Note de l'auteur : Comparaison de Gemini 3.1 Pro et Claude Sonnet 4.6 selon 5 dimensions clés (codage, raisonnement, multimodalité, travail de connaissance et tarification) pour vous aider à choisir le modèle de pointe au meilleur rapport qualité-prix.
En février 2026, le paysage des modèles d'IA présente une situation intéressante : la véritable compétition n'est plus de savoir « qui est le plus fort », mais « qui est le roi du rapport qualité-prix ». Le Gemini 3.1 Pro de Google (sorti le 19 février) et le Claude Sonnet 4.6 d'Anthropic (sorti le 17 février) ont été lancés presque simultanément, avec des tarifs proches et des performances annoncées comme quasi-flagship — le choix des développeurs n'a jamais été aussi cornélien.
Valeur centrale : Après avoir lu cet article, vous comprendrez l'écart réel entre ces deux modèles en matière de codage, de raisonnement, de multimodalité et de travail de connaissance, et lequel choisir selon votre scénario spécifique.

Comparaison des paramètres de base : Gemini 3.1 Pro vs Claude Sonnet 4.6
Le positionnement de ces deux modèles est très similaire : ce sont deux « poids lourds » offrant des performances proches de celles des fleurons, mais à un prix bien inférieur. Cependant, leurs approches techniques divergent radicalement.
| Dimension | Gemini 3.1 Pro | Claude Sonnet 4.6 | Commentaire comparatif |
|---|---|---|---|
| Date de sortie | 19.02.2026 | 17.02.2026 | À peine 2 jours d'intervalle |
| Fenêtre de contexte | 1 million (standard) | 200k standard / 1M Beta | Gemini gère nativement le million |
| Sortie maximale | 64K tokens | 64K tokens | Identique |
| Prix d'entrée | 2 $/million de tokens | 3 $/million de tokens | ✅ Gemini est 33 % moins cher |
| Prix de sortie | 12 $/million de tokens | 15 $/million de tokens | ✅ Gemini est 20 % moins cher |
| Prix entrée (long contexte) | 4 $ (>200K) | 3 $ (inchangé) | ⚠️ Sonnet est moins cher pour le long contexte |
| Prix sortie (long contexte) | 18 $ (>200K) | 15 $ (inchangé) | ⚠️ Sonnet est moins cher pour le long contexte |
| Modalités d'entrée | Texte, image, audio, vidéo, PDF | Texte, image, PDF | ✅ Gemini est plus complet (multimodal) |
| Mode de raisonnement | Réflexion à 3 niveaux (Low/Med/High) | Réflexion adaptative (dynamique) | Philosophies de conception différentes |
| Mise en cache des invites | Supportée | Lecture du cache à seulement 0,30 $/M (-90 %) | ✅ Le cache de Sonnet est plus économique |
🎯 Détails clés sur la tarification : Dans les scénarios classiques de moins de 200K, Gemini 3.1 Pro est plus abordable (2 $/12 $ contre 3 $/15 $). Cependant, dès que le contexte dépasse 200K, le prix de Gemini grimpe à 4 $/18 $, devenant plus coûteux que les 3 $/15 $ de Sonnet 4.6. Votre longueur de fenêtre de contexte moyenne déterminera directement quel modèle est le plus rentable pour vous.
Comparaison complète des Benchmarks : Gemini 3.1 Pro vs Sonnet 4.6
Comparaison des capacités de codage
| Test de codage | Gemini 3.1 Pro | Claude Sonnet 4.6 | Vainqueur |
|---|---|---|---|
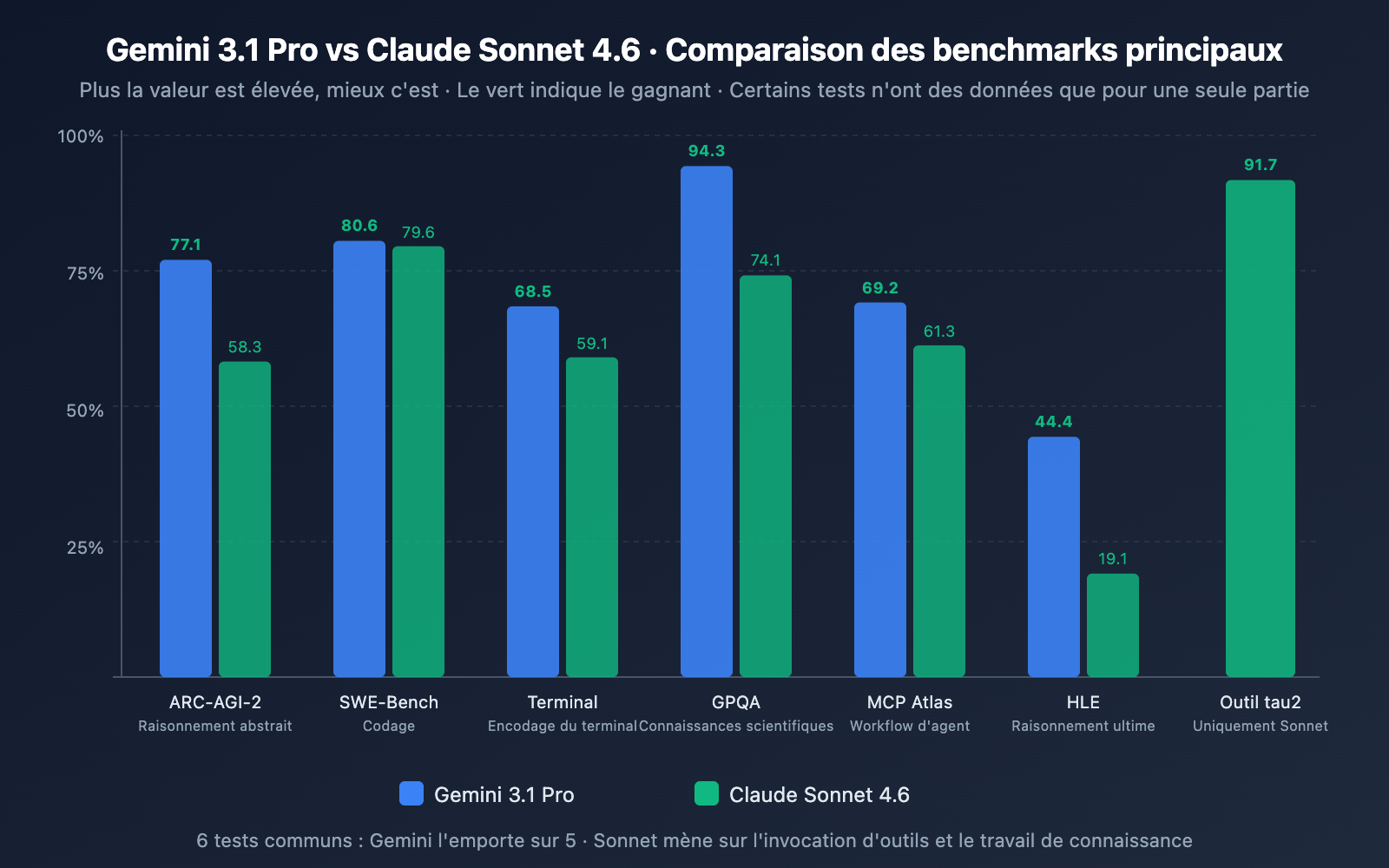
| SWE-Bench Verified | 80,6 % | 79,6 % | ✅ Gemini (+1,0 pt) |
| SWE-Bench Pro | 54,2 % | 42,7 % | ✅ Gemini (+11,5 pts) |
| Terminal-Bench 2.0 | 68,5 % | 59,1 % | ✅ Gemini (+9,4 pts) |
Analyse : Gemini 3.1 Pro mène sur les trois tests de codage. L'écart est particulièrement marqué sur SWE-Bench Pro (tâches de code réelles plus complexes) avec 11,5 points d'avance, et sur Terminal-Bench (codage en environnement terminal) avec 9,4 points. Il est toutefois intéressant de noter que Sonnet 4.6 a affiché un taux d'erreur de 0 % lors des tests internes d'édition de code de production de Replit, et a été choisi comme modèle de base pour l'agent de codage de GitHub Copilot — l'expérience de codage en environnement de production réel pourrait donc être plus équilibrée que ce que suggèrent les benchmarks.
Comparaison des capacités de raisonnement
| Test de raisonnement | Gemini 3.1 Pro | Claude Sonnet 4.6 | Vainqueur |
|---|---|---|---|
| ARC-AGI-2 (Abstrait) | 77,1 % | 58,3 % | ✅ Gemini (+18,8 pts) |
| GPQA Diamond (Science) | 94,3 % | 74,1 % | ✅ Gemini (+20,2 pts) |
| HLE (Raisonnement ultime) | 44,4 % | 19,1 % | ✅ Gemini (+25,3 pts) |
| MATH-500 | – | 97,8 % | Sonnet excelle en maths |
Analyse : Le raisonnement est la dimension où l'écart est le plus flagrant. Gemini 3.1 Pro devance largement Sonnet sur ARC-AGI-2, GPQA Diamond et HLE, avec des écarts allant de 18 à 25 points. Précisons que les scores de Gemini 3.1 Pro ont été obtenus avec son système de réflexion à trois niveaux en mode « High », tandis que la réflexion adaptative de Sonnet 4.6 n'atteint pas la profondeur de raisonnement d'Opus 4.6. Si le raisonnement pur est votre besoin central, Gemini 3.1 Pro possède un net avantage.
Comparaison du travail intellectuel et des capacités d'agent
| Test | Gemini 3.1 Pro | Claude Sonnet 4.6 | Vainqueur |
|---|---|---|---|
| GDPval-AA Elo (Travail intellectuel) | 1 317 | 1 633 | ✅ Sonnet (+316 pts) |
| Finance Agent (Analyse financière) | – | 63,3 % | Sonnet en tête |
| OSWorld (Contrôle d'OS) | – | 72,5 % | Sonnet en tête |
| MCP Atlas (Workflows multi-étapes) | 69,2 % | 61,3 % | ✅ Gemini (+7,9 pts) |
| tau2-bench Retail (Appel d'outils) | – | 91,7 % | Sonnet en tête |
Analyse : C'est ici que se produit le plus grand retournement de situation. Sur GDPval-AA (qui simule un travail intellectuel de niveau expert réel), Sonnet 4.6, avec un score de 1 633 Elo, dépasse non seulement largement les 1 317 de Gemini 3.1 Pro, mais surpasse même le fleuron de la marque, Opus 4.6 (1 559). Cela signifie que pour l'analyse de recherche, la rédaction de rapports ou la stratégie commerciale, Sonnet 4.6 est actuellement le modèle le plus performant du marché — y compris par rapport à des modèles 5 fois plus chers.
Gemini 3.1 Pro vs Sonnet 4.6 : conseils pour choisir selon vos besoins
Les forces et faiblesses des deux modèles sont très complémentaires. Choisir le bon scénario d'utilisation est bien plus important que de chercher à savoir « lequel est le meilleur ».

Quand choisir Gemini 3.1 Pro
- Algorithmes et programmation compétitive : Avec un score LiveCodeBench Elo de 2 887, il domine largement le domaine du codage algorithmique.
- Raisonnement complexe et recherche scientifique : ARC-AGI-2 à 77,1 %, GPQA Diamond à 94,3 %. Sa capacité de raisonnement pur se situe à un tout autre niveau que celle de Sonnet 4.6.
- Traitement multimodal : Support natif de la vidéo (jusqu'à 1 heure) et de l'audio (jusqu'à 8,4 heures), des fonctionnalités absentes chez Sonnet 4.6.
- Workflows d'agents MCP : MCP Atlas à 69,2 % (une avance de 7,9 points), ce qui le rend plus fiable pour construire des systèmes d'agents multi-étapes.
- Appels haute fréquence avec contexte court : Pour moins de 200k tokens, son tarif de 2 $/12 $ en fait l'option la plus économique des deux.
Quand choisir Claude Sonnet 4.6
- Travail intellectuel de niveau expert : Son score GDPval-AA de 1 633 Elo est le plus élevé parmi tous les modèles actuels. Inégalé pour les rapports de recherche, l'analyse financière et la stratégie commerciale.
- Édition de code en production : 0 % d'erreur lors des tests en environnement de production Replit. Il a d'ailleurs été choisi comme base pour l'agent de codage de GitHub Copilot.
- Appels d'outils et Computer Use : tau2-bench à 91,7 %, OSWorld à 72,5 %. Il offre une précision extrême pour l'automatisation des opérations et les appels de fonctions.
- Scénarios à contexte long : Au-delà de 200k tokens de contexte, le tarif de 3 $/15 $ de Sonnet 4.6 devient plus avantageux que les 4 $/18 $ de Gemini.
- Applications d'entreprise : Alignement de sécurité plus mature, mise en cache des invites (lecture à seulement 0,30 $/million de tokens, soit 90 % d'économie) et traitement par lots (Batch) à moitié prix.
Intégration rapide des API Gemini 3.1 Pro et Claude Sonnet 4.6
Exemple minimaliste
Via la plateforme APIYI, les deux modèles utilisent une interface unifiée :
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# Gemini 3.1 Pro - Meilleur en raisonnement et multimodal
response = client.chat.completions.create(
model="gemini-3.1-pro",
messages=[{"role": "user", "content": "Analyse la complexité temporelle de ce code et optimise-le"}]
)
print(response.choices[0].message.content)
Voir l’exemple d’appel pour Sonnet 4.6 et le basculement automatique par scénario
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# Claude Sonnet 4.6 - Meilleur pour le travail de connaissance et l'appel d'outils
response = client.chat.completions.create(
model="claude-sonnet-4-6",
messages=[{"role": "user", "content": "Rédige un rapport d'analyse de marché pour le T1, incluant une comparaison avec la concurrence et des suggestions de croissance"}]
)
print(response.choices[0].message.content)
# Routage automatique par scénario
def route_model(prompt, task_type="general"):
model_map = {
"reasoning": "gemini-3.1-pro",
"multimodal": "gemini-3.1-pro",
"algorithm": "gemini-3.1-pro",
"knowledge": "claude-sonnet-4-6",
"production_code": "claude-sonnet-4-6",
"tool_call": "claude-sonnet-4-6",
"general": "gemini-3.1-pro",
}
return client.chat.completions.create(
model=model_map.get(task_type, "gemini-3.1-pro"),
messages=[{"role": "user", "content": prompt}]
)
Conseil : Via la plateforme APIYI (apiyi.com), vous pouvez accéder aux deux modèles simultanément en utilisant une seule clé API pour basculer de l'un à l'autre. La plateforme offre un crédit de test gratuit, nous vous recommandons de comparer les résultats dans vos scénarios réels.
Comparaison approfondie des coûts entre Gemini 3.1 Pro et Sonnet 4.6
Estimation des coûts mensuels basée sur trois scénarios d'utilisation typiques :
| Scénario d'utilisation | Consommation mensuelle moyenne de tokens | Gemini 3.1 Pro | Claude Sonnet 4.6 | Option la moins chère |
|---|---|---|---|---|
| Utilisation légère (5M entrée + 1M sortie) | 6 millions | 22 $ | 30 $ | Gemini (27 % d'économie) |
| Utilisation modérée (20M entrée + 5M sortie) | 25 millions | 100 $ | 135 $ | Gemini (26 % d'économie) |
| Contexte long intensif (50M entrée >200K + 10M sortie) | 60 millions | 380 $ | 300 $ | ⚠️ Sonnet (21 % d'économie) |
🎯 Conclusion sur les coûts : En utilisation standard, Gemini 3.1 Pro est environ 26 % à 27 % moins cher. Cependant, si vous utilisez fréquemment des contextes longs dépassant 200K (comme l'analyse de bases de code complètes ou le traitement de documents longs), Sonnet 4.6 devient plus avantageux. En effet, le prix du contexte long de Gemini grimpe à 4 $/18 $, tandis que celui de Sonnet reste stable à 3 $/15 $. De plus, avec la mise en cache des invites (Prompt Caching) de Sonnet (lecture à seulement 0,30 $/million de tokens), le coût réel peut être inférieur de 30 % à 50 %.
L'accès via la plateforme APIYI (apiyi.com) permet de bénéficier de tarifs préférentiels supplémentaires, réduisant encore davantage les coûts d'utilisation des deux modèles.
Questions Fréquentes
Q1 : Le score GDPval-AA de Sonnet 4.6 est plus élevé que celui d’Opus 4.6, est-ce normal ?
C'est tout à fait exact. Sonnet 4.6 a obtenu un score Elo de 1 633 sur GDPval-AA, dépassant les 1 559 d'Opus 4.6. Anthropic a officiellement confirmé ces données. Cela s'explique probablement par le fait que Sonnet 4.6 a bénéficié d'optimisations spécifiques pour les scénarios de travail intellectuel en entreprise, tandis qu'Opus 4.6 se concentre davantage sur le raisonnement général et le traitement de contextes longs. Le taux de préférence des développeurs pour Sonnet 4.6 atteint également 70 % (par rapport à Sonnet 4.5) et 59 % (par rapport à Opus 4.5).
Q2 : Quel modèle est le plus adapté pour créer un Agent IA ?
Cela dépend du type d'agent. S'il s'agit d'un agent de flux de travail multi-étapes basé sur MCP, Gemini 3.1 Pro mène avec un score de 69,2 % sur MCP Atlas (soit 7,9 points d'avance). S'il s'agit d'un agent intensif en appels d'outils (comme OpenClaw), le score de 91,7 % de Sonnet 4.6 sur tau2-bench est plus fiable. Pour les agents de type "Computer Use" (contrôle du navigateur et du bureau), le score de 72,5 % de Sonnet 4.6 sur OSWorld est l'un des meilleurs résultats actuels. Les deux modèles sont directement accessibles pour test sur la plateforme APIYI (apiyi.com).
Q3 : J’utilise actuellement Sonnet 4.5, dois-je passer à Sonnet 4.6 ou changer pour Gemini 3.1 Pro ?
Si vous êtes satisfait de l'expérience de travail intellectuel et de codage avec Sonnet 4.5, passer à Sonnet 4.6 est le choix le plus sûr : compatibilité API totale, prix inchangé et performances en hausse sur tous les fronts (SWE-Bench passant de 77,2 % à 79,6 %, ARC-AGI-2 de 13,6 % à 58,3 %, soit une amélioration de 4,3 fois). Si vos besoins principaux s'orientent vers le raisonnement, le multimodal ou le codage algorithmique, Gemini 3.1 Pro présente des avantages significatifs dans ces domaines. Nous vous conseillons d'essayer les deux modèles via la plateforme APIYI (apiyi.com).
Conclusion
Voici les conclusions clés du comparatif entre Gemini 3.1 Pro et Claude Sonnet 4.6 :
- Raisonnement et multimodal : choisissez Gemini 3.1 Pro : Avance de 18,8 points sur ARC-AGI-2, 20,2 points sur GPQA Diamond, support natif vidéo/audio, plus économique pour les contextes courts.
- Travail intellectuel et codage de production : choisissez Claude Sonnet 4.6 : Son score Elo de 1 633 sur GDPval-AA est le plus élevé de tous les modèles (y compris Opus 4.6), taux d'erreur de 0 % sur Replit, premier choix pour GitHub Copilot.
- Scénarios à contexte long : Sonnet est plus rentable : Au-delà d'une fenêtre de contexte de 200k, Sonnet coûte 3 $ / 15 $ contre 4 $ / 18 $ pour Gemini. Avec la mise en cache des invites (Prompt caching), vous pouvez économiser 30 à 50 % de plus.
Ces deux modèles sont les modèles de pointe offrant le meilleur rapport qualité-prix en février 2026. La meilleure stratégie consiste à les utiliser de manière hybride selon vos besoins. Nous vous recommandons de passer par APIYI (apiyi.com) pour accéder aux deux simultanément et basculer de l'un à l'autre selon vos besoins avec une seule clé API.
📚 Références
-
Annonce de la sortie de Claude Sonnet 4.6 : Blog officiel d'Anthropic
- Lien :
anthropic.com/news/claude-sonnet-4-6 - Description : Présentation complète des fonctionnalités de Sonnet 4.6, données de benchmark et fonction de réflexion adaptative.
- Lien :
-
Blog officiel de Gemini 3.1 Pro : Annonce de Google DeepMind
- Lien :
blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-pro/ - Description : Le système de réflexion à trois niveaux de Gemini 3.1 Pro et les données de performance complètes.
- Lien :
-
Comparatif pratique de Tom's Guide : 7 défis réels pour départager Gemini 3.1 Pro et Sonnet 4.6
- Lien :
tomsguide.com/ai/i-tested-gemini-3-1-pro-vs-claude-sonnet-4-6-in-7-tough-challenges-and-there-was-one-clear-winner - Description : Comparaison des performances réelles dans des scénarios de tâches concrètes.
- Lien :
-
Classement Artificial Analysis : Plateforme indépendante d'évaluation de modèles
- Lien :
artificialanalysis.ai/leaderboards/models - Description : Données comparatives objectives sur la performance, la vitesse et le prix.
- Lien :
Auteur : Équipe technique
Échanges techniques : N'hésitez pas à partager votre expérience dans l'espace commentaires. Pour plus d'actualités sur les grands modèles de langage, rendez-vous sur APIYI (apiyi.com).