작자 주: Claude Opus 4.6과 GPT-5.4의 12개 벤치마크, 가격, 컨텍스트 윈도우, 에이전트 능력 및 적용 시나리오를 객관적으로 비교하여 개발자가 올바른 선택을 할 수 있도록 돕습니다.
2026년 2월과 3월, AI 분야는 두 가지 중요한 플래그십 모델을 맞이했습니다: Anthropic의 Claude Opus 4.6(2월 5일)과 OpenAI의 GPT-5.4(3월 5일). 둘 다 각 회사 역사상 가장 강력한 범용 모델이지만, 설계 철학과 강점 영역은 완전히 다릅니다.
벤치마크 결과: GPT-5.4가 5개 부문에서 승리, Claude Opus 4.6이 3개 부문에서 승리했습니다. 하지만 프로그래밍, 추론, 코드 품질과 같은 핵심 차원에서는 Claude의 리더십이 더 실질적인 가치를 지닙니다.
핵심 가치: 이 글을 읽고 나면 프로그래밍, 추론, 자동화, 비전 등 다양한 시나리오에서 어떤 모델을 선택해야 할지 명확히 알게 될 것입니다.

Claude Opus 4.6 vs GPT-5.4 핵심 데이터 비교
| 비교 차원 | Claude Opus 4.6 | GPT-5.4 | 설명 |
|---|---|---|---|
| 출시일 | 2026-02-05 | 2026-03-05 | 1개월 간격 |
| 모델 ID | claude-opus-4-6 | gpt-5.4 | — |
| 컨텍스트 윈도우 | 200K (1M Beta) | 1,000K | GPT가 공식적으로 1M 지원 |
| 최대 출력 | 128K | 128K | 동일 |
| 입력 가격 | $5.00/M | $2.50/M | GPT가 50% 저렴 |
| 출력 가격 | $25.00/M | $15.00/M | GPT가 40% 저렴 |
| 캐시 입력 | $0.50/M | $0.25/M | GPT가 50% 저렴 |
| 추론 모드 | 적응형 사고 (Adaptive) | 5단계 추론 (none→xhigh) | 각각의 특징 |
| 컴퓨터 제어 | ✅ (72.7%) | ✅ (75.0%) | GPT, 인간 능력 초월 |
| 에이전트 팀 | ✅ Agent Teams | ❌ | Claude만의 독자적 기능 |
| 도구 검색 | ❌ | ✅ Token 47% 감소 | GPT만의 독자적 기능 |
| 금융 플러그인 | ❌ | ✅ Excel/Sheets | GPT만의 독자적 기능 |
Claude Opus 4.6 vs GPT-5.4 설계 철학 차이
두 모델의 설계 철학은 완전히 다릅니다.
Claude Opus 4.6은 "심층 지능" 경로를 걷고 있습니다. 적응형 사고(Adaptive Thinking)는 모델이 문제의 복잡도에 따라 추론 깊이를 자동으로 결정하게 하여, 수동으로 예산을 설정할 필요가 없습니다. Agent Teams 기능은 하나의 메인 Claude 인스턴스가 여러 개의 독립적인 하위 에이전트를 파생시켜 병렬로 작업하고, 공유 작업 목록과 메시지 시스템을 통해 조율할 수 있게 합니다. 이러한 아키텍처 설계는 깊은 이해와 긴 체인 추론이 필요한 복잡한 프로그래밍 작업에 더 적합합니다.
GPT-5.4는 "올라운더(만능 도구)" 경로를 걷고 있습니다. 프로그래밍(GPT-5.3 Codex 상속), 컴퓨터 제어, 전체 해상도 비전 및 도구 검색을 하나의 범용 모델에 처음으로 통합했습니다. 도구 검색 메커니즘은 모델이 필요에 따라 도구 정의를 찾을 수 있게 하여, Token 사용량을 47% 줄였습니다. 금융 플러그인(Moody's, MSCI 등)과 ChatGPT for Excel는 기업급 전문 작업을 겨냥하고 있습니다.
🎯 모델 선택 팁: 두 모델의 강점 영역은 거의 상호 보완적입니다. APIYI apiyi.com을 통해 하나의 API 키로 Claude Opus 4.6과 GPT-5.4를 동시에 호출하고, 시나리오에 따라 유연하게 전환할 수 있습니다.
Claude Opus 4.6 vs GPT-5.4 벤치마크 상세 분석
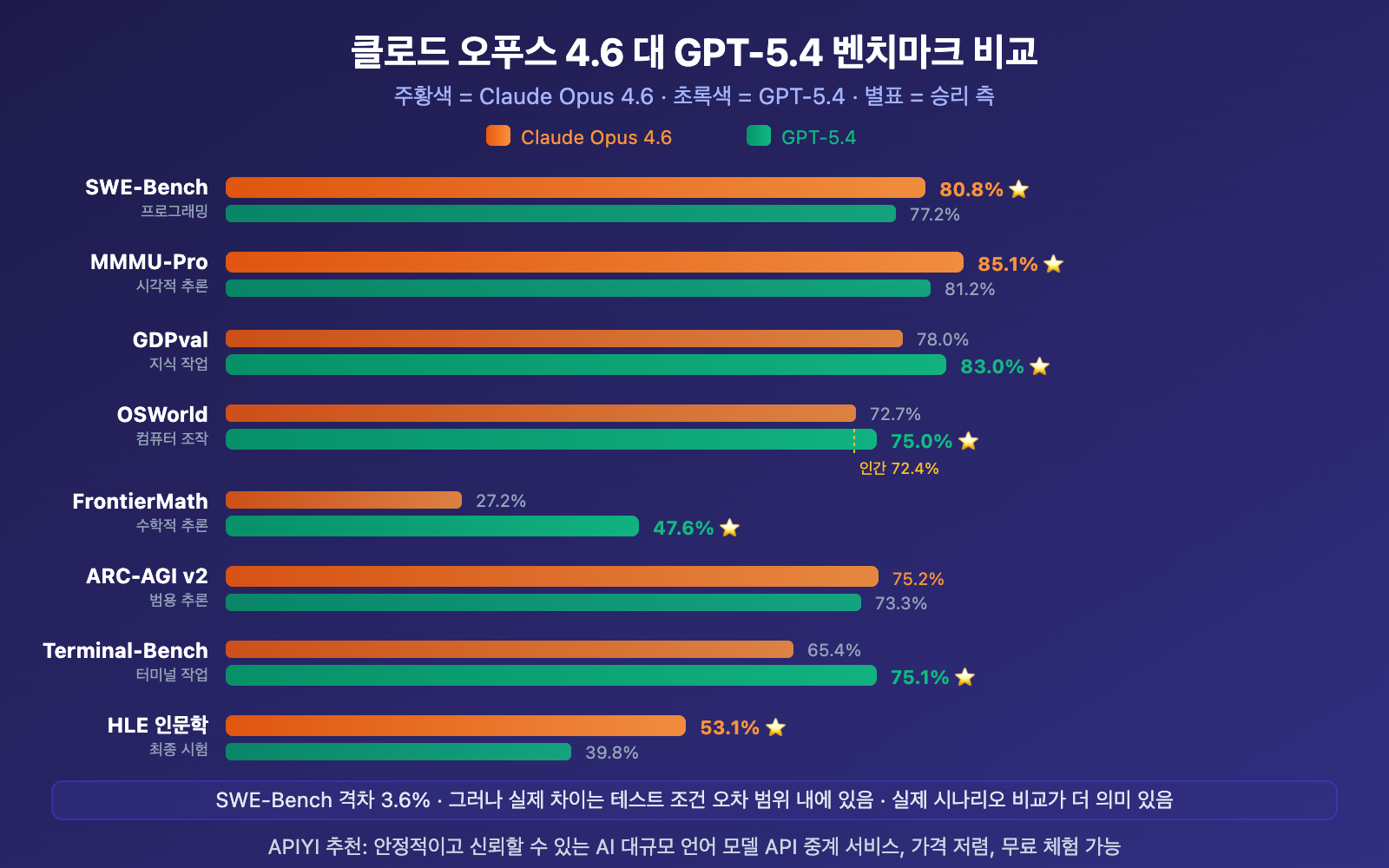
Claude Opus 4.6 vs GPT-5.4 완전한 벤치마크 테이블
| 벤치마크 | Claude Opus 4.6 | GPT-5.4 | 격차 | 승리 |
|---|---|---|---|---|
| SWE-Bench Verified | 80.8% | 77.2% | +3.6% | Claude |
| SWE-Bench Pro (고난이도) | ~45.9% | 57.7% | +11.8% | GPT |
| MMMU-Pro 비전 추론 | 85.1% | 81.2% | +3.9% | Claude |
| GDPval 지식 작업 | 78.0% | 83.0% | +5.0% | GPT |
| OSWorld 컴퓨터 제어 | 72.7% | 75.0% | +2.3% | GPT |
| FrontierMath 수학 | 27.2% | 47.6% | +20.4% | GPT |
| ARC-AGI v2 일반 추론 | 75.2% | 73.3% | +1.9% | Claude |
| Terminal-Bench 터미널 | 65.4% | 75.1% | +9.7% | GPT |
| Humanity's Last Exam | 53.1% | 39.8% | +13.3% | Claude |
| Tau2 Telecom | 99.3% | 98.9% | +0.4% | Claude |
| GPQA 대학원 수준 추론 | 91.3% | 92.8% | +1.5% | GPT |
| BrowseComp 웹 브라우징 | 84.0% | 82.7% | +1.3% | Claude |
특히 주목해야 할 점은: 80.0%, 80.6%, 80.8% 사이의 SWE-Bench 차이는 실제로 테스트 조건의 오차 범위 내에 있습니다. 다시 말해, 표준화된 프로그래밍 벤치마크에서는 두 모델의 성능이 수렴하는 추세입니다. 진정한 차이는 코드 품질, 아키텍처 이해, 그리고 실제 개발 경험에서 나타납니다.
🎯 실제 테스트 권장사항: 벤치마크는 참고용 시작점일 뿐입니다. APIYI apiyi.com을 통해 무료 크레딧을 받아, 여러분의 프로젝트에서 두 모델의 실제 성능을 직접 비교해 보시는 것을 권장합니다. 이는 어떤 벤치마크보다 더 가치 있는 경험이 될 것입니다.
Claude Opus 4.6 vs GPT-5.4 고유 능력 비교
Claude Opus 4.6 고유 장점
1. 에이전트 팀(Agent Teams)
Claude Opus 4.6에서 도입한 Agent Teams는 현재 AI 분야에서 독보적인 기능입니다. 하나의 주 Claude 인스턴스(Lead)가 여러 개의 독립적인 하위 에이전트(Teammates)를 생성할 수 있으며, 각 하위 에이전트는 완전한 독립적인 컨텍스트 윈도우를 가지고, 공유 작업 목록과 메시지 시스템을 통해 병렬적으로 협업합니다.
심층 연구 작업에서 이 다중 에이전트 기술은 성능을 약 15% 포인트 향상시켰습니다. 이러한 아키텍처는 특히 대규모 코드베이스의 병렬 리팩토링에 적합합니다. 주 에이전트가 계획을 담당하고, 하위 에이전트들이 각각 다른 모듈을 처리하는 방식입니다.
2. 적응형 사고(Adaptive Thinking)
GPT-5.4의 수동 5단계 추론 레벨과 달리, Claude의 적응형 사고는 모델이 문제의 복잡도를 자동으로 판단하고 동적으로 추론 깊이를 할당하도록 합니다. 기본 high 레벨에서는 Claude가 거의 항상 사고 체인(Chain of Thought)을 활성화하지만, 간단한 문제에서는 자동으로 건너뛰어 토큰과 지연 시간을 절약합니다.
적응형 사고는 또한 교차 사고(Interleaved Thinking)를 지원합니다. 이는 도구 호출 사이에 사고를 끼워 넣는 방식으로, 에이전트식 워크플로우에 특히 효과적입니다.
GPT-5.4 고유 장점
1. 네이티브 컴퓨터 제어
GPT-5.4는 OpenAI의 네이티브 컴퓨터 제어 능력을 내장한 최초의 범용 모델입니다. OSWorld 벤치마크에서 75.0%를 기록하여 인간 기준선 72.4%를 직접적으로 능가했습니다. Playwright 코드와 직접적인 키보드/마우스 명령 두 가지 방식을 통해 브라우저와 데스크톱 애플리케이션을 조작할 수 있습니다.
2. 도구 검색(Tool Search)
많은 도구가 있는 시스템에서 기존 방식은 모든 도구 정의를 모델에 한 번에 전송해야 했습니다. GPT-5.4의 도구 검색 기능은 모델이 필요에 따라 도구 정의를 찾아볼 수 있게 하여, 토큰 사용량을 47% 줄이면서 정확도는 그대로 유지합니다.
3. 금융 산업 심층 통합
ChatGPT for Excel/Google Sheets와 Moody's/MSCI/FactSet 데이터 통합은 GPT-5.4가 금융 분석 분야에서 Claude가 현재 따라잡을 수 없는 생태계적 우위를 형성하도록 했습니다. 내부 투자은행 벤치마크 점수가 43.7%에서 87.3%로 향상되었습니다.
🎯 API 접속: Claude Opus 4.6와 GPT-5.4 모두 APIYI apiyi.com의 통합 인터페이스를 통해 호출할 수 있습니다. GPT-5.4 가격은 공식 웹사이트와 동일($2.50/$15.00)하며, 100달러 충전 시 10%를 추가로 지급합니다.
Claude Opus 4.6 vs GPT-5.4 시나리오별 선택 가이드

Claude Opus 4.6 vs GPT-5.4 API 접속 예제
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# 복잡한 코드 리팩토링 → Claude Opus 4.6
refactor = client.chat.completions.create(
model="claude-opus-4-6",
messages=[{"role": "user", "content": "이 모듈의 의존성 주입을 리팩토링하세요"}]
)
# 초대형 프로젝트 전역 분석 → GPT-5.4
analysis = client.chat.completions.create(
model="gpt-5.4",
messages=[{"role": "user", "content": "전체 프로젝트의 보안 취약점을 분석하세요"}]
)
제안: APIYI apiyi.com에 계정을 등록하면 두 가지 플래그십 모델을 동시에 호출할 수 있습니다. GPT-5.4 가격은 공식 웹사이트와 동기화되며, 100달러 충전 시 10%를 추가로 지급합니다. 모델을 전환하려면 하나의 매개변수만 수정하면 됩니다.
자주 묻는 질문
Q1: Claude Opus 4.6과 GPT-5.4 중 어떤 모델이 프로그래밍에 더 강할까요?
어떤 측면을 보느냐에 따라 다릅니다. 표준 프로그래밍 벤치마크인 SWE-Bench에서는 Claude가 80.8% 대 77.2%로 앞서며, 코드 품질과 다중 파일 리팩토링 능력도 더 우수합니다. 하지만 GPT-5.4는 고난도 SWE-Bench Pro에서 57.7% 대 ~45.9%로 역전했고, 터미널 작업(75.1% vs 65.4%)에서도 크게 앞섭니다. 대부분의 개발자에게는 두 모델의 프로그래밍 능력이 이미 수렴하고 있다고 볼 수 있어요.
Q2: 가격 차이는 크나요? 어떻게 선택해야 할까요?
GPT-5.4가 전반적으로 더 저렴합니다: 입력 토큰이 $2.50 vs $5.00/M(50% 저렴), 출력 토큰이 $15.00 vs $25.00/M(40% 저렴). 비용이 주요 고려사항이라면 GPT-5.4가 더 적합합니다. 프로젝트에서 코드 품질과 아키텍처 이해도가 극히 중요하다면, Claude의 프리미엄 가치가 그만큼의 비용을 지불할 만합니다. APIYI(apiyi.com)를 통해 각 시나리오에 맞춰 두 모델을 혼합 사용하여 비용을 최적화하는 것을 추천드려요.
Q3: 하나의 플랫폼으로 두 모델을 동시에 사용하려면 어떻게 하나요?
APIYI(apiyi.com)에 계정을 등록하세요:
- 통합 API 키를 발급받습니다.
base_url을https://vip.apiyi.com/v1로 설정합니다.- 리팩토링 작업:
model="claude-opus-4-6" - 대규모 프로젝트 분석:
model="gpt-5.4" - 일상 작업:
model="gpt-5.3-chat-latest"(가장 경제적)
100달러 충전 시 10%를 추가로 지급하며, 하나의 계정으로 모든 주요 모델을 호출할 수 있습니다.
요약
Claude Opus 4.6 대 GPT-5.4의 핵심 결론입니다:
- 프로그래밍과 시각 추론에는 Claude 선택: SWE-Bench 80.8%, MMMU-Pro 85.1%로 업계 최고 수준이며, 코드 품질이 더 깔끔하고 Agent Teams(다중 에이전트 협업)은 독보적인 장점입니다.
- 지식 작업과 자동화에는 GPT 선택: GDPval 83.0%, OSWorld 75.0%로 인간을 능가하며, 1M 컨텍스트 윈도우가 정식으로 사용 가능하고, API 가격이 40-50% 저렴합니다.
- 가장 현명한 전략은 조합 사용: 두 모델의 강점 영역이 거의 상호 보완적입니다. 리팩토링에는 Claude를, 대규모 프로젝트 분석과 자동화에는 GPT를, 일상 작업에는 GPT-5.3 Instant로 비용을 절약하세요.
SWE-Bench에서 80.8% 대 77.2%의 격차는 크게 보이지 않을 수 있지만, 실제 개발에서는 Claude의 아키텍처 이해력과 코드 정리 능력이 여전히 뚜렷한 장점입니다. GPT-5.4는 1M 컨텍스트, 컴퓨터 제어 능력, 그리고 더 낮은 가격 정책으로 또 다른 차원에서 강점을 구축했습니다.
APIYI(apiyi.com)를 통해 두 플래그십 모델을 통합 접속하는 것을 추천합니다. 하나의 API 키로 모두 호출할 수 있으며, 100달러 충전 시 10%를 추가로 지급합니다.
📚 참고 자료
-
GPT-5.4 vs Claude Opus 4.6 프로그래밍 비교: 개발자 관점의 SWE-Bench, 코드 품질 및 에이전트 능력 분석
- 링크:
blog.getbind.co/gpt-5-4-vs-claude-opus-4-6-which-one-is-better-for-coding/ - 설명: SWE-Bench Pro와 Terminal-Bench 데이터를 포함한 가장 상세한 프로그래밍 차원 비교
- 링크:
-
GPT-5.4 vs Opus 4.6 vs Gemini 3.1 Pro 3강 비교: 12개 벤치마크 테스트 전 차원 분석
- 링크:
digitalapplied.com/blog/gpt-5-4-vs-opus-4-6-vs-gemini-3-1-pro-best-frontier-model - 설명: 가격, 컨텍스트, 벤치마크 테스트, 강점과 약점을 모두 다룹니다
- 링크:
-
Claude Opus 4.6 공식 발표 공지: 에이전트 팀, 적응형 사고 등 신규 기능 상세 정보
- 링크:
anthropic.com/news/claude-opus-4-6 - 설명: Claude의 독자적인 기능을 이해하는 최초의 자료
- 링크:
-
Claude Opus 4.6 적응형 사고 API 문서: 개발자 통합 가이드
- 링크:
platform.claude.com/docs/en/build-with-claude/adaptive-thinking - 설명: 적응형 사고의 구체적인 사용 방법과 매개변수 설정을 이해합니다
- 링크:
작성자: APIYI 기술 팀
기술 교류: 댓글로 토론을 환영합니다. 더 많은 자료는 APIYI docs.apiyi.com 문서 센터에서 확인하실 수 있습니다