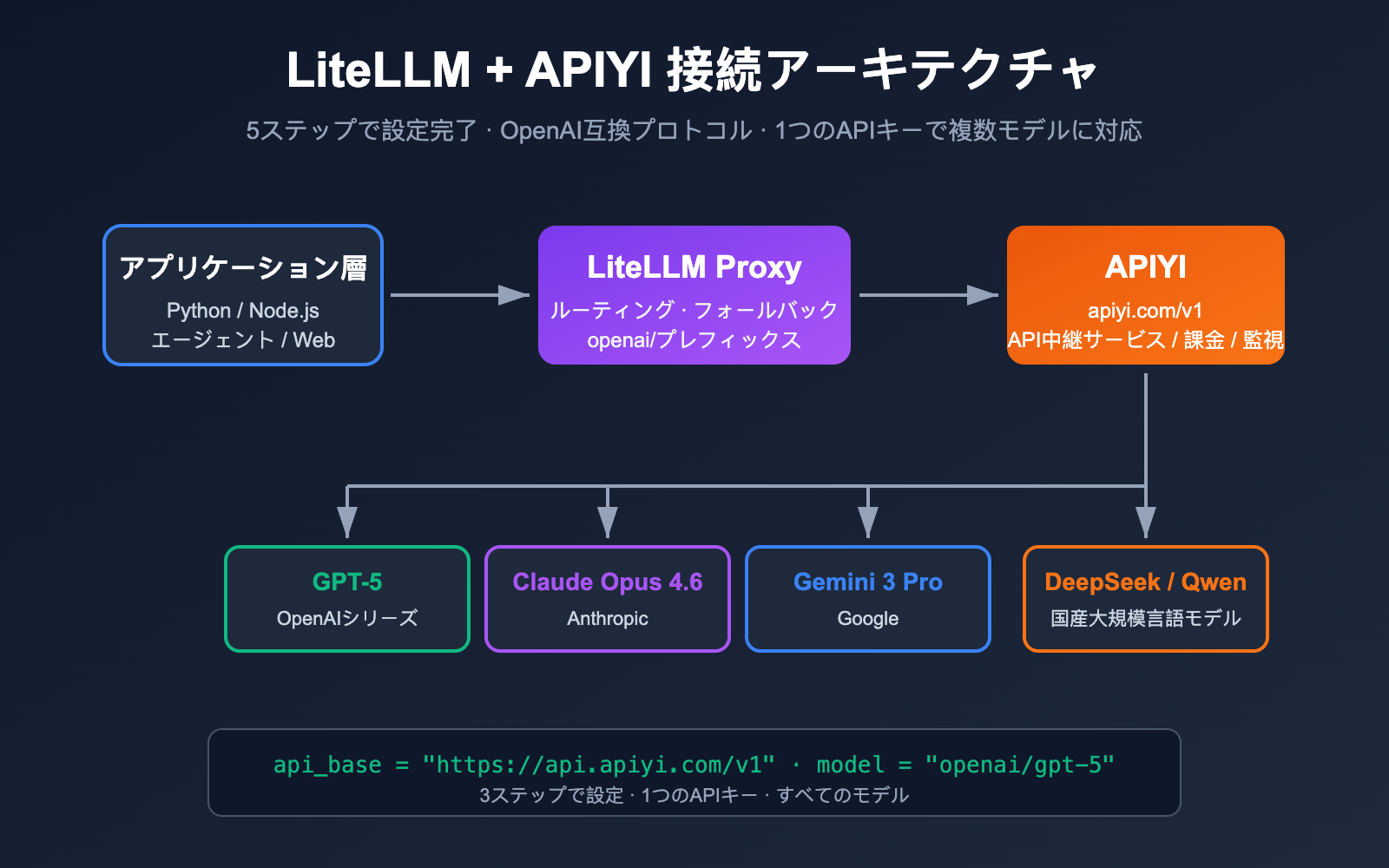
LiteLLM を使って OpenAI、Claude、Gemini、DeepSeek などの複数の大規模言語モデルを同時に管理したいけれど、海外アカウントの作成、ネットワーク環境、決済といった壁にぶつかっていませんか?その解決策は、LiteLLM を OpenAI 互換のサードパーティ製 API 中継サービスに接続することです。本記事では、LiteLLM + APIYI (apiyi.com) を例に、設定手順を分かりやすく解説します。
核心的価値: 本記事を読めば、LiteLLM で API 中継サービスを利用する 3 つの主要な方法(SDK、Proxy YAML、環境変数)を習得でき、5 分以内に APIYI への接続を完了できるようになります。
LiteLLM でサードパーティ製 API 中継サービスを設定する際のポイント
LiteLLM は、OpenAI 互換フォーマットを使用して 100 以上の大規模言語モデルを呼び出すことを目的としたオープンソースの LLM ゲートウェイ / SDK です。任意の「OpenAI 互換」エンドポイントをサポートしており、api_base を中継サービスに向け、api_key を中継サービスが発行したものに置き換えるだけで利用可能です。APIYI (apiyi.com) は標準的な OpenAI 互換の中継サービスであるため、両者の相性は抜群です。
| ポイント | 説明 | 価値 |
|---|---|---|
| OpenAI 互換プロトコル | LiteLLM は openai/ プレフィックスを通じて OpenAI クライアントにルーティング |
1 行の設定で任意の中継サービスに接続可能 |
| 3 つの設定方法 | SDK インライン / Proxy YAML / 環境変数 | スクリプト、本番環境、CLI の 3 つのシナリオに対応 |
| 統一されたモデル名 | openai/<provider-model> またはカスタム model_name |
上位コードで基盤の切り替えを意識する必要なし |
| エラー調査の鍵 | base_url は必ず /v1 で終わる必要がある |
404 エラーの 90% はここが原因 |
| フォールバックと負荷分散 | YAML モードで複数チャネルと失敗時の切り替えをサポート | 本番環境の可用性を最大化 |
LiteLLM でサードパーティ製 API 中継サービスを設定する詳細
LiteLLM の公式ドキュメントには、「モデル名の前に openai/ プレフィックスを付け、api_base を指定すれば、LiteLLM は OpenAI クライアントを使用してエンドポイントにアクセスする」と明記されています。これは、中継サービスの背後にあるのが GPT-5、Claude Opus 4.6、Gemini 3 Pro、DeepSeek のいずれであっても、LiteLLM にとっては「1 つの OpenAI エンドポイント」として扱われることを意味します。
APIYI (apiyi.com) の base_url は https://api.apiyi.com/v1 であり、標準的な /v1/chat/completions、/v1/embeddings、/v1/images/generations 仕様に準拠しているため、パッチを当てることなく LiteLLM と完全に互換性があります。

LiteLLM でサードパーティAPI中継サービスを設定する:クイックスタート
準備作業
始める前に、以下の準備を整えてください:
- APIYI APIキー: apiyi.com に登録後、コンソールで新しいキーを作成します(
litellm-prodなどの名前を推奨)。 - base_url:
https://api.apiyi.com/v1(末尾に/v1が必須です) - Python環境: Python 3.9以上
- 依存関係のインストール:
pip install litellm
シンプルな例:SDK内での設定
最も手軽な接続方法は、コード内で api_key と api_base を直接指定することです:
import litellm
response = litellm.completion(
model="openai/gpt-5", # 重要:openai/ プレフィックス
api_key="YOUR_APIYI_KEY",
api_base="https://api.apiyi.com/v1", # APIYI 中継サービスのアドレス
messages=[
{"role": "user", "content": "LiteLLMについて一言で紹介してください"}
],
)
print(response.choices[0].message.content)
💡 アドバイス: APIYI apiyi.com コンソールでテスト用クレジットを取得した後、
gpt-5をclaude-opus-4-6やgemini-3-proなどのモデル名に書き換えるだけで、他のコードを変更せずに利用可能です。これこそが OpenAI 互換プロトコルの最大のメリットです。
完全な実行サンプルを表示 (エラーハンドリングとストリーミング出力を含む)
import os
import litellm
from litellm import completion
# キー管理には環境変数を利用することを推奨します
os.environ["OPENAI_API_KEY"] = "YOUR_APIYI_KEY"
os.environ["OPENAI_API_BASE"] = "https://api.apiyi.com/v1"
litellm.set_verbose = False # デバッグ時は True に変更
def chat_with_apiyi(model: str, prompt: str, stream: bool = False):
"""LiteLLM + APIYI を通じて任意の OpenAI 互換モデルを呼び出す"""
try:
response = completion(
model=f"openai/{model}",
messages=[{"role": "user", "content": prompt}],
stream=stream,
temperature=0.7,
max_tokens=1024,
)
if stream:
for chunk in response:
delta = chunk.choices[0].delta.content or ""
print(delta, end="", flush=True)
print()
else:
return response.choices[0].message.content
except Exception as e:
print(f"呼び出し失敗: {e}")
return None
if __name__ == "__main__":
# 非ストリーミング
print(chat_with_apiyi("gpt-5", "LLMゲートウェイとは何か説明してください"))
# ストリーミング
chat_with_apiyi("claude-opus-4-6", "LiteLLMの利点を100文字で紹介してください", stream=True)
Proxy YAML 設定:本番環境向け
LiteLLM を独立したサービス(ポート 4000、チーム共有用)として運用する場合は、YAML モードを推奨します。litellm_config.yaml を新規作成します:
model_list:
- model_name: gpt-5 # 外部公開するモデル名
litellm_params:
model: openai/gpt-5 # openai/ プレフィックスで OpenAI クライアントへルーティング
api_base: https://api.apiyi.com/v1 # APIYI 中継アドレス
api_key: os.environ/APIYI_KEY # 環境変数を参照
- model_name: claude-opus-4-6
litellm_params:
model: openai/claude-opus-4-6
api_base: https://api.apiyi.com/v1
api_key: os.environ/APIYI_KEY
- model_name: gemini-3-pro
litellm_params:
model: openai/gemini-3-pro
api_base: https://api.apiyi.com/v1
api_key: os.environ/APIYI_KEY
litellm_settings:
drop_params: true # モデルがサポートしないパラメータを自動除外
num_retries: 2 # 呼び出しリトライ回数
router_settings:
fallbacks:
- gpt-5: ["claude-opus-4-6", "gemini-3-pro"]
Proxy を起動します:
export APIYI_KEY=sk-xxxxxxxxxxxxxxxx
litellm --config ./litellm_config.yaml --port 4000
以降、任意の OpenAI SDK から http://localhost:4000 を通じて呼び出し可能です:
from openai import OpenAI
client = OpenAI(
api_key="any-string", # LiteLLM Proxy は内容を検証しません(master_key設定時を除く)
base_url="http://localhost:4000",
)
resp = client.chat.completions.create(
model="gpt-5",
messages=[{"role": "user", "content": "Hello via LiteLLM Proxy"}]
)
print(resp.choices[0].message.content)
🎯 本番環境のヒント: LiteLLM Proxy の前に master_key を配置し、すべての基盤モデルを APIYI apiyi.com に集約することをお勧めします。これにより、アプリケーション層からは
gpt-5/claude-opus-4-6といった「セマンティックモデル名」のみが見え、基盤となるチャネル、課金、レート制限はすべて APIYI + LiteLLM の2層で処理されるため、上位層は意識する必要がありません。
環境変数モード:CLI やスクリプトに最適
使い捨てのスクリプトやコマンドラインツールの場合、環境変数を直接使うのが最も簡単です。LiteLLM は OPENAI_API_KEY と OPENAI_API_BASE を自動的に認識します:
export OPENAI_API_KEY=sk-xxxxxxxxxxxxxxxx
export OPENAI_API_BASE=https://api.apiyi.com/v1
これ以降、openai/ プレフィックスが付いたすべての呼び出しは APIYI を経由します:
import litellm
print(litellm.completion(
model="openai/gpt-5",
messages=[{"role": "user", "content": "ping"}]
).choices[0].message.content)
LiteLLM でサードパーティ中継サービスを設定する:3つの方式比較
用途に応じて最適な設定方式は異なります。以下の表を参考にしてください。
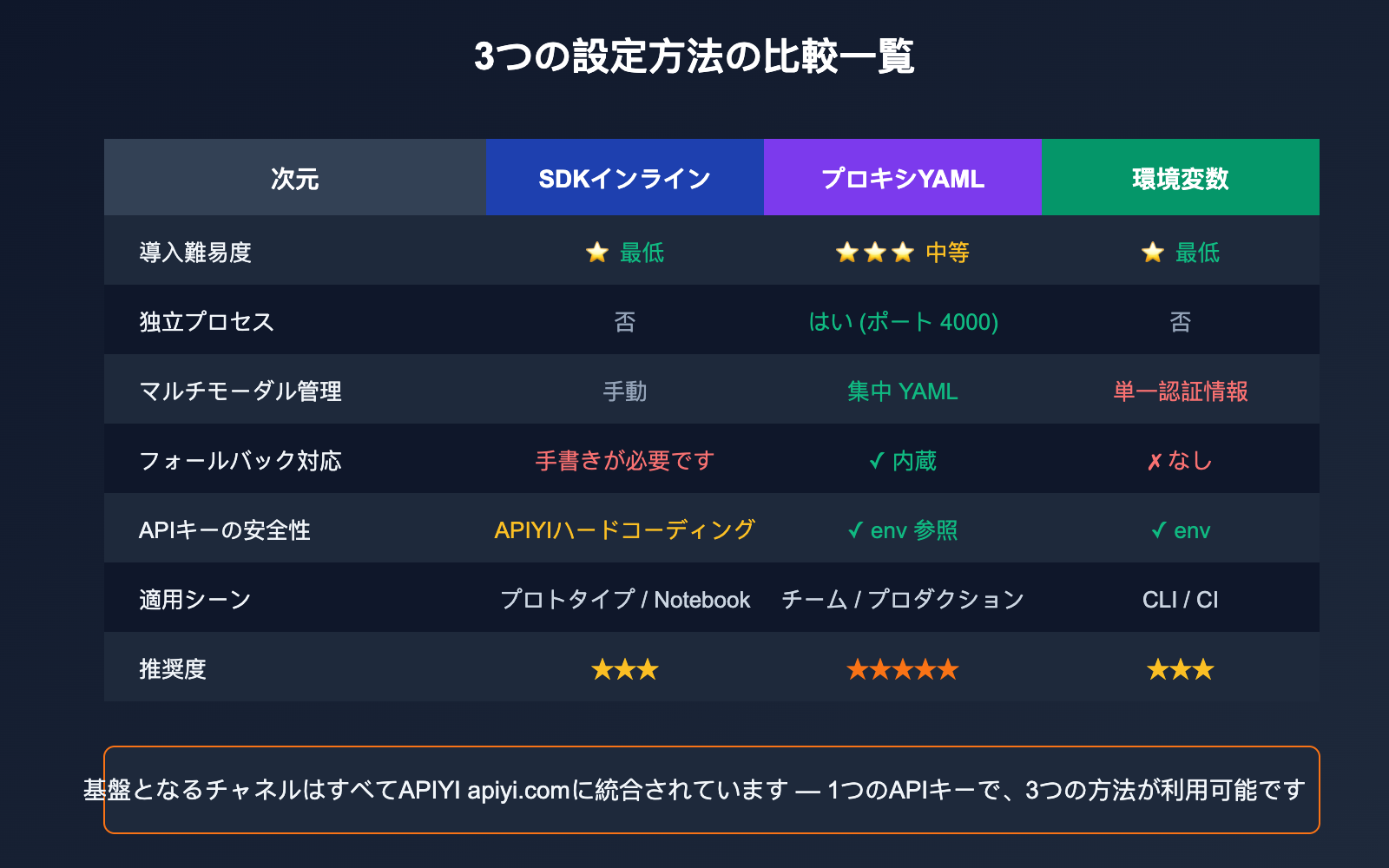
| 項目 | SDK内設定 | Proxy YAML | 環境変数 |
|---|---|---|---|
| 導入難易度 | ⭐ 最低 | ⭐⭐⭐ 中等 | ⭐ 最低 |
| 適した用途 | 単発スクリプト、Notebook | チーム共有、本番サービス | CLIツール、CI |
| 独立プロセス | 不要 | 必要(ポート4000) | 不要 |
| マルチモデル管理 | 手動管理 | YAMLで一元管理 | 単一認証のみ |
| Fallback対応 | try/exceptで手動実装 | ✅ 内蔵 | ❌ なし |
| キーの安全性 | ハードコードのリスク | ✅ 環境変数参照 | ✅ 環境変数利用 |
| 推奨度 | プロトタイプ段階 | 本番運用 | 個人スクリプト |
💡 選択のヒント: 個人の開発であれば環境変数が手軽ですが、チームや本番環境では「モデルルーティング + Fallback + レート制限 + 統計」を1つのファイルで管理できる Proxy YAML モードを強く推奨します。どの方法を選んでも、基盤となるチャネルを APIYI apiyi.com に接続するという点は共通しており、APIキーを1つ管理するだけで済みます。
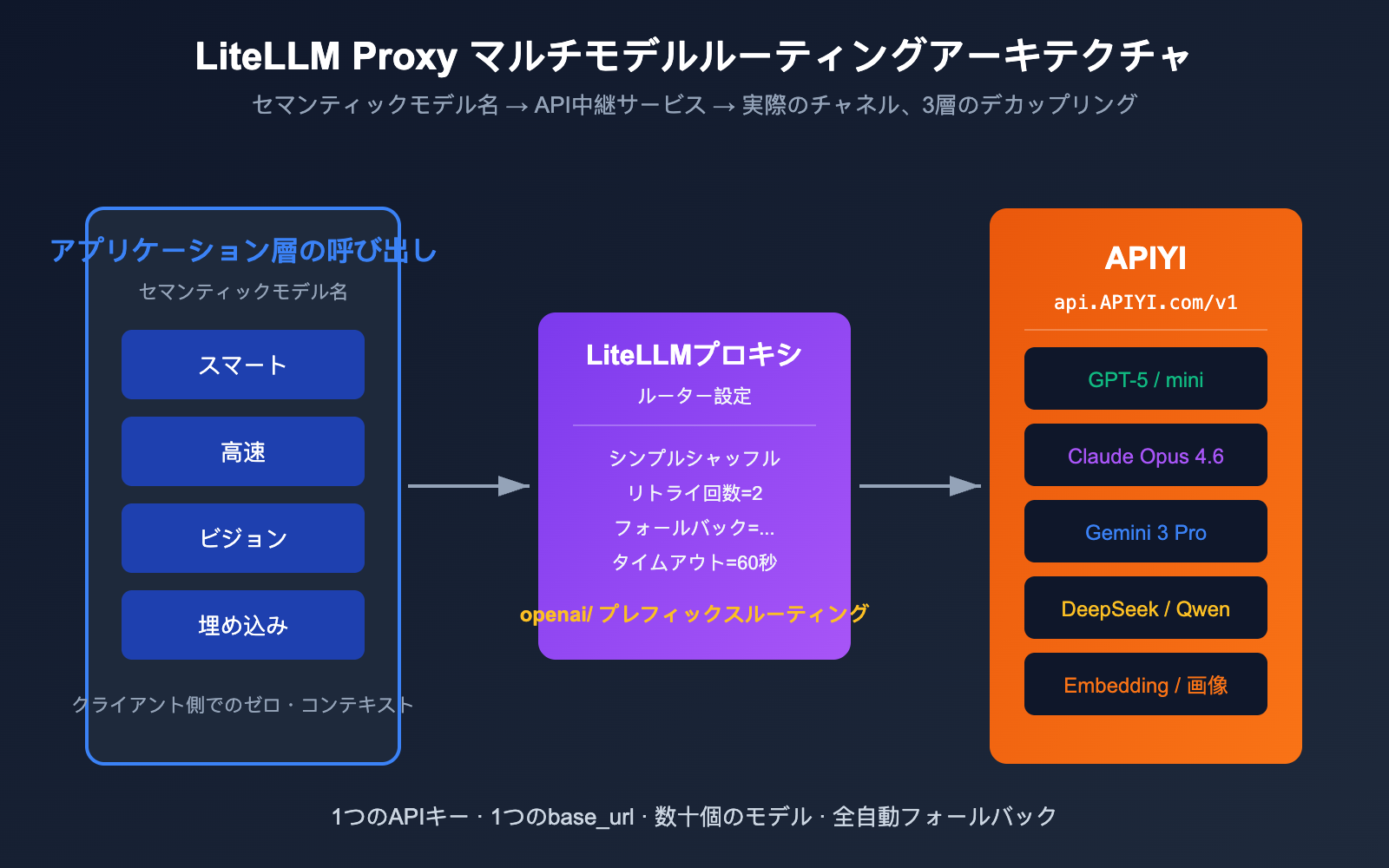
LiteLLM + APIYI:マルチモデルルーティングの実践
LiteLLM Proxyモードの真の強みは、同一のYAMLファイルを使用して「セマンティックなモデル名(論理名)」から「実際のチャネル」へのマッピングを完結できる点にあります。以下に、本番環境でも利用可能な最小構成のルーティング設定を紹介します。
# litellm_config.yaml - 本番環境ルーティング例
model_list:
# メイン推論モデル
- model_name: smart
litellm_params:
model: openai/gpt-5
api_base: https://api.apiyi.com/v1
api_key: os.environ/APIYI_KEY
timeout: 60
- model_name: smart
litellm_params:
model: openai/claude-opus-4-6
api_base: https://api.apiyi.com/v1
api_key: os.environ/APIYI_KEY
timeout: 60
# 高速・安価なモデル
- model_name: fast
litellm_params:
model: openai/gpt-5-mini
api_base: https://api.apiyi.com/v1
api_key: os.environ/APIYI_KEY
# ビジョン/マルチモーダル
- model_name: vision
litellm_params:
model: openai/gemini-3-pro
api_base: https://api.apiyi.com/v1
api_key: os.environ/APIYI_KEY
# Embedding(埋め込み)
- model_name: embed
litellm_params:
model: openai/text-embedding-3-large
api_base: https://api.apiyi.com/v1
api_key: os.environ/APIYI_KEY
litellm_settings:
drop_params: true
num_retries: 2
request_timeout: 60
router_settings:
routing_strategy: simple-shuffle # 同名モデルのラウンドロビン
fallbacks:
- smart: ["fast"] # smartが失敗した際にfastへフォールバック
general_settings:
master_key: sk-litellm-master-xxxx # クライアント側で必須となるキー
アプリケーション層からは smart / fast / vision / embed という4つのセマンティックな名前しか見えません。GPT-5がレート制限に達した場合、LiteLLMは自動的にClaude Opus 4.6へ切り替え(両方とも smart として登録されているため)、さらに失敗した場合は fast へフォールバックします。すべての基盤トラフィックは APIYI (apiyi.com) を経由して統合的に課金・監視されるため、アプリケーション層とチャネル層を完璧に分離できます。
LiteLLMでAPI中継サービスを設定する際のよくある質問
Q1: base_url を設定したのに 404 Not Found になるのはなぜですか?
9割のケースで、api_base の末尾に /v1 が不足しています。LiteLLMは内部でOpenAIクライアントを使用しており、自動的に /chat/completions を連結します。そのため、api_base は https://api.apiyi.com/v1 と指定する必要があります(https://api.apiyi.com ではない)。また、https://api.apiyi.com/v1/chat/completions と書いてしまうと重複して連結されるため注意してください。
Q2: なぜモデル名に openai/ というプレフィックスが必要なのですか?
LiteLLMは内部でプロバイダーのルーティングテーブルを管理しています。openai/ プレフィックスはLiteLLMに対し「OpenAIクライアントを使ってこのエンドポイントにアクセスせよ」という指示を与えます。プレフィックスがない場合、LiteLLMは組み込みのプロバイダー(例えば claude-opus-4-6 をAnthropicのネイティブAPIと認識するなど)とマッチングしようとして、プロトコルエラーになる可能性があります。中継サービスを利用する際は、常に openai/ プレフィックスを付けてください。
Q3: 1つの APIYI キーで複数のモデルを同時に呼び出せますか?
はい、可能です。APIYI (apiyi.com) の単一キーは、デフォルトでGPT-5、Claude Opus 4.6、Gemini 3 Pro、DeepSeek、Qwenなど、プラットフォーム上のすべての利用可能なモデルをサポートしています。これこそが公式APIとの決定的な違いであり、キーとベースURLを1つ管理するだけで、LiteLLMのYAML設定に数十個のモデルをマウントできます。
Q4: LiteLLM Proxy 起動後、中継経路が正常か確認するには?
最も手っ取り早いのは、curlで直接LiteLLM Proxyを叩く方法です:
curl http://localhost:4000/v1/chat/completions \
-H "Authorization: Bearer sk-litellm-master-xxxx" \
-H "Content-Type: application/json" \
-d '{
"model": "smart",
"messages": [{"role": "user", "content": "ping"}]
}'
200 OK + JSONが返ってくれば、アプリケーション → LiteLLM Proxy → APIYI の経路は正常です。失敗した場合は、まずLiteLLMのコンソールログを確認し、次に同じベースURLとキーを使って直接APIYIを叩いてみることで、問題箇所を切り分けられます。
Q5: ストリーミング出力 (stream) は中継環境で追加設定が必要ですか?
不要です。APIYI (apiyi.com) はSSEストリーミングレスポンスを完全にサポートしており、LiteLLMはデフォルトで透過的に転送します。completion() 呼び出し時に stream=True を指定するか、OpenAI SDKでProxyを呼び出す際に stream=True を含めるだけで、トークンごとの出力を受け取ることができます。
Q6: Embedding(埋め込み)や画像生成も同時に接続できますか?
はい。APIYI (apiyi.com) は /v1/embeddings、/v1/images/generations、/v1/audio/transcriptions をすべてサポートしており、同一のベースURLとキーで利用可能です。LiteLLMのYAML設定で、対応するモデルを model_list に追加するだけです(例:text-embedding-3-large、gpt-image-1、whisper-1)。使い方はチャットモデルと完全に同じです。詳細は前述の「本番環境ルーティング例」を参照してください。
まとめ
LiteLLM でサードパーティの API 中継サービスを設定する際、本質的には以下の3つのステップを行うだけです。
- プロトコルの整合: モデル名に
openai/というプレフィックスを付けることで、LiteLLM に対して OpenAI クライアントプロトコルを使用するよう指示します。 - エンドポイントの整合:
api_baseに中継サービスのルートパス +/v1を指定します(例:https://api.apiyi.com/v1)。 - 認証情報の整合: 中継サービスから発行されたキーを
api_keyまたは環境変数を通じて渡します。
この3ステップを完了すれば、LiteLLM のあらゆる機能(マルチモデルルーティング、フォールバック、レート制限、課金管理、ロギングなど)を、安定した中継サービス上でシームレスに利用できるようになります。
🚀 推奨アクション: チーム向けに統一された LLM ゲートウェイを構築中であれば、「アプリケーション → LiteLLM Proxy → APIYI (apiyi.com)」という3層構造を採用することをおすすめします。LiteLLM がルーティングとフォールバックを担い、APIYI が基盤となるモデル接続、安定性、従量課金を提供します。管理が必要なのは YAML ファイルと API キーだけです。apiyi.com に登録すればテスト用クレジットが取得でき、5分以内に最初の呼び出しを完了できます。
著者: APIYI Team — 開発者向けに主要な AI 大規模言語モデルへの安定したアクセスを提供しています。詳細は apiyi.com をご覧ください。
参考資料
-
LiteLLM 公式ドキュメント – OpenAI 互換エンドポイント
- リンク:
docs.litellm.ai/docs/providers/openai_compatible - 説明: SDK および Proxy YAML の公式サンプル
- リンク:
-
LiteLLM Proxy 設定概要
- リンク:
docs.litellm.ai/docs/proxy/configs - 説明: model_list、router_settings、fallbacks の全フィールド解説
- リンク:
-
LiteLLM GitHub リポジトリ
- リンク:
github.com/BerriAI/litellm - 説明: ソースコード、Issue、最新バージョン情報
- リンク:
-
daily_stock_analysis – LLM_CONFIG_GUIDE
- リンク:
github.com/ZhuLinsen/daily_stock_analysis/blob/main/docs/LLM_CONFIG_GUIDE.md - 説明: 3つの設定モードとマルチチャネル運用の実践ガイド
- リンク:
-
APIYI 公式ドキュメント
- リンク:
apiyi.com - 説明: 対応モデル一覧、base_url および API キーの管理について
- リンク: