Anmerkung des Autors: Vergleich von Gemini 3.1 Pro und Claude Sonnet 4.6 in den 5 Dimensionen Coding, Reasoning, Multimodalität, Wissensarbeit und Preisgestaltung, um Ihnen bei der Auswahl des kosteneffizientesten Spitzenmodells zu helfen.
Die KI-Modelllandschaft im Februar 2026 zeigt eine interessante Entwicklung: Der wahre Wettbewerb dreht sich nicht mehr darum, „wer der Stärkste ist“, sondern „wer der König der Preis-Leistung ist“. Googles Gemini 3.1 Pro (veröffentlicht am 19. Februar) und Anthropics Claude Sonnet 4.6 (veröffentlicht am 17. Februar) kamen fast zeitgleich auf den Markt, haben eine ähnliche Preisgestaltung und versprechen beide eine Leistung auf Flaggschiff-Niveau – Entwickler hatten noch nie eine so schwierige Wahl.
Kernwert: Nach der Lektüre dieses Artikels werden Sie die tatsächlichen Unterschiede zwischen den beiden Modellen in den Bereichen Coding, Reasoning, Multimodalität und Wissensarbeit kennen und wissen, welches Modell Sie für Ihr spezifisches Szenario wählen sollten.
Vergleich der Basisparameter: Gemini 3.1 Pro vs. Claude Sonnet 4.6
Die Positionierung beider Modelle ist sehr ähnlich – beide sind „Leistungsträger mit einer Performance nahe der Flaggschiff-Klasse zu einem deutlich niedrigeren Preis“, doch ihre technischen Ansätze sind grundlegend verschieden.
Parameter-Dimension
Gemini 3.1 Pro
Claude Sonnet 4.6
Vergleichsdetails
Veröffentlichungsdatum
19.02.2026
17.02.2026
Nur 2 Tage Unterschied
Kontextfenster
1 Million (Standard)
200k Standard / 1 Mio. Beta
Gemini bietet nativ 1 Mio. Kontext
Maximaler Output
64K Tokens
64K Tokens
Identisch
Eingabepreis
$2 / Mio. Token
$3 / Mio. Token
✅ Gemini ist 33 % günstiger
Ausgabepreis
$12 / Mio. Token
$15 / Mio. Token
✅ Gemini ist 20 % günstiger
Eingabepreis (langer Kontext)
$4 (>200K)
$3 (unverändert)
⚠️ Sonnet ist bei langem Kontext günstiger
Ausgabepreis (langer Kontext)
$18 (>200K)
$15 (unverändert)
⚠️ Sonnet ist bei langem Kontext günstiger
Eingabemodalitäten
Text, Bild, Audio, Video, PDF
Text, Bild, PDF
✅ Gemini ist multimodal umfassender
Reasoning-Modus
Drei Stufen (Low/Med/High)
Adaptives Reasoning (dynamisch)
Unterschiedliche Design-Philosophien
Prompt-Caching
Unterstützt
Lesezugriff nur $0,30/Mio. (90 % Ersparnis)
✅ Sonnet-Caching ist sparsamer
🎯 Wichtige Preisdetails: In gängigen Szenarien unter 200K ist Gemini 3.1 Pro günstiger ($2/$12 vs. $3/$15). Sobald der Kontext jedoch 200K überschreitet, steigt der Preis bei Gemini auf $4/$18, wodurch es teurer wird als Sonnet 4.6 mit $3/$15. Ihre durchschnittliche Kontextlänge entscheidet also direkt darüber, welches Modell wirtschaftlicher ist.
Umfassender Benchmark-Vergleich: Gemini 3.1 Pro vs. Sonnet 4.6
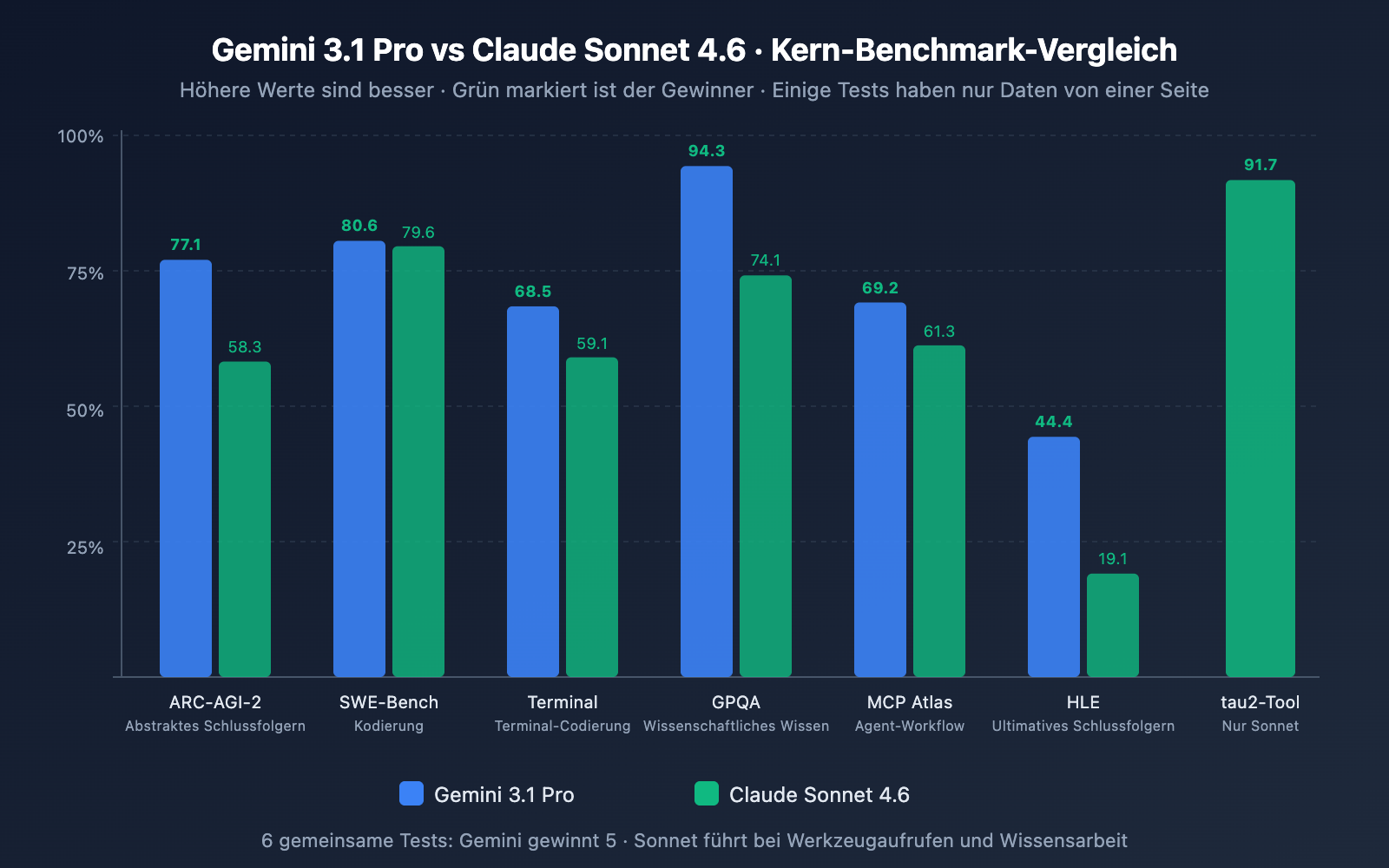
Vergleich der Coding-Fähigkeiten
Coding-Test
Gemini 3.1 Pro
Claude Sonnet 4.6
Gewinner
SWE-Bench Verified
80,6 %
79,6 %
✅ Gemini (+1,0 Pkt.)
SWE-Bench Pro
54,2 %
42,7 %
✅ Gemini (+11,5 Pkt.)
Terminal-Bench 2.0
68,5 %
59,1 %
✅ Gemini (+9,4 Pkt.)
Analyse: Gemini 3.1 Pro liegt in allen drei Coding-Tests vorn. Besonders bei SWE-Bench Pro (komplexere reale Code-Aufgaben) beträgt der Vorsprung 11,5 Punkte und bei Terminal-Bench (Coding in Terminal-Umgebungen) 9,4 Punkte. Es ist jedoch erwähnenswert, dass Sonnet 4.6 in internen Tests von Replit bei der Bearbeitung von Produktionscode eine Fehlerrate von 0 % erreichte und als Basismodell für den Coding-Agent von GitHub Copilot ausgewählt wurde – die tatsächliche Coding-Erfahrung in der Praxis könnte also enger beieinander liegen, als die Benchmarks vermuten lassen.
Vergleich der Reasoning-Fähigkeiten
Reasoning-Test
Gemini 3.1 Pro
Claude Sonnet 4.6
Gewinner
ARC-AGI-2 (Abstraktes Denken)
77,1 %
58,3 %
✅ Gemini (+18,8 Pkt.)
GPQA Diamond (Wissenschaft)
94,3 %
74,1 %
✅ Gemini (+20,2 Pkt.)
HLE (Ultimatives Reasoning)
44,4 %
19,1 %
✅ Gemini (+25,3 Pkt.)
MATH-500
–
97,8 %
Sonnet (starke Mathematik)
Analyse: Die Reasoning-Fähigkeit ist die Dimension mit dem größten Unterschied zwischen den beiden Modellen. Gemini 3.1 Pro führt in den Tests ARC-AGI-2, GPQA Diamond und HLE deutlich mit einem Vorsprung von 18 bis 25 Punkten. Hierbei muss angemerkt werden, dass Gemini 3.1 Pro seine Reasoning-Werte im „High“-Modus seines dreistufigen Thinking-Systems erzielt hat, während das adaptive Reasoning von Sonnet 4.6 in der Tiefe nicht ganz an Opus 4.6 heranreicht. Wenn reines Reasoning Ihre Kernanforderung ist, hat Gemini 3.1 Pro einen klaren Vorteil.
Vergleich: Wissensarbeit und Agent-Fähigkeiten
Test
Gemini 3.1 Pro
Claude Sonnet 4.6
Gewinner
GDPval-AA Elo (Wissensarbeit)
1.317
1.633
✅ Sonnet (+316 Pkt.)
Finance Agent (Finanzanalyse)
–
63,3 %
Sonnet (herausragend)
OSWorld (Betriebssystem-Steuerung)
–
72,5 %
Sonnet (herausragend)
MCP Atlas (Mehrstufige Workflows)
69,2 %
61,3 %
✅ Gemini (+7,9 Pkt.)
tau2-bench Retail (Tool-Aufrufe)
–
91,7 %
Sonnet (herausragend)
Analyse: Hier zeigt sich die größte Überraschung. Bei GDPval-AA (Simulation realer Experten-Wissensarbeit) übertrifft Sonnet 4.6 mit 1.633 Elo nicht nur Gemini 3.1 Pro (1.317) bei Weitem, sondern liegt sogar über dem hauseigenen Flaggschiff Opus 4.6 (1.559). Das bedeutet, dass Sonnet 4.6 in Szenarien für hochwertige Wissensarbeit wie Recherche-Analysen, Berichterstellung und Geschäftsstrategien derzeit das leistungsstärkste Modell auf dem Markt ist – und das, obwohl es fünfmal günstiger ist als Opus 4.6.
Gemini 3.1 Pro vs. Sonnet 4.6: Empfehlungen zur Szenarioauswahl
Die Stärken und Schwächen beider Modelle ergänzen sich sehr gut; die Wahl des richtigen Szenarios ist wichtiger als die Frage, „welches besser ist“.
Anmerkung des Autors: Basierend auf LM Arena-Blindtests und offiziellen Daten vergleiche ich das gpt-image-2 mit dem Nano Banana Pro anhand von 6 Dimensionen: Text-Rendering, 4K-Auflösung, Geschwindigkeit, Referenzbild, Preisgestaltung und Bearbeitungsfunktionen. So finden Sie heraus, ob das neue Modell den Status des Banana Pro als Spitzenreiter gefährden kann. Nano Banana Pro (Gemini 3 Pro Image) ist…
Anmerkung des Autors: Ein objektiver Vergleich von Claude Opus 4.6 und GPT-5.4 anhand von 12 Benchmark-Tests, Preisen, Kontextfenster, Agenten-Fähigkeiten und Anwendungsszenarien, um Entwicklern bei der richtigen Modellauswahl zu helfen. Im Februar und März 2026 kamen zwei Schwergewichte im KI-Bereich auf den Markt: Anthropics Claude Opus 4.6 (5. Februar) und OpenAIs GPT-5.4 (5. März). Beide sind…
In der technischen Support-Gruppe von APIYI wurden wir kürzlich mit einer sehr spezifischen Frage konfrontiert: Wenn man einem Modell gleichzeitig drei Bilder übergibt – Bild 1 als Basisszenario, Bild 2 als einzufügendes Objekt und Bild 3 als Referenz für Farbe und Atmosphäre – kombiniert mit einer ausführlichen Eingabeaufforderung: Welches Modell liefert die bessere Bildqualität und…
Seed 2.0 Modell: Pro, Lite oder Mini? Dies ist die zentrale Entscheidung für viele Entwickler bei der Anbindung der neuesten großen Sprachmodelle von ByteDance. In diesem Vergleich von Seed 2.0 Pro, Seed 2.0 Lite und Seed 2.0 Mini analysieren wir Benchmarks, Kosten und Kontextkapazität, um Ihnen eine fundierte Entscheidungshilfe zu bieten. Kernbotschaft: Nach der Lektüre…
Anmerkung des Autors: Ein tiefgehender Vergleich zwischen Seedream 5.0 Lite und Gemini 2.5 Flash Image (dem ursprünglichen Nano Banana). Wir analysieren Preis, Bildqualität, Geschwindigkeit und Chinesisch-Unterstützung, um Ihnen bei der Auswahl des passenden Modells für die Bilderzeugung zu helfen. Bei der Wahl eines Modells für die Bilderzeugung ist das Gleichgewicht zwischen Preis und Leistung eine…
Anmerkung des Autors: Ein tiefer Vergleich von Seedream 5.0 Lite und GPT Image 1.5 bezüglich Preis, Bildqualität, Geschwindigkeit, Text-Rendering, Bearbeitungsfunktionen und intelligenten Features – damit Sie das passende KI-Bilderzeugungsmodell finden. Anfang 2026 beherrschen zwei Modelle den Bereich der KI-Bilderzeugung: ByteDance Seedream 5.0 Lite – das branchenweit erste Bildmodell mit integrierter Websuche – und OpenAI GPT…