Примечание автора: Глубокий анализ 5 причин аномально высокого расхода токенов в OpenClaw (Open WebUI), включая скрытые фоновые вызовы API, накопление истории диалогов и другие факторы. В статье предложены готовые конфигурации для немедленной оптимизации.
«Я всего лишь спросил "что ты за модель", почему в Prompt Token больше 10 000?» — это типичное недоумение пользователей OpenClaw. В этой статье мы разберем с технической точки зрения коренные причины высокого расхода токенов в OpenClaw и предложим 5 готовых решений для оптимизации.
Ключевая ценность: Прочитав этот материал, вы поймете, почему OpenClaw тратит токены гораздо быстрее, чем ожидалось, и научитесь снижать затраты на 60–80% с помощью правильных настроек.
Ключевые моменты расхода токенов в OpenClaw
| Момент | Описание | Степень влияния |
|---|---|---|
| Скрытые фоновые вызовы | Каждое сообщение инициирует 4-5 независимых API-вызовов | ⭐⭐⭐⭐⭐ Максимальная |
| Накопление истории | В каждом раунде диалога пересылается вся история сообщений | ⭐⭐⭐⭐ Высокая |
| Модели задач не разделены | Фоновые задачи по умолчанию используют основную модель | ⭐⭐⭐⭐ Высокая |
| Инъекция системных промптов | Автоматическая вставка описаний инструментов и контекста RAG | ⭐⭐⭐ Средняя |
| Баг дублирования промптов | Наложение системных промптов при вызове агентских инструментов | ⭐⭐⭐ Средняя |
Коренная причина высокого расхода токенов в OpenClaw
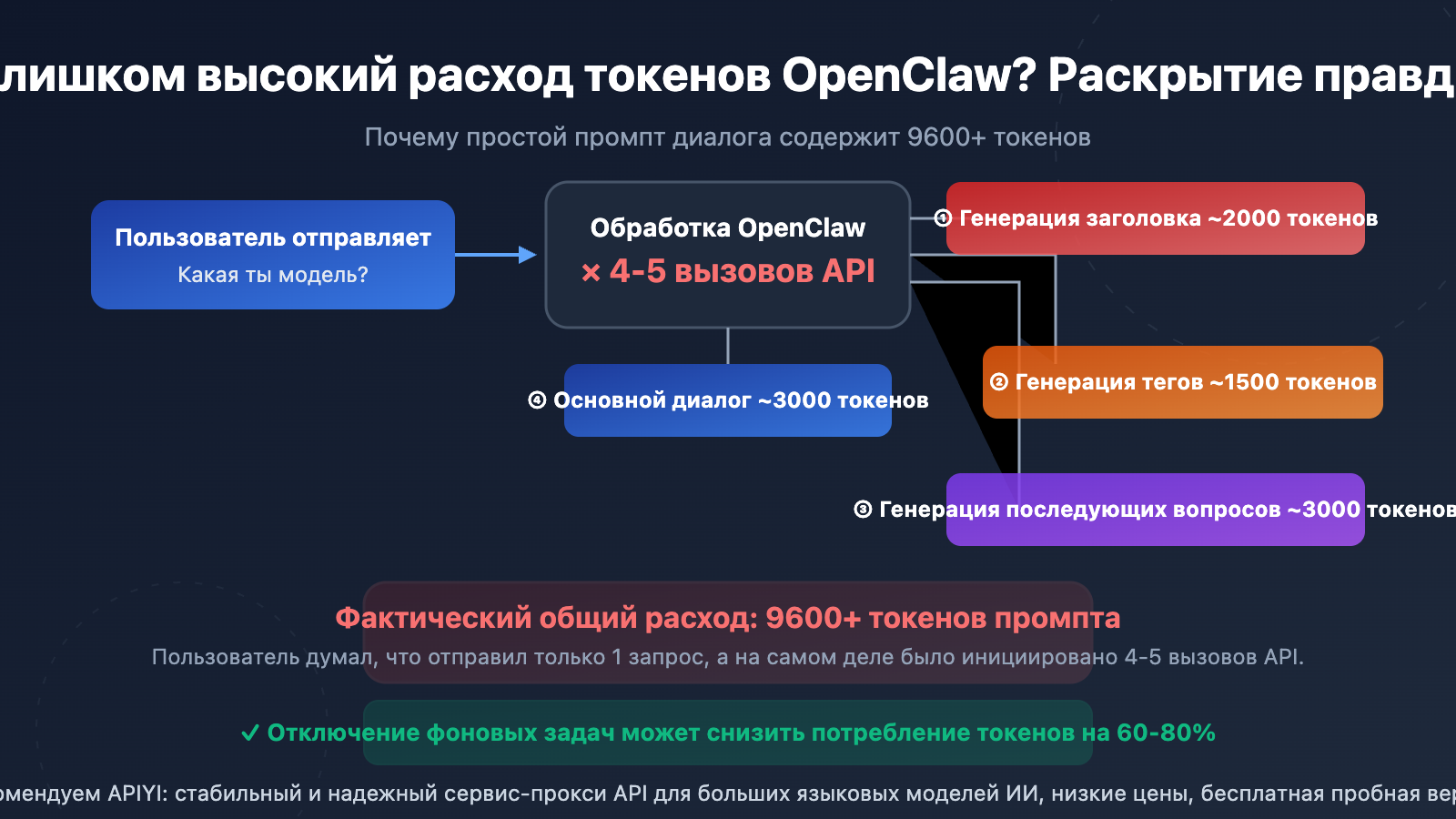
Многие пользователи при просмотре статистики API приходят в ужас: на простой вопрос «что ты за модель» тратится 9600–10000+ Prompt Token. Это не проблема тарификации провайдера API, а особенность архитектуры OpenClaw (Open WebUI).
Суть в следующем: OpenClaw при отправке каждого сообщения пользователем автоматически инициирует несколько независимых API-вызовов в фоновом режиме. Эти вызовы полностью невидимы для пользователя, но каждый из них потребляет реальные токены.
5 основных источников расхода токенов в OpenClaw
Источник 1: Автоматическая генерация заголовков (Title Generation)
После отправки первого сообщения OpenClaw автоматически вызывает API для создания заголовка диалога из 3–5 слов. Этот вызов отправляет содержимое сообщения пользователя и расходует около 1500–2000 Prompt Token.
Источник 2: Автоматическая генерация тегов (Tag Generation)
Одновременно с этим OpenClaw вызывает API для создания 1–3 классификационных тегов диалога. Это еще один независимый API-вызов, потребляющий около 1000–1500 Prompt Token.
Источник 3: Предложения последующих вопросов (Follow-up Generation)
По умолчанию OpenClaw генерирует 3–5 вариантов последующих вопросов. Этот вызов использует шаблон {{MESSAGES:END:6}}, который подтягивает последние 6 сообщений диалога в качестве контекста, что расходует около 2000–3000 Prompt Token.
Источник 4: Автодополнение (Autocomplete Generation)
В некоторых версиях OpenClaw включена функция автодополнения ввода, которая предсказывает, что пользователь может ввести дальше.
Источник 5: Сам основной запрос диалога
И только в последнюю очередь выполняется основной запрос, который видит пользователь. Он включает системный промпт, историю диалога и ввод пользователя.
Краткое руководство по оптимизации расхода токенов в OpenClaw
Минимальная настройка: отключаем фоновые задачи
Вот самый быстрый способ оптимизации — отключение ненужных фоновых вызовов API через переменные окружения:
# Добавьте эти переменные в ваш docker-compose.yml
environment:
- ENABLE_TITLE_GENERATION=false
- ENABLE_TAGS_GENERATION=false
- ENABLE_FOLLOW_UP_GENERATION=false
- ENABLE_AUTOCOMPLETE_GENERATION=false
Пошаговая настройка через панель управления
Если вам неудобно править переменные окружения, те же настройки можно изменить в панели управления OpenClaw:
- Войдите в админку OpenClaw.
- Перейдите в раздел Settings → Tasks.
- Поочередно отключите следующие опции:
- Title Generation (Генерация заголовков) → Выключить
- Tags Generation (Генерация тегов) → Выключить
- Follow-up Generation (Генерация уточняющих вопросов) → Выключить
- Autocomplete Generation (Автодополнение) → Выключить
- Если вы не хотите полностью отключать эти функции, установите в поле Task Model бюджетную модель (например,
gpt-4o-mini). - Сохраните настройки и обновите страницу.
# Вариант 2: не отключать функции, но использовать дешевую модель для фоновых задач
environment:
- TASK_MODEL_EXTERNAL=gpt-4o-mini
В этом случае фоновые задачи продолжат работать (заголовки, теги и вопросы будут создаваться автоматически), но для них будет использоваться модель с низкой стоимостью, а не ваша основная дорогая модель.
🎯 Совет по оптимизации: Отключение фоновых задач — это самый прямой способ снизить расход токенов в OpenClaw. Если вы используете API через сервис-прокси API APIYI (apiyi.com), эти настройки помогут существенно сократить ваши расходы. APIYI предоставляет единый интерфейс для множества моделей, что позволяет легко назначать разные модели для основных чатов и фоновых задач (Task Model).
Анализ реального расхода токенов в OpenClaw
Ниже приведены реальные данные от пользователей, которые наглядно показывают масштаб проблемы избыточного потребления токенов:
| Сценарий использования | Ожидаемый расход | Реальный расход | Во сколько раз больше |
|---|---|---|---|
| Простой вопрос "Кто ты?" | ~200 | 9,600–10,269 | ~50x |
| 5 раундов обычного диалога | ~3,000 | ~45,000 | 15x |
| 30 раундов диалога о программировании | ~12,000 | 1,860,000 | 155x |
| Диалог после загрузки документа | ~5,000 | 600,000+ | 120x |
Данные в таблице основаны на отзывах сообщества Open WebUI на GitHub. Экстремальный случай (превышение в 155 раз) при написании кода объясняется тем, что шаблон генерации уточняющих вопросов {{MESSAGES:END:6}} подтягивает 6 последних сообщений, а в программировании одно сообщение часто содержит огромные блоки кода.
Накопительный эффект расхода токенов по раундам диалога
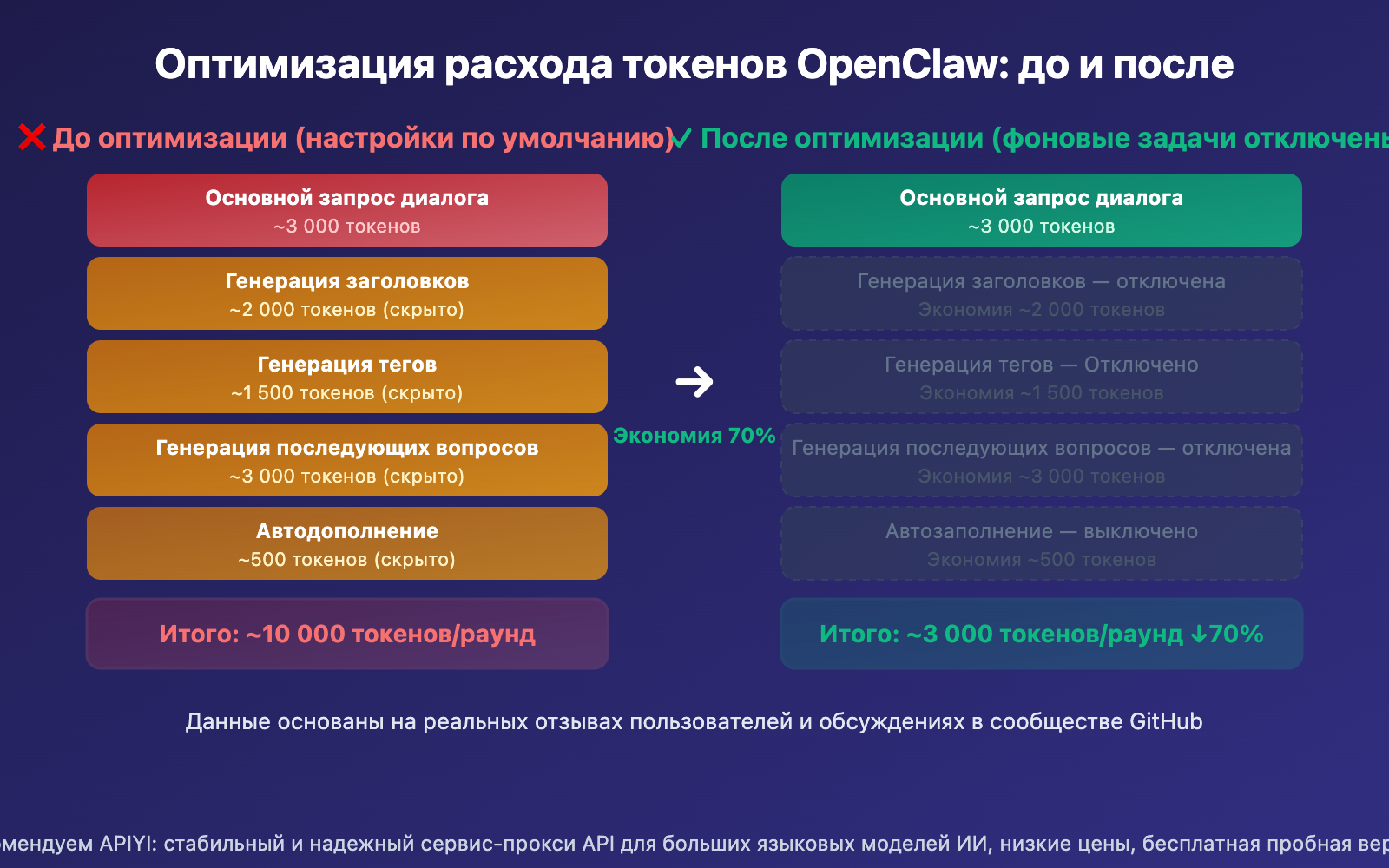
| Раунд диалога | Расход (настройки по умолчанию) | Расход (после оптимизации) | Экономия |
|---|---|---|---|
| 1-й раунд | ~10,000 | ~3,000 | 70% |
| 5-й раунд | ~50,000 | ~15,000 | 70% |
| 10-й раунд | ~150,000 | ~45,000 | 70% |
| 20-й раунд | ~500,000 | ~150,000 | 70% |
| 30-й раунд | ~1,200,000 | ~360,000 | 70% |
С увеличением количества раундов расход токенов растет в геометрической прогрессии. Это происходит потому, что в каждом новом раунде заново отправляется вся история переписки. При стандартных настройках эта история дублируется: один раз для основного ответа и по разу для генерации заголовка, тегов и уточняющих вопросов.
🎯 Рекомендация по контролю затрат: В длинных диалогах расход токенов растет пугающе быстро. Мы рекомендуем выполнять вызов модели через APIYI (apiyi.com). Платформа предоставляет детальную панель статистики использования, которая поможет вам вовремя заметить аномальный расход и оптимизировать настройки.
Сравнение способов оптимизации расхода токенов в OpenClaw

| Способ оптимизации | Сложность | Экономия токенов | Влияние на функции | Рекомендация |
|---|---|---|---|---|
| Отключение уточняющих вопросов | Легко | ~30% | Перестает предлагать варианты вопросов | ⭐⭐⭐⭐⭐ |
| Использование дешевых моделей | Легко | Снижение затрат на 90% | Функционал полностью сохранен | ⭐⭐⭐⭐⭐ |
| Отключение генерации заголовков/тегов | Легко | ~25% | Нужно именовать чаты вручную | ⭐⭐⭐⭐ |
| Перенос RAG в системный промпт | Средне | Включение кэша | Без негативных последствий | ⭐⭐⭐⭐ |
| Фильтр длины контекста | Средне | Контроль затрат в длинных чатах | Возможна потеря раннего контекста | ⭐⭐⭐ |
🎯 Лучшая практика: Если вы не хотите жертвовать функциями, способ №2 (использование дешевых моделей для задач) — оптимальный выбор. Фоновые процессы продолжат работать, но на базе бюджетных моделей вроде
gpt-4o-mini. Через сервис-прокси API APIYI (apiyi.com) удобно управлять API-ключами: один ключ дает доступ ко всем популярным нейросетям.
Часто задаваемые вопросы
Q1: Почему расход токенов в OpenClaw намного выше, чем в официальном ChatGPT?
Официальный ChatGPT работает по подписке, там нет лимита на токены, поэтому вы их не замечаете. OpenClaw работает через вызов модели по API, где тарифицируется каждый токен. Кроме того, в OpenClaw по умолчанию включены фоновые задачи, из-за чего реальный расход в 3-5 раз выше, чем объем видимых вами сообщений.
Q2: Вернется ли расход токенов в норму, если отключить фоновые задачи?
Да. Если отключить генерацию заголовков, тегов, уточняющих вопросов и автодополнение, каждое сообщение будет вызывать только один API-запрос (основной диалог). Это снизит расход токенов на 60-80%. Если эти функции вам нужны, можно через платформу APIYI (apiyi.com) настроить дешевую модель (например, gpt-4o-mini) специально для обработки этих фоновых задач.
Q3: Как отслеживать реальный расход токенов в OpenClaw?
Рекомендуем следующие способы мониторинга:
- Используйте панель статистики на APIYI (apiyi.com), чтобы видеть детальные данные по каждому вызову API.
- Проверяйте раздел Usage в панели управления OpenClaw.
- Следите за соотношением Prompt Token и Completion Token — если объем входящих токенов (Prompt) намного больше исходящих, значит фоновые задачи потребляют слишком много ресурсов.
Итоги
Основные причины высокого расхода токенов в OpenClaw:
- Скрытые фоновые вызовы — вот корень проблемы: каждое сообщение инициирует 4–5 независимых вызовов API, хотя пользователь видит только один.
- Использование дешевых моделей для задач — оптимальное решение: настройка
TASK_MODEL_EXTERNAL=gpt-4o-miniпозволяет снизить затраты на фоновые задачи на 90%, сохраняя при этом полную функциональность. - Особое внимание длинным диалогам: история переписки пересылается при каждом вызове. В диалоге из 30 реплик расход может достигать 1 млн токенов и более.
Применив эти советы по оптимизации, вы сможете снизить затраты на токены в OpenClaw на 60–80%, сделав использование API гораздо более экономичным.
Рекомендуем использовать APIYI (apiyi.com) для управления вашими вызовами API. Платформа предоставляет единый интерфейс и детальную статистику использования, что поможет вам точно контролировать расход токенов и затраты.
📚 Справочные материалы
-
Обсуждение расхода токенов в Open WebUI: ветка в сообществе GitHub, посвященная высокому потреблению токенов.
- Ссылка:
github.com/open-webui/open-webui/discussions/7281 - Описание: Пользователи делятся реальными данными о расходе и опытом оптимизации.
- Ссылка:
-
Документация по настройке переменных окружения Open WebUI: официальный справочник по конфигурации.
- Ссылка:
docs.openwebui.com/reference/env-configuration - Описание: Содержит список всех доступных переменных окружения и их значения по умолчанию.
- Ссылка:
-
Проблема расхода токенов при генерации уточняющих вопросов (Follow-up): потребление полного контекста при создании подсказок.
- Ссылка:
github.com/open-webui/open-webui/issues/15081 - Описание: Подробный анализ того, как шаблоны генерации последующих вопросов съедают огромное количество токенов.
- Ссылка:
-
Баг с дублированием системного промпта: наслоение системных инструкций при вызове инструментов (Agentic tools).
- Ссылка:
github.com/open-webui/open-webui/issues/19169 - Описание: Известная проблема, на которую стоит обратить внимание при использовании функций вызова инструментов.
- Ссылка:
Автор: Техническая команда APIYI
Техническое обсуждение: Будем рады пообщаться в комментариях. Больше материалов можно найти в нашем документационном центре: docs.apiyi.com