Note de l'auteur : Analyse approfondie des 5 raisons principales pour lesquelles la consommation de tokens d'OpenClaw (Open WebUI) est anormalement élevée, incluant les appels API en arrière-plan cachés et l'accumulation de l'historique de conversation, avec des solutions de configuration immédiatement applicables.
"Je n'ai posé qu'une question : 'Quel modèle es-tu ?', alors pourquoi le Prompt Token dépasse-t-il les 10 000 ?" C'est une interrogation réelle pour beaucoup d'utilisateurs d'OpenClaw. Cet article analyse techniquement les causes profondes de la consommation excessive de Tokens dans OpenClaw et propose 5 solutions d'optimisation immédiates.
Valeur ajoutée : En lisant cet article, vous comprendrez pourquoi la consommation de Tokens d'OpenClaw dépasse de loin vos attentes et vous maîtriserez les méthodes de configuration spécifiques pour réduire vos coûts de 60 à 80 %.
Points clés de la consommation de Tokens OpenClaw
| Point clé | Explication | Niveau d'impact |
|---|---|---|
| Appels en arrière-plan cachés | Chaque message déclenche 4 à 5 appels API indépendants | ⭐⭐⭐⭐⭐ Maximum |
| Accumulation de l'historique | Chaque tour de conversation renvoie l'intégralité de l'historique | ⭐⭐⭐⭐ Élevé |
| Modèles de tâches non séparés | Les tâches de fond utilisent par défaut le modèle principal | ⭐⭐⭐⭐ Élevé |
| Injection d'invites système | Descriptions d'outils et contexte RAG injectés automatiquement | ⭐⭐⭐ Moyen |
| Bug de répétition d'invite système | Superposition d'invites lors d'appels d'outils Agentic | ⭐⭐⭐ Moyen |
La cause profonde de la consommation élevée de Tokens dans OpenClaw
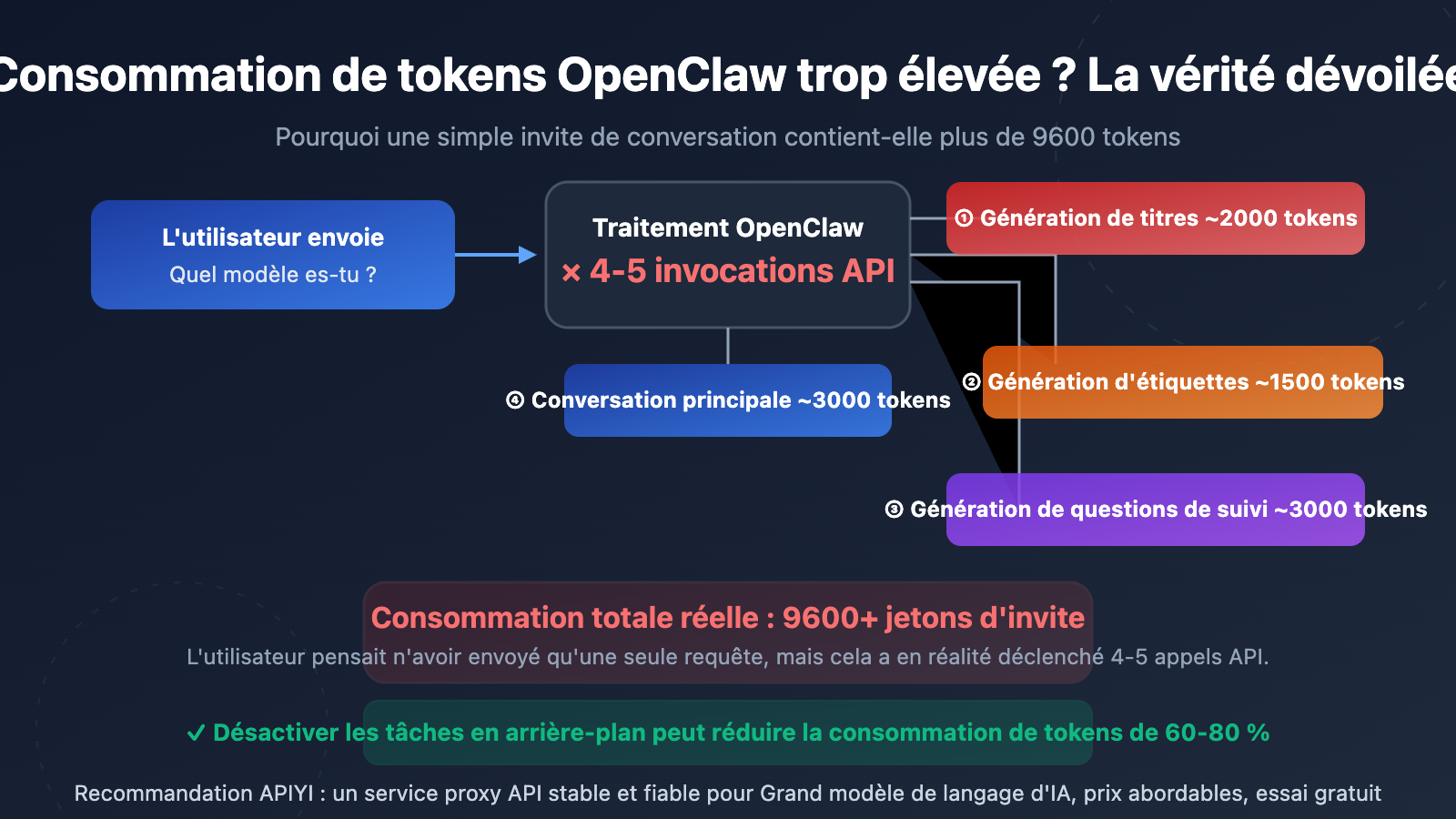
De nombreux utilisateurs sont choqués en consultant leurs statistiques d'utilisation API : pour une question aussi simple que "Quel modèle es-tu ?", le Prompt Token s'élève à 9 600-10 000+. Ce n'est pas un problème de facturation du fournisseur d'API, mais une conséquence de l'architecture d'OpenClaw (Open WebUI).
La raison principale est la suivante : OpenClaw déclenche automatiquement plusieurs appels API indépendants en arrière-plan à chaque fois qu'un utilisateur envoie un message. Ces appels sont totalement invisibles pour l'utilisateur, mais chacun consomme réellement des Tokens.
Détail des 5 sources de consommation de Tokens dans OpenClaw
Source 1 : Génération automatique de titre (Title Generation)
Après l'envoi du premier message, OpenClaw appelle automatiquement l'API pour générer un titre de conversation de 3 à 5 mots. Cet appel envoie le contenu du message de l'utilisateur et consomme environ 1 500 à 2 000 Prompt Tokens.
Source 2 : Génération automatique de tags (Tag Generation)
Simultanément, OpenClaw appelle l'API pour générer 1 à 3 tags de classification pour la conversation. Il s'agit d'un autre appel API indépendant, consommant environ 1 000 à 1 500 Prompt Tokens.
Source 3 : Suggestions de questions (Follow-up Generation)
Par défaut, OpenClaw génère 3 à 5 suggestions de questions de suivi. Cet appel utilise le modèle {{MESSAGES:END:6}}, qui récupère les 6 derniers messages de la conversation comme contexte, consommant environ 2 000 à 3 000 Prompt Tokens.
Source 4 : Saisie semi-automatique (Autocomplete Generation)
Certaines versions d'OpenClaw activent également une fonction d'autocomplétion de la saisie, prédisant ce que l'utilisateur pourrait taper ensuite.
Source 5 : La requête de conversation principale elle-même
Enfin, il y a la requête principale que l'utilisateur voit réellement, comprenant l'invite système, l'historique de la conversation et la saisie de l'utilisateur.
Guide d'optimisation rapide de la consommation de tokens OpenClaw
Configuration minimale : désactiver les tâches d'arrière-plan
Voici la méthode la plus rapide pour optimiser votre consommation — désactiver les appels API inutiles via les variables d'environnement :
# Ajouter les variables d'environnement dans docker-compose.yml
environment:
- ENABLE_TITLE_GENERATION=false
- ENABLE_TAGS_GENERATION=false
- ENABLE_FOLLOW_UP_GENERATION=false
- ENABLE_AUTOCOMPLETE_GENERATION=false
Voir les étapes complètes pour configurer via le panneau d’administration
Si vous ne pouvez pas modifier facilement les variables d'environnement, vous pouvez aussi configurer cela via l'interface d'administration d'OpenClaw :
- Connectez-vous au panneau d'administration d'OpenClaw.
- Allez dans Settings → Tasks.
- Désactivez les options suivantes une par une :
- Title Generation (Génération de titre) → Désactivé
- Tags Generation (Génération de tags) → Désactivé
- Follow-up Generation (Génération de questions de suivi) → Désactivé
- Autocomplete Generation (Génération d'autocomplétion) → Désactivé
- Si vous ne voulez pas tout désactiver, vous pouvez définir le Task Model sur un modèle économique (comme
gpt-4o-mini). - Enregistrez les paramètres et rafraîchissez la page.
# Option 2 : Ne pas désactiver les fonctionnalités, mais utiliser un modèle économique pour les tâches d'arrière-plan
environment:
- TASK_MODEL_EXTERNAL=gpt-4o-mini
De cette façon, les tâches d'arrière-plan continuent de fonctionner normalement (les titres, tags et questions de suivi sont générés automatiquement), mais elles utilisent un modèle moins coûteux au lieu de votre modèle de chat principal.
🎯 Conseil d'optimisation : Désactiver les tâches d'arrière-plan est la méthode la plus directe pour réduire la consommation de tokens sur OpenClaw. Si vous passez par le service proxy API de APIYI (apiyi.com), ces optimisations réduiront considérablement vos coûts d'utilisation. APIYI propose une interface unifiée pour plusieurs modèles, ce qui facilite la configuration de différents Task Models.
Analyse réelle de la consommation de tokens OpenClaw
Voici des données réelles de consommation de tokens rapportées par des utilisateurs, illustrant clairement l'ampleur du problème :
| Scénario d'utilisation | Consommation de tokens attendue | Consommation réelle | Multiplicateur |
|---|---|---|---|
| Simple Q&A "Quel modèle es-tu ?" | ~200 | 9 600-10 269 | 50x |
| 5 tours de conversation quotidienne | ~3 000 | ~45 000 | 15x |
| 30 tours de conversation de programmation | ~12 000 | 1 860 000 | 155x |
| Conversation après upload de document | ~5 000 | 600 000+ | 120x |
Les données du tableau ci-dessus proviennent de retours d'utilisateurs réels sur la communauté GitHub d'Open WebUI. Le cas extrême de 155 fois pour 30 tours de programmation est principalement dû au fait que le modèle de génération de questions de suivi {{MESSAGES:END:6}} récupère les 6 derniers messages, et dans une conversation technique, un seul message contient souvent une grande quantité de code.
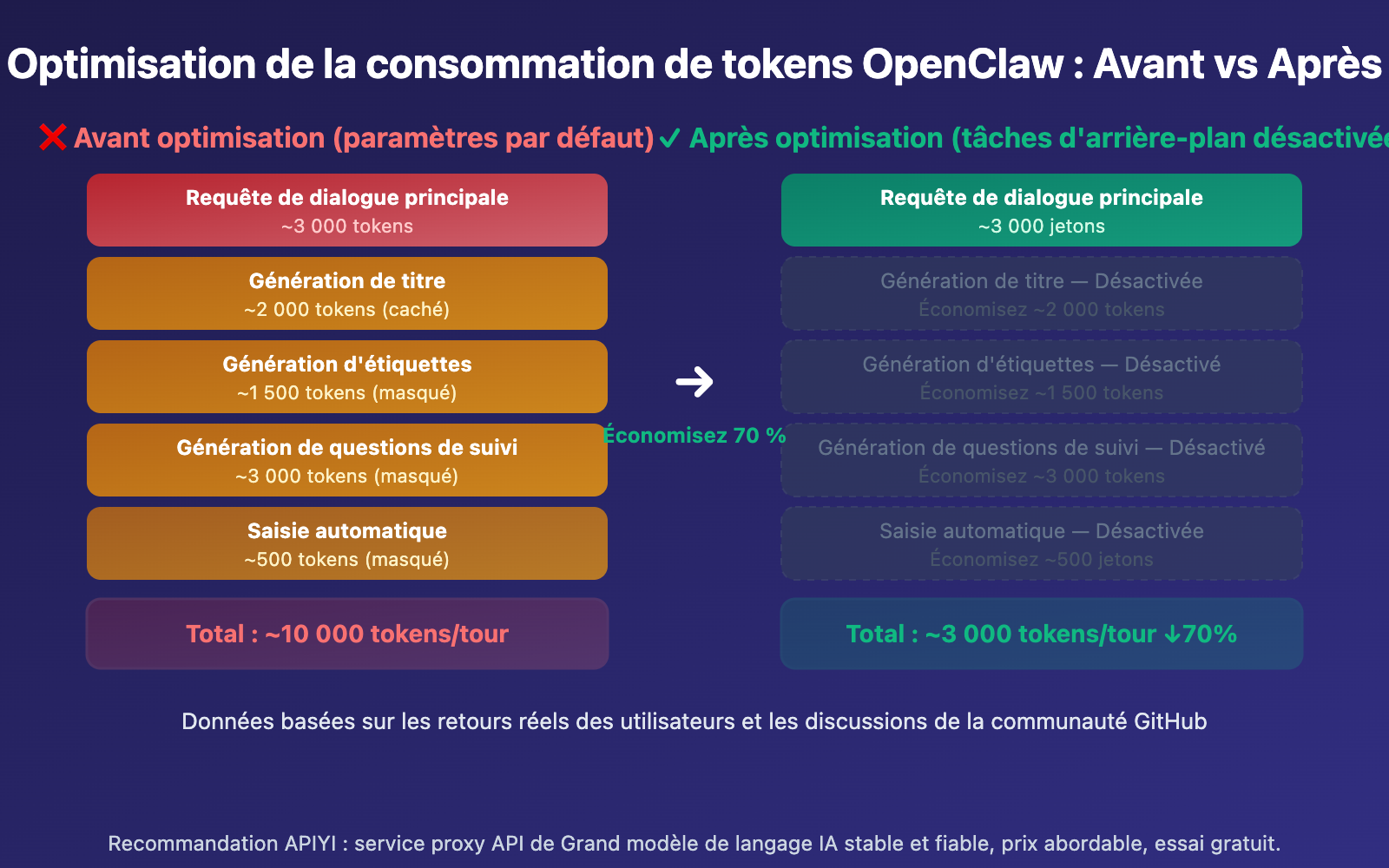
Effet cumulatif des tours de conversation sur la consommation de tokens OpenClaw
| Tour de conversation | Consommation par défaut | Consommation optimisée | Ratio d'économie |
|---|---|---|---|
| 1er tour | ~10 000 | ~3 000 | 70% |
| 5ème tour | ~50 000 | ~15 000 | 70% |
| 10ème tour | ~150 000 | ~45 000 | 70% |
| 20ème tour | ~500 000 | ~150 000 | 70% |
| 30ème tour | ~1 200 000 | ~360 000 | 70% |
À mesure que le nombre de tours de conversation augmente, la consommation de tokens croît de manière exponentielle. C'est parce que chaque tour renvoie l'intégralité de l'historique de la conversation. Avec les paramètres par défaut, cet historique n'est pas seulement envoyé une fois pour l'invocation du modèle de chat principal, mais aussi pour la génération du titre, des tags et des questions de suivi.
🎯 Conseil de contrôle des coûts : Dans les scénarios de conversations longues, l'augmentation de la consommation de tokens est particulièrement impressionnante. Nous vous recommandons d'effectuer vos appels API via APIYI (apiyi.com). La plateforme propose un tableau de bord détaillé des statistiques d'utilisation, vous permettant de surveiller et d'optimiser facilement votre consommation de tokens.
Comparaison des solutions d'optimisation de la consommation de tokens OpenClaw

| Solution d'optimisation | Difficulté | Économie de tokens | Impact fonctionnel | Recommandation |
|---|---|---|---|---|
| Désactiver la génération de questions suggérées | Facile | ~30% | N'affiche plus de suggestions | ⭐⭐⭐⭐⭐ |
| Configurer un modèle de tâche économique | Facile | Coût réduit de 90% | Fonctionnalités préservées | ⭐⭐⭐⭐⭐ |
| Désactiver la génération de titres/tags | Facile | ~25% | Nommage manuel des conversations requis | ⭐⭐⭐⭐ |
| Déplacer le RAG vers l'invite système | Moyenne | Activation du cache | Aucun impact négatif | ⭐⭐⭐⭐ |
| Filtre de longueur de contexte | Moyenne | Contrôle le coût des longs chats | Perte possible du contexte initial | ⭐⭐⭐ |
🎯 Meilleure pratique : Si vous ne souhaitez perdre aucune fonctionnalité, la solution 2 (configurer un modèle de tâche économique) est le choix optimal. Les tâches d'arrière-plan continuent de s'exécuter, mais utilisent des modèles à bas coût comme
gpt-4o-mini. Via APIYI (apiyi.com), vous pouvez facilement gérer les clés API de plusieurs modèles : une seule clé suffit pour invoquer tous les modèles principaux.
Questions Fréquentes
Q1 : Pourquoi la consommation de tokens d’OpenClaw est-elle si différente de celle de ChatGPT officiel ?
ChatGPT officiel fonctionne par abonnement et non par facturation au token, la consommation est donc invisible pour vous. OpenClaw utilise des appels API où chaque token est facturé. De plus, les tâches d'arrière-plan d'OpenClaw sont activées par défaut, ce qui rend la consommation réelle 3 à 5 fois supérieure aux requêtes visibles par l'utilisateur.
Q2 : La consommation de tokens d’OpenClaw reviendra-t-elle à la normale après avoir désactivé les tâches d’arrière-plan ?
Oui. En désactivant la génération de titres, de tags, de questions suggérées et l'autocomplétion, chaque message ne déclenchera qu'un seul appel API (la conversation principale). La consommation de tokens diminuera de 60 à 80 %. Si vous souhaitez conserver ces fonctions, vous pouvez configurer un modèle économique (comme gpt-4o-mini) spécifiquement pour ces tâches via la plateforme APIYI (apiyi.com).
Q3 : Comment surveiller la consommation réelle de tokens sur OpenClaw ?
Nous recommandons les méthodes suivantes pour surveiller votre consommation :
- Consultez les données détaillées de chaque appel API via le panneau de statistiques d'utilisation d'APIYI (apiyi.com).
- Vérifiez les statistiques sur la page "Usage" du panneau d'administration d'OpenClaw.
- Surveillez le ratio entre les tokens d'invite (Prompt) et les tokens de complétion (Completion) : si le Prompt est bien plus élevé que la Completion, cela signifie que les tâches d'arrière-plan consomment trop.
Résumé
Voici les points clés pour comprendre la consommation excessive de tokens par OpenClaw :
- Les appels en arrière-plan cachés sont la cause principale : Chaque message déclenche 4 à 5 appels API indépendants, alors que l'utilisateur n'en voit qu'un seul.
- Configurer un modèle de tâche économique est la solution optimale : Utiliser
TASK_MODEL_EXTERNAL=gpt-4o-minipermet de réduire les coûts des tâches en arrière-plan de 90 % tout en conservant les fonctionnalités. - Attention particulière aux conversations longues : L'historique de la conversation est renvoyé lors de chaque appel ; une discussion de 30 tours peut ainsi atteindre plus d'un million de tokens.
Une fois ces astuces d'optimisation maîtrisées, vous pourrez réduire les coûts de tokens d'OpenClaw de 60 à 80 %, rendant l'utilisation de l'API beaucoup plus économique et efficace.
Nous vous recommandons de gérer vos appels API via APIYI (apiyi.com). La plateforme propose une interface unifiée et des statistiques d'utilisation détaillées pour vous aider à contrôler précisément votre consommation de tokens et vos coûts.
📚 Ressources complémentaires
-
Discussion sur la consommation de tokens d'Open WebUI : Échanges au sein de la communauté GitHub sur la consommation élevée de tokens.
- Lien :
github.com/open-webui/open-webui/discussions/7281 - Description : Plusieurs utilisateurs partagent des données réelles de consommation et leurs retours d'expérience sur l'optimisation.
- Lien :
-
Documentation de configuration des variables d'environnement d'Open WebUI : Référence officielle pour la configuration.
- Lien :
docs.openwebui.com/reference/env-configuration - Description : Liste complète des variables d'environnement configurables et leurs valeurs par défaut.
- Lien :
-
Problème de consommation de tokens lors de la génération de questions de suivi : La génération de questions de suivi consomme l'intégralité du contexte.
- Lien :
github.com/open-webui/open-webui/issues/15081 - Description : Analyse détaillée de la manière dont les modèles de génération de questions de suivi consomment une quantité massive de tokens.
- Lien :
-
Bug de duplication de l'invite système : L'appel d'outils agentiques entraîne une superposition des invites système.
- Lien :
github.com/open-webui/open-webui/issues/19169 - Description : Un problème connu à surveiller de près lors de l'utilisation des fonctions d'appel d'outils (tool calling).
- Lien :
Auteur : Équipe technique APIYI
Échanges techniques : N'hésitez pas à réagir dans la section commentaires. Pour plus de ressources, vous pouvez consulter notre centre de documentation sur docs.apiyi.com.