作者注:从编码、推理、多模态、知识工作、定价 5 大维度对比 Gemini 3.1 Pro 和 Claude Sonnet 4.6,帮你选出最适合的高性价比前沿模型
2026 年 2 月的 AI 模型格局出现了一个有意思的局面:真正的竞争不再是「谁是最强」,而是 「谁是性价比之王」。Google 的 Gemini 3.1 Pro(2 月 19 日发布)和 Anthropic 的 Claude Sonnet 4.6(2 月 17 日发布),几乎同期上线,定价接近,都宣称接近旗舰级性能——开发者的选择从未如此纠结。
核心价值: 看完本文,你将清楚两个模型在编码、推理、多模态、知识工作上的真实差距,以及在你的具体场景下该选哪一个。

Gemini 3.1 Pro 与 Claude Sonnet 4.6 基础参数对比
两个模型的定位非常相似——都是「接近旗舰性能、远低于旗舰价格」的实力派,但技术路线截然不同。
| 参数维度 | Gemini 3.1 Pro | Claude Sonnet 4.6 | 对比说明 |
|---|---|---|---|
| 发布日期 | 2026.02.19 | 2026.02.17 | 相隔仅 2 天 |
| 上下文窗口 | 100 万(标准) | 20 万标准 / 100 万 Beta | Gemini 原生百万上下文 |
| 最大输出 | 64K tokens | 64K tokens | 完全一致 |
| 输入价格 | $2/百万 Token | $3/百万 Token | ✅ Gemini 便宜 33% |
| 输出价格 | $12/百万 Token | $15/百万 Token | ✅ Gemini 便宜 20% |
| 长上下文输入价 | $4(>200K) | $3(不变) | ⚠️ 长上下文 Sonnet 更便宜 |
| 长上下文输出价 | $18(>200K) | $15(不变) | ⚠️ 长上下文 Sonnet 更便宜 |
| 输入模态 | 文本、图片、音频、视频、PDF | 文本、图片、PDF | ✅ Gemini 多模态更全 |
| 推理模式 | 三级思考(Low/Med/High) | 自适应思考(动态调节) | 设计理念不同 |
| Prompt 缓存 | 支持 | 缓存读取仅 $0.30/百万(省 90%) | ✅ Sonnet 缓存更省 |
🎯 定价关键细节: 在 200K 以内的常规场景下,Gemini 3.1 Pro 更便宜($2/$12 vs $3/$15)。但一旦上下文超过 200K,Gemini 涨价到 $4/$18,反而比 Sonnet 4.6 的 $3/$15 更贵。你的平均上下文长度直接决定谁更划算。
Gemini 3.1 Pro 与 Sonnet 4.6 Benchmark 全面对比
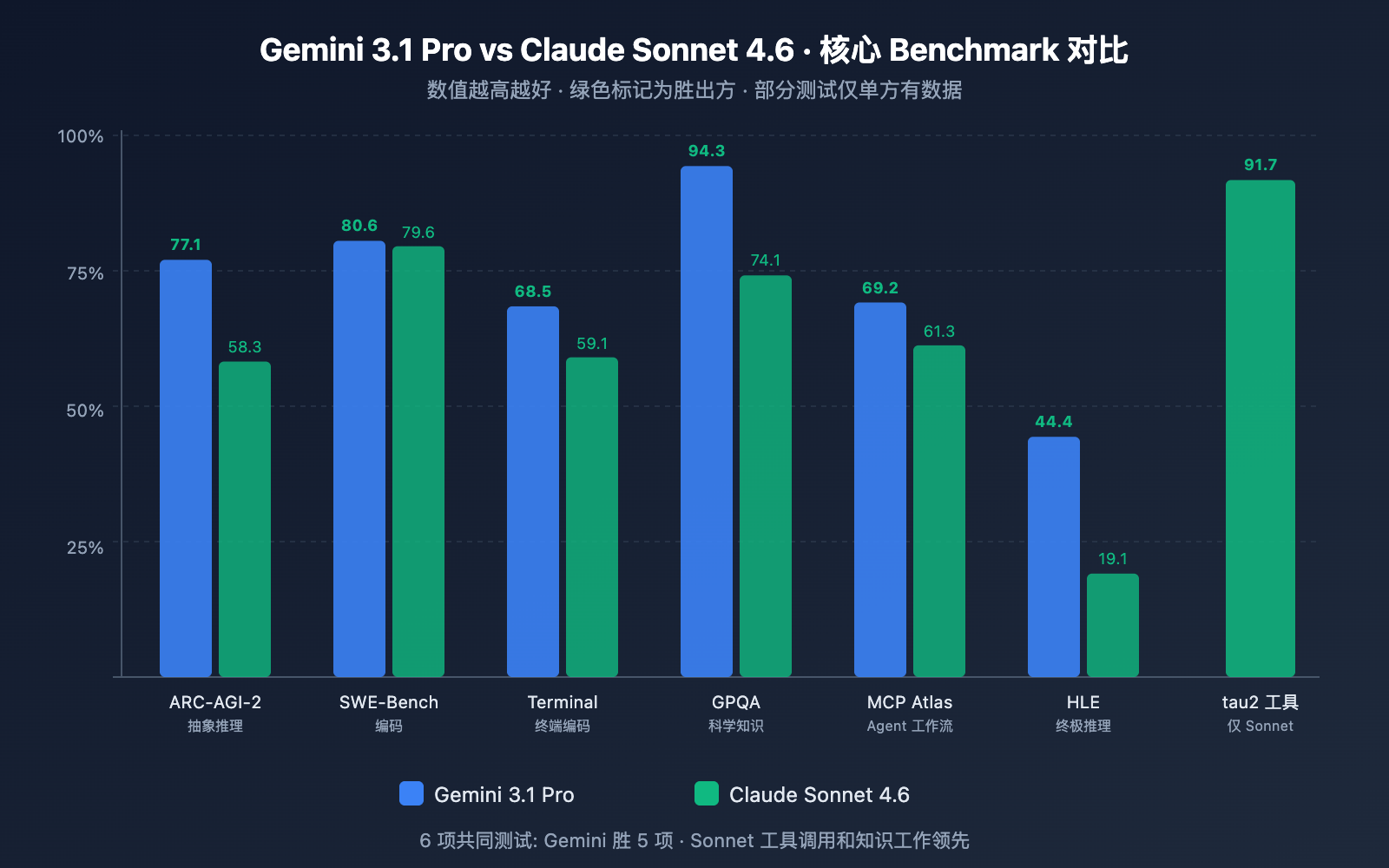
编码能力对比
| 编码测试 | Gemini 3.1 Pro | Claude Sonnet 4.6 | 胜出方 |
|---|---|---|---|
| SWE-Bench Verified | 80.6% | 79.6% | ✅ Gemini 高 1.0 分 |
| SWE-Bench Pro | 54.2% | 42.7% | ✅ Gemini 高 11.5 分 |
| Terminal-Bench 2.0 | 68.5% | 59.1% | ✅ Gemini 高 9.4 分 |
分析: Gemini 3.1 Pro 在三项编码测试中全面领先。特别是 SWE-Bench Pro(更复杂的真实代码任务)差距达 11.5 分,Terminal-Bench(终端环境编码)差距达 9.4 分。不过值得注意的是,Sonnet 4.6 在 Replit 的生产代码编辑内部测试中实现了 0% 错误率,并被选为 GitHub Copilot 的编码 Agent 基础模型——实际生产环境中的编码体验可能比 Benchmark 更接近。
推理能力对比
| 推理测试 | Gemini 3.1 Pro | Claude Sonnet 4.6 | 胜出方 |
|---|---|---|---|
| ARC-AGI-2(抽象推理) | 77.1% | 58.3% | ✅ Gemini 高 18.8 分 |
| GPQA Diamond(科学) | 94.3% | 74.1% | ✅ Gemini 高 20.2 分 |
| HLE(终极推理) | 44.4% | 19.1% | ✅ Gemini 高 25.3 分 |
| MATH-500 | – | 97.8% | Sonnet 数学能力突出 |
分析: 推理能力是两者差距最大的维度。Gemini 3.1 Pro 在 ARC-AGI-2、GPQA Diamond、HLE 三项推理测试上大幅领先,差距从 18 到 25 分不等。这里需要说明的是,Gemini 3.1 Pro 的推理得分是在其三级思考系统的 High 模式下取得的,而 Sonnet 4.6 的自适应思考在推理深度上不如 Opus 4.6。如果纯推理是你的核心需求,Gemini 3.1 Pro 优势明显。
知识工作与 Agent 能力对比
| 测试 | Gemini 3.1 Pro | Claude Sonnet 4.6 | 胜出方 |
|---|---|---|---|
| GDPval-AA Elo(知识工作) | 1,317 | 1,633 | ✅ Sonnet 高 316 分 |
| Finance Agent(金融分析) | – | 63.3% | Sonnet 数据突出 |
| OSWorld(操作系统控制) | – | 72.5% | Sonnet 数据突出 |
| MCP Atlas(多步骤工作流) | 69.2% | 61.3% | ✅ Gemini 高 7.9 分 |
| tau2-bench Retail(工具调用) | – | 91.7% | Sonnet 数据突出 |
分析: 这里出现了最大的反转。在 GDPval-AA(模拟真实专家级知识工作)上,Sonnet 4.6 以 1,633 Elo 不仅远超 Gemini 3.1 Pro 的 1,317,甚至超过了自家旗舰 Opus 4.6 的 1,559。这意味着在研究分析、报告撰写、商业策略等高价值知识工作场景中,Sonnet 4.6 是目前所有模型中表现最好的——包括比它贵 5 倍的 Opus 4.6。
Gemini 3.1 Pro 与 Sonnet 4.6 的场景选择建议
两个模型的优劣势非常互补,场景选择比「哪个更好」更重要。

选 Gemini 3.1 Pro 的场景
- 算法和竞赛编程: LiveCodeBench Elo 2,887,在算法类编码上碾压级领先
- 复杂推理和科学研究: ARC-AGI-2 77.1%、GPQA Diamond 94.3%,纯推理能力是 Sonnet 4.6 的另一个层级
- 多模态处理: 原生支持视频(1 小时)、音频(8.4 小时),Sonnet 4.6 不支持
- MCP Agent 工作流: MCP Atlas 69.2%(领先 7.9 分),构建多步骤 Agent 系统时更可靠
- 短上下文高频调用: 200K 以内 $2/$12 的定价是两者中更便宜的选择
选 Claude Sonnet 4.6 的场景
- 专家级知识工作: GDPval-AA 1,633 Elo 是当前所有模型最高分,研究报告、金融分析、商业策略等场景无出其右
- 生产代码编辑: 在 Replit 生产环境测试中 0% 错误率,被 GitHub Copilot 选为编码 Agent 基础
- 工具调用和 Computer Use: tau2-bench 91.7%、OSWorld 72.5%,在自动化操作和函数调用上精度极高
- 长上下文场景: 超过 200K 上下文时,Sonnet 4.6 的 $3/$15 比 Gemini 的 $4/$18 更便宜
- 企业级应用: 更成熟的安全对齐、Prompt 缓存(读取仅 $0.30/百万 Token,省 90%)、批处理半价
Gemini 3.1 Pro 和 Claude Sonnet 4.6 API 快速接入
极简示例
通过 API易平台,两个模型使用统一接口:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# Gemini 3.1 Pro - 推理和多模态更强
response = client.chat.completions.create(
model="gemini-3.1-pro",
messages=[{"role": "user", "content": "分析这段代码的时间复杂度并优化"}]
)
print(response.choices[0].message.content)
查看 Sonnet 4.6 调用和按场景自动切换示例
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# Claude Sonnet 4.6 - 知识工作和工具调用更强
response = client.chat.completions.create(
model="claude-sonnet-4-6",
messages=[{"role": "user", "content": "撰写 Q1 市场分析报告,包含竞品对比和增长建议"}]
)
print(response.choices[0].message.content)
# 按场景自动路由
def route_model(prompt, task_type="general"):
model_map = {
"reasoning": "gemini-3.1-pro",
"multimodal": "gemini-3.1-pro",
"algorithm": "gemini-3.1-pro",
"knowledge": "claude-sonnet-4-6",
"production_code": "claude-sonnet-4-6",
"tool_call": "claude-sonnet-4-6",
"general": "gemini-3.1-pro",
}
return client.chat.completions.create(
model=model_map.get(task_type, "gemini-3.1-pro"),
messages=[{"role": "user", "content": prompt}]
)
建议: 通过 API易 apiyi.com 平台可以同时接入两个模型,使用同一个 API Key 切换。平台提供免费测试额度,建议在你的实际场景中对比效果。
Gemini 3.1 Pro 与 Sonnet 4.6 成本深度对比
以三种典型使用场景估算月成本:
| 使用场景 | 月均 Token 消耗 | Gemini 3.1 Pro | Claude Sonnet 4.6 | 更便宜方 |
|---|---|---|---|---|
| 轻度使用(500 万输入 + 100 万输出) | 600 万 | $22 | $30 | Gemini 省 27% |
| 中度使用(2000 万输入 + 500 万输出) | 2500 万 | $100 | $135 | Gemini 省 26% |
| 重度长上下文(5000 万输入 >200K + 1000 万输出) | 6000 万 | $380 | $300 | ⚠️ Sonnet 省 21% |
🎯 成本结论: 常规使用下 Gemini 3.1 Pro 便宜约 26%-27%。但如果你频繁使用超过 200K 的长上下文(如全代码库分析、长文档处理),Sonnet 4.6 反而更便宜——因为 Gemini 长上下文涨价到 $4/$18,而 Sonnet 保持 $3/$15 不变。再加上 Sonnet 的 Prompt 缓存(读取仅 $0.30/百万 Token),实际成本可能还要低 30%-50%。
通过 API易 apiyi.com 平台接入可享受额外优惠价格,进一步降低两个模型的使用成本。
常见问题
Q1: Sonnet 4.6 的 GDPval-AA 比自家 Opus 4.6 还高,这正常吗?
确实如此。Sonnet 4.6 在 GDPval-AA 上拿到了 1,633 Elo,超过了 Opus 4.6 的 1,559。Anthropic 官方确认了这一数据。可能的原因是 Sonnet 4.6 针对企业知识工作场景做了专项优化,而 Opus 4.6 更侧重于通用推理和长上下文处理。开发者对 Sonnet 4.6 的偏好率也达到了 70%(对比 Sonnet 4.5)和 59%(对比 Opus 4.5)。
Q2: 哪个模型更适合做 AI Agent?
取决于 Agent 类型。如果是基于 MCP 的多步骤工作流 Agent,Gemini 3.1 Pro 的 MCP Atlas 69.2% 领先 7.9 分。如果是工具调用密集型 Agent(如 OpenClaw),Sonnet 4.6 的 tau2-bench 91.7% 更可靠。如果是 Computer Use 类 Agent(操控浏览器和桌面),Sonnet 4.6 的 OSWorld 72.5% 是目前最好的成绩之一。两个模型在 API易 apiyi.com 平台都可直接接入测试。
Q3: 我现在用的是 Sonnet 4.5,该升级到 Sonnet 4.6 还是换 Gemini 3.1 Pro?
如果你对 Sonnet 4.5 的知识工作和编码体验满意,直接升级 Sonnet 4.6 是最稳妥的选择——API 兼容、价格不变、性能全面提升(SWE-Bench 从 77.2% 到 79.6%,ARC-AGI-2 从 13.6% 到 58.3%,提升 4.3 倍)。如果你的核心需求偏向推理、多模态或算法编码,Gemini 3.1 Pro 在这些方向上有显著优势。建议通过 API易 apiyi.com 平台两个模型都试一试。
总结
Gemini 3.1 Pro 与 Claude Sonnet 4.6 的核心结论:
- 推理和多模态选 Gemini 3.1 Pro: ARC-AGI-2 领先 18.8 分,GPQA Diamond 领先 20.2 分,原生视频/音频支持,短上下文下更便宜
- 知识工作和生产编码选 Claude Sonnet 4.6: GDPval-AA 1,633 Elo 是所有模型最高分(包括 Opus 4.6),Replit 0% 错误率,GitHub Copilot 首选
- 长上下文场景 Sonnet 更划算: 超过 200K 上下文时 Sonnet $3/$15 vs Gemini $4/$18,配合 Prompt 缓存可再省 30%-50%
这两个模型是 2026 年 2 月性价比最高的前沿模型,最佳策略是根据场景混合使用。推荐通过 API易 apiyi.com 同时接入,用同一个 API Key 按需切换。
📚 参考资料
-
Claude Sonnet 4.6 发布公告: Anthropic 官方博客
- 链接:
anthropic.com/news/claude-sonnet-4-6 - 说明: Sonnet 4.6 的完整功能介绍、Benchmark 数据和自适应思考功能
- 链接:
-
Gemini 3.1 Pro 官方博客: Google DeepMind 发布公告
- 链接:
blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-pro/ - 说明: Gemini 3.1 Pro 的三级思考系统和完整性能数据
- 链接:
-
Tom's Guide 实测对比: 7 项挑战实测 Gemini 3.1 Pro vs Sonnet 4.6
- 链接:
tomsguide.com/ai/i-tested-gemini-3-1-pro-vs-claude-sonnet-4-6-in-7-tough-challenges-and-there-was-one-clear-winner - 说明: 真实任务场景下的实际表现对比
- 链接:
-
Artificial Analysis 排行榜: 第三方独立模型评测平台
- 链接:
artificialanalysis.ai/leaderboards/models - 说明: 客观的性能、速度、价格横向对比数据
- 链接:
作者: 技术团队
技术交流: 欢迎在评论区分享你的使用体验,更多 AI 模型资讯可访问 API易 apiyi.com