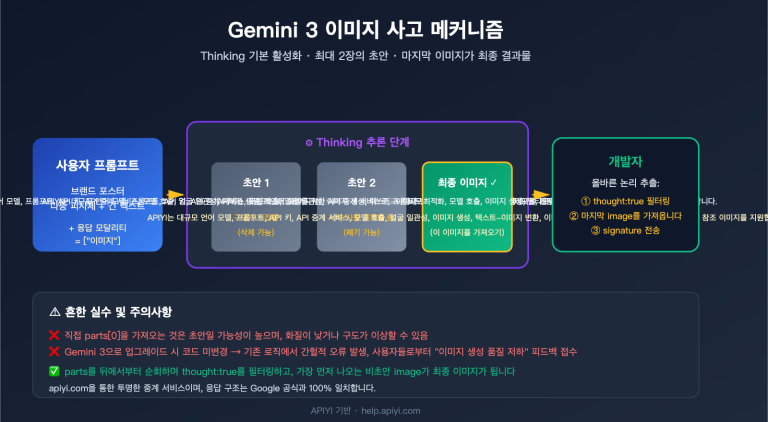
“gemini-3.1-flash-lite-image가 도대체 추론 모드를 지원하긴 하나요?”는 최근 API 호출 그룹에서 가장 많이 나오는 질문 중 하나예요. 답은 예예요. 그리고 이건 추측이 아니에요. Google 공식 문서를 함께 확인하고, APIYI 게이트웨이를 통해 세 가지 대조 실험을 진행해 실제 token 소모량과 지연 시간을 측정했어요. 이 글에서는 파라미터 구조, 실측 데이터, 과금 규칙 세 가지 관점에서 thinkingLevel 스위치를 자세히 설명할게요.
핵심 가치: 이 글을 읽고 나면 gemini-3.1-flash-lite-image의 추론 모드를 어떻게 켜는지, 켰을 때 token이 얼마나 더 드는지, 그리고 어떤 상황에서 그 지연 시간을 감수할 만한지 분명하게 알 수 있어요.

gemini-3.1-flash-lite-image 추론 모드 핵심 결론
먼저 결론부터 말하고, 그다음에 자세히 설명할게요. Google 공식 문서에는 gemini-3.1-flash-image와 gemini-3.1-flash-lite-image를 통해 개발자가 모델이 사용하는 사고량을 제어할 수 있다고 명시돼 있어요. 즉, flash-lite 단계에도 추론 능력이 내장돼 있다는 뜻이고, 플래그십 모델만 가능한 건 아니에요. 다만 모든 이미지 모델이 이 파라미터를 지원하는 건 아니니, 아래 표에서 세 가지 주요 Gemini 이미지 모델의 지원 여부를 비교해볼게요.
| 모델 | thinkingLevel 지원 여부 | 조절 가능한 단계 | 기본 단계 | 비고 |
|---|---|---|---|---|
| gemini-3.1-flash-image | ✅ 지원 | minimal / high | minimal | 공식 문서에 명확히 표기됨 |
| gemini-3.1-flash-lite-image | ✅ 지원 | minimal / high | minimal | flash-image와 같은 thinkingConfig를 사용함 |
| gemini-3-pro-image | ⚠️ 파라미터 무효 | 고정, 조절 불가 | 내부 고정 | high를 넣어도 오류는 없지만 실측 변화 없음 |
특히 thinkingLevel은 두 단계만 선택할 수 있어요. 텍스트 모델처럼 연속적으로 사고 예산을 조절하는 방식은 아니에요. 공식 원문에서도 “minimal thinking은 모델이 전혀 생각하지 않는다는 뜻이 아니다”라고 설명해요. 즉, 기본 단계에서도 모델 내부에서는 어느 정도의 기초 추론이 이뤄지지만, high 단계처럼 여러 번 구성을 검증하지는 않는 거예요.
이 점은 업계 흐름에서도 꽤 의미가 커요. 더 이른 세대의 이미지 생성 모델, 예를 들면 nano banana나 초창기 flash-image에서는 공식 API가 이런 추론 단계 파라미터를 공개하지 않았어요. 모델은 고정된 전략으로 이미지를 만들거나, 구성상 부족한 부분을 프롬프트 엔지니어링으로 보완해야 했죠. 그런데 3.1 세대에 와서는 Google이 “먼저 계획하고, 그다음 생성하는” 추론 메커니즘을 flash 계열에 열어줬어요. 본질적으로는 텍스트 모델에서 먼저 검증된 사고 패턴을 이미지 생성 영역으로 옮겨온 셈이에요. 이런 배경을 이해하면 앞으로 다른 업체의 이미지 모델도 같은 방향으로 갈지 판단하는 데 도움이 돼요.
🎯 기술 조언: APIYI apiyi.com을 통해 Gemini 이미지 계열 모델을 호출하고 있다면, 먼저 기본 minimal 단계로 업무 흐름을 안정적으로 돌려본 뒤 실제 이미지 품질을 보고 high로 전환할지 결정하는 걸 추천해요. 이 플랫폼은 통합 인터페이스를 제공해서 gemini-3.1-flash-image, flash-lite-image, pro-image를 같은 코드로 바꿔가며 호출할 수 있어 A/B 비교를 하기에 편해요.
thinkingLevel 매개변수 상세 설명과 호출 방식
thinkingLevel은 독립된 매개변수가 아니라, generationConfig 아래에 중첩된 thinkingConfig 객체 안에 들어가며 includeThoughts와 함께 사용해요. includeThoughts는 모델의 생각 요약을 호출자에게 반환할지 결정하고, thinkingLevel은 생각의 “강도”를 정해요. 둘은 서로 분리된 두 개의 스위치이니 혼동하지 마세요.

아래 표는 thinkingConfig 객체 안의 두 핵심 필드의 타입과 값 범위를 정리한 거예요.
| 필드 | 타입 | 가능한 값 | 기본값 | 역할 |
|---|---|---|---|---|
| thinkingLevel | 열거형 문자열 | minimal / high |
minimal |
모델의 추론 강도를 제어해요. flash 계열 이미지 모델에서만 적용돼요 |
| includeThoughts | 불리언 | true / false |
false |
응답에 생각 과정 요약을 반환할지 여부를 정해요. 과금에는 영향을 주지 않아요 |
실제 호출할 때는 세 가지 주요 언어 모두 구조가 완전히 같고, config 안에 thinkingConfig 객체를 넣는 방식이에요. Python 예시는 아래처럼 작성해요.
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # APIYI 통합 게이트웨이를 통해 호출
)
response = client.chat.completions.create(
model="gemini-3.1-flash-lite-image",
messages=[{"role": "user", "content": "산맥 아래에서 커피를 마시는 고양이를 그려줘"}],
extra_body={
"thinkingConfig": {
"thinkingLevel": "high",
"includeThoughts": True
}
}
)
print(response.choices[0].message.content)
REST 원본 호출 전체 예시 보기
{
"contents": [{"parts": [{"text": "산맥 아래에서 커피를 마시는 고양이를 그려줘"}]}],
"generationConfig": {
"responseModalities": ["IMAGE"],
"thinkingConfig": {
"thinkingLevel": "high",
"includeThoughts": true
}
}
}
JavaScript SDK도 구조는 같고, REST의 snake 스타일만 camelCase의 thinkingConfig 객체로 바뀌어요. 그 외 필드명은 변하지 않아요. 세 언어의 호출 로직에 본질적인 차이는 없고, “thinkingConfig는 generationConfig 아래에만 둔다”는 규칙만 기억하면 돼요.
한 가지 주의할 점도 있어요. thinkingLevel 값은 대소문자를 구분하는 문자열 열거형인데, 공식 예시에는 "High"와 "high"가 섞여 나온 적이 있어요. 실제 테스트에서는 두 방식 모두 게이트웨이에서 정상 인식됐지만, 문서화되지 않은 호환성에 기대는 건 피하는 게 좋아요. 실무 코드에서는 "high"와 "minimal"처럼 소문자로 통일하면, 나중에 상위 서비스가 대소문자 검사를 더 엄격하게 해도 문제없이 쓸 수 있어요.
추천: APIYI apiyi.com에서 무료 테스트 크레딧을 받아보세요. 게이트웨이에서 thinkingConfig가 제대로 전달되는지 바로 검증할 수 있어서, 직접 공식 Key를 발급받아 디버깅하는 것보다 훨씬 편해요.
APIYI 실측 데이터: thinkingLevel이 토큰과 지연 시간에 미치는 실제 영향
문서가 아무리 잘 정리돼 있어도, 실제 데이터를 한 번 보는 것만큼 직관적인 건 없어요. 같은 프롬프트를 사용해서 1K 해상도 텍스트-이미지 변환을 기준으로, APIYI 게이트웨이를 통해 gemini-3.1-flash-image의 minimal 기본값, high 설정, 그리고 gemini-3-pro-image에 high를 강제로 넣은 세 가지 경우를 테스트했어요.
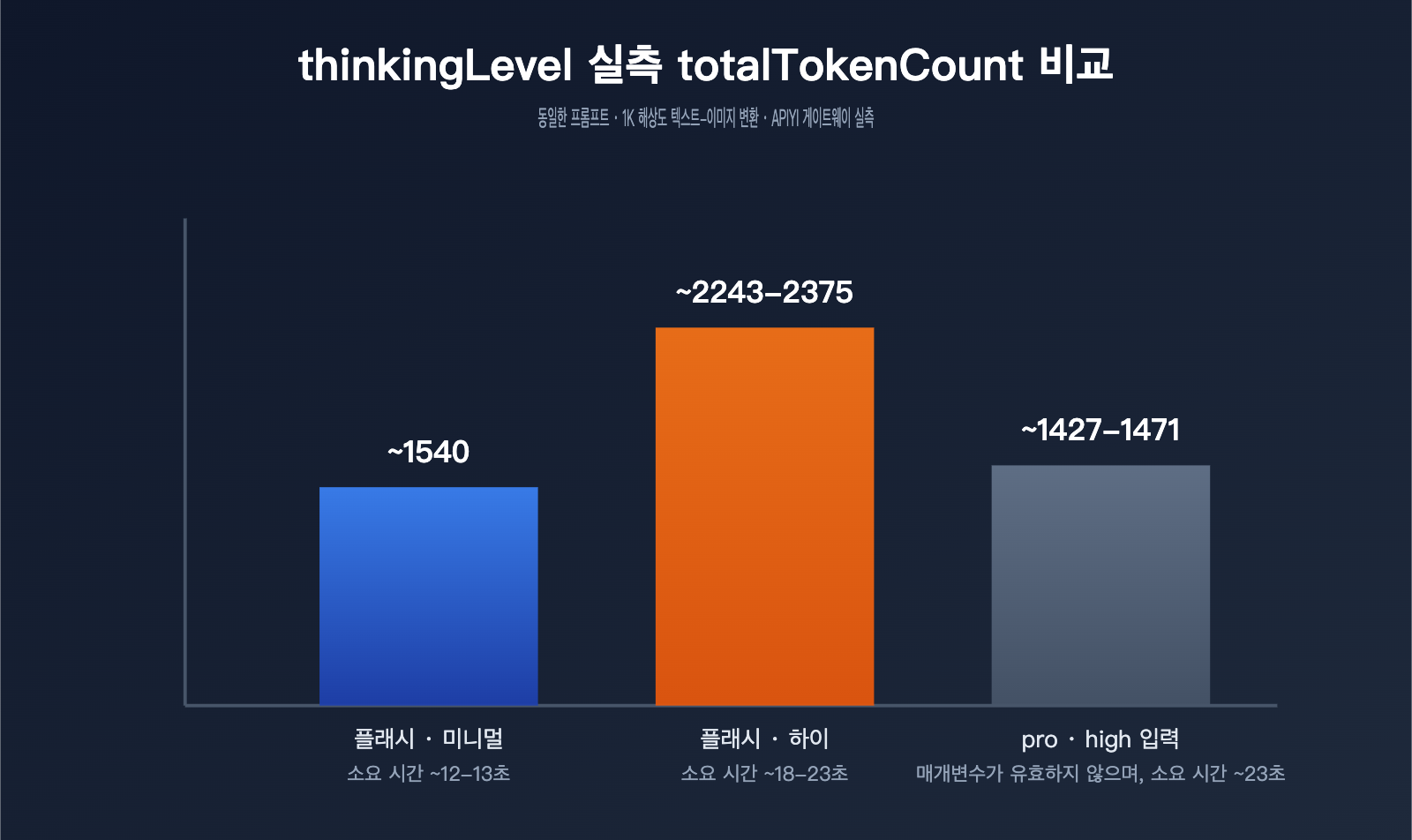
| 모델 / 설정 | thoughtsTokenCount | 이미지 tokens | totalTokenCount | 소요 시간 |
|---|---|---|---|---|
| gemini-3.1-flash-image · minimal(기본값) | 해당 필드 없음 | 1120 | 약 1540 | 약 12~13초 |
| gemini-3.1-flash-image · high | 700~792 | 1120 | 약 2243~2375 | 약 18~23초 |
| gemini-3-pro-image · high 전달 | 181~214(기본과 거의 동일) | 1120 | 약 1427~1471 | 약 23초 |
이 데이터에서 세 가지 중요한 패턴을 볼 수 있어요. 첫째, thinkingLevel을 high로 바꾸면 thoughtsTokenCount가 기본의 0에서 바로 700800대까지 올라가고, 응답에서 아예 이 필드가 보이지 않던 상태에서 크게 늘어나요. 전체 토큰 사용량도 약 50% 가까이 증가하고, 응답 지연도 1213초에서 1823초로 늘어나요. 즉, 더 많이 생각하게 하면 실제로 비용과 시간이 든다는 뜻이에요. 둘째, minimal이든 high든 최종 출력 이미지의 토큰 수는 항상 1120으로 같아요. 다시 말해 thinkingLevel은 모델이 어떻게 생각하는지에만 영향을 주고, 출력 이미지의 해상도나 이미지 자체의 과금에는 영향을 주지 않아요. 셋째, gemini-3-pro-image에 high를 넣어도 에러는 나지 않지만, 181214 정도의 생각 토큰은 기본과 거의 차이가 없어요. 이는 공식 문서에 나온 “pro-image는 생각 동작이 고정되어 있고 외부 조절을 지원하지 않는다”는 설명과 일치해요.
즉, 사업 로직에서 thinkingConfig를 공통으로 만들어 flash, flash-lite, pro 모델에 일괄 전달하더라도, pro-image는 이 값을 조용히 무시할 거예요. 에러로 호출이 끊기지는 않지만, 기대한 대로 추론 강도가 바뀌지도 않아요.
추가로 알아둘 점도 있어요. 위 데이터는 단 한 번 측정한 결과가 아니라, 같은 프롬프트를 각 설정으로 여러 번 호출한 뒤 얻은 범위예요. 그래서 high 설정의 thoughtsTokenCount가 700~792처럼 흔들릴 수 있어요. 생각형 작업은 본질적으로 어느 정도 랜덤성이 있어서, 모델이 매번 조금씩 다른 중간 추론 경로를 만들고, 그에 따라 토큰 소모도 약간씩 달라져요. 그래도 전체적인 규모와 지연 시간의 추세는 안정적으로 재현되며, high가 minimal보다 오히려 빠르다거나 토큰이 수천 단위로 급증하는 식의 이상 현상은 나오지 않아요.
이미지 모델의 생각 token과 과금 규칙
많은 개발자가 처음 thoughtsTokenCount 필드를 보면 텍스트 모델의 생각 비용과 비슷하다고 생각하기 쉬운데요, 이미지 모델의 생각 메커니즘은 사실 두 부분으로 나뉘어 과금돼요. 이 차이를 이해하면 비용을 훨씬 잘 관리할 수 있어요.
| 항목 | 텍스트 모델의 생각 | 이미지 모델의 생각 |
|---|---|---|
| 생각 산출물 형태 | 순수 텍스트 추론 체인 | 텍스트 요약 + 최대 2장의 임시 구성 스케치 |
| 생각 텍스트 token 규모 | 수천까지 가능 | Pro는 400 초과 없음, Flash high는 약 700-800 |
| 주요 비용 반영 필드 | thoughtsTokenCount | 스케치는 candidatesTokenCount에 포함, 일반 이미지 part로 과금 |
| 이미지 1장 스케치 과금 기준 | 해당 없음 | 1K 해상도 기준 약 1120 tokens, 약 0.0336달러/장 |
| includeThoughts가 과금에 미치는 영향 | 영향 없음, 고정 과금 | 영향 없음, 고정 과금 |
공식 문서에서도 특히 강조하는데요. includeThoughts를 true로 하든 false로 하든, 생각 과정에서 발생한 token은 그대로 과금돼요. 실측에서도 이 점이 확인됐는데, includeThoughts를 켜도 응답 구조와 총 과금에는 변화가 없고, 디버깅용으로 생각 요약 텍스트만 추가로 보이는 수준이었어요. 다시 말해 includeThoughts는 “볼지 말지”를 정하는 스위치일 뿐, “돈을 낼지 말지”를 정하는 스위치는 아니에요. 이 부분을 정말 쉽게 오해하더라고요.
더 주목할 점은, 이미지 모델의 생각 비용 핵심이 thoughtsTokenCount 자체가 아니라 추론 과정에서 생성되는 임시 구성 이미지에 있다는 거예요. 공식 문서에 따르면 모델은 생각 단계에서 최대 2장의 임시 이미지를 만들어 구도와 논리적 타당성을 점검하는데, 이 스케치는 일반 이미지 part로 반환되며 candidatesTokenCount에 포함되고 출력 이미지 기준 단가로 과금돼요. 즉, high 모드로 추론형 이미지 생성을 한 번 실행하면, 눈에 보이지 않는 스케치 비용이 1~2장 더 붙을 수 있다는 뜻이에요. 비용 예측할 때 이 부분을 빼먹기 쉬워요.
간단히 계산해 보면 더 직관적이에요. 예를 들어 1K 해상도 이미지 생성 요청을 high 모드로 보냈고, 생각 텍스트가 약 750 tokens를 사용했다고 해볼게요. 여기에 모델이 실제로 임시 스케치 2장을 생성했다면 최종 결과물까지 합쳐 총 3장의 이미지 part가 생기게 돼요. 장당 1120 tokens, 약 0.0336달러 기준으로 계산하면 출력 이미지 비용만 해도 거의 0.1달러에 가깝고, 여기에 생각 텍스트 비용까지 더해지죠. 전체 비용은 minimal 모드의 23배 수준이 될 수 있어요. 다만 실제로 2장의 스케치가 항상 생기는 건 아니고, 모델이 현재 프롬프트를 어떻게 판단하느냐에 따라 달라져요. 그래서 실측 총 token이 22432375처럼 범위로 나타나는 거예요. 정확히 두 배로 딱 떨어지지 않는 이유가 여기 있어요.
💰 비용 최적화: token 비용에 민감한 팀이라면, 먼저 APIYI apiyi.com 플랫폼의 호출 로그로 실제
totalTokenCount를 확인한 뒤 high 모드를 장기적으로 켤지 결정하는 게 좋아요. 스케치 과금을 놓치면 예산이 쉽게 초과될 수 있어요.
어떤 경우에 high를 쓰고, 어떤 경우에 기본 minimal을 쓸까
실측 데이터를 바탕으로 간단한 판단 기준을 정리해볼게요.

| 비즈니스 시나리오 | 추천 모드 | 이유 |
|---|---|---|
| 마케팅용 이미지를 대량 생성하고, 구도 정밀도 요구가 높지 않은 경우 | minimal(기본) | 지연이 더 낮고 token 비용도 통제하기 쉬워서 일상적인 이미지 생성에 충분해요 |
| 복잡한 다중 주체 구도, 또는 텍스트 배치나 공간 관계를 정확히 따라야 하는 경우 | high | 추가 생각으로 구도 정확도가 높아져서 품질에 비용을 지불할 가치가 있어요 |
| 이커머스 상세페이지, 배너처럼 디테일 허용오차가 낮은 경우 | high | 재작업과 재생성 횟수를 줄여서 전체적으로는 오히려 더 경제적일 수 있어요 |
| 응답 속도가 매우 중요한 실시간 인터랙션 | minimal | high 모드는 지연이 5~10초 길어질 수 있어 강한 인터랙션에는 맞지 않아요 |
gemini-3-pro-image를 호출하는 경우 |
설정 불필요 | 이 모델은 생각 동작이 고정되어 있어서 파라미터를 넣어도 적용되지 않아요 |
간단히 말하면, high 모드는 “속도보다 한 번에 잘 나오는 것”이 더 중요한 경우에 적합해요. 만약 앱이 반복 재시도를 자주 하거나, 프롬프트를 여러 번 조정해야 만족스러운 구도를 얻는다면 차라리 처음부터 high를 켜는 편이 나아요. 단가는 조금 올라가도 최초 성공률이 높아져서 전체적으로는 더 효율적일 수 있어요.
실무에서는 thinkingLevel을 코드에 하드코딩하지 말고 설정 가능한 항목으로 분리해두는 게 가장 안정적이에요. 예를 들어 API 호출 주체가 넘겨주는 업무 유형에 따라 자동으로 분기하는 방식이 좋아요. 배치 작업은 기본적으로 minimal, 정교한 레이아웃이나 다중 주체 공간 관계가 필요한 요청은 자동으로 high로 보내는 식이죠. 그러면 평균 비용은 관리하면서도 중요한 장면에서 품질을 놓치지 않을 수 있어요. 만약 팀에서 flash, flash-lite, pro 세 가지 모델 호출 로직을 함께 관리하고 있다면, 파라미터 래핑 단계에서 지원되는 모델에만 thinkingLevel을 넣도록 통일하는 걸 추천해요. 그래야 pro-image에 무효 파라미터가 전달돼서 생기는 디버깅 혼란을 줄일 수 있어요.
🚀 빠른 시작: APIYI apiyi.com 플랫폼을 사용하면 같은
base_url로 minimal과 high 설정을 손쉽게 바꿔가며 비교 테스트할 수 있어요. 서로 다른 모드마다 인증 정보를 따로 설정할 필요도 없어서 프로토타입을 빠르게 만들기 좋아요.
자주 묻는 질문
Q1: gemini-3.1-flash-lite-image와 gemini-3.1-flash-image의 추론 성능은 같나요?
둘 다 같은 thinkingConfig 파라미터 구조를 공유하고, 지원하는 단계도 minimal과 high로 같습니다. 다만 flash-lite는 경량 버전으로 포지셔닝되어 있어서, 실제 사고 깊이와 최종 이미지의 디테일은 보통 flash-image보다 약해요. 이름 규칙만 봐도 이 점이 드러나는데, flash-lite 계열은 텍스트 모델에서도 늘 “더 빠르고, 더 저렴하지만, 정확도는 조금 낮은” 쪽에 가깝게 설계되어 있고, 이미지 계열도 같은 선택을 이어가고 있어요. high 단계를 켜면 경량 모델의 복잡한 구도 처리 약점을 어느 정도 보완할 수는 있지만, flash-image 수준까지 완전히 따라잡기는 어렵습니다. 정량 비교를 하려면 APIYI apiyi.com 플랫폼에서 두 모델을 동시에 호출해 같은 프롬프트로 돌린 뒤 thoughtsTokenCount와 이미지 결과를 직접 비교해보면 돼요.
Q2: gemini-3-pro-image에 thinkingLevel 파라미터를 전달하면 오류가 나나요?
오류는 나지 않아요. 실측 결과, high 파라미터를 넣어도 요청은 정상적으로 반환되지만 thoughtsTokenCount는 181-214 구간에 머물렀고, 파라미터를 넣지 않았을 때와 거의 같았어요. 즉, 이 모델의 내부 사고 방식은 고정되어 있고 외부에서 조절할 수 없다는 뜻입니다. 여러 모델을 한꺼번에 호출하는 경우에는 비즈니스 코드에서 모델명을 따로 분기 처리해, 파라미터가 실제로 적용됐다고 오해하지 않도록 하는 게 좋아요.
Q3: `high` 단계로 설정하면 이미지 해상도나 품질 파라미터도 함께 조정해야 하나요?
그럴 필요는 없어요. 실측 데이터상 minimal과 high 두 단계의 이미지 token은 모두 1120으로 안정적으로 유지됐어요. 즉, thinkingLevel은 모델의 내부 추론 과정에만 영향을 주고, 출력 이미지의 해상도 설정은 바꾸지 않는다는 뜻입니다. 해상도는 여전히 imageConfig 안의 크기 파라미터로 따로 제어되며, 생각 단계와는 무관해요. 쉽게 말해 thinkingLevel과 해상도 파라미터는 서로 간섭하지 않는 두 개의 조절축이에요. 하나는 “얼마나 충분히 생각할지”, 다른 하나는 “얼마나 크고 세밀하게 그릴지”를 담당하므로, 서로 배타적이거나 연동되는 관계가 아닙니다.
요약
gemini-3.1-flash-lite-image는 실제로 추론 모드를 지원하며, 이 점은 공식 문서와 APIYI의 실측 데이터로 모두 확인됐어요. thinkingLevel은 minimal과 high 두 단계만 선택할 수 있고, high를 켜면 사고 token이 700 이상으로 올라가고 전체 소요 시간도 약 5-10초 늘어나지만, 최종 이미지의 token 소모는 바뀌지 않아요. 반면 gemini-3-pro-image는 이 파라미터를 받아도 오류는 나지 않지만 실제로는 적용되지 않습니다. “생각은 thoughtsTokenCount로, 구도 스케치는 candidatesTokenCount로 집계된다”는 이중 과금 구조를 이해하는 게 이미지 생성 비용을 관리하는 핵심이에요. 여러 Gemini 이미지 모델을 빠르게 전환하며 테스트해야 한다면, APIYI apiyi.com의 통합 게이트웨이를 이용해 보세요. 모델마다 별도 API 키를 발급받거나 호출 코드를 따로 유지할 필요가 없습니다.
이 글의 데이터는 APIYI 기술팀의 실측 결과를 바탕으로 작성됐어요. Gemini 이미지 모델의 더 자세한 호출 방식이 궁금하다면 APIYI apiyi.com을 통해 기술 지원에 문의해 보세요.
참고 자료
- Gemini API 공식 문서 – 이미지 생성: 사고 수준(thinking levels) 파라미터 설명
- 링크:
ai.google.dev/gemini-api/docs/generate-content/image-generation
- 링크: