作者注:OpenClaw(Open WebUI)の Token 消費が異常に高い5つの原因(隠れたバックグラウンド API 呼び出し、会話履歴の累積など)を深く分析し、即座に効果を発揮する最適化設定案を提供します。
「『あなたは何のモデルですか?』と一言聞いただけで、なぜ Prompt Token が 10,000 以上も消費されるの?」これは多くの OpenClaw ユーザーが抱く切実な疑問です。本記事では、技術的な視点から OpenClaw の Token 消費が高すぎる根本原因を解析し、即座に導入できる5つの最適化ソリューションを紹介します。
核心となる価値: 本記事を読み終える頃には、OpenClaw の Token 消費が予想を遥かに超える理由を理解し、Token コストを 60〜80% 削減するための具体的な設定方法を習得できるはずです。
OpenClaw Token 消費の核心ポイント
| ポイント | 説明 | 影響度 |
|---|---|---|
| 隠れたバックグラウンド呼び出し | 1つのメッセージにつき 4〜5 回の独立した API 呼び出しが発生 | ⭐⭐⭐⭐⭐ 最高 |
| 会話履歴の累積 | ターンごとに全履歴メッセージを再送信 | ⭐⭐⭐⭐ 高 |
| タスクモデルの未分離 | バックグラウンドタスクがデフォルトでメインモデルを使用 | ⭐⭐⭐⭐ 高 |
| システムプロンプトの注入 | ツール説明や RAG コンテキストが自動注入される | ⭐⭐⭐ 中 |
| システムプロンプト重複バグ | Agentic なツール呼び出し時にシステムプロンプトが重なる | ⭐⭐⭐ 中 |
OpenClaw Token 消費が高い根本原因
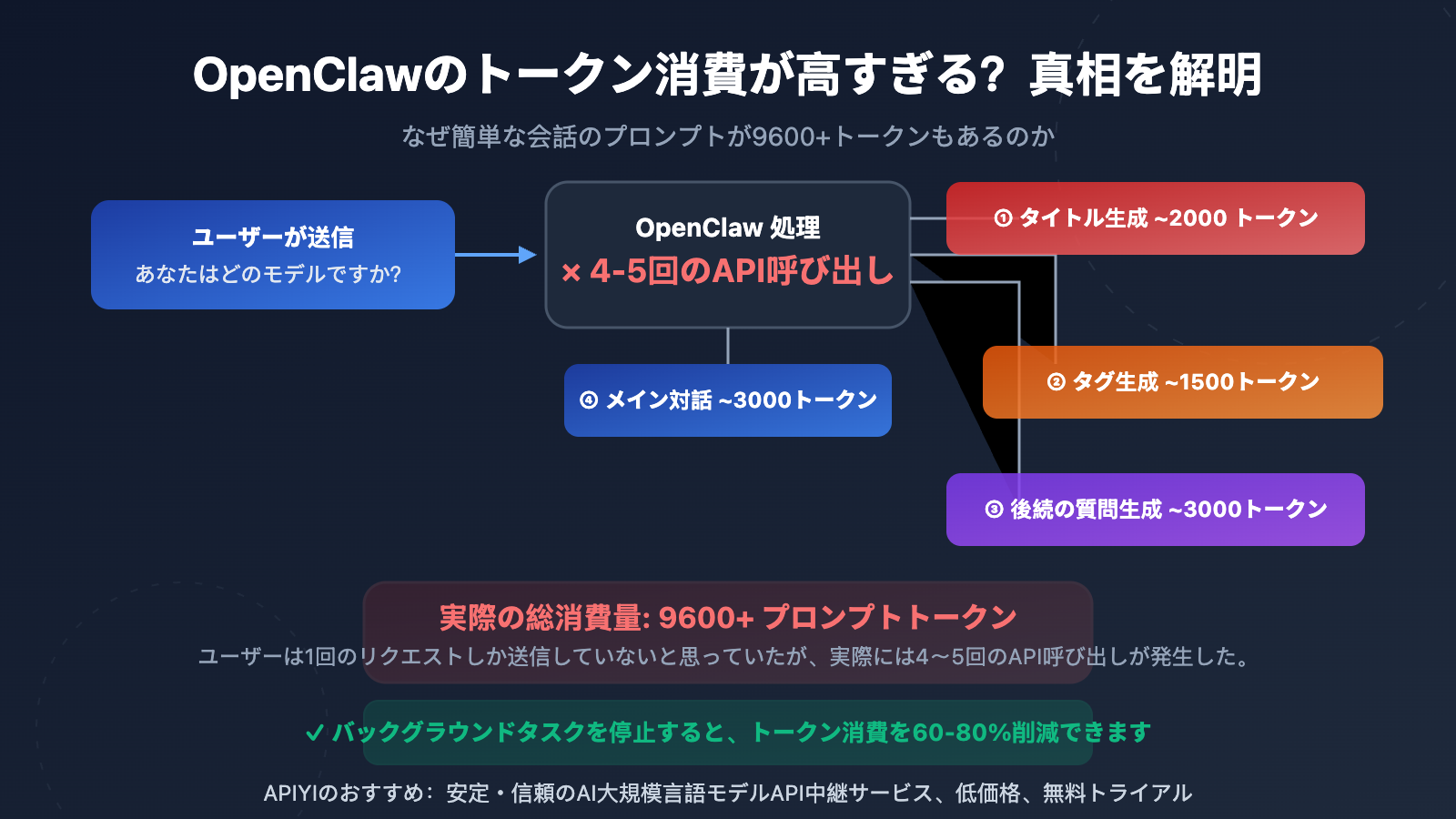
多くのユーザーが API の使用統計を見て驚愕します。単に「あなたは何のモデルですか?」といった簡単な質問をしただけなのに、Prompt Token が 9,600〜10,000+ に達しているからです。これは API プロバイダーの課金ミスではなく、OpenClaw(Open WebUI)のアーキテクチャ設計に起因しています。
核心的な原因は、OpenClaw がユーザーがメッセージを送信するたびに、バックグラウンドで複数の独立した API 呼び出しを自動的にトリガーすることにあります。これらの呼び出しはユーザーには完全に見えませんが、その一つひとつが実際の Token を消費しています。
OpenClaw Token 消費の5大要因を詳解
要因 1:タイトル自動生成(Title Generation)
ユーザーが最初のメッセージを送信した後、OpenClaw は 3〜5 文字程度の会話タイトルを生成するために API を自動的に呼び出します。この呼び出しはユーザーのメッセージ内容を送信するため、約 1,500〜2,000 Prompt Token を消費します。
要因 2:タグ自動生成(Tag Generation)
同時に、OpenClaw は会話に 1〜3 個の分類タグを付けるために API を呼び出します。これも独立した API 呼び出しであり、約 1,000〜1,500 Prompt Token を消費します。
要因 3:次の質問の提案(Follow-up Generation)
OpenClaw はデフォルトで 3〜5 個の「次の質問」の提案を生成します。この呼び出しは {{MESSAGES:END:6}} テンプレートを使用し、直近 6 件の会話メッセージをコンテキストとして取得するため、約 2,000〜3,000 Prompt Token を消費します。
要因 4:オートコンプリート(Autocomplete Generation)
一部のバージョンの OpenClaw では、ユーザーが次に入力する内容を予測する入力オートコンプリート機能が有効になっています。
要因 5:メインの会話リクエスト自体
最後に、ユーザーが実際に目にするメインの会話リクエストが実行されます。これにはシステムプロンプト、会話履歴、およびユーザーの入力が含まれます。
OpenClaw Token消費のクイック最適化ガイド
最小構成:バックグラウンドタスクの無効化
最も手軽な最適化方法は、環境変数を使用して不要なバックグラウンドAPI呼び出しを無効にすることです。
# docker-compose.yml に環境変数を追加
environment:
- ENABLE_TITLE_GENERATION=false
- ENABLE_TAGS_GENERATION=false
- ENABLE_FOLLOW_UP_GENERATION=false
- ENABLE_AUTOCOMPLETE_GENERATION=false
管理パネルからの設定手順を確認する
環境変数の変更が難しい場合は、OpenClawの管理パネルから設定することも可能です。
- OpenClawの管理画面にログインします。
- Settings → Tasks に移動します。
- 以下のオプションを順次「オフ」にします。
- Title Generation(タイトル生成) → オフ
- Tags Generation(タグ生成) → オフ
- Follow-up Generation(関連質問の生成) → オフ
- Autocomplete Generation(オートコンプリート生成) → オフ
- 完全にオフにしたくない場合は、Task Model を廉価なモデル(
gpt-4o-miniなど)に設定してください。 - 設定を保存し、ページを更新します。
# 方法2:機能は無効化せず、バックグラウンドタスクに廉価モデルを使用する
environment:
- TASK_MODEL_EXTERNAL=gpt-4o-mini
これにより、バックグラウンドタスク(タイトル、タグ、関連質問の自動生成)は引き続き動作しますが、メインのチャットモデルではなく、より低価格なモデルが使用されるようになります。
🎯 最適化のアドバイス: バックグラウンドタスクを無効化することは、OpenClawのToken消費を抑える最も直接的な方法です。APIYI (apiyi.com) を通じてAPIを利用している場合、これらの最適化により利用コストを大幅に削減できます。APIYIは統合されたマルチモデルインターフェースを提供しているため、異なるTask Modelの設定も簡単に行えます。
OpenClaw Token消費の実際のデータ分析
以下はユーザーから報告された実際のToken消費データです。問題の深刻さが一目でわかります。
| 利用シーン | 予想されるToken消費 | 実際のToken消費 | 倍率 |
|---|---|---|---|
| シンプルな質疑応答「あなたはどのモデルですか?」 | ~200 | 9,600 – 10,269 | 50倍 |
| 日常的な会話 5往復 | ~3,000 | ~45,000 | 15倍 |
| プログラミングに関する会話 30往復 | ~12,000 | 1,860,000 | 155倍 |
| ドキュメントアップロード後の会話 | ~5,000 | 600,000+ | 120倍 |
上記の表のデータは、Open WebUIのGitHubコミュニティにおける実際のユーザーフィードバックに基づいています。30往復のプログラミング会話で155倍という極端な数値になった主な原因は、関連質問生成テンプレート {{MESSAGES:END:6}} が直近の6メッセージを取得するためです。プログラミングの会話では、1つのメッセージに大量のコードが含まれることが多いため、消費が膨れ上がります。
OpenClaw Token消費における会話ターンの累積効果
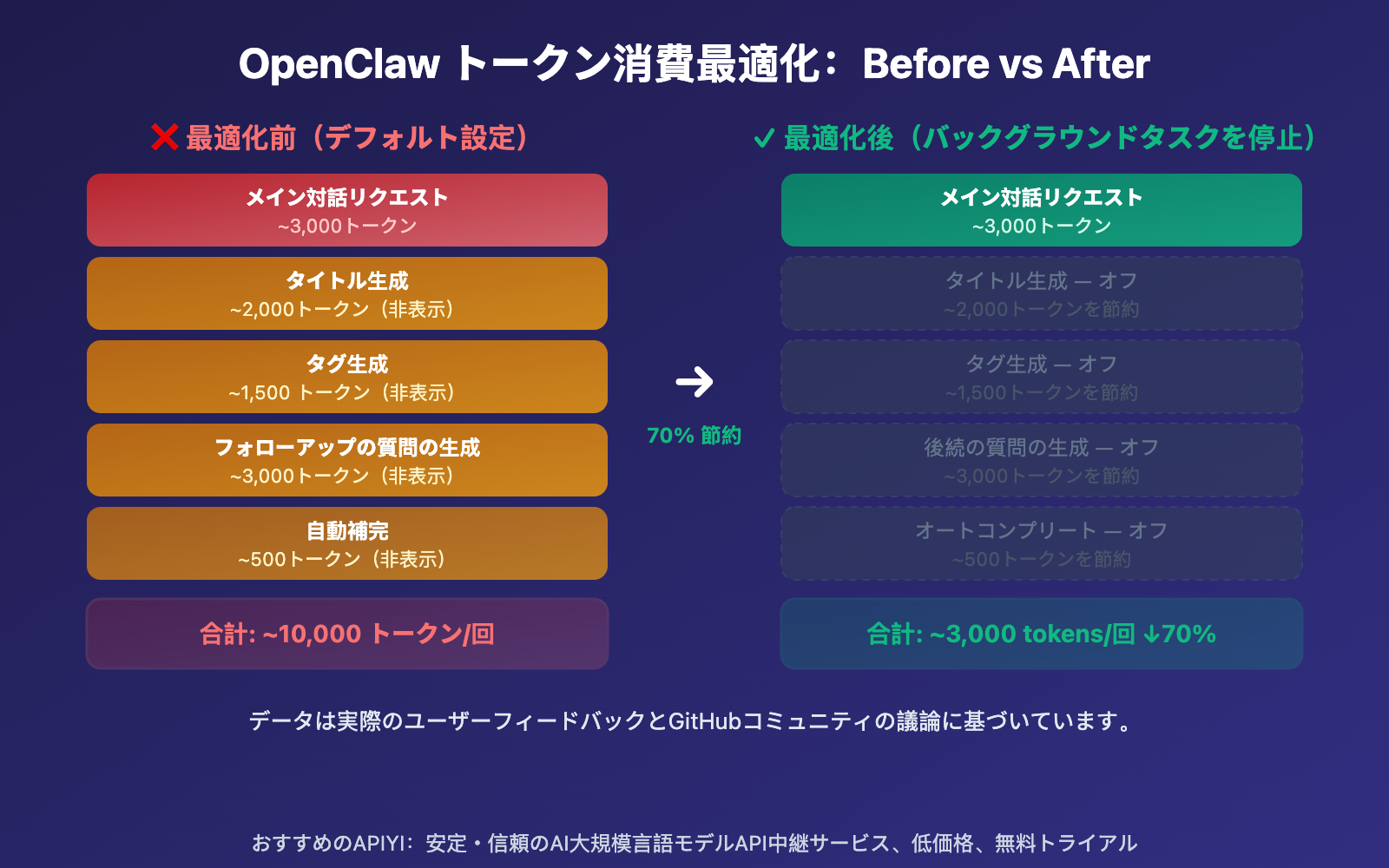
| 会話ターン数 | デフォルト設定での消費 | 最適化後の消費 | 節約率 |
|---|---|---|---|
| 第1ターン | ~10,000 | ~3,000 | 70% |
| 第5ターン | ~50,000 | ~15,000 | 70% |
| 第10ターン | ~150,000 | ~45,000 | 70% |
| 第20ターン | ~500,000 | ~150,000 | 70% |
| 第30ターン | ~1,200,000 | ~360,000 | 70% |
会話のターン数が増えるにつれて、Token消費量は指数関数的に増加します。これは、各ターンの会話で会話履歴全体が再送信されるためです。デフォルト設定では、この履歴がメインのチャットで送信されるだけでなく、タイトルの生成、タグの生成、関連質問の生成でもそれぞれ送信されます。
🎯 コスト管理のアドバイス: 長い会話シーンでは、Token消費の増加が特に顕著になります。APIYI (apiyi.com) を使用してモデル呼び出しを行うことをお勧めします。プラットフォームが提供する詳細な利用統計パネルにより、Token消費を簡単に監視し、最適化することが可能です。
OpenClaw Token 消費最適化プランの比較
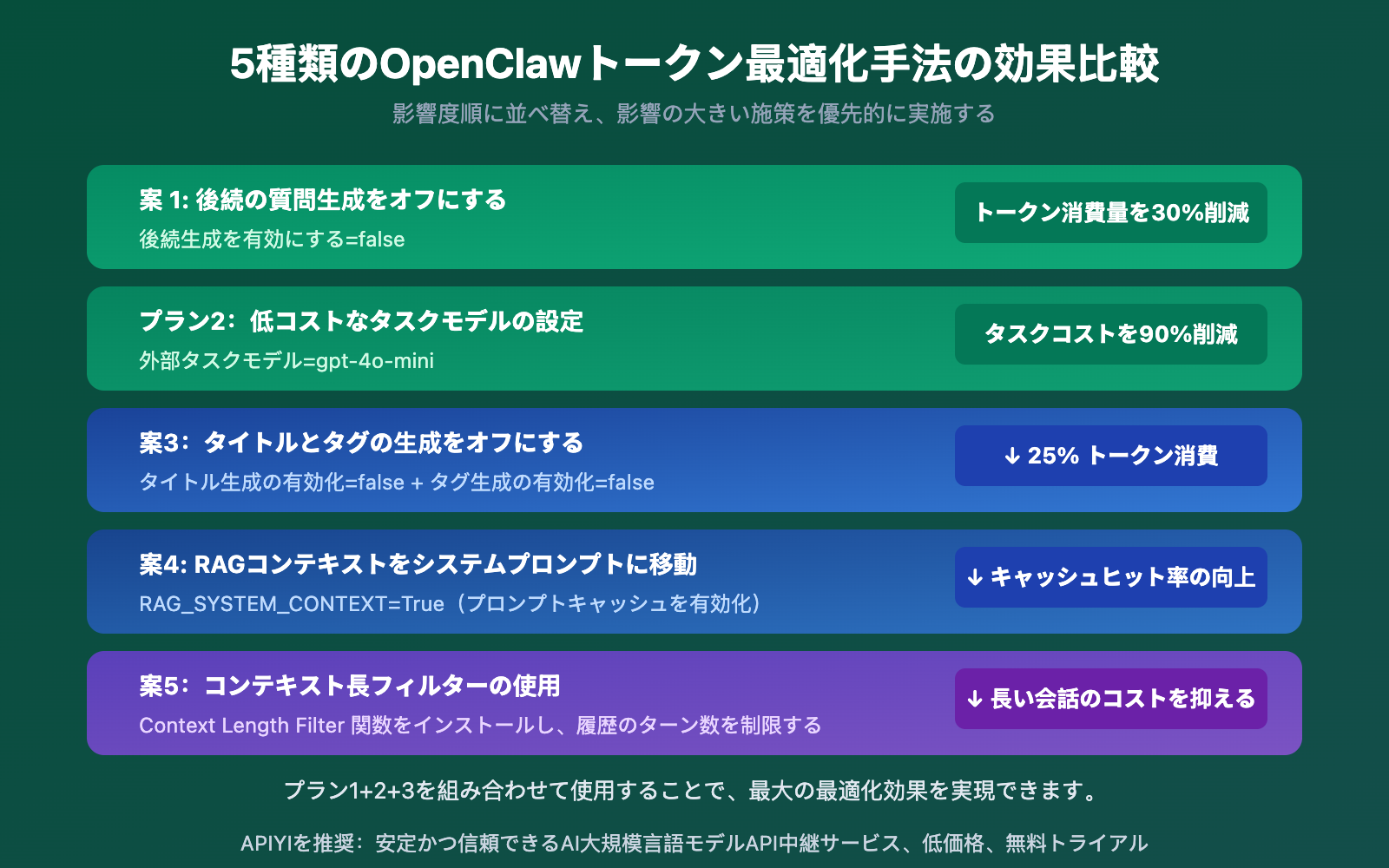
| 最適化プラン | 操作難易度 | Token 節約 | 機能への影響 | 推奨度 |
|---|---|---|---|---|
| 関連質問の生成をオフ | 簡単 | ~30% | 提案される質問が表示されなくなる | ⭐⭐⭐⭐⭐ |
| 安価なタスク用モデルを設定 | 簡単 | タスクコストを 90% 削減 | 機能を完全に維持 | ⭐⭐⭐⭐⭐ |
| タイトル/タグ生成をオフ | 簡単 | ~25% | 会話に手動で名前を付ける必要あり | ⭐⭐⭐⭐ |
| RAG をシステムプロンプトに移動 | 中程度 | キャッシュの有効化 | マイナスの影響なし | ⭐⭐⭐⭐ |
| コンテキスト長のフィルター | 中程度 | 長い会話のコストを制御 | 初期のコンテキストが失われる可能性あり | ⭐⭐⭐ |
🎯 ベストプラクティス: 機能を一切損ないたくない場合は、プラン 2(安価なタスク用モデルの設定)が最適な選択肢です。バックグラウンドタスクは継続して実行されますが、
gpt-4o-miniなどの低コストモデルを使用します。APIYI (apiyi.com) を利用すれば、複数のモデルの API キーを簡単に管理でき、1 つのキーですべての主要な大規模言語モデルを呼び出すことが可能です。
よくある質問
Q1: OpenClaw の Token 消費量が ChatGPT 公式とこれほど違うのはなぜですか?
ChatGPT 公式はサブスクリプション制であり、Token 単位で課金されないため、Token 消費を意識することはありません。一方、OpenClaw は API 呼び出し経由のため、1 Token ごとに課金されます。さらに、OpenClaw のバックグラウンドタスクがデフォルトでオンになっているため、実際の消費量はユーザーに見えるリクエストの 3〜5 倍になります。
Q2: バックグラウンドタスクをオフにすれば、OpenClaw の Token 消費は正常に戻りますか?
はい。タイトル生成、タグ生成、関連質問の生成、およびオートコンプリートをオフにすると、メッセージごとに 1 回の API 呼び出し(メインの会話)のみが発生し、Token 消費量は 60〜80% 削減されます。これらの機能を維持したい場合は、APIYI (apiyi.com) プラットフォームを通じて、これらのバックグラウンドタスク専用に安価なモデル(gpt-4o-mini など)を設定することをお勧めします。
Q3: OpenClaw の実際の Token 消費を監視するにはどうすればよいですか?
以下の方法で Token 消費を監視することをお勧めします:
- APIYI (apiyi.com) の使用量統計パネルから、各 API 呼び出しの詳細な Token データを確認する
- OpenClaw 管理パネルの Usage ページで統計を確認する
- Prompt Token と Completion Token の比率に注目する。Prompt が Completion より大幅に多い場合は、バックグラウンドタスクの消費が多すぎることを示しています。
まとめ
OpenClawのトークン消費が過大になる主な要因と対策は以下の通りです:
- バックグラウンドでの隠れた呼び出しが主因: 1つのメッセージに対して、バックグラウンドで4〜5回の独立したAPI呼び出しが発生しています。ユーザーには1回しか見えていませんが、実際には複数回実行されています。
- 安価なタスクモデルの設定が最適解:
TASK_MODEL_EXTERNAL=gpt-4o-miniを設定することで、機能を維持したままバックグラウンドタスクのコストを90%削減できます。 - 長い会話には特に注意: 会話履歴は呼び出しのたびに再送信されます。30往復程度の会話でも、累計で100万トークンを超える可能性があります。
これらの最適化手法を活用することで、OpenClawのトークンコストを60〜80%削減し、APIをより経済的かつ効率的に利用できるようになります。
API呼び出しの管理には、APIYI (apiyi.com) の利用をおすすめします。統一されたインターフェースと詳細な利用統計により、トークン消費とコストを正確にコントロールすることが可能です。
📚 参考文献
-
Open WebUI トークン消費に関する議論: GitHubコミュニティにおける高トークン消費に関するディスカッション
- リンク:
github.com/open-webui/open-webui/discussions/7281 - 説明: 複数のユーザーが実際のトークン消費データと最適化の経験を共有しています。
- リンク:
-
Open WebUI 環境変数設定ドキュメント: 公式の環境変数設定リファレンス
- リンク:
docs.openwebui.com/reference/env-configuration - 説明: すべての設定可能な環境変数とデフォルト値が含まれています。
- リンク:
-
フォローアップ質問生成のトークン消費問題: 後続の質問生成がコンテキスト全体を消費する問題
- リンク:
github.com/open-webui/open-webui/issues/15081 - 説明: フォローアップ質問生成テンプレートがどのように大量のトークンを消費するかを詳細に分析しています。
- リンク:
-
システムプロンプト重複のバグ: Agenticツール呼び出しによるシステムプロンプトの累積
- リンク:
github.com/open-webui/open-webui/issues/19169 - 説明: ツール呼び出し機能を使用する際に特に注意が必要な既知の問題です。
- リンク:
著者: APIYI テクニカルチーム
技術交流: コメント欄での議論を歓迎します。詳細な資料については APIYI docs.apiyi.com ドキュメントセンター をご覧ください。