저자 주: 코딩, 추론, 멀티모달, 지식 작업, 가격의 5대 핵심 지표를 통해 Gemini 3.1 Pro와 Claude Sonnet 4.6을 비교 분석하여, 여러분에게 가장 적합한 고가성비 최첨단 모델을 추천해 드립니다.
2026년 2월의 AI 모델 판도는 매우 흥미로운 국면에 접어들었습니다. 이제 진정한 경쟁은 '누가 가장 강력한가'가 아니라 '누가 가성비 왕인가'의 싸움입니다. 구글의 Gemini 3.1 Pro(2월 19일 출시)와 앤스로픽의 Claude Sonnet 4.6(2월 17일 출시)이 거의 동시에 공개되었습니다. 두 모델 모두 플래그십급 성능을 갖추면서도 가격은 합리적으로 책정되어, 개발자들의 고민이 그 어느 때보다 깊어지고 있습니다.
핵심 가치: 이 글을 읽고 나면 코딩, 추론, 멀티모달, 지식 작업에서 두 모델의 실제 성능 차이가 무엇인지, 그리고 여러분의 구체적인 사용 환경에 어떤 모델이 더 적합한지 명확하게 알 수 있습니다.

Gemini 3.1 Pro vs Claude Sonnet 4.6 기본 파라미터 비교
두 모델의 포지셔닝은 매우 유사합니다. 모두 '플래그십에 근접한 성능, 플래그십보다 훨씬 저렴한 가격'을 지향하는 실력파들이지만, 기술적 접근 방식은 확연히 다릅니다.
| 파라미터 비교 | Gemini 3.1 Pro | Claude Sonnet 4.6 | 비교 설명 |
|---|---|---|---|
| 출시일 | 2026.02.19 | 2026.02.17 | 단 2일 차이 |
| 컨텍스트 윈도우 | 100만 (표준) | 20만 표준 / 100만 Beta | Gemini 네이티브 100만 컨텍스트 |
| 최대 출력 | 64K tokens | 64K tokens | 완전 일치 |
| 입력 가격 | $2/백만 토큰 | $3/백만 토큰 | ✅ Gemini가 33% 저렴 |
| 출력 가격 | $12/백만 토큰 | $15/백만 토큰 | ✅ Gemini가 20% 저렴 |
| 긴 컨텍스트 입력가 | $4 (>200K) | $3 (불변) | ⚠️ 긴 컨텍스트에서는 Sonnet이 더 저렴 |
| 긴 컨텍스트 출력가 | $18 (>200K) | $15 (불변) | ⚠️ 긴 컨텍스트에서는 Sonnet이 더 저렴 |
| 입력 모달리티 | 텍스트, 이미지, 오디오, 비디오, PDF | 텍스트, 이미지, PDF | ✅ Gemini의 멀티모달 지원이 더 포괄적 |
| 추론 모드 | 3단계 사고 (Low/Med/High) | 자가 적응형 사고 (동적 조절) | 설계 철학의 차이 |
| 프롬프트 캐싱 | 지원 | 캐시 읽기 단 $0.30/백만 (90% 절감) | ✅ Sonnet 캐싱으로 비용 절감 효과 큼 |
🎯 가격 책정의 핵심 디테일: 200K 이내의 일반적인 상황에서는 Gemini 3.1 Pro가 더 저렴합니다($2/$12 vs $3/$15). 하지만 컨텍스트가 200K를 넘어서는 순간 Gemini의 가격이 $4/$18로 인상되어, 오히려 Sonnet 4.6의 $3/$15보다 비싸집니다. 여러분의 평균 컨텍스트 길이가 어떤 모델이 더 경제적인지를 결정하는 핵심 요소입니다.
Gemini 3.1 Pro와 Sonnet 4.6 벤치마크 전격 비교
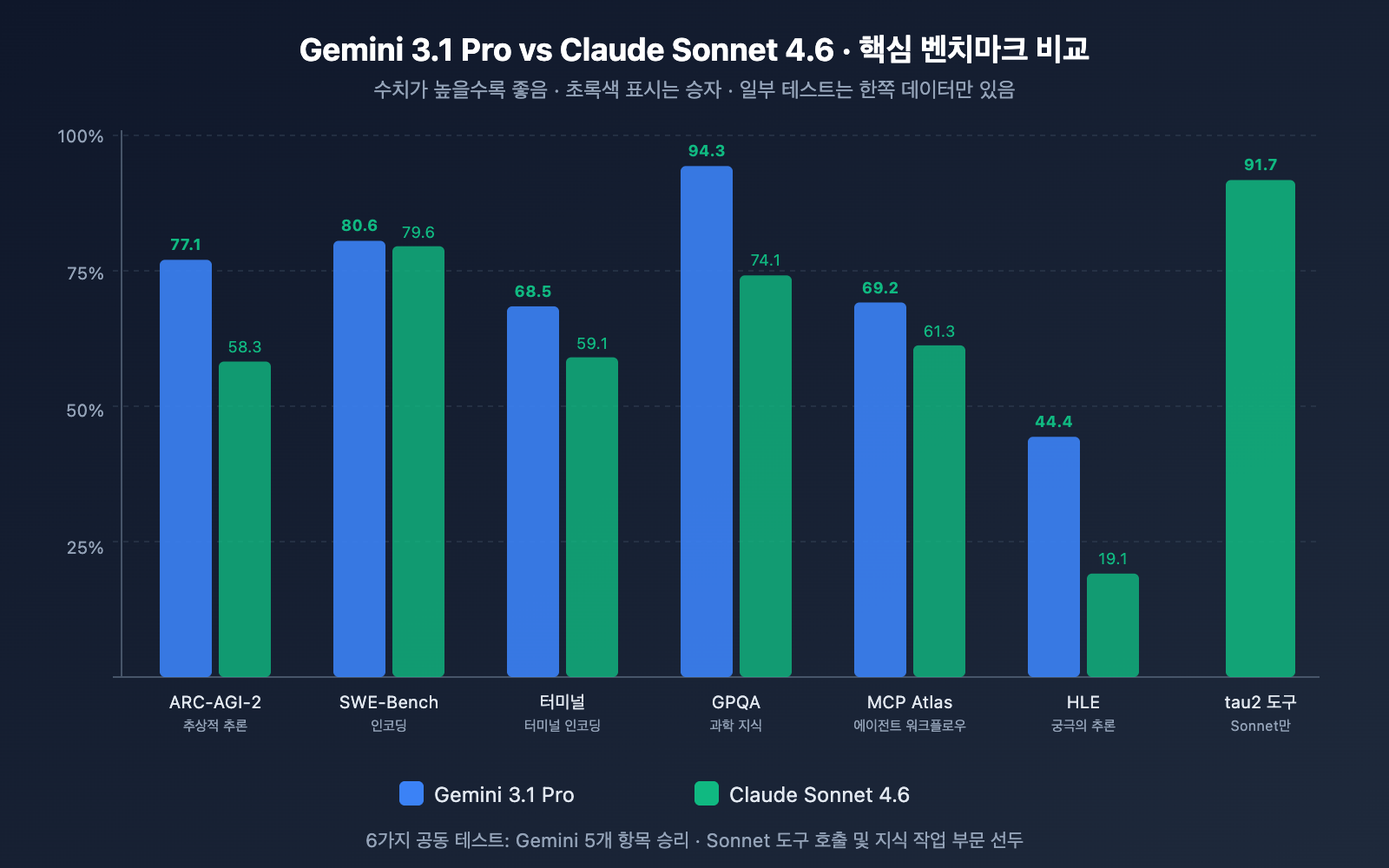
코딩 능력 비교
| 코딩 테스트 | Gemini 3.1 Pro | Claude Sonnet 4.6 | 승자 |
|---|---|---|---|
| SWE-Bench Verified | 80.6% | 79.6% | ✅ Gemini 1.0점 우세 |
| SWE-Bench Pro | 54.2% | 42.7% | ✅ Gemini 11.5점 우세 |
| Terminal-Bench 2.0 | 68.5% | 59.1% | ✅ Gemini 9.4점 우세 |
분석: Gemini 3.1 Pro가 세 가지 코딩 테스트에서 모두 앞서고 있습니다. 특히 복잡한 실제 코드 작업을 다루는 SWE-Bench Pro에서는 11.5점, 터미널 환경 코딩인 Terminal-Bench에서는 9.4점의 큰 격차를 보였습니다. 다만, Sonnet 4.6은 Replit의 프로덕션 코드 편집 내부 테스트에서 오류율 0%를 기록했고 GitHub Copilot의 코딩 에이전트 기본 모델로 선정된 만큼, 실제 개발 환경에서의 체감 성능은 벤치마크 결과보다 더 뛰어날 수 있습니다.
추론 능력 비교
| 추론 테스트 | Gemini 3.1 Pro | Claude Sonnet 4.6 | 승자 |
|---|---|---|---|
| ARC-AGI-2 (추상적 추론) | 77.1% | 58.3% | ✅ Gemini 18.8점 우세 |
| GPQA Diamond (과학) | 94.3% | 74.1% | ✅ Gemini 20.2점 우세 |
| HLE (심화 추론) | 44.4% | 19.1% | ✅ Gemini 25.3점 우세 |
| MATH-500 | – | 97.8% | Sonnet 수학 능력 탁월 |
분석: 추론 능력은 두 모델 간의 격차가 가장 크게 벌어지는 영역입니다. Gemini 3.1 Pro는 ARC-AGI-2, GPQA Diamond, HLE 세 가지 테스트에서 18점에서 25점 차이로 압도적인 우위를 점했습니다. 여기서 주목할 점은 Gemini 3.1 Pro의 추론 점수가 3단계 사고 시스템의 'High' 모드에서 얻은 결과라는 것입니다. 반면 Sonnet 4.6의 적응형 사고는 추론 깊이 면에서 Opus 4.6에 미치지 못하는 모습입니다. 순수 추론 성능이 핵심이라면 Gemini 3.1 Pro가 확실히 유리합니다.
지식 업무 및 에이전트 능력 비교
| 테스트 | Gemini 3.1 Pro | Claude Sonnet 4.6 | 승자 |
|---|---|---|---|
| GDPval-AA Elo (지식 업무) | 1,317 | 1,633 | ✅ Sonnet 316점 우세 |
| Finance Agent (금융 분석) | – | 63.3% | Sonnet 데이터 우세 |
| OSWorld (운영체제 제어) | – | 72.5% | Sonnet 데이터 우세 |
| MCP Atlas (다단계 워크플로) | 69.2% | 61.3% | ✅ Gemini 7.9점 우세 |
| tau2-bench Retail (도구 호출) | – | 91.7% | Sonnet 데이터 우세 |
분석: 이 영역에서는 흥미로운 반전이 일어납니다. 실제 전문가 수준의 지식 업무를 시뮬레이션하는 GDPval-AA에서 Sonnet 4.6은 1,633 Elo를 기록하며 Gemini 3.1 Pro(1,317)는 물론, 자사 플래그십인 Opus 4.6(1,559)까지 제쳤습니다. 이는 연구 분석, 보고서 작성, 비즈니스 전략 등 고부가가치 지식 업무 시나리오에서 Sonnet 4.6이 현재 모든 모델 중 가장 뛰어난 성능을 보여준다는 것을 의미합니다. 심지어 5배 더 비싼 Opus 4.6보다도 말이죠.
Gemini 3.1 Pro와 Sonnet 4.6의 시나리오별 선택 제안
두 모델의 장단점은 매우 상호 보완적입니다. 따라서 '어느 것이 더 나은가'보다 '어떤 상황에서 사용하는가'가 훨씬 더 중요해요.

Gemini 3.1 Pro를 선택해야 하는 경우
- 알고리즘 및 경진 대회 코딩: LiveCodeBench Elo 2,887점을 기록하며, 알고리즘 관련 코딩에서 압도적인 우위를 점하고 있습니다.
- 복잡한 추론 및 과학 연구: ARC-AGI-2 77.1%, GPQA Diamond 94.3% 등 순수 추론 능력은 Sonnet 4.6보다 한 단계 높은 수준입니다.
- 멀티모달 처리: 비디오(1시간), 오디오(8.4시간)를 네이티브로 지원합니다. Sonnet 4.6은 이를 지원하지 않습니다.
- MCP 에이전트 워크플로우: MCP Atlas 69.2%(7.9점 리드)를 기록하여, 다단계 에이전트 시스템 구축 시 더 높은 신뢰성을 보여줍니다.
- 짧은 컨텍스트의 빈번한 호출: 200K 이내에서 $2/$12의 가격으로 책정되어 두 모델 중 더 경제적인 선택입니다.
Claude Sonnet 4.6을 선택해야 하는 경우
- 전문가급 지식 작업: GDPval-AA 1,633 Elo로 현재 모든 모델 중 최고점을 기록했습니다. 연구 보고서, 금융 분석, 비즈니스 전략 등의 시나리오에서 독보적입니다.
- 프로덕션 코드 편집: Replit 프로덕션 환경 테스트에서 오류율 0%를 기록했으며, GitHub Copilot의 코딩 에이전트 기반 모델로 선정되었습니다.
- 도구 호출 및 Computer Use: tau2-bench 91.7%, OSWorld 72.5%를 기록하며 자동화 작업 및 함수 호출에서 매우 높은 정밀도를 자랑합니다.
- 긴 컨텍스트 시나리오: 200K 이상의 컨텍스트를 사용할 때 Sonnet 4.6은 $3/$15로 Gemini의 $4/$18보다 저렴합니다.
- 기업용 애플리케이션: 더욱 성숙한 안전 정렬, 프롬프트 캐싱(읽기 비용 $0.30/1M 토큰으로 90% 절감), 배치 처리 반값 혜택 등을 제공합니다.
Gemini 3.1 Pro 및 Claude Sonnet 4.6 API 빠른 연동
초간단 예제
APIYI 플랫폼을 통해 두 모델을 하나의 통합 인터페이스로 사용할 수 있습니다.
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# Gemini 3.1 Pro - 추론 및 멀티모달 성능 강화
response = client.chat.completions.create(
model="gemini-3.1-pro",
messages=[{"role": "user", "content": "이 코드의 시간 복잡도를 분석하고 최적화해 줘"}]
)
print(response.choices[0].message.content)
Sonnet 4.6 호출 및 시나리오별 자동 전환 예제 보기
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# Claude Sonnet 4.6 - 지식 작업 및 도구 호출 성능 강화
response = client.chat.completions.create(
model="claude-sonnet-4-6",
messages=[{"role": "user", "content": "경쟁사 비교 및 성장 제안을 포함한 1분기 시장 분석 보고서 작성"}]
)
print(response.choices[0].message.content)
# 시나리오별 자동 라우팅
def route_model(prompt, task_type="general"):
model_map = {
"reasoning": "gemini-3.1-pro",
"multimodal": "gemini-3.1-pro",
"algorithm": "gemini-3.1-pro",
"knowledge": "claude-sonnet-4-6",
"production_code": "claude-sonnet-4-6",
"tool_call": "claude-sonnet-4-6",
"general": "gemini-3.1-pro",
}
return client.chat.completions.create(
model=model_map.get(task_type, "gemini-3.1-pro"),
messages=[{"role": "user", "content": prompt}]
)
팁: APIYI(apiyi.com) 플랫폼을 이용하면 하나의 API 키로 두 모델을 동시에 연동하고 전환하며 사용할 수 있습니다. 플랫폼에서 무료 테스트 크레딧을 제공하니, 실제 프로젝트 환경에서 직접 성능을 비교해 보세요.
Gemini 3.1 Pro vs Sonnet 4.6 비용 심층 비교
세 가지 대표적인 사용 시나리오별 월간 예상 비용입니다.
| 사용 시나리오 | 월평균 토큰 소모량 | Gemini 3.1 Pro | Claude Sonnet 4.6 | 더 저렴한 쪽 |
|---|---|---|---|---|
| 가벼운 사용 (입력 500만 + 출력 100만) | 600만 | $22 | $30 | Gemini 27% 절약 |
| 보통 사용 (입력 2,000만 + 출력 500만) | 2,500만 | $100 | $135 | Gemini 26% 절약 |
| 헤비한 긴 컨텍스트 (입력 5,000만 >200K + 출력 1,000만) | 6,000만 | $380 | $300 | ⚠️ Sonnet 21% 절약 |
🎯 비용 결론: 일반적인 사용 환경에서는 Gemini 3.1 Pro가 약 26
27% 더 저렴합니다. 하지만 전체 코드베이스 분석이나 장문 문서 처리와 같이 200K 이상의 긴 컨텍스트를 빈번하게 사용한다면 Sonnet 4.6이 오히려 더 경제적입니다. Gemini는 긴 컨텍스트에서 가격이 $4/$18로 인상되는 반면, Sonnet은 $3/$15를 유지하기 때문입니다. 여기에 Sonnet의 프롬프트 캐싱(읽기 비용 100만 토큰당 단 $0.30)까지 활용하면 실제 비용은 3050% 더 낮아질 수 있습니다.
APIYI(apiyi.com) 플랫폼을 통해 접속하면 추가 할인 혜택을 받을 수 있어, 두 모델의 사용 비용을 더욱 효과적으로 낮출 수 있습니다.
자주 묻는 질문(FAQ)
Q1: Sonnet 4.6의 GDPval-AA 점수가 자사 모델인 Opus 4.6보다 높게 나왔는데, 이게 정상인가요?
네, 실제로 그렇습니다. Sonnet 4.6은 GDPval-AA에서 1,633 Elo를 기록하며 Opus 4.6의 1,559점을 넘어섰습니다. Anthropic 측에서도 이 데이터를 공식 확인했는데요. 이는 Sonnet 4.6이 기업용 지식 작업 시나리오에 맞춰 특화된 최적화를 거쳤기 때문으로 보입니다. 반면 Opus 4.6은 범용적인 추론과 긴 컨텍스트 처리에 더 중점을 두고 있죠. 개발자들의 선호도 역시 Sonnet 4.5 대비 70%, Opus 4.5 대비 59%에 달할 정도로 Sonnet 4.6에 대한 평가가 매우 높습니다.
Q2: AI 에이전트를 만들기에 어떤 모델이 더 적합한가요?
에이전트의 성격에 따라 다릅니다. 만약 MCP(Model Context Protocol) 기반의 다단계 워크플로우 에이전트라면, MCP Atlas에서 69.2%를 기록하며 7.9점 차이로 앞선 Gemini 3.1 Pro를 추천해요. 하지만 도구 호출(Tool use)이 잦은 에이전트(예: OpenClaw)라면 tau2-bench 91.7%를 기록한 Sonnet 4.6이 더 안정적입니다. 브라우저나 데스크톱을 직접 제어하는 Computer Use 유형의 에이전트라면 OSWorld 72.5%라는 역대급 성적을 낸 Sonnet 4.6이 현재로선 최선의 선택입니다. 두 모델 모두 APIYI(apiyi.com) 플랫폼에서 바로 연결해 테스트해 보실 수 있습니다.
Q3: 현재 Sonnet 4.5를 사용 중인데, Sonnet 4.6으로 업그레이드해야 할까요, 아니면 Gemini 3.1 Pro로 갈아타야 할까요?
만약 현재 Sonnet 4.5의 지식 작업이나 코딩 경험에 만족하고 계신다면, Sonnet 4.6으로 업그레이드하는 것이 가장 합리적입니다. API 호환성이 유지되고 가격도 동일하면서, 성능은 전반적으로 크게 향상되었기 때문이죠(SWE-Bench 77.2% → 79.6%, ARC-AGI-2 13.6% → 58.3%로 약 4.3배 상승). 하지만 핵심 니즈가 추론, 멀티모달, 혹은 알고리즘 코딩 쪽에 치우쳐 있다면 Gemini 3.1 Pro가 확실한 강점을 가집니다. APIYI(apiyi.com) 플랫폼을 통해 두 모델을 모두 사용해 보시고 결정하시는 것을 추천드려요.
요약
Gemini 3.1 Pro와 Claude Sonnet 4.6 비교의 핵심 결론은 다음과 같습니다.
- 추론과 멀티모달은 Gemini 3.1 Pro: ARC-AGI-2에서 18.8점, GPQA Diamond에서 20.2점 앞서며, 네이티브 비디오/오디오 지원 및 짧은 컨텍스트에서 더 저렴한 비용을 자랑합니다.
- 지식 작업과 실무 코딩은 Claude Sonnet 4.6: GDPval-AA 1,633 Elo로 모든 모델 중 최고점(Opus 4.6 포함)을 기록했으며, Replit 0% 오류율로 GitHub Copilot이 선택한 최고의 모델입니다.
- 긴 컨텍스트 시나리오는 Sonnet이 유리: 200K 이상의 컨텍스트 사용 시 Sonnet($3/$15)이 Gemini($4/$18)보다 저렴하며, 프롬프트 캐싱을 활용하면 비용을 30%~50% 더 절감할 수 있습니다.
이 두 모델은 2026년 2월 현재 가성비가 가장 뛰어난 최첨단 모델들입니다. 가장 좋은 전략은 상황에 맞춰 두 모델을 혼용하는 것인데요. APIYI(apiyi.com)를 통해 하나의 API 키로 필요에 따라 모델을 전환하며 사용해 보시길 추천합니다.
📚 참고 자료
-
Claude Sonnet 4.6 출시 공지: Anthropic 공식 블로그
- 링크:
anthropic.com/news/claude-sonnet-4-6 - 설명: Sonnet 4.6의 전체 기능 소개, 벤치마크 데이터 및 적응형 사고(Adaptive Thinking) 기능
- 링크:
-
Gemini 3.1 Pro 공식 블로그: Google DeepMind 출시 공지
- 링크:
blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-pro/ - 설명: Gemini 3.1 Pro의 3단계 사고 시스템 및 전체 성능 데이터
- 링크:
-
Tom's Guide 실측 비교: 7가지 고난도 테스트: Gemini 3.1 Pro vs Sonnet 4.6
- 링크:
tomsguide.com/ai/i-tested-gemini-3-1-pro-vs-claude-sonnet-4-6-in-7-tough-challenges-and-there-was-one-clear-winner - 설명: 실제 작업 시나리오에서의 성능 비교
- 링크:
-
Artificial Analysis 순위표: 제3자 독립 모델 평가 플랫폼
- 링크:
artificialanalysis.ai/leaderboards/models - 설명: 객관적인 성능, 속도, 가격 비교 데이터
- 링크:
작성자: 기술 팀
기술 교류: 댓글을 통해 여러분의 사용 경험을 공유해 주세요. 더 많은 AI 모델 정보는 APIYI(apiyi.com)에서 확인하실 수 있습니다.