을 사용하세요.
2. 일반적인 이야기보다는 구체적인 기술 방안을 제시하세요.
3. 코드가 포함될 경우, 실행 가능한 예제를 제공하세요.
4. 적절한 위치에 잠재적 리스크와 주의 사항을 표시하세요."""
},
{
"role": "user",
"content": "백만 단위 동시 접속을 지원하는 메시지 큐 시스템을 설계해 주세요."
}
]
GLM-5 temperature 튜닝 가이드
작업의 종류에 따라 temperature 설정에 민감하게 반응합니다. 다음은 실측 권장 사항입니다.
- temperature 0.1-0.3: 코드 생성, 데이터 추출, 형식 변환 등 정확한 출력이 필요한 작업
- temperature 0.5-0.7: 기술 문서 작성, 질의응답, 요약 등 안정적이면서도 어느 정도 표현의 유연성이 필요한 작업
- temperature 0.8-1.0: 창의적 글쓰기, 브레인스토밍 등 다양성이 필요한 작업
- temperature 1.0 (Thinking 모드): 수학적 추론, 복잡한 프로그래밍 등 깊은 사고가 필요한 작업
GLM-5 긴 컨텍스트 처리 팁
GLM-5는 200K 토큰의 컨텍스트 창을 지원하지만, 실제 사용 시 다음 사항에 주의해야 합니다.
- 중요 정보 전진 배치: 가장 핵심적인 컨텍스트는 프롬프트의 마지막이 아닌 앞부분에 배치하세요.
- 단락 나누기: 100K 토큰이 넘는 문서는 단락별로 나누어 처리한 후 합치는 방식이 더 안정적인 출력을 보장합니다.
- 캐시 활용: 다회차 대화에서 동일한 접두사 내용은 자동으로 캐싱되며, 캐싱된 입력 가격은 $0.20/M에 불과합니다.
- 출력 길이 제어: 긴 컨텍스트를 입력할 때는
max_tokens를 적절히 설정하여 불필요한 비용 발생을 방지하세요.
GLM-5 로컬 배포 참고 가이드
자체 인프라에 GLM-5를 배포해야 하는 경우, 주요 배포 방식은 다음과 같습니다.
| 배포 방식 | 권장 하드웨어 | 정밀도 | 특징 |
|---|---|---|---|
| vLLM | 8x A100/H100 | FP8 | 주류 추론 프레임워크, 투기적 디코딩(Speculative Decoding) 지원 |
| SGLang | 8x H100/B200 | FP8 | 고성능 추론, Blackwell GPU 최적화 |
| xLLM | 화웨이 어센드(Ascend) NPU | BF16/FP8 | 중국 국산 컴퓨팅 자원 최적화 |
| KTransformers | 소비자용 GPU | 양자화 | GPU 가속 추론 |
| Ollama | 소비자용 하드웨어 | 양자화 | 가장 간편한 로컬 경험 |
GLM-5는 BF16 전체 정밀도와 FP8 양자화라는 두 가지 가중치 형식을 제공하며, HuggingFace(huggingface.co/zai-org/GLM-5) 또는 ModelScope에서 다운로드할 수 있습니다. FP8 양자화 버전은 대부분의 성능을 유지하면서도 그래픽 메모리(VRAM) 요구 사항을 크게 낮춰줍니다.
GLM-5 배포에 필요한 핵심 설정은 다음과 같습니다.
- 텐서 병렬화(Tensor Parallel): 8로 설정 (tensor-parallel-size 8)
- VRAM 이용률: 0.85 설정을 권장
- 도구 호출 파서(Tool Call Parser): glm47
- 추론 파서(Reasoning Parser): glm45
- 투기적 디코딩(Speculative Decoding): MTP 및 EAGLE 두 가지 방식 지원
대부분의 개발자에게는 API 호출이 가장 효율적인 방법입니다. 배포 및 운영 비용을 절감하고 애플리케이션 개발에만 집중할 수 있기 때문이죠. 프라이빗 배포가 필요한 시나리오는 공식 문서를 참고하세요:
github.com/zai-org/GLM-5
GLM-5 API 호출 요약
GLM-5 핵심 능력 속성표
| 능력 분야 | GLM-5 성능 | 활용 사례 |
|---|---|---|
| 추론 | AIME 92.7%, MATH 88% | 수학 증명, 과학적 추론, 논리 분석 |
| 코딩 | HumanEval 90%, SWE-bench 77.8% | 코드 생성, 버그 수정, 아키텍처 설계 |
| 에이전트(Agent) | HLE w/ Tools 50.4% | 도구 호출, 작업 계획, 자율 실행 |
| 지식 | MMLU 85%, GPQA 68.2% | 학과 질의응답, 기술 컨설팅, 지식 추출 |
| 지시어 이행 | IFEval 88% | 포맷팅 출력, 구조화된 생성, 규칙 준수 |
| 정확성 | 환각 현상 56% 감소 | 문서 요약, 사실 확인, 정보 추출 |
GLM-5 오픈 소스 생태계의 가치
GLM-5는 Apache-2.0 라이선스로 오픈 소스화되었습니다. 이는 다음과 같은 이점을 제공합니다.
- 상업적 자유: 기업은 라이선스 비용 없이 무료로 사용, 수정 및 배포할 수 있습니다.
- 미세 조정(Fine-tuning) 맞춤화: GLM-5를 기반으로 특정 도메인에 맞춰 미세 조정을 진행하여 산업 전용 모델을 구축할 수 있습니다.
- 프라이빗 배포: 민감한 데이터가 내부 네트워크를 벗어나지 않아 금융, 의료, 정부 기관 등의 보안 규정 요구사항을 충족합니다.
- 커뮤니티 생태계: HuggingFace에는 이미 11개 이상의 양자화 변체와 7개 이상의 미세 조정 버전이 존재하며, 생태계가 지속적으로 확장되고 있습니다.
GLM-5는 Zhipu AI의 최신 플래그십 모델로서, 오픈 소스 대규모 언어 모델 분야에서 새로운 이정표를 세웠습니다.
- 744B MoE 아키텍처: 256개 전문가 시스템을 갖추고 있으며, 추론 시마다 40B 파라미터를 활성화하여 모델 용량과 추론 효율성 사이의 뛰어난 균형을 유지합니다.
- 오픈 소스 최강 에이전트: HLE w/ Tools 50.4%로 Claude Opus를 능가하며, 장기 에이전트 워크플로우를 위해 설계되었습니다.
- 국산 컴퓨팅 자원 훈련: 10만 개의 화웨이 어센드(Ascend) 칩을 기반으로 훈련되어, 국산 컴퓨팅 스택의 최첨단 모델 훈련 능력을 입증했습니다.
- 높은 가성비: 입력 $1/M, 출력 $3.2/M으로 동급 폐쇄형 모델보다 훨씬 저렴하며, 오픈 소스 커뮤니티에서 자유롭게 배포하고 미세 조정할 수 있습니다.
- 200K 초장문 컨텍스트: 전체 코드 베이스와 대규모 기술 문서를 한 번에 처리할 수 있으며, 최대 128K 토큰 출력을 지원합니다.
- 56% 낮은 환각률: Slime 비동기 RL(강화 학습) 사후 훈련을 통해 사실 정확도를 대폭 향상시켰습니다.
APIYI(apiyi.com)를 통해 GLM-5의 다양한 기능을 빠르게 체험해 보시는 것을 추천합니다. 플랫폼 가격은 공식 가격과 동일하며, 충전 추가 증정 이벤트를 통해 약 20% 할인된 혜택을 누리실 수 있습니다.
본 문서는 APIYI Team 기술팀에서 작성하였습니다. 더 많은 AI 모델 사용 튜토리얼은 APIYI(apiyi.com) 도움말 센터를 확인해 주세요.