title: Gemini 3.1 Pro vs Claude Sonnet 4.6:2026年最強のコスパモデル決定戦
description: 2026年2月にリリースされたGemini 3.1 ProとClaude Sonnet 4.6を徹底比較。コーディング、推論、マルチモーダル、価格の5つの観点から、どちらが「真のコスパ王」かを検証します。
著者注:コーディング、推論、マルチモーダル、ナレッジワーク、価格設定の5つの次元からGemini 3.1 ProとClaude Sonnet 4.6を比較し、最もコストパフォーマンスの高い最先端モデル選びをサポートします。
2026年2月、AIモデルの勢力図において興味深い局面を迎えています。真の競争はもはや「誰が最強か」ではなく、「誰がコスパ(費用対効果)の王様か」という点にあります。GoogleのGemini 3.1 Pro(2月19日リリース)とAnthropicのClaude Sonnet 4.6(2月17日リリース)は、ほぼ同時期に登場し、価格帯も近く、共にフラッグシップ級の性能を謳っています。開発者にとって、これほど悩ましい選択はありません。
核心的な価値: この記事を読み終える頃には、コーディング、推論、マルチモーダル、ナレッジワークにおける両モデルの真の格差と、あなたの具体的なユースケースにおいてどちらを選ぶべきかが明確になっているはずです。
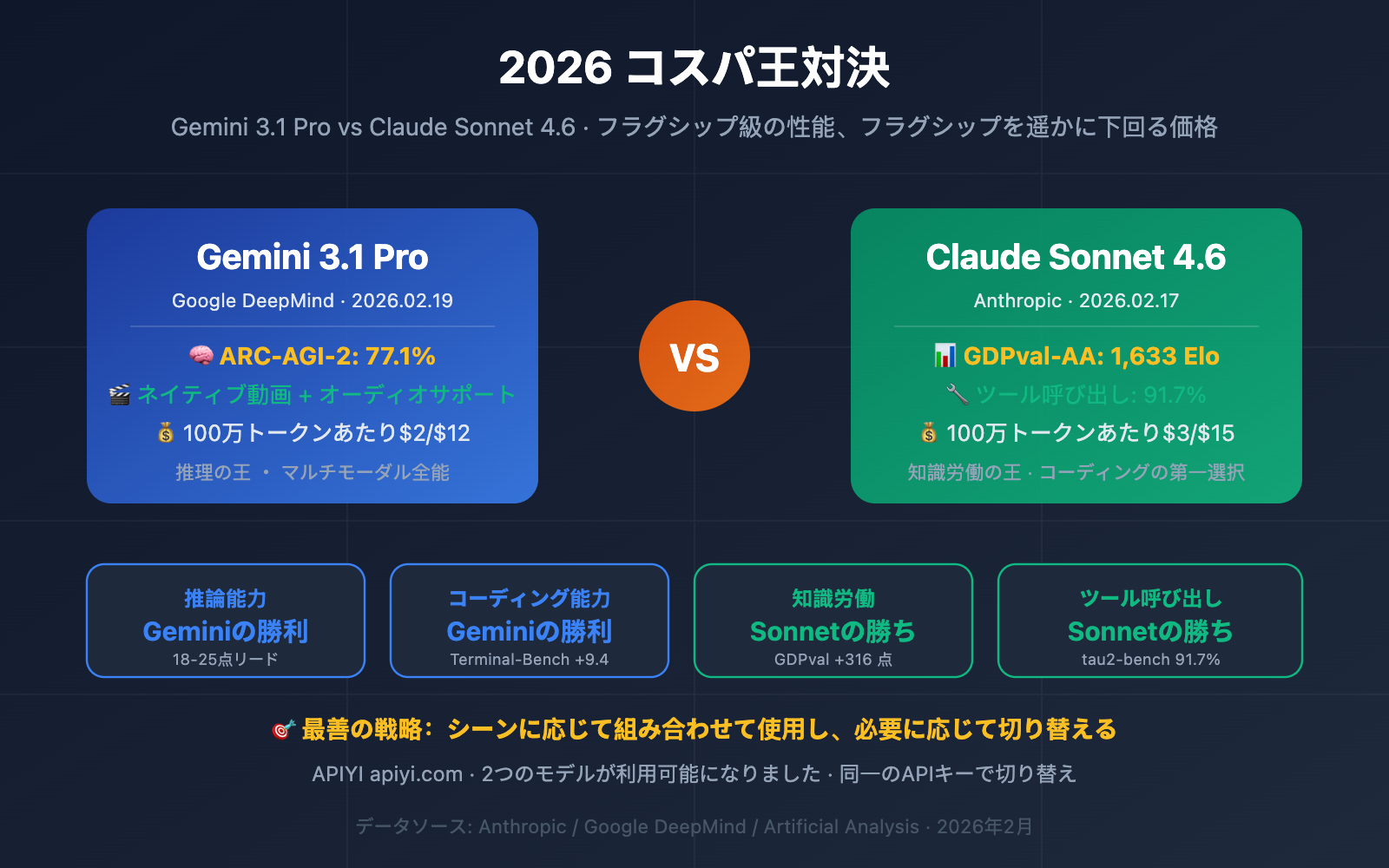
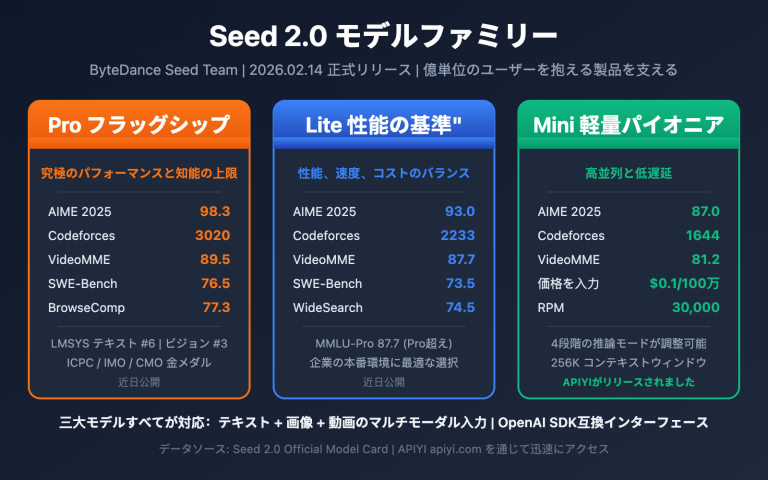
Gemini 3.1 Pro と Claude Sonnet 4.6 基本パラメータ比較
両モデルのポジショニングは非常に似ています。どちらも「フラッグシップ級の性能を持ちながら、価格はフラッグシップを大幅に下回る」実力派ですが、技術的なアプローチは全く異なります。
| 項目 | Gemini 3.1 Pro | Claude Sonnet 4.6 | 比較・備考 |
|---|---|---|---|
| リリース日 | 2026.02.19 | 2026.02.17 | わずか2日の差 |
| コンテキストウィンドウ | 100万(標準) | 20万標準 / 100万 Beta | Geminiはネイティブで100万に対応 |
| 最大出力 | 64K tokens | 64K tokens | 完全に一致 |
| 入力価格 | $2 / 100万 Token | $3 / 100万 Token | ✅ Geminiの方が33%安価 |
| 出力価格 | $12 / 100万 Token | $15 / 100万 Token | ✅ Geminiの方が20%安価 |
| 長文入力価格 | $4(>200K) | $3(不変) | ⚠️ 長文ではSonnetの方が安価 |
| 長文出力価格 | $18(>200K) | $15(不変) | ⚠️ 長文ではSonnetの方が安価 |
| 入力モーダル | テキスト、画像、音声、動画、PDF | テキスト、画像、PDF | ✅ Geminiの方がマルチモーダル対応が充実 |
| 推論モード | 3段階の思考(Low/Med/High) | 適応型推論(動的調整) | 設計思想の違い |
| プロンプトキャッシュ | 対応 | キャッシュ読み取りわずか $0.30(90%節約) | ✅ Sonnetのキャッシュの方が節約効果大 |
🎯 価格設定の重要な詳細: 200K以内の一般的なシナリオでは、Gemini 3.1 Proの方が安価です($2/$12 vs $3/$15)。しかし、コンテキストが200Kを超えると、Geminiの価格は$4/$18に跳ね上がり、逆にSonnet 4.6の$3/$15の方が割安になります。あなたの平均的なコンテキスト長が、どちらがよりお得かを直接左右します。
Gemini 3.1 Pro と Sonnet 4.6 ベンチマーク全面比較
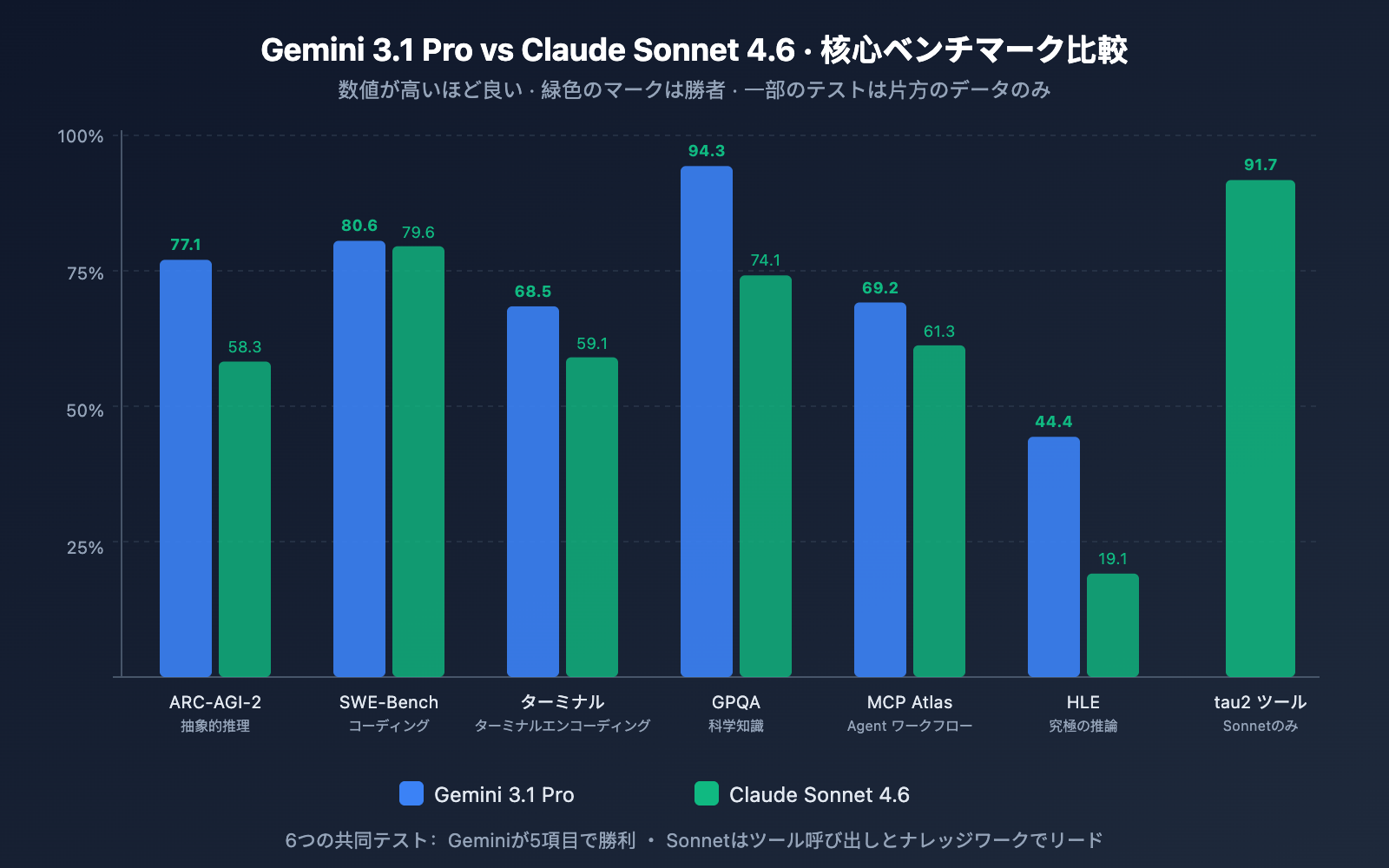
コーディング能力の比較
| コーディングテスト | Gemini 3.1 Pro | Claude Sonnet 4.6 | 勝者 |
|---|---|---|---|
| SWE-Bench Verified | 80.6% | 79.6% | ✅ Geminiが1.0ポイントリード |
| SWE-Bench Pro | 54.2% | 42.7% | ✅ Geminiが11.5ポイントリード |
| Terminal-Bench 2.0 | 68.5% | 59.1% | ✅ Geminiが9.4ポイントリード |
分析: Gemini 3.1 Pro は3つのコーディングテストすべてでリードしています。特に、より複雑な実務コードタスクである SWE-Bench Pro では11.5ポイント、ターミナル環境でのコーディングを評価する Terminal-Bench では9.4ポイントの差をつけています。一方で、Sonnet 4.6 は Replit の本番コード編集テストでエラー率0%を達成し、GitHub Copilot のコーディングエージェントの基盤モデルに採用されるなど、実際の開発現場での体験はベンチマーク以上に優れている可能性があります。
推論能力の比較
| 推論テスト | Gemini 3.1 Pro | Claude Sonnet 4.6 | 勝者 |
|---|---|---|---|
| ARC-AGI-2(抽象推論) | 77.1% | 58.3% | ✅ Geminiが18.8ポイントリード |
| GPQA Diamond(科学) | 94.3% | 74.1% | ✅ Geminiが20.2ポイントリード |
| HLE(究極の推論) | 44.4% | 19.1% | ✅ Geminiが25.3ポイントリード |
| MATH-500 | – | 97.8% | Sonnetの数学能力が顕著 |
分析: 推論能力は、両者の差が最も顕著に現れた項目です。Gemini 3.1 Pro は ARC-AGI-2、GPQA Diamond、HLE の3つの推論テストで、18〜25ポイントという大差をつけてリードしています。補足として、Gemini 3.1 Pro の推論スコアは3段階の思考システムの「High」モードで測定されたものであり、Sonnet 4.6 の適応型思考(Adaptive Thinking)は推論の深さにおいて Opus 4.6 には及びません。純粋な推論能力を重視する場合、Gemini 3.1 Pro が圧倒的に有利です。
ナレッジワークとエージェント能力の比較
| テスト | Gemini 3.1 Pro | Claude Sonnet 4.6 | 勝者 |
|---|---|---|---|
| GDPval-AA Elo(ナレッジワーク) | 1,317 | 1,633 | ✅ Sonnetが316ポイントリード |
| Finance Agent(金融分析) | – | 63.3% | Sonnetの数値が顕著 |
| OSWorld(OS操作) | – | 72.5% | Sonnetの数値が顕著 |
| MCP Atlas(マルチステップ・ワークフロー) | 69.2% | 61.3% | ✅ Geminiが7.9ポイントリード |
| tau2-bench Retail(ツール呼び出し) | – | 91.7% | Sonnetの数値が顕著 |
分析: ここで最大の逆転劇が起こりました。実社会の専門家レベルのナレッジワークをシミュレートする GDPval-AA において、Sonnet 4.6 は 1,633 Elo という驚異的なスコアを記録しました。これは Gemini 3.1 Pro の 1,317 を大きく引き離すだけでなく、自社のフラッグシップモデルである Opus 4.6 の 1,559 さえも上回っています。つまり、調査分析、レポート作成、ビジネス戦略といった高付加価値なナレッジワークのシーンにおいて、Sonnet 4.6 は現在、5倍高価な Opus 4.6 を含めた全モデルの中で最高のパフォーマンスを発揮することを意味しています。
Gemini 3.1 Pro と Sonnet 4.6 の利用シーン選択アドバイス
これら2つのモデルの長所と短所は非常に相補的です。そのため、「どちらが優れているか」よりも「どのシーンで使うか」を選択することの方が重要です。

Gemini 3.1 Pro を選ぶべきシーン
- アルゴリズムと競技プログラミング: LiveCodeBench Elo 2,887を記録し、アルゴリズム系のコーディングにおいて圧倒的なリードを保っています。
- 複雑な推論と科学研究: ARC-AGI-2 で77.1%、GPQA Diamond で94.3%を達成。純粋な推論能力は Sonnet 4.6 とは別次元のレベルにあります。
- マルチモーダル処理: 動画(1時間)、音声(8.4時間)をネイティブでサポート。Sonnet 4.6 はこれらをサポートしていません。
- MCP Agent ワークフロー: MCP Atlas で69.2%(7.9ポイントのリード)を記録。多段階の Agent システムを構築する際、より高い信頼性を発揮します。
- 短いコンテキストでの高頻度呼び出し: 200K 以内であれば $2/$12 という価格設定で、両者の中でより安価な選択肢となります。
Claude Sonnet 4.6 を選ぶべきシーン
- 専門家レベルのナレッジワーク: GDPval-AA で 1,633 Elo という全モデル中最高スコアを記録。調査レポート、金融分析、ビジネス戦略などのシーンで右に出るものはいません。
- プロダクション環境でのコード編集: Replit の本番環境テストでエラー率 0% を達成。GitHub Copilot のコーディング Agent 基盤としても選ばれています。
- ツール呼び出しと Computer Use: tau2-bench 91.7%、OSWorld 72.5% を記録。自動操作や関数呼び出しにおいて極めて高い精度を誇ります。
- 長いコンテキストのシーン: 200K を超えるコンテキストでは、Sonnet 4.6 の $3/$15 という価格は Gemini の $4/$18 よりも安価です。
- エンタープライズ級アプリケーション: より成熟した安全性のガードレール(セーフティ・アライメント)、プロンプトキャッシュ(読み取りわずか $0.30/百万トークン、90% 削減)、バッチ処理半額などの機能が充実しています。
Gemini 3.1 Pro と Claude Sonnet 4.6 API クイックスタート
シンプルな実装例
APIYIプラットフォームを利用すれば、2つのモデルを統一されたインターフェースで呼び出すことができます:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# Gemini 3.1 Pro - 推論とマルチモーダル性能に強み
# このコードの時間複雑度を分析し、最適化してください
response = client.chat.completions.create(
model="gemini-3.1-pro",
messages=[{"role": "user", "content": "分析这段代码的时间复杂度并优化"}]
)
print(response.choices[0].message.content)
Sonnet 4.6 の呼び出しとシーン別自動切り替えの例を表示
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# Claude Sonnet 4.6 - ナレッジワークとツール呼び出し(Tool Use)に強み
# 競合比較と成長提案を含む、第1四半期の市場分析レポートを作成してください
response = client.chat.completions.create(
model="claude-sonnet-4-6",
messages=[{"role": "user", "content": "撰写 Q1 市场分析报告,包含竞品对比和增长建议"}]
)
print(response.choices[0].message.content)
# シーンに応じた自動ルーティング
def route_model(prompt, task_type="general"):
model_map = {
"reasoning": "gemini-3.1-pro",
"multimodal": "gemini-3.1-pro",
"algorithm": "gemini-3.1-pro",
"knowledge": "claude-sonnet-4-6",
"production_code": "claude-sonnet-4-6",
"tool_call": "claude-sonnet-4-6",
"general": "gemini-3.1-pro",
}
return client.chat.completions.create(
model=model_map.get(task_type, "gemini-3.1-pro"),
messages=[{"role": "user", "content": prompt}]
)
アドバイス: APIYI(apiyi.com)プラットフォームを経由することで、1つのAPIキーで両方のモデルにアクセスし、簡単に切り替えることができます。プラットフォームでは無料のテストクレジットも提供されているため、実際の利用シーンで効果を比較してみることをお勧めします。
Gemini 3.1 Pro と Sonnet 4.6 のコスト詳細比較
3つの典型的な利用シーンにおける月間コストを試算しました:
| 利用シーン | 月間平均トークン消費量 | Gemini 3.1 Pro | Claude Sonnet 4.6 | より安価な方 |
|---|---|---|---|---|
| ライトユーザー(500万入力 + 100万出力) | 600万 | $22 | $30 | Geminiが27%お得 |
| ミドルユーザー(2000万入力 + 500万出力) | 2500万 | $100 | $135 | Geminiが26%お得 |
| ヘビーユーザー(長文コンテキスト)(5000万入力 >200K + 1000万出力) | 6000万 | $380 | $300 | ⚠️ Sonnetが21%お得 |
🎯 コストに関する結論: 通常の使用範囲内では、Gemini 3.1 Proの方が約26%〜27%安価です。しかし、200Kを超える長文コンテキスト(コードベース全体の分析、長大なドキュメント処理など)を頻繁に使用する場合、Sonnet 4.6の方が安くなります。これは、Geminiの長文コンテキスト料金が$4/$18(100万トークンあたり)に跳ね上がるのに対し、Sonnetは$3/$15を維持しているためです。さらに、Sonnetのプロンプトキャッシュ(読み取りはわずか$0.30/100万トークン)を活用すれば、実際のコストはさらに30%〜50%低くなる可能性があります。
APIYI(apiyi.com)プラットフォームを通じて導入することで、さらなる割引価格が適用され、両モデルの利用コストをさらに抑えることができます。
よくある質問
Q1: Sonnet 4.6 の GDPval-AA が自社の Opus 4.6 よりも高いのですが、これは正常ですか?
その通りです。Sonnet 4.6 は GDPval-AA で 1,633 Elo を記録し、Opus 4.6 の 1,559 を上回りました。Anthropic 公式もこのデータを確認しています。考えられる理由は、Sonnet 4.6 が企業のナレッジワーク(知識作業)シーン向けに特化して最適化されている一方で、Opus 4.6 は汎用的な推論や長文コンテキスト処理をより重視しているためです。開発者の選好率も、Sonnet 4.6 は Sonnet 4.5 に対して 70%、Opus 4.5 に対して 59% と高い数値を示しています。
Q2: AI エージェントにはどちらのモデルが適していますか?
エージェントの種類によります。MCP ベースのマルチステップ・ワークフロー・エージェントであれば、Gemini 3.1 Pro が MCP Atlas で 69.2% を記録し、7.9 ポイントリードしています。ツール呼び出し(Tool Use)が頻繁なエージェント(OpenClaw など)なら、Sonnet 4.6 の tau2-bench 91.7% の方が信頼性が高いです。ブラウザやデスクトップを操作する Computer Use 型エージェントであれば、Sonnet 4.6 の OSWorld 72.5% が現時点で最高レベルの成績の一つです。どちらのモデルも APIYI(apiyi.com)プラットフォームで直接接続してテスト可能です。
Q3: 現在 Sonnet 4.5 を使っていますが、Sonnet 4.6 にアップグレードすべきか、Gemini 3.1 Pro に乗り換えるべきでしょうか?
Sonnet 4.5 のナレッジワークやコーディング体験に満足しているなら、Sonnet 4.6 へのアップグレードが最も確実な選択肢です。API の互換性があり、価格も据え置きで、性能が全面的に向上しています(SWE-Bench は 77.2% から 79.6% へ、ARC-AGI-2 は 13.6% から 58.3% へと 4.3 倍向上)。もし主要なニーズが推論、マルチモーダル、あるいはアルゴリズムのコーディングに偏っているなら、Gemini 3.1 Pro がそれらの分野で顕著な優位性を持っています。APIYI(apiyi.com)を通じて両方のモデルを試してみることをお勧めします。
まとめ
Gemini 3.1 Pro と Claude Sonnet 4.6 の比較における主な結論は以下の通りです:
- 推論とマルチモーダルなら Gemini 3.1 Pro: ARC-AGI-2 で 18.8 ポイント、GPQA Diamond で 20.2 ポイントリード。ネイティブなビデオ/オーディオ対応、短文コンテキストではより低価格。
- ナレッジワークとプロダクション・コーディングなら Claude Sonnet 4.6: GDPval-AA 1,633 Elo は全モデルの中で最高スコア(Opus 4.6 を含む)。Replit でのエラー率 0%、GitHub Copilot の第一候補。
- 長文コンテキストのシナリオでは Sonnet の方がお得: 200K コンテキストを超える場合、Sonnet は $3/$15 に対し、Gemini は $4/$18。プロンプトキャッシュを併用すれば、さらに 30%〜50% 節約可能。
これら 2 つのモデルは 2026 年 2 月時点で最もコスパ(費用対効果)の高い最先端モデルです。最適な戦略は、利用シーンに応じてこれらを併用することです。APIYI(apiyi.com)から同時に接続し、同じ API キーで必要に応じて切り替えて使用することをお勧めします。
📚 参考文献
-
Claude Sonnet 4.6 リリース発表: Anthropic 公式ブログ
- リンク:
anthropic.com/news/claude-sonnet-4-6 - 説明: Sonnet 4.6 の全機能紹介、ベンチマークデータ、およびアダプティブ・シンキング機能の詳細
- リンク:
-
Gemini 3.1 Pro 公式ブログ: Google DeepMind リリース発表
- リンク:
blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-pro/ - 説明: Gemini 3.1 Pro の3段階思考システムと詳細なパフォーマンスデータ
- リンク:
-
Tom's Guide 実機検証比較: 7つの難題で Gemini 3.1 Pro と Sonnet 4.6 を徹底比較
- リンク:
tomsguide.com/ai/i-tested-gemini-3-1-pro-vs-claude-sonnet-4-6-in-7-tough-challenges-and-there-was-one-clear-winner - 説明: 実際のタスクシナリオにおける実効パフォーマンスの比較
- リンク:
-
Artificial Analysis ランキング: 第三方独立モデル評価プラットフォーム
- リンク:
artificialanalysis.ai/leaderboards/models - 説明: パフォーマンス、速度、価格の客観的な横断比較データ
- リンク:
著者: 技術チーム
技術交流: コメント欄で使用体験をぜひ共有してください。さらなる AI モデルの情報については、APIYI apiyi.com をご覧ください。