Anmerkung des Autors: Tiefgehende Analyse der 5 Hauptgründe für den ungewöhnlich hohen Token-Verbrauch von OpenClaw (Open WebUI), einschließlich versteckter Hintergrund-API-Aufrufe, Akkumulation des Dialogverlaufs usw., sowie Bereitstellung sofort wirksamer Optimierungskonfigurationen.
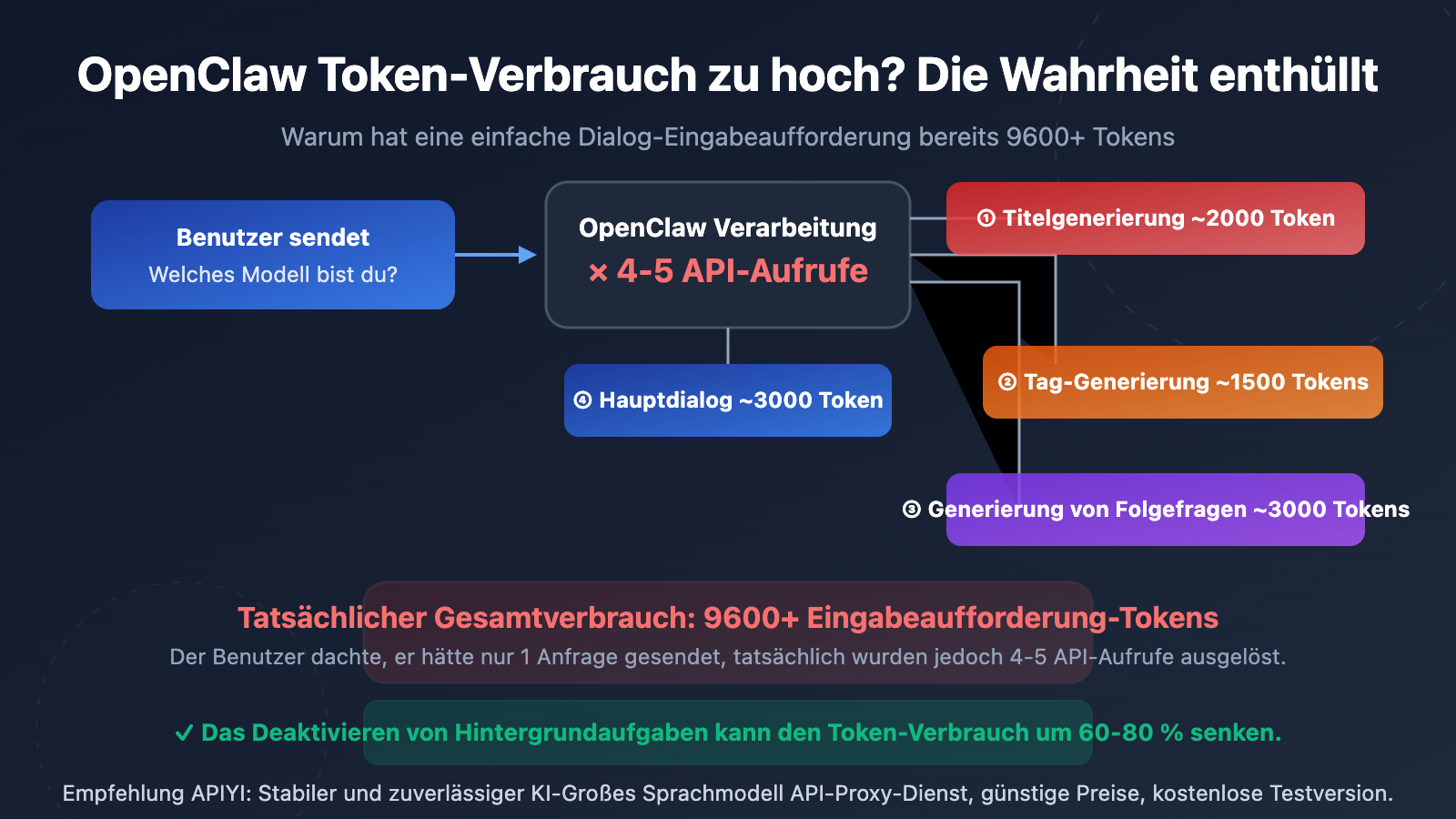
"Ich habe nur gefragt 'Welches Modell bist du?', warum liegt der Prompt-Token-Verbrauch bei über 10.000?" Das ist eine berechtigte Frage, die sich viele OpenClaw-Nutzer stellen. In diesem Artikel analysieren wir auf technischer Ebene die Grundursachen für den übermäßigen Token-Verbrauch in OpenClaw und bieten 5 sofort umsetzbare Optimierungslösungen.
Kernwert: Nach der Lektüre dieses Artikels werden Sie verstehen, warum der Token-Verbrauch von OpenClaw weit über den Erwartungen liegt, und Sie werden konkrete Konfigurationsmethoden beherrschen, um Ihre Token-Kosten um 60-80 % zu senken.
OpenClaw Token-Verbrauch: Kernpunkte
| Punkt | Erläuterung | Auswirkung |
|---|---|---|
| Versteckte Hintergrundaufrufe | Jede Nachricht löst 4-5 unabhängige API-Aufrufe aus | ⭐⭐⭐⭐⭐ Höchste |
| Akkumulation des Verlaufs | Jede Dialogrunde sendet den gesamten Verlauf erneut | ⭐⭐⭐⭐ Hoch |
| Keine Trennung der Aufgabenmodelle | Hintergrundaufgaben nutzen standardmäßig das Hauptmodell | ⭐⭐⭐⭐ Hoch |
| Injektion von System-Prompts | Tool-Beschreibungen und RAG-Kontext werden automatisch injiziert | ⭐⭐⭐ Mittel |
| System-Prompt Duplizierungs-Bug | Überlagerung von System-Prompts bei Agentic-Tool-Aufrufen | ⭐⭐⭐ Mittel |
Die Grundursache für den hohen Token-Verbrauch in OpenClaw
Viele Nutzer sind schockiert, wenn sie ihre API-Nutzungsstatistiken sehen – obwohl sie nur eine einfache Frage wie "Welches Modell bist du?" gestellt haben, liegt der Prompt-Token-Verbrauch bei 9.600 bis über 10.000. Dies ist kein Abrechnungsfehler des API-Anbieters, sondern liegt am Architekturdesign von OpenClaw (Open WebUI).
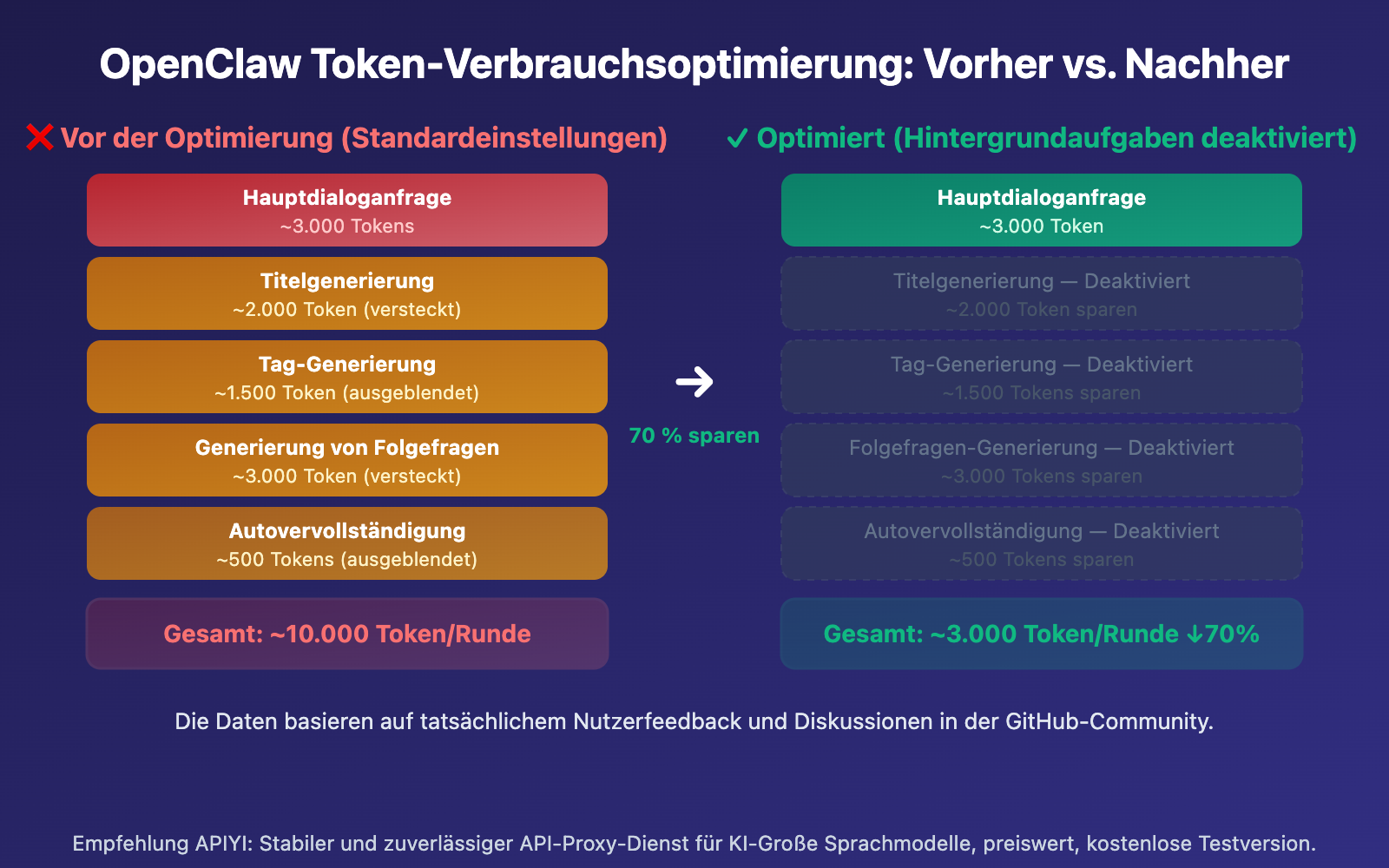
Die Hauptursache ist: Jedes Mal, wenn ein Benutzer eine Nachricht sendet, löst OpenClaw im Hintergrund automatisch mehrere unabhängige API-Aufrufe aus. Diese Aufrufe sind für den Benutzer völlig unsichtbar, verbrauchen aber bei jedem Mal echte Token.
Die 5 Hauptquellen des Token-Verbrauchs in OpenClaw im Detail
Quelle 1: Automatische Titelgenerierung (Title Generation)
Nachdem der Benutzer die erste Nachricht gesendet hat, ruft OpenClaw automatisch die API auf, um einen Dialogtitel mit 3-5 Wörtern zu generieren. Dieser Aufruf sendet den Inhalt der Benutzernachricht und verbraucht etwa 1.500-2.000 Prompt-Token.
Quelle 2: Automatische Tag-Generierung (Tag Generation)
Gleichzeitig ruft OpenClaw die API auf, um 1-3 Kategorisierungs-Tags für den Dialog zu erstellen. Dies ist ein weiterer unabhängiger API-Aufruf, der etwa 1.000-1.500 Prompt-Token verbraucht.
Quelle 3: Vorschläge für Folgefragen (Follow-up Generation)
OpenClaw generiert standardmäßig 3-5 Vorschläge für Folgefragen. Dieser Aufruf verwendet das Template {{MESSAGES:END:6}}, welches die letzten 6 Nachrichten als Kontext heranzieht und etwa 2.000-3.000 Prompt-Token verbraucht.
Quelle 4: Autovervollständigung (Autocomplete Generation)
Einige Versionen von OpenClaw aktivieren zudem eine Autovervollständigungsfunktion für die Eingabe, um vorherzusagen, was der Benutzer als Nächstes schreiben könnte.
Quelle 5: Die eigentliche Dialoganfrage
Erst am Ende erfolgt die eigentliche Dialoganfrage, die der Benutzer sieht, bestehend aus System-Prompt, Dialogverlauf und Benutzereingabe.
OpenClaw Token-Verbrauch: Schnellanleitung zur Optimierung
Minimale Konfiguration: Hintergrundaufgaben deaktivieren
Dies ist der schnellste Weg zur Optimierung – deaktivieren Sie unnötige Hintergrund-API-Aufrufe über Umgebungsvariablen:
# Umgebungsvariablen in der docker-compose.yml hinzufügen
environment:
- ENABLE_TITLE_GENERATION=false
- ENABLE_TAGS_GENERATION=false
- ENABLE_FOLLOW_UP_GENERATION=false
- ENABLE_AUTOCOMPLETE_GENERATION=false
Vollständige Schritte zur Konfiguration über das Admin-Panel anzeigen
Falls Sie die Umgebungsvariablen nicht direkt ändern können, ist die Konfiguration auch über das OpenClaw Admin-Panel möglich:
- Melden Sie sich im OpenClaw Admin-Backend an.
- Gehen Sie zu Settings → Tasks.
- Deaktivieren Sie nacheinander folgende Optionen:
- Title Generation → Aus
- Tags Generation → Aus
- Follow-up Generation → Aus
- Autocomplete Generation → Aus
- Falls Sie die Funktionen nicht komplett deaktivieren möchten, können Sie das Task Model auf ein kostengünstiges Modell (wie
gpt-4o-mini) setzen. - Speichern Sie die Einstellungen und laden Sie die Seite neu.
# Option 2: Funktionen beibehalten, aber ein günstiges Modell für Hintergrundaufgaben nutzen
environment:
- TASK_MODEL_EXTERNAL=gpt-4o-mini
Auf diese Weise laufen die Hintergrundaufgaben weiterhin (Titel, Tags und Folgefragen werden automatisch generiert), nutzen jedoch ein preiswerteres Modell anstelle Ihres Haupt-Chatmodells.
🎯 Optimierungstipp: Das Deaktivieren von Hintergrundaufgaben ist die direkteste Methode, um den Token-Verbrauch in OpenClaw zu senken. Wenn Sie API-Aufrufe über APIYI (apiyi.com) tätigen, können diese Optimierungen Ihre Nutzungskosten erheblich reduzieren. APIYI bietet eine einheitliche Schnittstelle für verschiedene Modelle, was das Zuweisen unterschiedlicher Task-Modelle vereinfacht.
OpenClaw Token-Verbrauch: Analyse realer Daten
Hier sind echte Daten zum Token-Verbrauch aus Nutzerfeedback, die das Ausmaß des Problems verdeutlichen:
| Nutzungsszenario | Erwarteter Token-Verbrauch | Tatsächlicher Token-Verbrauch | Faktor |
|---|---|---|---|
| Einfache Frage: "Welches Modell bist du?" | ~200 | 9.600 – 10.269 | 50x |
| 5 Runden Alltags-Chat | ~3.000 | ~45.000 | 15x |
| 30 Runden Programmier-Chat | ~12.000 | 1.860.000 | 155x |
| Chat nach Dokumenten-Upload | ~5.000 | 600.000+ | 120x |
Die Daten in der obigen Tabelle stammen aus Nutzerberichten der Open WebUI GitHub-Community. Der Extremfall von 155-fachem Verbrauch bei 30 Programmier-Chat-Runden liegt vor allem daran, dass das Template für Folgefragen {{MESSAGES:END:6}} die letzten 6 Nachrichten abruft – und in Programmier-Chats enthalten einzelne Nachrichten oft riesige Mengen an Code.
Kumulativer Effekt der Gesprächsrunden auf den Token-Verbrauch
| Gesprächsrunde | Verbrauch bei Standardeinstellungen | Verbrauch nach Optimierung | Ersparnis |
|---|---|---|---|
| Runde 1 | ~10.000 | ~3.000 | 70% |
| Runde 5 | ~50.000 | ~15.000 | 70% |
| Runde 10 | ~150.000 | ~45.000 | 70% |
| Runde 20 | ~500.000 | ~150.000 | 70% |
| Runde 30 | ~1.200.000 | ~360.000 | 70% |
Mit zunehmender Anzahl der Gesprächsrunden steigt der Token-Verbrauch exponentiell an. Das liegt daran, dass bei jeder neuen Runde der komplette Gesprächsverlauf erneut gesendet wird. In den Standardeinstellungen wird dieser Verlauf nicht nur einmal für den Haupt-Chat übertragen, sondern jeweils ein weiteres Mal für die Titelgenerierung, die Schlagwortvergabe (Tags) und die Erstellung von Folgefragen.
🎯 Tipp zur Kostenkontrolle: Bei langen Konversationen wächst der Token-Verbrauch erschreckend schnell. Wir empfehlen, Modellaufrufe über APIYI (apiyi.com) durchzuführen. Die Plattform bietet ein detailliertes Dashboard für Nutzungsstatistiken, mit dem Sie Ihren Token-Verbrauch bequem überwachen und optimieren können.
OpenClaw Token 消耗 优化方案对比

| 优化方案 | 操作难度 | Token 节省 | 功能影响 | 推荐度 |
|---|---|---|---|---|
| 关闭后续问题生成 | 简单 | ~30% | 不再显示建议问题 | ⭐⭐⭐⭐⭐ |
| 设置廉价任务模型 | 简单 | 任务成本降 90% | 功能完全保留 | ⭐⭐⭐⭐⭐ |
| 关闭标题/标签生成 | 简单 | ~25% | 需手动命名对话 | ⭐⭐⭐⭐ |
| RAG 移至系统提示词 | 中等 | 启用缓存 | 无负面影响 | ⭐⭐⭐⭐ |
| 上下文长度过滤器 | 中等 | 控制长对话成本 | 可能丢失早期上下文 | ⭐⭐⭐ |
🎯 最佳实践: 如果你不想损失任何功能,方案 2(设置廉价任务模型)是最优选择——后台任务继续运行,但使用
gpt-4o-mini等低成本模型。通过 APIYI apiyi.com 可以方便地管理多个模型的 API Key,一个 Key 即可调用所有主流模型。
常见问题
Q1: OpenClaw Token 消耗为什么和 ChatGPT 官方差这么多?
ChatGPT 官方是订阅制,不按 Token 计费,你感知不到 Token 消耗。而 OpenClaw 通过 API 调用,每个 Token 都会计费。加上 OpenClaw 的后台任务默认开启,实际消耗是用户可见请求的 3-5 倍。
Q2: 关闭后台任务后 OpenClaw Token 消耗会恢复正常吗?
是的。关闭标题生成、标签生成、后续问题生成和自动补全后,每条消息只会触发一次 API 调用(主对话),Token 消耗会降低 60-80%。如果还想保留这些功能,可以通过 APIYI apiyi.com 平台设置一个廉价模型(如 gpt-4o-mini)专门处理这些后台任务。
Q3: 如何监控 OpenClaw Token 的实际消耗?
推荐以下方式监控 Token 消耗:
- 通过 APIYI apiyi.com 的用量统计面板查看每次 API 调用的详细 Token 数据
- 在 OpenClaw 管理面板的 Usage 页面查看统计
- 关注 Prompt Token 和 Completion Token 的比例——如果 Prompt 远大于 Completion,说明后台任务消耗过多
Zusammenfassung
Die Kernpunkte für den hohen Token-Verbrauch bei OpenClaw:
- Versteckte Hintergrundaufrufe sind die Hauptursache: Jede Nachricht löst 4-5 unabhängige API-Aufrufe aus, während der Benutzer nur einen sieht.
- Die Einrichtung eines günstigen Aufgabenmodells ist die beste Lösung:
TASK_MODEL_EXTERNAL=gpt-4o-minikann die Kosten für Hintergrundaufgaben um 90 % senken, während die Funktionalität erhalten bleibt. - Besondere Vorsicht bei langen Gesprächen: Der Gesprächsverlauf wird bei jedem Aufruf erneut gesendet. Bei 30 Gesprächsrunden kann dies über 1 Million Token erreichen.
Durch die Anwendung dieser Optimierungstechniken können Sie die Token-Kosten von OpenClaw um 60-80 % senken und die API-Nutzung deutlich wirtschaftlicher gestalten.
Wir empfehlen die Verwaltung Ihrer API-Aufrufe über APIYI (apiyi.com). Die Plattform bietet eine einheitliche Schnittstelle und detaillierte Nutzungsstatistiken, die Ihnen helfen, den Token-Verbrauch und die Kosten präzise zu kontrollieren.
📚 Referenzen
-
Diskussion zum Token-Verbrauch in Open WebUI: GitHub-Community-Diskussion über hohen Token-Verbrauch
- Link:
github.com/open-webui/open-webui/discussions/7281 - Beschreibung: Mehrere Benutzer teilen tatsächliche Token-Verbrauchsdaten und Optimierungserfahrungen.
- Link:
-
Dokumentation zur Konfiguration der Umgebungsvariablen in Open WebUI: Offizielle Referenz für Umgebungsvariablen
- Link:
docs.openwebui.com/reference/env-configuration - Beschreibung: Enthält alle konfigurierbaren Umgebungsvariablen und deren Standardwerte.
- Link:
-
Token-Verbrauchsprobleme bei der Generierung von Folgefragen: Die Generierung von Folgefragen verbraucht den vollständigen Kontext
- Link:
github.com/open-webui/open-webui/issues/15081 - Beschreibung: Detaillierte Analyse, wie Vorlagen für Folgefragen große Mengen an Token verbrauchen.
- Link:
-
Bug bei der Duplizierung von System-Prompts: Agentic Tool-Aufrufe führen zur Überlagerung von System-Prompts
- Link:
github.com/open-webui/open-webui/issues/19169 - Beschreibung: Bekannte Probleme, die bei der Verwendung von Tool-Aufruffunktionen beachtet werden müssen.
- Link:
Autor: APIYI Technik-Team
Technischer Austausch: Diskutieren Sie gerne im Kommentarbereich mit uns. Weitere Informationen finden Sie im APIYI Dokumentationszentrum unter docs.apiyi.com.